

“You can have data without information, but you cannot have information without data.” — Daniel Keys Moran
Recent estimates suggest there are over 1.5 billion websites on the internet, with around 2 million new posts published every day. This ocean of data holds valuable insights for guiding decisions, but there’s a catch: about 80% of it is unstructured, meaning it needs additional processing to be useful. That’s where web scraping tools come in, becoming essential for anyone looking to tap into online data.
If you’re new to web scraping, terms like web components and HTML might sound a bit intimidating. But in the age of AI, these challenges are much easier to overcome. Today’s AI-powered scraping tools can help you get started without requiring deep technical knowledge. These tools make it possible to collect and process data quickly, no coding skills are needed.
The Best Web Scraping Tools & Software
- Thunderbit for an easy-to-use AI web scraper with the best results
- Browse AI for real-time monitoring and bulk data extraction
- Bardeen AI for no-code automation with extensive app integrations
- Web Scraper for a more professional visual web scraping
- Octoparse for powerful no-code scraping avoiding IP blocking and bot detection
- Diffbot for advanced AI-powered data extraction API and knowledge graphs
Try Using AI for Web Scraping
Try it! You can click, explore, and run the workflow as you watch.
How Does Web Scraping Work?
Web scraping is all about grabbing data from websites. You give a tool a set of instructions, and it goes off to pull text, images, or whatever you need into a table from a webpage. This can come in handy for everything from tracking prices on e-commerce sites to gathering research data or even just building up a good Excel spreadsheet or Google Sheets.
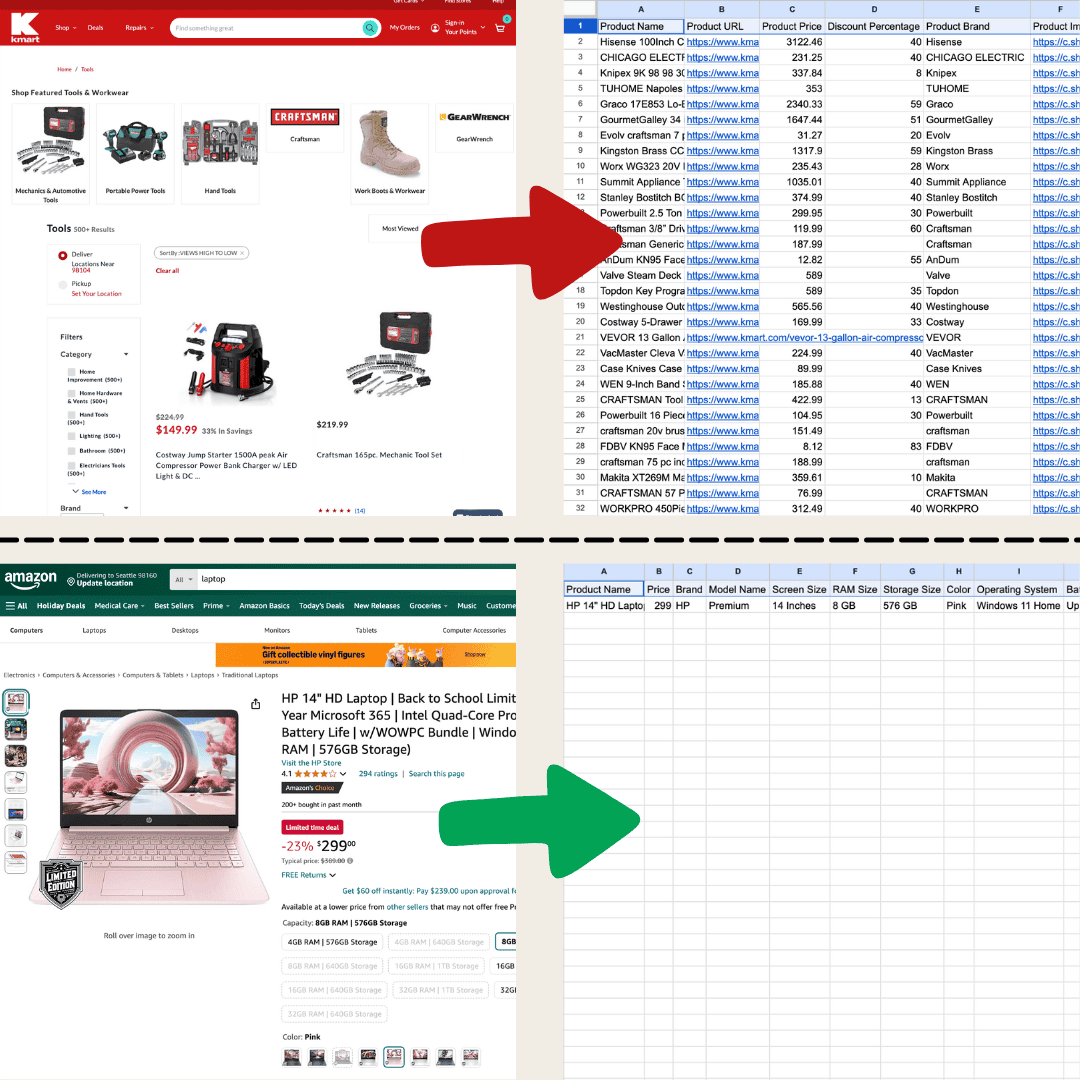 I made this with Thunderbit using the AI Web Scraper.
I made this with Thunderbit using the AI Web Scraper.
There are a few ways to do it. At the simplest level, you could just copy and paste stuff yourself, but that’s a lot of work if there’s a ton of data. So, most people use one of three methods: traditional web scrapers, AI web scrapers, or custom code.
Traditional web scrapers work by setting specific rules about what data to grab based on the page’s structure. For example, you can set it to grab product names or prices from certain HTML tags. They work best on websites that don’t change too often, since any layout tweaks mean you’ll have to go in and adjust your scraper.
 Using a traditional scraper will take a long time to learn, and it will probably take you dozens of clicks to complete the setup.
Using a traditional scraper will take a long time to learn, and it will probably take you dozens of clicks to complete the setup.
Scrape data from any website using AI Get Started Free
AI web scrapers basically mean: ChatGPT reads the whole website and then extracts content based on your need. It can handle data extraction, translation & summarization at the same time. They use natural language processing to analyze and understand the website’s layout, which means they can handle site changes more smoothly. Say the website rearranges its sections a little—an AI web scraper might be able to adjust without you needing to rewrite anything. So they’re great for high-maintenance sites or ones with more complex structures.
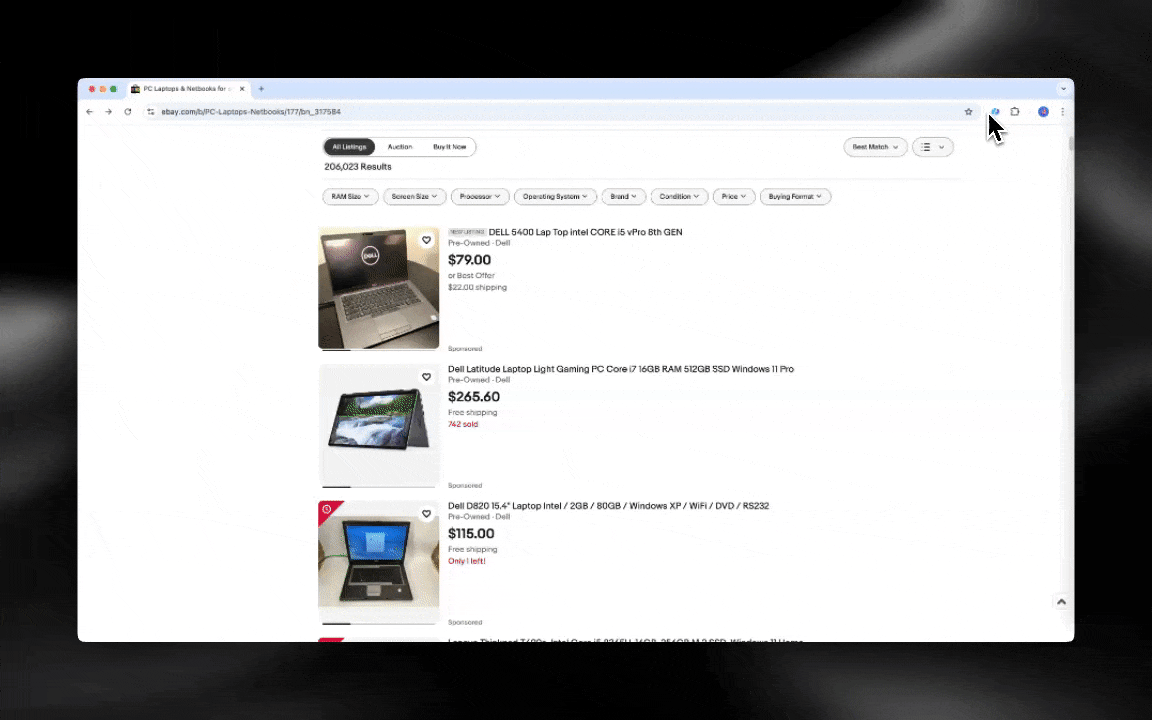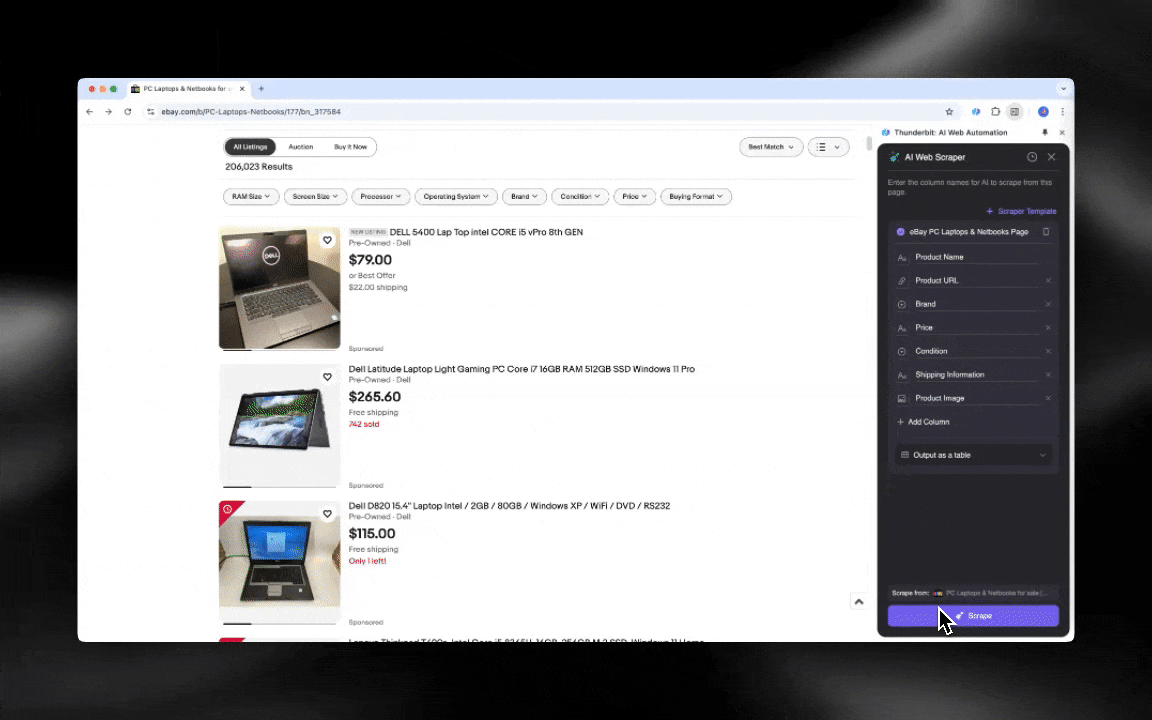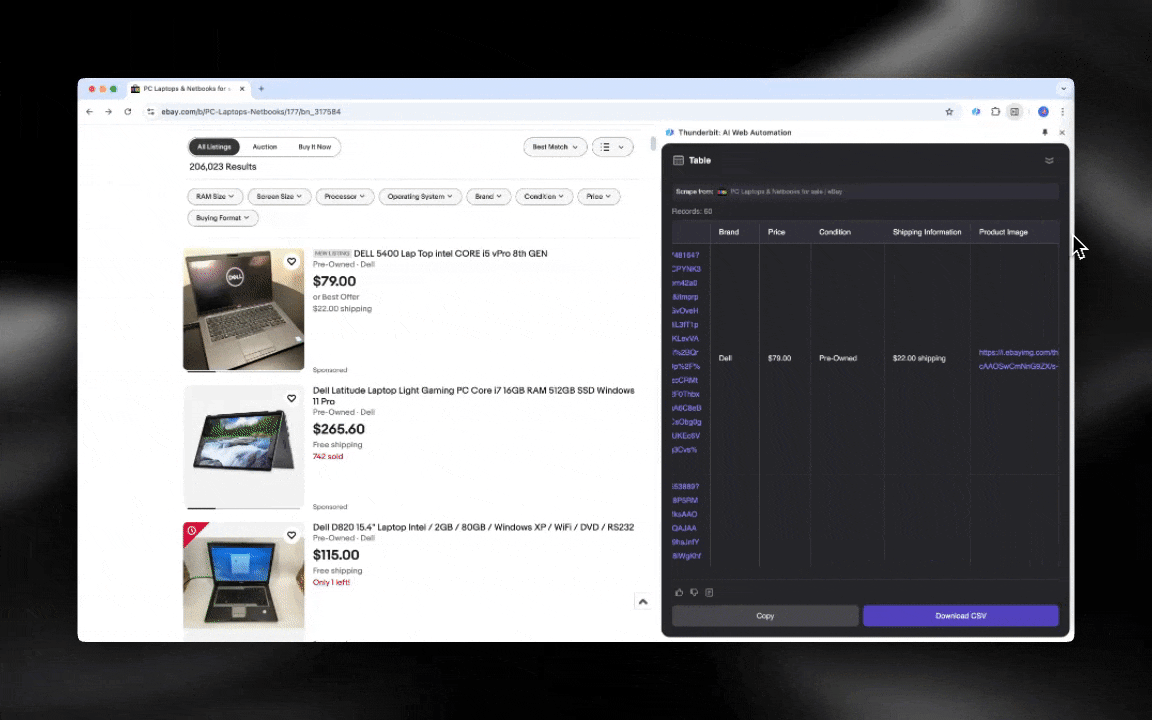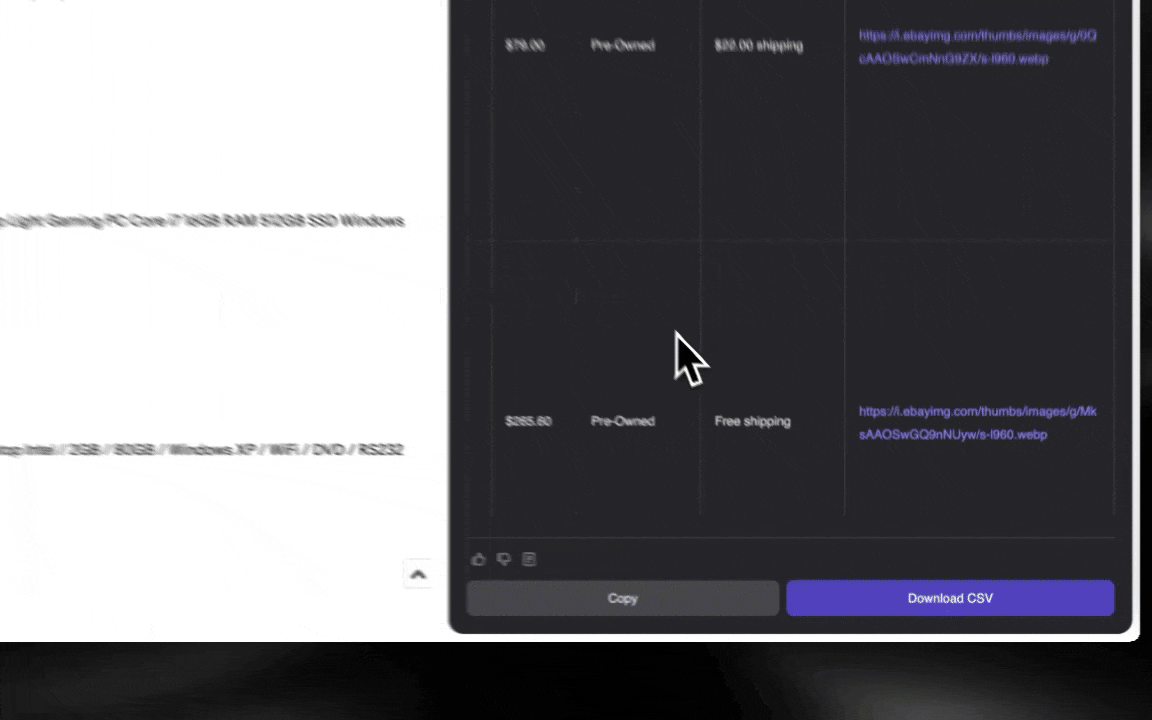 The AI web scraper is easy to get started and gives you detailed data in just a few clicks!
The AI web scraper is easy to get started and gives you detailed data in just a few clicks!
Which one should you pick? It depends. If you’re comfortable tinkering with code or need to collect large amounts of data on a popular website, traditional scrapers can be very efficient. But if you’re new to web scraping or want something that can roll with website updates, AI web scrapers are usually the better bet. Check the table below for more detailed scenarios!
| Scenario | Best Choice |
|---|---|
| Light-weight scraping on pages such as directories, shopping websites, or any website with a list | AI Web Scraper |
| The page contains less than 200 rows of data, building a scraper using a traditional web scraper takes too long | AI Web Scraper |
| The data you need to scrape for needs a certain data format to upload to somewhere else. For example: scraping contact info to upload to HubSpot. | AI Web Scraper |
| Widely used websites at scale, such as tens of thousands of Amazon product pages or Zillow property listings. | Traditional Web Scraper |
The Best Web Scraping Tools & Software at a Glance
| Tool | Pricing | Key Features | Pros | Cons |
|---|---|---|---|---|
| Thunderbit | From $9/month, free tier available | AI web scraper, auto-detects and formats data, supports multiple formats, one-click export, user-friendly interface. | Code-free, AI support, integrations with apps like Google Sheets | Large-scale scraping can be slow, advanced features may cost more |
| Browse AI | From $48.75/month, free tier available | No-code interface, real-time monitoring, bulk data extraction, workflow integration. | User-friendly, integrates with Google Sheets & Zapier | Complex pages need extra setup, bulk scraping can cause timeouts |
| Bardeen AI | From $60/month, free tier available | No-code automation, integrates with 130+ apps, MagicBox turns tasks into workflows. | Extensive integrations, scalable for businesses | Steep learning curve for new users, time-consuming setup |
| Web Scraper | Free for local use, $50/month for cloud | Visual task creation, supports dynamic sites (AJAX/JavaScript), cloud scraping. | Works well for dynamic sites | Requires technical knowledge for best setup |
| Octoparse | Starts at $119/month, free tier available | No-code scraping, auto-detection of page elements, cloud scraping with scheduled tasks, template library for common websites. | Powerful features for dynamic sites, handles restrictions | Complex sites require learning |
| Diffbot | From $299/month | Data extraction API, no-rule API, NLP for unstructured text, extensive knowledge graph. | Strong AI extraction, extensive API integration, large-scale scraping | Learning curve for non-technical users, setup time |
The Best Web Scraper in the AI Era
Thunderbit
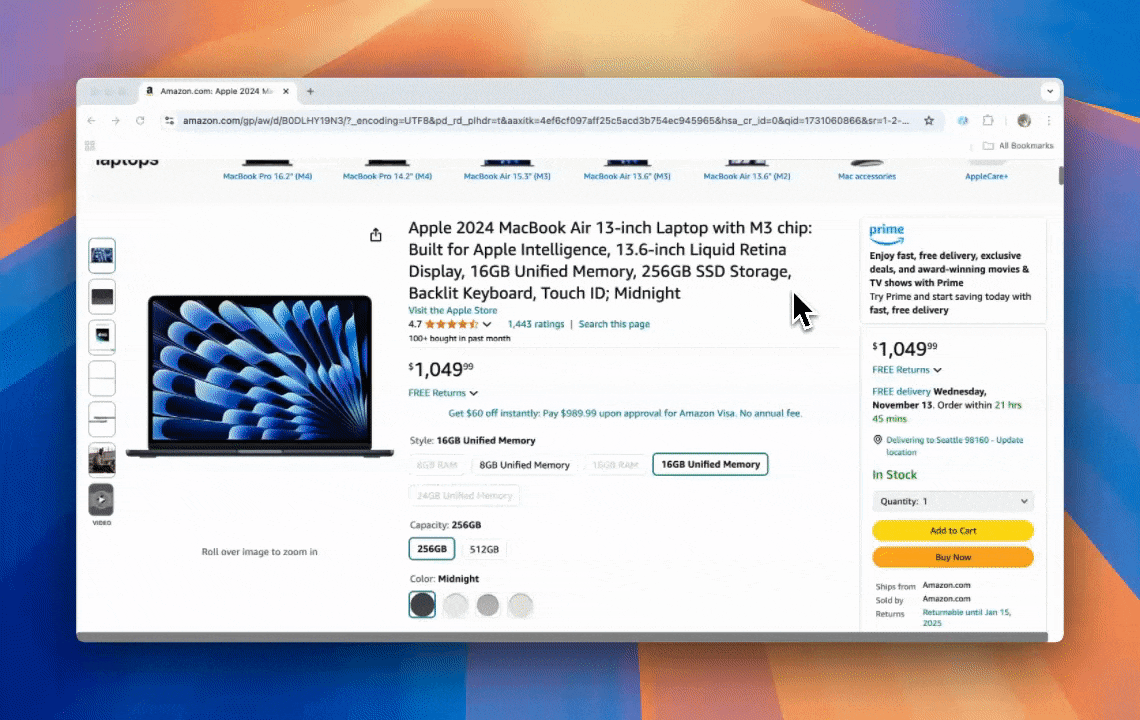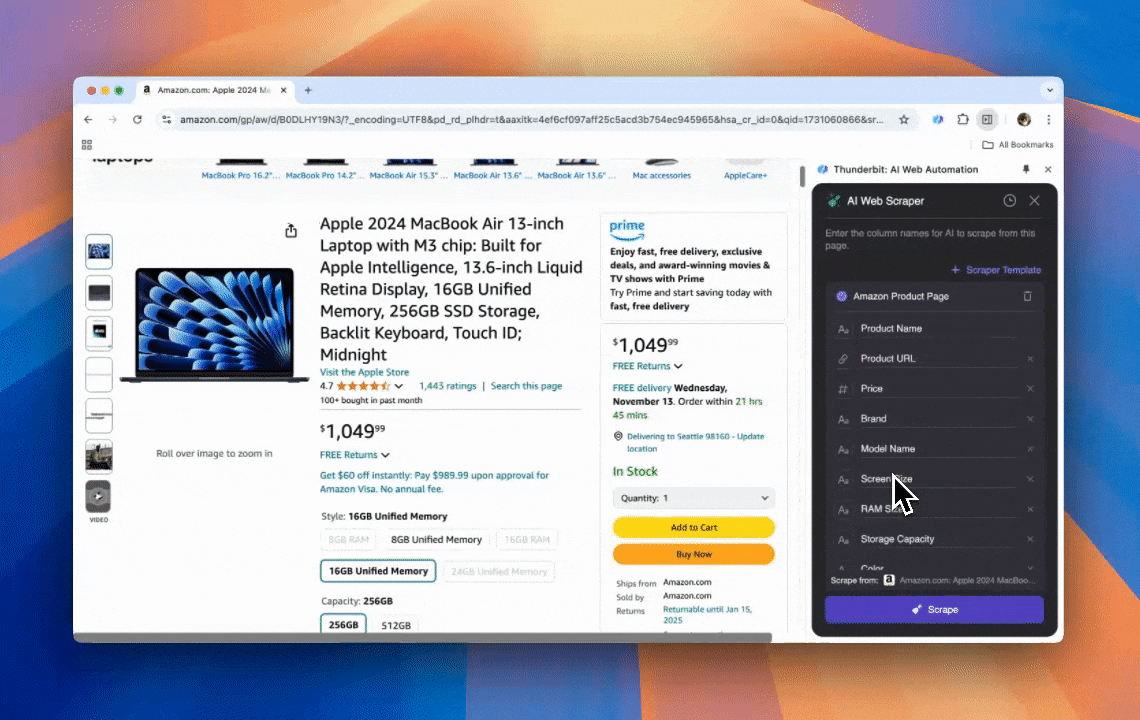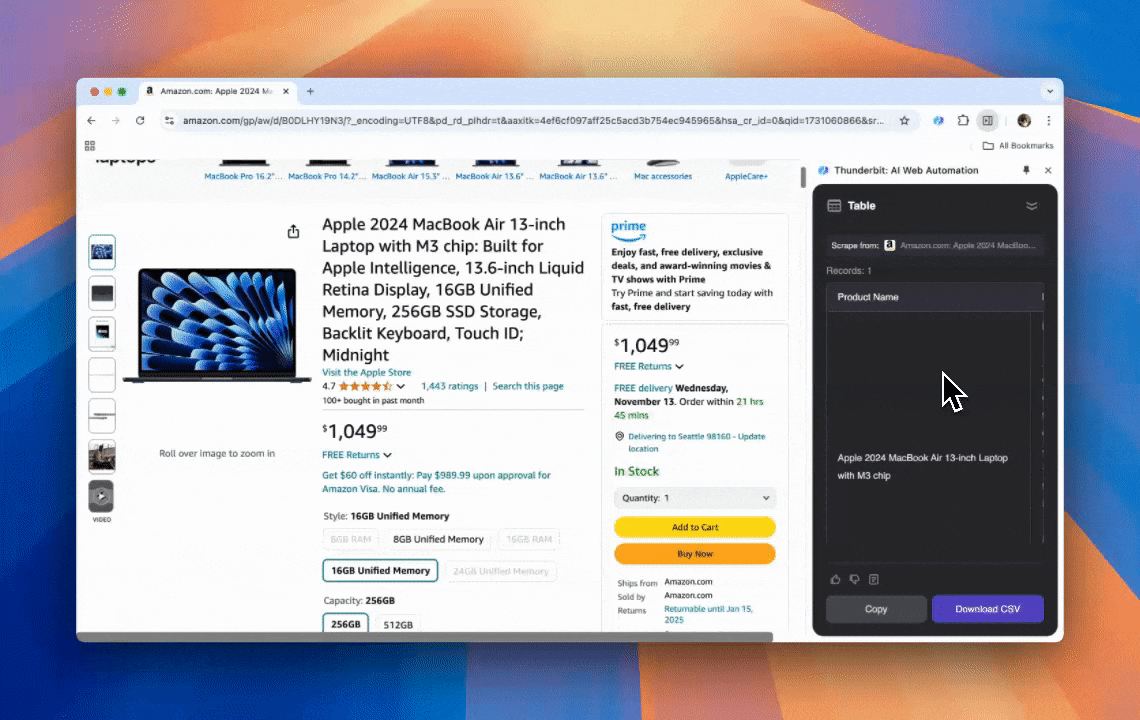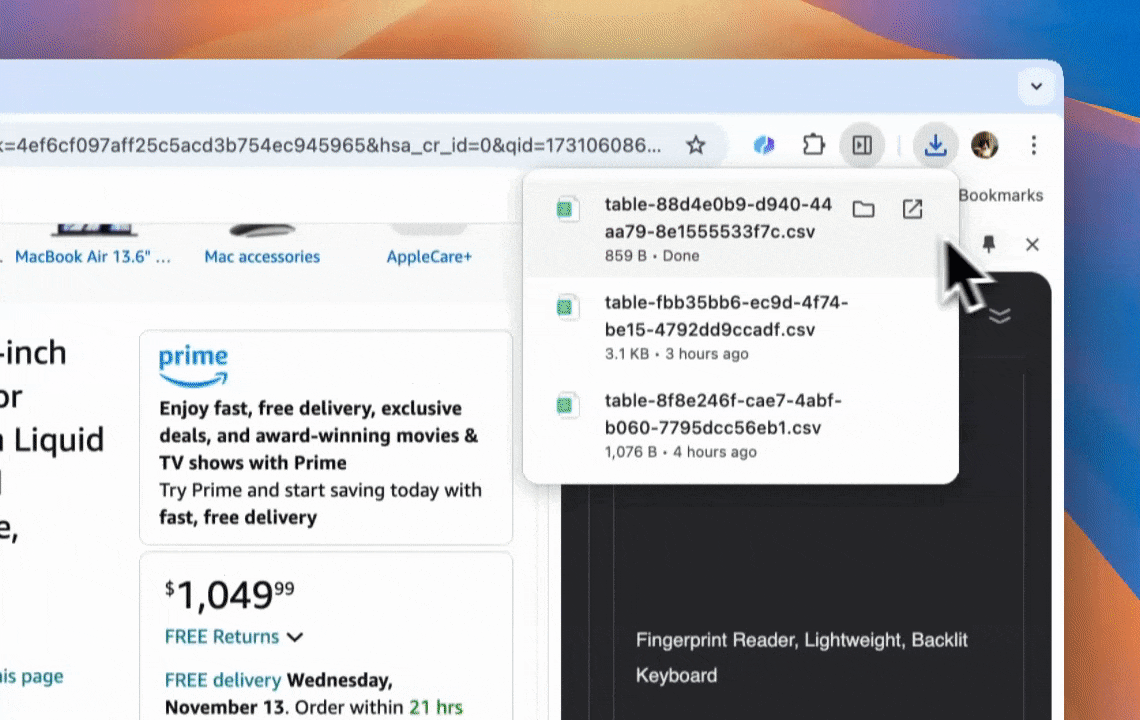
Thunderbit is a powerful, user-friendly AI web automation tool that enables users without coding skills to extract and organize data easily. With its Chrome extension, Thunderbit’s AI Web Scraper simplifies data scraping—users can quickly pull web data without manually interacting with web elements or setting up individual scrapers for different page layouts.
Key Features
- AI-Powered Flexibility: Thunderbit’s AI Web Scraper automatically detects and formats web data, eliminating the need for CSS selectors.
- The Easiest Scraping Experience: All you need to do is to click “AI suggest column” and then click “Scrape” on the page you need to extract from. That’s it.
- Support for Various Data Formats: Thunderbit can scrape URLs, images, and display captured data in multiple formats.
- Automated Data Processing: Thunderbit’s AI can reformat data on the go, including summarizing, categorizing, and translating it to the required format.
- Easy Data Export: Export data to Google Sheets, Airtable, or Notion with one click, simplifying data management.
- User-Friendly Interface: An intuitive interface makes it accessible for users of all skill levels.
Pricing
Thunderbit offers tiered plans, starting from $9 a month for 5,000 credits. It goes all the way up to $199 for 240,000 credits. Also, for the annual plan, you will get all credits up front.
Pros:
- Strong AI support simplifies data extraction and processing.
- Code-free, accessible to users of all skill levels.
- Perfect for lightweight scraping such as directories, shopping websites, etc.
- High integration capabilities for direct exports to popular apps.
Cons:
- Large-scale data scraping may take some time to ensure accuracy.
- Certain advanced features may require a paid subscription.
Want more information? Start by installing Thunderbit, or discover how to easily scrape websites with Thunderbit.
Best Web Scraper for Data Monitoring and Bulk Extraction
Browse AI
Browse AI is a robust no-code data scraping tool designed to help users extract and monitor data without writing any code. Browse AI has some AI features, but it’s not quite up to the level of full-on AI scraping. That said, it does make things easier for users to get started.
Key Features
- No-code Interface: Enables users to create custom workflows with simple clicks.
- Real-Time Monitoring: Uses bots to track webpage changes and deliver updated information.
- Bulk Data Extraction: Capable of handling up to 50,000 data entries in one go.
- Workflow Integration: Links multiple bots for more complex data processing.
Pricing
Starts at $48.75 per month, including 2,000 credits. A free tier is available, providing 50 credits per month to try out its basic features.
Pros:
- Offers integrations with Google Sheets and Zapier.
- Pre-built bots simplify common data extraction tasks.
Cons:
- May require extra configuration for complex pages.
- Bulk scraping speed can vary, sometimes resulting in timeouts.
Best Web Scraper for Workflow Integration
Bardeen AI
Bardeen AI is a no-code automation tool designed to streamline workflows by connecting various apps. While it uses AI to create custom automation, it lacks the adaptability of a full AI Scraping tool.
Key Features
- No-code Automation: Allows users to set up workflows with clicks.
- MagicBox: Describes tasks in plain language, which Bardeen AI converts into workflows.
- Broad Integration Options: Integrates with over 130 apps, including Google Sheets, Slack, and LinkedIn.
Pricing
Starts at $60 per month, with 1,500 credits (about 1,500 rows of data). A free tier offers 100 credits monthly to try basic features.
Pros:
- Extensive integration options support diverse business needs.
- Flexible and scalable for businesses of all sizes.
Cons:
- New users may need time to learn the full platform.
- Initial setup may be time-intensive.
Best Visual Web Scraper for People with Experience
Web Scraper
Yes, you heard it right: the tool is called "Web Scraper". Web Scraper is a popular browser extension for Chrome and Firefox that enables users to extract data without coding, offering a visual way to create scraping tasks. However, you may need to spend a few days watching and learning from the tutorials above to fully master this tool. If you want to make scraping easy on your brain, choose AI Web Scraper.
Key Features
- Visual Creation: Let users set up scraping tasks by clicking web elements.
- Dynamic Website Support: Can handle AJAX requests and JavaScript for dynamic sites.
- Cloud Scraping: Schedule tasks through Web Scraper Cloud for periodic scraping.
Pricing
Free for local use; paid plans start at $50/month for cloud features.
Pros:
- Works well for dynamic sites.
- Free for local use.
Cons:
- Requires technical knowledge for optimal setup.
- Complex testing is required for changes.
Best Web Scraper Avoiding IP Blocking and Bot Detection
Octoparse
Octoparse is a versatile software for more technical users to collect and monitor specific web data without code, ideal for large-scale data needs. Octoparse doesn’t rely on the user’s browser to operate; instead, it uses cloud servers for data scraping. So, it can offer various methods to bypass IP blocking and certain website bot detection.
Key Features
- No-code Operation: Users can create scraping tasks without writing code, making it accessible to users with varying technical skills.
- Smart Auto-Detection: It automatically detects page data, quickly identifying elements available for scraping, simplifying setup.
- Cloud Scraping: Supports 24/7 cloud data scraping with scheduled scraping tasks for flexible data retrieval.
- Extensive Template Library: Offers hundreds of preset templates, allowing users to quickly access data from popular websites without complex setup.
Pricing
Octoparse’s pricing plan starts at $119 per month, including 100 tasks. A free tier with 10 tasks per month is also available to test its basic functionality.
Pros:
- Powerful features support dynamic site scraping with high adaptability.
- Provides solutions for handling scraping restrictions and dynamic content issues.
Cons:
- Complex website structures may require more time to set up.
- New users may need time to learn usage techniques.
Best Web Scraper for Advanced AI-Powered Data Extraction API
Diffbot
Diffbot is an advanced web data extraction tool that uses AI to transform unstructured web content into structured data. With powerful APIs and a knowledge graph, Diffbot helps users extract, analyze, and manage information from the web, suitable for various industries and applications.
Key Features
- Data Extraction API: Diffbot offers a no-rule data extraction API, allowing users to simply provide a URL for automatic data extraction, eliminating the need to set custom rules for each website.
- Natural Language Processing API: Extracts structured entities, relationships, and sentiment from unstructured text, aiding users in building their own knowledge graphs.
- Knowledge Graph: Diffbot has one of the largest knowledge graphs, connecting extensive entity data, including details about individuals and organizations.
Pricing
Diffbot’s pricing plan starts at $299 per month, including 250,000 credits (equivalent to approximately 250,000 API-based webpage extractions).
Pros:
- Strong no-rule data extraction capabilities with high adaptability.
- Extensive API integration options for easy integration with existing systems.
- Supports large-scale data scraping, suitable for enterprise-level applications.
Cons:
- Initial setup may require some learning time for non-technical users.
- Users must write a program to call the API to use it.
What Can You Use Scrapers For?
If you’re new to web scraping, here are a few popular use cases to help you get started. Many people use scrapers to retrieve Amazon product listings, pull real estate data from Zillow, or gather business details from Google Maps. But that’s just the beginning—you can use Thunderbit AI Web Scraper to collect data from almost any website, streamlining tasks and saving time in your daily workflow. Whether it’s for research, tracking prices, or building databases, web scraping opens up countless ways to put the internet’s data to work for you.
FAQs
-
Is web scraping legal?
Web scraping is typically legal but must follow website terms of service and the nature of the data being accessed. Always review relevant policies and comply with legal guidelines.
-
Do I need programming skills to use web scraping tools?
Most of the tools featured here do not require programming skills, but tools like Octoparse and Web Scraper may benefit from users having basic knowledge of web structures and a programming mindset for optimal use.
-
Are there free web scraping tools?
Yes, free tools like BeautifulSoup, Scrapy, and Web Scraper are available, and some tools also offer limited-feature free plans.
-
What are common challenges in web scraping?
Common challenges include handling dynamic content, CAPTCHAs, IP blocking, and complex HTML structures. Advanced tools and techniques can effectively address these issues.
Learn More:
Use AI to work with zero effort. Get Started Free




