列表爬虫
作者
从任意网页 URL 中提取有序和无序列表项。将分组列表以纯文本方式查看,快速抓住关键要点。
Scrape hundreds of webpages with the Thunderbit Chrome Extension in one click, try the Thunderbit API for free, or use our 网页数据采集服务 to save engineering time.







一键提取网页列表使用 Thunderbit 快速将网页、子页面、PDF、文档和图片抓取为结构化数据。自动完成提取,并将结果导出到 Sheets、Airtable 或 Notion。

安装自Chrome Web Store
一键提取网页列表
借助 Thunderbit 的 AI 网页爬虫 Chrome 扩展,从文章、文档和知识库中收集要点、步骤和检查清单。点击“AI 建议字段”,再点击“开始抓取”,即可提取网页中的结构化列表数据,包括分页内容,并整理成干净的表格。
主页面提供的信息还不够?使用子页面抓取跟随链接,丰富数据集;当列表嵌在文件中时,也可以抓取 PDF、文档和图片中的内容。对提取出的条目进行摘要、分类和格式化,然后导出到 Google Sheets、Airtable 或 Notion。
如何使用 Thunderbit 抓取列表


步骤 2打开扩展在 Chrome 中打开 Thunderbit,然后打开列表爬虫工具。在“输入 URL”标签页中,将有效的 HTTP 或 HTTPS 链接粘贴到“url”字段中(例如,https://example.com/article)。请确认该页面可公开访问;如果内容需要身份验证,请确保浏览器已登录该网站。

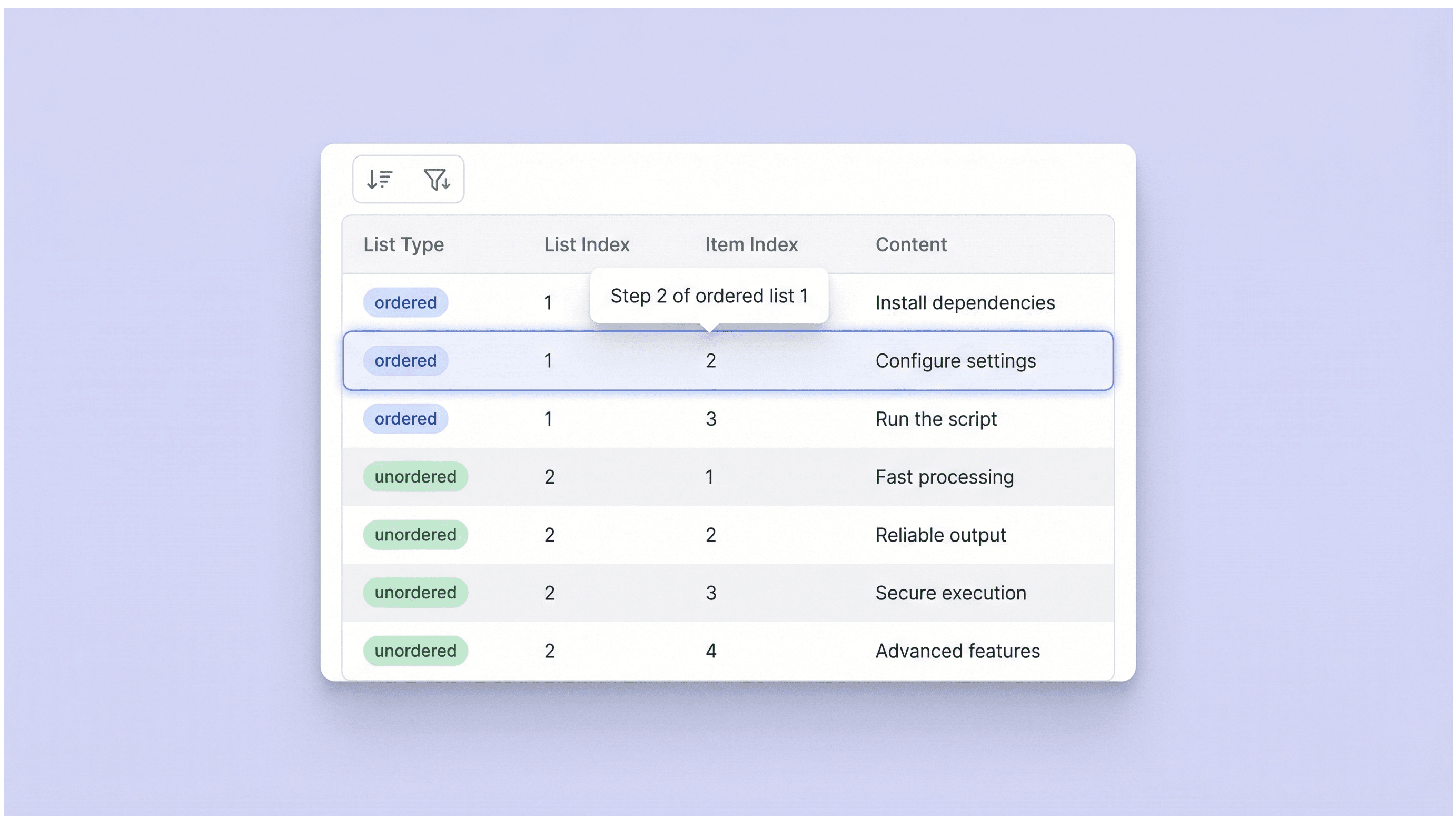
步骤 3点击“抓取列表”按钮点击“抓取列表”按钮开始提取。Thunderbit 会扫描所提供的页面,并返回一个检测到的列表项表格,按列表类型分组,列包括“列表类型”“列表索引”“条目索引”和“列表项文本”。查看结果后,可将表格导出到 Excel、Google Sheets、Airtable 或 Notion,或下载为 CSV 或 JSON。
了解如何抓取网页并提取有序和无序列表项
从任意 URL 提取列表项
列表爬虫可接收一个 HTTP 或 HTTPS 网页 URL,并扫描页面中的有序和无序列表。它会将每个列表项的文本提取到结构化表格中,让你无需复制粘贴就能查看关键要点、步骤和检查清单。它专为需要从文章、文档、帮助中心和博客文章中快速、可靠获取摘要的商务用户而设计。

按列表类型和位置整理结果
工具会按列表类型(有序或无序)对输出进行分组,并添加列表索引和条目索引,以保留原始结构。这样你就能轻松还原多步骤说明、比较同一页面上的多个列表,或定位某个特定条目来自哪里。对于需要为研究、质检和内容审阅整理出清晰、可追溯笔记的团队来说,这非常实用。
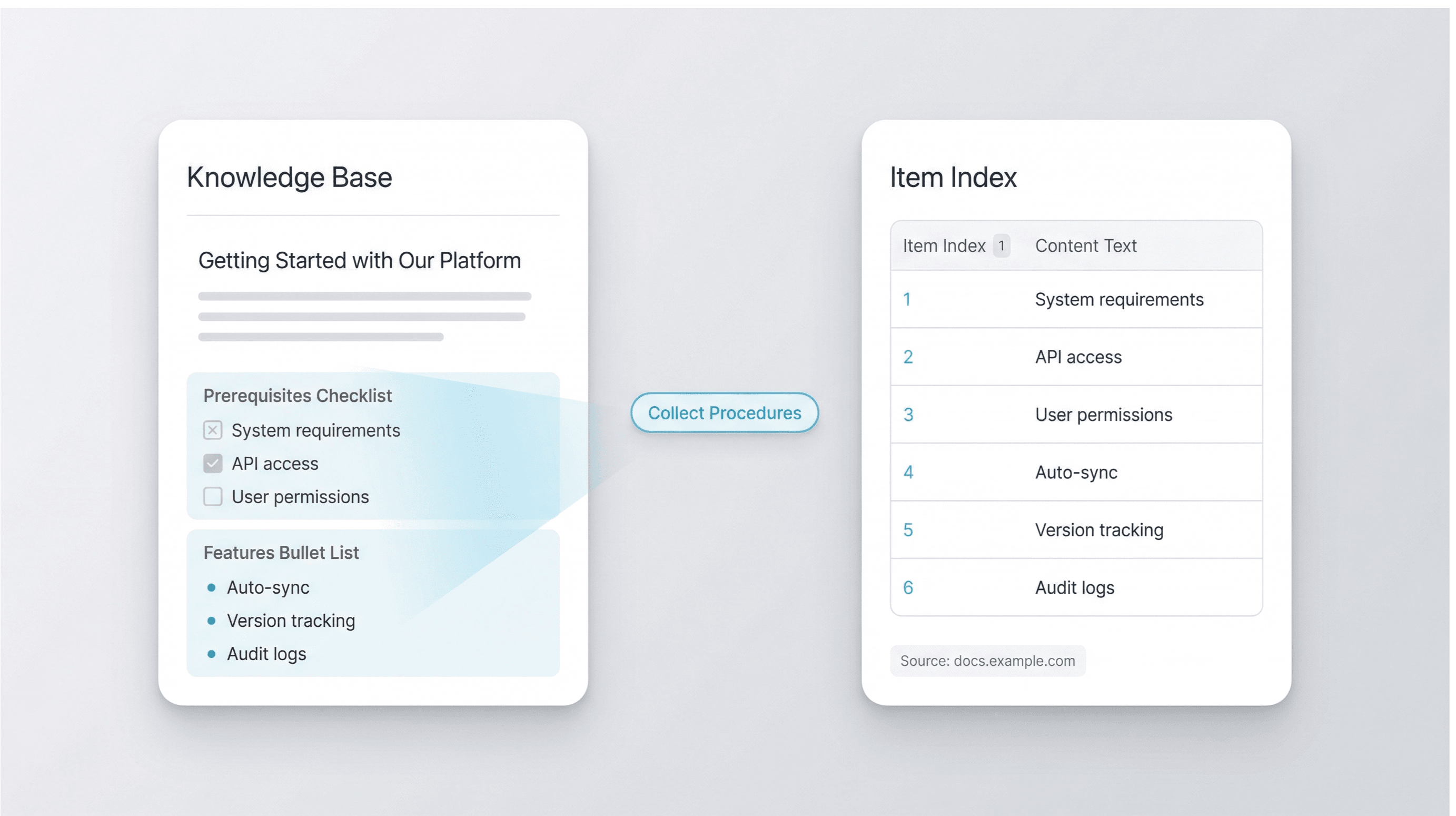
总结文档和操作指南内容
使用列表爬虫从产品文档、知识库和教程中收集流程、前置条件和功能要点。产品、支持和运营团队可以把零散列表整理成一张表,用于审计、内部 Wiki 或培训材料。由于每个条目都有索引,你还可以跟踪时间变化,并确保内部引用与源页面保持一致。
构建可分析、可复用的结构化数据集
把以列表为主的页面转化为结构化数据,你可以从 Thunderbit 导出到 Excel、Google Sheets、Airtable 或 Notion,或者下载为 CSV 或 JSON。这有助于市场和研究团队整理竞品功能列表、收集需求或汇总精选资源。表格格式还支持在分享给相关人员前进行快速筛选、去重和分类。

发现更多免费工具
网站地图提取器
解析 XML 网站地图 URL,并将所有页面链接整理成清晰的表格。快速审查网站结构,发现缺失或异常 URL,助力 SEO 与 QA 检查。
网站图片提取器
立即从任意网页中提取所有图片,并快速下载。完全免费,速度快,导出也非常简单。
URL 提取器和批量下载器
从任意页面提取所有网站链接,并下载为 CSV。快速收集用于调研、分析或数据采集任务的 URL。
在线从文本中提取邮箱
粘贴任意文本,快速整理出有效邮箱地址清单。节省清理笔记、消息和文档的时间。
文本电话号码提取器
扫描文本中的有效电话号码,并返回一份干净、有条理的列表。节省手动检查时间,轻松复制你需要的号码。
文本提取器
从图片中提取文字,并支持下载结果。轻松将扫描文件或照片快速转换为可编辑文本,方便后续使用。
免费从网站提取邮箱
扫描网页中的有效邮箱地址,获取一份干净的名单,用于外联或联系人调研。
Google Scholar 爬虫
从 Google Scholar 页面提取学术检索结果,并将论文标题、引用次数、作者和出版信息导出为 CSV,帮助你更快完成研究。
用户如何评价 Thunderbit
Taryn W.增长策略师@Thunderbit 改变了我做竞品调研的方式。我点一下 “AI Suggest Fields”,它就能把分页结果整理成整洁的表格——不用写代码,也不用碰 CSS。分析长尾市场的商品数据时,真的省了太多时间。
Miles T.销售开发顾问我用 Thunderbit 从名录里抓邮箱和电话号码。它只需一次点击就能提取干净的联系方式,导出到 Sheets 或 Notion 也只要几秒。不需要额外配置,也不用写代码——拿到手就是能直接用的数据。
Rhea C.电商分析师Thunderbit 帮我监控多个页面上的 SKU 数据。我先抓取商品列表,再用 Subpage Scraping 拉取完整规格、价格、评论和库存。AI 会把所有内容整理成我定义的列。
Cassian B.房地产顾问Thunderbit 的 Scheduled Scraper 让房产跟踪轻松很多。我只要用自然语言描述时间间隔,它就会自动拉取更新后的房源、价格和链接,不用再回头改设置。简单又实用。
Dorian B.内容与 SEO 专家我用 Thunderbit 的 Field AI Prompts 来清理和标记抓取到的博客内容。它可以提取标题、作者,甚至自动建议分类。对动态网站和子页面也很好用,非常适合构建结构化 SEO 数据集。
Lina K.平台运营负责人我们用 Thunderbit 跟踪小众商店的 SKU。Cloud Scraping 一次能处理 50 页,而需要登录的网站,我们就切换到浏览器模式。速度快、灵活,而且不需要持续维护或手动改脚本。
Jorge F.入站销售经理Thunderbit 的 AI Autofill 简直救命。抓完联系人信息后,我直接用它在浏览器里填写潜客表单。只要选中标签页,它就会根据抓取到的数据自动填好所有内容,不用手动输入。
Alina D.自由研究员我经常靠 Thunderbit 从 PDF、图片型网站和无限滚动页面提取数据。它能用 AI 处理各种乱格式,并输出可直接导出的表格,我几秒就能发到 Google Sheets 或 Airtable。
Taryn W.增长策略师@Thunderbit 改变了我做竞品调研的方式。我点一下 “AI Suggest Fields”,它就能把分页结果整理成整洁的表格——不用写代码,也不用碰 CSS。分析长尾市场的商品数据时,真的省了太多时间。
Miles T.销售开发顾问我用 Thunderbit 从名录里抓邮箱和电话号码。它只需一次点击就能提取干净的联系方式,导出到 Sheets 或 Notion 也只要几秒。不需要额外配置,也不用写代码——拿到手就是能直接用的数据。
Rhea C.电商分析师Thunderbit 帮我监控多个页面上的 SKU 数据。我先抓取商品列表,再用 Subpage Scraping 拉取完整规格、价格、评论和库存。AI 会把所有内容整理成我定义的列。
Cassian B.房地产顾问Thunderbit 的 Scheduled Scraper 让房产跟踪轻松很多。我只要用自然语言描述时间间隔,它就会自动拉取更新后的房源、价格和链接,不用再回头改设置。简单又实用。
Dorian B.内容与 SEO 专家我用 Thunderbit 的 Field AI Prompts 来清理和标记抓取到的博客内容。它可以提取标题、作者,甚至自动建议分类。对动态网站和子页面也很好用,非常适合构建结构化 SEO 数据集。
Lina K.平台运营负责人我们用 Thunderbit 跟踪小众商店的 SKU。Cloud Scraping 一次能处理 50 页,而需要登录的网站,我们就切换到浏览器模式。速度快、灵活,而且不需要持续维护或手动改脚本。
Jorge F.入站销售经理Thunderbit 的 AI Autofill 简直救命。抓完联系人信息后,我直接用它在浏览器里填写潜客表单。只要选中标签页,它就会根据抓取到的数据自动填好所有内容,不用手动输入。
Alina D.自由研究员我经常靠 Thunderbit 从 PDF、图片型网站和无限滚动页面提取数据。它能用 AI 处理各种乱格式,并输出可直接导出的表格,我几秒就能发到 Google Sheets 或 Airtable。




