Substack 爬虫

深受领先企业专业人士信赖












用 Thunderbit 解锁 Substack 数据
将 Substack 数据直接发送到你的应用
别再手动复制粘贴 Substack 出版物详情,比如作者名、文章标题和订阅人数了。使用 Thunderbit,只需点击一次,就能将提取的数据直接发送到 Google Sheets、Notion 或 Airtable。无需繁琐的手工操作,就能分析出版物趋势和内容表现。
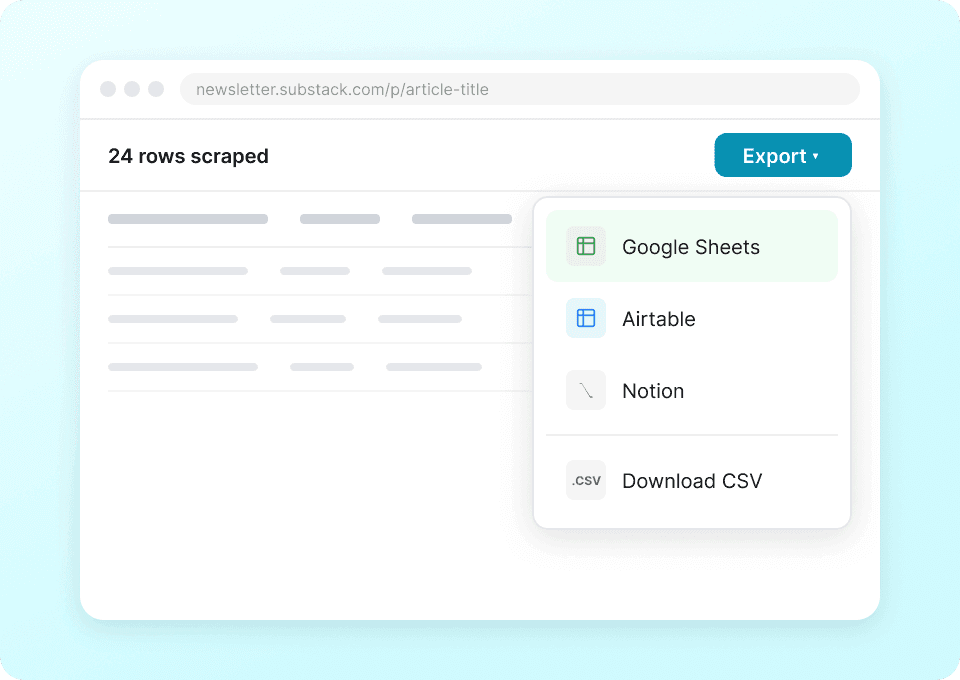
一个爬虫,既适用于 Substack,也适用于更多网站
别再为每个网站单独使用不同的爬虫。Thunderbit 开箱即用,支持 Substack,还内置了 50 多个适用于其他热门平台的预设模板。你可以提取出版物描述、文章内容等信息,然后继续用同一工具从其他任何网站采集数据。
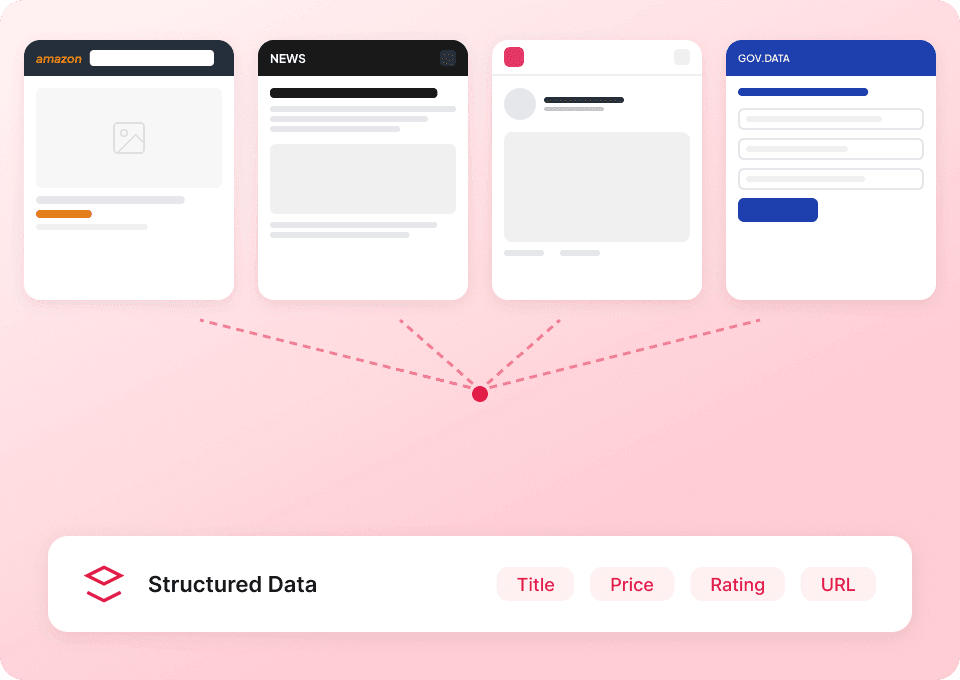
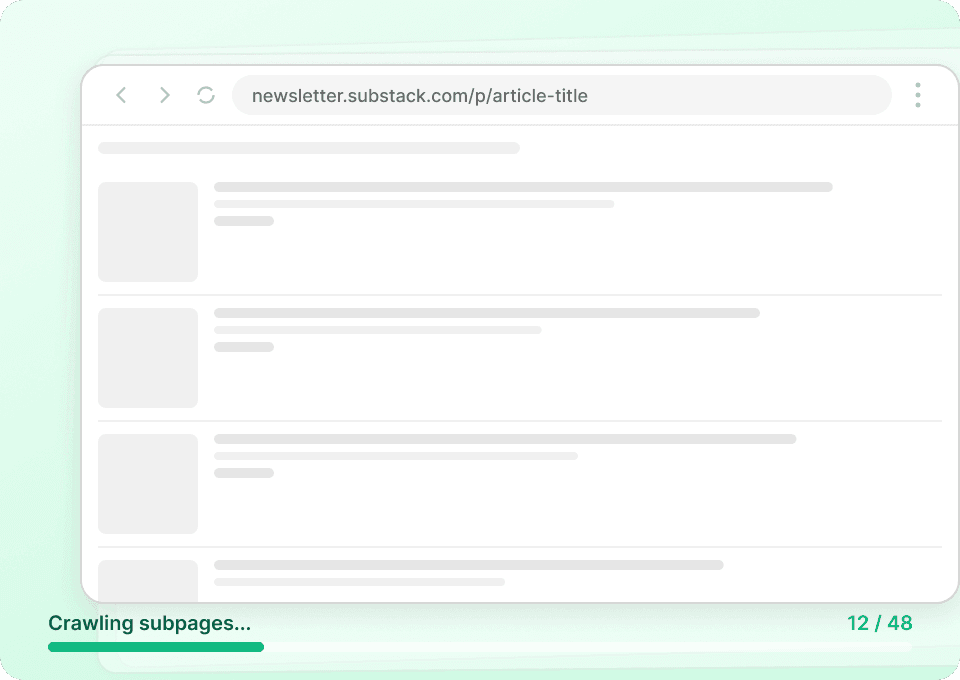
获取完整的 Substack 信息
Substack 出版物列表页通常只显示摘要。Thunderbit 会自动访问每篇文章的子页面,提取完整内容,为你提供一份完整的数据集。一次即可获取文章标题、作者名、出版物名称和文章内容。
还在为高效抓取 Substack 而发愁?
看看为什么 Thunderbit 在 Substack 数据抓取上比传统爬虫更胜一筹。
传统爬虫
老一套的做法Thunderbit
更智能的选择别只看我们的说法
看看用户如何评价 Thunderbit。






常见问题
相关 使用场景
探索 Thunderbit 网页爬虫的更多使用场景。

United Airlines 爬虫
只需指点点击,即可采集 United Airlines 航班数据,例如航班号、到达时间和出发机场——剩下的都交给 Thunderbit AI。
了解更多 ->
ReverseAustralia 爬虫
Thunderbit ReverseAustralia 爬虫可帮助您从 ReverseAustralia 的投诉和评论页面提取数据。借助 AI 智能字段推荐,快速收集电话号码、投诉内容、评论文本、用户名等信息,便于分析与研究。非常适合市场营销人员、研究者及企业获取结构化反馈数据。
了解更多 ->PeopleWhiz 爬虫
Thunderbit PeopleWhiz 爬虫可借助 AI 字段建议,从 PeopleWhiz 的搜索结果和个人资料中提取数据。轻松收集姓名、联系方式、位置等信息,用于研究、营销或线索开发。快速高效地将 PeopleWhiz 数据整理为结构化数据集。
了解更多 ->
Herold 爬虫
Thunderbit Herold 爬虫可帮助你仅用两步从 Herold 的企业和个人搜索结果中提取数据。借助 AI 智能字段推荐,快速收集企业名称、地址、电话、邮箱等信息,无论是用于获客、调研还是市场营销都非常高效。非常适合销售、市场和研究团队获取结构化 Herold 数据。
了解更多 ->
People-Search 爬虫
Thunderbit People-Search 爬虫可帮助您从 People-Search 个人资料和电话反查页面提取结构化数据。借助 AI 智能字段推荐,快速收集姓名、地址、电话号码、邮箱等信息,适用于调研、营销或获客。非常适合需要获取公开记录和联系方式的市场人员、研究者及企业。
了解更多 ->
iBegin 爬虫
Thunderbit 的 iBegin 爬虫可帮助你从 iBegin 网站提取商家搜索结果及详细信息。借助 AI 智能字段推荐,快速收集商家名称、联系方式、地址、评分等数据,助力获客、市场调研或营销分析。
了解更多 ->准备好让数据提取火力全开了吗?
加入已在使用 Thunderbit 自动化网页抓取流程的 10 万+ 专业人士行列。
免费试用可为 8 个网页提供无限额度。