

The web is growing faster than my coffee addiction—and trust me, that’s saying something. In 2026, web data extraction isn’t just a niche skill for data geeks; it’s the backbone of business intelligence, AI training, and automation. Whether you’re tracking market trends, fueling your next-gen LLM, or just trying to keep up with your competitors’ pricing, the need for real-time, structured web data has never been higher. And at the heart of this data gold rush? Python. With its massive ecosystem and approachable syntax, Python remains the go-to language for web scraping, powering everything from quick one-off scripts to industrial-scale crawlers.
But here’s the kicker: picking the right Python web scraping packages can make or break your project. I’ve seen teams waste days fighting anti-bot walls with the wrong tool, or burn hours parsing messy HTML when a smarter library would’ve done the trick in minutes. So, as someone who’s spent years in SaaS, automation, and AI (and built Thunderbit to make scraping easier for everyone), I’ve rounded up the 12 best Python web scraping packages for 2026—each with its own strengths, quirks, and ideal use cases. Let’s dive in and find the perfect fit for your next data adventure.
Why the Right Python Web Scraping Packages Matter
Scrape data from any website using AI Get Started Free
Let’s get real: not all web scraping projects are created equal. Sometimes you just need to grab a few product prices from a static page. Other times, you’re wrangling a JavaScript-heavy site that’s more stubborn than a cat at bath time. The right package can save you hours (or days), reduce errors, and help you dodge common pitfalls like anti-bot blocks or broken HTML.
Python’s popularity in web scraping isn’t just hype. Libraries like requests and urllib3 see over 1 billion downloads per month, and nearly every major scraping tool is Python-first. But with great power comes great responsibility: choose the wrong tool, and you might find yourself stuck on a project that’s slower than dial-up internet. Choose wisely, and you’ll be swimming in clean, structured data before your coffee gets cold.
How We Chose the Best Python Web Scraping Packages
I didn’t just throw darts at a PyPI chart. Here’s how I evaluated each package:
- Performance & Concurrency: Can it fetch hundreds (or thousands) of pages quickly?
- Ease of Use: Is it beginner-friendly, or does it require a PhD in computer science?
- HTML Parsing Power: Does it handle broken markup, support XPath/CSS selectors, and make data extraction painless?
- Dynamic Content Support: Can it deal with JavaScript-heavy sites, or is it strictly for static pages?
- Community & Documentation: Is there a thriving user base and solid docs, or will you be stuck in Stack Overflow purgatory?
- Best Use Case: Is it for quick scripts, large-scale crawlers, or something in between?
I also factored in real-world developer feedback, recent benchmarks, and my own (sometimes painful) experiences in the field. Now, let’s meet the contenders.
1. Thunderbit
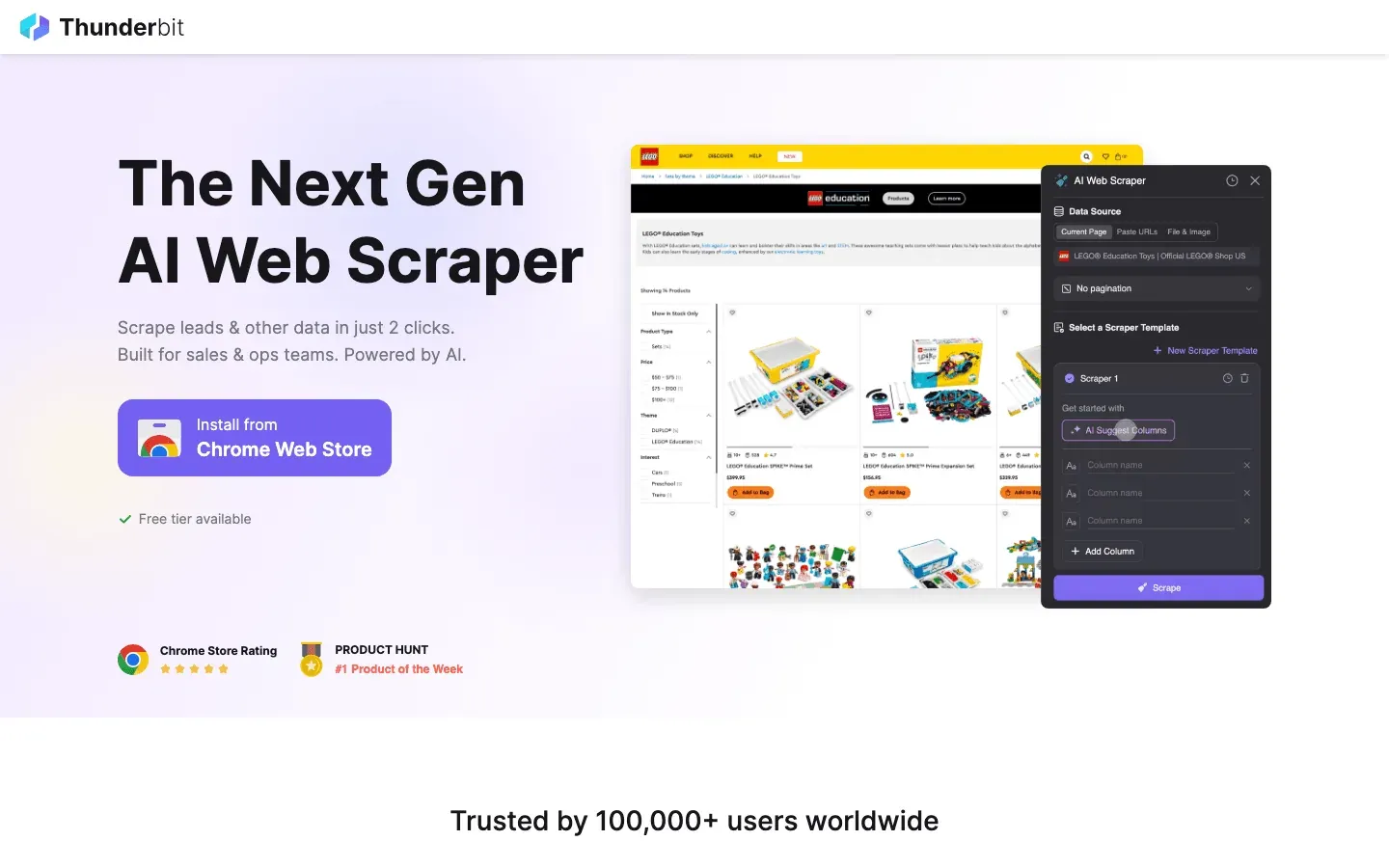 Thunderbit isn’t your typical Python library—it’s an AI-powered Chrome extension that’s changing the game for web scraping, especially for Python developers who want speed, accuracy, and a touch of AI magic. What makes Thunderbit stand out? It lets you use natural language instructions to tell the AI what data you want, and then it handles everything: field suggestions, subpage navigation, pagination, and even exporting to Excel, Google Sheets, Notion, or Airtable.
Thunderbit isn’t your typical Python library—it’s an AI-powered Chrome extension that’s changing the game for web scraping, especially for Python developers who want speed, accuracy, and a touch of AI magic. What makes Thunderbit stand out? It lets you use natural language instructions to tell the AI what data you want, and then it handles everything: field suggestions, subpage navigation, pagination, and even exporting to Excel, Google Sheets, Notion, or Airtable.
Thunderbit is a lifesaver for scraping complex, unstructured data—think messy directories, product listings, or sites where the HTML is more “abstract art” than “structured document.” Its AI Suggest Fields feature reads the page and proposes the best columns, while Subpage Scraping lets you enrich your dataset by automatically visiting linked detail pages. And if you’re tired of anti-bot headaches, Thunderbit’s browser-based and cloud scraping options have you covered.
Python developers love Thunderbit for rapid prototyping, lead generation, and market research. You can use its output directly in your Python data pipeline, or even automate scraping workflows with its API. It’s not a traditional code library, but it’s quickly becoming a favorite for anyone who wants to spend less time coding and more time analyzing data.
Key Features:
- AI-powered field suggestion and data extraction
- Handles subpages, pagination, and even PDFs/images
- Exports to CSV, Excel, Google Sheets, Notion, Airtable
- No coding required—perfect for both non-technical users and Python pros who want to move fast
- Free tier available; paid plans scale with your needs
Best For: Lead generation, market research, rapid prototyping, and scraping complex or messy web data.
Try Thunderbit AI Web Scraper for Free
2. Beautiful Soup
 Beautiful Soup is the OG of HTML parsing in Python. If you’re just starting out, or need to extract data from static web pages, this is your best friend. Beautiful Soup excels at navigating and parsing poorly structured HTML (“tag soup”), making it a lifesaver for scraping sites that don’t play by the rules.
Beautiful Soup is the OG of HTML parsing in Python. If you’re just starting out, or need to extract data from static web pages, this is your best friend. Beautiful Soup excels at navigating and parsing poorly structured HTML (“tag soup”), making it a lifesaver for scraping sites that don’t play by the rules.
The API is beginner-friendly—think .find(), .select(), and .text—and it pairs perfectly with requests for fetching web pages. Under the hood, you can choose different parsers (like lxml for speed or html5lib for maximum compatibility). The documentation is top-notch, and the community is massive.
Key Features:
- Intuitive, Pythonic API for navigating HTML/XML
- Handles broken or inconsistent markup gracefully
- Works with multiple parsers for speed or compatibility
- Huge community and tons of tutorials
Best For: Quick scripts, static page scraping, and beginners who want a gentle learning curve.
Learn more about Beautiful Soup
3. Scrapy
 Scrapy is the heavyweight champion for large-scale, automated web crawling. If you need to scrape hundreds or thousands of pages, manage pipelines, or schedule recurring jobs, Scrapy is the framework most teams land on. It still runs on a Twisted reactor under the hood, but as of the 2.14 release a large chunk of its async internals were rewritten as native
Scrapy is the heavyweight champion for large-scale, automated web crawling. If you need to scrape hundreds or thousands of pages, manage pipelines, or schedule recurring jobs, Scrapy is the framework most teams land on. It still runs on a Twisted reactor under the hood, but as of the 2.14 release a large chunk of its async internals were rewritten as native asyncio coroutines, and there are now AsyncCrawlerProcess / AsyncCrawlerRunner entry points that play nicely with the rest of the modern Python async ecosystem. It's fast, supports concurrent crawling, item pipelines for data cleaning, and exports to JSON, CSV, or databases.
Scrapy is extendable, with plugins for proxies, caching, and even limited JavaScript rendering (via Splash or Selenium integration). The learning curve is steeper than Beautiful Soup, but if you’re serious about web data at scale, Scrapy is what you grow into.
Key Features:
- Asynchronous crawling via Twisted reactor + native
asynciocoroutines (Scrapy 2.14+, Python 3.10+) - Built-in pipelines for data cleaning and storage
- Export to multiple formats (JSON, CSV, DB)
- Large, active community and plugin ecosystem
Best For: Large-scale, recurring scraping projects, data pipelines, and anyone who needs speed and reliability.
4. Selenium
 Selenium is the go-to tool for scraping JavaScript-heavy or interactive sites. It automates real browsers (Chrome, Firefox, etc.), letting you simulate user actions like clicks, scrolling, and form submissions. If the data you need only appears after JavaScript runs, Selenium can get it—no matter how stubborn the site.
Selenium is the go-to tool for scraping JavaScript-heavy or interactive sites. It automates real browsers (Chrome, Firefox, etc.), letting you simulate user actions like clicks, scrolling, and form submissions. If the data you need only appears after JavaScript runs, Selenium can get it—no matter how stubborn the site.
The trade-off? Selenium is slow and resource-intensive. You’re running a full browser for each scrape, so don’t expect to process thousands of pages per minute. But for those “no other tool can do it” scenarios, Selenium is a lifesaver.
Key Features:
- Full browser automation (supports Chrome, Firefox, Edge, etc.)
- Handles JavaScript-rendered content and interactive elements
- Supports headless mode for faster, UI-less scraping
- Large community and extensive documentation
Best For: Scraping dynamic, JavaScript-heavy sites, automating login flows, and handling CAPTCHAs or complex user interactions.
Read more about Selenium’s strengths and weaknesses
5. PyQuery
 PyQuery brings jQuery-style syntax to Python, making HTML parsing feel familiar to anyone who’s worked with jQuery in JavaScript. It wraps the fast
PyQuery brings jQuery-style syntax to Python, making HTML parsing feel familiar to anyone who’s worked with jQuery in JavaScript. It wraps the fast lxml parser and lets you use CSS selectors like $('div.classname') to find elements.
PyQuery is great for rapid prototyping and for developers who want concise, readable code. It’s faster than Beautiful Soup for complex queries and integrates easily with async tools or Selenium for more advanced workflows.
Key Features:
- jQuery-like selectors and syntax in Python
- Fast parsing with lxml backend
- Great for developers transitioning from JavaScript
- Supports chaining and concise queries
Best For: Prototyping, jQuery fans, and anyone who wants to write less code for HTML parsing.
PyQuery tutorial and comparison
6. LXML
 LXML is the speed demon of HTML and XML parsing in Python. Built on top of the C libraries
LXML is the speed demon of HTML and XML parsing in Python. Built on top of the C libraries libxml2 and libxslt, it’s renowned for its performance and powerful support for XPath and CSS selectors. If you’re dealing with large documents or need to run complex queries, lxml is your best bet.
It can be used directly or as the backend for Beautiful Soup or PyQuery. The API is a bit more advanced, but the speed and flexibility are worth it for big jobs.
Key Features:
- Fastest parsing available in Python
- Full support for XPath and CSS selectors
- Handles large and complex documents efficiently
- Can be used standalone or as a parser for other libraries
Best For: High-performance parsing, large-scale scraping, and projects requiring advanced querying.
Why lxml stands out for parsing
7. Requests
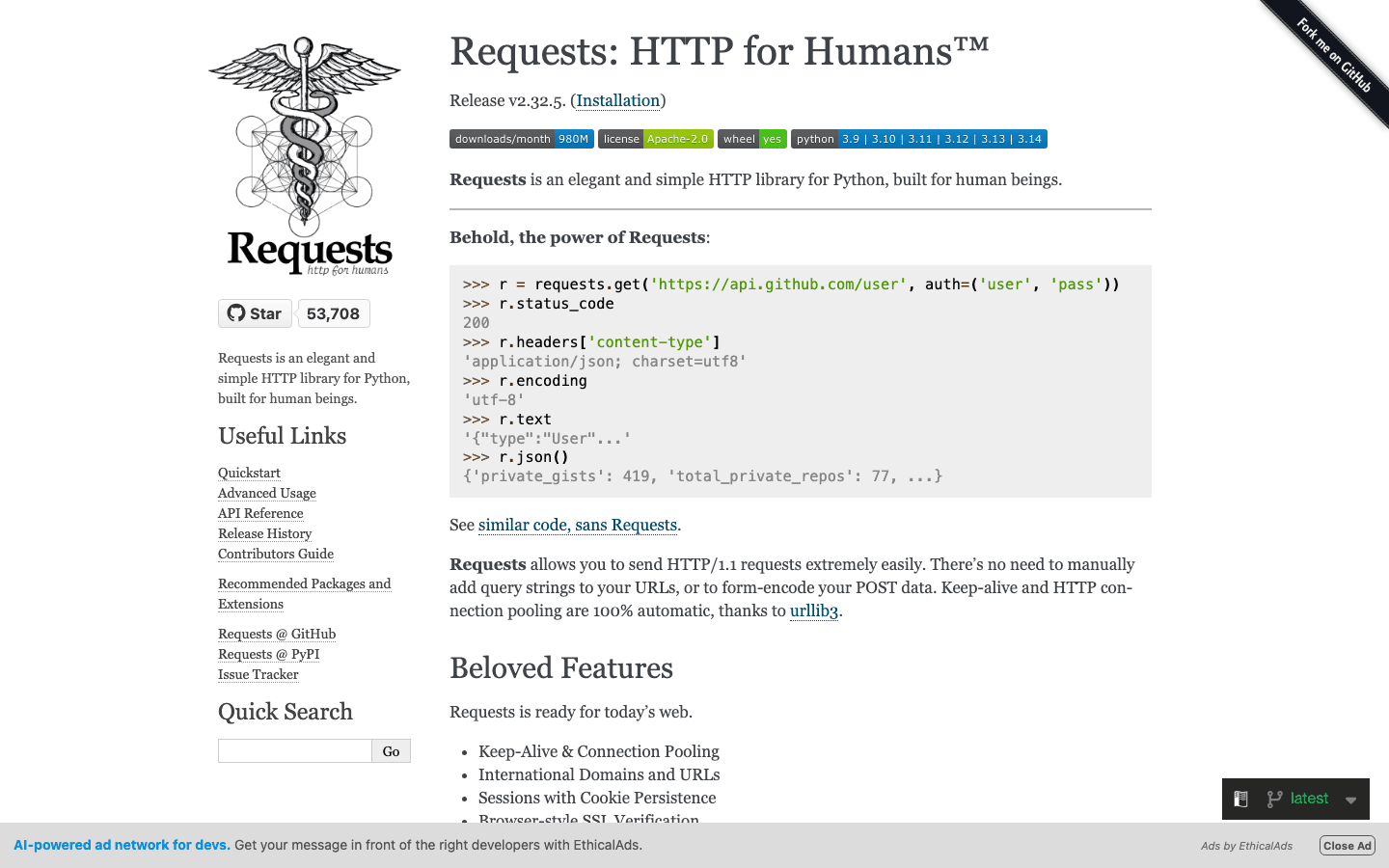 Requests is the de facto standard for making HTTP requests in Python. Its clean, intuitive API makes fetching web pages as easy as
Requests is the de facto standard for making HTTP requests in Python. Its clean, intuitive API makes fetching web pages as easy as requests.get(url). It handles cookies, sessions, and even JSON decoding out of the box.
While Requests is synchronous (each request waits for completion), it’s perfect for quick scripts and small-scale scraping. Pair it with Beautiful Soup or lxml for a classic scraping workflow.
Key Features:
- Simple, Pythonic API for HTTP requests
- Handles cookies, sessions, and redirects
- Integrates seamlessly with parsing libraries
- Massive community and documentation
Best For: Simple scripts, static page scraping, and beginners who want to get started fast.
See why Requests is so popular
8. MechanicalSoup
 MechanicalSoup is a lightweight library that automates simple browser interactions—like filling out forms or navigating multi-step login flows—without launching a full browser. It wraps
MechanicalSoup is a lightweight library that automates simple browser interactions—like filling out forms or navigating multi-step login flows—without launching a full browser. It wraps requests and Beautiful Soup, making it much faster and lighter than Selenium for sites that don’t rely heavily on JavaScript.
If you need to log in, submit forms, or click through a few pages (and the site isn’t too dynamic), MechanicalSoup is a great middle ground.
Key Features:
- Automates form filling and navigation
- Built on top of Requests and Beautiful Soup
- Lightweight and fast (no browser overhead)
- Easy to use for moderate interactivity
Best For: Sites requiring login or form submission, simple automation tasks, and anyone who wants to avoid Selenium’s overhead.
9. Aiohttp
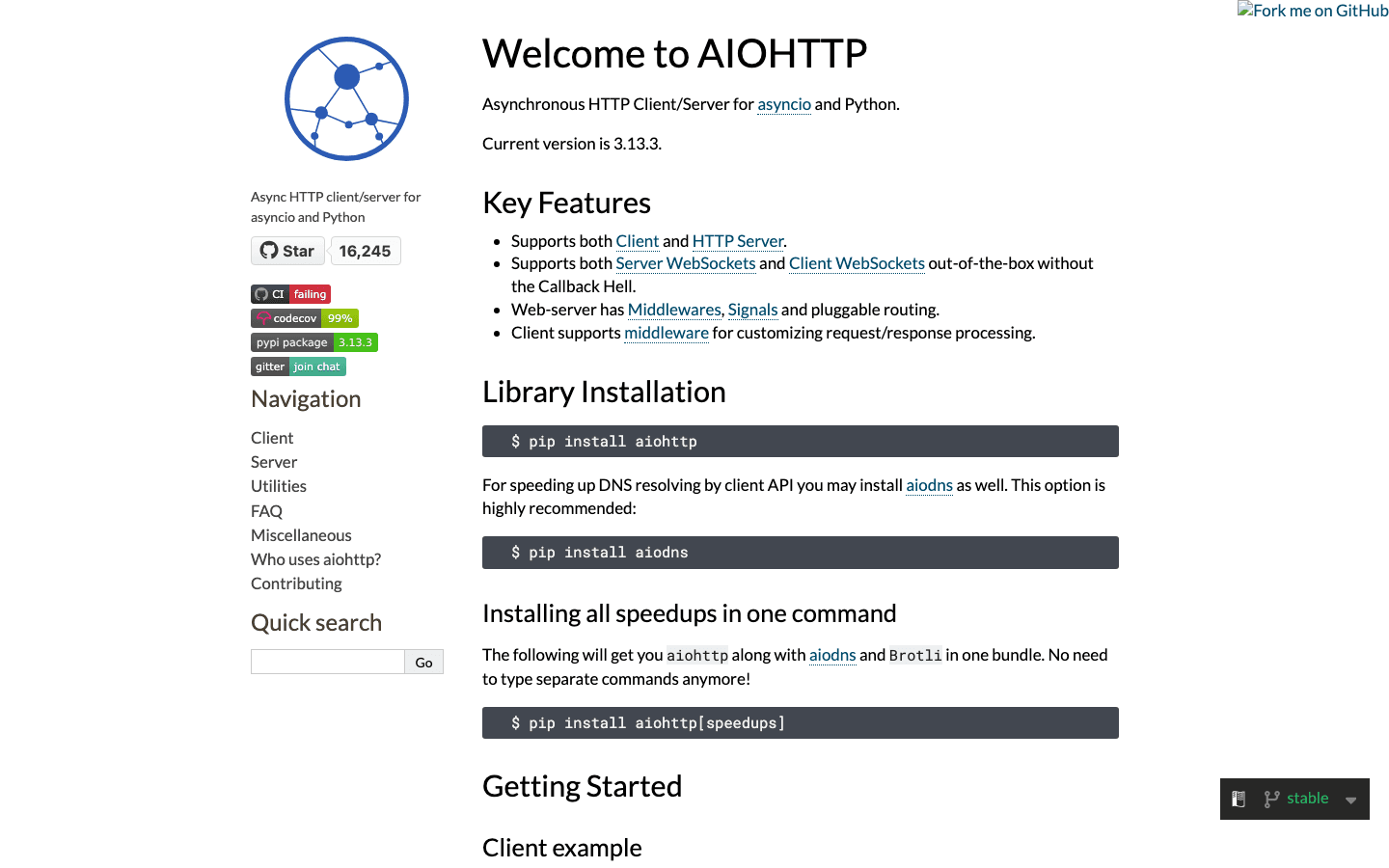 Aiohttp is the async powerhouse for high-speed, concurrent web requests. If you need to scrape hundreds of pages quickly, aiohttp lets you fire off requests in parallel, dramatically reducing total runtime. In one benchmark, a 50-page scrape took just 3 seconds with aiohttp, compared to 16 seconds using synchronous requests (see the performance difference).
Aiohttp is the async powerhouse for high-speed, concurrent web requests. If you need to scrape hundreds of pages quickly, aiohttp lets you fire off requests in parallel, dramatically reducing total runtime. In one benchmark, a 50-page scrape took just 3 seconds with aiohttp, compared to 16 seconds using synchronous requests (see the performance difference).
Aiohttp requires writing async def code and using await, but the speed gains are worth it for large-scale jobs.
Key Features:
- Asynchronous HTTP client/server framework
- Supports sessions, cookies, and HTTP/2
- Massive speedup for concurrent requests
- Integrates with async parsing libraries
Best For: High-speed, large-scale scraping, API harvesting, and anyone comfortable with async programming.
10. Twisted
 Twisted is the event-driven networking engine that powers Scrapy. While it’s not a scraping library per se, advanced users can use Twisted directly to build custom crawlers, handle non-HTTP protocols, or implement hyper-concurrent spiders.
Twisted is the event-driven networking engine that powers Scrapy. While it’s not a scraping library per se, advanced users can use Twisted directly to build custom crawlers, handle non-HTTP protocols, or implement hyper-concurrent spiders.
Twisted is powerful but comes with a steep learning curve. It’s best for highly custom scenarios or when building frameworks from scratch.
Key Features:
- Event-driven networking for HTTP, WebSockets, SSH, and more
- Supports SSL, concurrency, and custom protocols
- Underpins Scrapy’s async engine
- Highly flexible for advanced use cases
Best For: Custom protocols, building scraping frameworks, and advanced users who need maximum control.
11. Grab
 Grab is an all-in-one scraping toolkit that combines HTTP requests, parsing, automation, proxy rotation, and CAPTCHA handling. It’s similar in spirit to Scrapy but aims to be easier to learn and use, with built-in support for proxies, caching, and asynchronous spiders.
Grab is an all-in-one scraping toolkit that combines HTTP requests, parsing, automation, proxy rotation, and CAPTCHA handling. It’s similar in spirit to Scrapy but aims to be easier to learn and use, with built-in support for proxies, caching, and asynchronous spiders.
Grab’s standout feature is its Grab:Spider system, which can run thousands of requests in parallel using multicurl. If you need an all-in-one solution with less setup than Scrapy, Grab is worth a look.
Key Features:
- Built-in support for proxies, user-agent rotation, and caching
- Asynchronous spider system for high concurrency
- XPath parsing and modular architecture
- Used in production for large-scale scraping
Best For: All-in-one scraping projects, proxy-heavy tasks, and users who want power without Scrapy’s complexity.
12. Urllib3
 Urllib3 is the low-level HTTP engine that powers many Python clients, including Requests. It offers connection pooling, thread safety, retries, and fine-grained control over HTTP connections. While most developers use it indirectly, urllib3 is your go-to when you need maximum performance or are building higher-level libraries.
Urllib3 is the low-level HTTP engine that powers many Python clients, including Requests. It offers connection pooling, thread safety, retries, and fine-grained control over HTTP connections. While most developers use it indirectly, urllib3 is your go-to when you need maximum performance or are building higher-level libraries.
It’s not as beginner-friendly as Requests, but it’s battle-tested and highly reliable.
Key Features:
- Connection pooling and thread safety
- Fine control over HTTP connections
- Used as a foundation for many other libraries
- High performance for repeated requests
Best For: Custom HTTP clients, multi-threaded crawlers, and developers building on top of the Python HTTP stack.
See urllib3’s role in scraping
Comparison Table: Python Web Scraping Packages at a Glance
| Package | Ease of Use | Performance | Dynamic Content | Parsing Power | Community/Docs | Best For |
|---|---|---|---|---|---|---|
| Thunderbit | ★★★★☆ (GUI/AI) | Fast (cloud/local) | Yes (via AI) | Auto-fields, subpage | Growing (AI trend) | Lead-gen, market research, no-code users |
| Beautiful Soup | ★★★★★ (easy) | Medium | No | HTML/XML, forgiving | Huge | Static pages, beginners |
| Scrapy | ★★☆☆☆ (steep) | ★★★★★ (very high) | Plugins only | CSS/XPath, pipelines | Large, active | Large-scale, recurring scraping |
| Selenium | ★★☆☆☆ (medium) | ★☆☆☆☆ (slow) | Yes (full) | Full DOM, JS | Mature | JS-heavy, interactive sites |
| PyQuery | ★★★★☆ (jQuery) | Fast (lxml) | No* | jQuery selectors | Moderate | Prototyping, jQuery devs |
| LXML | ★★★☆☆ (advanced) | ★★★★★ (fastest) | No | XPath/CSS, XML | Moderate | Large docs, advanced queries |
| Requests | ★★★★★ (very easy) | ★★☆☆☆ (sync) | No | HTTP, JSON | Massive | Simple scripts, static pages |
| MechanicalSoup | ★★★★☆ (easy) | ★★☆☆☆ (sync) | No | Forms, navigation | Small | Login flows, form automation |
| Aiohttp | ★★☆☆☆ (async) | ★★★★★ (concurrent) | No | Async HTTP | Large (async) | High-speed, concurrent scraping |
| Twisted | ★☆☆☆☆ (complex) | ★★★★★ (custom) | No | Networking, protocols | Niche | Custom frameworks, advanced users |
| Grab | ★★★☆☆ (modular) | ★★★★☆ (async) | No | Proxies, XPath | Small | All-in-one, proxy/captcha heavy |
| Urllib3 | ★★★★☆ (low-level) | ★★★★☆ (pooled) | No | HTTP, pooling | Massive | Custom clients, multi-threaded crawlers |
*PyQuery can be combined with Selenium for dynamic sites.
How to Choose the Right Python Web Scraping Package for Your Needs
What Is Data Scraping and How to Do It in 2026 Get Started Free
So, which package should you pick? Here’s my cheat sheet:
- Static pages, small jobs, or you’re new to scraping: Start with Requests + Beautiful Soup.
- Large-scale, recurring, or production scraping: Scrapy or Grab (for all-in-one needs).
- JavaScript-heavy or interactive sites: Selenium (or Thunderbit if you want AI-powered, no-code scraping).
- High-speed, concurrent scraping: Aiohttp (if you’re comfortable with async).
- Form automation or login flows: MechanicalSoup (for simple sites), Selenium (for complex JS).
- Advanced parsing or massive documents: LXML or PyQuery.
- Custom networking or protocol work: Twisted.
- Rapid prototyping, lead-gen, or messy/unstructured data: Thunderbit.
And don’t be afraid to mix and match—many workflows combine these tools for maximum efficiency. For example, you might use Selenium to render a page, then pass the HTML to Beautiful Soup or PyQuery for parsing.
Conclusion: Supercharge Your Web Scraping with the Right Python Tools
Web scraping in 2026 is more powerful—and more necessary—than ever. With the right Python web scraping packages, you can turn the chaos of the web into clean, actionable data for your business, research, or next big idea. Whether you’re a seasoned developer or just dipping your toes into the data pool, there’s a tool on this list that fits your needs.
If you want to see what AI-powered, no-code scraping looks like, give Thunderbit a try. And if you’re hungry for more tips, deep dives, and tutorials, check out the Thunderbit Blog for the latest in web scraping, automation, and data-driven workflows.
Happy scraping—and may your selectors always match, your proxies never fail, and your data be as clean as your code.
FAQs
1. What is the best Python web scraping package for beginners?
For most beginners, the combination of Requests and Beautiful Soup is the easiest way to start. Both have intuitive APIs, tons of tutorials, and handle most static page scraping tasks.
2. How do I scrape JavaScript-heavy websites with Python?
Use Selenium to automate a real browser, or try Thunderbit for AI-powered, no-code scraping that can handle dynamic content. For large-scale needs, Scrapy can be combined with Splash or Selenium.
3. Which package is best for large-scale, high-speed scraping?
Scrapy is built for large-scale, asynchronous crawling. If you need even more speed and are comfortable with async code, aiohttp is a top choice for concurrent requests.
4. Can I combine these packages in my workflow?
Absolutely! Many developers use Requests or Selenium to fetch pages, then parse with Beautiful Soup, lxml, or PyQuery. Thunderbit’s exports can be fed into Python scripts for further analysis.
5. Is Thunderbit a Python library or a standalone tool?
Thunderbit is an AI-powered Chrome extension and platform, not a traditional Python library. However, its output (CSV, Excel, Sheets, Notion, Airtable) integrates seamlessly into Python data pipelines, making it a powerful companion for Python developers.
6. Do AI coding agents replace Python scraping libraries in 2026? Not yet, but they're worth knowing about. Tools like Claude Code and OpenAI Codex can generate a working Requests + Beautiful Soup or Scrapy script from a plain-English prompt in seconds, which is genuinely useful for one-off jobs and prototyping. For natural-language browser flows (logins, dynamic JS, multi-step navigation), Browser Use is the open-source option people are reaching for, and Firecrawl is popular when the goal is feeding clean markdown to an LLM. None of these remove the hard parts — anti-bot defenses, rate limits, and TOS still apply — and for production crawlers at scale, Scrapy + aiohttp still win on cost and control. Treat AI agents as a faster way to write the scraper, not a drop-in replacement for the libraries on this list.
Want to stay ahead in the world of web scraping? Subscribe to the Thunderbit YouTube Channel and keep an eye on the Thunderbit Blog for more guides, comparisons, and automation tips.
Try Thunderbit AI Web Scraper for Free Get Started Free
Learn More




