
The web is growing faster than ever, and if you’re in business, tech, or just a data nerd like me, you’ve probably noticed: the real gold is in the data you can collect—not just the data you can see. These days, companies are racing to automate web data collection, with the global web scraping industry expected to hit . And here’s a fun fact: over now use web crawlers or scrapers to feed their AI, analytics, and business workflows.
So, how do you get in on this action? For most people, the answer is Python. It’s the go-to language for building website crawlers—simple, powerful, and loaded with libraries that make crawling and scraping a breeze. In this guide, I’ll walk you through what a website crawler is, why Python is the top pick, how to build your own crawler step by step, and how tools like can make the whole process even easier (especially if you’d rather click than code). Whether you’re a developer, a data-driven marketer, or just someone who wants to automate the boring stuff, you’ll find something here to take your web data game to the next level.
What Is a Website Crawler? (And Why Should You Care?)
Let’s break it down: a website crawler is a program that automatically browses the web, visiting pages, following links, and (optionally) collecting data along the way. Think of it as a superhuman web surfer—one that never sleeps, never gets bored, and never accidentally closes the wrong tab. Crawlers are the backbone of search engines (like Googlebot), but they’re also used by businesses for everything from price monitoring to market research.
But wait—what’s the difference between crawling and scraping? Crawling is about discovering and navigating pages (like mapping out a city), while scraping is about extracting specific data from those pages (like collecting all the restaurant menus in town). In practice, most projects do both: crawl to find the pages, scrape to get the data you need ().
Real-world business use cases for crawlers:
- Lead generation: Automatically gather contact info from directories or social media.
- Price monitoring: Track competitors’ prices and inventory across thousands of products.
- Content monitoring: Get alerts when your brand is mentioned in news, blogs, or forums.
- SEO auditing: Scan your own site for broken links or missing metadata.
- Market research: Aggregate real estate listings, job postings, or product reviews for analysis.
If you’ve ever wished you could clone yourself to keep up with web research, a crawler is the next best thing.
Why Website Crawlers Matter for Business Automation
Let’s get practical. Why are businesses investing in crawlers and scrapers? Because the ROI is massive. Here’s a quick look at how different teams use crawlers—and what they get out of it:
| Use Case | Key Benefit | Who Uses It |
|---|---|---|
| Lead Generation | Automates prospect list building, saves hours | Sales, Recruiting |
| Price Tracking | Real-time competitor insights, dynamic pricing | E-commerce, Product Teams |
| Content Monitoring | Brand protection, trend spotting | Marketing, PR |
| SEO Site Audit | Site health, improved rankings | SEO, Webmasters |
| Market Research | Up-to-date, large-scale datasets for analysis | Analysts, Research Teams |
One case study found that automating a weekly data collection task (scraping 5-7 websites) saved a single employee over 50 hours a year—multiply that across a team, and you see why once they start using crawlers.
Python: The Top Choice for Building a Website Crawler
 So, why is Python the king of web crawling? Three big reasons:
So, why is Python the king of web crawling? Three big reasons:
- Simplicity: Python’s syntax is readable, beginner-friendly, and lets you write working crawlers in just a few lines.
- Library Ecosystem: Python has a rich set of libraries for every part of crawling—fetching pages, parsing HTML, handling JavaScript, and more.
- Community: With nearly powered by Python, there’s a huge community, tons of tutorials, and answers to almost any problem you’ll hit.
Top Python libraries for web crawling:
- Requests: The easiest way to fetch web pages (HTTP GET/POST).
- BeautifulSoup: The go-to for parsing HTML and finding elements.
- Scrapy: A full-featured crawling framework for large-scale projects.
- Selenium: Automates browsers for scraping JavaScript-heavy sites.
Compared to other languages (like Java or C#), Python lets you go from idea to working crawler in a fraction of the time. And if you’re a data person, you can plug your crawler output straight into Pandas for analysis—no messy exporting/importing.
Comparing Parsing Methods: Regex vs. BeautifulSoup vs. Scrapy
When it comes to extracting data from web pages, you’ve got options. Here’s how the main methods stack up:
| Method | How It Works | Pros 🟢 | Cons 🔴 | Best For |
|---|---|---|---|---|
| Regex | Pattern-match raw HTML | Fast for simple, known patterns | Brittle, breaks on HTML changes | Quick hacks, extracting URLs |
| BeautifulSoup | Parses HTML into a tree, search by tags | Easy, flexible, handles messy HTML | Slower on huge pages, manual crawl logic | Most small/medium scraping scripts |
| Scrapy | Full crawling framework, CSS/XPath parsing | Fast, scalable, handles crawling & parsing | Steeper learning curve, more setup | Large-scale, production crawlers |
- Regex is like using a metal detector on a beach—quick, but you’ll miss things if the sand shifts.
- BeautifulSoup is like having a map and a shovel—you can dig anywhere, but you have to walk the beach yourself.
- Scrapy is like bringing a whole team with trucks and GPS—overkill for a sandbox, but unbeatable for big jobs.
For most beginners, I recommend starting with Requests + BeautifulSoup. You’ll learn the fundamentals, and you can always “graduate” to Scrapy when you’re ready to scale up.
Step-by-Step: How to Build a Simple Website Crawler in Python
Ready to get your hands dirty? Let’s build a basic crawler that visits pages, follows links, and grabs some data. I’ll walk you through each step, with code you can copy and tweak.
Step 1: Setting Up Your Python Environment
First, make sure you have Python 3.10+ installed. (Check with python --version.) I recommend creating a virtual environment for your project:
1python -m venv venv
2source venv/bin/activate # On Windows: venv\Scripts\activateThen, install the libraries you’ll need:
1pip install requests beautifulsoup4That’s it! Open your favorite code editor and get ready to write your crawler.
Step 2: Writing Your First Website Crawler Script
Let’s start by fetching a single page. Here’s a simple script:
1import requests
2def crawl_page(url):
3 response = requests.get(url)
4 response.raise_for_status() # Throws error if not 200 OK
5 print(response.text[:500]) # Print first 500 chars for preview
6crawl_page("https://www.scrapingcourse.com/ecommerce/")You should see a chunk of HTML in your console—proof you’re talking to the web.
Step 3: Following Links and Collecting More Data
Now, let’s make our crawler follow links and visit multiple pages. We’ll keep a list of URLs to visit, and a set of URLs we’ve already seen (to avoid loops):
1from bs4 import BeautifulSoup
2start_url = "https://www.scrapingcourse.com/ecommerce/"
3urls_to_visit = [start_url]
4visited_urls = set()
5max_pages = 20 # Safety limit
6while urls_to_visit and len(visited_urls) < max_pages:
7 current_url = urls_to_visit.pop(0)
8 try:
9 resp = requests.get(current_url)
10 resp.raise_for_status()
11 except Exception as e:
12 print(f"Failed to retrieve \{current_url\}: \{e\}")
13 continue
14 soup = BeautifulSoup(resp.text, "html.parser")
15 print(f"Crawled: \{current_url\}")
16 for link_tag in soup.find_all("a", href=True):
17 url = link_tag['href']
18 if not url.startswith("http"):
19 url = requests.compat.urljoin(current_url, url)
20 if url.startswith(start_url) and url not in visited_urls:
21 urls_to_visit.append(url)
22 visited_urls.add(current_url)This script will crawl up to 20 pages, following links that stay within the same site. You’ll see each URL as it’s crawled.
Step 4: Extracting Data from Pages
Let’s say you want to grab product names and prices from each page. Here’s how you might do it:
1product_data = []
2while urls_to_visit and len(visited_urls) < max_pages:
3 # ... (same as above)
4 soup = BeautifulSoup(resp.text, "html.parser")
5 if "/page/" in current_url or current_url == start_url:
6 items = soup.find_all("li", class_="product")
7 for item in items:
8 name = item.find("h2", class_="product-name")
9 price = item.find("span", class_="price")
10 link = item.find("a", class_="woocommerce-LoopProduct-link")
11 if name and price and link:
12 product_data.append({
13 "name": name.get_text(),
14 "price": price.get_text(),
15 "url": link['href']
16 })
17 # ... (rest of crawl logic)
18# Save to CSV
19import csv
20with open("products.csv", "w", newline="") as f:
21 writer = csv.DictWriter(f, fieldnames=["name", "price", "url"])
22 writer.writeheader()
23 writer.writerows(product_data)
24print(f"Scraped {len(product_data)} products.")Now you’ve got a CSV file with all your scraped products—ready for analysis, uploading, or bragging to your friends.
Step 5: Debugging and Optimizing Your Crawler
Building a crawler is one thing; making it robust is another. Here are some tips from my own experience (and a few hard-earned headaches):
- Set a User-Agent header: Some sites block “Python-requests” by default. Pretend to be a browser:
1headers = {"User-Agent": "Mozilla/5.0"} 2requests.get(url, headers=headers) - Handle errors gracefully: Use try/except to skip over broken or blocked pages.
- Avoid infinite loops: Always track visited URLs, and set a max page limit.
- Throttle your requests: Add
time.sleep(1)between requests to avoid getting blocked. - Check robots.txt: Always respect a site’s crawling rules ().
- Log your progress: Print or log each URL as you crawl—it’s a lifesaver for debugging.
If you ever find your crawler getting blocked, returning weird content, or missing data, check your headers, slow down, and make sure you’re not running afoul of anti-bot measures.
Thunderbit: Simplifying Website Crawling with AI
Now, let’s talk about the “easy button” for web crawling: . As much as I love Python, sometimes you just want the data—without the setup, debugging, or maintenance. Thunderbit is an AI-powered web scraper Chrome extension that lets you scrape data from any website in just a couple of clicks.
What makes Thunderbit special?
- AI Suggest Fields: Thunderbit’s AI scans the page and recommends what data you can extract—no need to inspect HTML or write selectors.
- No-code, browser-based: Runs in your browser, so it works with logged-in sites and JavaScript-heavy pages.
- Subpage Scraping: Need more details? Thunderbit can automatically visit each subpage (like product details) and enrich your table.
- Instant export: Export your data to Excel, Google Sheets, Airtable, or Notion—no CSV wrangling required.
- Cloud or local scraping: Choose between fast cloud scraping (for public sites) or browser mode (for logged-in or tricky sites).
- Scheduling: Set up scrapes to run automatically—no cron jobs or servers needed.
For business users, Thunderbit is a game changer. You can go from “I need this data” to “Here’s my spreadsheet” in minutes, not hours. And if you’re a developer, Thunderbit can complement your scripts—use it for quick jobs, or as a backup when your code needs a break.
Want to see how it works? and try scraping your favorite site. The free tier lets you scrape a handful of pages, and paid plans start at just $15/month for 500 credits.
Key Considerations When Building a Website Crawler in Python
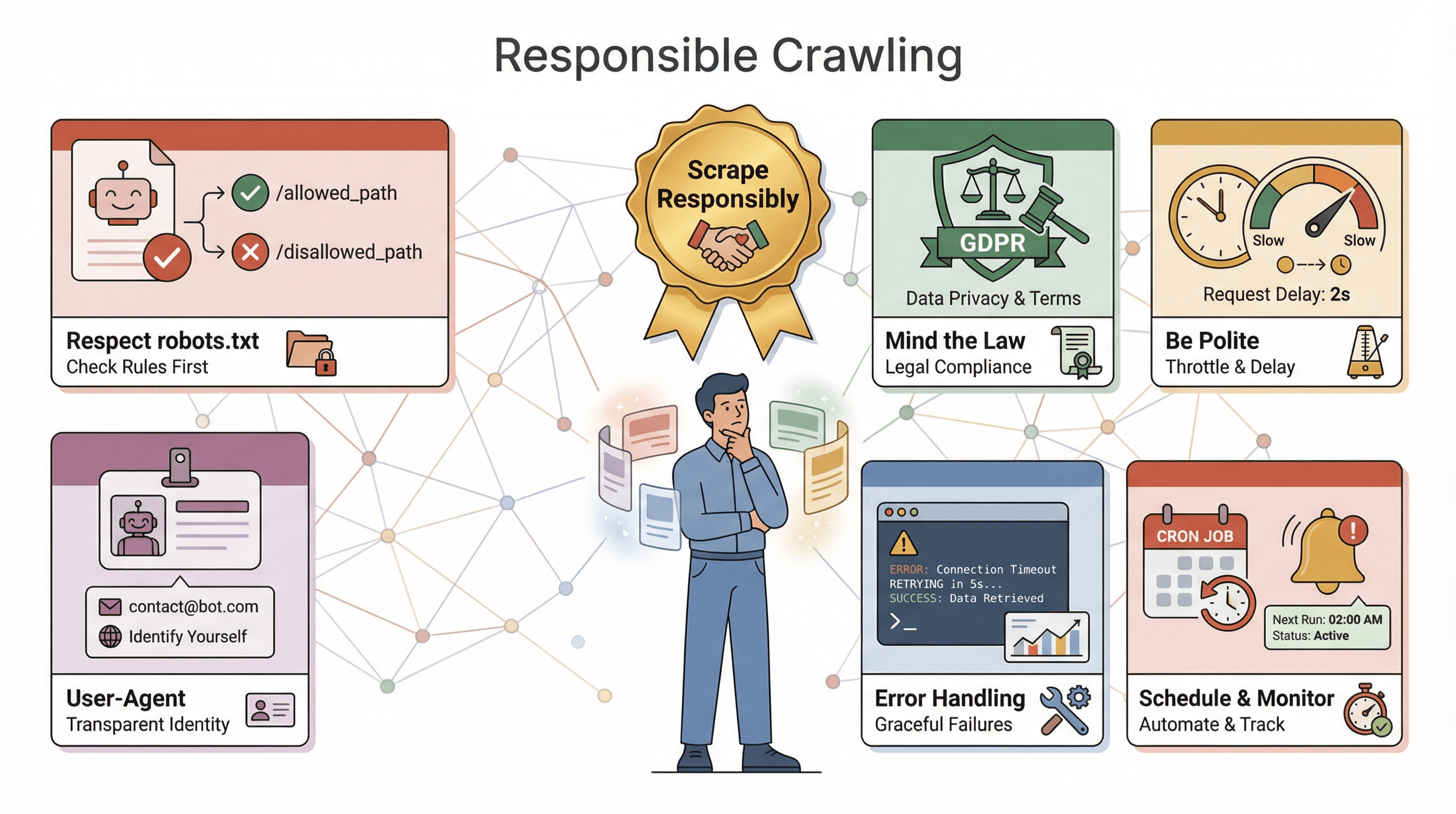 Before you unleash your crawler on the world, a few words of caution (and wisdom):
Before you unleash your crawler on the world, a few words of caution (and wisdom):
- Respect robots.txt: Most sites publish a
robots.txtfile that tells crawlers what’s allowed. Ignoring it can get you blocked—or worse, in legal trouble. Always check and obey these rules (). - Mind the law: Some sites’ terms of service forbid scraping. And if you’re collecting personal data, privacy laws like GDPR and CCPA may apply (). When in doubt, stick to public, non-sensitive data.
- Be polite: Don’t hammer sites with requests—throttle your crawler, randomize delays, and avoid scraping during peak hours.
- Identify yourself: Use a custom User-Agent string, and consider including contact info if you’re scraping at scale.
- Handle errors and logging: Expect sites to change, pages to break, and data to get messy. Build in error handling, logging, and monitoring so you can fix issues fast.
- Schedule and monitor: For regular crawls, use scheduling tools (like cron or Thunderbit’s built-in scheduler), and set up alerts if your crawler starts failing or collecting zero data.
The golden rule: scrape responsibly. The web is a shared resource—don’t be “that bot” that ruins it for everyone.
Advanced Tips: Scaling and Enhancing Your Python Website Crawler
Once you’ve mastered the basics, you might want to level up your crawler. Here are some advanced moves:
- Handle JavaScript: Use Selenium or Playwright to scrape sites that load data dynamically.
- Scale up: For big projects, move to Scrapy or use async libraries (like
aiohttp) for concurrent requests. - Use proxies: Rotate IP addresses to avoid blocks on high-volume crawls.
- Automate data pipelines: Write directly to databases, or integrate with cloud storage for large datasets.
- Monitor and alert: Set up logging, health checks, and notifications for long-running crawlers.
If your crawler becomes mission-critical, consider using managed services or APIs to offload the heavy lifting. And if you’re scraping multiple sites with different layouts, modularize your code so you can update parsers easily.
Conclusion & Key Takeaways
Building a website crawler in Python is one of the most empowering skills you can pick up in today’s data-driven world. Here’s what we covered:
- Website crawlers automate the process of visiting and extracting data from web pages—a must-have for business automation, research, and competitive intelligence.
- Python is the top choice for building crawlers, thanks to its simple syntax, powerful libraries, and massive community.
- Parsing methods matter: use regex for quick hacks, BeautifulSoup for most scripts, and Scrapy for big jobs.
- Step-by-step, you can go from fetching a page to crawling a whole site and saving structured data—no PhD required.
- Thunderbit takes things even further, letting you scrape data with AI, no code, and instant exports—perfect for business users or anyone who wants results fast.
- Responsible crawling is key: respect site rules, handle errors, and always put ethics first.
- Scaling up is possible with the right tools—whether that’s Selenium for JavaScript, Scrapy for concurrency, or Thunderbit for no-code automation.
The best way to learn is to start small—write a script, try Thunderbit, and see what data you can unlock. The web is your oyster (or your data buffet, if you’re hungry like me).
Want to dive deeper? Check out these resources:
- for more tips, guides, and advanced techniques.
Happy crawling—and may your scrapers be fast, your data be clean, and your coffee never run out.
FAQs
1. What’s the difference between a website crawler and a web scraper?
A crawler systematically visits and discovers web pages (like mapping a site), while a scraper extracts specific data from those pages. Most real-world projects use both: crawl to find pages, scrape to get the data.
2. Why is Python so popular for building website crawlers?
Python is easy to learn, has powerful libraries (like Requests, BeautifulSoup, Scrapy, Selenium), and a huge community. Nearly 70% of web scraping projects use Python, making it the industry standard.
3. When should I use regex, BeautifulSoup, or Scrapy for parsing?
Use regex for simple, predictable patterns. BeautifulSoup is best for most scripts—easy and flexible. Scrapy is ideal for large-scale or production crawlers that need speed, concurrency, and robust features.
4. How does Thunderbit compare to coding a crawler in Python?
Thunderbit lets you scrape data with AI and no code—just click, select fields, and export. It’s perfect for business users or quick jobs. Python gives you more control and customization, but requires coding and maintenance.
5. What legal or ethical issues should I watch out for when crawling websites?
Always check and respect robots.txt, follow site terms of service, avoid collecting sensitive or personal data without consent, and throttle your requests to avoid overloading servers. Responsible scraping keeps the web open for everyone.
Ready to try it yourself? or fire up your favorite Python editor and start crawling. The data’s out there—go get it!
Learn More