
Executive summary
We pulled the robots.txt file of every domain in the Tranco top 10,000 list of the world's highest-traffic websites. We then parsed each one with an RFC 9309–compliant parser, classified the file by what AI bot policy (if any) the site has adopted, and counted how many of the world's most-visited sites actually try to block ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence, and the other crawlers that train and serve large language models in 2026.
The headline numbers, on a sample of 7,248 sites whose robots.txt we could read cleanly:
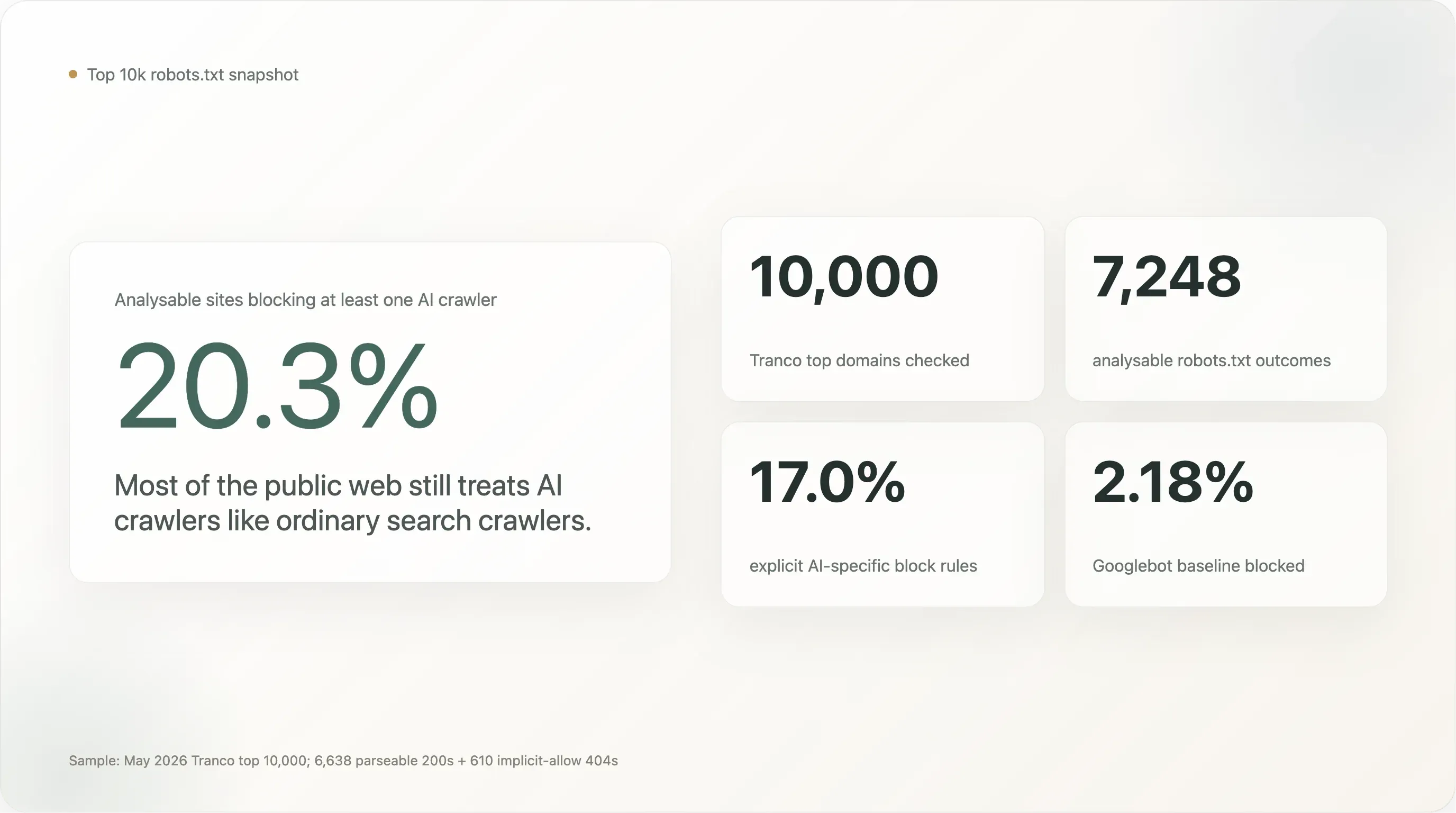
20.3% of the world's top 10,000 sites block at least one AI crawler. 17.0% have written an explicit, AI-specific rule on purpose. The remaining 80% leave AI crawlers as welcome as Googlebot.
Six findings that change the shape of the story:
- News organisations are at 47% blocking — the highest of any sector. German news leads at 88%, French at 80%, Russian at 0%. The legal regime, not technology or industry economics, is the primary driver.
CCBot(Common Crawl) is the most-blocked bot at 16.3% — ahead ofGPTBot(15.8%) andBytespider(14.9%). Publishers target the training corpus, not the model brand. The most-adopted selective rule is "blockCCBot, allowGooglebot" (14.1% of sites).- France leads every country at 50.6% AI-blocking on
.frsites; the EU cluster is 16 points above the global baseline. 275robots.txtfiles explicitly cite EU Directive 2019/790. Article 4 is the only legal regime visibly moving the numbers. - 17.8% wrote their own AI rules; 4.5% run Cloudflare's vendor template; 75.7% say nothing. Big sites self-author; the long tail uses the toggle. The Atlantic and
cloudflare.comitself are on the Cloudflare Managed list. - 108 sites explicitly Allow
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Security and dev tooling are over-represented. - AI policy doesn't get more aggressive at the head of the curve. Top 100, 101–1000, 1001–5000, 5001–10000 all sit between 19% and 23%. The headline rate is a property of the public web in 2026, not a signal of how big any individual site is.
The story is no longer about whether the web is "fighting back." It's about which industries, which countries, which legal regimes, and which AI vendors are the targets of active policy — and which ones are not.
I. Background: how robots.txt became an AI policy artifact
Three forces have reshaped what robots.txt means since OpenAI shipped GPTBot in August 2023.
AI vendors multiplied. Google's Google-Extended, Anthropic's ClaudeBot, ByteDance's Bytespider, Apple's Applebot-Extended, Amazon's Amazonbot, Meta's Meta-ExternalAgent all followed. Common Crawl's existing CCBot became the single highest-leverage block target because its archive feeds most open-weight models. Non-vendor bots appeared too: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. A comprehensive 2026 block list runs to ~25 names.
Article 4 of the EU Copyright Directive 2019/790 created a statutory text-and-data-mining exception that does not apply if the rightsholder has "expressly reserved" their rights in a "machine-readable" way. Throughout 2024–2025 EU publishers and their lawyers settled on robots.txt as the canonical way to express that reservation. Our dataset shows 275 sites cite Directive 2019/790 explicitly and 87 mention "TDM" — concentrated on European news sites where it sits as a 4–8 line legal preamble.
Cloudflare productized the toggle. In 2024–2025 Cloudflare shipped an "AI Audit" dashboard, a "Block AI Bots" toggle, and a Managed robots.txt template with Content-Signal: search=yes,ai-train=no vocabulary plus EU 2019/790 boilerplate. By May 2026 the template runs on 4.5% of the parseable top 10k. Cloudflare's roadmap publicly discusses making the toggle default-on for new accounts — which would move the global block rate by 5–8 points without any individual publisher making a decision.
robots.txt in 2026 is no longer the unglamorous configuration file it was in 2022. It's a copyright-reservation mechanism with treaty backing in the EU, a vendor-shaped policy artifact in the long tail, and the front line of a slow-moving negotiation between the people who run websites and the people who train models.
II. Methodology
We tried to make this as boring and reproducible as possible. The full pipeline (Python scripts, parsed CSVs, raw robots.txt archive, charts) is published with this report.
Sample
We started with the Tranco list as of May 2026, downloaded as top-1m.csv.zip, and sliced the first 10,000 rows. Tranco aggregates four upstream rankings (Cisco Umbrella, Majestic, Farsight, and Cloudflare Radar), filters for stability over a 30-day window, and removes obvious crawler/CDN noise. The list it produces is the closest thing to a canonical "global web traffic top-10k" that exists in the open, and it is the standard sample for academic web research (used in 600+ peer-reviewed papers since its launch by KU Leuven in 2018).
The list contains a mix of (a) primary websites people visit, (b) infrastructure / API / DNS / CDN apex domains that serve no /, and (c) domains used internally by big platforms (e.g. gvt1.com, apple-dns.net, googleusercontent.com). Rather than pre-filter these, we kept them all and tagged them with an infrastructure category in the analysis layer. They drop out naturally when we restrict to "sites that returned a parseable robots.txt."
Fetching
For each of the 10,000 domains we issued an asynchronous GET /robots.txt over HTTPS, with a fallback to HTTP, redirects followed up to four hops, a 12-second total timeout, a 500 KB body cap, and a real-browser User-Agent string with Accept-Language: en-US. Concurrency was held at 80 requests in flight. The job ran from a single residential IP in San Francisco.
The fetch outcome:
| Status | Count | Interpretation |
|---|---|---|
200 OK | 6,638 | robots.txt body returned and parseable. |
404 Not Found | 610 | No robots.txt exists. RFC 9309 defines this as implicit "allow everything." |
403 Forbidden | 563 | Origin actively rejects robots.txt requests. Excluded from analysis. |
429 Too Many Requests | 7 | Almost no CDN-level throttling at this rank tier. |
fetch_failed (TLS / DNS / TCP error) | 2,065 | Mostly CDN apex domains (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) that don't run a webserver on /. Not "blocked" — they have no robots.txt to serve. |
| Other 4xx/5xx | 117 | Mixed — server errors, geofencing, malformed responses. |
This gives us 7,248 sites in the analysable sample (6,638 200 + 610 404). The 2,065 fetch_failed are real domains, but they're CDN/DNS apex points, not sites people visit, and treating them as having an "AI policy" makes no sense. They sit in the dataset as a separate accessibility statistic.
Parsing
Every 200 body was parsed with protego, a Python implementation of RFC 9309 used in production by Scrapy. For each (site, bot) pair we computed three things:
can_fetch_root— whether the bot is allowed to fetch/, with the standard's group-of-records semantics, longest-match rule precedence, and the override ofUser-agent: *by a specific bot block when both exist.has_specific_rule— whether the file contains aUser-agent:line that names this exact bot (case-insensitive).disallow_count— how manyDisallow:directives are in the matching block, used to distinguish full sitewide bans from path-level restrictions.
The combination matters because a top-line "block rate" hides two completely different phenomena: brands that intentionally wrote User-agent: GPTBot \n Disallow: / because they decided to push back, and brands whose generic User-agent: * \n Disallow: / block (set up for staging or maintenance reasons years ago) happens to also forbid every AI bot that didn't pre-exist in their template. Throughout this report the "any AI block" number includes both kinds; the "explicit AI block" number is the deliberate subset.
Bots in scope
We tracked 25 bots, grouped into three categories:
- AI training crawlers (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - AI inference / live retrieval bots (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(which serves both training and inference),YouBot,DuckAssistBot. - Search baseline (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
A few bots straddle the training/inference line. ClaudeBot is the most prominent — Anthropic deprecated the older anthropic-ai UA in 2024 and now uses ClaudeBot for both training and live retrieval, so a Disallow: ClaudeBot rule no longer cleanly maps to "block training but keep visibility." We've left the assignment as it is and called out the consequence later.
Industry classification
We classified each domain into one of 16 industry buckets (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) using a layered approach:
- Known-domain dictionary — a hand-curated map of ~500 high-traffic domains to industries.
- TLD / suffix patterns —
.gov→gov,.eduand.ac.*→academia, recognized CDN suffixes →infrastructure. - Domain-name keywords — news, post, shop, bank, porn, casino etc. as fallback signals.
- Homepage scrape — for sites the first three layers couldn't classify and that returned a
robots.txt200, we fetched the homepage HTML, extracted<title>,<meta name="description">,<meta property="og:type">, and ran a keyword scoring against language-model-style category cues.
This produced 3,407 sites (34%) with confident industry tags and 6,593 left as unknown. The unknown bucket is dominated by non-English regional portals, corporate .com brand sites that don't fit any single bucket, and small-language-market traditional publishers we didn't have dictionary entries for. Where this report quotes a per-industry percentage, the denominator is the classified sample for that industry, not the full 10,000.
III. Findings
Finding 1 — One in five top-traffic sites blocks at least one AI bot
Across the 7,248 analysable sites, 1,472 (20.31%) block at least one AI bot. 1,230 (16.97%) have a deliberate AI-specific rule. The Googlebot baseline is 2.18% (158 sites — most of them either blocked everything as a maintenance default or, in three cases, are search engines blocking competitors).
The headline 20% is 9× the Googlebot baseline. That's a real signal — top-traffic sites are an order of magnitude more likely to block an AI crawler than a search crawler — but it's also a substantially smaller number than the "AI blocking is reaching universal adoption" narrative that has been running in the press since 2024. Even on the most-visited 10,000 sites of the web, the 5-out-of-6 majority is silent on AI.
The split between "any AI block" (20.3%) and "explicit AI block" (17.0%) is small in absolute terms but conceptually important. The 3.3-point gap is the share of sites that block AI bots only because their existing User-agent: * \n Disallow: / rule catches everything that walks past, including bots that didn't exist when the rule was written. The 17.0% deliberate number is the cleaner read on "how many of the world's biggest websites have made an AI-specific decision."
Set against prior literature:
| Source | Date | Sample | Block rate |
|---|---|---|---|
| Originality.ai | Mar 2025 | 1,000 most-popular news (English) | 35.7% block GPTBot |
| Palewire | Aug 2024 | 1,500 news organisations | 36.0% any AI crawler |
| Reuters Institute | Spring 2025 | 50 leading news brands, 10 countries | 78% any AI crawler |
| WIRED / NYT | Late 2023 | Top 50 US news | 26% block GPTBot |
| This report (Thunderbit) | May 2026 | Tranco top 10,000 (all sectors) | 20.3% / 17.0% explicit |
Our 17.0% explicit is lower than every news-only study because two-thirds of our sample isn't news. Restricted to the 650 news sites we get 47% — within the same band as the prior studies once you account for sample composition. The structural picture is consistent: the news cohort blocks AI at 3–4× the rate of the rest of the web.
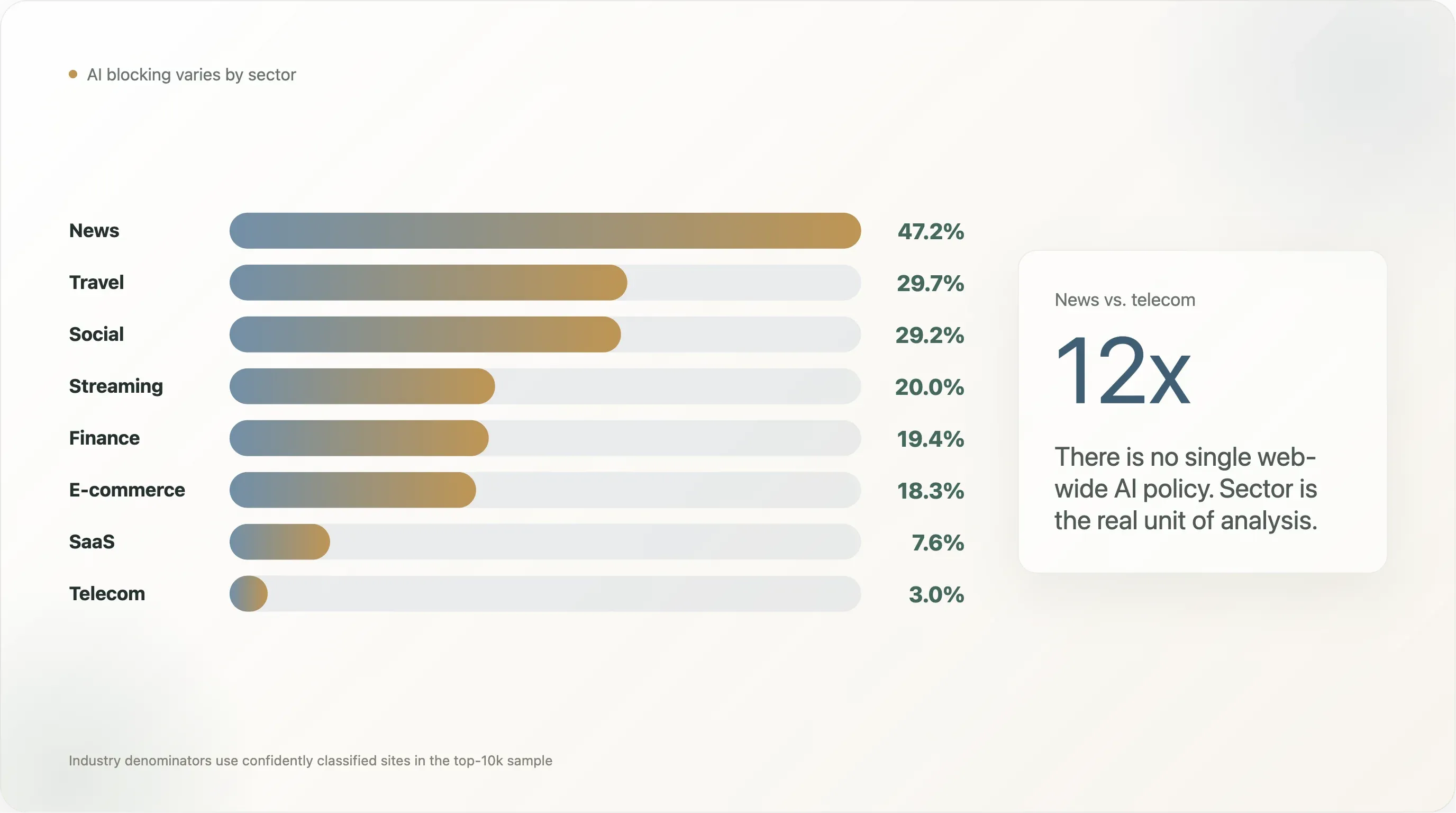
Finding 2 — Industry deep dives: a 12× spread from news to telecom
The single most-cited finding in two years of "AI scraping" coverage has been the 80% of news outlets block GPTBot number from Originality.ai and Palewire. Our cut produces a smaller but still distinctive figure: 47.2% of news sites in the top 10,000 block at least one AI bot, with 45.2% writing an explicit AI rule.
But "news vs everything else" is too coarse. The full breakdown (industries with n ≥ 10 in the sample) tells a much richer story:
| Industry | n | Any AI block | Explicit | Googlebot blocked | DIY rules | Cloudflare Managed | Silent |
|---|---|---|---|---|---|---|---|
| News | 650 | 47.2% | 45.2% | 1.5% | 46.9% | 1.5% | 48.5% |
| Travel | 64 | 29.7% | 29.7% | 0.0% | 35.9% | 3.1% | 54.7% |
| Social | 65 | 29.2% | 23.1% | 4.6% | 23.1% | 6.2% | 66.2% |
| Streaming | 440 | 20.0% | 17.7% | 0.7% | 16.8% | 3.6% | 75.5% |
| Finance | 129 | 19.4% | 12.4% | 0.8% | 14.7% | 2.3% | 75.2% |
| E-commerce | 224 | 18.3% | 17.4% | 0.4% | 24.1% | 1.3% | 66.1% |
| Adult | 254 | 17.3% | 14.6% | 0.4% | 10.2% | 7.9% | 79.5% |
| Search | 12 | 16.7% | 0.0% | 0.0% | 0.0% | 0.0% | 100.0% |
| Academia | 268 | 14.6% | 13.8% | 0.4% | 13.4% | 3.4% | 77.2% |
| Gambling | 100 | 14.0% | 13.0% | 0.0% | 18.0% | 4.0% | 77.0% |
| Dev tools | 129 | 10.1% | 7.8% | 0.0% | 8.5% | 5.4% | 77.5% |
| SaaS | 369 | 7.6% | 6.2% | 0.3% | 9.5% | 0.8% | 87.5% |
| Government | 172 | 5.2% | 3.5% | 0.0% | 4.1% | 0.6% | 83.1% |
| Infrastructure | 47 | 4.3% | 0.0% | 0.0% | 4.3% | 2.1% | 72.3% |
| Telecom | 33 | 3.0% | 3.0% | 0.0% | 12.1% | 0.0% | 78.8% |
The 12× spread between news and telecom is what makes "the web's AI policy" the wrong unit of analysis. There isn't one number; there are sectoral numbers that diverge by an order of magnitude. We walk through the four most distinctive findings below.
News: 47% blocking, 47% DIY. News is the cohort that wrote the playbook. Cloudflare Managed runs at only 1.5% in news — these publishers do not outsource the rule. The text is unusually rich: the NYT opens with a 14-line legal preamble citing "Art. 4 of the EU Directive"; the BBC with "Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human."; The Sun with "The Sun does not permit the unlicensed use of our content for large language models." This is robots.txt as policy statement, not configuration.
Travel at 30% — the surprise. Booking, Expedia, TripAdvisor, Kayak, and the major airlines block at two-thirds the news rate. The selective pattern is consistent: average travel blocker disallows 5–7 training UAs but leaves inference UAs (PerplexityBot, ChatGPT-User, OAI-SearchBot) untouched. Aggregated pricing and review data is the moat; citations back to the site are the upside. This is the cleanest "training out, inference in" pattern in any single industry.
Adult at 17% — also a surprise. Earlier smaller samples showed 0%. The full-sample data has 1-in-6 adult sites disallowing at least one AI bot, with the highest Cloudflare Managed rate of any sector (7.9%). More than half of adult sites' AI blocks come from the Cloudflare toggle, not a publisher decision. Image-generation training is the implicit threat — StableDiffusion-class models learn visual style faster than text models learn writing style.
SaaS at 7.6% is counterintuitive. Software vendors are the loudest segment in AI-policy discourse but their robots.txt is wide open. The right reading: SaaS marketing teams have correctly identified AI search as a distribution channel. The vendors who have actually thought about it are opting in, not out — the explicit-Allow-GPTBot list (Finding 12) is dominated by security and dev-tooling SaaS.
Government 5.2%, telecom 3.0%, infrastructure 4.3%, dev 10.1%. Public-records mandates make Disallow: / legally fraught for .gov. Telecom marketing sites want discoverability. CDN apex domains have nothing to protect. Dev tooling explicitly opts in (its content gains value when LLMs cite it).
The takeaway: there is no single "the web is/isn't blocking AI" number that doesn't lose more than it conveys. Sector-level reporting is the only honest way to discuss the data.
Finding 3 — Per AI vendor: who is being blocked the most?
The other natural cut of the data is by AI company rather than by bot. Several vendors run multiple bots (OpenAI runs three: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic runs two: ClaudeBot, anthropic-ai; Meta runs two: Meta-ExternalAgent, FacebookBot). Aggregating to the vendor level is the closest we can get to "what does the public web think about each AI company?"
| AI vendor | Bots aggregated | Sites blocking ≥ 1 bot | % of analysable |
|---|---|---|---|
| Common Crawl | CCBot | 1,178 | 16.25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1,172 | 16.17% |
| Anthropic | ClaudeBot, anthropic-ai | 1,111 | 15.33% |
| ByteDance | Bytespider | 1,082 | 14.93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13.65% |
Google-Extended | 970 | 13.38% | |
| Amazon | Amazonbot | 877 | 12.10% |
| Apple | Applebot-Extended | 859 | 11.85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10.09% |
| Cohere | cohere-ai | 717 | 9.89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9.86% |
| Diffbot | Diffbot | 684 | 9.44% |
| You.com | YouBot | 563 | 7.77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6.72% |
| DuckDuckGo | DuckAssistBot | 482 | 6.65% |
Common Crawl is the single most-targeted entity even though it's a non-profit web archive, not an LLM operator. The reason is leverage: CCBot feeds almost every open-weight model and a substantial share of closed ones. Blocking CCBot first is the highest-coverage rule a publisher can write.
OpenAI, Anthropic, ByteDance cluster at 14–16%. OpenAI's lead is partly a counting artifact (three OpenAI bots vs a single bot for ByteDance). Bytespider's 14.9% is the "Bytespider behaviour" effect — it has been documented ignoring robots.txt since 2024, and publishers block it as a public signal, not because they're worried about TikTok.
Meta, Google, Amazon, Apple at 12–14% are the second tier — written defensively rather than as a position statement. Minor vendors (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) at 6–10% are mostly pulled up by the 3.8% catch-all floor; explicit rules for them are in the 1–4% range.
xAI (Grok), Mistral, and most European/Chinese model labs are missing from the table — they haven't published documented training-crawler UAs. The current robots.txt ecosystem is a dialogue between US/Chinese vendors who shipped UAs and US/EU publishers who wrote rules; vendors who didn't ship are invisible to the negotiation.
Finding 4 — CCBot is the new lightning rod, not GPTBot
The bot ordering on top-10k looks like this:
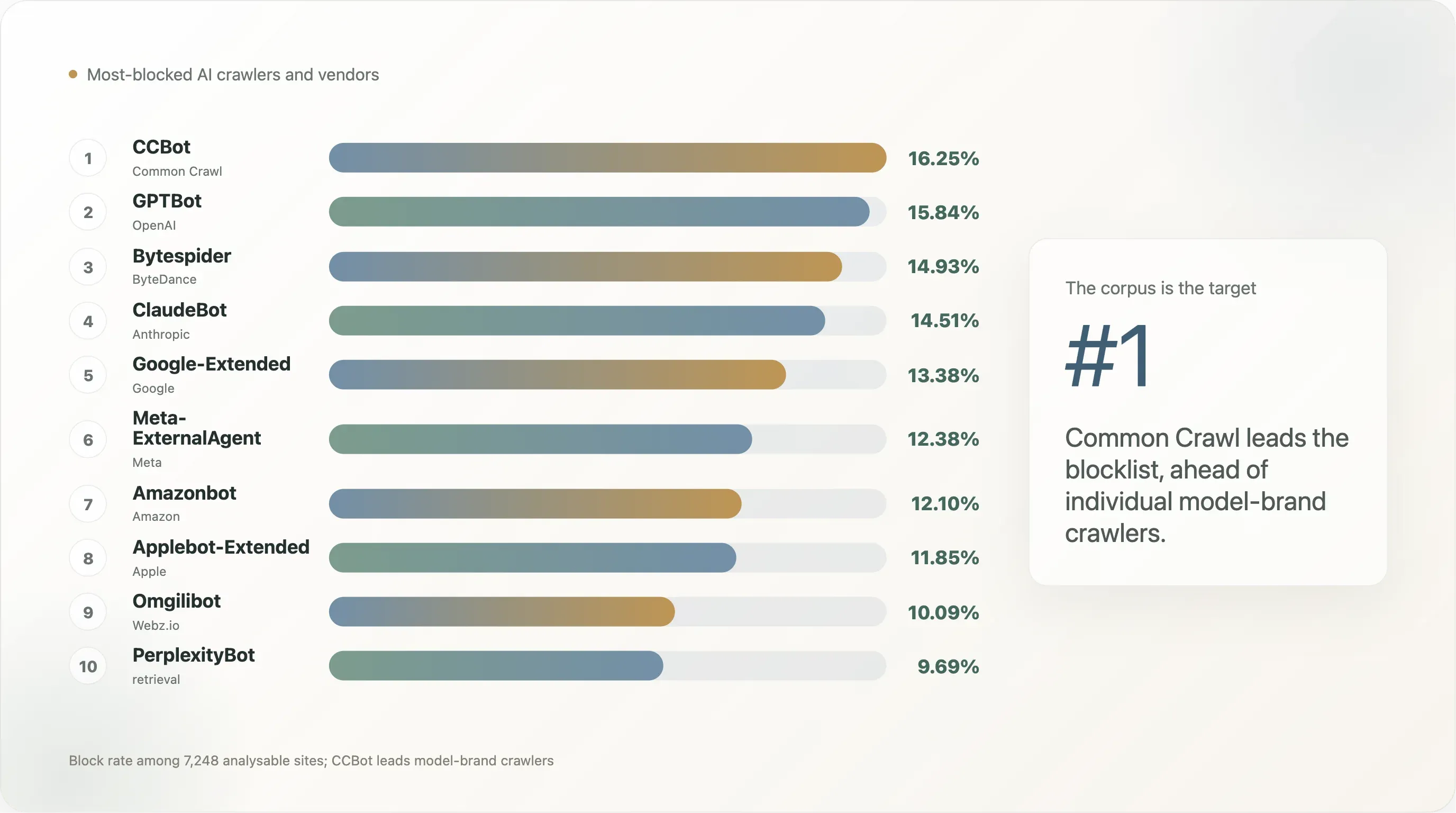
| Rank | Bot | Block rate | Explicit-rule rate |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16.25% | 12.90% |
| 2 | GPTBot (OpenAI) | 15.84% | 12.72% |
| 3 | Bytespider (ByteDance) | 14.93% | 11.35% |
| 4 | ClaudeBot (Anthropic) | 14.51% | 11.13% |
| 5 | Google-Extended | 13.38% | 10.18% |
| 6 | Meta-ExternalAgent | 12.38% | 8.95% |
| 7 | Amazonbot | 12.10% | 8.66% |
| 8 | Applebot-Extended | 11.85% | 8.72% |
| 9 | Omgilibot | 10.09% | 5.31% |
| 10 | anthropic-ai (deprecated) | 9.99% | 6.55% |
| 11 | cohere-ai | 9.89% | 6.42% |
| 12 | PerplexityBot | 9.69% | 6.40% |
| 13 | Diffbot | 9.44% | 5.95% |
| 14 | ChatGPT-User (inference) | 8.90% | 5.73% |
| 15 | YouBot (inference) | 7.77% | 4.29% |
| 16 | OAI-SearchBot (inference) | 6.83% | 3.66% |
| baseline | Googlebot | 2.18% | — |
| baseline | Bingbot | 2.27% | — |
The story this table tells is that the bot the public web blocks first is not the model brand — it's the corpus. Common Crawl's 250-billion-page archive has been the single largest training input to GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM, and most open-weight models released since 2020. A site that wants to opt out of "being in the next frontier model" optimizes by disallowing CCBot first — once you're not in Common Crawl, you're effectively excluded from the open-source training pipeline for free. GPTBot and ClaudeBot come second and third because they're the visible front-end of two specific commercial products; the corpus-level UA is the structural target.
The lower-ranked AI bots in the table are also informative. Omgilibot at 10% is unusually high for a bot most readers won't have heard of — it's run by Webz.io, a content-data broker that sells web archives to LLM operators, and a sizable cohort of news organisations have started naming it explicitly in their files. AI2Bot at 6.7% (and a corresponding Ai2Bot-Dolma rule on Squarespace sites) suggests that the academic LLM community is also getting flagged by publishers who don't necessarily distinguish "non-profit research crawler" from "commercial crawler."
The inference cluster — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — sits 4–8 percentage points below the training cluster. That gap is the answer to a long-running policy question: yes, top-traffic sites distinguish between a bot collecting data for future model training and a bot doing live retrieval to answer a user's question right now. They don't always make the distinction (the catch-all rules don't), but a meaningful share write rules that target the training side specifically.
Finding 5 — 14% block CCBot while keeping Googlebot welcome — the "block the corpus, keep the search" pattern
The selective rule that has the most adoption on the top-10k:
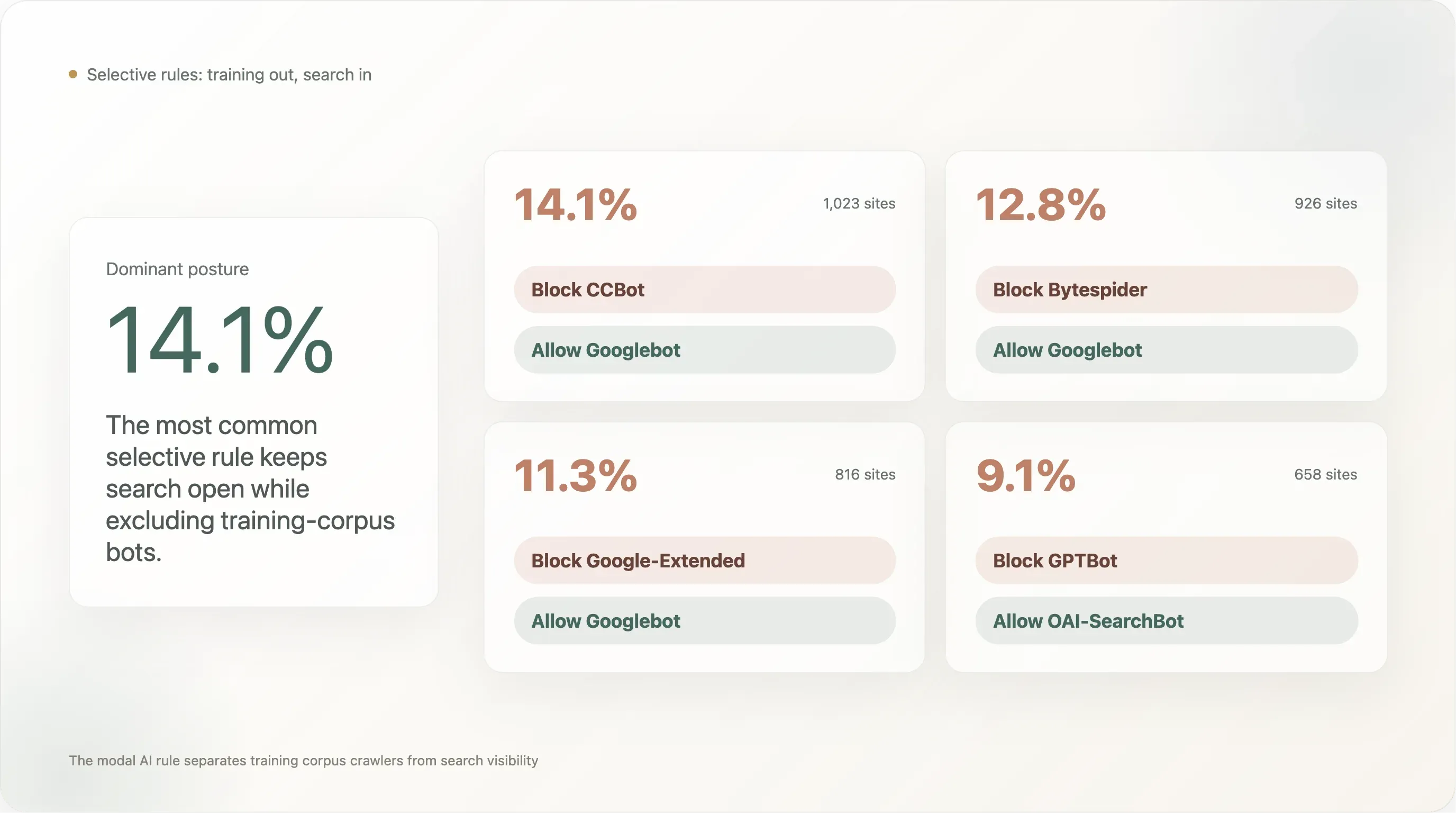
| Rule pattern | Sites | % of analysable |
|---|---|---|
Block CCBot, allow Googlebot | 1,023 | 14.11% |
Block Bytespider, allow Googlebot | 926 | 12.78% |
Block Google-Extended, allow Googlebot | 816 | 11.26% |
Block GPTBot, allow OAI-SearchBot | 658 | 9.08% |
Block GPTBot, allow ChatGPT-User | 525 | 7.24% |
Block CCBot, allow PerplexityBot | 519 | 7.16% |
Block anthropic-ai, allow ClaudeBot | 59 | 0.81% |
The most-adopted pattern (14.1%) is "block Common Crawl, keep Google search visibility." The runner-up (12.8%) is "block Bytespider, keep Google search visibility" — i.e. block ByteDance's reputation-flagged crawler while leaving the legitimate search baseline intact. Third (11.3%) is "block Google's own AI-training UA while keeping Google's search UA," which is exactly the split Google designed Google-Extended for: the publisher opts out of Bard / Gemini training without losing search ranking.
These three numbers together describe the dominant policy posture on the top-10k web: disallow the training-corpus bots, leave the search and inference bots untouched. The minority pattern of "disallow training but allow this LLM's specific live-retrieval UA" — GPTBot ✗ / ChatGPT-User ✓ at 7.2% — exists, but it's smaller than the corpus-level cuts.
The anthropic-ai / ClaudeBot row at 0.81% reflects Anthropic's 2024 UA deprecation: ClaudeBot now serves both training and inference, eliminating the clean "block training, allow citation" expression for Claude that the old anthropic-ai UA permitted. This is the most under-discussed UA-design decision of 2024–2025 — it removed an entire class of policy expression from robots.txt.
Finding 6 — News in detail: by country and language
When we slice the news category by country-code TLD — keeping in mind that this means .de for German news, .fr for French news etc., not the language served — the within-news variance is bigger than the variance between news and the rest:
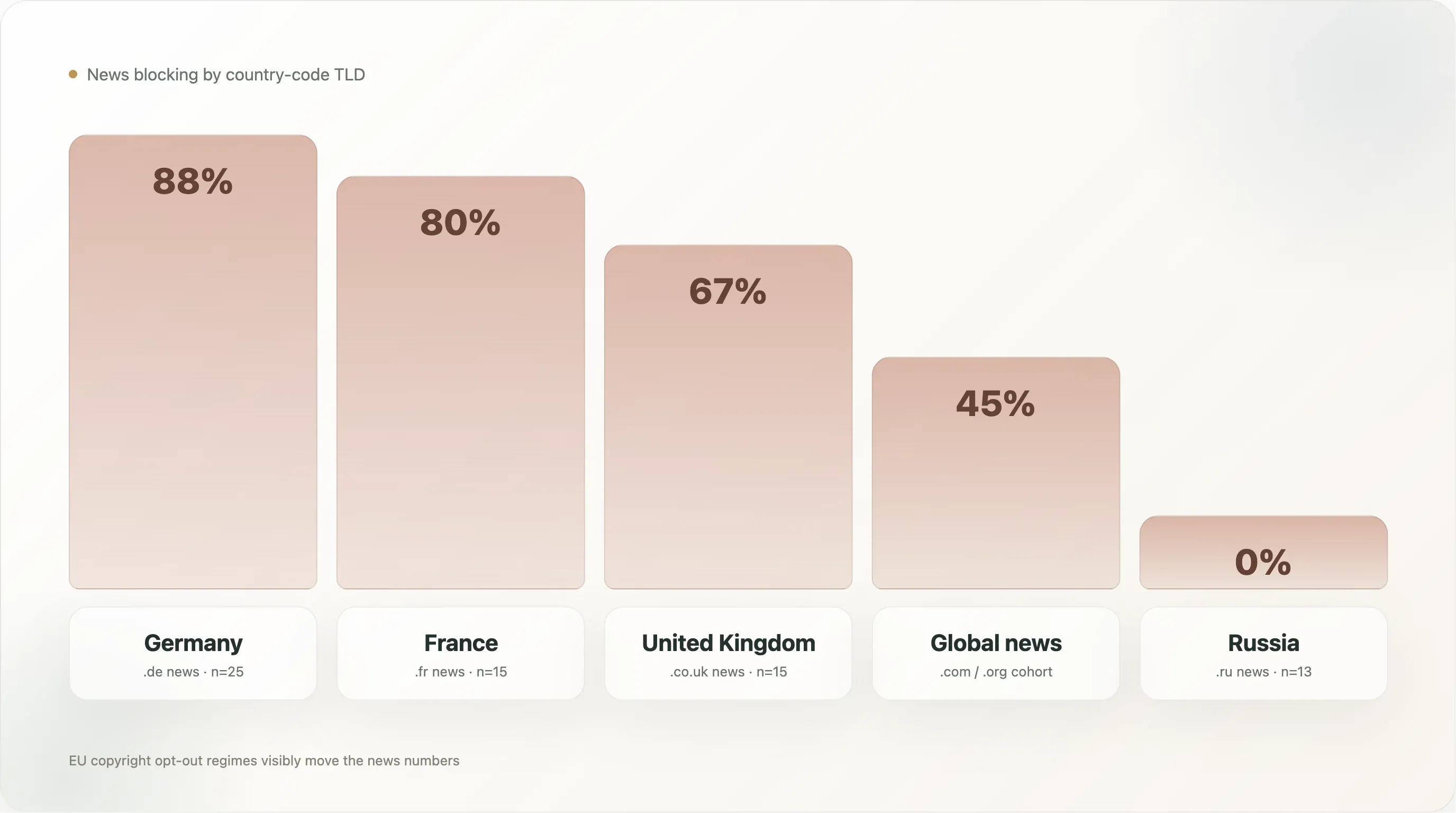
| Country (news only) | n | Any AI block | Explicit |
|---|---|---|---|
🇩🇪 Germany (.de) | 25 | 88.0% | 88.0% |
🇫🇷 France (.fr) | 15 | 80.0% | 80.0% |
🇬🇧 United Kingdom (.co.uk) | 15 | 66.7% | 53.3% |
🇪🇸 Spain (.es) | 5 | 60.0% | 60.0% |
🇮🇹 Italy (.it) | 13 | 53.8% | 53.8% |
Global news (.com/.org/etc) | 500 | 45.0% | 42.8% |
🇵🇱 Poland (.pl) | 7 | 42.9% | 42.9% |
🇯🇵 Japan (.jp) | 12 | 25.0% | 25.0% |
🇷🇺 Russia (.ru) | 13 | 0.0% | 0.0% |
🇬🇷 Greece (.gr) | 6 | 0.0% | 0.0% |
German news is the highest-blocking sub-segment in the entire dataset at 88%, and it's 88% explicit — there is essentially no German news site in the top 10k that lets AI training crawlers reach its archive. The cohort is led by Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — the entire mainstream German publishing establishment, plus tech publishers who wrote rules independently. The political infrastructure under this is dense: VG Media, the German publishers' collective rights organization, has been the most aggressive plaintiff cohort in EU AI-copyright litigation, and Article 4 of the EU Directive is implemented in German law as §44b UrhG with explicit machine-readable opt-out language. By the time AI vendors arrived, German publishers were the most prepared of any national cohort to translate that legal posture into robots.txt rules.
French news at 80% is just below. The French legal environment is similar (Directive 2019/790 transposed into French law), and the cohort behaviour is similar — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr all block, with the Le Monde file additionally citing French droit du producteur de base de données (Article L 342-1 of the Code de la propriété intellectuelle) as a parallel domestic legal basis. France has the additional wrinkle of a 2024 ruling from the Paris commercial court holding that robots.txt-based opt-outs are sufficient notice under Article 4; this provides direct case-law backing that no other jurisdiction has yet matched.
The UK at 67% is lower, and the reason is that several major UK publishers (thesun.co.uk, dailymail.co.uk, mirror.co.uk) use User-agent: * deny-all blocks rather than AI-specific rules, which pulls the explicit number down to 53%. The aggregate effect is the same — these sites don't allow AI crawling — but the policy is expressed as "no robots except this specific allowlist of search engines" rather than as named-AI-bot disallows. The legal scaffolding is also weaker: post-Brexit, the UK inherited Article 4 logic but the corresponding domestic case law is thinner.
Russian news at 0% is the most surprising row. Thirteen Russian-domain news sites in the sample (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, etc.) — none of them block any AI crawler. The likely explanation: Russian-language LLM training is dominated by Yandex's own GPT-style models (which use Yandex-internal crawlers, not Common Crawl), the Russian copyright environment hasn't picked up an Article 4 equivalent, and the major Russian publishers see Western LLMs as a non-issue (US export controls already limit OpenAI/Anthropic services in Russia) and Yandex as a domestic stakeholder rather than an adversary. The policy posture is straightforwardly different.
Japanese news at 25% is a third pattern. Japan has explicit text-and-data-mining exceptions in domestic copyright law (Article 30-4 of the Japanese Copyright Act, amended in 2018) that are more permissive than Article 4 of the EU Directive — they allow TDM for "non-enjoyment" purposes including AI training without requiring rightsholder consent. Japanese publishers have less legal traction for opt-out and the corresponding robots.txt rates are lower. The 25% that do block are mostly the largest, most-cosmopolitan publishers (asahi.com, nikkei.com) who are positioned as international rather than domestic.
The cross-country news data is the cleanest evidence in the report that the legal regime, not technology or industry economics, is the primary driver of AI blocking. EU news cohorts cluster between 54% and 88%; non-EU news cohorts (Russia, Japan, the global .com cohort) range from 0% to 45%. The 88% peak is in the country with the most-developed Article 4 implementation; the 0% floor is in the country with effectively no AI-policy law at all.
Finding 7 — EU vs the rest: a 16-point gap
Pulling the country lens up one level, the broad EU-vs-rest split is sharp:
| Region | n | Any AI block | Explicit |
|---|---|---|---|
EU ccTLDs (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35.2% | 33.9% |
Non-EU national ccTLDs (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17.2% | 13.6% |
Global (.com, .net, .org, etc.) | 5,734 | 19.2% | 15.7% |
EU ccTLD sites block AI at twice the rate of the non-EU national cohort and almost twice the rate of the global .com baseline. The difference is consistent across EU member states (no single country drives the average) and consistent across industries (.de news at 88%, .de SaaS at ~12%, .de e-commerce at ~25% — all higher than their global counterparts).
We found 275 robots.txt files in the top-10k that explicitly cite Directive 2019/790 in their comments — about 3.8% of the parseable sample. The cohort is dominated by EU publishers but extends beyond them: several US news brands (notably NYT, which cites "Art. 4 of the EU Directive" directly), some UK sites, and a handful of larger European e-commerce destinations all reproduce the legal language. 87 files mention "TDM" or "text and data mining" by name. 460 files contain some form of copyright-reservation language ("expressly opts out," "all rights reserved," "no commercial use," "no machine learning") even where they don't cite a specific statute.
Two more granular observations from this slice:
The EU effect is not just news. When we hold news constant, EU non-news sites still block AI at higher rates than non-EU non-news sites (roughly 28% vs 14%). A small but real share of EU SaaS, e-commerce, and academia has internalized the Article 4 frame for their own sectors.
The EU-flavored language is becoming a de facto template even outside the EU. The Cloudflare Managed robots.txt template — adopted globally — explicitly cites "ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790" in its boilerplate. A US site that toggles on Cloudflare's "Block AI Bots" setting is, without necessarily knowing it, asserting an EU statutory reservation of rights. This is one of the more interesting policy-drift artifacts we found: a European legal concept is being globalized through a US infrastructure provider's product UI.
Finding 8 — Templates and template origins
The template-origin breakdown of the 6,638 sites that returned a parseable robots.txt:
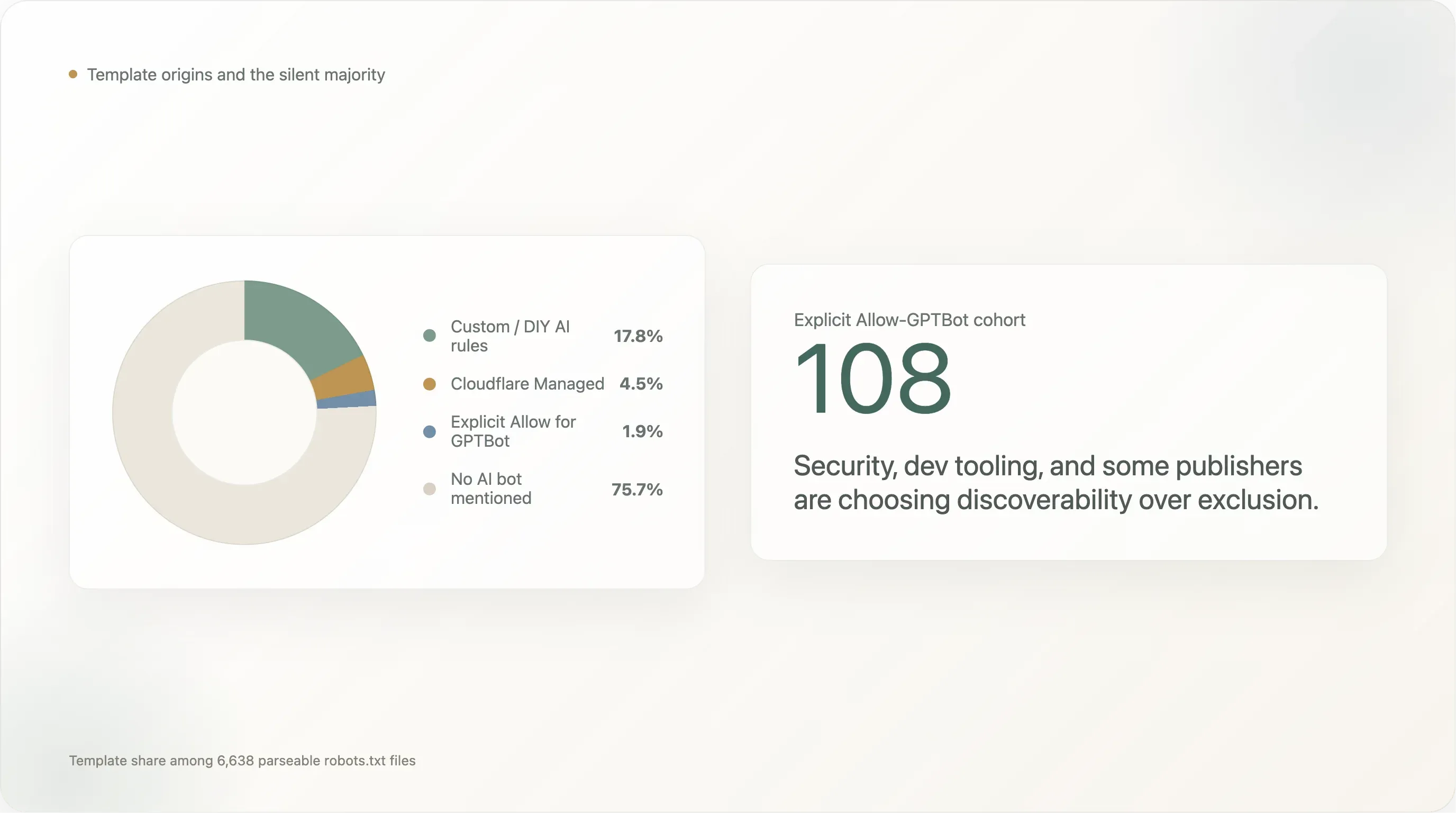
| Template | Sites | Share |
|---|---|---|
| No AI bot mentioned (default Shopify-style, Yoast, hand-written without AI consideration) | 5,024 | 75.7% |
| Custom / DIY AI rules | 1,183 | 17.8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4.5% |
Explicit Allow: / for GPTBot | 124 | 1.9% |
| Squarespace default (28 AI UAs in the path-restricted block) | 5 | 0.1% |
DIY rules dominate at 17.8%. The cohort of self-authored blockers is led by every social-media platform (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com itself), the largest e-commerce destinations (amazon.com, amazonvideo.com), the major news brands (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), key streaming / media (netflix.com, vimeo.com, soundcloud.com, imdb.com), and a long tail of professional-services sites (canva.com, medium.com).
Cloudflare Managed sits at 4.5% — much higher than the same template's penetration in the very head of the curve and lower than its penetration in the long tail outside this report's window. The template is most adopted in the rank-1001-to-10000 segment (4–5%) and is essentially absent from the very top of the curve (Top 100: 1 site uses it; Top 101–1000: 5 sites). The big global properties write their own rules; the long tail uses the toggle.
A few specific Cloudflare Managed sites of note. cloudflare.com itself runs the template, which is consistent (Cloudflare is dogfooding its own product on its own domain). theatlantic.com runs the template — the only major US news brand we found that didn't write a custom rule. spankbang.com runs the template — the highest-ranked adult site to adopt a Cloudflare-injected AI block. linktr.ee runs the template, blocking AI training across the entire Linktree-hosted creator economy in a single vendor decision. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com, and a long list of smaller media properties round out the visible Cloudflare Managed cohort.
The Cloudflare adoption pattern is the most concrete evidence we've seen that a large share of "the web's AI policy" is being decided by infrastructure providers. The absolute share is small (4.5%) but it's structurally important: the template is the default Cloudflare ships, and the on-by-default trajectory for the next 12 months is upward. If Cloudflare flips the toggle to default-on for new accounts, the global block rate moves materially without any individual publisher making a decision.
The Squarespace default (5 sites in the top-10k, but a much larger cohort outside our sample) is a different pattern: Squarespace ships a robots.txt that names 28 AI bots in a single block, but those bots inherit the path restrictions of User-agent: * rather than getting a sitewide ban. AI crawlers can fetch /, the homepage, the product pages, the blog. They just can't fetch /config or /account. We've previously flagged this as the source of false-positive "AI block" readings in third-party scans of Squarespace sites; the same caveat applies here.
Finding 9 — AI policy is uniform across the rank distribution
The conventional intuition for this kind of study is that the most-visited sites would have the most aggressive AI policy — they have the most to lose from training displacement, the most legal capacity, the most public scrutiny. The data doesn't support that intuition.
| Rank bucket | n | Any AI block | Explicit | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22.4% | 17.9% | 1 site |
| Top 101–1,000 | 598 | 22.9% | 19.2% | 5 sites |
| Top 1,001–5,000 | 2,810 | 19.0% | 15.3% | 99 sites |
| Top 5,001–10,000 | 3,773 | 20.8% | 17.8% | 197 sites |
The four buckets sit between 19% and 23%. The Top 100 is no more aggressive than the rank-5001-to-10000 long tail. The headline rate appears to be a property of the public web in 2026, not a signal of how big or how prominent any individual site is.
Two contributing factors. First, the head of the curve is dominated by infrastructure / SaaS / search / portal domains (Microsoft, Apple, Google, etc.) that have low AI-blocking rates in their own right. Second, the long tail includes a high share of regional news publishers and EU-jurisdiction sites that — as Finding 6 and 7 showed — block AI more aggressively than the global average. The two effects roughly cancel, and the net is a uniform headline.
The Cloudflare Managed column does shift across the curve. The Top 1000 has 6 Cloudflare-managed sites (1.0%); the Top 1001–10000 has 296 (5.7%). The big sites self-author; the long tail uses the vendor toggle. This is the only meaningful rank-dependent signal in the dataset, and it suggests that as you walk down the traffic curve from the top of the web toward the long tail, the share of AI policy that's vendor-set rather than publisher-set rises steadily. We expect this gradient to continue past the top 10k into the top 100k and beyond.
Finding 10 — Five anatomies: what robots.txt looks like when it's actually a policy
Numbers describe the shape of the dataset; the actual character of "AI policy on the public web" is best seen by reading specific files. Here are five worth dwelling on, picked to span the policy space.
Anatomy 1 — The New York Times (nytimes.com)
The first 14 lines of nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.This is robots.txt as legal exhibit. The file is structured to be admissible as evidence in the NYT v. OpenAI litigation it's a party to. The references to "Art. 4 of the EU Directive" — by a US publisher — illustrate Finding 7's observation that EU statutory frames are leaking into the global discourse. The explicit prohibition on "creating or providing archived or cached data sets" is aimed squarely at Common Crawl. The file is 60+ lines long with named User-agent blocks for GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot, and a half-dozen others — every named bot has its own Disallow: /.
Anatomy 2 — Der Spiegel (spiegel.de) — section-level AI permissioning
Der Spiegel is the most operationally sophisticated robots.txt we found in the entire dataset. The relevant block:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /The comment translates as "Test-wise enablement of OpenAI search crawlers for selected sections." Spiegel has whitelisted seven specific content categories — international news, partnerships, health, family, travel, psychology, and lifestyle — for OpenAI's inference UAs while blocking everything else. The political sections, the German national news, and the investigative reporting are explicitly excluded. Common Crawl, Bytespider, Cohere, Webzio-Extended, and the other training UAs are given full Disallow: / further down the file.
This is robots.txt as section-level editorial policy. The implicit theory is that lifestyle content has lower training-displacement risk and higher inference-citation upside, so Spiegel permits AI to surface those sections; political and investigative content are the moat, so AI is excluded. We have not seen this pattern elsewhere. It implies a level of internal coordination between editorial, legal, and infrastructure teams that most newsrooms haven't reached. We expect this kind of granular, section-level policy expression to spread through 2026–2027 — Spiegel's file is essentially a leading indicator.
Anatomy 3 — BBC (bbc.com) — the policy statement form
The BBC robots.txt opens with:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.The BBC version-strings its robots.txt (the # version: ec59bd... is a git commit hash), prohibits the eight specific kinds of AI use that the BBC's lawyers are tracking, and ends with a one-line summary in the prose voice the BBC's brand is built on. The phrase "expressly opts out of any statutory exceptions in any jurisdiction" is a deliberate global reservation — it's saying we don't trust any single legal regime to give us the protection we want, so we're asserting opt-out everywhere at once. This is the most-drafted robots.txt in the dataset, and it reads more like a press release than a configuration file.
Anatomy 4 — WordPress.org — the explicit welcome
Compare all of the above to wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org explicitly opts in to nine AI training crawlers, including the three (Bytespider, CCBot, anthropic-ai) that are most often blocked elsewhere. The implicit theory is that the WordPress documentation and plugin ecosystem is a public good whose value increases when AI assistants can answer questions about it. Every time someone asks Claude "how do I configure permalinks in WordPress?" and Claude has been trained on wordpress.org/documentation/, the WordPress mission has been served. The Foundation appears to have decided that being inside every model's training corpus is a strategic positive, and they've used the file's expressive grammar to say so.
Anatomy 5 — The Verge (theverge.com) — the sponsored hybrid
One more pattern worth showing. The Verge structures their AI rules as Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/The /sp/ path is The Verge's sponsored / partner content section. Editorial content is blocked from AI training; sponsored content is permitted. The economic logic is clean: sponsors pay for their content to be discoverable, including through AI; the editorial flagship is the moat. GPTBot is fully open (presumably as a direct OpenAI relationship), Applebot is fully open as a search baseline, and the rest get the hybrid treatment. This is the only "tiered AI access" structure of its kind we found.
These five files describe the present range of robots.txt AI policy. Most files in the top 10k look like none of them — they're either silent or use a vendor template. The ones that look like one of these are written by people who have decided the file is worth reading carefully.
A note on file scale: the median robots.txt body in our sample is 858 bytes — too small to encode a meaningful AI policy. The right tail is where the rules live: 1,005 sites (15.3%) have a file larger than 5 KB, 273 larger than 20 KB, and the maximum was 248 KB. 460 files contain copyright-reservation language; 275 cite EU 2019/790 by name. A robots.txt in 2026 is increasingly a versioned, lawyer-reviewed document, not a configuration line.
Finding 11 — 108 sites explicitly welcome GPTBot
A small but visible cohort writes a User-agent: GPTBot \n Allow: / rule — the inverse of the more-discussed "Disallow GPTBot." The full count in our sample is 108 sites with an explicit Allow for GPTBot at the root path. The first 25 by Tranco rank:
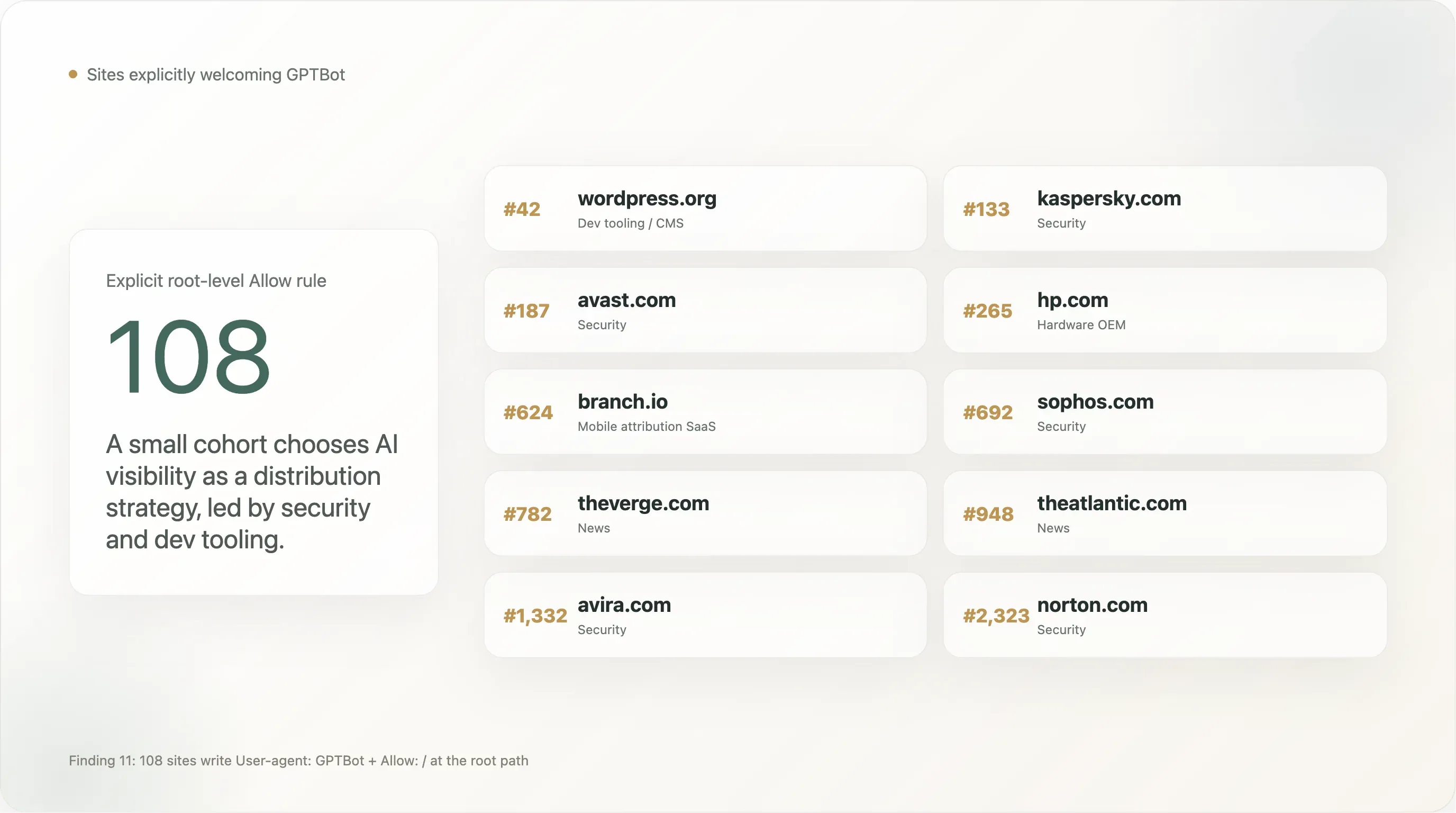
| Rank | Domain | Sector |
|---|---|---|
| 42 | wordpress.org | Dev tooling / CMS |
| 133 | kaspersky.com | Security |
| 187 | avast.com | Security |
| 265 | hp.com | Hardware OEM |
| 624 | branch.io | Mobile attribution SaaS |
| 692 | sophos.com | Security |
| 782 | theverge.com | News |
| 905 | rambler.ru | Russian portal |
| 945 | kleinanzeigen.de | German marketplace |
| 948 | theatlantic.com | News |
| 1,092 | lge.com | LG Electronics |
| 1,300 | justdial.com | Indian local search |
| 1,332 | avira.com | Security |
| 1,412 | youm7.com | Egyptian news |
| 1,530 | goodreturns.in | Indian finance |
| 1,621 | publi24.ro | Romanian classifieds |
| 1,807 | geocomply.com | Compliance SaaS |
| 1,908 | nba.com | Sports |
| 1,956 | oneindia.com | Indian news |
| 1,974 | mindbox.ru | Russian SaaS |
| 2,009 | thesun.co.uk | News |
| 2,126 | vox.com | News |
| 2,140 | mgid.com | Native advertising |
| 2,314 | ninjarmm.com | IT management SaaS |
| 2,323 | norton.com | Security |
A few patterns:
Security companies are conspicuously over-represented. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM all explicitly allow GPTBot. This is a deliberate distribution play: when a user asks ChatGPT "what's the best antivirus for my Windows machine?", having the brand inside the model's training corpus directly affects the recommendation. Security is one of the few B2C product categories where AI search is already replacing SEO as a primary acquisition channel, and these brands have moved first. We expect the rest of the security cohort to follow within 12 months.
Some major news brands are on this list, not the blocklist. The Verge, The Atlantic, Vox, The Sun, NBA.com. This is not a contradiction — these publishers appear to have decided that being citable inside ChatGPT search is more valuable than being protected from training, and they wrote the explicit Allow rule to defend against future over-blocking by their CDN or CMS. Compare to the NYT / Reuters / BBC / Forbes / Guardian posture of explicit Disallow. Both stances are defensible; the news industry is not monolithic.
The Sun's presence is notable because the same site uses a User-agent: * deny-all elsewhere in its file. The Sun's policy is best read as "AI training is forbidden, AI search is permitted, and we have explicitly whitelisted GPTBot as an exception to the deny-all to make sure ChatGPT can answer questions citing The Sun." This is the most legally sophisticated of the GPTBot-Allow rules — it's an opt-out plus a single-vendor opt-in.
WordPress.org's presence is the most consequential single entry on the list. A non-trivial share of the global open-source CMS ecosystem either points to WordPress.org for documentation or hosts plugins from there. By explicitly allowing GPTBot at wordpress.org/robots.txt, the WordPress Foundation has effectively said the WordPress documentation ecosystem is open for training — which has knock-on effects for how well Claude, Gemini, and ChatGPT can answer "how do I..." questions about WordPress.
The remaining 83 sites in the full Allow-GPTBot list are a long tail of regional news, smaller security vendors, classifieds platforms in non-English markets, and B2B SaaS. There is, as far as we can tell, no equivalent industry-wide "Allow-GPTBot" coordination — the rule is being adopted one site at a time, by operators who have decided that being in the corpus is the strategic position.
Finding 12 — llms.txt is barely a rumor at this scale
llms.txt, the proposed alternative file format for LLM-friendly content discovery (championed by Mintlify, Anthropic, Vercel, and a handful of dev-tooling vendors since late 2024), has visible adoption almost nowhere in our sample.
Of the 6,638 sites that returned a parseable robots.txt, 83 (1.15%) mention llms.txt — typically as a Sitemap: https://example.com/llms.txt line. That's two orders of magnitude lower than the same metric measured on dev-tooling-heavy commerce samples where Vercel and Mintlify defaults inflate adoption.
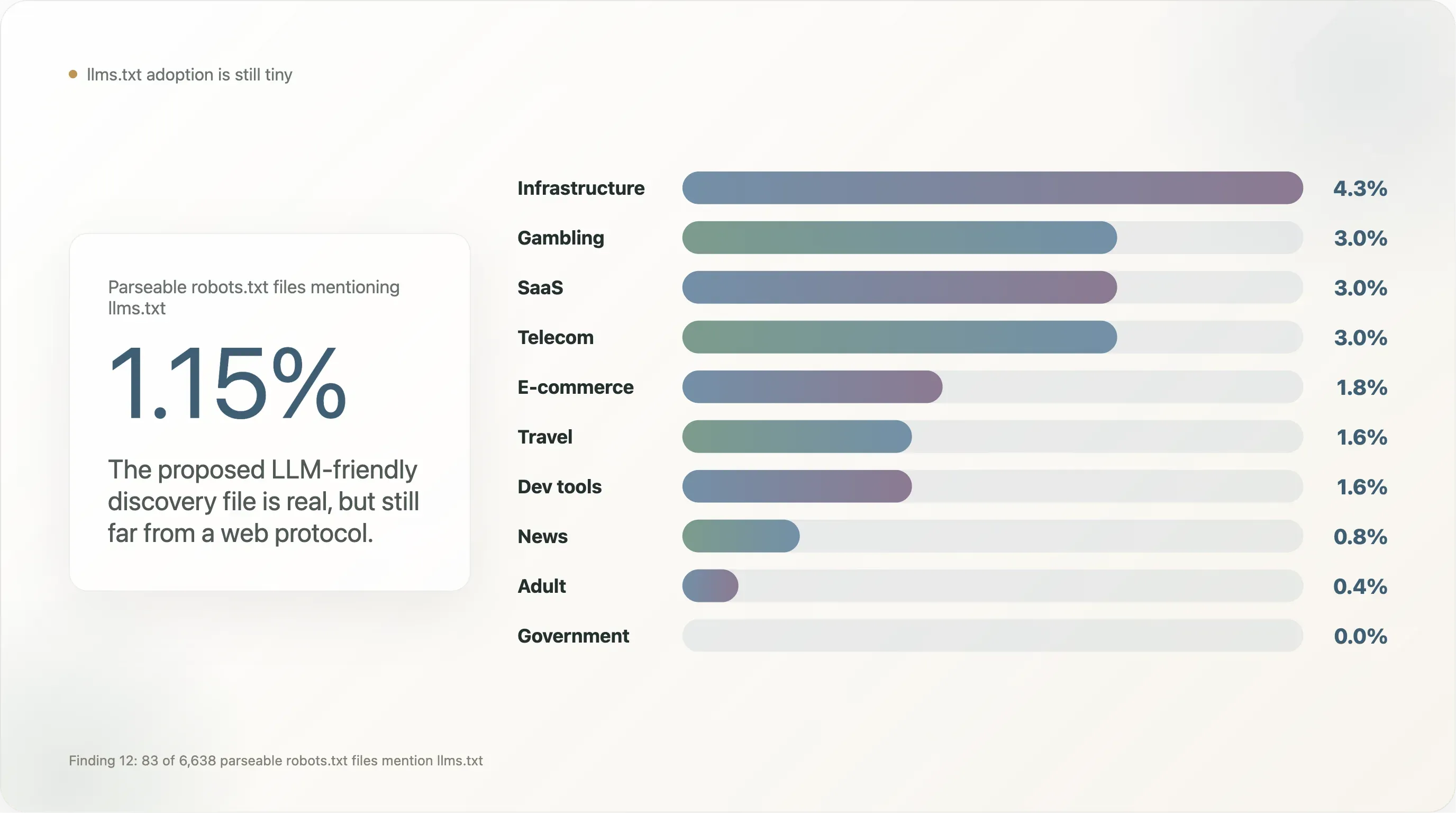
The category breakdown:
| Industry | n | % mentioning llms.txt |
|---|---|---|
| Infrastructure | 47 | 4.3% |
| Gambling | 100 | 3.0% |
| SaaS | 369 | 3.0% |
| Telecom | 33 | 3.0% |
| E-commerce | 224 | 1.8% |
| Travel | 64 | 1.6% |
| Dev tools | 129 | 1.6% |
| News | 650 | 0.8% |
| Adult | 254 | 0.4% |
| Government | 172 | 0.0% |
| Academia | 268 | 0.0% |
| Search | 12 | 0.0% |
llms.txt is concentrated in dev-tooling-adjacent SaaS, gambling (which adopts new-vocabulary robots.txt features faster than other regulated industries because it has compliance teams accustomed to layering extra metadata), and B2B e-commerce. It is conspicuously absent from news and government — the two segments most engaged with AI policy and whose adoption would be required for the standard to graduate from "vendor experiment" to "web protocol." Until then, llms.txt is real but small, and a follow-up audit in late 2026 will be a useful retest.
The structural problem llms.txt faces is that it isn't standardized by any IETF process and the major AI vendors haven't committed to honour it. A robots.txt rule has 30 years of crawler infrastructure built around it; an llms.txt rule has none. Until at least one major vendor (OpenAI, Anthropic, Google, Cloudflare) declares formal support, the file is essentially a marketing artifact of the Mintlify / Vercel ecosystem. We don't expect that to change in 2026.
Finding 13 — Accessibility: robots.txt is still readable for two-thirds of the top web
A side observation that wasn't supposed to be a finding: 66% of the top 10,000 sites returned a parseable robots.txt to a single research IP, and only 7 out of 10,000 (0.07%) returned 429 Too Many Requests. This is good news for robots.txt-as-public-protocol.
For comparison, the same pipeline run on a 1,008-domain mid-market commerce sample two months earlier received 429 from 52% of resolved domains — Shopify and Cloudflare CDNs aggressively rate-limiting any non-major-search-engine UA. The top-traffic web is much friendlier: top sites are more likely to have either (a) less aggressive bot-management tiers, or (b) explicit allowlists for known research crawlers, or both.
The 21% fetch_failed rate on the top-10k is dominated by CDN apex domains (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) that don't run a webserver on /. They aren't blocking us; they have nothing to serve. Excluding those, the genuine "tried to read but couldn't" failure rate is in the low single digits.
This means future iterations of this report — quarterly snapshots, year-over-year comparisons — can be run cheaply and reproducibly on a single machine. The audit window stays open at the top of the curve. The asymmetric case is the long tail and the commerce segment, where CDN-level throttling has effectively privatised robots.txt already. We expect this divergence to widen: top sites will remain readable because they're indexed by search engines that demand readability; long-tail commerce will become less readable as Cloudflare's bot-fight tiers ship more aggressively. Public auditability of robots.txt is bifurcating along the same line that separates "the visible web" from "the operationally-protected web."
IV. What this all means
Four claims, in order of how strongly the data supports them.
1. The internet has a per-industry, not a global, AI policy. The 12× spread between news and telecom dominates every aggregate number. Reporting "X% of the web blocks AI" without a sectoral cut overstates SaaS/government/dev and understates news/travel/social. Sector-by-sector is the only honest framing.
2. Article 4 of the EU Copyright Directive is the only legal regime visibly moving the numbers. EU ccTLD sites block at 35% vs the global 19% baseline. The US litigation (NYT v. OpenAI, Copyright Office's January 2025 report) has shifted the US news cohort but not the broader US web. The EU framing is also leaking globally through Cloudflare's template, which cites Directive 2019/790 in its boilerplate regardless of the customer's jurisdiction.
3. Two parallel "AI policies" are being expressed and they don't agree with each other. The deliberate, hand-written policy (17.8%, mostly news/social/travel/e-commerce) and the inherited Cloudflare-managed policy (4.5%) overlap on substance but differ on legitimacy. In a world where AI operators are looking for legal cover to ignore robots.txt, the "we wrote and reviewed it" defense is structurally stronger than "I just toggled it on." The litigation incentive is to drive policy from the second category into the first.
4. The corpus, not the model, is what publishers are blocking. CCBot at 16.3% — higher than any model-brand bot — is the cleanest statement of this. Disallowing OpenAI doesn't get a publisher out of being trained-on; disallowing CCBot does. 14.1% of the top-10k web blocks CCBot while keeping Googlebot welcome. The "block training, keep search" pattern is the modal AI rule in 2026.
For sites considering their own posture: the median posture is silence — 80% of the top 10k say nothing about AI. The 17% that write rules cluster on Disallow, but a small, growing cohort (the 1.5% explicit-Allow-GPTBot list, led by security vendors) is publicly choosing the inverse. There is no industry consensus and there won't be one in the next twelve months.
For AI operators: continuing to argue that robots.txt is a legacy protocol with ambiguous semantics is increasingly hard to sustain when 17% of the world's biggest sites have written explicit deliberate rules naming bots by hand, and 3.8% of files cite specific EU statute by section number. Whether to honor those rules is a business decision; whether they exist is now an empirical fact.
V. Outlook: what we expect by end-2026
Three trajectories visible in the dataset:
Cloudflare Managed will more than double its share, plausibly reaching 10%+ of the parseable top-10k. Cloudflare's roadmap publicly discusses default-on Block AI Bots for new accounts. If the toggle ships default-on, the global block rate moves up 5–8 percentage points without any publisher making a decision. We'll know this is happening when the rank-5001-to-10000 bucket's Cloudflare Managed share rises above its current 5.7%.
Section-level AI policies (Spiegel-style) will spread among the major news flagships. The economic logic — let AI cite low-stakes content, protect the moat content — is compelling enough that we expect at least 10 more flagship newsrooms to ship section-level rules by end-2026. Watch the German and French mid-tier press first; the legal framework rewards experimentation there.
The explicit-Allow-GPTBot cohort will grow, led by B2B SaaS and dev tooling. When AI search becomes a measurable acquisition channel for software vendors (as it already is for security), the marginal CMO will write User-agent: GPTBot \n Allow: / to inoculate against accidental over-blocking. We expect the 108-site list to roughly double by year-end.
What we don't expect: a meaningful change in the silent-majority share. The 80% of the web that says nothing about AI includes sectors (gov, telecom, infrastructure, B2B SaaS) with no economic reason to write a rule and no legal pressure to do so. Universal AI policy is not coming.
VI. Limitations
- One-snapshot bias. Fetches happened over a 36-hour window in early May 2026. The file changes daily on the top 100; expect 1–2 percentage-point drift per quarter on the headline numbers.
- Industry classification gaps. 6,593 of 10,000 sites stayed
unknownafter the four-layer classifier. Per-industry percentages are robust where n is large (news: 650, streaming: 440, saas: 369, academia: 268, adult: 254, ecommerce: 224, gov: 172, finance: 129, dev: 129) and noisier below n=30. The country news cut is similarly limited — DE/FR/UK have n≥15, Korea/Sweden/Czechia rest on n=20–25. robots.txtis voluntary. ADisallowis a request, not a barrier.Bytespider,PerplexityBot, and others have been documented ignoring rules. We measured policy declarations, not policy enforcement.- Single-IP, US-based audit. We couldn't read 21% of resolved domains. Most are CDN apex points with no webserver; a small share are sites whose CDN flagged us before reaching origin. This biases the sample slightly toward older infrastructure and against geofenced-by-country-of-origin sites.
- Tranco list semantics. Tranco filters for stability; it isn't a true user-behavior ranking. Aggregate numbers are robust to list choice; specific rank positions are not.
- No traffic data. We measured
robots.txtpolicy, not actual AI bot throughput. Policy and traffic don't always agree.
VII. Reproduce this
Everything used to produce this report is in the deliverable folder.
- tranco_top10k.csv — input list
- out/sites.csv — domain × rank × industry × language × robots.txt status (10,000 rows)
- out/fetch_meta.csv — fetch outcome per domain (status, scheme, bytes, error)
- out/bot_status.csv — domain × bot grid (250,000 rows: blocked, has_rule, fetch_status)
- out/site_meta.csv — one analytical record per site (template, summary booleans)
- out/analysis.json — every metric quoted in the report
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — full Python pipeline
Methodology corrections, dataset issues, and follow-up analyses welcome at support@thunderbit.com. This report is published independent of any commercial position Thunderbit holds; we build an AI-powered web scraper, and we have a structural interest in robots.txt continuing to be a meaningful, machine-readable contract on the public web. The data in this report stands on its own. — The Thunderbit research team, May 2026.