
Thunderbit 的 Magento 爬虫 可用 AI 将 Magento(Adobe Commerce)页面快速整理成干净、结构化的数据集。你只需打开一个 Magento 页面,点击 AI Suggest Fields,再点击 Scrape,就能提取商品名称、SKU、价格、图片等信息。它面向真实业务场景设计,几分钟内即可导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON。
🛍️ 什么是 Magento 爬虫
Magento 爬虫是一种 AI 网页爬虫,用于从 Magento(Adobe Commerce)网站与市场(Marketplace)页面中提取商品列表与商品详情数据。使用 ,你只要进入目标页面(例如商品列表页或扩展插件页),点击 AI Suggest Fields 让 AI 自动识别最合适的列,再点击 Scrape 即可采集数据。
当你需要 分页抓取(跨多页采集列表)以及 子页面抓取(逐个进入每个商品/扩展详情页,为表格补充更深层字段,如版本兼容性、文档链接或更细的价格信息)时,这个能力尤其好用。
🧾 Magento 爬虫可以抓取哪些内容
Magento 页面里往往包含大量有价值的电商与目录数据,但通常不方便直接复制到表格里。Thunderbit 的 AI 网页爬虫(https://thunderbit.com/)会像人一样理解页面内容,并输出结构化的行数据,帮助你搭建商品目录、监控价格、追踪市场变化。
下面是两种你可以立刻上手的常见工作流。
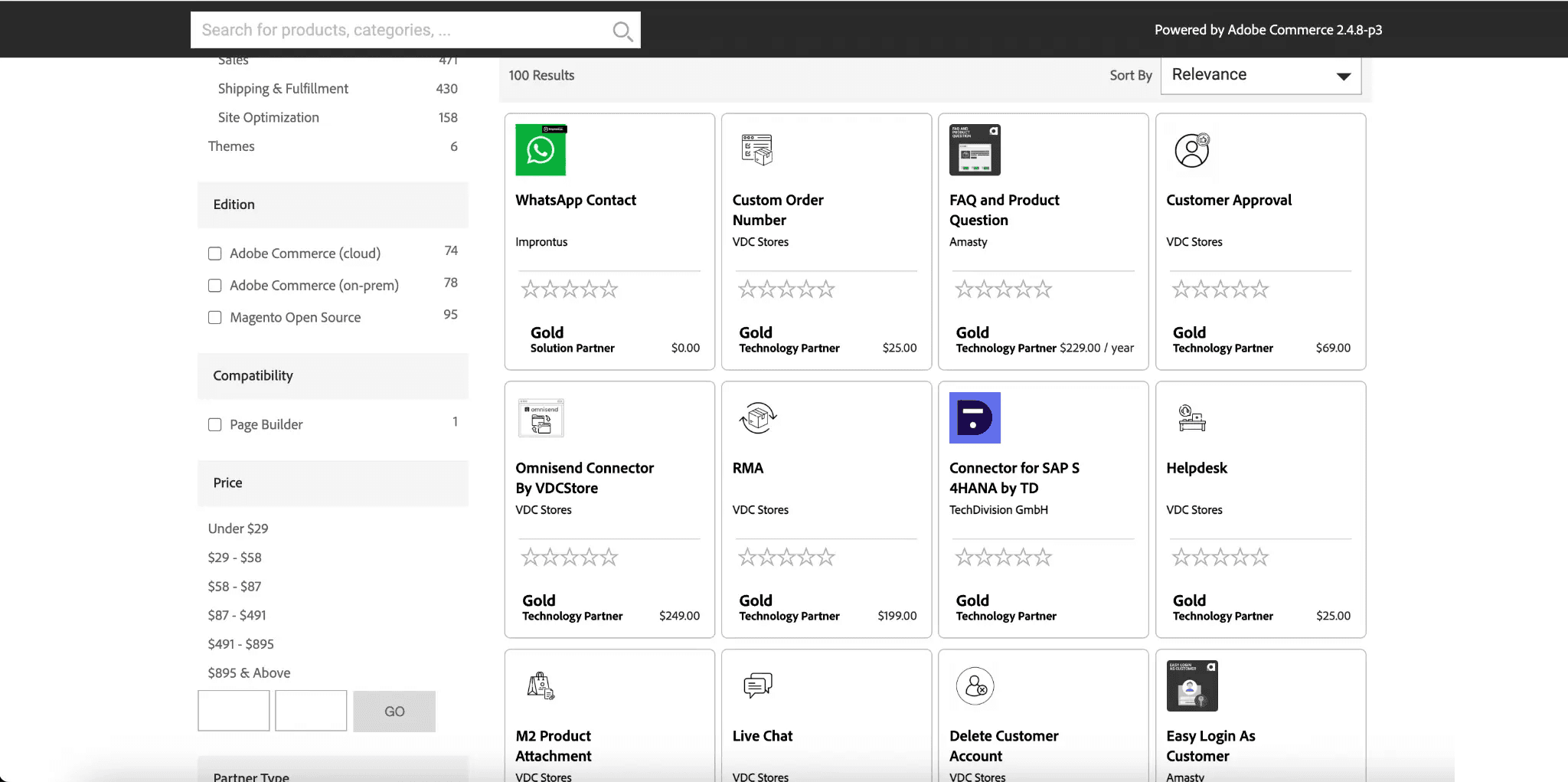
🧩 抓取 Magento 商品数据(信息提取)
该场景聚焦于从 Magento Marketplace 的详情页提取结构化的商品/扩展信息,例如:
https://commercemarketplace.adobe.com/extensions/customer-support.html
你可以采集关键字段(名称、厂商、分类、兼容性、文档链接等),如果页面还链接到更多细节,也可以用 子页面抓取 进一步补全数据集。
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:https://commercemarketplace.adobe.com/extensions/customer-support.html
- 点击 AI Suggest Fields,生成推荐的列名与数据类型。
- 点击 Scrape 运行爬虫,然后导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON。
字段(列)示例
| Column | Description |
|---|---|
| 🏷️ Product / Extension Name | 页面上展示的 Magento 扩展或商品名称。 |
| 🔗 Product URL | 你抓取的商品/扩展详情页直达链接。 |
| 🧑💻 Vendor / Publisher | 发布该扩展的公司或开发者。 |
| 🧾 Short Description | 对扩展功能的简要说明。 |
| 🧩 Category | Marketplace 分类(例如:客服支持、结账、营销)。 |
| 🧱 Platform / Edition | 页面展示的版本/发行版信息(如 Adobe Commerce / Magento Open Source)。 |
| 🧰 Version Compatibility | 页面列出的可兼容 Magento/Adobe Commerce 版本。 |
| 💲 Price | 标价(如适用也可能显示“Free”)。 |
| ⭐ Rating | Marketplace 页面显示的平均评分(如有)。 |
| 🗳️ Review Count | 评论数量(如有)。 |
| 🖼️ Image / Logo | 主要商品图片或厂商 Logo 的 URL。 |
| 📄 Documentation URL | 文档、用户指南或安装说明链接(如有)。 |
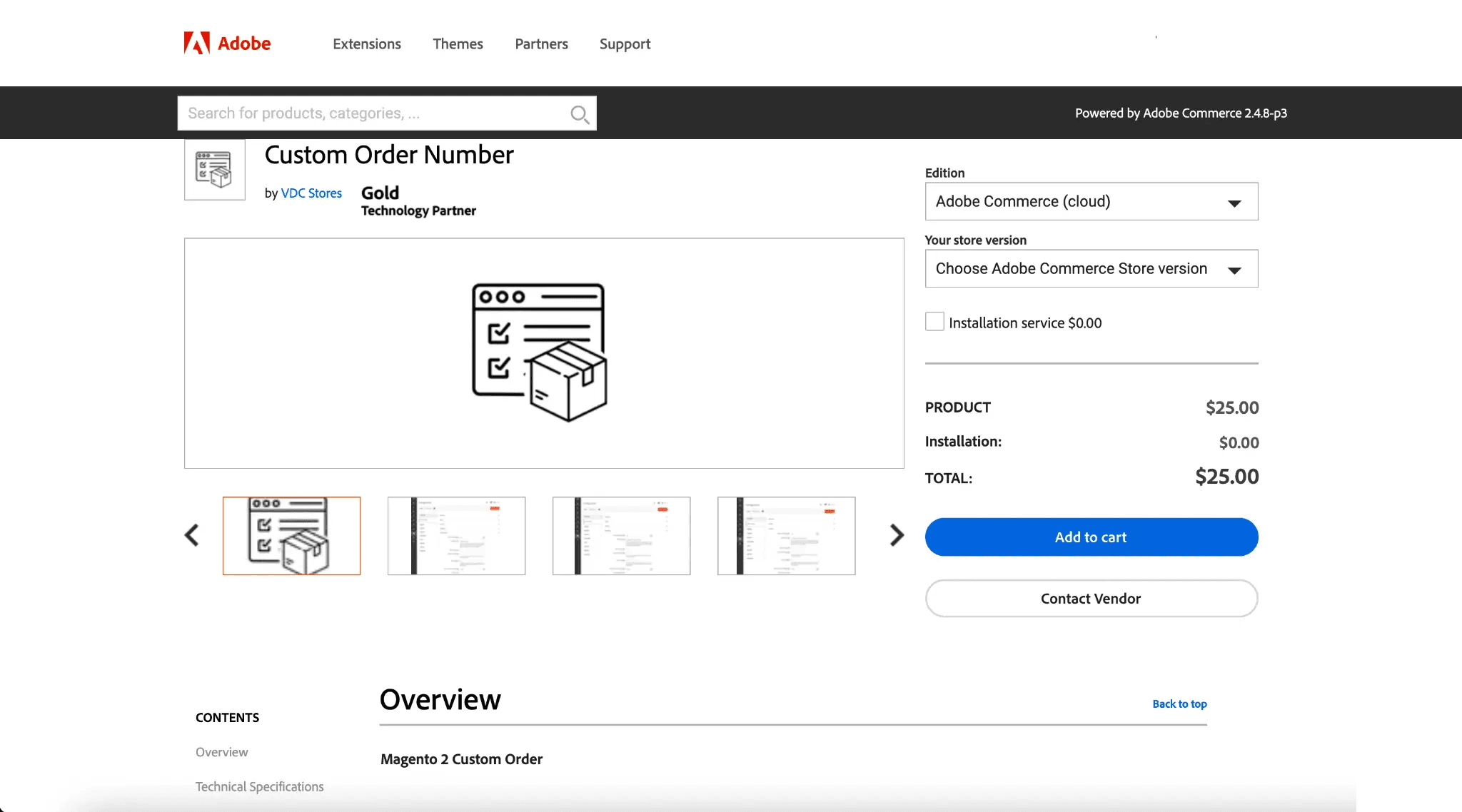
💲 抓取 Magento 商品价格(价格监控)
该场景用于持续跟踪 Magento Marketplace 商品页的价格变化与列表更新,例如:
https://commercemarketplace.adobe.com/vdcstore-module-customordernumber.html
你可以按需手动运行,也可以使用 定时爬虫 按固定频率监控(每天、每周或你设定的任意周期)。
操作步骤:
- 安装 并注册账号。
- 打开目标页面,例如:https://commercemarketplace.adobe.com/vdcstore-module-customordernumber.html
- 点击 AI Suggest Fields,生成适合监控的推荐字段(价格、可用性、更新时间等)。
- 点击 Scrape 获取最新快照,然后导出或设置定时运行。
字段(列)示例
| Column | Description |
|---|---|
| 🏷️ Product / Extension Name | 你要监控的商品/扩展名称。 |
| 🔗 Product URL | 作为监控目标的页面链接。 |
| 💲 Current Price | 抓取时刻的最新标价。 |
| 🧾 Pricing Model | 页面展示的计费方式:一次性、订阅、免费等。 |
| 🧑💻 Vendor / Publisher | 用于厂商维度追踪的发布者名称。 |
| 🧩 Category | 分类标签,便于对监控项分组。 |
| 🧰 Compatibility | 支持的版本/发行版(兼容性变化时很有用)。 |
| 🕒 Last Updated | 页面显示的“更新”日期(如有)。 |
| ✅ Availability / Status | 可用、下架等状态信息(如有)。 |
| 🖼️ Image URL | 便于在 Airtable/Notion 建档的图片/Logo 链接。 |
| 🧷 SKU / Identifier | 页面展示的唯一标识(SKU、模块名或列表 ID)。 |
🎯 为什么要用 Magento 爬虫工具
当你需要用于分析、运营或汇报的 可重复、结构化数据 时,抓取 Magento(Adobe Commerce)页面会非常高效。
常见使用理由包括:
- 电商运营:搭建结构化的扩展目录、对比不同厂商,并统一商品元数据,便于内部评估。
- 价格与竞品监控:通过快照或定时任务,持续追踪价格、列表更新与兼容性变化。
- 销售与合作:识别厂商/发布者,收集产品定位信息,建立外联名单(当页面有联系方式时,可搭配 Thunderbit 免费的 邮箱提取器 与 Phone Number Extractor)。
- 营销与研究:跨多个列表分析分类、评论数量与文案定位,洞察市场趋势。
Thunderbit 面向经常变化的真实网页而设计。你无需维护脆弱的选择器,而是让 AI 每次运行时重新理解页面结构,从而更能适应布局或组件变化。
🧩 如何使用 Magento Chrome 扩展
- 安装 Thunderbit Chrome 扩展:在 获取,并在 创建账号。
- 进入你要抓取的 Magento 页面:例如列表页 https://commercemarketplace.adobe.com/extensions/customer-support.html 或商品页 https://commercemarketplace.adobe.com/vdcstore-module-customordernumber.html
- 启用 AI 驱动的爬取:点击 AI Suggest Fields 生成字段,按需调整字段名或数据类型,然后点击 Scrape。如需更深层信息,使用 Scrape Subpages 访问链接页面,为每一行补全更多字段。
提示:如果要抓取多页列表,请开启 分页抓取(包含适用时的无限滚动)。若页面无需登录,通常 Cloud Scraping 更快;若需要保持登录态,则使用 Browser Scraping 更合适。
💳 Magento 爬虫的计费方式
Thunderbit 的 Magento 爬虫采用简单的积分(credit)机制:
- 1 credit = 1 条输出行(结果表中的一行)
- AI 驱动的抓取体验(AI Suggest Fields + Scrape)包含在内,且 数据导出免费
免费可体验内容:
- 免费计划:每月可抓取 6 个页面
- 免费试用:可免费抓取 10 个页面,适合在升级前验证字段设置与子页面补全效果
付费计划会随工作量扩展。如果你需要高频抓取(价格监控、目录更新、每周报表),通常 年付方案 更划算(相较月付有折扣)。
最新方案请查看 :
- Starter:$15/月 或 $9/月(年付)
- Pro 档:为团队提供更高月度额度,适合更大规模抓取(每年数千到数十万行)
❓ 常见问题(FAQ)
-
什么是 AI Powered Magento Scraper?
AI Powered Magento Scraper 是 Thunderbit 中的一套工作流,利用 AI 读取 Magento(Adobe Commerce)页面并转换为结构化的行与列。你先点 AI Suggest Fields 生成字段结构,再点 Scrape 提取商品名称、价格、图片、兼容性等信息。 -
Thunderbit 是什么?
是一款 AI 网页爬虫 Chrome 扩展,可将网站、PDF 与图片中的信息提取为结构化数据。它面向业务团队,强调快速配置、稳定提取,并可轻松导出到 Excel、Google Sheets、Airtable、Notion 等工具。 -
Thunderbit 能同时抓取列表页和商品详情页吗?
可以。你可以先抓取列表页快速生成表格,再用 子页面抓取 逐个进入商品/扩展详情页,为数据集补充更深层字段。对于需要点进详情才能看到的属性,这种方式尤其有效。 -
Magento 的分页抓取是怎么实现的?
Thunderbit 可根据站点实现方式,自动跟随“下一页”按钮或处理无限滚动,从而跨多页采集数据。这样你无需手动复制粘贴,也能收集多页累计上百行的数据。 -
从 Magento 页面能导出哪些数据?
取决于页面内容,你可以导出文本、数字、日期、URL、图片等。Thunderbit 支持导出到 Excel、Google Sheets、Airtable、Notion、CSV 与 JSON,方便直接接入你的报表或运营流程。 -
在动态电商页面上,AI 提取的准确性如何?
AI 提取的设计目标就是适应布局变化与混合结构(电商站点很常见)。如果某个字段需要更精确的规则,你可以为该列添加 Field AI Prompt,指导爬虫如何理解或格式化该字段。 -
可以自动监控 Magento 商品价格吗?
可以。使用 Thunderbit 的 定时爬虫,按你设定的频率运行(例如“每天早上 9 点”)。这对追踪价格变化、兼容性更新或上架/下架状态变化很有帮助。 -
Magento 抓取应选 Cloud Scraping 还是 Browser Scraping?
若页面公开且无需登录,通常 Cloud Scraping 更快,适合批量处理。若页面需要登录、地区设置或个性化内容,Browser Scraping 更合适,因为它会在你的 Chrome 会话中运行。 -
抓取 Magento(Adobe Commerce)页面是否合法?
合法性取决于网站条款、数据类型以及你的使用方式。请仅抓取你有权访问的数据,尊重隐私与知识产权,并遵守适用法律及网站服务条款。
📚 了解更多
- 从 开始
- 阅读:
- 阅读:
- 阅读:
- 阅读:
- 在 探索更多指南
想用 AI 网页爬虫(https://thunderbit.com/)为商品调研或价格监控构建一份干净的 Magento 数据集?安装 Thunderbit,点击 AI Suggest Fields,几分钟内就能抓取你的前几页数据。