如果你曾想从一个网站里精准拿到所需数据——可能是竞品价格列表、产品目录,或者一批最新销售线索——你一定懂这种感觉:标准爬虫工具能帮你完成 80%,但最后那 20% 呢?那才是真正有魔力、也最让人头疼的地方。在今天这个数据驱动的时代,企业根本没法接受“差不多对”。定制化提取和数据提取服务已经成了现代运营的基础。全球网页爬虫市场预计将从 2024 年的 7.54 亿美元增长到 。如果你的数据策略里没有定制爬取,你可能已经在市场里“隐身”了。
这些年,我一直在帮助各种团队——从精力充沛的初创公司到成熟的大企业——摆脱反复复制粘贴的苦差事,以及那些脆弱、千篇一律的一刀切工具。差别在哪?就在于掌握定制化数据提取。在这篇指南里,我会带你了解什么是定制提取、为什么它至关重要、(我和团队打造的 AI 网页爬虫)如何让它变得极其简单,以及怎样为你的业务挑选合适的数据提取服务。我还会分享几个“血泪教训”——毕竟,每个数据控都少不了几段这样的故事。
什么是定制提取?释放定制数据提取服务的力量
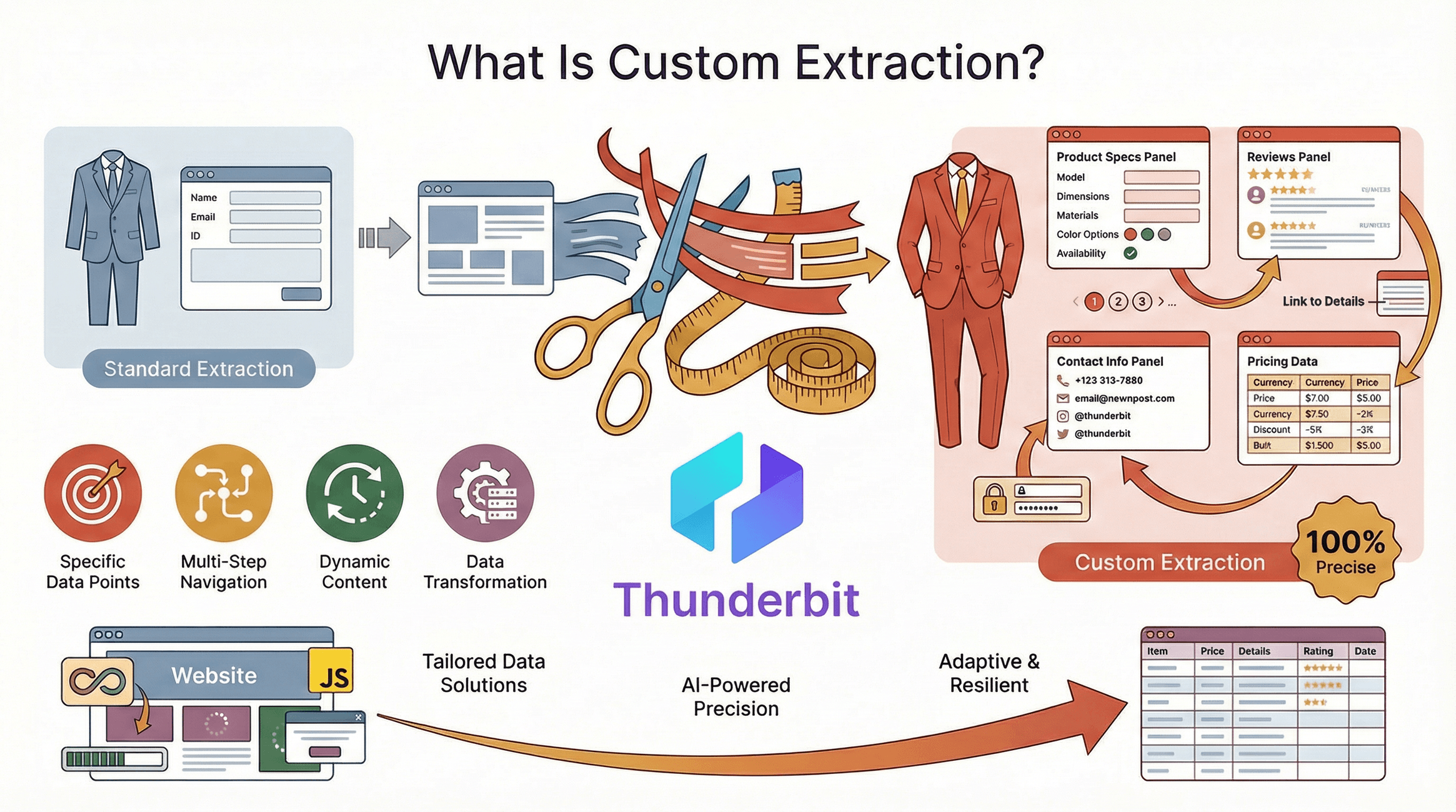 先从基础说起:定制提取,就是从对你的业务真正重要的网站中,精准拿到你需要的数据,并以你想要的格式输出。和只能抓取表面内容的标准爬虫工具不同,定制化数据提取更精准、更灵活,也更能扛住变化——即使网站结构复杂、内容动态加载,或者隔三差五改版也不怕。
先从基础说起:定制提取,就是从对你的业务真正重要的网站中,精准拿到你需要的数据,并以你想要的格式输出。和只能抓取表面内容的标准爬虫工具不同,定制化数据提取更精准、更灵活,也更能扛住变化——即使网站结构复杂、内容动态加载,或者隔三差五改版也不怕。
你可以把它想成订制西装,而不是买成衣。用了定制提取,你不再受限于“默认”字段或模板。你可以:
- 选取特定数据点(比如产品规格、评论或联系方式)
- 处理多步骤浏览流程(分页、子页面、登录)
- 适配动态内容(无限滚动、JavaScript 加载数据)
- 在提取过程中直接对数据进行格式化、清洗或转换
这为什么重要?因为真实的业务需求往往没那么简单。也许你需要先抓取产品列表,再逐个点击链接获取详细规格和评论。或者你想监控几十个页面上的竞品价格,但只关注某些 SKU。标准工具要么失效,要么漏数据,要么逼你变成半吊子的 HTML 侦探。相反,定制提取服务就是为这种场景而生的——而且常常还会借助 AI 和自然语言处理。
如果你想更深入了解定制爬取和标准爬取的区别,可以看看 。
为什么定制数据提取服务对业务增长如此重要
我们说点实际的。为什么你应该关心定制数据提取?因为它不只是一次技术升级,而是业务增长的加速器。定制提取服务能这样推动现实中的结果:
| 业务需求 | 定制数据爬取解决方案 | 典型效果 / 投资回报 |
|---|---|---|
| 线索开发 | 从目录、领英或点评网站抓取最新联系方式 | 人工调研时间最多减少 80%;线索名单更大、更相关 |
| 竞品价格监控 | 跟踪竞品网站价格和库存,即使页面布局动态变化 | 动态定价带来 4%+ 销售增长;利润率最高提升 15% |
| 市场情报与研究 | 大规模汇总新闻、评论或监管文件 | 数据利用率增长 50%+;决策更快、更有依据 |
| 产品目录更新 | 从多个来源提取产品信息,处理子页面和变体 | 目录始终保持最新;错误和手动更新更少 |
| 运营自动化 | 为报告、合规或库存设置定期爬取 | 数据上线时间快 85%;采集成本降低 73% |
(,)
结论很简单:定制提取不是奢侈品,而是竞争必需品。掌握它的公司,正在更快地压制对手、响应市场变化,并挖掘出真正能推动增长的洞察。
Thunderbit 的做法:让定制数据提取变得简单
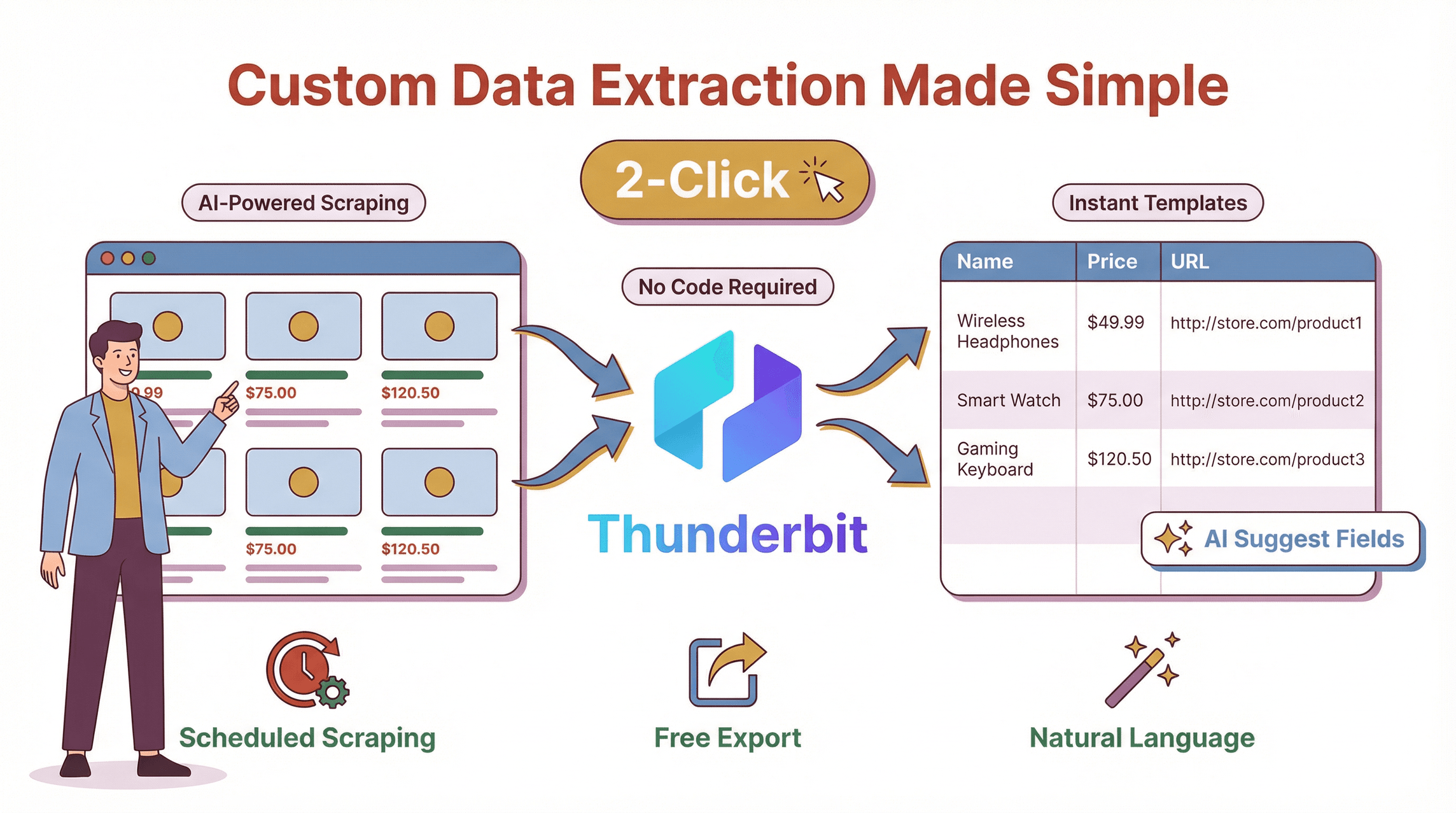
老实说,我之所以打造 Thunderbit,就是因为我看够了团队被那些笨重、代码密集型的爬虫折腾得焦头烂额——网站稍微一“抽风”,它们就坏了。Thunderbit 是一个 ,目标是让每个人都能轻松做定制化数据提取,而不只是开发者。
Thunderbit 的不同之处在于:
- AI 驱动的字段建议: 点击“AI 建议字段”,Thunderbit 会扫描页面,并推荐最适合提取的列,比如“产品名称”“价格”“图片 URL”或“邮箱”。再也不用猜,也不用反复调选择器。
- 自然语言提示: 想提取日期、翻译描述,或者给条目分类?直接用自然语言告诉 Thunderbit 就行。AI 会自己想办法完成。
- 两步抓取: 打开目标网站,启动 Thunderbit,然后点“抓取”。就这么简单。无需代码,无需模板(除非你想用),也没有麻烦。
- 处理复杂页面: Thunderbit 能应对分页、无限滚动、子页面,甚至 JavaScript 加载的动态内容。网站怎么变,它都能跟着适应。
- 子页面抓取: 想从每个条目里拿更多细节?Thunderbit 可以自动访问每个子页面(比如产品详情页),把表格丰富起来。
- 定时抓取: 用自然语言设置重复任务(比如“每周一上午 9 点”),剩下的交给 Thunderbit。
- 即用模板: 对于 Amazon、Zillow 或领英这类热门网站,Thunderbit 提供一键模板,无需配置。
- 免费导出数据: 可将数据导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON——没有付费墙,也没有限制。
Thunderbit 的使命很简单:让业务用户描述自己想要什么,然后让 AI 负责技术上的重活。它就像一个永远不累、也从不抱怨咖啡的 AI 研究助理。
步骤详解:用 Thunderbit 做定制数据爬取
下面我们用 Thunderbit 走一遍真实的定制提取流程。我会以产品目录为例,但如果是线索、评论或别的数据,步骤也大同小异。
步骤 1:安装 Thunderbit
前往 并添加到浏览器。注册一个免费账户——免费套餐无需信用卡。
步骤 2:打开目标网站
进入你想抓取的页面(例如包含产品列表的分类页)。
步骤 3:启动 Thunderbit 并使用 AI 建议字段
点击 Thunderbit 图标。再点“AI 建议字段”——Thunderbit 的 AI 会扫描页面,并建议诸如“产品名称”“价格”“图片 URL”等列。你可以按需重命名、添加或删除字段。
步骤 4:用字段 AI 提示词进行自定义
想提取某个特定内容?你可以为每个字段添加自定义指令,比如“将日期提取为 YYYY-MM-DD 格式”或“把描述翻译成西班牙语”。Thunderbit 的 AI 会在提取过程中应用你的规则。
步骤 5:如有需要,启用分页或子页面抓取
如果数据分布在多页,打开分页功能。如果你需要子页面(如产品详情页)里的更多信息,就使用子页面抓取——Thunderbit 会自动访问每个链接,并把额外信息抓进表格。
步骤 6:点击“抓取”,看数据流入表格
Thunderbit 会自动处理导航和格式化,帮你提取数据。运行过程中你会看到预览表格。
步骤 7:导出数据
当你对结果满意后,可以直接导出到 。你也可以下载为 CSV 或 JSON。
就是这么简单。无需代码,无需模板(除非你想用),也不会再出现“这到底为什么不行?”的时刻。想了解更多,可以查看 。
将 Thunderbit 与其他数据提取服务对比
我们来稍微硬核一点。Thunderbit 和 Azure AI Document Intelligence,或者传统爬虫相比,表现如何?
| 功能 / 评估标准 | Thunderbit | Azure AI Document Intelligence | 传统爬虫(如 Octoparse、Scrapy) |
|---|---|---|---|
| 易用性 | 无代码、AI 驱动、两步配置 | 面向开发者、基于 API | 学习曲线陡峭,通常需要编码 |
| 定制提取 | 自然语言提示、字段 AI | 面向文档的自定义 ML 模型 | 手动配置、选择器、脚本 |
| 处理网页 | 支持(HTML、动态页面、子页面) | 不支持(主要面向文档 / PDF) | 支持,但难以应对动态网站 |
| 处理文档 / PDF | 支持(通过浏览器 / PDF 模式) | 支持(OCR、ML) | 有时可以,但能力有限 |
| 适应性 | AI 可适应页面布局变化 | ML 可适应新文档 | 网站一变就容易坏,需要更新 |
| 定时任务 | 内置,支持自然语言 | 通过 API,需要集成 | 有时支持,但配置复杂 |
| 导出选项 | Sheets、Excel、Airtable、Notion、CSV、JSON | API/JSON,需要开发集成 | CSV、Excel、数据库等,因工具而异 |
| 支持 | 现代 SaaS,响应快 | 企业级,正式支持 | 社区或厂商支持,因情况而异 |
| 价格 | 免费套餐,按需积分制 | 按使用量计费,面向企业 | 免费(开源)或月付方案 |
Thunderbit 的优势区间在于:面向想要强大能力、但不想承受折腾的数据提取业务用户。Azure 非常适合大规模文档处理,但不适合抓网站。传统爬虫在合适的人手里很强,但需要技术能力和持续维护。
想看更深入的对比,可以阅读 。
如何为你的需求选择合适的定制数据提取服务
选择数据提取服务,不只是看功能,更重要的是是否适合你。下面这份清单可以帮你做决定:
- 数据质量与可靠性: 它能否提供准确、干净、完整的数据?能否在目标网站上测试?
- 灵活性与可定制性: 它能否处理你的特定网站、动态内容、登录或子页面?能否定义自定义字段或转换规则?
- 合规与伦理: 它是否遵守法律和道德规范?是否尊重隐私法规和网站条款?
- 可扩展性与性能: 它能否处理你的数据量和抓取频率?是否支持云端抓取或并行处理?
- 集成与工作流: 能否把数据导出到你的工具里(Sheets、Excel、CRM 等)?是否支持定时或自动化?
- 支持与文档: 是否有响应及时的支持和清晰的文档?是否提供教程或知识库?
- 安全性: 它能否安全处理你的数据?登录信息是否加密?是否有合规认证?
- 成本: 定价是否透明,并且对你的需求来说足够划算?是否有隐藏费用或付费墙?
把每个候选工具都拿来试用一下。抓一个真实网站,导出数据,看看它是否适合你的工作流。想了解更多建议,可以看看 。
将定制数据爬取整合进你的业务工作流
提取数据只是第一步,真正的价值在于把它变成日常运营的一部分。下面是把定制数据提取嵌入业务流程的方法:
- 自动化重复任务: 用定时抓取保持数据新鲜,比如每日价格检查、每周更新线索等。
- 把数据送进你的工具: 直接导出到 。再配合 Zapier、Make 或 n8n 继续自动化,例如把新线索推送到 CRM。
- 设置提醒: 集成 Slack 或邮箱,在关键变化发生时通知你,比如竞品降价或新产品发布。
- 在云端协作: 使用共享数据库(Airtable、Notion),让爬取的数据能被团队共同访问。
- 端到端自动化: 将爬取与 BI 工具(Tableau、Power BI)结合,做实时仪表盘,或者基于抓取数据触发动作(例如重新定价)。
想找点灵感,可以看看 。
从定制数据提取服务中最大化价值的最佳实践
想把定制提取的效果发挥到最大?这些是我总结出来的经验,有些还是吃过亏才明白的:
- 明确目标: 先搞清楚你到底需要什么数据,以及为什么需要。不要因为“能抓”就去抓,要有目的地抓。
- 从小开始,频繁测试: 先做小范围试点,检查数据质量,确认没问题再扩大规模。
- 监控数据质量: 定期抽查结果。为异常情况设置校验规则或提醒。
- 优化抓取频率: 只在需要时抓,不要过度抓取。抓太频繁可能会被封,还会惹怒 IT 团队。
- 保持合规与道德: 尊重网站条款、隐私法规和伦理规范。不要抓取敏感或受限制的数据。
- 利用字段提示词: 用 AI 提示词在提取过程中清洗、格式化或丰富数据。
- 保护你的数据: 谨慎对待凭证和抓取结果,使用加密和访问控制。
- 记录你的流程: 记下你抓什么、从哪里抓、多久抓一次。以后会少很多麻烦。
- 持续迭代与改进: 把定制提取当成一个不断演进的过程。随着需求变化不断优化方法。
想了解更多最佳实践,可以查看 。
结论与关键要点:用定制提取提升你的数据策略
定制数据提取和数据爬取服务,不只是数据极客的玩具——它们是任何想要快速行动、保持竞争力并做出更聪明决策的企业都必备的工具。手动复制粘贴和脆弱脚本的时代已经过去了。借助像 这样的 AI 工具,任何人都能掌握定制提取——无需编码。
你要记住这些:
- 定制提取 = 精准提取。 拿到对的数据,而不只是更多的数据。
- 商业价值是实打实的。 从销售到运营,再到市场研究,定制爬取都能带来真实 ROI。
- 易用性已经到来。 像 Thunderbit 这样的工具,让每个人都能用上数据提取。
- 集成才是关键。 让抓取数据成为日常工作流的一部分,而不是孤立存在。
- 选择要聪明。 根据需求匹配工具——测试、对比、迭代。
- 最佳实践决定成败。 明确目标、质量检查和合规标准,能让你的数据策略更稳健。
准备好提升你的数据能力了吗?,用一个真实业务问题试一次定制抓取。或者,如果你还想继续深入,去看看 ,那里有深度解析、教程,以及最新的 AI 驱动数据提取资讯。
网页就是一座信息金矿——定制提取就是你的镐。祝你抓取顺利!
常见问题
1. 什么是定制数据提取,它和标准爬取有什么不同?
定制数据提取,是指根据你的具体需求,从任何网站上提取你真正需要的数据,并以你想要的格式输出——即使网站很复杂或是动态的也没关系。标准工具通常只抓容易拿到的内容,而定制提取会根据你的业务需求和不断变化的网站布局进行适配。
2. 谁最能从定制数据提取服务中受益?
销售团队(线索)、营销团队(竞品追踪)、运营团队(自动化)、产品经理(目录更新)和市场研究人员(情报分析)都能从定制提取中获得巨大收益——尤其是在标准工具不够用的时候。
3. Thunderbit 如何让定制提取更简单?
Thunderbit 会用 AI 帮你建议字段、处理复杂导航(分页、子页面),并允许你用自然语言描述需求。无需编码,无需模板(除非你想用),而且能直接导出到你最常用的工具。
4. 选择数据提取服务时,我应该关注什么?
重点看数据质量、灵活性、合规性、可扩展性、集成选项、支持、安全性和成本。先拿真实需求测试,再决定是否采用。
5. 我怎样把定制数据爬取整合进业务工作流?
自动化重复任务,把数据导出到 Sheets/Excel/Notion,设置提醒,并使用 Zapier 或 n8n 这类工作流工具。目标是让网页数据成为你日常运营中的活数据,而不是一次性项目。
准备好看看定制提取能为你的业务做什么了吗?,开始把网页里的混乱变成清晰的业务洞察。
了解更多