

دعني أعود بك إلى وقت ليس ببعيد: أنا جالس على مكتبي، أرتشف قهوتي، وأحدّق في جدول بيانات أكثر فراغًا من ثلاجتي ليلة الأحد. فريق المبيعات يريد بيانات تسعير المنافسين، وفريق التسويق يريد عملاء محتملين جدد، وفريق العمليات يريد قوائم المنتجات من عشرات المواقع — وكل ذلك كان مطلوبًا بالأمس. أعرف أن البيانات موجودة هناك، لكن الوصول إليها؟ هذه هي العقدة الحقيقية. إذا سبق أن شعرت وكأنك تلعب لعبة «اضرب الخلد» الرقمية بين النسخ واللصق، فأنت لست وحدك.
نقفز سريعًا إلى اليوم، فالمشهد تغيّر كثيرًا. انتقل استخراج بيانات الويب من مشروع جانبي لمحبي التقنية إلى جزء أساسي من استراتيجية العمل. أصبحت JavaScript وNode.js في الواجهة، وتشغّل كل شيء من السكربتات السريعة إلى خطوط البيانات الكاملة. لكن المشكلة هنا: رغم أن الأدوات أصبحت أقوى من أي وقت مضى، قد يظل منحنى التعلم أشبه بتسلق جبل إيفرست مرتديًا شبشبًا. لذلك، سواء كنت مستخدمًا أعماليًا، أو شغوفًا بالبيانات، أو مجرد شخص سئم الإدخال اليدوي، فهذا الدليل لك. سأفكك المنظومة، وأعرض المكتبات الأساسية، ونقاط الألم، ولماذا يكون القرار الأذكى أحيانًا هو ترك الذكاء الاصطناعي يتولى الجزء الأصعب.
لماذا يهم استخراج بيانات الويب باستخدام JavaScript وNode.js للأعمال
لنبدأ بـ«لماذا». في عام 2026، لم تعد بيانات الويب مجرد ميزة إضافية لطيفة — بل أصبحت عنصرًا أساسيًا في التشغيل. ووفقًا لأبحاث حديثة، فإن 73% من الشركات تنسب إلى بيانات الويب العامة دورًا في تمكين اتخاذ قرارات أسرع وأكثر دقة، كما أن نحو 42% من ميزانيات بيانات المؤسسات تُخصّص الآن لجمع بيانات الويب. أما سوق البيانات البديلة — والذي يشمل استخراج بيانات الويب — فهو بالفعل صناعة بقيمة 4.9 مليار دولار وينمو بسرعة.
فما الذي يغذي هذه الموجة؟ إليك بعض أكثر حالات الاستخدام شيوعًا في الأعمال:
- التسعير التنافسي والتجارة الإلكترونية: تجمع متاجر التجزئة الأسعار والمخزون من مواقع المنافسين، وأحيانًا يؤدي ذلك إلى رفع المبيعات بنسبة 4% أو أكثر.
- توليد العملاء المحتملين وذكاء المبيعات: تؤتمت فرق المبيعات جمع البريد الإلكتروني وأرقام الهاتف وتفاصيل الشركات من الأدلة والمنصات الاجتماعية.
- أبحاث السوق وتجميع المحتوى: يستخرج المحللون الأخبار والمراجعات وبيانات المشاعر لاكتشاف الاتجاهات والتنبؤ بها.
- الإعلانات وتقنيات الإعلان: تتبع شركات تقنيات الإعلان أماكن الظهور والحملات المنافسة في الوقت الفعلي.
- العقارات والسفر: تستخرج الوكالات القوائم والأسعار والمراجعات لتغذية نماذج التقييم وتحليلات السوق.
- مجمّعات المحتوى والبيانات: تجمع المنصات البيانات من مصادر متعددة لتشغيل أدوات المقارنة ولوحات المعلومات.
أصبحت JavaScript وNode.js الخيار المفضل لهذه المهام، خاصة مع اعتماد المزيد من المواقع على المحتوى الديناميكي المُنشأ عبر JavaScript. تتفوق Node.js في العمليات غير المتزامنة، ما يجعلها خيارًا طبيعيًا للاستخراج على نطاق واسع. ومع منظومة نشطة من المكتبات، يمكنك بناء كل شيء من سكربتات سريعة إلى أدوات استخراج متينة وجاهزة للإنتاج.
ما هو استخراج البيانات وكيفية القيام به في 2025 Get Started Free
سير العمل الأساسي: كيف يعمل استخراج بيانات الويب باستخدام JavaScript وNode.js
لنوضح سير العمل المعتاد لاستخراج بيانات الويب. سواء كنت تستخرج بيانات من مدونة بسيطة أو من موقع تجارة إلكترونية يعتمد بكثافة على JavaScript، فالمراحل متشابهة إلى حد كبير:
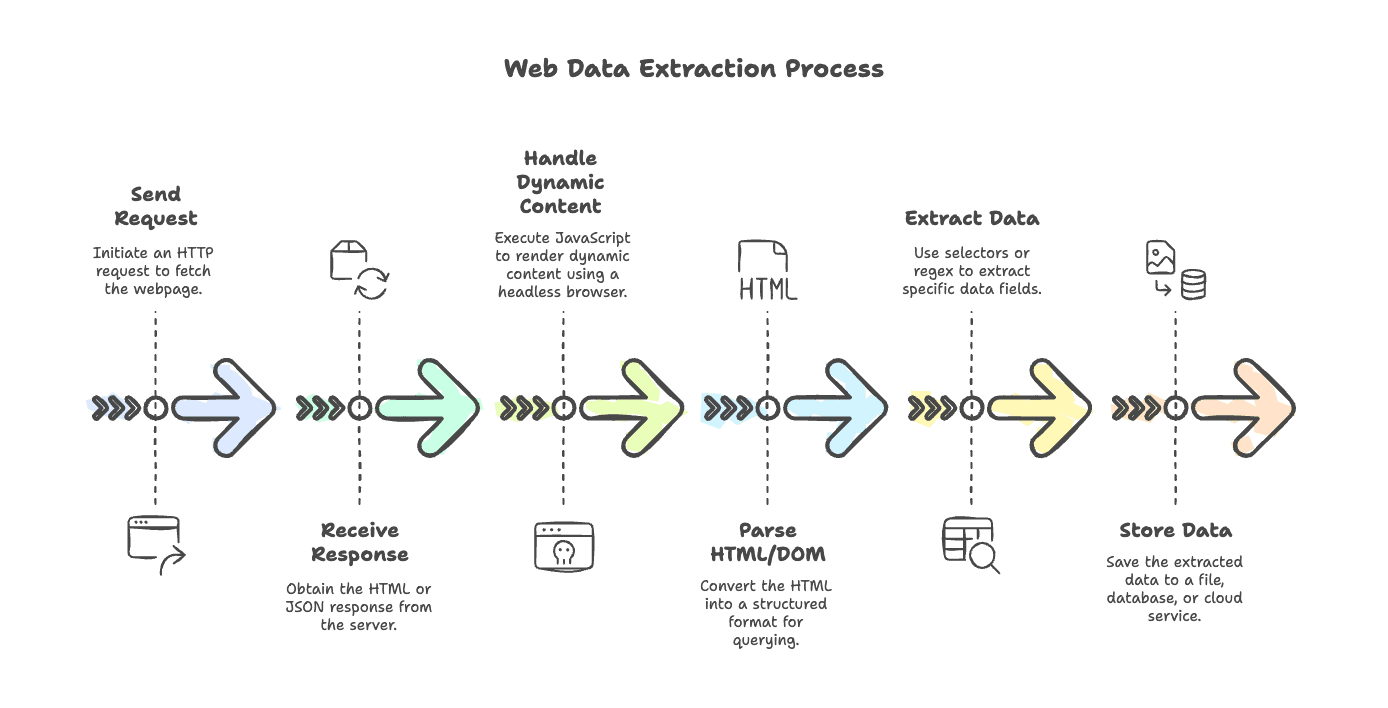
- إرسال الطلب: استخدم عميل HTTP لجلب الصفحة (مثل
axiosأوnode-fetchأوgot). - استقبال الاستجابة: احصل على HTML (وأحيانًا JSON) من الخادم.
- التعامل مع المحتوى الديناميكي: إذا كانت الصفحة تُعرض بواسطة JavaScript، فاستخدم متصفحًا بلا واجهة (مثل Puppeteer أو Playwright) لتنفيذ السكربتات والحصول على المحتوى النهائي.
- تحليل HTML/DOM: استخدم محللًا مثل (
cheerioأوjsdom) لتحويل HTML إلى بنية يمكنك الاستعلام عنها. - استخراج البيانات: استخدم المحددات أو التعبيرات النمطية لسحب الحقول التي تحتاجها.
- تخزين البيانات: احفظ النتائج في ملف أو قاعدة بيانات أو خدمة سحابية.
لكل خطوة أدواتها وأفضل ممارساتها الخاصة، وسنتعمق فيها بعد قليل.
مكتبات طلبات HTTP الأساسية لاستخراج بيانات الويب باستخدام JavaScript
الخطوة الأولى في أي أداة استخراج هي إرسال طلبات HTTP. تمنحك Node.js مجموعة واسعة من الخيارات — بعضها كلاسيكي وبعضها حديث. إليك نظرة على أشهر المكتبات:
1. Axios
عميل HTTP قائم على الوعود لكل من Node والمتصفح. إنه «سكين الجيش السويسري» لمعظم احتياجات الاستخراج.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
المزايا: غني بالميزات، يدعم async/await، وتحليل JSON تلقائيًا، وinterceptors، ودعم البروكسي.
العيوب: أثقل قليلًا، وأحيانًا يبدو «سحريًا» في طريقة تعامله مع البيانات.
2. node-fetch
يطبّق واجهة fetch الخاصة بالمتصفح داخل Node.js. بسيط وحديث.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
المزايا: خفيف، وواجهة مألوفة لمن يأتي من JavaScript الخاصة بالواجهة الأمامية.
العيوب: ميزات أقل، ومعالجة الأخطاء يدوية، وإعداد البروكسي مطوّل.
3. SuperAgent
مكتبة HTTP مخضرمة بواجهة قابلة للتسلسل.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
المزايا: ناضج، يدعم النماذج، ورفع الملفات، والإضافات.
العيوب: تبدو واجهته قديمة قليلًا، واعتماده أكبر حجمًا.
4. Unirest
عميل HTTP بسيط ومحايد من حيث اللغة.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
المزايا: صياغة سهلة، ومناسب للسكربتات السريعة.
العيوب: ميزات أقل، ومجتمع أقل نشاطًا.
5. Got
عميل HTTP سريع ومتين لـ Node.js مع ميزات متقدمة.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
المزايا: سريع، يدعم HTTP/2، وإعادة المحاولة، والبث.
العيوب: يعمل على Node فقط، وقد تبدو واجهته كثيفة بعض الشيء للمبتدئين.
6. http/https المدمج في Node
يمكنك دائمًا العودة إلى الأسلوب القديم:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Response length:', data.length);
});
});
المزايا: بلا تبعيات.
العيوب: مطوّل، يعتمد على callbacks بكثافة، ولا يدعم الوعود.
اطّلع هنا على مقارنة مفصلة للميزات وأمثلة برمجية.
اختيار عميل HTTP المناسب لمشروعك
كيف تختار الأداة المناسبة للمهمة؟ هذا ما أبحث عنه:
- سهولة الاستخدام: Axios وGot ممتازان مع async/await والصياغة النظيفة.
- الأداء: Got وnode-fetch خفيفان وسريعا الاستجابة للاستخراج عالي التوازي.
- دعم البروكسي: يجعل Axios وGot تدوير البروكسيات أمرًا سهلًا.
- معالجة الأخطاء: يطرح Axios أخطاء HTTP افتراضيًا؛ بينما يتطلب node-fetch تحققًا يدويًا.
- المجتمع: لدى Axios وGot مجتمعات نشطة وأمثلة كثيرة.
توصياتي السريعة:
- سكربتات سريعة أو نماذج أولية: node-fetch أو Unirest.
- الاستخراج في بيئة إنتاج: Axios — لميزاته — أو Got — لأدائه.
- أتمتة المتصفح: يتولى Puppeteer أو Playwright الطلبات داخليًا.
تحليل HTML واستخراج البيانات: Cheerio وjsdom وغيرهما
بعد جلب HTML، تحتاج إلى تحويله إلى شيء يمكن التعامل معه فعليًا. هنا يأتي دور المحللات.
Cheerio
تخيّل Cheerio على أنه jQuery للخادم. إنه سريع وخفيف ومثالي لـ HTML الثابت.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
المزايا: سريع جدًا، وواجهة مألوفة، ويتعامل مع HTML المشوّش.
العيوب: لا ينفذ JavaScript — فهو يرى فقط ما هو موجود في HTML.
اعرف المزيد عن سرعة Cheerio وحالات استخدامه.
jsdom
يحاكي jsdom بيئة DOM شبيهة بالمتصفح داخل Node.js. يمكنه تنفيذ سكربتات بسيطة وهو «أقرب للمتصفح» من Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
المزايا: يمكنه تشغيل السكربتات، ويدعم واجهة DOM كاملة.
العيوب: أبطأ وأثقل من Cheerio، وليس متصفحًا كاملًا.
قارن بين Cheerio وjsdom بالتفصيل.
متى تستخدم التعبيرات النمطية أو طرق تحليل أخرى
تشبه التعبيرات النمطية في استخراج بيانات الويب الصلصة الحارة — ممتازة باعتدال، لكن لا تصبّها على كل شيء. تفيد التعبيرات النمطية في:
- استخراج الأنماط من النصوص (البريد الإلكتروني، أرقام الهاتف، الأسعار).
- تنظيف أو التحقق من صحة البيانات المستخرجة.
- سحب البيانات من كتل النصوص أو وسوم السكربت.
مثال: استخراج رقم من نص
const text = "إجمالي المبيعات: 1,234 وحدة";
const match = text.match(/([\d,]+)\s*وحدة/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("عدد الوحدات المباعة:", units);
}
لكن لا تحاول تحليل HTML كامل باستخدام التعبيرات النمطية — استخدم محلل DOM لذلك. المزيد من النصائح حول التعبيرات النمطية للاستخراج.
التعامل مع المواقع الديناميكية: Puppeteer وPlaywright والمتصفحات بلا واجهة
تعشق المواقع الحديثة JavaScript. أحيانًا لا تكون البيانات التي تريدها موجودة في HTML الأولي — بل تُعرض بواسطة السكربتات بعد تحميل الصفحة. هنا يأتي دور المتصفحات بلا واجهة.
Puppeteer
مكتبة من Google لـ Node.js تتحكم في Chrome/Chromium. الأمر أشبه بامتلاك روبوت ينقر ويتنقل داخل الصفحات نيابةً عنك.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
المزايا: عرض كامل عبر Chrome، وواجهة سهلة، وممتاز للمحتوى الديناميكي.
العيوب: يعمل مع Chromium فقط، ويستهلك موارد أكثر.
اقرأ المزيد عن نقاط قوة Puppeteer.
Playwright
مكتبة أحدث من Microsoft، وتدعم Chromium وFirefox وWebKit. إنه أشبه بابن عمّ Puppeteer الأكثر أناقة والمتعدد المتصفحات.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
المزايا: متعدد المتصفحات، وسياقات متوازية، وانتظار تلقائي للعناصر.
العيوب: منحنى تعلمه أعلى قليلًا، وحجم التثبيت أكبر.
لماذا يزداد انتشار Playwright.
Nightmare
أداة أتمتة مبنية على Electron كانت شائعة قبل سنوات. نُقل المستودع إلى منظمة GitHub segment-boneyard — وهي بمثابة موقف مشاريع Segment التي توقفت عن دعمها — وكان آخر إصدار على npm في عام 2019. لا أنصح بالاعتماد عليها في أي مشروع جديد في 2026؛ وإن كنت ترث سكربتًا يستخدمها، فلا بأس، لكن بالنسبة لمشروع جديد، انتقل مباشرة إلى Playwright أو Puppeteer.
مقارنة حلول المتصفحات بلا واجهة
| الجانب | Puppeteer (Chrome) | Playwright (متعدد المتصفحات) | Nightmare (Electron) |
|---|---|---|---|
| دعم المتصفحات | Chrome/Edge | Chrome وFirefox وWebKit | Chrome (قديم) |
| الأداء والنطاق | سريع لكنه ثقيل | سريع، وتوازي أفضل | أبطأ وأقل استقرارًا |
| الاستخراج الديناميكي | ممتاز | ممتاز + ميزات أكثر | جيد للمواقع البسيطة |
| الصيانة | مُصان جيدًا | نشط جدًا | مؤرشف (segment-boneyard، وآخر نشر على npm في 2019) |
| الأفضل لـ | استخراج Chrome | المهام المعقدة ومتعددة المتصفحات | المهام البسيطة والقديمة |
نصيحتي: استخدم Playwright للمشاريع الجديدة والمعقدة. لا يزال Puppeteer ممتازًا لمهام Chrome فقط. أما Nightmare فهي غالبًا للحنين إلى الماضي أو للسكربتات القديمة.
الأدوات المساندة: الجدولة، البيئة، سطر الأوامر، وتخزين البيانات
الأداة الحقيقية لاستخراج البيانات في العالم الواقعي أكثر من مجرد جلب وتحليل. إليك بعض الأدوات المساندة التي أعتمد عليها:
الجدولة: node-cron
جدول أدوات الاستخراج لتعمل تلقائيًا.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('يتم الاستخراج الساعة 9 صباحًا كل يوم اثنين');
});
تُعد Node-cron مثالية لأتمتة المهام المتكررة.
إدارة البيئة: dotenv
احتفظ بالأسرار والإعدادات خارج الكود.
require('dotenv').config();
const apiKey = process.env.API_KEY;
أدوات CLI: chalk وcommander وinquirer
- chalk: تلوين مخرجات وحدة التحكم.
- commander: تحليل خيارات سطر الأوامر.
- inquirer: أسئلة تفاعلية لإدخال المستخدم.
تخزين البيانات
- fs: الكتابة إلى الملفات (JSON وCSV).
- lowdb: قاعدة بيانات JSON خفيفة.
- sqlite3: قاعدة بيانات SQL محلية.
- mongodb: قاعدة بيانات NoSQL للمشاريع الأكبر.
مثال: حفظ البيانات بصيغة JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
نقاط الضعف في استخراج بيانات الويب التقليدي باستخدام JavaScript وNode.js
لنكن صريحين — الاستخراج التقليدي ليس كله ورديًا ومشرقًا. هذه أكبر المتاعب التي رأيتها — وشعرت بها أيضًا:

- منحنى تعلم مرتفع: تحتاج إلى فهم DOM، والمحددات، والمنطق غير المتزامن، وأحيانًا غرائب المتصفحات.
- عبء الصيانة: تتغير المواقع، وتنکسر المحددات، وتجد نفسك تترقع الكود باستمرار.
- ضعف القابلية للتوسع: كل موقع يحتاج إلى سكربت خاص به؛ لا يوجد شيء «يناسب الجميع» حقًا.
- تعقيد تنظيف البيانات: البيانات المستخرجة تكون فوضوية — وتنظيفها وتنسيقها وإزالة التكرار منها عمل بحد ذاته.
- قيود الأداء: أتمتة المتصفح بطيئة وتستهلك موارد كبيرة في المهام الضخمة.
- الحظر وإجراءات مكافحة الروبوتات: تحظر المواقع أدوات الاستخراج، أو تعرض CAPTCHA، أو تخفي البيانات خلف تسجيل الدخول.
- مناطق رمادية قانونية وأخلاقية: عليك التعامل مع شروط الخدمة والخصوصية والامتثال.
اقرأ المزيد عن هذه النقاط والإحصاءات الواقعية.
Thunderbit مقابل استخراج الويب التقليدي: ثورة في الإنتاجية
والآن لنتحدث عن الفيل في الغرفة: ماذا لو استطعت تجاوز كل الكود، وكل المحددات، وكل أعمال الصيانة؟
هنا يأتي دور Thunderbit. وبوصفي الشريك المؤسس والرئيس التنفيذي، فأنا منحاز قليلًا، لكن اسمعني — Thunderbit صُمم لمستخدمي الأعمال الذين يريدون البيانات، لا الصداع.
كيف يقارن Thunderbit
| الجانب | Thunderbit (ذكاء اصطناعي بلا كود) | استخراج JS/Node التقليدي |
|---|---|---|
| الإعداد | خطوتان، بلا كود | كتابة سكربتات وتصحيحها |
| المحتوى الديناميكي | يُعالج داخل المتصفح | برمجة متصفح بلا واجهة |
| الصيانة | الذكاء الاصطناعي يتكيف مع التغييرات | تحديثات يدوية للكود |
| استخراج البيانات | اقتراح الحقول بالذكاء الاصطناعي | محددات يدوية |
| استخراج الصفحات الفرعية | مدمج، بنقرة واحدة | حلقات وكود لكل موقع |
| التصدير | Excel وSheets وNotion | تكامل يدوي مع الملفات/قواعد البيانات |
| المعالجة اللاحقة | تلخيص، ووسم، وتنسيق | كود إضافي أو أدوات إضافية |
| من يمكنه استخدامه | أي شخص لديه متصفح | المطورون فقط |
يقرأ الذكاء الاصطناعي في Thunderbit الصفحة، ويقترح الحقول، ويستخرج البيانات ببضع نقرات فقط. يتعامل مع الصفحات الفرعية، ويتكيف مع تغييرات التخطيط، ويمكنه حتى تلخيص البيانات أو وسمها أو ترجمتها أثناء الاستخراج. يمكنك التصدير إلى Excel أو Google Sheets أو Airtable أو Notion — من دون أي إعداد تقني.
حالات الاستخدام التي يتألق فيها Thunderbit:
- فرق التجارة الإلكترونية التي تتابع SKU وأسعار المنافسين
- فرق المبيعات التي تستخرج العملاء المحتملين ومعلومات الاتصال
- باحثو السوق الذين يجمعون الأخبار أو المراجعات
- وكلاء العقارات الذين يسحبون القوائم وتفاصيل العقارات
في عمليات الاستخراج المتكررة وعالية الأهمية للأعمال، يوفر Thunderbit وقتًا هائلًا. أما في المشاريع المخصصة، أو واسعة النطاق، أو شديدة التكامل، فلا يزال للبرمجة التقليدية مكانها — لكن بالنسبة لمعظم الفرق، فإن Thunderbit هو أسرع طريق من «أحتاج إلى البيانات» إلى «لديّ البيانات».
شاهد إضافة Thunderbit على Chrome أثناء العمل أو اطلع على المزيد من حالات الاستخدام في مدونة Thunderbit.
جرّب أداة Thunderbit لاستخراج بيانات الويب بالذكاء الاصطناعي
مرجع سريع: أشهر مكتبات استخراج بيانات الويب باستخدام JavaScript وNode.js
إليك ورقة الغش الخاصة بمنظومة استخراج البيانات في JavaScript لعام 2026:
طلبات HTTP
- Axios: عميل HTTP قائم على الوعود وغني بالميزات.
- node-fetch: واجهة fetch الخاصة بـ Node.js.
- Got: عميل HTTP سريع ومتقدم.
- SuperAgent: طلبات HTTP ناضجة وقابلة للتسلسل.
- Unirest: عميل بسيط ومحايد من حيث اللغة.
تحليل HTML
المحتوى الديناميكي
- Puppeteer: أتمتة Chrome بلا واجهة.
- Playwright: أتمتة متعددة المتصفحات.
- Nightmare: أتمتة متصفح قديمة مبنية على Electron.
الجدولة
- node-cron: مهام cron داخل Node.js.
CLI والأدوات المساعدة
- chalk: تنسيق النص في الطرفية.
- commander: محلل وسائط سطر الأوامر.
- inquirer: أسئلة تفاعلية في CLI.
- dotenv: محمّل متغيرات البيئة.
التخزين
- fs: نظام ملفات مدمج.
- lowdb: قاعدة بيانات JSON محلية صغيرة.
- sqlite3: قاعدة بيانات SQL محلية.
- mongodb: قاعدة بيانات NoSQL.
الأطر
- Crawlee: إطار عمل عالي المستوى للزحف واستخراج البيانات من Apify. نسخة JavaScript/TypeScript كانت على الإصدار v3.16 حتى مايو 2026، وهي المسار الأكثر نضجًا (أما منفذ Python فهو أحدث). وهو يغلف Puppeteer وPlaywright وCheerio وJSDOM عبر واجهة واحدة، مع تدوير البروكسيات وبناء الطوابير داخليًا — وهو مفيد إذا وجدت نفسك تعيد بناء نفس البنية التحتية حول أدوات الاستخراج مرارًا.
(تحقق دائمًا من أحدث الوثائق ومستودعات GitHub للحصول على التحديثات.)
موارد موصى بها لإتقان استخراج بيانات الويب باستخدام JavaScript
هل تريد التعمق أكثر؟ إليك قائمة مختارة من الموارد لرفع مستوى مهاراتك في الاستخراج:
الوثائق والأدلة الرسمية
- MDN Web Docs: Web Scraping
- توثيق Puppeteer
- توثيق Playwright
- توثيق Crawlee
- أكاديمية Apify لاستخراج بيانات الويب
الدروس والدورات
- freeCodeCamp: الدليل الشامل لاستخراج بيانات الويب باستخدام Node.js
- YouTube: استخراج بيانات الويب باستخدام Node.js (freeCodeCamp)
- DigitalOcean: كيفية استخراج موقع باستخدام Node.js وPuppeteer
مشاريع مفتوحة المصدر وأمثلة
المجتمع والمنتديات
الكتب والأدلة الشاملة
- كتاب O’Reilly «Web Scraping with Python» (للمفاهيم المشتركة بين اللغات)
- دورات Udemy/Coursera: «Web Scraping in Node.js»
(تحقق دائمًا من أحدث الإصدارات والتحديثات.)
كيفية استخراج أي موقع باستخدام الذكاء الاصطناعي Get Started Free
الخلاصة: اختيار النهج المناسب لفريقك
الخلاصة هي أن JavaScript وNode.js تمنحانك قوة ومرونة هائلتين لاستخراج بيانات الويب. يمكنك بناء أي شيء — من سكربتات سريعة وعفوية إلى زواحف متينة وقابلة للتوسع. لكن مع القوة العظيمة تأتي… أعمال صيانة عظيمة. البرمجة التقليدية هي الأفضل للمشاريع المخصصة والثقيلة هندسيًا، حيث تحتاج إلى تحكم كامل وتكون مستعدًا للصيانة المستمرة.
أما بالنسبة للجميع الآخرين — مستخدمي الأعمال، والمحللين، والمسوقين، وكل من يريد البيانات فقط — فإن الحلول الحديثة بلا كود مثل Thunderbit هي بمثابة نسمة هواء منعشة. تتيح لك إضافة Chrome المدعومة بالذكاء الاصطناعي من Thunderbit استخراج البيانات وتنظيمها وتصديرها في دقائق، لا في أيام. بلا كود، بلا محددات، بلا صداع.
إذًا ما النهج الصحيح؟ إذا كان لدى فريقك قوة هندسية ومتطلبات خاصة، فانغمس في أدوات Node.js. وإذا كنت تريد السرعة والبساطة والحرية في التركيز على الرؤى بدل البنية التحتية، فجرب Thunderbit. في كلتا الحالتين، الويب هو قاعدة بياناتك — اذهب واحصل على تلك البيانات.
وإذا علِقت يومًا، فتذكر فقط: حتى أفضل أدوات الاستخراج بدأت بصفحة فارغة وفنجان قهوة قوي. استخراج سعيد.
هل تريد معرفة المزيد عن الاستخراج المدعوم بالذكاء الاصطناعي أو رؤية Thunderbit أثناء العمل؟
- الموقع الرسمي لـ Thunderbit
- تنزيل إضافة Thunderbit لمتصفح Chrome
- مدونة Thunderbit
- كيفية استخراج أي موقع باستخدام الذكاء الاصطناعي
- ما هو استخراج البيانات وكيفية القيام به في 2025
إذا كانت لديك أسئلة أو قصص أو حتى أكثر حكايات الاستخراج رعبًا، فاتركها في التعليقات أو تواصل معي. أحب أن أسمع كيف يحول الناس الويب إلى ملعب بياناتهم الخاص.
ابقَ فضوليًا، وابقَ متيقظًا بالقهوة، واستخرج بذكاء أكبر لا بجهد أكبر.
تنزيل إضافة Thunderbit لمتصفح Chrome
جرّب أداة استخراج الويب بالذكاء الاصطناعي Get Started Free
الأسئلة الشائعة:
1. لماذا يُستخدم JavaScript وNode.js لاستخراج بيانات الويب في 2025؟
لأن معظم المواقع الحديثة مبنية باستخدام JavaScript. وNode.js سريعة، وتدعم العمل غير المتزامن، ولديها منظومة غنية (مثل Axios وCheerio وPuppeteer) تدعم كل شيء من الجلب البسيط إلى استخراج المحتوى الديناميكي على نطاق واسع.
2. ما سير العمل المعتاد لاستخراج موقع باستخدام Node.js؟
يبدو عادةً هكذا:
طلب → معالجة الاستجابة → (تنفيذ JavaScript اختياري) → تحليل HTML → استخراج البيانات → الحفظ أو التصدير
ويمكن تنفيذ كل خطوة باستخدام أدوات مخصصة مثل axios أو cheerio أو puppeteer.
3. كيف تستخرج الصفحات الديناميكية المُنشأة عبر JavaScript؟
استخدم متصفحات بلا واجهة مثل Puppeteer أو Playwright. فهي تحمل الصفحة كاملةً — بما في ذلك JavaScript — مما يجعل من الممكن استخراج ما يراه المستخدمون فعليًا.
4. ما أكبر التحديات في الاستخراج التقليدي؟
- تغيّر بنية الموقع
- اكتشاف أدوات الحظر ضد الروبوتات
- تكلفة موارد المتصفح
- تنظيف البيانات يدويًا
- الصيانة العالية مع مرور الوقت
هذه العوامل تجعل الاستخراج على نطاق واسع أو غير الملائم للمطورين أمرًا صعب الاستمرار فيه.
5. متى ينبغي أن أستخدم Thunderbit بدلًا من الكود؟
استخدم Thunderbit إذا كنت تحتاج إلى السرعة والبساطة ولا تريد كتابة الكود أو صيانته. إنه مثالي لفرق المبيعات أو التسويق أو الأبحاث التي تريد استخراج البيانات وتنظيمها بسرعة — خاصة من المواقع المعقدة أو متعددة الصفحات.




