

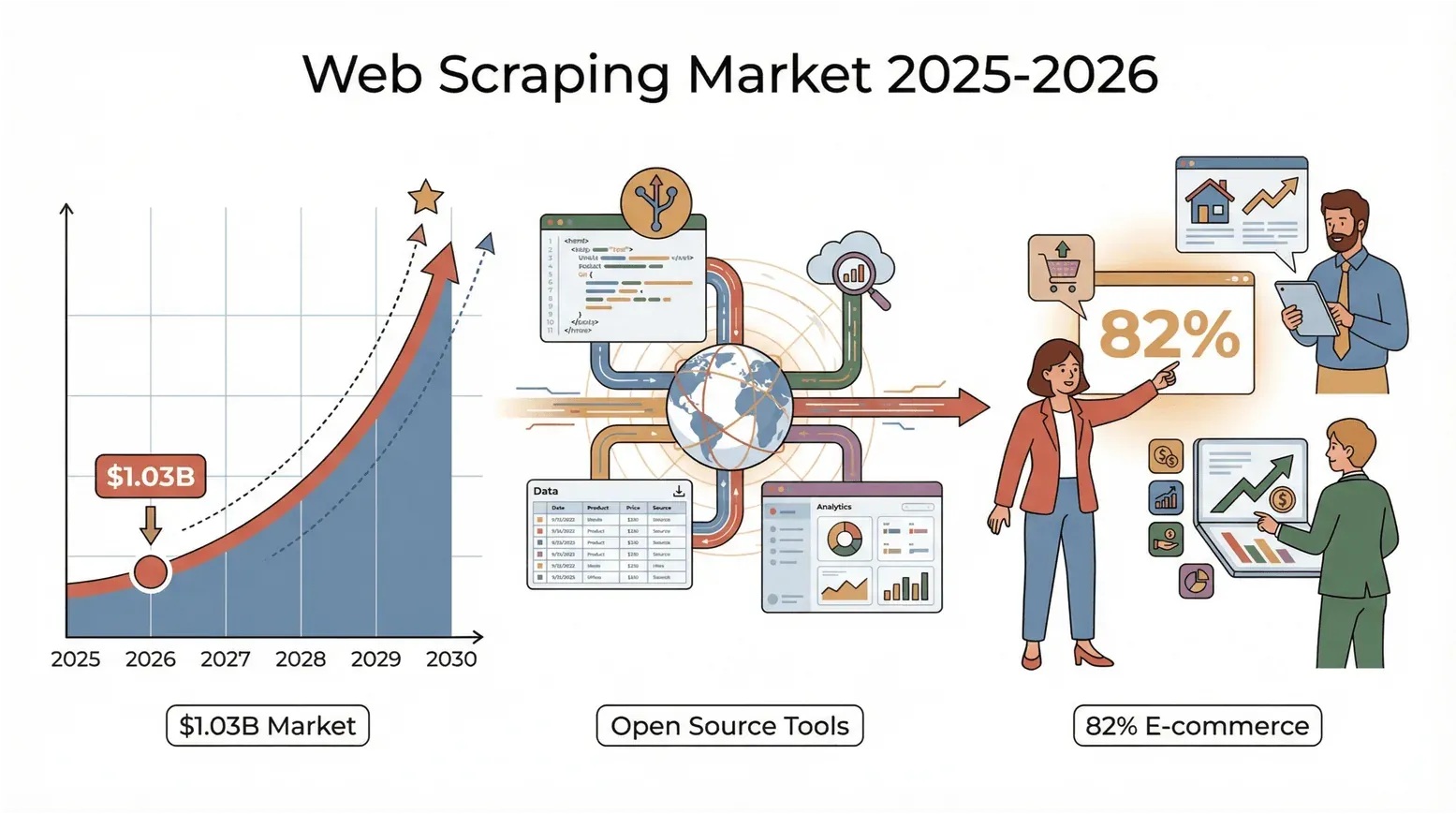
The web is bursting at the seams with data, and in 2026, the race to turn that chaos into insight is more intense than ever. Whether you’re in sales, e-commerce, real estate, or just a data geek like me, you’ve probably noticed that the old “copy-paste” routine just doesn’t cut it anymore. Here’s a wild stat: the global web scraping market hit $1.03 billion in 2025 per Mordor Intelligence (cited in PromptCloud's 2026 state-of-web-scraping report), and is on track to roughly double by 2030. And it’s not just tech giants—82% of e-commerce companies and over a third of investment firms are scraping the web for leads, pricing, and market research (Browsercat). The bottom line: if you’re not using a web scraping tool, you’re probably leaving money—and insights—on the table.
But here's the good news: open source web scraping tools are more powerful, accessible, and community-driven than ever. Whether you're a Python pro, a JavaScript junkie, or a business user who just wants data without the headaches, there's a tool out there for you. I've spent years in SaaS and automation, and I've watched this ecosystem evolve. So, let's dive into the 5 best open source web scraping tools you should explore in 2026 — plus how to pick the right one for your needs.
Why Choose Open Source Web Scraping Tools?
What Is Data Scraping and How to Do It in 2026 Get Started Free
Open source web scraping tools are the Swiss Army knives of the data world. They’re cost-effective (no license fees), flexible (customize anything), and transparent (you can see exactly how they work). But the real magic? The community. Open source tools are backed by thousands of developers and users who share plugins, tutorials, and fixes—so you’re never stuck on your own (Oreate AI).
Compared to commercial tools, open source options put you in the driver’s seat. You’re not locked into a vendor’s roadmap or pricing, and you can adapt your scrapers as websites change. Plus, many commercial scraping services are actually built on top of these open source engines—so why not go straight to the source?
How We Selected the Best Open Source Web Scraping Tools
With so many options out there, I focused on a few key criteria:
- Ease of use: Can non-coders get started quickly? Are there visual or AI-driven options?
- Scalability: Can the tool handle large projects or just one-off jobs?
- Language and platform support: Python, JavaScript, browser-based, desktop—something for every stack.
- Community and maintenance: Is the tool actively updated? Are there forums, docs, and plugins?
- Unique features: AI field detection, subpage scraping, scheduling, cloud support, and more.
I also considered real-world feedback and business use cases—because the best tool is the one that actually solves your problem.
The Top 5 Best Open Source Web Scraping Tools to Explore
Let’s get to the good stuff. Here’s my handpicked list, from AI-powered simplicity to developer powerhouses.
1. Scrapy
Scrapy is the Python developer's dream. It's a battle-tested framework for building scalable, customizable crawlers and data pipelines. You define "spiders" in Python, and Scrapy handles queuing, throttling, and exporting to JSON, CSV, or XML. As of the 2.14 release (Oct 2025) and 2.14.1 patch (Jan 2026), a large chunk of Scrapy's Twisted-Deferred internals were rewritten as native asyncio coroutines, with a new AsyncCrawlerProcess entry point that plays nicely with the rest of the modern Python async ecosystem; the asyncio reactor is now the default for newly generated projects. Heads up: Scrapy 2.14+ requires Python 3.10 or newer.
The plugin ecosystem is massive, with middleware for proxies, cookies, and even headless browser integration for dynamic sites. Scrapy is the framework most teams reach for when crawling entire e-commerce catalogs or aggregating news at scale. It's got a steep learning curve for non-coders, but if you want power and flexibility, Scrapy delivers (Octoparse).
2. Beautiful Soup
Beautiful Soup is the classic Python library for quick-and-dirty HTML parsing. It’s beloved by beginners and pros alike for its gentle learning curve and forgiving parser (it can handle even the messiest HTML). You fetch a page (usually with requests), load it into Beautiful Soup, and use simple methods to find and extract elements.
It’s perfect for small projects, prototypes, and educational use. The catch? Beautiful Soup can’t execute JavaScript, so it only works on static HTML. For dynamic sites, you’ll need to pair it with something like Selenium or requests_html (ProsperaSoft).
3. Selenium
Selenium is the OG browser automation tool. Originally built for testing, it’s become a favorite for scraping dynamic, JavaScript-heavy sites. Selenium launches a real browser (Chrome, Firefox, etc.) and simulates user actions—clicks, scrolls, logins, you name it. If a human can see it, Selenium can scrape it.
It supports multiple languages (Python, Java, JS, C#) and is great for scraping behind logins or interactive flows. Selenium 4 has also been steadily integrating WebDriver BiDi, a bidirectional protocol that lets your script subscribe to browser events (network requests, console logs, DOM mutations) and intercept network calls — features that previously made Puppeteer or Playwright the easier choice for scraping. The 4.40 release (January 2026) and 4.41 (February 2026) expanded BiDi support across Python, Java, .NET, and Ruby bindings. Downsides remain: Selenium is slower and heavier than pure HTTP scrapers, and managing browser drivers is still a chore. But for tricky sites — and for teams already standardized on Selenium for test automation — it's a credible scraping option in 2026 (ScrapeHero).
4. Cheerio
Cheerio is the jQuery of the Node.js world. It lets you parse HTML on the server with a familiar, jQuery-like syntax. It’s blazing fast and perfect for static pages—just fetch the HTML (with Axios or Fetch), load it into Cheerio, and use selectors to grab what you need.
Cheerio doesn’t execute JavaScript, so it’s best for static content. But it integrates beautifully with other Node.js tools, and is a favorite for developers who want to keep everything in JavaScript (Cheerio Docs).
5. Puppeteer
Puppeteer is a Node.js library for controlling Chrome or Chromium in headless mode. It's a popular pick for scraping modern web apps and single-page applications that need real browser rendering: screenshots, PDF generation, network interception, all behind a clean async/await API. The Chrome team at Google still maintains Puppeteer and keeps it aligned with each new Chrome version and DevTools Protocol update.
A bit of context worth knowing for 2026: Puppeteer's release cadence has narrowed to Chrome-compatibility and dependency updates rather than new capabilities, and the original team that built Puppeteer's most ambitious features went on to create Playwright at Microsoft. If you're already invested in Puppeteer and only need Chrome automation, it remains a stable choice. If you're starting fresh and want cross-browser support, a built-in test runner, auto-waiting locators, and a trace viewer, most 2026 teams point at Playwright first (Firecrawl — Playwright vs Puppeteer, Autonoma — Playwright vs Puppeteer 2026).
Try Thunderbit AI Web Scraper for Free
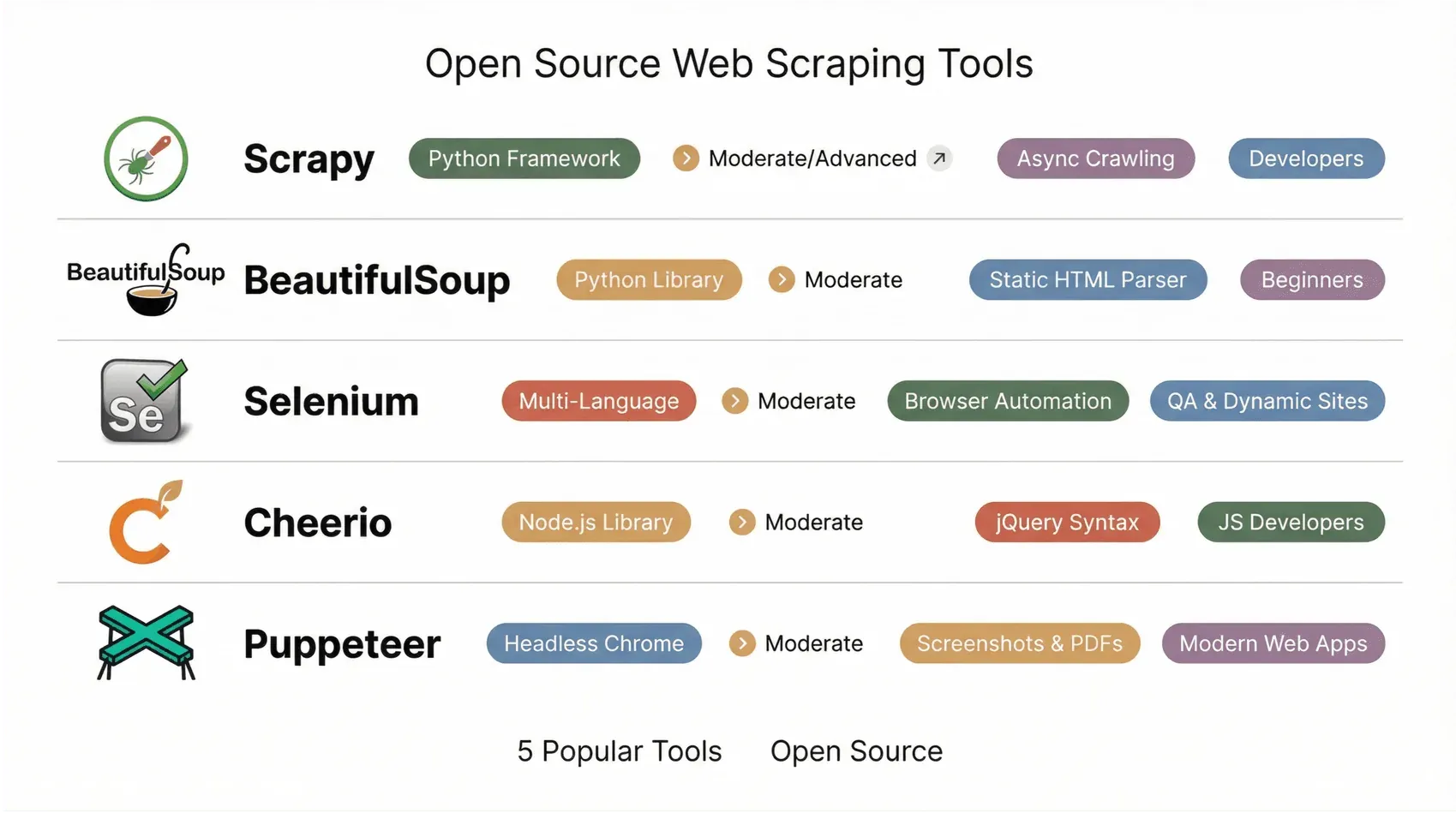
Quick Comparison Table: Best Open Source Web Scraping Tools
| Tool | Ease of Use | Platform/Language | Dynamic Content | Best For | Unique Strengths |
|---|---|---|---|---|---|
| Scrapy | Moderate/Advanced (code) | Python framework | Partial | Developers, data scientists | Async crawling, plugins, huge community |
| BeautifulSoup | Moderate (simple code) | Python library | No | Beginners, quick parsing | Forgiving parser, great for static HTML |
| Selenium | Moderate (scripting) | Multi-language | Yes | QA, scraping dynamic sites | Real browser automation, handles logins, user events |
| Cheerio | Moderate (JS code) | Node.js library | No | JS devs, static pages | jQuery syntax, fast HTML parsing |
| Puppeteer | Moderate (JS code) | Node.js (headless Chrome) | Yes | Devs, modern web apps | Screenshots, PDFs, SPA scraping, async/await API |
How to Choose the Right Open Source Web Scraping Tool for Your Needs
How to Scrape Any Website Using AI Get Started Free
Here’s my cheat sheet for picking the right tool:
- Technical Skill: Non-coders? Start with Thunderbit, Octoparse, ParseHub, or WebHarvy. Developers? Scrapy, Cheerio, Puppeteer, or Apify.
- Project Scale: One-off or small jobs? Beautiful Soup, Cheerio, WebHarvy. Large-scale or ongoing? Scrapy, Apify, Thunderbit (with scheduling).
- Data Type: Static HTML? Use Cheerio, Beautiful Soup, or WebHarvy. Dynamic/JS-heavy? Puppeteer, Selenium, Thunderbit, Octoparse.
- Integration: Need to export to Sheets, Notion, or databases? Thunderbit and Octoparse make it easy. Need APIs or custom pipelines? Scrapy and Apify are your friends.
- Community & Support: Look for active forums, recent updates, and lots of tutorials. Scrapy, Cheerio, and Selenium have huge communities; Thunderbit and Octoparse have growing user bases and lots of guides.
Try a couple of tools on a small project—see which one fits your workflow and comfort level. And don’t be afraid to mix and match: sometimes the fastest solution is a quick scrape with a visual tool, then a deeper crawl with a code-based framework.
The Value of Community and Ongoing Support in Open Source Scraping
One of the biggest perks of open source? The community. Active forums, GitHub repos, and Stack Overflow tags mean you’re never alone. If you hit a snag, chances are someone’s already solved it—or will help you out. Community-driven tools get frequent updates and new features, and you’ll find tons of tutorials, plugins, and best practices (Oreate AI).
Therefore, for visual tools like Thunderbit and Octoparse, user forums and template sharing are a goldmine. For developer tools, GitHub issues and Discord/Slack groups are where the magic happens. When you choose an open source tool, you’re joining a global network of problem-solvers—and that’s priceless.
Thunderbit:An Easier No-coding Web Scraping Soluion for Everyone
Yeah, open source is nice—but sometimes you don’t actually want to build, tune, and babysit a scraper just to get usable data. And not every scraping problem can be solved with open source code—and that’s where Thunderbit fits in nicely. If you’ve read this far and thought, “These tools are powerful, but I just want the data without building or maintaining scrapers,” Thunderbit is the natural next step.
Thunderbit is an AI-powered Chrome extension designed for business users who care more about outcomes than infrastructure. Instead of writing selectors or scripts, you start by clicking AI Suggest Fields. The AI understands the page structure, proposes columns, and you scrape with a second click. Pagination, subpages, and list-detail workflows are handled for you.
One of Thunderbit’s biggest strengths is how it bridges human intent and structured data. You can describe what you want in plain language (for example, “collect product names, prices, and ratings”), and Thunderbit translates that into a clean table. Subpage scraping makes it easy to extract richer data by automatically visiting detail pages. Exports to Excel, Google Sheets, Notion, and Airtable are built in, so your data is usable immediately.
Thunderbit is especially popular with sales, marketing, e-commerce, and real estate teams that need reliable data but don’t want to maintain open source pipelines. It supports dozens of languages, works well on dynamic sites, and offers a generous free tier to get started. While it’s not open source, it complements open source tools well—think of it as the fastest way to validate ideas or handle recurring business scrapes without engineering overhead.
Conclusion: Unlocking Web Data with the Best Open Source Tools
Web scraping is no longer just for coders or big companies. With today’s open source tools, anyone can turn the web into structured, actionable data—whether you’re building a lead list, monitoring prices, or fueling your next AI project. The key is to match the tool to your needs: AI-powered and visual tools for speed and simplicity, code frameworks for power and scale.
So, what’s next? Pick a tool from this list, try it on a real-world task, and see how much time and effort you save. And if you want a quick win, download Thunderbit and see how easy web scraping can be. The web’s your oyster—go get those pearls of data.
For more deep dives and tutorials, check out the Thunderbit Blog. Happy scraping!
Try Thunderbit AI Web Scraper for Free Get Started Free
FAQs
1. What is the main advantage of open source web scraping tools over commercial ones?
Open source tools are cost-effective, flexible, and backed by active communities. You can customize them, avoid vendor lock-in, and benefit from shared knowledge and frequent updates.
2. Which open source tool is best for non-technical business users?
Thunderbit, Octoparse, ParseHub, and WebHarvy are all excellent for non-coders. Thunderbit stands out for its AI-driven, two-click workflow and direct export options.
3. Can open source tools handle dynamic, JavaScript-heavy websites?
Yes! Tools like Thunderbit, Selenium, Puppeteer, Octoparse, and ParseHub can all scrape dynamic content by rendering pages in a real or headless browser.
4. How do I know if a tool is actively maintained and supported?
Check GitHub for recent commits, open issues, and contributor activity. Look for active forums, recent blog posts, and lots of user-contributed plugins or templates.
5. What’s the best way to get started with web scraping if I’m new?
Start with a visual or AI-powered tool like Thunderbit or Octoparse. Try scraping a small dataset, export it to Excel or Sheets, and experiment. As you get comfortable, you can explore code-based tools for more advanced projects.
Want to see Thunderbit in action? Download the Chrome extension and join 30,000+ users turning the web into data—no code required.
Learn More




