

网页爬虫合法吗?这几乎是我每周都会从创始人、营销人员和数据爱好者那里听到的“百万美元问题”。
如今,51% 的互联网流量都来自机器人——这是自动化流量第一次超过人工流量——其中很大一部分又是用于商业情报、销售和 AI 训练的网页爬虫,难怪大家都想弄清楚法律边界到底划在哪。
今天你会看到一条新闻,说法院裁定抓取公开数据是允许的;明天监管机构又会警告社交媒体上的“非法”数据抓取。连我这种每天都在 Thunderbit 做 AI 网页爬虫工具的人,有时也会觉得这件事很绕。
所以,网页爬虫合法吗?答案不是简单的“是”或“不是”。它取决于你抓取的是什么、从哪里抓取、你如何使用这些数据,以及你所在国家的法律怎么规定。
这篇深度解析里,我会拆解法律全景,澄清一些常见误区,还会分享一些实用建议和亲身踩坑经验,帮你在合规前提下使用网页爬虫——不管你是独立创始人,还是财富 500 强的数据团队。
网页爬虫与法律:有明确界线吗?
如果你期待一句话答案,那我先帮你省点时间:法律并没有给网页爬虫划出一条清晰明亮的红线。
相反,现实更像是一张彼此交叠的规则拼图——数据所有权、隐私、知识产权、反黑客法律,以及那些臭名昭著的服务条款(ToS)。这些规则都可能同时适用,最终答案往往取决于你的具体场景(multilogin.com)。
我们来拆解三大法律领域:
- 数据所有权: 一般来说,事实和公开信息(比如价格或电话号码)不受版权保护。但创作性内容(文章、图片)和专有数据库可能受保护——尤其是在欧盟,“数据库权利”本身就是一项重要制度(cliffordchance.com)。
- 隐私: 现代隐私法(比如欧洲的 GDPR、中国的 PIPL)把个人数据视为受监管资产——即使这些数据是公开发布的。未经合法依据抓取姓名、邮箱或社交资料,都可能让你惹上麻烦(ico.org.uk)。
- 合同(服务条款): 很多网站在 ToS 里明确禁止抓取。虽然 ToS 不是法律,但法院可以把它视为具有约束力的合同。违反 ToS 可能导致诉讼;在某些情况下,如果你还绕过了技术限制,甚至可能触发反黑客法规(cliffordchance.com)。
所以,网页爬虫合法吗?有时合法,有时不合法,很多时候只能说“视情况而定”。关键都藏在细节里。
法律视角对比:美国、欧盟、英国、中国
下面这张表格可以快速看出主要地区对网页爬虫的态度:
| 地区 | 抓取公开数据 | 抓取个人/私密数据 | 执法与重点 |
|---|---|---|---|
| 美国 | 一般允许抓取公开数据(见 hiQ v. LinkedIn)。违反 ToS 可能面临民事诉讼。 | 若你突破登录限制或滥用个人数据,则受限或不合法。州法律(如 CCPA)也可能适用。 | 停止侵权函、IP 封锁、诉讼。如果绕过技术屏障,CFAA 可能适用。 |
| 欧盟 | 对非个人、公开数据有条件允许。数据库权利可能适用。欧盟 AI 法案(2026)还增加了 AI 训练数据透明度要求。 | 在 GDPR 之下受到严格监管——即使是公开的个人数据也需要合法依据。 | 数据保护机构可因隐私违规处罚。版权和数据库权利也会被执行。欧盟 AI 法案禁止为 AI 抓取人脸图像。 |
| 英国 | 与欧盟类似。公开的非个人数据可以抓取,但必须尊重数据权利和合同。 | 对个人数据要求严格——适用英国 GDPR。Computer Misuse Act 会将未经授权访问定为犯罪。 | ICO 可因数据保护违规处罚。法院也可能执行 ToS。 |
| 中国 | 监管较严。公开、非个人数据可在内部使用场景下抓取,但整体环境比较谨慎。 | 限制很强——PIPL 要求个人数据必须取得同意。反不正当竞争法也可能适用。 | 大规模抓取可能涉及刑事案件。法院也会用不正当竞争法制止未经授权的抓取。 |
网页爬虫合法吗?需要考虑的关键法律因素
那么,到底是什么决定你的抓取项目是合法还是高风险?主要看这些因素:
- 公开数据还是私密数据: 抓取任何人都能在开放网页上看到的数据,一般更安全。抓取需要登录、付费墙或技术屏障后面的内容?这很可能不合法(thunderbit.com)。
- 数据性质: 个人数据(姓名、邮箱、资料页)会触发隐私法。受版权保护的内容(文章、图片)不能整篇照搬。纯事实信息(价格、天气)通常风险更低(oxylabs.io)。
- 使用目的: 内部分析或研究通常比重新发布或出售抓取数据更容易被接受。把抓来的数据直接拿去和原网站竞争?这基本就是诉讼预告(thunderbit.com)。
- 是否遵守网站规则: 一定要查看 robots.txt 和 ToS。robots.txt 不具有法律约束力,但尊重它是最佳实践。违反 ToS 可能导致民事诉讼,甚至更严重的后果(promptcloud.com)。
- 技术措施: 以接近真人的速度抓取,并且不要绕过安全措施,这点非常关键。狂轰服务器或绕过验证码,可能会越线到“黑客”范畴(cliffordchance.com)。
2024–2026 年发生了什么:关键判例与监管变化
自 2023 年以来,网页爬虫的法律环境发生了显著变化。下面这些进展,每个做爬虫的人都应该知道:
重要判例
-
Meta v. Bright Data(2024): 美国联邦法院裁定 Meta 的服务条款并不禁止未登录用户抓取公开数据。法官认为,“访客只有拥有账户后才算‘用户’。” Meta 随后撤回了其余主张。这是公开数据抓取的一次里程碑式胜利。
-
X Corp v. Bright Data(2024): Twitter(现 X)在类似诉讼中败诉,进一步强化了同一原则:未登录情况下抓取公开可访问数据,并不违反 ToS,因为抓取者从未同意过这些条款。
-
Reddit v. Perplexity AI(2025 年 10 月): Reddit起诉 Perplexity AI 和多家抓取服务提供商,援引 DMCA,并指控其规避反机器人系统。这表明平台正在采取新的法律策略:不再主要依赖 CFAA,而是转向版权和反规避主张。
-
NYT v. OpenAI(2025 年 3 月): 联邦法官允许《纽约时报》针对 OpenAI 的版权诉讼继续推进,驳回了 OpenAI 的驳回请求。这可能会为“使用抓取内容训练 AI 模型是否属于合理使用”建立重要先例。
-
Anthropic 和解案(2025 年 9 月): Anthropic 同意支付 15 亿美元,和解一宗关于使用受版权保护文本训练其 AI 模型的美国版权集体诉讼——这说明“为 AI 而抓取”的成本是真实存在的。
大趋势:从 CFAA 转向合同法和版权法
趋势已经很清楚:CFAA(《计算机欺诈和滥用法》)作为对抗公开数据抓取者的武器,正在失去威力。 过去试图用 CFAA 对付公开数据抓取的公司——Meta、X、LinkedIn——大多都没能成功。法律战场正在转向:
- 合同法(违反 ToS——但法院也在说,没同意条款的非用户未必受其约束)
- 版权主张(尤其是 AI 训练数据)
- 反规避法规(DMCA 第 1201 条)
对爬虫使用者来说,这意味着法律风险并没有消失,只是换了地方。
监管变化
- CCPA 2026 更新: 加州修订后的 CCPA 规定于2026 年 1 月 1 日生效,新增了自动化决策技术(ADMT)、风险评估和数据经纪人义务相关规则。
- 新的美国州级隐私法: 印第安纳州、肯塔基州和罗德岛州都在 2026 年实施了全面隐私法。
- 欧盟 AI 法案: 完整执法将从2026 年 8 月 2 日开始——要求 AI 开发者披露训练数据来源、尊重版权退出机制,并禁止为 AI 系统抓取人脸图像。
- AI 出版者问责法案(2026 年 2 月): 这是一个拟议中的美国法律,要求 AI 公司在抓取内容之前先获得许可并向出版者付费。
主要平台的爬虫政策:你需要知道什么
并不是所有网站对抓取的态度都一样。下面按平台拆解一下这些大站允许什么、会拦什么,以及法院怎么说:
| 平台 | ToS 中对抓取的规定 | 技术防御 | 法律执行 | 实践上相对安全的做法 |
|---|---|---|---|---|
| Google(搜索与地图) | ToS 禁止自动化访问。Maps Platform 还有明确的“禁止抓取”条款。 | SearchGuard JS 挑战、验证码、速率限制。2025 年更新 robots.txt,阻止 AI 爬虫。 | 2025 年 12 月起以 DMCA 起诉爬虫方。积极阻止 AI 爬虫(Anthropic、Meta、OpenAI)。 | 抓取公开的 Google 地图商家数据在法律上有一定依据(hiQ 先例),但会遇到技术拦截。尽量使用官方 API。 |
| Amazon | 在使用条件中明确禁止一切抓取(“不得使用机器人、蜘蛛、爬虫或其他自动化方式”)。 | 强力反机器人检测、验证码、IP 封锁。robots.txt 阻止除 Googlebot/Bingbot 外的所有机器人。自 2025 年起明确阻止 AI 爬虫。 | 2025 年 11 月起诉 Perplexity AI。经常发出停止侵权函。2026 年 3 月更新 BSA,加入 AI 代理规则。 | 公开商品数据(价格、列表)在美国法下属于事实信息,可抓取,但 Amazon 反击很强。要限速,避免抓取个人数据。 |
| LinkedIn(领英) | ToS 禁止抓取;访问服务需要用户同意。 | 大多数资料数据都有登录墙,反机器人检测、速率限制。 | hiQ 案确认抓取公开资料不构成 CFAA 违规,但当使用虚假账号时,LinkedIn 在合同/不正当竞争主张上胜诉。 | 可见的公开资料页(无需登录即可查看)在法律上更站得住脚。绝不要创建虚假账号,也不要抓取登录后才能看到的数据。 |
| Meta(Facebook 与 Instagram) | ToS 禁止抓取;对登录状态与未登录数据有不同规则。 | 大多数内容有登录墙,配备先进反机器人检测。 | 2024 年输给 Bright Data——法院裁定 ToS 不适用于未登录抓取者。Meta 撤回了其余主张。 | 未登录就能看到的公开数据(商业主页、公开帖子)相对安全。绝不要抓取私密资料或登录后数据。 |
| X(Twitter) | 2023 年更新 ToS,禁止在未经书面同意的情况下进行任何抓取和爬取,并取消了原先的 robots.txt 例外。 | robots.txt 屏蔽所有爬虫(Disallow: /)。Cloudflare Turnstile 挑战。严格速率限制(每小时 300 次请求)。IP 声誉评分。 | 在公开数据案中输给 Bright Data,但在技术层面持续强力限制访问。 | 公共推文和资料页在法律上有一定依据,但到 2026 年,X 的技术防线仍是最难突破的之一。没有高级代理基础设施时,大概率会被拦。 |
结论很明确: 法院一再裁定,抓取公开可见且未登录即可访问的数据并不违反 CFAA。可平台仍然可能从合同法、版权或反规避角度继续追责——而且它们也会通过技术手段让你非常难受。一定要负责任地抓取。
AI 训练数据与网页爬虫:新的法律前沿
如果你关注 2026 年的新闻,就会知道:为了训练 AI 模型而抓取数据,已经成了最热门的法律战场。现状如下:
- 版权诉讼不断增加。《纽约时报》、作家和出版商已经起诉 OpenAI、Anthropic 等公司,指控为了训练 LLM 大规模抓取受版权保护内容并不属于“合理使用”。Anthropic 在 2025 年就一宗重大集体诉讼达成 15 亿美元和解——这说明为 AI 而抓取的成本是真实存在的。
- “合理使用”抗辩并不稳。 美国法院尚未就“用抓取数据训练 AI 是否属于合理使用”给出最终定论。早期判决显示,这很大程度取决于数据是怎么获得的,以及AI 输出被怎么使用。
- 新立法正在推进。 AI 出版者问责法案(2026 年 2 月提出)希望要求 AI 公司在抓取内容前获得许可并向出版者付费。
- 欧盟 AI 法案(2026 年 8 月全面执法)要求 AI 开发者披露训练数据来源、尊重可机器读取的版权退出机制(依据版权指令的 TDM 例外),并标注 AI 生成内容。同时,它也禁止 AI 系统从互联网上抓取人脸图像。
- AI/LLM 爬虫激增。 仅用 8 个月,AI 爬虫在网页流量中的占比就从 2.6% 增长到 10.1%,增长了四倍。OpenAI 的 GPTBot 单独就增长了 305%。对此,Amazon、Reddit、《纽约时报》等大站都在更新 robots.txt,明确阻止 AI 爬虫。
这对你意味着什么: 如果你抓取数据只是做传统业务用途(线索开发、价格监控、市场研究),这些 AI 相关规则未必直接适用。但如果你要把抓到的数据喂给 AI 模型,那就务必要格外谨慎,并先咨询法律意见。
全球网页爬虫法律概览:快速对比
我们把视角拉大一点,看看全球规则到底怎么分布:
- 美国: 没有一刀切禁令。抓取面向公众的网站通常是合法的(hiQ v. LinkedIn),而 2024 年 Meta 和 X Corp 的判决进一步强化了公开数据抓取的法律基础。但如果你绕过登录或技术封锁,仍可能触发 CFAA。现在的趋势是公司更多转向合同法和版权主张。隐私法也在快速扩张:CCPA 已于 2026 年 1 月 1 日迎来重大更新,包括自动化决策和数据经纪人义务的新规则。印第安纳州、肯塔基州和罗德岛州也在 2026 年通过了全面隐私法。
- 欧盟: 隐私法规非常严格。即使是公开的个人数据,GDPR 也适用。数据库权利可能阻止对结构化数据的大规模抓取(cliffordchance.com)。新变化: 欧盟 AI 法案将于 2026 年 8 月 2 日全面执法,要求 AI 开发者披露训练数据来源并尊重版权退出机制。该法案还禁止为 AI 系统从互联网上抓取人脸图像。
- 英国: 脱欧后规则与欧盟相近。公开数据可以抓取,但个人信息抓取受到严格监管。Computer Misuse Act 可能把未经授权访问定为犯罪。
- 中国: 限制非常严格。PIPL 和《数据安全法》要求个人数据必须取得同意。法院也会用反不正当竞争法来阻止损害企业利益的抓取行为(malwarebytes.com)。
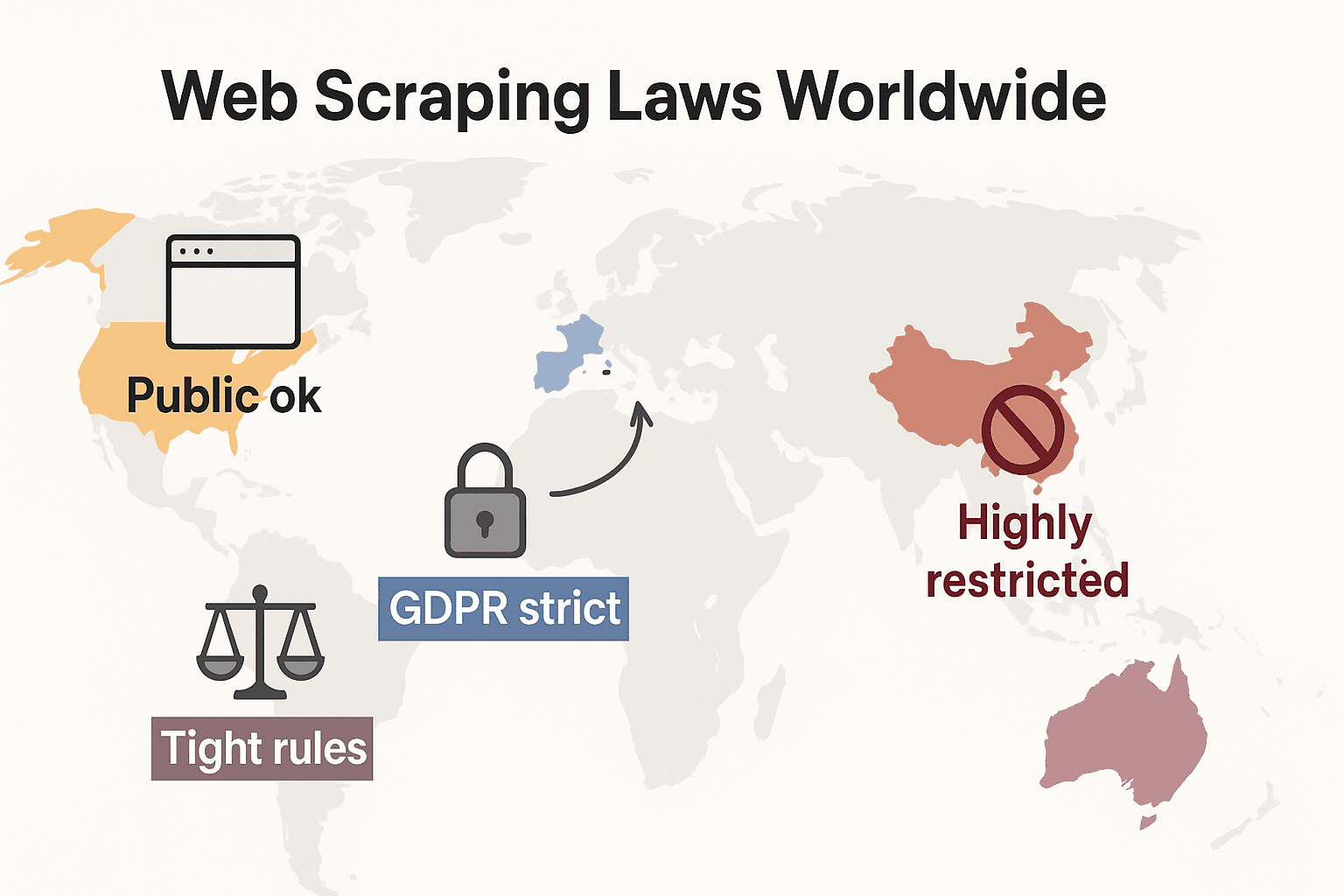
总之,出于内部使用目的去抓取公开、非个人数据,通常是最安全的。其他情况?先查本地法律,再小心行事。
关于网页爬虫合法性的常见误区
下面这些误区,我几乎每次都会听到,今天就来逐个拆掉:
- 误区 1:“网页爬虫一律违法。”
错。没有哪条法律一刀切禁止所有网页爬虫。关键在于你抓什么、怎么抓(oxylabs.io)。 - 误区 2:“只要数据是公开的,我就可以随便怎么用。”
也不完全对。公开数据仍可能受隐私法或版权法保护,ToS 也可能限制某些用途(ico.org.uk)。 - 误区 3:“网页爬虫和黑客攻击是一回事。”
不是。抓取公开网页不是黑客攻击。绕过登录或技术屏障则是另一回事(calawyers.org)。 - 误区 4:“只要没被抓到就没事。”
这是很危险的想法。很多网站都有反机器人技术,而且它们会注意到。沉默不等于同意。 - 误区 5:“只要注明来源,或者只是内部用,就没问题。”
署名并不能覆盖版权法或隐私法。内部使用更安全,但绝不是免死金牌。 - 误区 6:“所有网页爬虫都会侵犯隐私。”
并不是所有抓取都涉及个人数据。但如果在没有任何保护措施的情况下大规模抓取个人信息,几乎总是违法的(oxylabs.io)。 - 误区 7:“网站 ToS 禁止抓取,那抓取就一定违法。”
不一定。2024 年,Meta v. Bright Data 和 X Corp v. Bright Data 的判决说明:如果用户从未同意这些条款,ToS 可能无法约束他们——也就是说,如果你在未登录、未创建账户的情况下抓取,网站 ToS 未必适用于你。这仍然是一个在发展中的领域,但变化非常重要。
如何合法抓取数据:合规最佳实践
下面是我最常用的合法、合规网页爬虫清单:
- 阅读并尊重网站的服务条款。 如果它写着“禁止抓取”,就考虑停手,或者先申请许可(ql2.com)。
- 只抓取公开数据。 如果需要密码才能访问,那就是受限内容——不要抓(thunderbit.com)。
- 检查 robots.txt,并礼貌地抓取。 它不具法律约束力,但属于良好礼仪。不要猛刷服务器——把请求间隔拉开(promptcloud.com)。
- 除非你有合法依据,否则避免抓取个人数据。 如果必须收集,要遵守 GDPR/CCPA,并尽量减少收集量。
- 不要整篇重新发布抓来的内容。 最好加上分析或增值,或者先获得许可(thunderbit.com)。
- 不要在未检查版权的情况下,把抓来的内容喂给 AI 模型。 法律环境变化很快——如果你的用途是这个,先咨询专业意见。
- 有官方 API 或数据导出时,优先使用。 这些接口本来就是为这类用途设计的,通常更安全(thunderbit.com)。
- 保持透明和可追溯。 如果你收集个人数据,要告知相关人员,并保留操作记录。
- 最小化收集并妥善保护数据。 只收集你需要的内容,保证准确,并安全存储。
- 持续关注变化,边缘场景先问律师。 法律和判例都在快速变化——尤其是欧盟 AI 法案和美国州级隐私法。拿不准时,找专业人士。
试用 Thunderbit Chrome 扩展,实现合规抓取
合法使用网页爬虫工具:企业需要知道什么
像 Thunderbit 这样的网页爬虫工具,让不会写代码的人也能轻松采集数据,但你仍然要负责任地使用:
- 选择以合规为核心的工具。 比如 Thunderbit 只抓取你在浏览器里能看到的内容——不会偷偷调用 API,也不会未经授权访问(thunderbit.com)。
- 坚持正当使用场景。 内部分析、市场研究和竞争对手价格监控通常都比较安全。把抓取数据重新发布或出售?风险高得多。
- 按合规方式配置工具。 设置爬取延迟,遵守 robots.txt,只使用真正需要的模板字段。
- 尽量内部使用。 内部使用抓取数据,比重新发布更安全。
- 培训你的团队。 确保每个人都懂规则和最佳实践。
- 利用内置合规功能。 Thunderbit 会提醒高风险网站,以接近真人的速度抓取,并且不会把你的数据存到他们的服务器上。
- 别硬来。 如果工具抓不了某个网站,就不要想办法绕过去。不是所有数据都能在不承担风险的情况下拿到。
Thunderbit 的做法:让合规的 AI 网页爬虫成为可能
在 Thunderbit,我们花了很多时间思考合规问题。下面是我们的 AI 网页爬虫如何帮助用户走在法律边界内:
- 只抓取你看得到的内容。 Thunderbit 在你的浏览器会话中运行,所以它无法访问你手动都无法复制的数据。
- 通过提示引导用户。 如果你尝试抓取有严格反爬政策的网站,Thunderbit 会提醒你。
- 以接近真人的速度抓取。 不管是本地还是云端抓取,Thunderbit 都不会猛刷服务器。
- 可自定义数据选择。 我们的 AI 会建议相关列,帮助你只收集真正需要的内容。
- 支持子页面和分页处理。 Thunderbit 像真实用户一样浏览网站,并尊重其结构。
- 隐私与安全。 你的数据只属于你——Thunderbit 不会存储或重复使用。
- 便于合规导出。 可直接导出到 Google Sheets、Airtable、Notion 或 CSV,方便安全的内部使用。
- 支持定时和自动化。 你可以设置合理间隔的周期性抓取。
- 多语言支持。 Thunderbit 的界面支持 34 种语言,让全球用户都能更容易合规使用。
- 模板持续更新。 我们为热门网站提供的即时模板会随着法律和技术变化保持同步。
把合规逻辑直接写进产品后,Thunderbit 就能帮助团队拿到所需数据,同时避免法律麻烦。
继续领先:应对网页爬虫中的法律与技术变化
探索更多网页爬虫指南 Get Started Free
网页爬虫不是“设好就不用管”的工具。法律和网站结构都在不断变化。想要保持领先,可以这样做:
- 关注法律进展。 2024–2026 年变化速度明显加快——留意科技法律新闻、监管动态和行业博客(比如 Thunderbit 的博客)。重点关注欧盟 AI 法案的执法时间(2026 年 8 月)、新的美国州级隐私法,以及持续推进的 AI 版权案件。
- 适应技术变化。 网站会不断更新页面结构和反机器人防御。Amazon、X、Google 等主要平台在 2025–2026 年都明显加强了防护。Thunderbit 的 AI 和模板会尝试自动适配这些变化。
- 有官方 API 就优先用。 如果网站改成付费 API 模式,可以考虑切换过去,以提高稳定性和合规性。
- 定期审计你的抓取流程。 记录数据来源,检查 ToS 或政策变化,并根据需要调整策略。
- 利用 Thunderbit 的模板更新。 我们团队会持续更新模板,这样你就不用担心页面结构变化或新的合规要求。
- 保持灵活。 如果某个数据源风险太高,就换一个,或者寻找合作方式。
只要工具和思路都对,你就能让数据管道持续运转——而不用踩上法律地雷。
结语:如何穿越网页爬虫的法律迷雾
网页爬虫本身并不违法——它是商业、研究和创新的强大工具。但和任何工具一样,它也有规则。关键在于理解你抓取什么、如何抓取,以及你会如何使用这些数据。尊重当地法律,遵守网站政策,并使用像 Thunderbit 这样以合规为导向的工具,才能让你的操作始终站得住脚。
2024–2026 年的判例(Meta v. Bright Data、X Corp v. Bright Data)增强了公开数据抓取的法律基础,但围绕 AI 训练数据、版权主张和欧盟 AI 法案的新风险也正在出现。各平台的政策差异很大——Google、Amazon、LinkedIn、Meta 和 X 的执行方式都不一样——所以在抓取前一定先了解清楚。
如果你拿不准,尤其是在大型或敏感项目上,先咨询法律意见。并且记住:法律环境一直在变化,所以要保持信息更新和行动灵活。
想了解更多关于网页爬虫、合规和自动化的内容?欢迎查看 Thunderbit 博客 获取更多指南,或者直接试试 Thunderbit 的 Chrome 扩展。
常见问题
1. 网页爬虫在所有地方都违法吗?
不。网页爬虫本身并不违法,但是否合法取决于你抓什么、怎么抓,以及你身处哪里。抓取公开的非个人数据用于内部使用,在大多数地区通常是允许的;但抓取个人数据、受版权保护的数据,或者违反网站条款,都可能违法(oxylabs.io)。
2. 如果我忽略 robots.txt,抓取就违法吗?
robots.txt 没有法律约束力,但最好还是尊重它。单纯忽略 robots.txt 并不会自动让你被起诉,但一旦发生争议,它可能会让你看起来像一个“坏行为者”(promptcloud.com)。
3. 我能抓取 Google、Amazon 或 LinkedIn 吗?
这很复杂。这三家都在 ToS 中禁止抓取,但法院已裁定,ToS 可能无法约束未登录用户(见 2024 年的 Meta v. Bright Data 和 X Corp v. Bright Data)。抓取公开可见的数据(商品价格、商家列表、公开资料页)在美国通常有一定法律依据。不过,各平台的执行方式不同:Amazon 的法律动作最激进(它在 2025 年 11 月起诉了 Perplexity AI);LinkedIn 更依赖技术屏障和合同主张;Google 越来越多地使用基于 DMCA 的执法。一定要负责任地抓取,并预期会遇到技术反制。
4. 我能抓取 Facebook 或 Instagram 吗?
在 Meta v. Bright Data(2024)之后,不登录就抓取 Facebook 和 Instagram 的公开数据,法律基础更强了。法院裁定 Meta 的 ToS 不适用于非用户。但绝不要创建虚假账号,也不要抓取登录墙后的数据——那就越界了。
5. 我能抓取 X(Twitter)吗?
X 在 2023 年更新 ToS,禁止在未经书面同意的情况下进行任何抓取,并部署了很强的技术防御(Cloudflare Turnstile、每小时 300 次请求的速率限制、IP 声誉评分)。不过,Bright Data 在类似案件中胜诉——未创建账户就抓取的公开数据,不受 X 的 ToS 约束。从技术上看,X 到 2026 年仍是最难抓取的平台之一。
6. 抓取数据来训练 AI 模型合法吗?
这是 2026 年最大的开放问题。几起重大诉讼(NYT v. OpenAI、Anthropic 的 15 亿美元和解)都表明,法律风险相当高。欧盟 AI 法案要求披露训练数据来源并尊重版权退出机制。拟议中的 AI 出版者问责法案也会要求先获得许可并付费。如果你要为训练 AI 而抓取数据,建议先咨询法律意见再继续。
7. 使用 Thunderbit 这类网页爬虫工具最安全的方法是什么?
只抓取公开数据,尊重网站条款,除非有合法依据否则不要收集个人信息,并把数据用于内部。Thunderbit 通过只抓取你在浏览器里可见的内容,以及提醒你注意高风险网站,来帮助你保持合规(thunderbit.com)。
8. 我可以把抓取的数据用于商业用途吗?
要看情况。把抓取数据用于内部分析或研究通常更安全。重新发布或出售抓取数据,尤其是受版权保护或涉及个人信息的数据,风险要高得多,可能还需要许可或授权。
9. 我该如何跟上网页爬虫法律和技术变化?
关注科技法律新闻,监测目标网站的 ToS 或政策变化,并使用像 Thunderbit 这样会持续更新模板和合规功能的工具。2026 年最需要关注的事项:欧盟 AI 法案的执法(8 月)、持续进行中的 AI 版权案件,以及新的美国州级隐私法。拿不准时,咨询法律专业人士。
试用 AI 网页爬虫 Get Started Free




