

The web has become a visual jungle—images everywhere, from product galleries to real estate listings, social media feeds to competitor catalogs. I’ve seen firsthand how teams in sales, ecommerce, and marketing are scrambling to keep up, not just with words and numbers, but with the tidal wave of images that drive decisions and shape brands. Did you know that articles with images get 94% more views than text-only posts? Or that pairing instructions with visuals can boost productivity by 15%? Visual data isn’t just a nice-to-have—it’s the new business currency.

But here’s the catch: extracting images at scale is a pain. Manually right-clicking and saving each photo? That’s a one-way ticket to carpal tunnel. And with websites getting more dynamic—think infinite scroll, pop-up galleries, and AJAX-loaded content—the old-school scrapers just can’t keep up. That’s why I’ve put together this list of the top 5 best image crawler tools for efficient data extraction in 2025. Whether you’re a non-coder who just wants results, a developer who loves to tinker, or an enterprise with serious data needs, there’s a tool here for you.
Let’s dive into what makes a great image crawler, how each tool stacks up, and which one might be the secret weapon your workflow has been missing.
Why Choosing the Best Image Crawler Matters
Discover the Best Web Scraping Tools Get Started Free
Images are everywhere, but getting them out of the web and into your workflow is anything but simple. Businesses rely on image data for everything from market research and competitor analysis to AI model training and content creation. In retail and real estate, images can make or break a sale—customers want to see, not just read. Marketing teams track user-generated images to spot trends, while researchers scrape product photos to analyze design shifts.
But here’s where things get tricky:
- Dynamic content: Many sites load images only after you scroll or click—basic scrapers miss these entirely.
- Pagination and infinite scroll: Product galleries often span dozens of pages, and the best crawlers need to handle “Next” buttons or endless scrolling automatically.
- Filtering relevant images: Not every picture is useful—ads, icons, and decorative graphics can clutter your dataset.
- Integration headaches: After scraping, you need to get those images (or their URLs) into Excel, Sheets, Notion, or your database—preferably without a week of copy-pasting.
Pick the wrong tool, and you risk incomplete data, wasted time, or even getting blocked by websites. The right image crawler, on the other hand, can save hours (or days), improve accuracy, and help you make better, faster decisions.
How We Selected the Best Image Crawler Tools
Not all image crawlers are created equal. When I set out to find the best, I looked at:
- Ease of Use: Can non-technical users get started quickly? Do you need to write code, or can you just point and click?
- Scalability: Does it handle hundreds or thousands of pages? Can it run in the cloud for speed?
- Accuracy & Flexibility: Can it extract images from dynamic, JavaScript-heavy sites? Does it handle subpages, filtering, and custom logic?
- Integration & Export: How easily can you get your data into Excel, Google Sheets, Notion, Airtable, or your own database?
- Pricing & Value: Is there a free tier? Does the cost make sense for small teams, or is it built for enterprise budgets?
I also considered the diversity of user needs—some folks want a no-code solution, others need developer-level control, and some enterprises demand ironclad reliability and compliance.
With that, here are my picks for the top 5 best image crawler tools for 2025.
1. Thunderbit
Thunderbit is my go-to recommendation for anyone who wants image extraction to be fast, smart, and (dare I say) fun. As the co-founder, I’m a little biased—but I built Thunderbit because I was tired of watching teams struggle with clunky, outdated scrapers.
Why Thunderbit Stands Out:
- AI-Powered Simplicity: Just describe what you want (“grab all product images and prices”), and Thunderbit’s AI figures out the rest. No selectors, no code, no guesswork.
- 2-Click Workflow: Click “AI Suggest Fields” and Thunderbit automatically detects image URLs, titles, and more. Click “Scrape” and you’re done.
- Subpage Scraping: Need images from detail pages? Thunderbit can crawl into each subpage and pull out every image—perfect for e-commerce, real estate, or any site with galleries.
- Handles Dynamic Content & Pagination: Whether it’s infinite scroll, “Load More” buttons, or JavaScript-loaded images, Thunderbit’s browser and cloud modes can handle it all (docs).
- Instant Export: Push your image data (including actual image files, not just URLs) directly to Excel, Google Sheets, Airtable, or Notion.
- Free Image Extraction: Thunderbit’s image extraction and export features are free for small jobs (6-10 pages), with a pay-per-row credit system for larger projects—no hidden fees or surprises.
Thunderbit’s Key Features for Image Extraction:
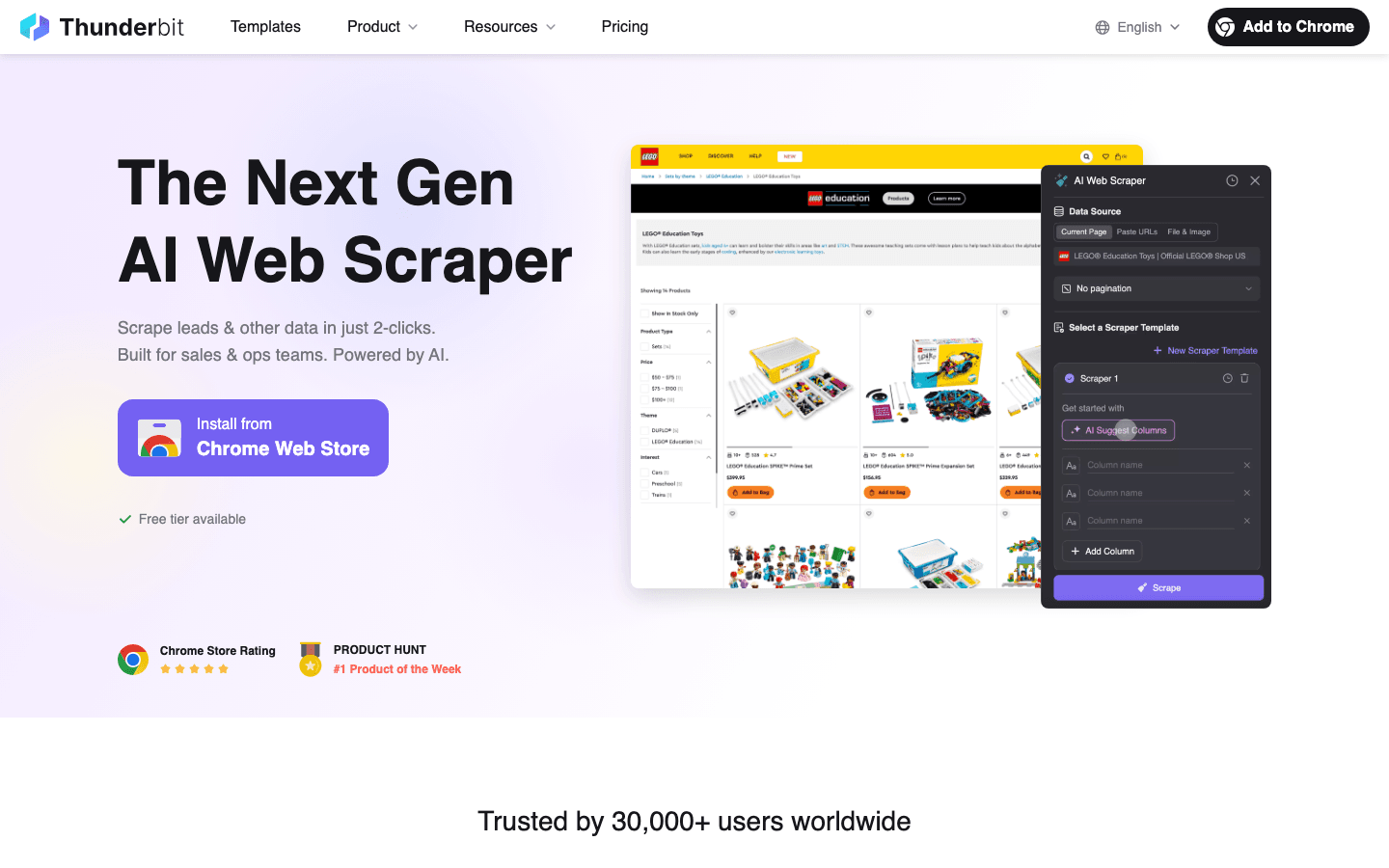
- AI Field Detection: Thunderbit’s AI scans the page and suggests image fields, so you don’t have to hunt for the right HTML tag (docs).
- Subpage & Pagination Automation: Scrape images from listing pages, then dive into each detail page—all in one flow.
- Cloud vs. Browser Scraping: Use cloud mode for speed (up to 50 pages at once), or browser mode for sites that require login or heavy JavaScript.
- Export & Integration: One-click export to Excel, Sheets, Notion, or Airtable. Images display natively in Notion/Airtable—no extra upload steps (docs).
- Multi-language Support: Thunderbit works in 34 languages, so it’s ready for global teams.
Who’s It For?
- Sales, marketing, and research teams who want results without coding.
- Anyone who needs to scrape images from modern, dynamic sites—fast.
Pricing: Free for up to 6-10 pages. Paid plans start at $15/month for 500 credits (rows), making it accessible for small teams and scalable for bigger projects.
Try Thunderbit Free for Image Extraction
If you want to see just how easy image crawling can be, download the Thunderbit Chrome Extension and give it a spin.
2. Scrapy
Scrapy is the Swiss Army knife of web scraping for developers. It’s open-source, Python-based, and built for those who want to customize every step of the crawl.
Why Scrapy Stands Out:
- Ultimate Flexibility: Write your own “spiders” in Python to crawl any site, handle logins, parse tricky HTML, and extract exactly the images (or data) you want.
- High Performance: Scrapy’s asynchronous architecture means it can crawl thousands of pages and download images in parallel—perfect for large-scale projects.
- Images Pipeline: Scrapy has a built-in Images Pipeline that can not only grab image URLs, but actually download the files, generate thumbnails, and filter by size or format.
- Extensible: Tons of plugins for proxies, login handling, and more. Huge community support.
Scrapy’s Image Extraction Capabilities:
- Custom Logic: Need to scrape only images above a certain size? Want to skip duplicates? Scrapy can do it all in code.
- Integration: Output to your own database, cloud storage, or any format you want.
- Open Source: Free to use—just bring your Python chops and server.
Who’s It For?
- Developers, data engineers, and technical teams who want full control.
- Projects where you need to integrate scraping into a larger pipeline or automate at scale.
Pricing: Free (open source), but you’ll need to invest in development and infrastructure.
3. Octoparse
Octoparse is a visual, no-code web scraping tool that makes image extraction accessible to everyone—even if your last coding experience was changing your MySpace background.
Why Octoparse Stands Out:
- Point-and-Click Interface: Just click on the images you want, and Octoparse auto-detects the rest. No code, no XPath, no headaches.
- Auto-Detection & Templates: Octoparse’s auto-detect feature can scan a page and suggest images, lists, and more. Templates for popular sites mean you can start scraping in seconds.
- Handles Pagination & Infinite Scroll: Visual workflow lets you add “Next Page” or auto-scroll steps with a couple of clicks.
- Cloud Scraping & Scheduling: Paid plans let you run jobs in the cloud, schedule recurring scrapes, and handle large volumes.
Octoparse’s Visual Workflow for Image Extraction:
- Bulk Extraction: Scrape thousands of image URLs in minutes, then use a Chrome extension to download the files if needed.
- Export Options: Download results as CSV, Excel, or push to your database/API.
- Free Plan: Limited runs for small jobs; paid plans start at ~$119/month for more power.
Who’s It For?
- Non-technical teams, marketers, researchers, and small businesses.
- Anyone who wants to scrape images without writing a line of code.
4. ParseHub
ParseHub is another visual scraper, but it’s especially good at handling complex, dynamic websites—think JavaScript-heavy pages, single-page apps, or sites that require conditional logic.
Why ParseHub Stands Out:
- Dynamic Content Support: ParseHub can interact with AJAX-loaded content, pop-ups, and multi-step navigation. If images only appear after clicking or scrolling, ParseHub can get them.
- Visual Scripting with Logic: Add conditions, loops, and variables to your scraping workflow—no code required, but plenty of power for advanced users.
- Multi-Data Extraction: Grab images, text, links, and more in one project.
- Cloud Execution & Scheduling: Run jobs in the cloud, schedule recurring scrapes, and integrate via API.
ParseHub’s Advanced Features for Image Data:
- Pagination & Subpages: Easily scrape images across multiple pages, or dive into detail pages for more.
- Export: Download as CSV, Excel, or connect to BI tools like Tableau.
- Free Tier: Up to 200 pages per run; paid plans start at ~$189/month for higher volume.
Who’s It For?
- Users who need a no-code tool but deal with complex or modern websites.
- Data analysts and researchers who want more control without coding.
5. Content Grabber
Content Grabber (also known as Sequentum Enterprise) is the heavy hitter for enterprise-scale image crawling. If you’re managing massive, ongoing scraping projects with strict compliance needs, this is your tool.
Why Content Grabber Stands Out:
- Enterprise-Grade Platform: On-premise Windows software designed for high-volume, mission-critical scraping.
- Visual Editor + Scripting: Build workflows visually, but add custom C#/VB.NET scripts for advanced scenarios.
- Multi-threaded Crawling: Download images from thousands of pages in parallel.
- Robust Error Handling & Scheduling: Built-in scheduler, error recovery, and monitoring for reliable, unattended operation.
- Integration: Export to databases, APIs, cloud storage, or any format your IT team dreams up.
- Team Collaboration: Version control, user access, and centralized management for large teams.
Content Grabber’s Workflow Automation for Images:
- Handles Complex Sites: AJAX, JavaScript, pop-ups, CAPTCHAs, and more.
- Security & Compliance: Runs on your infrastructure—no data leaves your servers.
- Custom Pricing: Typically a significant investment, but justified for enterprises with ongoing, large-scale needs.
Who’s It For?
- Enterprises, data providers, and anyone running large, repeatable image/data extraction pipelines.
- Teams that need ironclad reliability, compliance, and integration.
Quick Comparison: Best Image Crawler Tools at a Glance
| Tool | Key Strengths | Best For | Pricing (Approx.) |
|---|---|---|---|
| Thunderbit | AI-powered, 2-click setup, subpage/pagination, instant export | Non-coders, fast results, SMBs | Free for 6-10 pages, then pay-per-row (from $15/mo) |
| Scrapy | Python-based, flexible, scalable, downloads images directly | Developers, custom projects, large scale | Free (open source) |
| Octoparse | No-code, visual, auto-detect, templates, cloud scraping | Non-tech teams, marketing, research | Free plan, paid from ~$119/mo |
| ParseHub | Visual, handles dynamic sites, logic/conditions, cloud scheduling | Complex sites, analysts, no-code power users | Free tier, paid from ~$189/mo |
| Content Grabber | Enterprise-grade, visual + scripting, multi-threaded, on-prem | Enterprises, high-volume, compliance | Custom/enterprise pricing |
Choosing the Best Image Crawler for Your Business Needs
How to Scrape Any Website Using AI Get Started Free
So, which tool should you pick? Here’s my take:
- Need results fast, with zero setup? Go with Thunderbit. It’s the easiest way to scrape images, especially if you want to export to Sheets, Notion, or Airtable.
- Have a developer and want full control? Scrapy is unbeatable for custom, large-scale projects.
- No coding skills, but want a visual workflow? Octoparse is perfect for small to mid-size teams, while ParseHub is better for complex, dynamic sites.
- Running an enterprise operation? Content Grabber is built for you—think big data, compliance, and automation.
Always consider your team’s technical skills, the complexity of your target sites, and how often you need to run your scrapes. Most of these tools offer free trials or tiers—so don’t be afraid to experiment and see what fits your workflow.
Conclusion: Unlocking Efficient Data Extraction with the Best Image Crawler
Visual data is only going to get more important. Whether you’re tracking competitors, fueling your AI models, or just trying to keep your product catalogs up to date, the right image crawler can turn days of manual work into minutes of automation. Tools like Thunderbit are making this power accessible to everyone, not just developers or big enterprises.
Start Scraping Images with Thunderbit
Ready to transform your image extraction workflow? Try Thunderbit for free or explore one of the other top tools on this list. And if you want to dive deeper into web scraping, check out the Thunderbit Blog for more guides, tips, and real-world use cases.
FAQs
1. What is an image crawler and why do businesses need one?
An image crawler is a tool that automatically extracts images (or their URLs) from websites. Businesses use image crawlers to gather product photos, monitor competitors, fuel AI models, and streamline content operations—saving time and improving data quality.
2. How does Thunderbit make image extraction easier than other tools?
Thunderbit uses AI to auto-detect images and other fields, so you can set up a scrape in just two clicks—no code or technical setup required. It can also crawl subpages, handle dynamic content, and export data directly to Excel, Sheets, Notion, or Airtable.
3. Can I use these tools if I don’t have any coding experience?
Absolutely. Thunderbit, Octoparse, and ParseHub are all designed for non-coders, offering visual interfaces and AI-powered features. Scrapy is best for those with Python skills, while Content Grabber is aimed at enterprise IT teams.
4. What should I consider when choosing an image crawler?
Think about your technical skills, the complexity of your target sites (dynamic content, logins, etc.), the volume of data you need, and how you want to export or integrate the results. Also consider pricing—some tools are free, while others are enterprise-grade.
5. Is it legal to scrape images from any website?
Always check the website’s terms of service and respect copyright laws. Only scrape publicly available data, and avoid collecting personal or sensitive information without permission. Responsible, ethical scraping is key to staying compliant and avoiding legal issues.
Want to see Thunderbit in action? Download the Chrome extension and try scraping images from your favorite site. And if you have questions or want more scraping tips, swing by the Thunderbit Blog for the latest guides and insights.
Lear More Best 10 Free Website Crawler Online Options for 2025 Top 10 Automated Web Scraping Tools in 2025 Top 12 Free Data Scraper Tools in 2025 Top 10 AI Web Scraper Tools to Enhance Productivity in 2025
Try Thunderbit AI Image Scraper Get Started Free




