
如果你在 2026 年需要网页数据,真正难的早就不是“能不能抓取”,而是“哪一层工具能让我用最少的设置、维护和基础设施成本拿到可用数据?”所以这篇文章会先看适配场景:追求速度就选 AI 网页爬虫;需要可重复的浏览器任务就选无代码工具;要考虑规模和反爬处理就选 API;如果团队想完全掌控,就选 Python 库。
快速答案
- 如果你想用最少设置,把页面最快变成表格,选 AI 网页爬虫。
- 如果你需要更明确的分页、定时、登录处理或可重复任务控制,选 无代码爬虫。
- 如果渲染、反爬防护、并发和稳定解封比界面简单更重要,选 爬取 API。
- 如果团队想完全掌控请求、解析、浏览器自动化、重试和部署,选 Python 库。
对大多数业务团队来说,常见错误是太早往更底层走。先从能可靠完成工作的最轻量工具开始,只有当工作流逼着你升级时,再依次从 AI 转到无代码,再到 API,最后才是代码。
在这里下载完整视觉素材包:。
快速对比表:一眼看懂网站爬虫工具
下面的价格信息已于 2026 年 5 月 12 日核对,来源为官方产品页、定价页或文档页。对于采用定制计费或按量计费的厂商,我会直接说明计费模式,而不是硬凑一个看似公平、实际上失真的月费数字。
| 工具 | 类别 | 最佳适用场景 | 入选 2026 榜单的原因 | 价格信号(2026 年 5 月核对) |
|---|---|---|---|---|
| Thunderbit | AI 网页爬虫 | 销售、运营、电商、房地产 | 从网页到结构化表格最快的非技术路径 | 免费版、付费层级、企业定价 |
| Kadoa | AI 提取平台 | 数据团队和大型持续性项目 | 适合自修复、Agent 式提取工作流 | 免费评估、按量计费和企业版 |
| Octoparse | 无代码爬虫 | 分析师和重复性运营任务 | 成熟的云端爬取和可视化任务构建器 | 免费版,Standard 版起价 $69/月,更高档位可选 |
| ParseHub | 低代码爬虫 | 技术型非程序员和研究人员 | 适合复杂网站的灵活导航逻辑 | 免费版,付费版起价 $189/月 |
| Web Scraper | 浏览器无代码爬虫 | 新手和轻量级可重复任务 | 简洁的网站地图模型,支持可选云端层 | 免费扩展程序,Cloud 版起价 $50/月 |
| Browse AI | 无代码机器人爬虫 | 监控类场景和以表格为中心的团队 | 非常适合重复监控和变更提醒 | 免费版、付费方案、托管层级 |
| Bardeen | AI 浏览器自动化 | GTM 和 revops 自动化 | 当爬取只是更大工作流中的一步时最合适 | 免费版,Basic 版起价 $10/月,Premium 和企业版可选 |
| ScrapeStorm | AI 辅助可视化爬虫 | 想要快速可视化配置的用户 | 手动选择器与 AI 辅助之间的实用桥梁 | 免费试用、付费方案、企业定价 |
| ScraperAPI | 爬取 API | 需要扩展请求量的开发者 | 简单 API 外加代理、验证码和渲染卸载 | 7 天试用,付费版起价 $49/月 |
| Bright Data Web Scraper | 企业级爬取平台 | 采购要求高、合规要求强的项目 | 这一组里数据采集栈最完整 | 按产品和按量计费 |
| Zyte | API + 反爬技术栈 | 开发者和数据团队 | 浏览器动作、JS 渲染和 IP 轮换能力强 | $5 免费试用额度,按量计费方案 |
| ZenRows | 爬取 API | 初创公司和开发团队 | 反爬 API 简洁,采用门槛低 | 免费试用,Developer 版起价 $69/月 |
| ScrapingBee | 爬取 API | 抓取 JS 很重的网站的团队 | 渲染是主要痛点时很有用 | 免费试用,付费版起价 $49/月 |
| Selenium | 开源浏览器自动化 | QA 风格流程和交互密集型爬取 | 在精确用户交互很重要的场景里仍然有价值 | 免费且开源 |
| Beautiful Soup | Python 解析库 | 轻量级 Python 爬取 | 处理杂乱 HTML 最容易上手的解析器 | 免费且开源 |
| Playwright | 现代浏览器自动化 | 现代 Web 应用和开发团队 | 脚本化浏览器爬取的现代最佳选择 | 免费且开源 |
| urllib3 | Python HTTP 库 | 想要底层请求控制的开发者 | 当你想直接掌控传输行为时很实用的基础库 | 免费且开源 |
如何选择合适的网站爬虫工具
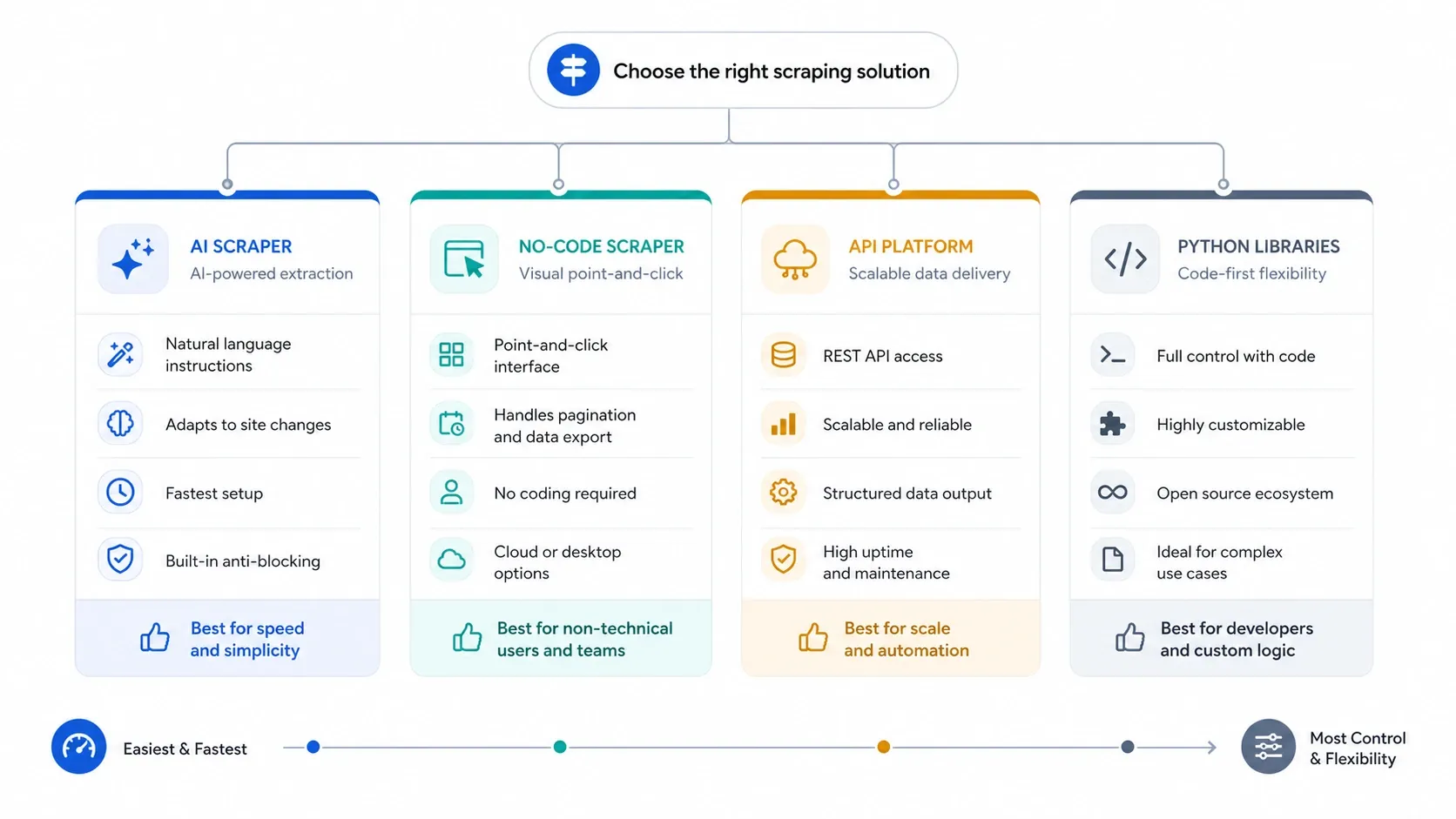
在比较品牌之前,先看这四个筛选条件:
- 首次拿到可用结果所需时间
如果工具不能很快拿出一张真实表格,它对大多数业务场景来说就已经输了一半。 - 维护成本
一个便宜但每次页面改版就崩的爬虫,其实一点也不便宜。 - 规模上限
浏览器扩展对每周 50 个页面可能很完美,但对每月 500 万次请求就会很糟糕。 - 工作流适配度
最适合 revops 的爬虫,通常不会是平台工程师最需要的那一个。
这个决策框架通常比团队想象得更简单:
- 如果你想抓取线索、列表或产品页,又不想碰选择器,先从 AI 开始。
- 如果你需要可重复任务、云端运行和更明确的控制,转向 无代码可视化构建器。
- 如果真正的问题是反爬、JavaScript 渲染和并发,就直接上 API。
- 如果你想自己掌控每一层,就用 Python 库,并接受维护成本。
最佳 AI 网页爬虫:快速业务工作流首选
如果你想要的是几乎无需配置、直接能进表格的数据,我最先会测试这一类工具。
1. Thunderbit
对于非程序员来说,Thunderbit 依然是这里最容易上手的起点。它的核心优势不只是笼统意义上的“AI”,而是把设置循环压缩得非常短。你打开页面,让 AI 建议字段,在需要时通过子页面补充数据,然后把结果直接送到团队正在使用的工具里。
- 最佳适用场景: 销售开发、电商监控、房地产采集,以及一直在浏览器里工作的运营团队。
- 突出之处: 从杂乱页面到结构化表格的最快路径。
- 注意: 如果你需要接近爬虫级别的逻辑,或者高度定制的工程流程,最终还是会走向 API 或代码。
- 价格信号: 免费版、自助付费层级和企业定价。
如果你想判断 AI 优先的爬取方式是否已经足够适合你的工作流,这个演示仍然是最快的方式:
2. Kadoa
Kadoa 是这组里更偏基础设施导向的 AI 选择。它适合你想要自修复提取,并且要处理比大多数浏览器扩展更大规模的持续性任务时。
- 最佳适用场景: 数据团队、内部情报项目和更大规模的重复提取工作负载。
- 突出之处: 类 Agent 的编排能力,以及更强的维护减负能力叙事。
- 注意: 对大多数业务用户来说,它比快速一次性爬取更重。
- 价格信号: 免费评估、按量计费和企业版。
最佳无代码网站爬虫:适合重复任务
一旦爬取任务开始重复发生,可视化工作流构建器和云端执行的重要性就会超过纯粹的“一键速度”。
3. Octoparse
当任务规模大过浏览器扩展,但又还没大到需要定制工程项目时,Octoparse 仍然是最值得信赖的无代码工具之一。它的价值在于云端运行、模板和成熟的可视化任务构建器组合。
- 最佳适用场景: 分析师、定价团队,以及具有现实运营重要性的重复采集任务。
- 突出之处: 比浏览器插件更强大,但不会把你直接推向代码。
- 注意: 这种灵活性是有代价的,学习曲线比 AI 优先工具更陡。
- 价格信号: 免费版,Standard 版起价 $69/月,更高付费层级可选。
如果你想在投入 AI 优先工具之前,先看看更传统的无代码工作区,这个 Octoparse 官方概览仍然很有参考价值:
4. ParseHub
ParseHub 之所以仍然重要,是因为有很多团队想要的任务逻辑,比轻量级 AI 爬虫能提供的步骤更多。它不是这个类别里最好看的产品,但依然很灵活。
- 最佳适用场景: 研究人员、记者,以及愿意承担更多设置工作的技术型非程序员。
- 突出之处: 条件逻辑和导航控制能力强于很多入门工具。
- 注意: 学习更慢,整体感觉也没有新产品那么现代。
- 价格信号: 免费版,付费版起价 $189/月。
5. Web Scraper
Web Scraper 是“先学基础,不先买平台”这类选择里最清爽的一个。如果你喜欢网站地图模型,它仍然是个不错的入门方式。
- 最佳适用场景: 新手、个人项目和较小的浏览器驱动任务。
- 突出之处: 设置直接,而且从本地扩展到云端方案的过渡也很自然。
- 注意: 当你需要更自适应的逻辑或更强的解封处理时,它会开始显得受限。
- 价格信号: 免费扩展程序,Cloud 版起价 $50/月。
6. Browse AI
当“爬取”和“监控”同样重要时,Browse AI 依然是很强的选择。它的机器人模型对业务用户非常直观,特别适合那种“盯住这个页面,告诉我哪里变了”的思路。
- 最佳适用场景: 竞品监控、价格追踪和以表格为中心的团队。
- 突出之处: 上手体验完善、支持持续监控,并且输出结果很适合自动化。
- 注意: 复杂的大规模任务,成本可能比 API 优先栈更快上升。
- 价格信号: 免费版、付费方案、托管层级。
如果你的团队评估的是页面监控而不是一次性提取,这个简短的官方概览依然是个不错的信号检查:
7. Bardeen
Bardeen 不只是看重爬取本身,更看重爬取之后会发生什么。当网页提取只是更大浏览器自动化工作流中的一步时,它最强。
- 最佳适用场景: GTM 运营、线索分发、CRM 交接和浏览器原生自动化。
- 突出之处: 围绕爬取本身的工作流自动化故事很强。
- 注意: 如果你唯一关心的是提取准确率,它并不是最干净利落的选择。
- 价格信号: 免费版,Basic 版起价 $10/月,Premium 和企业层级可选。
8. ScrapeStorm
对于既想要 AI 辅助、又希望保留更传统可视化爬取环境的用户来说,ScrapeStorm 仍然填补了一个有用的中间地带。
- 最佳适用场景: 目录爬取、电商页面采集,以及可视化配置的重复任务。
- 突出之处: 比很多老式可视化工具更容易上手。
- 注意: 它不如类别头部产品精致,在更难的网站上也会显得能力范围更窄。
- 价格信号: 免费试用、付费方案、企业定价。

当规模和反爬处理更重要时,最佳爬取 API
当真正的限制不再是“怎么选中数据”,而变成“怎么在高负载下保持稳定”时,就该进入这一类。
9. ScraperAPI
对于想把代理和请求成功率这些问题都交给工具处理的开发者来说,ScraperAPI 依然是最容易上手的 API 优先产品之一。
- 最佳适用场景: 需要快速从原型扩展到生产环境的开发者。
- 突出之处: 简单 API,再加上代理、验证码和渲染支持。
- 注意: 解析、重试和下游数据质量仍然要你自己负责。
- 价格信号: 7 天试用,付费版起价 $49/月。
10. Bright Data Web Scraper
当解封能力、代理库存、合规姿态和托管选项比简单易用更重要时,Bright Data 就是更重型的选择。
- 最佳适用场景: 企业级采集和对合规敏感的项目。
- 突出之处: 这是本文对比里最完整的数据栈,从代理到托管采集产品一应俱全。
- 注意: 如果你的团队工作流其实很简单,很容易买过头。
- 价格信号: 按产品和按量计费。
11. Zyte
对于想把浏览器动作、JS 渲染、轮换 IP 和反爬能力放在同一平台叙事里的开发团队来说,Zyte 仍然是很认真的选择。
- 最佳适用场景: 以工程为主导的爬取项目和可重复的提取系统。
- 突出之处: 强大的反检测栈和 API 优先工作流。
- 注意: 更适合有工程负责人的团队,不太适合业务用户。
- 价格信号: $5 免费试用额度,按量计费方案。
12. ZenRows
如果你想要反爬处理,但又不想经历企业级采购流程,ZenRows 是 API 类别里用户体验最清爽的选择之一。
- 最佳适用场景: 初创公司、开发者和精简的内部工具团队。
- 突出之处: 采用门槛相对低,同时反爬定位很明确。
- 注意: 它仍然是 API 产品,所以应用逻辑和 QA 负担还是在你这边。
- 价格信号: 免费试用,Developer 版起价 $69/月。
13. ScrapingBee
当你的核心需求是渲染后的页面,而且希望少做基础设施工作,尤其是面对 JS 很重的网站时,ScrapingBee 就很合适。
- 最佳适用场景: 需要渲染卸载的动态网站开发者。
- 突出之处: 围绕无头浏览和代理构建了一个简单 API。
- 注意: 它能减少基础设施工作,但不会消除你对良好爬取逻辑的需求。
- 价格信号: 免费试用,付费版起价 $49/月。
最佳 Python 网页爬取库:适合自定义技术栈
当控制比便利更重要,而且团队已经准备好自己承担维护责任时,这一组仍然是正确答案。
14. Selenium
Selenium 不是最新的浏览器工具,但在用户交互逼真度比原始爬取吞吐量更重要的场景里,它仍然很有价值。
- 最佳适用场景: 交互密集型流程、与 QA 重叠的场景,以及浏览器行为本身就是核心挑战的网站。
- 突出之处: 生态成熟,浏览器支持面广。
- 注意: 对很多爬取负载来说,它比更新的自动化栈更重、更慢。
- 价格信号: 免费且开源。
15. Beautiful Soup

Beautiful Soup 仍然是 Python 爬取栈里最容易上手的解析库。它不是完整的爬取平台,但把杂乱 HTML 转成可用结构时,它依然是最简单的方式之一。
- 最佳适用场景: 轻量级 Python 任务、静态 HTML 页面和快速原型。
- 突出之处: 认知负担低,解析容错性强。
- 注意: 最好和
requests、浏览器层或爬虫配合使用;单独使用时,它只负责解析。 - 价格信号: 免费且开源。
16. Playwright
对于需要在当今 Web 上做稳健浏览器自动化的开发团队来说,Playwright 是我默认推荐的现代选择。
- 最佳适用场景: JavaScript 很重的网站、现代浏览器自动化,以及已经习惯写代码的团队。
- 突出之处: 等待机制强、多浏览器支持好,API 也很干净。
- 注意: 并发、选择器、浏览器基础设施和数据校验仍然要你自己负责。
- 价格信号: 免费且开源。
17. urllib3
urllib3 之所以能上榜,是因为有些团队想要直接控制传输行为,而不是更高层的抽象。它不是面向新手的爬虫,但当你在搭建自己的技术栈时,它是很有用的基础库。
- 最佳适用场景: 想要精细控制重试、代理、会话和 HTTP 行为的开发者。
- 突出之处: 轻量、可靠,而且作为基础设施被广泛使用。
- 注意: 你几乎是在自己搭建整个技术栈。
- 价格信号: 免费且开源。
值得先测试的免费网站爬虫工具
如果你想先试再买,这份榜单里最值得从免费版开始的工具是 Thunderbit、Octoparse、ParseHub、Web Scraper、Browse AI、Bardeen、Selenium、Beautiful Soup、Playwright 和 urllib3。免费体验已经足够让你弄清楚自己真正需要哪种爬虫,这通常比第一天就纠结一份完美功能清单更重要。
按团队类型给出的精简推荐

- 销售、运营和电商团队: 先从 Thunderbit 开始;如果监控比子页面补充更重要,再对比 Browse AI。
- 分析师和重复性手工操作者: 先选 Octoparse;如果你需要更自定义的任务逻辑,再看 ParseHub。
- GTM 自动化团队: 如果爬取结果需要直接进入 CRM、Sheets 或浏览器工作流,选 Bardeen。
- 正在构建内部工具的开发团队: 根据你想承担多少栈所有权,在 ScraperAPI、ZenRows、Zyte 或 Playwright 之间选。
- 企业数据项目: Bright Data 和 Zyte 是这里更严肃的基础设施选项;如果维护减负是主要目标,Kadoa 是 AI 路线的替代方案。
什么时候该往更底层走
可以按这个升级路径来:
- 只要还没碰到重复性或边缘案例限制,就继续用 AI 网页爬虫。
- 当定时、分页和云端执行比一键简单更重要时,转向 无代码构建器。
- 当解封率、渲染和并发成为瓶颈时,转向 API。
- 当厂商抽象层的成本已经高过你自己掌控整个系统时,转向 Python 库。
大多数团队都会把顺序搞反:先过度设计,后来才发现更轻的工具本来就能解决真正的工作流问题。
最后结论
2026 年最好的网站爬虫工具,不是功能列表最长的那个,而是能以最低维护成本,把准确数据送进下一个工作流的那个。这也是为什么 AI 优先工具继续赢得运营型用户的青睐,无代码工具在可重复浏览器任务中依然重要,API 在规模和封锁问题面前占据主导,而 Python 库则继续掌控高控制力的技术栈末端。
如果你的目标是这周就拿到有用数据,先从简单的开始。如果你的工作负载已经在告诉你,解封率、浏览器渲染和工程控制才是真问题,那就有意识地往更底层走,不要只是出于习惯。
常见问题
1. 2026 年最适合非技术用户的网站爬虫工具是什么?
对大多数非技术团队来说,Thunderbit 和 Browse AI 这类 AI 优先工具仍然是最快的路径,因为它们能减少设置时间、选择器工作和维护成本。
2. 对 JavaScript 很重或有反爬保护的网站,我该选什么?
这类场景通常更适合 ScraperAPI、Bright Data、Zyte、ZenRows、ScrapingBee、Playwright 或 Selenium,而不是浏览器扩展。
3. 既然 AI 爬虫更强了,无代码爬取工具还有意义吗?
有。Octoparse、ParseHub、Web Scraper 和 Browse AI 在你需要更明确的任务控制、重复运行或浏览器可见调试时,依然非常重要。
4. 哪些工具最适合开发团队?
当工程团队负责工作流时,ScraperAPI、Zyte、ZenRows、ScrapingBee、Playwright、Selenium、Beautiful Soup 和 urllib3 都是最自然的选择。
相关阅读