

Nearly half of all internet traffic is now bots. Most of them are scraping links, data, and URLs at scale. If you’re still doing it by hand, you’re losing ground.
I tested 12 link extractor tools — from AI-powered Chrome extensions to Python libraries — to see which ones actually deliver when you need thousands of URLs scraped fast.
Here’s what I found.
Why Link Extractors Matter
Let’s be real: The web is overflowing with data, and businesses are racing to turn that chaos into actionable insights. Link extractors and URL extractors are now mission-critical for teams that want to:
- Generate leads: Sales teams can pull company profile links from directories or LinkedIn in minutes, then feed those URLs into tools to extract contact info. No more endless clicking.
- Aggregate content and boost SEO: Marketers can collect all article URLs from a blog, monitor competitor backlinks, or audit site structures for broken links.
- Monitor competitors and do market research: Operations teams can automatically gather links to new products, pricing pages, or press releases—keeping tabs on the competition without breaking a sweat.
- Automate workflows and save time: Modern link scrapers handle bulk URLs, crawl subpages, and export data in structured formats (CSV, Excel, Google Sheets, Notion, you name it). That means no more copy-paste marathons or cleaning up messy text files.
Given that tens of billions of web pages are crawled daily, doing this manually is a non-starter. The right link extractor is like having a supercharged assistant who never gets tired, never misses a link, and never asks for a coffee break.
How We Chose the Best Link Extractors
With so many tools out there, picking the right link extractor can feel like speed-dating at a tech conference—everyone promises to be "the one," but only a few actually deliver. Here’s how I narrowed down the top 12:
- Ease of Use: Can non-coders use it without a PhD in regex? No-code and low-code solutions got extra points.
- Bulk & Multi-Level Scraping: Can it handle hundreds of URLs at once? Does it crawl subpages and follow links automatically?
- Export & Integration: Does it export to CSV, Excel, Google Sheets, Notion, Airtable, or via API? The less manual work, the better.
- User Type & Flexibility: Is it for business users, analysts, or developers? Some tools are built for everyone; others are more niche.
- Advanced Features: AI-driven recognition, scheduling, cloud-based scaling, data cleaning, and templates for common sites.
- Pricing & Scalability: Free tiers, pay-as-you-go, or enterprise? I looked at what you get for your money.
I’ve included everything from browser extensions to enterprise platforms, so whether you’re a solo founder or a Fortune 500 data team, you’ll find a fit.
Thunderbit: The Smartest Link Extractor for Business Users
Let’s start at the top. Thunderbit is my go-to recommendation for link extraction, and not just because I helped build it. Thunderbit is an AI-powered web scraper Chrome Extension designed for business users who want results—fast.
What makes Thunderbit stand out? It’s like having an AI intern who actually listens. You can use natural language to describe what you want (“Grab all the product links and prices from this page”), and Thunderbit’s AI figures out the rest. No need to tinker with selectors or write scripts.
But it doesn’t stop there:
- Bulk URL Support: Paste a single URL or a list of hundreds—Thunderbit handles them all in one go.
- Subpage Navigation: Need to scrape links from a list page and then visit each detail page for more URLs? Thunderbit’s multi-layer scraping logic has you covered.
- Structured Export: Once your links are extracted, you can rename fields, categorize them, and export directly to Google Sheets, Notion, Airtable, Excel, or CSV. No more post-processing headaches.
Scrape links from any website using AI Get Started Free
Thunderbit is trusted by over 30,000 users worldwide, from sales teams to real estate agents to indie e-commerce shops. And yes, there’s a free tier (scrape up to 6 pages, or 10 with a trial boost), so you can try it out risk-free.
Try Thunderbit Link Extractor for Free
Thunderbit’s Standout Features
Let’s dig into what really sets Thunderbit apart:
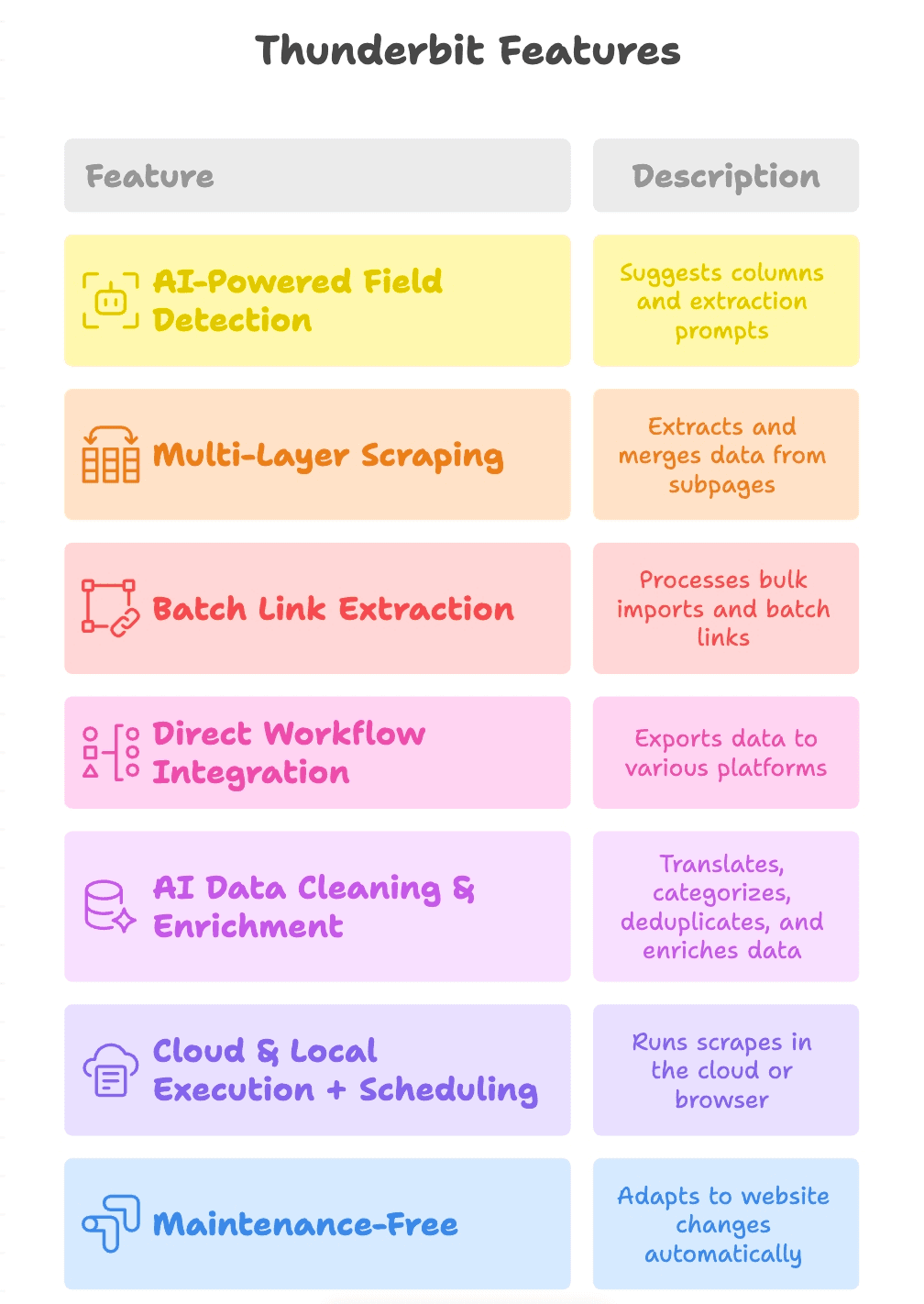
- AI-Powered Field Detection: Just click “AI Suggest Fields,” and Thunderbit reads the page, suggests columns (like “Product Link,” “PDF URL,” “Contact Email”), and even creates extraction prompts for each field.
- Multi-Layer Scraping: Thunderbit can follow links from a main page to subpages (like product detail pages or PDF downloads), extract more links, and merge everything into a single table.
- Batch Link Extraction: Whether you’re scraping one page or a thousand, Thunderbit can process bulk imports and batch link extraction with ease.
- Direct Workflow Integration: Export results to Google Sheets, Notion, Airtable, or download as CSV/Excel. Your data lands exactly where your team needs it.
- AI Data Cleaning & Enrichment: Thunderbit can translate, categorize, deduplicate, and even enrich your data as it scrapes—so your output is ready to use, not just a raw dump.
- Cloud & Local Execution + Scheduling: Run scrapes in the cloud for speed, or in your browser for sites that require login. Schedule recurring jobs to keep your data fresh.
- Maintenance-Free: Thunderbit’s AI adapts to website changes, so you spend less time fixing broken scrapers and more time getting results.
Octoparse: No-Code Link Scraper for Everyone
Octoparse is a classic in the no-code scraping world. It’s a desktop app (Windows/Mac) with a visual, point-and-click interface. You load a webpage, click on the links you want, and Octoparse figures out the rest.
- Great for Beginners: No coding needed. Just click, extract, and go.
- Handles Pagination & Dynamic Content: Octoparse can click “Next” buttons, scroll, and even log in to sites.
- Cloud Scraping & Scheduling: Paid plans let you run jobs in the cloud and schedule recurring tasks.
- Export Options: Download data as CSV, Excel, JSON, or push to databases.
The free plan is generous for small jobs (up to 10 tasks and 50,000 rows/month), but heavier users will need a paid plan (starting around $75/month).
Apify: Flexible URL Extractor for Custom Workflows
Apify is the Swiss Army knife of web scraping. It offers a marketplace of pre-built “actors” (scraping tools), as well as the ability to write your own scripts in JavaScript or Python.
- Pre-Built & Customizable: Use community actors for common tasks, or build your own for custom workflows.
- Bulk & Scheduled Scraping: Queue up URLs, run jobs in parallel, and schedule recurring scrapes.
- API-First: Export to JSON, CSV, Excel, or Google Sheets, and integrate with your data pipeline.
- Pay-As-You-Go: Free credits each month, then usage-based billing.
Apify is ideal for semi-technical teams and developers who want flexibility and scalability.
Bright Data URL Scraper: Enterprise-Grade Link Scraping
Bright Data is built for enterprises that need to scrape at scale. Their Data Collector offers a preset URL Scraper for high-volume jobs.
- Handles Massive Scale: Scrape thousands or millions of pages, with robust proxy infrastructure to avoid blocks.
- Preset Templates: Ready-made scrapers for e-commerce, social, real estate, and more.
- Enterprise Features: Compliance tools, expert support, and advanced anti-blocking.
- Pricing: Starts around $350 for 100,000 page loads—definitely aimed at big business.
If you’re a startup, this might be overkill. But for mission-critical, high-volume scraping, Bright Data is a powerhouse.
WebHarvy: Visual Link Extractor with Point-and-Click Simplicity
WebHarvy is a desktop app (Windows) that lets you scrape links by simply clicking on them in its built-in browser.
- Super Simple: Click on a link, and WebHarvy highlights all similar elements for extraction.
- Regular Expression Support: Built-in patterns for common tasks, no coding required.
- Export to Excel, CSV, JSON, XML, SQL: Great for business users who want data in familiar formats.
- One-Time License: Pay once, use forever.
Perfect for small businesses, researchers, or anyone who wants a quick, no-fuss way to get links without coding.
Web Scraper (Chrome Extension): Quick Link Scraping in Your Browser
The Web Scraper Chrome Extension is a free, open-source tool that turns your browser into a scraper.
- Define Sitemaps: Tell it how to navigate and what to extract.
- Handles Pagination & Multi-Level Crawling: Crawl categories, subcategories, and detail pages.
- Export to CSV/XLSX: Download data right from your browser.
- Community Templates: Lots of shared sitemaps for popular sites.
It’s perfect for quick, one-off jobs or for students and small teams on a budget.
ScraperAPI: Scalable Link Scraper for Developers
ScraperAPI is for developers who want to fetch web pages at scale without worrying about proxies, blocks, or CAPTCHAs.
- API-Driven: Send a URL, get back HTML or scraped data.
- Handles Scale & Anti-Bot Measures: Proxy rotation, JS rendering, and CAPTCHA solving built-in.
- Integrates with Your Code: Use with Python, Node.js, or any language.
- Pricing: Free tier (~1000 API calls), then pay per request.
Great for custom crawlers or when you need reliability and speed at scale.
ParseHub: Visual Link Scraper with Advanced Selection
ParseHub is a desktop app (Windows, Mac, Linux) that lets you build scraping projects visually.
- Advanced Selection & Navigation: Click, loop, and conditionally extract links—even from dynamic or hidden elements.
- Handles Nested Pages: Crawl categories, then detail pages, then extract more links.
- Export to CSV, Excel, JSON: Cloud runs and API access on paid plans.
- Free Plan: 5 projects, up to 200 pages per run.
ParseHub is a favorite for marketers and researchers who want power without code.
Scrapy: Python Link Extractor for Developers
Scrapy is the gold standard for Python developers who want full control.
- Code-First: Build custom spiders to crawl and extract links at any scale.
- Handles Distributed Crawling: Efficient, asynchronous, and highly customizable.
- Export to CSV, JSON, XML, or Database: You control the output.
- Open-Source & Free: But you’ll need to manage your own environment.
If you’re comfortable with Python, Scrapy is as powerful as it gets.
Diffbot: AI-Powered Link Scraper for Structured Data
Diffbot is the “AI brain” of web scraping. It analyzes pages and returns structured data—including links—without manual setup.
- Automatic Content Recognition: Feeds a URL, gets back structured data (articles, products, links, etc.).
- Crawlbot & Knowledge Graph: Crawl entire sites, or query their massive web index.
- API-Driven: Integrate with your BI tools or data pipeline.
- Enterprise Pricing: Starts around $299/month, but you get what you pay for.
Best for enterprises that want clean, structured data without managing scrapers.
Cheerio: Lightweight Link Scraper for Node.js
Cheerio is a fast, jQuery-like HTML parser for Node.js.
- Super Fast: Parses HTML in milliseconds.
- Familiar Syntax: If you know jQuery, you know Cheerio.
- Great for Static Pages: Doesn’t render JS, but perfect for server-rendered content.
- Open-Source & Free: Pair with axios or fetch for requests.
Ideal for developers building custom scripts who want speed and simplicity.
Puppeteer: Browser Automation for Advanced Link Scraping
Puppeteer is a Node.js library for controlling Chrome in headless mode.
- Full Browser Automation: Load pages, click, scroll, and interact like a real user.
- Handles Dynamic Content & Logins: Perfect for JavaScript-heavy sites or complex workflows.
- Fine Control: Wait for elements, take screenshots, intercept network requests.
- Open-Source & Free: But resource-intensive and slower than lightweight tools.
Use Puppeteer when you need to scrape links from sites that don’t play nice with basic scrapers.
At-a-Glance Comparison: Which Link Extractor Fits Your Needs?
Here’s a quick comparison of all 12 tools:
| Tool | Best For | Bulk & Subpage Support | Data Export Options | Pricing |
|---|---|---|---|---|
| Thunderbit | Non-coders, business | Yes (AI, multi-level) | Excel, CSV, Sheets, Notion, Airtable | Free trial, from ~$9/mo |
| Octoparse | No-code users, analysts | Yes | CSV, Excel, JSON, cloud storage | Free tier, ~$75/mo |
| Apify | Semi-tech, devs | Yes | CSV, JSON, Sheets via API | Free credits, usage-based |
| Bright Data | Enterprise | Yes (high volume) | CSV, JSON, NDJSON via API | ~$350/100k pages |
| WebHarvy | Non-coders, desktop | Yes | Excel, CSV, JSON, XML, SQL | Paid license |
| Web Scraper Extension | Anyone, quick/free | Yes | CSV, XLSX | Free, open-source |
| ScraperAPI | Developers, API users | Yes | JSON (HTML via API) | Free 1k req, paid tiers |
| ParseHub | Non-coders, advanced | Yes | CSV, Excel, JSON, API | Free 5 projects, paid |
| Scrapy | Devs, Python | Yes | CSV, JSON, XML, DB | Free, open-source |
| Diffbot | Enterprise, AI | Yes (AI crawl) | JSON (structured data via API) | ~$299/mo+ |
| Cheerio | Devs, Node.js | Yes (custom code) | Custom (JSON, etc.) | Free, open-source |
| Puppeteer | Devs, complex sites | Yes (full automation) | Custom (scripted output) | Free, open-source |
Choosing the Right Link Scraper for Your Business
So, how do you pick? Here’s my cheat sheet:
- No coding skills? Start with Thunderbit, Octoparse, ParseHub, WebHarvy, or the Web Scraper extension.
- Need custom workflows? Apify, ScraperAPI, or Cheerio are great for devs.
- Enterprise scale? Bright Data or Diffbot are built for you.
- Python or Node.js developer? Scrapy (Python) or Cheerio/Puppeteer (Node.js) give you full control.
- Want direct export to Sheets/Notion? Thunderbit is your best bet.
Match the tool to your technical comfort, data volume, and integration needs. Most offer free trials, so don’t be afraid to experiment.
Explore more web scraping guides Get Started Free
Thunderbit’s Unique Value for Link Extraction in 2026
Let’s circle back to what makes Thunderbit truly different:
- AI-Powered Simplicity: Describe what you want in plain English—Thunderbit’s AI handles the rest.
- Multi-Layer Scraping: Extract links from main pages, follow to subpages, and grab more URLs—all in one flow.
- Bulk Import & Batch Processing: Paste hundreds of URLs, extract links in bulk, and export structured data instantly.
- Workflow Integration: Export directly to Google Sheets, Notion, Airtable, or download as CSV/Excel.
- Zero Maintenance: Thunderbit’s AI adapts to website changes, so you’re not constantly fixing broken scrapers.
Thunderbit bridges the gap between “just scraping data” and “getting data you can actually use.” It’s the tool I wish I’d had years ago when I was drowning in manual data tasks.
Start Free Link Extraction with Thunderbit
Conclusion: Scrape Links Smarter and Boost Your Workflow
Web data is the fuel for business growth—and the right link extractor is your engine. Whether you’re building lead lists, monitoring competitors, or automating research, there’s a tool here that fits your needs and your skillset.
If you want to see what modern link extraction looks like, give Thunderbit’s free trial a spin. I think you’ll be surprised how much you can accomplish in just a few clicks. And if Thunderbit isn’t the perfect fit, try out a few others from this list—there’s never been a better time to automate the boring stuff and focus on what really matters.
Happy scraping—and may your links always be clean, structured, and ready for action. If you want to dive deeper into web scraping, check out the Thunderbit Blog for more guides and tips.
Try Thunderbit Link Extractor for Free Get Started Free
FAQs
1. Why are link extractors essential?
With nearly half of internet traffic coming from bots and businesses aggressively scraping data, link extractors are vital for turning web chaos into actionable insights. They help automate tasks like lead generation, content aggregation, SEO audits, and competitor monitoring, saving massive amounts of time and effort.
2. What makes Thunderbit stand out among other link extractors?
Thunderbit uses AI to simplify scraping—just describe your goal in plain language, and it handles the rest. It supports bulk URL input, multi-layer scraping, smart field detection, and seamless export to platforms like Google Sheets and Notion. It’s ideal for non-coders and business users who want powerful results without technical hassle.
3. Are there link extractor tools suitable for developers and custom workflows?
Yes. Tools like Apify, ScraperAPI, Cheerio, Puppeteer, and Scrapy cater to developers. They offer scripting, API integration, and flexibility to handle complex scraping tasks, large-scale jobs, and advanced automation.
4. Which tools are best for users with no coding experience?
Thunderbit, Octoparse, ParseHub, WebHarvy, and the Web Scraper Chrome extension are top picks for non-technical users. These tools offer visual interfaces, pre-built templates, and AI-driven features that make link extraction accessible to everyone.
5. How should I choose the right link extractor for my needs?
Consider your technical skills, data volume, and export needs. Non-coders should opt for tools like Thunderbit or Octoparse, while developers may prefer Scrapy or Puppeteer. Enterprises might look at Bright Data or Diffbot for large-scale operations. Always start with a free trial to see what fits best.




