
Executive Summary
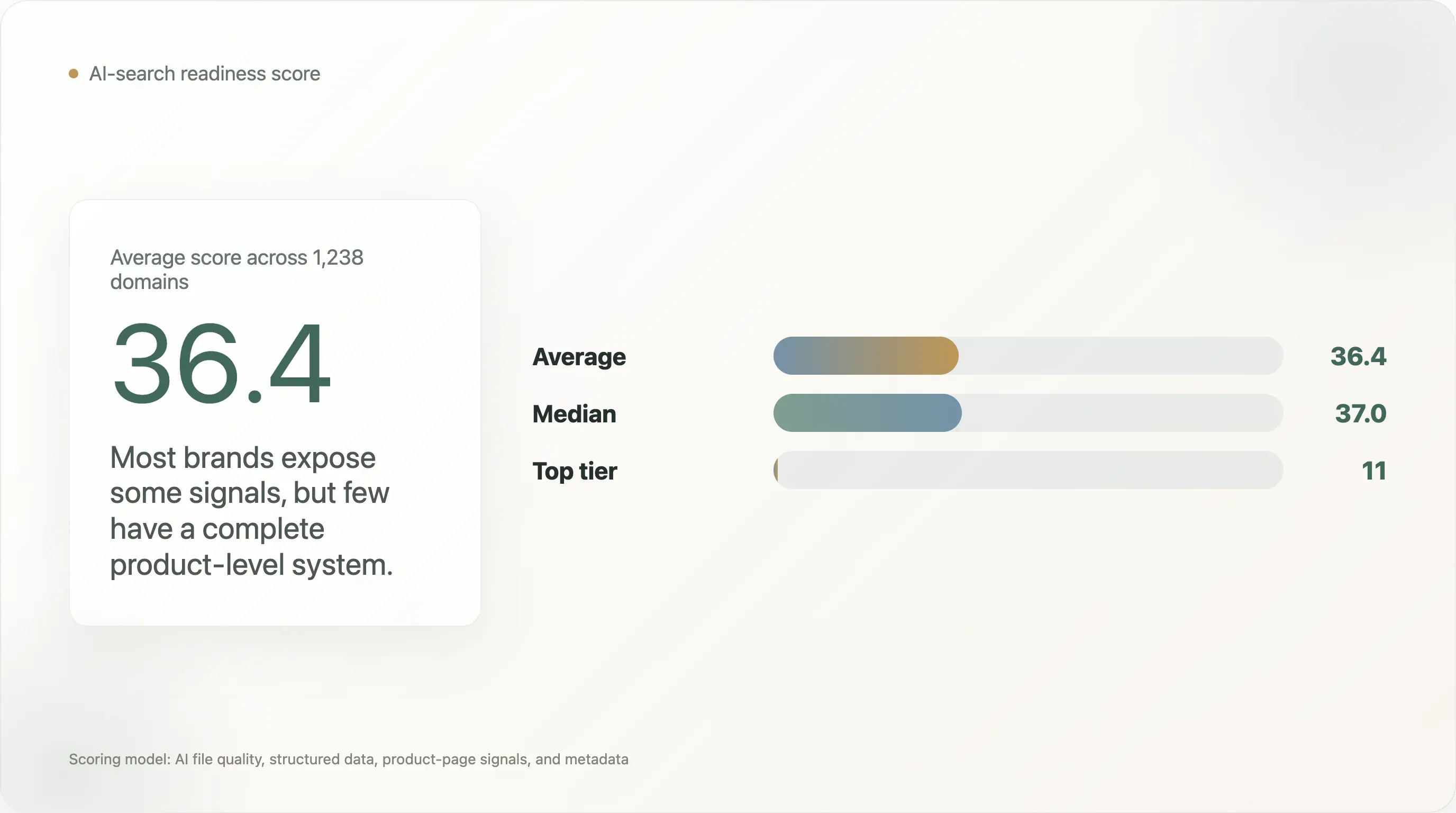
This research scores 1,238 DTC domains on AI-search readiness using four layers: AI file quality, general structured data, product-page structured signals, and metadata. The average score is 36.4 out of 100, and the median is 37.0. Only 11 domains reached the ai_ready tier under this scoring model.
The biggest finding is the gap between surface-level discoverability and product-level understanding. The largest llms.txt quality bucket is platform_default, with 629 domains. That means many brands have a basic AI-readable file because their platform generated it. But homepage Product schema appears on only 0.9% of scored domains, and product-page Product schema appears on 39.2% of scored domains where product pages were attempted. Product-page price signals appear on 48.1%, and review or rating signals on 43.5%.
The tier distribution shows how early the market still is:
| AI readiness tier | Domains |
|---|---|
| Not ready | 435 |
| Partially ready | 425 |
| Basic discoverability | 367 |
| AI ready | 11 |
That split is useful because it separates three ideas that are often mixed together. A brand may be discoverable. A brand may have metadata. A brand may have llms.txt. But being discoverable is not the same as being understandable at the product level.
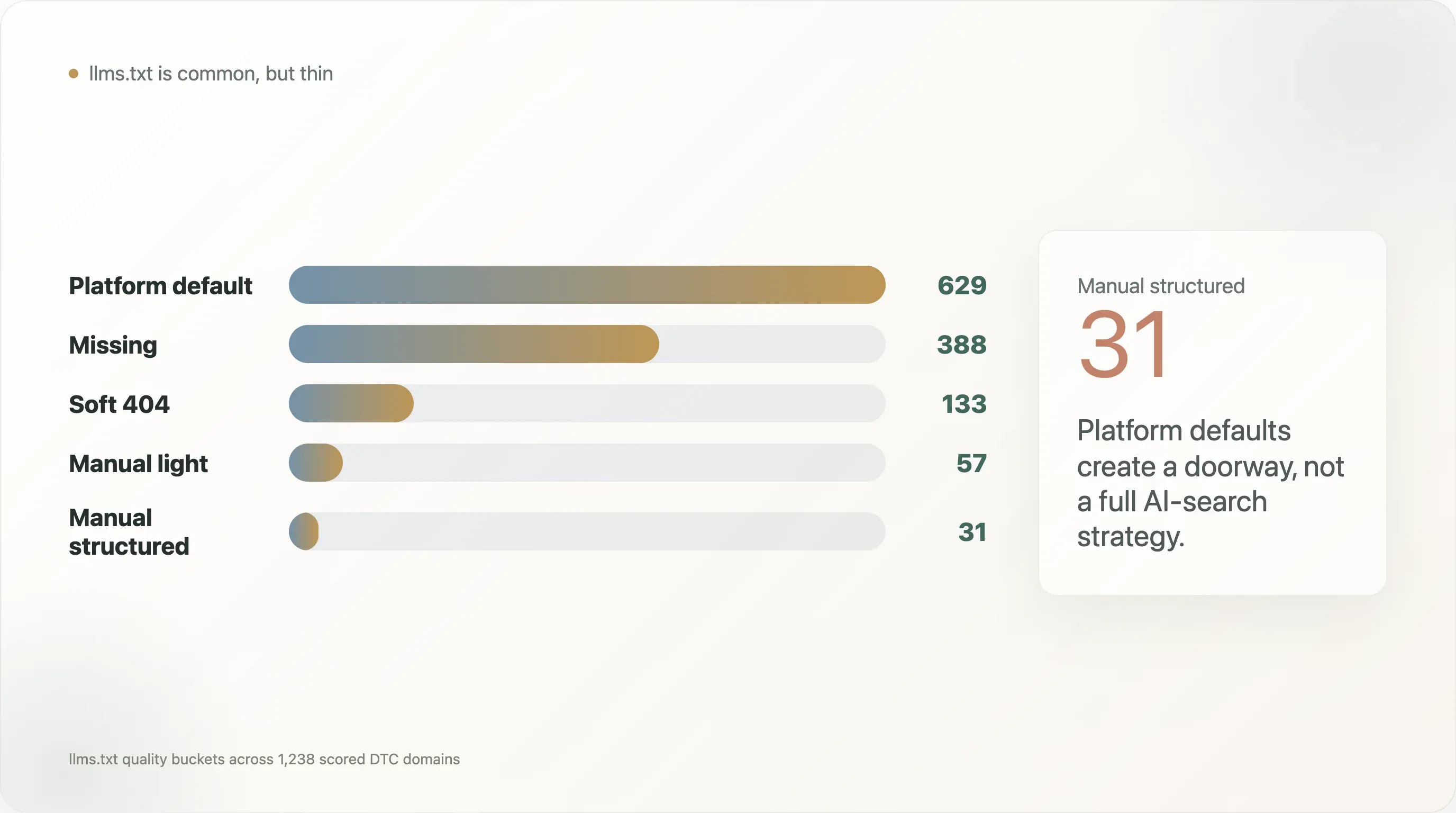
The llms.txt quality distribution makes this even clearer:
| llms.txt quality bucket | Domains |
|---|---|
| Platform default | 629 |
| Missing | 388 |
| Soft 404 | 133 |
| Manual light | 57 |
| Manual structured | 31 |
The strongest report angle is therefore not "DTC brands have llms.txt." That headline is too shallow. The better angle is: platform defaults have created a thin first layer of AI discoverability, but most DTC brands have not built the product-level structured data layer needed for AI shopping and answer engines.
Positive examples show what better readiness can look like. The ai_ready tier includes brands such as Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty, and Manukora. These examples matter because they show that AI readiness is not reserved for one category or one kind of brand. Food, beauty, wellness, furniture, apparel, and specialty commerce can all improve their machine-readable product layer.
The Most Shareable Findings
-
The average DTC AI-readiness score is only 36.4/100.
-
Only 11 of 1,238 scored domains reached the
ai_readytier. -
llms.txt is common, but mostly platform-generated. The largest quality bucket is platform default, with 629 domains.
-
Manual structured llms.txt is rare. Only 31 domains fall into the manual structured bucket.
-
Homepage Product schema is almost absent. It appears on only 0.9% of scored domains.
-
Product-page Product schema is better but still incomplete. It appears on 39.2% of scored domains where product pages were attempted.
-
AI shopping readiness requires product facts, not just crawler access. Price, offer, review, availability, and product schema signals matter more than a thin file alone.
1. Why AI Search Readiness Is Different From SEO Basics
Traditional SEO asks whether a page can be crawled, indexed, ranked, and clicked. AI search adds a different layer: can the system understand the brand, product, offer, price, reviews, availability, policies, and entity relationships well enough to answer questions or recommend products?
That difference matters for DTC because ecommerce pages are full of details that can be easy for a human and messy for a machine. A shopper can look at a product page and understand the product name, price, size, subscription option, discount, reviews, inventory status, and return policy. A crawler or AI agent needs those facts to be expressed consistently.
Metadata helps. Open Graph helps. Canonical tags help. llms.txt may help crawlers find important content. But product-level structure is the real test. If an AI shopping assistant is comparing five protein powders, skincare products, candles, dresses, or coffee subscriptions, it needs structured facts. Without those facts, the brand may be visible but not reliably understood.
This report separates four readiness layers:
- AI file layer: whether llms.txt exists and whether it is missing, soft 404, platform default, manual light, or manual structured.
- General structured data layer: JSON-LD, Organization, WebSite, BreadcrumbList, and Product schema.
- Product-page layer: Product schema, offer or price signals, rating or review signals, and availability signals.
- Metadata layer: canonical, meta description, Open Graph image, Twitter card, hreflang, and similar machine-readable context.
The layered model matters because it prevents a shallow conclusion. A brand with llms.txt but no product facts is not as ready as it looks. A brand without llms.txt but with rich product-page schema may be more understandable than the file layer suggests.
2. The llms.txt Story: A Thin Layer, Mostly Created by Platforms
The llms.txt audit produced five quality buckets:
| Quality bucket | Domains | Interpretation |
|---|---|---|
| Platform default | 629 | A standard platform-generated file, usually thin but valid |
| Missing | 388 | No usable file found |
| Soft 404 | 133 | A misleading or non-useful response |
| Manual light | 57 | Human-created or custom file, but limited structure |
| Manual structured | 31 | More substantial manual file with headings, links, product or policy terms |
This is the most important nuance in the report. On the surface, llms.txt adoption looks strong because platform-default files are common. But platform default is not the same as a thoughtful AI-search strategy. It is often a basic pointer layer.
That does not make platform-default files worthless. They may help crawlers find important paths. They also show how quickly platform-level decisions can move the market. A platform can give hundreds of stores a new machine-readable file before most brand teams have even discussed AI-search operations.
But the manual structured bucket is much smaller: 31 domains. Examples in the audit include manual structured files from brands such as Dermalogica, Ad Hoc Atelier, DKNY, and several ai_ready examples like Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, and Three Ships Beauty. These are useful positive examples because they show what it means to move beyond a default file: more links, more headings, more product terms, more policy terms, and more deliberate structure.
The soft-404 bucket is also important. A soft 404 means the request returns something, but not a useful llms.txt file. That can mislead simple audits. For AI-search readiness, existence checks are not enough. Quality checks matter.
3. Product-Level Structure Is the Real Gap
The strongest gap in the data is Product schema.
Homepage Product schema appears on only 0.9% of scored domains. Product-page Product schema appears on 39.2% of scored domains where product pages were attempted. Product-page price signals appear on 48.1%, and review or rating signals appear on 43.5%.
These numbers tell a clear story. Basic product facts are not consistently machine-readable, even when the brand has an ecommerce storefront.
This matters because AI search and AI shopping are likely to reward clarity. If a product page exposes Product schema, offers, price, availability, review signals, and policy links, it gives machines more reliable facts. If those facts are buried in JavaScript, inconsistent templates, images, or dynamic widgets, machines may misunderstand or ignore them.
The readiness gap is not just about ranking. It is about representation. When AI systems summarize a product category, compare options, answer "best for" questions, or generate shopping recommendations, brands with cleaner product facts may be easier to include accurately.
Positive examples from the ai_ready group make the point:
- Mokobara reached the highest score in the output at 83.
- Magic Mind, Le Petit Ballon, and Maine Lobster Now scored 81.
- Yo Mama's Foods scored 80.
- La Maison Convertible, Unbloat, Vinocheepo, and NuRange Coffee scored 79.
- Three Ships Beauty scored 77.
- Manukora scored 75.
These examples span categories. AI readiness is not a beauty-only issue or a tech-only issue. It matters for food, wellness, furniture, apparel, specialty products, and any category where a shopper may ask an AI system for recommendations, comparisons, or explanations.
4. AI-Readiness Tiers: Most Brands Are Still Below the Line
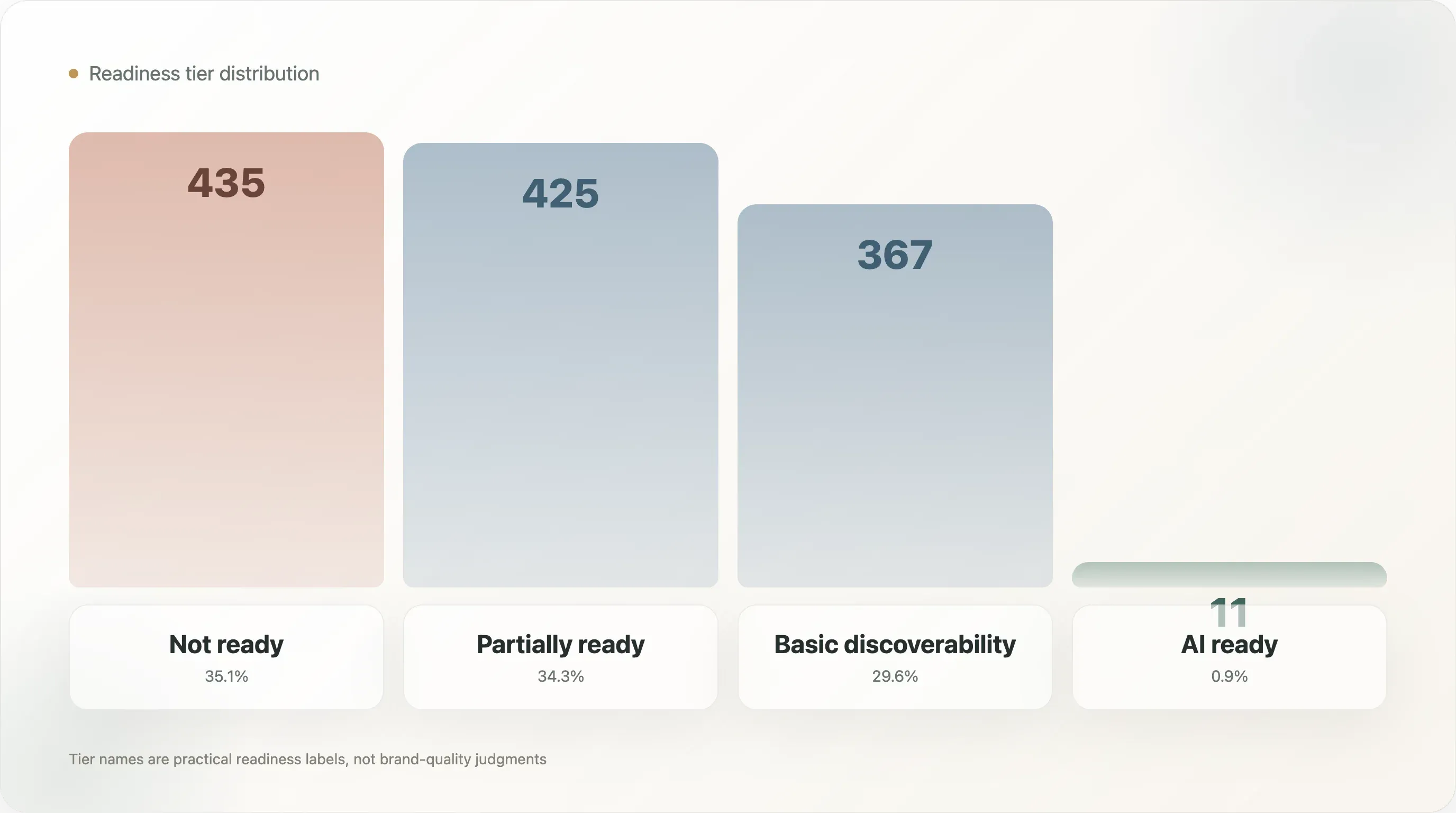
The tier distribution is:
| Tier | Domains | Share of sample |
|---|---|---|
| Not ready | 435 | 35.1% |
| Partially ready | 425 | 34.3% |
| Basic discoverability | 367 | 29.6% |
| AI ready | 11 | 0.9% |
The names are intentionally practical. Not ready does not mean the brand is bad. It means the public signals used by this model do not show enough AI-search readiness. Partially ready means some pieces exist, but important layers are missing. Basic discoverability means the brand is more visible to machines but may still lack product-level completeness. AI ready means the domain shows a stronger combination of file quality, structured data, product facts, and metadata.
Only 11 domains reached the top tier. That is the headline, but the more useful insight is the shape of the middle. The sample is almost evenly split among not ready, partially ready, and basic discoverability. The market is not empty. It is transitional. Many brands have some signals, but few have a complete system.
This creates a near-term opportunity. AI-search readiness is still early enough that a brand can move from average to strong with relatively practical work: improve llms.txt, validate schema, expose product facts, clean metadata, and make product pages easier for machines to parse.
5. Category Patterns: Beauty and Apparel Are Ahead, But No Category Is Finished
Category classification is directional, not exact. Still, the category table shows useful patterns:
| Category | Sample | Avg AI readiness | Manual or structured llms | Product-page schema | Product-page schema rate |
|---|---|---|---|---|---|
| Beauty & Skincare | 98 | 46.2 | 3 | 56 | 57.1% |
| Apparel & Footwear | 149 | 45.7 | 6 | 79 | 53.0% |
| Jewelry & Accessories | 34 | 44.5 | 0 | 20 | 58.8% |
| Pet | 15 | 43.5 | 0 | 8 | 53.3% |
| Baby & Kids | 27 | 42.6 | 1 | 15 | 55.6% |
| Food & Beverage | 118 | 42.5 | 5 | 58 | 49.2% |
| Home & Furniture | 48 | 42.3 | 0 | 23 | 47.9% |
| Health & Wellness | 58 | 40.7 | 6 | 27 | 46.6% |
| Outdoor & Sports | 49 | 39.8 | 1 | 23 | 46.9% |
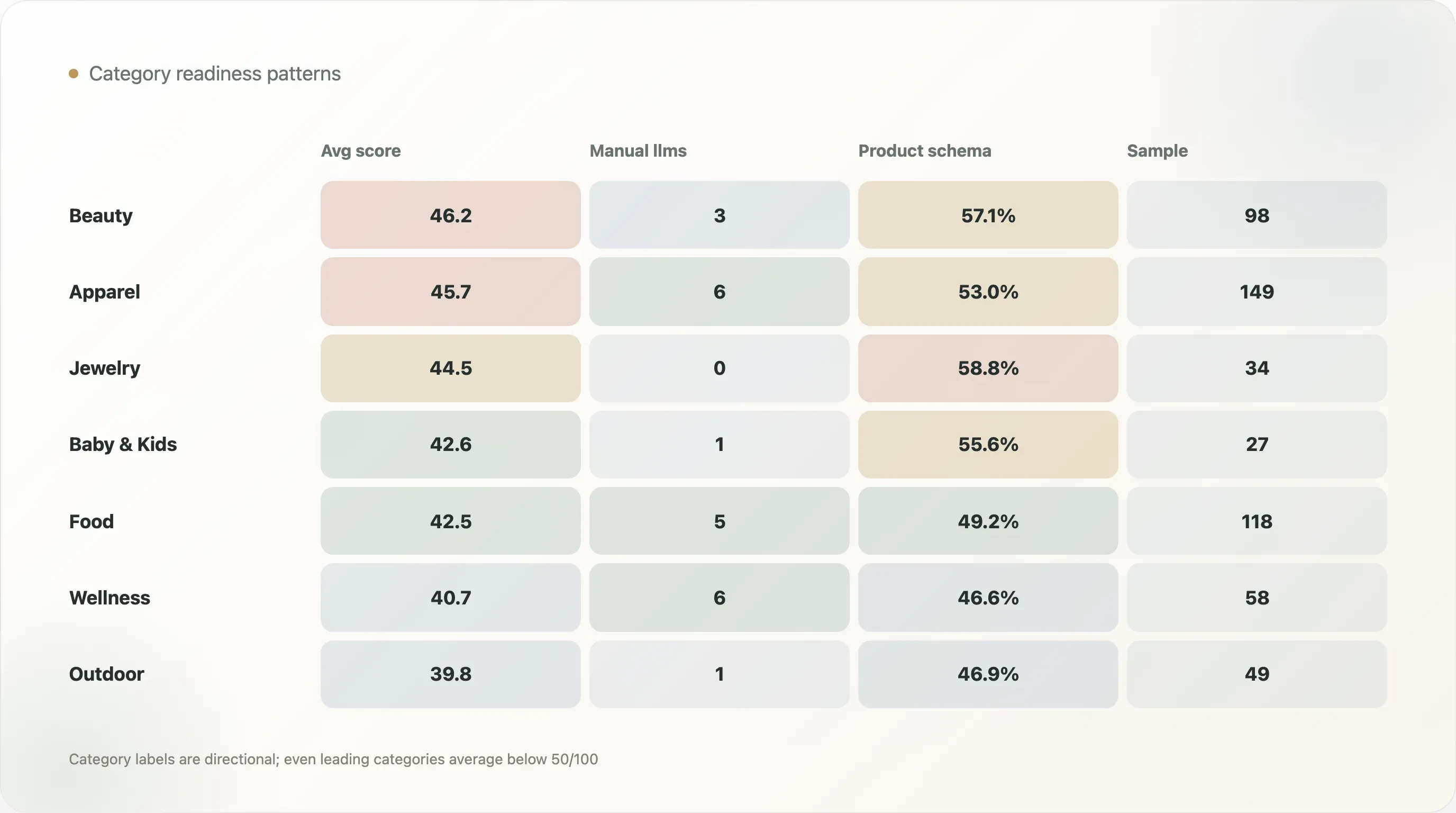
Beauty & Skincare has the highest average AI-readiness score at 46.2. Apparel & Footwear follows at 45.7. These categories often have strong ecommerce templates, rich product catalogs, reviews, variants, visual assets, and content needs. They may benefit more quickly from structured product work.
Jewelry & Accessories has a high product-page schema rate at 58.8%, but no manual or structured llms.txt detections in the category table. That shows why readiness must be layered. A category can be strong on product schema and weak on AI file quality.
Food & Beverage includes several strong positive examples, including Maine Lobster Now, Yo Mama's Foods, NuRange Coffee, and Manukora. This is important because food and beverage products often need clear facts: ingredients, nutrition, serving size, subscription, origin, shipping, storage, reviews, and availability. AI systems can only represent those details accurately if the site exposes them cleanly.
Health & Wellness has a manual or structured llms rate of 10.3%, the highest among major categories in the table, but an average score of 40.7. This suggests some brands in the category are actively experimenting with AI-readable files, while product-page structure still has room to improve. Given the trust and education burden in wellness, this category should be one of the most aggressive about structured facts.
No category is finished. Even the leading categories average below 50/100. That makes category-specific AI-readiness content a strong opportunity for SEO writers and consultants.
6. What Good Looks Like: Positive Patterns From AI-Ready Brands
The ai_ready group is small but useful because it shows patterns worth copying.
Mokobara scored 83, the highest in the output. It appears as an example of strong combined readiness rather than a single-signal win.
Magic Mind, Le Petit Ballon, and Maine Lobster Now each scored 81 and fall into the manual structured llms bucket. That matters because they show deliberate file-level work, not just platform defaults.
Yo Mama's Foods scored 80, also with manual structured llms. Food brands can benefit from AI-readable structure because AI systems may be asked about ingredients, flavor, use cases, recipes, dietary fit, and comparisons.
Three Ships Beauty scored 77 with manual structured llms. Beauty is an ideal category for structured AI readiness because shoppers ask about skin type, ingredients, routines, texture, reviews, and alternatives.
Manukora scored 75. Honey and wellness-adjacent food products often require education around origin, quality, benefits, certifications, and usage, making structured product and policy signals valuable.
The lesson is not that every brand needs to look identical. The lesson is that AI readiness is a system:
- A useful llms.txt file
- Clean metadata
- Structured organization and website data
- Product-page schema
- Price and offer signals
- Review or rating signals
- Availability signals
- Policy and support clarity
Any one layer helps. The combination is what creates readiness.
7. Why llms.txt Alone Is Not Enough
llms.txt has become a convenient shorthand for AI readiness. That is understandable because it is visible, easy to check, and new enough to feel strategic. But this research shows why it should not be treated as the whole story.
A platform-default llms.txt file can create a basic doorway. It may point crawlers to important pages. It may tell machines that the site has an AI-readable entry point. But if the product pages do not expose product facts clearly, the doorway leads to a messy room.
The AI-search problem is not only "can the crawler find the site?" It is:
- Can the crawler identify the product?
- Can it identify the brand?
- Can it parse price?
- Can it parse availability?
- Can it identify reviews or ratings?
- Can it distinguish product content from marketing content?
- Can it understand policies?
- Can it compare variants?
- Can it cite the right canonical page?
llms.txt helps with navigation and prioritization. Structured product data helps with understanding. AI readiness requires both.
8. The Operator Playbook: How to Improve AI Search Readiness
For DTC and ecommerce teams, the practical workflow is straightforward.
Step 1: Check the AI file layer. Does the domain have llms.txt? Is it real, or is it a soft 404? Is it platform default, manual light, or structured? Does it point to useful pages?
Step 2: Audit metadata. Confirm canonical tags, meta descriptions, Open Graph images, Twitter cards, hreflang where relevant, and mobile viewport. These are not glamorous, but they help machines build context.
Step 3: Validate JSON-LD. Check Organization, WebSite, BreadcrumbList, and Product schema. Product schema is the most important ecommerce gap.
Step 4: Audit product pages, not just the homepage. AI shopping will care about product pages. Confirm product name, description, image, price, offer, availability, SKU, reviews, ratings, variants, and return policy.
Step 5: Make product facts stable. Avoid burying critical product facts only in images, tabs that do not render cleanly, or JavaScript widgets that crawlers may not parse.
Step 6: Improve policy clarity. Shipping, returns, subscription terms, guarantees, certifications, and safety claims should be easy to find and easy to parse.
Step 7: Re-test after template changes. Schema often breaks during redesigns, theme changes, app changes, and headless migrations. Treat structured data as part of QA.
Step 8: Own the system. AI readiness should not sit only with SEO. It touches ecommerce, product, content, engineering, legal, and customer support.
9. What SEO and Content Teams Can Cite
This research creates several strong citation angles:
"Only 11 of 1,238 scored DTC domains reached the AI-ready tier." This is the broadest readiness hook.
"llms.txt is common, but mostly platform-generated." The platform-default bucket contains 629 domains, while manual structured files appear on only 31.
"Homepage Product schema appears on only 0.9% of scored domains." This is the sharpest structured-data gap.
"Product-page Product schema appears on 39.2% where product pages were attempted." This adds nuance: product pages are better than homepages, but still incomplete.
"Beauty and Apparel lead the category table, but still average below 50/100." This creates a category-specific angle.
"AI readiness is layered." This is the most important educational point for readers who may otherwise equate llms.txt with readiness.
The caveat is essential: the data reflects public website signals in this sample, not total industry adoption and not internal search performance.
10. What AI Shopping Changes for DTC Teams
Traditional ecommerce discovery was built around pages, rankings, ads, and clicks. A shopper searched, compared results, opened pages, read reviews, and made decisions. AI shopping and answer engines compress that journey. A shopper may ask for "the best low-sugar sauce for weeknight pasta," "a carry-on backpack under $200 with good reviews," or "a gentle cleanser for sensitive skin with no fragrance." The AI system may summarize options before the shopper ever sees a brand's page.
That changes the job of the product page. The page still has to persuade humans, but it also has to describe the product clearly enough for machines to compare it. Brand tone is not enough. Beautiful imagery is not enough. A clever product name is not enough. The machine needs facts: what it is, who it is for, what it costs, whether it is available, what variants exist, what reviews say, what claims are supported, what ingredients or materials matter, and what policies apply.
This is why product-level structure matters more than a generic AI file. llms.txt can help a crawler understand where to look. Product schema and clean product-page facts help it understand what it found.
The risk for DTC brands is not only being excluded. It is being misrepresented. If a product page is unclear, an AI answer may summarize the wrong feature, miss a key differentiator, omit an important policy, or compare the product unfairly against better-structured competitors. In that sense, AI readiness is partly a brand-protection issue.
For categories with complex consideration paths, the stakes are higher. Beauty shoppers ask about skin type, ingredients, routines, sensitivity, and results. Food shoppers ask about nutrition, allergens, origin, flavor, recipes, and dietary fit. Apparel shoppers ask about fit, size, materials, returns, and styling. Wellness shoppers ask about evidence, usage, safety, and trust. Home shoppers ask about dimensions, materials, delivery, assembly, and durability. These are all machine-readable content problems as much as marketing problems.
The opportunity is that most brands are still early. The average readiness score is only 36.4/100, and only 11 domains reached the ai_ready tier. A brand does not need to wait for a full site rebuild. It can start with templates, schema, policy clarity, and product facts.
11. A Department-by-Department AI Readiness Plan
AI readiness should not belong only to SEO. It touches several teams.
SEO owns discoverability and schema validation. SEO teams should audit canonical tags, metadata, structured data, product schema, breadcrumbs, hreflang, and crawlability. They should also monitor whether product schema survives theme changes and app updates.
Ecommerce owns product-page facts. Product names, prices, variants, availability, bundles, subscriptions, reviews, shipping terms, and return details must be clear and consistent. If those facts are fragmented across widgets, tabs, images, and scripts, machines may struggle.
Content owns explanatory depth. AI systems reward pages that clearly answer questions. Buying guides, comparison tables, ingredient explainers, use-case pages, sizing guidance, and FAQ sections can help both humans and machines.
Engineering owns implementation quality. Schema should be valid, stable, and template-driven. Product facts should not depend entirely on fragile client-side rendering. Product-page templates should be tested after releases.
Legal and compliance own claims. If a product makes health, sustainability, safety, ingredient, or performance claims, those claims should be accurate, supportable, and easy to interpret. AI systems may amplify unclear claims.
Customer support owns recurring questions. Support tickets reveal what shoppers and AI systems may ask: shipping time, fit, ingredients, compatibility, returns, subscription cancellation, care instructions, and product comparisons. Those questions should feed product-page content.
Leadership owns prioritization. AI readiness competes with many other projects. The leadership case is simple: structured product facts support SEO, AI search, product feeds, paid shopping, onsite search, support, and conversion. This is not only an AI project.
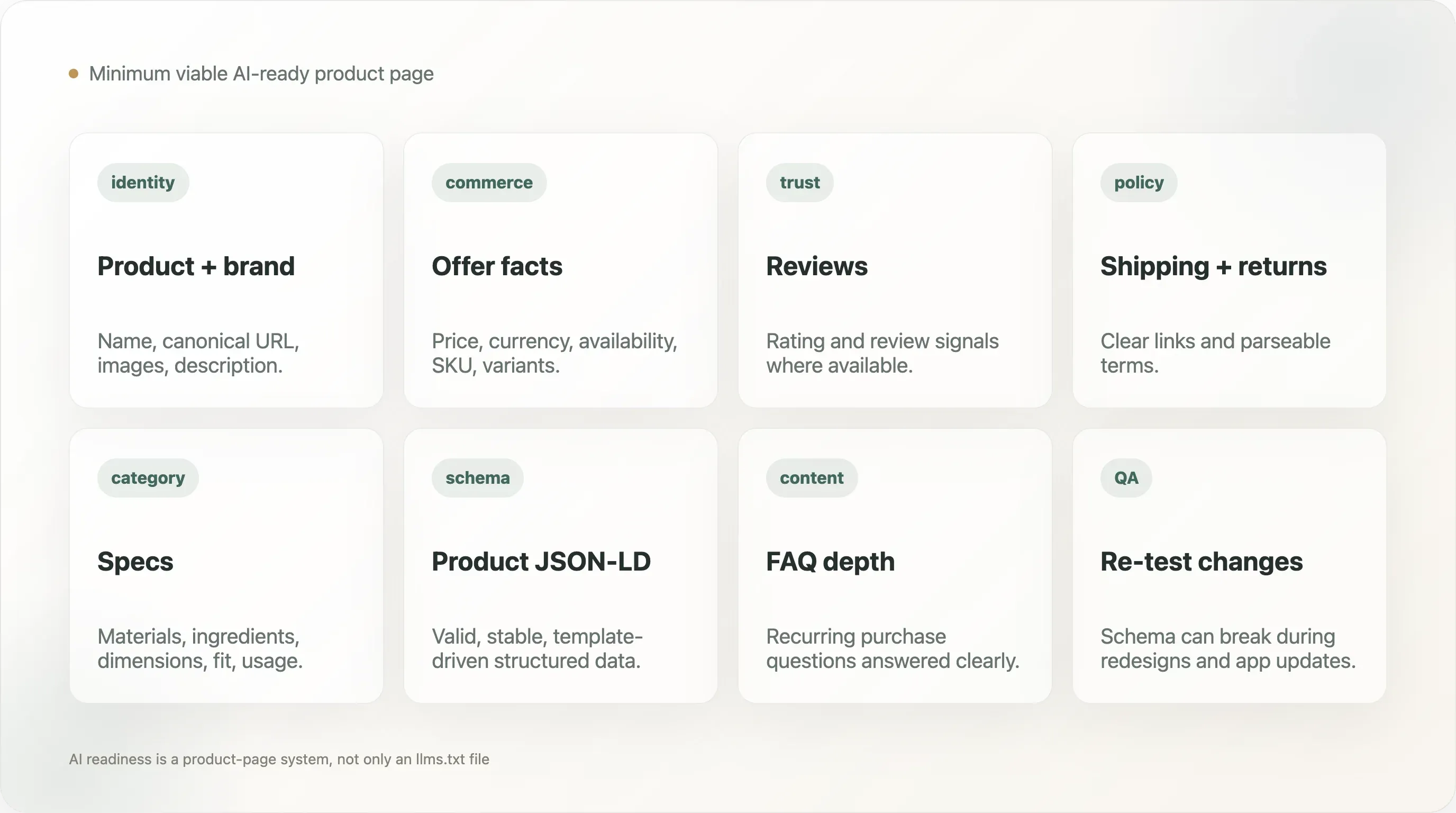
12. The Minimum Viable AI-Ready Product Page
A practical DTC product page should expose:
- Product name
- Brand name
- Canonical URL
- Product description
- Product images
- Price
- Currency
- Availability
- Variant information
- SKU or product identifier where relevant
- Review or rating signals where available
- Offer details
- Shipping and return policy links
- Material, ingredient, or specification facts where category-relevant
- FAQ or support content for recurring purchase questions
The page should also include valid Product schema and avoid hiding critical facts only inside images or scripts that crawlers may not parse. This does not require boring product pages. It requires a separation between persuasive design and reliable structured facts.
For many brands, the fastest win is not writing a long AI strategy document. It is validating ten important product pages, fixing schema, and making sure the most important product facts are visible in the HTML and structured data.
Methodology
This research uses the DTC dual-report dataset collected on May 11, 2026. It scores 1,238 domains using master.csv, detection.csv, seo_signals.csv, raw llms.txt files, and raw product-page HTML where available.
The scoring model separates four layers:
- AI file layer: llms.txt existence and quality.
- General structured data layer: JSON-LD, Organization, WebSite, BreadcrumbList, Product, and related structured signals.
- Product-page layer: Product schema, offer or price signals, review or rating signals, and availability signals.
- Metadata layer: canonical, meta description, Open Graph image, Twitter card, hreflang, and related page context.
The model produces an AI-readiness score from 0 to 100 and assigns domains to one of four tiers: not ready, partially ready, basic discoverability, and ai_ready.
Caveats
-
AI readiness is not AI traffic. The score does not measure actual referrals from AI search systems or shopping agents.
-
Public signals are a lower bound. Some structured data may load dynamically or appear in ways the crawl did not capture.
-
llms.txt quality is heuristic. Manual structured files are identified through observable file characteristics such as headings, links, product terms, and policy terms.
-
Product-page detection depends on attempted product-page fetches. Product-page schema percentages apply where product pages were attempted and available.
-
The sample is not a full DTC census. It is biased toward brands visible in ecommerce tool ecosystems and public DTC lists.
-
Category labels are directional. They are useful for broad comparison but not exact taxonomy.
-
AI-search standards are still evolving. The scoring model is designed as a practical 2026 benchmark, not a permanent definition.
Reproducibility Notes
The delivery folder includes:
analyze_ai_search_readiness.py— scoring script used to evaluate DTC domains acrossllms.txt, structured data, product-page signals, and metadata signals.ai_search_readiness_scores.csv— domain-level AI readiness scores, tiers, and component signals.llms_quality_audit.csv— domain-levelllms.txtquality audit, including platform-default, soft-404, missing, manual-light, and manual-structured classifications.category_ai_readiness.csv— category-level AI readiness comparison.top_ai_ready_brands.csv— highest-scoring domains for editorial review and example selection.lowest_ai_ready_brands.csv— lowest-scoring domains for gap analysis and editorial review.summary.json— headline aggregate metrics quoted in this report, including sample size, tier counts, average score, median score, and product-page signal rates.
Methodology corrections, dataset issues, and follow-up analyses welcome at support@thunderbit.com. This report is published independent of any commercial position Thunderbit holds; we build an AI-powered web scraper, and we have a structural interest in public ecommerce websites becoming easier for humans, search engines, and AI agents to understand accurately. The benchmark is based on 1,238 scored DTC domains from public website signals collected on May 11, 2026. The data in this report stands on its own. — The Thunderbit research team, May 2026.