الويب صار فوضويًا في 2026 — نصف حركة الإنترنت الآن من الروبوتات، وأدوات الزحف مفتوحة المصدر هي الأبطال المجهولون خلف الكواليس، إذ تدعم كل شيء من مراقبة الأسعار إلى تدريب الذكاء الاصطناعي. لقد قضيت سنوات في عالم SaaS والأتمتة، وإذا كان هناك شيء تعلمته، فهو أن اختيار الزاحف المستضاف ذاتيًا المناسب يمكن أن يوفر على فريقك أشهرًا من الصداع (وربما بعض جلسات تصحيح الأخطاء المتأخرة ليلًا). سواء كنت تستخرج بيانات من بضع صفحات منتجات أو تزحف عبر ملايين الروابط لأغراض البحث، فإن بدائل Firecrawl المفتوحة المصدر في هذه القائمة ستغطي احتياجاتك — بغض النظر عن حجمك، أو بنية التقنية لديك، أو مدى تقبلك للتعقيد.
لكن هنا المفاجأة: لا يوجد حل واحد يناسب الجميع. بعض الفرق تحتاج إلى القوة الخام لـ Scrapy أو القدرات الأرشيفية لـ Heritrix، بينما قد تجد فرق أخرى أن صيانة المكتبات مفتوحة المصدر مكلفة أكثر من اللازم. لذلك، دعنا نفكك أفضل 9 بدائل مفتوحة المصدر لـ Firecrawl لعام 2026، ونوضح أين يتألق كل منها، ونساعدك على مطابقة الأداة المناسبة مع احتياجات عملك — من دون معاناة التجربة والخطأ.
كيف تختار أفضل بديل مفتوح المصدر لـ Firecrawl لعملك
قبل أن تغوص في القائمة، دعنا نتحدث عن الاستراتيجية. إن مشهد الزحف المفتوح المصدر للويب أكثر تنوعًا من أي وقت مضى، ويجب أن يعتمد اختيارك على عدة عوامل رئيسية:
- سهولة الاستخدام: هل تريد واجهة بالنقر والإشارة، أم أنك مرتاح لكتابة Python أو Go أو JavaScript؟
- قابلية التوسع: هل تزحف إلى موقع واحد، أم تحتاج إلى الزحف عبر ملايين الصفحات ضمن مئات النطاقات؟
- نوع المحتوى: هل موقعك المستهدف HTML ثابت، أم يعتمد على JavaScript كثيف وتحميل ديناميكي؟
- احتياجات التكامل: كيف تريد استخدام البيانات — تصديرها إلى Excel، أو دفعها إلى قاعدة بيانات، أو إدخالها في خط معالجة تحليلي؟
- الصيانة: هل لديك الموارد اللازمة لصيانة الشيفرة المخصصة، أم تريد أداة تتكيف تلقائيًا مع تغييرات الموقع؟
إليك ورقة غش سريعة تساعدك على اتخاذ القرار:
| السيناريو | أفضل أداة(أدوات) |
|---|---|
| بلا أكواد، تصفح دون اتصال | HTTrack |
| زحف واسع النطاق ومتعدد النطاقات | Scrapy، Apache Nutch، StormCrawler |
| مواقع ديناميكية/غنية بـ JavaScript | Puppeteer |
| أتمتة النماذج/تسجيل الدخول مطلوب | MechanicalSoup |
| تنزيل/أرشفة موقع ثابت | Wget، HTTrack، Heritrix |
| مطوّر Go، أداء عالٍ | Colly |
والآن، لندخل في أفضل 9 بدائل مفتوحة المصدر لـ Firecrawl لعام 2026.
1. Scrapy: الأفضل للزحف واسع النطاق باستخدام Python

هو البطل الثقيل في عالم الزحف المفتوح المصدر. بُني باستخدام Python، وهو الإطار المفضل للمطورين الذين يحتاجون إلى الزحف على نطاق واسع — أي ملايين الصفحات، وتحديثات متكررة، ومنطق مواقع معقد.
لماذا Scrapy؟
- نطاق هائل: يمكن لـ Scrapy التعامل مع آلاف الطلبات في الثانية، وتستخدمه شركات تستخرج مليارات الصفحات شهريًا ().
- قابل للتوسعة ووحداتي: اكتب عناكب مخصصة، وأضف وسطاء للبروكسيات، وتعامل مع عمليات تسجيل الدخول، وأخرج النتائج إلى JSON أو CSV أو قواعد بيانات.
- مجتمع نشط: الكثير من الإضافات، والوثائق، وإجابات Stack Overflow.
- مجرّب في الإنتاج: يُستخدم في بيئات الإنتاج لدى فرق التجارة الإلكترونية والأخبار والبحث حول العالم.
القيود: منحنى تعلم حاد لغير المطورين، وستحتاج إلى صيانة العناكب مع تغيّر المواقع. لكن إذا كنت تريد تحكمًا كاملًا وقابلية توسع عالية، فمن الصعب التفوق على Scrapy.
2. Apache Nutch: الأفضل لمحركات البحث المؤسسية
هو الجدّ الأكبر للزواحف مفتوحة المصدر، وهو مصمم للزحف على مستوى المؤسسات وعلى نطاق الإنترنت. إذا كنت تحلم ببناء محرك البحث الخاص بك أو الزحف عبر ملايين النطاقات، فـ Nutch هو صديقك.
لماذا Apache Nutch؟
- نطاق مدعوم بـ Hadoop: بُني على Hadoop، ويمكن لـ Nutch الزحف عبر مليارات الصفحات ضمن عناقيد من الخوادم ( يستخدمه للزحف على الويب العام).
- زحف دفعي: زوّده بقائمة من عناوين URL البذرية واتركه يعمل — ممتاز للمهام المجدولة واسعة النطاق.
- التكامل: يعمل مع Solr وElasticsearch وخطوط بيانات كبيرة.
القيود: الإعداد معقد (فكر في عناقيد Hadoop وملفات إعداد Java)، وهو يركز أكثر على الزحف الخام بدلًا من استخراج البيانات المهيكلة. مبالغ فيه للمشاريع الصغيرة، لكنه لا يُضاهى في الزحف على مستوى الويب.
3. Heritrix: الأفضل للأرشفة والامتثال

هو الزاحف الخاص بـ Internet Archive، وهو مصمم خصيصًا لأرشفة الويب والحفاظ الرقمي.
لماذا Heritrix؟
- اكتمال بمعايير أرشيفية: يلتقط كل صفحة وأصل ورابط — مثالي للامتثال القانوني أو اللقطات التاريخية.
- مخرجات WARC: يخزن كل شيء في ملفات Web ARChive معيارية، جاهزة لإعادة التشغيل أو التحليل.
- إدارة عبر الويب: يمكنك تهيئة عمليات الزحف ومراقبتها من خلال واجهة متصفح.
القيود: ثقيل ويحتاج إلى مساحة وذاكرة كبيرتين، ولا ينفذ JavaScript، ويُخرج أرشيفات خامًا بدلًا من جداول بيانات مهيكلة. الأنسب للمكتبات والأرشيفات والقطاعات المنظمة.
4. Colly: الأفضل لمطوري Go ذوي الأداء العالي
هو المفضل لدى مطوري Go — أداة سريعة وخفيفة وعالية التوازي للزحف على الويب.
لماذا Colly؟
- سريع للغاية: يتيح توازي Go لـ Colly استخراج آلاف الصفحات باستهلاك محدود جدًا للمعالج والذاكرة ().
- واجهة بسيطة: عرّف دوال استدعاء لعناصر HTML، وتعامل مع ملفات تعريف الارتباط وrobots.txt تلقائيًا.
- ممتاز للمواقع الثابتة: مثالي للصفحات المولدة من الخادم أو واجهات API، أو عندما تريد دمج الزحف في واجهة خلفية بـ Go.
القيود: لا يوجد تنفيذ مدمج لـ JavaScript (وللمواقع الديناميكية ستحتاج إلى دمجه مع شيء مثل Chromedp)، وستحتاج إلى معرفة Go.
5. MechanicalSoup: الأفضل لأتمتة النماذج البسيطة

هو مكتبة Python تملأ الفجوة بين طلبات HTTP البسيطة وأتمتة المتصفح الكاملة.
لماذا MechanicalSoup؟
- أتمتة النماذج: يسهل تسجيل الدخول، وملء النماذج، والحفاظ على الجلسات — ممتاز للاستخراج من خلف المصادقة.
- خفيف الوزن: يعتمد داخليًا على Requests وBeautifulSoup، لذا فهو سريع وسهل الإعداد.
- مثالي للمواقع التفاعلية: إذا كنت بحاجة إلى إرسال نماذج بحث أو استخراج البيانات بعد تسجيل الدخول، فهو خيار ممتاز ().
القيود: لا ينفذ JavaScript، لذلك لن يعمل جيدًا مع المواقع الثقيلة بـ JS. الأفضل للصفحات الثابتة أو الصفحات المولدة من الخادم ذات التفاعلات البسيطة.
6. Puppeteer: الأفضل للمواقع الديناميكية والثقيلة بـ JavaScript
هو السكين السويسري لاستخراج البيانات من المواقع الحديثة الثقيلة بـ JavaScript. إنه مكتبة Node.js تمنحك تحكمًا كاملًا في متصفح Chrome بلا واجهة رسومية.
لماذا Puppeteer؟
- يتعامل مع المحتوى الديناميكي: استخرج البيانات من تطبيقات الصفحة الواحدة، والتمرير اللانهائي، والصفحات التي تحمل البيانات عبر AJAX ().
- محاكاة المستخدم: انقر الأزرار، واملأ النماذج، والتقط لقطات شاشة، وحتى حل CAPTCHAs (مع الإضافات).
- أتمتة قوية: ممتاز للاختبار، والمراقبة، واستخراج أي شيء يمكن لمستخدم حقيقي رؤيته.
القيود: يستهلك موارد كبيرة (يشغّل مثيلات Chrome كاملة)، وأبطأ من أدوات الاستخراج المعتمدة على HTTP فقط، كما أن التوسع يحتاج إلى عتاد قوي أو تنسيق سحابي.
7. Wget: الأفضل للتنزيل السريع من سطر الأوامر

هو أداة سطر أوامر كلاسيكية لتنزيل المواقع والملفات الثابتة.
لماذا Wget؟
- البساطة: نزّل مواقع أو أدلة كاملة بأمر واحد — من دون أي برمجة.
- السرعة: مكتوب بـ C، لذا فهو سريع وفعّال.
- ممتاز للمحتوى الثابت: مثالي لمواقع التوثيق، والمدونات، أو التنزيلات الجماعية للملفات ().
القيود: لا ينفذ JavaScript ولا يتعامل مع النماذج، كما أنه ينزل الصفحات الخام لا البيانات المهيكلة. اعتبره كمنظف كهربائي رقمي للمواقع الثابتة.
8. HTTrack: الأفضل للتصفح دون اتصال (بلا أكواد)
هو النسخة الأكثر سهولة من Wget، إذ يوفر واجهة رسومية لنسخ المواقع.
لماذا HTTrack؟
- بساطة الواجهة: معالج خطوة بخطوة يجعله مناسبًا لغير التقنيين.
- تصفح دون اتصال: يضبط الروابط بحيث يمكنك تصفح المواقع المنسوخة محليًا.
- ممتاز للأرشفة: مثالي للباحثين، والمسوقين، أو أي شخص يريد لقطة من موقع من دون كتابة أكواد ().
القيود: لا يدعم المحتوى الديناميكي، وقد يكون بطيئًا في المواقع الكبيرة، ولم يُصمم لاستخراج البيانات المهيكلة.
9. StormCrawler: الأفضل للزحف الموزع في الوقت الحقيقي

هو الزاحف الموزع الحديث للفرق التي تحتاج إلى بيانات ويب مستمرة وفورية وعلى نطاق واسع.
لماذا StormCrawler؟
- زحف في الوقت الحقيقي: مبني على Apache Storm، ويعالج البيانات على شكل تدفقات — ممتاز لمراقبة الأخبار أو محركات البحث ().
- وحداتي وقابل للتوسع: أضف التحليل والفهرسة ووحدات المعالجة المخصصة بحسب الحاجة.
- يُستخدم من قِبل Common Crawl: يدعم مجموعة بيانات الأخبار الخاصة بأحد أكبر أرشيفات الويب المفتوحة.
القيود: يتطلب تطوير Java وعنقود Storm، لذا فهو الأنسب للفرق ذات الخبرة في الأنظمة الموزعة. مبالغ فيه للمشاريع الصغيرة.
مقارنة بدائل Firecrawl مفتوحة المصدر: أي منافس مجاني يناسب احتياجاتك؟
إليك نظرة جنبًا إلى جنب على الأدوات التسع:
| الأداة | أفضل حالة استخدام | المزايا الرئيسية | العيوب | اللغة / الإعداد |
|---|---|---|---|---|
| Scrapy | الزحف واسع النطاق والمتكرر | قوي، قابل للتوسع، مجتمع ضخم | منحنى تعلم حاد، يتطلب Python | إطار Python |
| Apache Nutch | الزحف المؤسسي وعلى مستوى الويب | مدعوم بـ Hadoop، مثبت على نطاق واسع | إعداد معقد، قائم على الدُفعات | Java/Hadoop |
| Heritrix | الأرشفة، الزحف للامتثال | التقاط كامل للموقع، مخرجات WARC | ثقيل، بلا JavaScript، أرشيفات خام | تطبيق Java، واجهة ويب |
| Colly | مطورو Go، استخراج عالي الأداء | سريع، واجهة بسيطة، توازٍ | لا JavaScript، يتطلب Go | مكتبة Go |
| MechanicalSoup | أتمتة النماذج، استخراج مع تسجيل الدخول | خفيف، التعامل مع الجلسات | لا JavaScript، نطاق محدود | مكتبة Python |
| Puppeteer | المواقع الديناميكية/الثقيلة بـ JavaScript | تحكم كامل بالمتصفح، أتمتة | يستهلك موارد كبيرة، يتطلب Node.js | مكتبة Node.js |
| Wget | تنزيل مواقع ثابتة، وصول دون اتصال | بسيط، سريع، سطر أوامر | لا JavaScript، صفحات خام | أداة سطر أوامر |
| HTTrack | مستخدمون غير تقنيين، أرشفة المواقع | واجهة رسومية، تصفح دون اتصال سهل | لا JavaScript، بطيء على المواقع الكبيرة | تطبيق سطح مكتب (GUI) |
| StormCrawler | الزحف الموزع وفي الوقت الحقيقي | قابل للتوسع، وحداتي، فوري | يحتاج خبرة في Java/Storm | عنقود Java/Storm |
هل يجب أن تبني أداة خاصة بك أم تستخدم بديلًا مفتوح المصدر قائمًا لـ Firecrawl؟
إليك الحقيقة بصراحة: بناء زاحفك الخاص يبدو ممتعًا — حتى تجد نفسك غارقًا في الصيانة والبروكسيات ومشكلات الحظر المضاد للروبوتات. الأدوات المفتوحة المصدر أعلاه تختصر سنوات من الخبرة المكتسبة بصعوبة وحكمة المجتمع. ووفقًا لتقارير الصناعة، فإن استخدام الحلول الموجودة مسبقًا هو أسرع وأوثق طريقة لتحقيق النتائج وتجنب إعادة اختراع العجلة ().
- اختر المصدر المفتوح إذا: كانت احتياجاتك منسجمة مع ما هو متاح بالفعل، وتريد تقليل وقت التطوير، وتقدّر دعم المجتمع.
- ابنِ حلك الخاص إذا: كانت لديك متطلبات فريدة بحق، وخبرة داخلية عميقة، وكانت عملية الاستخراج جزءًا أساسيًا من عملك.
لكن تذكّر أن المصدر المفتوح ليس "مجانيًا" عندما تحسب تكلفة وقت الهندسة، وصيانة الخوادم، والتحديثات المستمرة لمواجهة وسائل مكافحة الاستخراج. إذا كنت تريد فوائد زاحف قوي من دون كتابة كود، فهناك خيار إضافي واحد.
مكافأة: عندما يكون المصدر المفتوح معقدًا جدًا، جرّب Thunderbit
على الرغم من أن الأدوات المذكورة أعلاه مذهلة للمطورين، إلا أنها تشترك في قيود متشابهة: فهي تتطلب معرفة برمجية، وتواجه صعوبة مع أنظمة الحماية الديناميكية المعتمدة على الذكاء الاصطناعي، وتحتاج إلى صيانة مستمرة.
هو خياري المفضل لأي شخص يحتاج إلى تجاوز هذه القيود. إنه يجسر الفجوة بين قوة الاستخراج وسهولة الاستخدام.
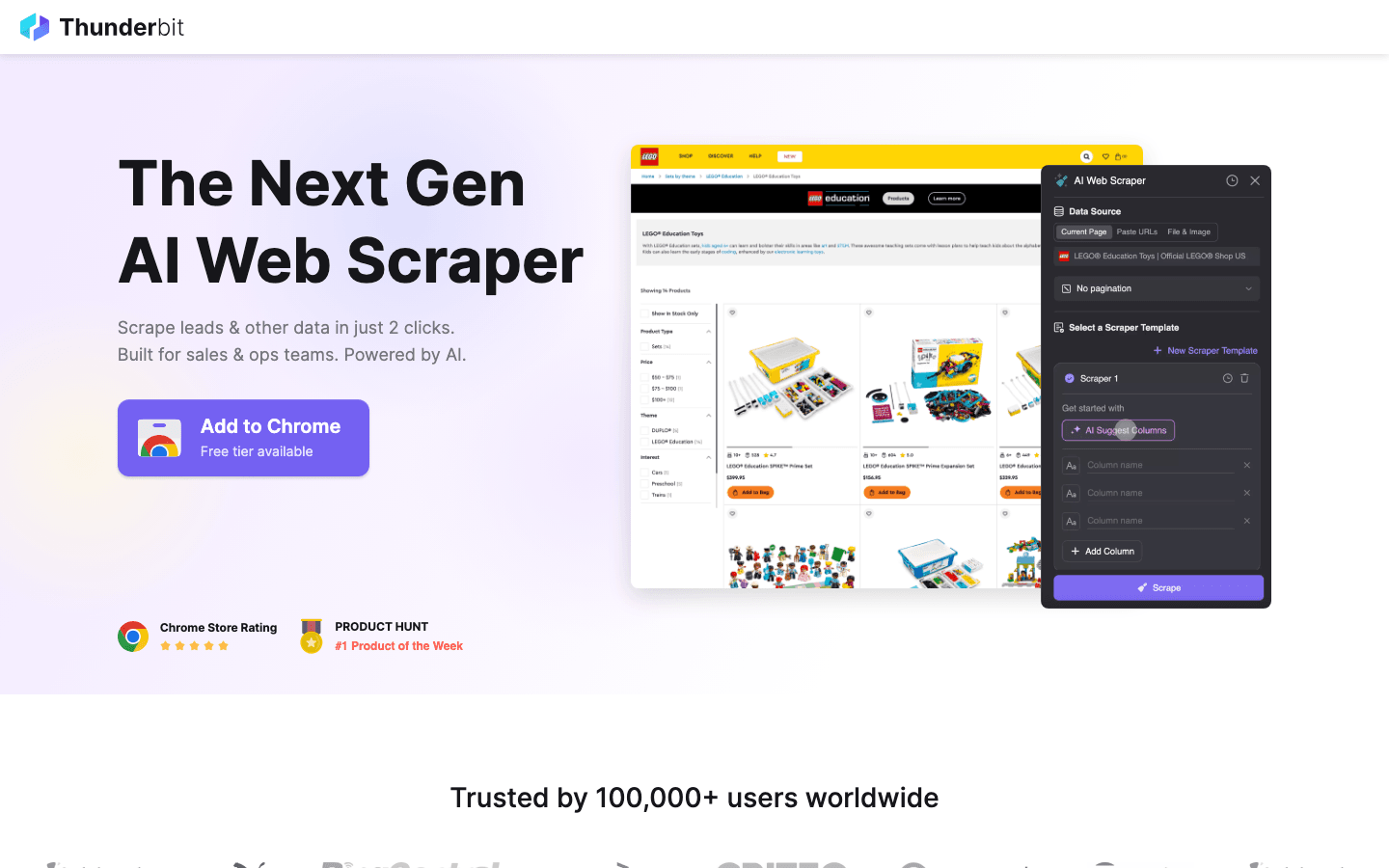
لماذا تفكر في Thunderbit بدلًا من الحلول المفتوحة المصدر؟
- لا حاجة لأي برمجة: على عكس Scrapy أو Puppeteer، فإن Thunderbit هو إضافة Chrome مدعومة بالذكاء الاصطناعي. تنقر على "اقتراح الحقول بالذكاء الاصطناعي"، فيبني لك أداة الاستخراج.
- يتعامل مع المهام الصعبة: يتم التعامل تلقائيًا مع المحتوى الديناميكي، والتمرير اللانهائي، وتعدد الصفحات بواسطة الذكاء الاصطناعي، مما يوفر عليك ساعات من كتابة السكربتات المخصصة.
- تصدير فوري: انتقل من الموقع إلى Excel أو Google Sheets أو Notion بِنقرتين.
- لا صيانة: لا تحتاج إلى تحديث الكود عندما يغيّر الموقع تخطيطه — فالذكاء الاصطناعي في Thunderbit يتكيف نيابةً عنك.
إذا كنت مندوب مبيعات أو مسوّقًا أو باحثًا وتريد البيانات الآن من دون تعلم Python أو Go، فإن Thunderbit هو الرفيق المثالي للأدوات المفتوحة المصدر في هذه القائمة.
هل تريد رؤيته عمليًا؟ وجرّبها بنفسك.
الخلاصة: العثور على الزاحف المناسب المستضاف ذاتيًا لعام 2026
عالم بدائل Firecrawl مفتوحة المصدر أصبح أكثر ثراءً من أي وقت مضى. سواء كنت تحتاج إلى النطاق الخام لـ Scrapy أو Nutch، أو الدقة الأرشيفية لـ Heritrix، فهناك حل لكل سيناريو تجاري. المهم هو أن تطابق الأداة مع احتياجاتك — لا تبالغ في الهندسة إذا كنت تحتاج فقط إلى سحب سريع للبيانات، ولا تبخل بالاستثمار إذا كنت تزحف على نطاق الإنترنت.
وتذكّر، إذا اتضح أن الطريق المفتوح المصدر تقني جدًا أو يستغرق وقتًا طويلًا، فالأدوات المدعومة بالذكاء الاصطناعي مثل Thunderbit جاهزة لتسد الفجوة.
هل أنت مستعد للبدء؟ شغّل Scrapy لمشروع البيانات الكبير التالي، أو لاستخراج بسيط مدعوم بالذكاء الاصطناعي. وإذا كنت تتوق إلى المزيد من نصائح استخراج بيانات الويب، فتفقّد للاطلاع على شروحات معمقة ودروس تعليمية.
الأسئلة الشائعة
1. ما الميزة الرئيسية لاستخدام بدائل Firecrawl مفتوحة المصدر؟
توفر البدائل مفتوحة المصدر المرونة، وتوفير التكاليف، وإمكانية الاستضافة الذاتية وتخصيص الزاحف. كما أنك تتجنب الارتباط بمورد واحد وتستفيد من دعم وتحديثات مجتمع نشط.
2. ما الأداة الأفضل لغير التقنيين الذين يحتاجون إلى نتائج سريعة؟
خيار مفتوح المصدر جيد للتصفح دون اتصال. لكن لاستخراج البيانات المهيكلة (مثل جداول Excel)، نوصي بالأداة الإضافية بفضل قدراتها المعتمدة على الذكاء الاصطناعي.
3. كيف أتعامل مع المواقع الديناميكية الثقيلة بـ JavaScript؟
هو أفضل خيار — لأنه يتحكم بمتصفح حقيقي، ويمكنه استخراج أي شيء يراه المستخدم، بما في ذلك تطبيقات الصفحة الواحدة والمحتوى المحمّل عبر AJAX.
4. متى يجب أن أستخدم زاحفًا ثقيلًا مثل Apache Nutch أو StormCrawler؟
إذا كنت بحاجة إلى الزحف عبر ملايين الصفحات ضمن العديد من النطاقات، أو تحتاج إلى زحف موزع في الوقت الحقيقي (كما في محركات البحث أو مراقبة الأخبار)، فهذه الأدوات مصممة للنطاق الواسع والموثوقية.
5. هل من الأفضل أن أبني زاحفي الخاص أم أستخدم حلًا مفتوح المصدر قائمًا؟
بالنسبة لمعظم الفرق، استخدام أداة مفتوحة المصدر قائمة وتخصيصها أسرع وأرخص وأكثر موثوقية. ابنِ حلك الخاص فقط إذا كانت لديك احتياجات شديدة التخصص والموارد اللازمة لصيانته على المدى الطويل.
زحفًا سعيدًا — ولتبقَ بياناتك دائمًا حديثة، ومهيكلة، وجاهزة للعمل.
اعرف المزيد