在我用 Simplescraper 跑了上千次抓取之后,我不再只看成功了多少次,反而开始记录失败案例。这个转变——从“它跑通了吗?”变成“这次为什么又坏了?”——教会我的东西,比任何文档页面都多。
Simplescraper 是一款不错的 Chrome 扩展,可以在不写代码的情况下从网站提取数据。它在 Chrome Web Store 上拥有 ,界面也足够直观、上手友好,已经在无代码爬取工具里占有一席之地。但首页上没人会告诉你的是:如果你想在规模化场景里持续拿到稳定可靠的结果,就必须理解视觉爬虫最容易出问题的地方。,员工每周要花九个多小时在重复性数据录入上——这正是把人们推向 Simplescraper 这类工具的痛点。但如果你不了解工具本身的特性,这九个小时最后很可能都花在排错上,而不是产出真正有价值的东西。本文总结了我从真实运营经验里提炼出的五条最佳实践:排查选择失败、选择合适的爬取模式、最大化利用免费方案、避免封禁,以及知道什么时候该换工具。

什么是 Simplescraper(以及为什么最佳实践很重要)
Simplescraper 是一个 Chrome 扩展,能让你在网页上可视化选择元素——产品标题、价格、图片、联系方式——然后把它们提取成结构化数据,全程不用写一行代码。你只要点一点,它就会生成一份可以复用到相似页面上的“配方”。
它的核心工作方式如下:
- 可视化元素选择:点击你想要的内容。Simplescraper 会自动识别重复模式(产品列表、搜索结果、招聘信息等)。
- 配方:保存你的提取配置,方便之后复用,或者批量运行多个 URL。
- 两种爬取模式:浏览器模式(本地运行,在你的 Chrome 里执行)和云端模式(在 Simplescraper 的服务器上运行,不需要你一直盯着)。
- 集成:可导出到 Google Sheets、Airtable、webhook、Zapier、Make、CSV 和 JSON。
- AI 提取:较新的 ,可以根据结构提示词生成 CSS 选择器。
它面向的人群很广——市场人员、销售团队、电商运营、研究人员——任何需要从网站提取结构化数据、又不想雇开发的人。对于结构简单的页面,Simplescraper 的确能很快出结果。
那为什么最佳实践还是重要?因为一旦你面对的不是简单的商品列表或干净的目录页,摩擦就会冒出来。动态内容、反爬措施、懒加载图片、嵌套 HTML 结构——这些真实场景,才是真正把“用起来很烦”和“高效产出”区分开的地方。提前知道正确做法,能帮你省下大量试错时间。
最佳实践 1:当 Simplescraper 无法正确选择元素时怎么办
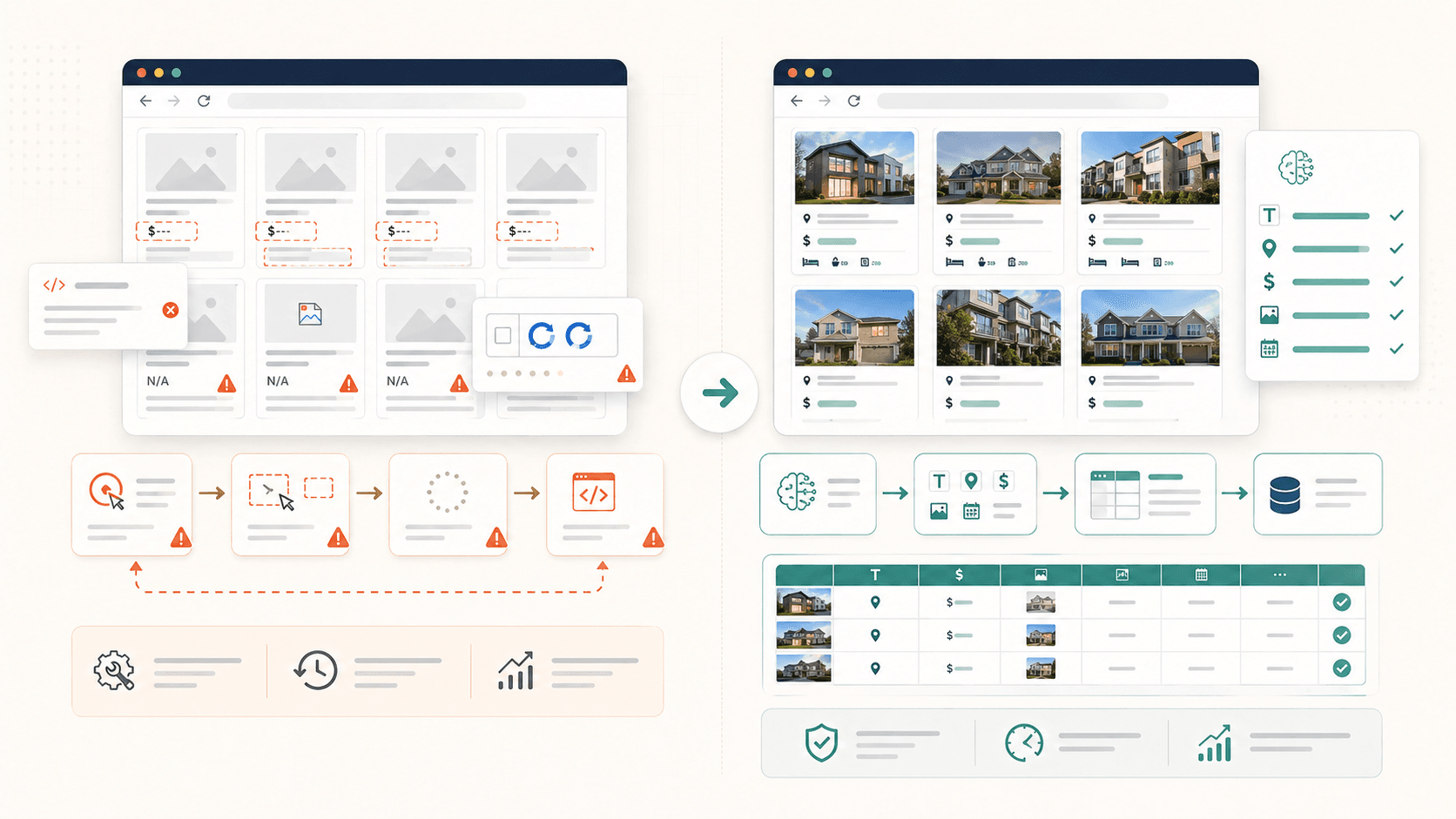
这几乎是我见过最常见的挫败感。你点了一个元素,Simplescraper 也把它高亮了,你以为稳了——结果输出里一半数据都丢了。图片是空的,简介没了,地点字段也消失了。
创始人自己也曾在早期 :“元素 / CSS 选择器还没做到 100% 准确。”这种坦诚很难得,但它并不能在你周三晚上 11 点的时候,把一个坏掉的抓取自动修好。
常见的选择失败类型(以及原因)
下面四种情况最容易让 Simplescraper 出错:
- 懒加载图片:图片元素在你滚动到它之前,页面里 。如果你在滚动前就抓取,就会得到空的图片字段。
- 嵌套或分组容器:Simplescraper 的自动识别 ,但这有时意味着它只抓到页面中的一个区域,而不是完整的重复集合。用户会反馈表格“不能一次选中所有行”。
- 动态 JavaScript 内容:通过 React、Vue 或 AJAX 请求在初始加载后才渲染出来的元素,在爬虫动作发生得太早时根本还没出现。
- 无限滚动分页:你想要的数据还没有进入 HTML,因为它需要你继续滚动或者点击“加载更多”。
实用的排查步骤
在你开始手动写选择器之前,先试试这些方法:
- 先把整页滚动一遍。 这样能把懒加载图片和内容强制放进 DOM。
- 当列表数量明显偏少时,使用 “Include Similar”。Simplescraper 自己的文档也建议对分组内容这么做。
- 在 JS 很重的网站上,等页面完全渲染。在触发抓取前多给它几秒钟。
- 先从小样本开始。 在正式跑 500 页批量任务前,先确认 2 到 3 个页面的行数是否正确。
切换到手动 CSS 选择器
当可视化选择总是失败时,就该手动上了。这是区分普通用户和高效用户的关键一步。
流程如下:
- 在 Chrome 里右键你要的元素 → 检查。
- 在 DevTools 中找到元素的类名或数据属性,比如
.product-card .price或[data-test="location"]。 - 在 Simplescraper 里切换到 ,然后粘贴你的选择器。
- 运行一次小规模抓取,测试选择器是否有效。
更稳健的选择器建议:
- 优先用类名(
.listing-title),不要用位置选择器(div:nth-child(3)) - 如果有 ,优先使用——它们通常在网站更新后更稳定
- 避免过深的嵌套路径,因为网站 HTML 结构一变就会失效
AI 替代方案:让 Thunderbit 自动识别字段
我先说明白——我们团队之所以做 ,就是因为我们也受够了这个问题。Thunderbit 的“AI Suggest Fields”会读取页面结构,自动推荐列和提取逻辑,不需要你懂 CSS。AI 能适配不同网站的布局,包括嵌套内容和懒加载图片。
如果你每次抓取都要花好几分钟排查选择器,其实很值得彻底换一种思路。
最佳实践 2:如何在云端爬取和浏览器爬取之间做选择
大多数 Simplescraper 用户都会默认选一种模式——通常就是第一次试的那种——却没想过哪种更适合自己的实际场景。这会导致很多本可避免的失败。
什么时候用浏览器(本地)爬取
- 需要登录的页面:LinkedIn、CRM 仪表盘、内部工具——任何需要身份验证的页面都要用你当前的浏览器会话。
- 快速一次性提取:你已经在页面上了,只想立刻拿到数据。
- 节省免费额度:浏览器爬取不消耗云端额度。
代价是:你的电脑必须一直开着,而且大任务跑起来会比云端慢很多。
什么时候用云端爬取
- 公开页面(电商列表、目录页、房产网站)且不需要登录。
- 定时监控:按周期无人值守运行。
- 批量任务:单次云端批处理最多可处理 。
- 集成投递:自动推送到 Google Sheets、Airtable 或 webhook。
代价是:云端爬取会 ——启用 JavaScript 的页面每页 2 点,非 JS 页面每页 1 点——很快就会把免费方案的 100 点额度用完。
决策框架
| 场景 | 推荐模式 | 原因 | 选错的风险 |
|---|---|---|---|
| 需要登录的页面(LinkedIn、仪表盘) | 浏览器 | 需要你的已登录会话 | 云端模式会卡在登录墙 |
| 公开电商商品列表 | 云端 | 更快,可无人值守运行 | 浏览器模式会占用你的电脑 |
| 定时重复监控 | 云端 | 无需你在场 | 浏览器模式要求你一直在线 |
| 反爬很强的网站(Amazon、Yelp) | 浏览器(备用)或带代理的云端 | 需要 IP 轮换或会话复用 | 云端不带代理很快被封 |
| 快速一次性提取 | 浏览器 | 立刻可用,没有额度成本 | 为一页内容搭云端流程太大材小用 |

Thunderbit 如何简化这件事
在 里,这只是同一个界面里的一个简单切换。云端模式最多可并发处理 50 个页面——不需要为了云端访问单独买更高等级的套餐。浏览器模式可以直接处理需要登录的网站,不用额外配置。把“我该选哪个模式?”这个心理负担,降到了很低,因为两种模式都在同一套工作流里。
最佳实践 3:充分利用 Simplescraper 免费方案
价格认知上的混乱是真实存在的。我见过有人在论坛里以为“免费 Chrome 扩展”就意味着“所有功能都免费”。事实并非如此。反过来也有人因为付费档没被突出展示,就以为 Simplescraper 很贵。两种理解都没什么帮助。
Simplescraper 的免费计划到底包含什么
根据 :
- 浏览器爬取:无限制(在你的 Chrome 本地运行)
- 云端额度:每月 100 点
- 已保存配方:3 个
- 导出格式:CSV 和 JSON
- 不包含的内容:优先支持、高级代理选项、更高的云端额度
一个现实的免费方案使用场景
假设你需要从一个公开电商网站抓取 50 个商品页面。
- 浏览器模式(免费):你可以完全免费完成。逐个打开页面(或者用列表),运行配方,导出为 CSV。所需时间取决于你的耐心和网速,但如果是手动导航 50 个页面,预留 15 到 30 分钟的主动操作时间比较合理。
- 云端模式(免费方案):如果启用了 JavaScript 渲染,每个页面要花 2 点额度。50 个页面 = 100 点。一次任务就用完了你整个月的云端额度,而且不能定时,也没有失败重试。
免费方案对小规模、偶尔性的抓取确实有用。但一旦你需要云端自动化或更大规模,额度会很快耗尽。
免费方案对比:Simplescraper vs. Thunderbit
| 功能 | Simplescraper 免费版 | Thunderbit 免费版 |
|---|---|---|
| 页面 / 额度 | 无限浏览器 + 100 云端额度 | 6 个页面,含完整 AI 功能 |
| AI 提取 | 有限制(Smart Extract 会消耗额度) | 包含完整的 AI Suggest Fields |
| 导出目的地 | CSV、JSON | Excel、Google Sheets、Airtable、Notion——全部免费 |
| 已保存配置 | 3 个配方 | 提供模板 |
| 子页面抓取 | 需要手动设置配方 | 已包含在页面计数内 |
这两种模式确实不一样。Simplescraper 给你的是无限的本地抓取,但云端能力受限。 提供的页面数更少,但每一页都带完整 AI 能力,而且还能免费导出到团队最常用的工具里。如果你只需要基础本地抓取,并且能接受手动操作,Simplescraper 的免费方案是够用的。但如果你想要带灵活导出的 AI 提取,Thunderbit 的免费方案每页产出更高。
最佳实践 4:如何避免在抓取时被封
没人会在真的碰到验证码墙或空数据集之前想到反爬措施。等你发现时,时间和可能的额度早就已经烧掉了。
主动防御永远比事后排错更省钱。
设置速率限制,控制请求节奏
被封的头号原因,就是对网站发起过快、过密的请求。对 Web 服务器来说,10 秒内从同一个 IP 发出 50 个请求,看起来不像研究,像攻击。
通用经验法则:
- 大多数商业网站,页面请求之间间隔 2 到 5 秒。
- 对更敏感的目标(市场平台、评论网站),放慢到 5 到 10 秒。
- 如果你在用 Simplescraper 的 API, 参数可以帮助确保页面在提取前完全加载,同时也会自然放慢节奏。
什么时候开启代理轮换
代理轮换会在请求之间更换你的 IP 地址,让你看起来像不同用户。下面这些场景通常需要它:
- Amazon、Yelp、TripAdvisor、LinkedIn(反爬系统更激进)
- 任何按 IP 限速的网站
- 大批量任务(同一域名下数百个页面)
Simplescraper 平台 ,包括标准、高级和住宅代理。不过,公开文档里对具体方案是否可用并不总是说得很清楚——别想当然地认为免费方案就能覆盖难抓的网站。住宅代理通常更贵,但更不容易被识别为异常流量。
处理重 JavaScript 网站
现代网站如果基于 React、Vue 或 Angular 构建,内容通常会在初始页面加载之后才渲染出来。如果爬虫动作发生在 JavaScript 执行完成之前,你拿到的就会是空字段。
应对策略:
- 使用 云端爬取模式,渲染能力更好(Simplescraper 的云端可以执行 JavaScript)。
- 在运行浏览器抓取前,手动滚动 页面,触发懒加载内容。
- 在基于 API 的流程里使用
waitForSelector,等目标元素出现后再继续。 - 接受这样一个现实:某些高度动态的单页应用,可能本来就不是视觉爬虫能稳定处理的。
无需操心的替代方案
会自动处理反爬保护、验证码和 JavaScript 渲染——不用配置代理,不用调延迟,不用手动滚动。对于那些不想为了抓一个商品目录就先去当半个 DevOps 的用户来说,这一点非常重要。问题并没有消失——只是变成了别人的问题。
最佳实践 5:知道什么时候 Simplescraper 已经到头了
两年前要是有人帮我写这一节就好了。
有一个临界点:工具不再节省时间,反而开始吞噬时间。早点识别这个阈值,能避免你陷入“我都已经做了 15 个配方了,现在不能换”的沉没成本陷阱。
Simplescraper 的实际限制
- 动态单页应用:通过 AJAX 加载内容,而且没有传统页面跳转
- 无限滚动:需要持续滚动才能加载全部条目(不是标准的点击翻页)
- 子页面补充:先抓列表页,再逐个访问详情页补充数据。Simplescraper 可以通过 做到,但设置复杂度会迅速上升。
- 布局变更:网站更新 HTML 结构后,原来的配方就会失效。你精心调好的 CSS 选择器也会失灵。
你已经超出工具能力范围的信号
当你出现下面这些情况时,大概率已经到上限了:
- 每次抓取都要手动调整 CSS 选择器,因为自动识别一直失败
- 网站一更新,配方就坏,还得重建
- 你需要同时抓几十页甚至几百页,但总是撞上额度或速度限制
- 子页面数据要通过复杂的多步骤配方链才能拿到
- 你花在维护抓取上的时间,比真正使用数据的时间还多
最后这一条,信号最明确。当维护本身变成工作时,无代码工具带来的便利红利就已经没了。
迁移到 AI 驱动的工作流
这时候我就要讲一下我们团队用 做了什么,因为它就是专门为上面这些失败模式设计的:

- AI 每次都会重新读取页面——不用维护脆弱的配方或 CSS 选择器。网站布局一变,下一次运行时 AI 就会自动适应。
- 子页面抓取 一键把数据表补充完整。先抓列表,再自动访问每个详情页,补充更多字段。
- 定时爬取 用自然语言设置(比如“每周一上午 9 点”),不用配置复杂的定时预设。
- 云端爬取可同时处理 50 个页面,公开网站上速度更快。
- 原生免费导出 到 Google Sheets、Airtable、Notion 和 Excel,不需要配置 webhook。
Simplescraper vs. Thunderbit:并排对比
把所有内容放在一起看更直观:

| 能力 | Simplescraper | Thunderbit |
|---|---|---|
| 字段设置 | 手动 CSS 选择器 / 可视化选择 | AI Suggest Fields(自然语言) |
| 子页面补充 | 可通过批量工作流实现(设置复杂) | 一键自动补充 |
| 自动适应布局变化 | 会失效(需要手动修复) | AI 每次都会重新读取页面结构 |
| 云端页面并发 | 单批最多 5,000 个 URL(因方案而异) | 同时 50 页 |
| 导出到 Notion/Airtable | 通过 webhook(付费方案) | 原生支持,免费 |
| 定时任务 | 预设 + 自定义时间控制 | 自然语言描述 |
| 反爬 / 验证码处理 | 提供代理模式(取决于方案) | 自动处理,无需配置 |
| 免费方案 | 100 云端额度 + 无限浏览器 + 3 个配方 | 6 个页面,完整 AI 功能 + 免费导出 |
简单来说:Simplescraper 适合简单、可视化、低配置的提取任务,只要你偶尔愿意手动调一调也能接受。Thunderbit 则是在这个模式开始失效的地方接手——处理页面解析、布局适配和工作流复杂度,让你不用自己操心。
没有哪款工具在所有场景里都绝对更好。它们只是处在复杂度曲线的不同位置——这完全没问题。
快速参考:Simplescraper 最佳实践清单
下次抓取时可以先收藏这一段:
- 先用小样本测试。 扩大规模前,先在 2 到 3 个页面上确认行数和字段完整性。
- 抓取前先滚动页面,触发懒加载内容。
- 当列表识别范围看起来太窄时,使用 “Include Similar”。
- 有意识地选择爬取模式。 需要登录的网站用浏览器模式;公开页面和定时任务用云端模式。
- 设置请求间隔——商业网站至少 2 到 5 秒,反爬更强的目标要更慢。
- 算清免费额度。 100 个云端额度 = 50 个启用 JavaScript 的页面。提前规划。
- 只给稳定页面保存配方。 如果网站经常更新,配方迟早会坏。
- 学一点基础 CSS 选择器 作为备用。类名和 data 属性通常比位置选择器更靠谱。
- 主动监控封禁。 如果结果为空或频繁出验证码,就该放慢速度或切换模式。
- 认清上限。 当维护时间超过数据使用时间时,就该评估替代方案了。
结论:让每一次抓取都物尽其用
从一千多次抓取里得到的最大教训,并不是某个单独工具有多强,而是 方法比软件更重要。理解一次抓取为什么失败——懒加载、模式选错、反爬太强、选择器太脆弱——比任何功能列表都更有价值。
Simplescraper 的确很适合简单直接的提取任务。只要你的页面足够干净、需求不复杂,而且你不介意偶尔手动调一下,它就能干活。
但如果你发现自己更多是在和工具较劲,而不是在使用它——排查选择器、重建坏掉的配方、配置代理、手动滚动页面——这不是你的失败,而是一个信号。说明你已经超出了纯视觉爬取能稳定处理的范围。
如果这听起来很熟悉,不妨试试 ——6 个页面,完整 AI 功能,免费导出到 Sheets、Airtable 和 Notion。把它和你现在的流程比一比,看看哪种更顺手。有时候,最佳实践就是知道什么时候该直接换一款工具。
常见问题
Simplescraper 可以免费使用吗?
可以。Simplescraper 有免费方案,包含无限本地浏览器爬取、每月 、3 个已保存配方,以及 CSV/JSON 导出。启用 JavaScript 的云端页面每页消耗 2 点,所以这 100 点大约能覆盖 50 个云端页面。付费方案从每月 39 美元的 Plus 套餐开始,包含 6,000 点额度;Pro 套餐每月 70 美元,包含 15,000 点额度。
Simplescraper 能处理重 JavaScript 网站吗?
有时可以。Simplescraper 的云端模式可以渲染 JavaScript,而且工具也宣称支持单页应用。不过,渲染非常动态的复杂 SPA、无限滚动或反爬系统很强的网站,仍可能出现结果不完整的情况。使用云端模式并设置合适的等待时间,能提升可靠性;但对任何视觉爬虫来说,高动态网站始终都是挑战。
Simplescraper 的云端爬取和浏览器爬取有什么区别?
浏览器爬取在你的 Chrome 浏览器本地运行——它使用你当前的会话(很适合需要登录的网站),不消耗额度,但需要你的电脑保持开启。 在 Simplescraper 的服务器上运行——速度更快,可无人值守,支持定时和集成,但每页都会消耗额度,而且无法访问你个人登录之后才能看到的页面。
什么时候应该从 Simplescraper 换成 Thunderbit 这类替代工具?
最明显的信号,是维护时间已经超过数据使用时间。如果你经常在网站更新后修复坏掉的选择器、手动配置代理、重建配方,或者花在排错上的时间比分析数据还多,那就说明你已经超出了手动视觉爬取能高效提供的能力范围。像 这种每次运行都会用 AI 解析页面结构的工具,能消除大部分维护负担。
用 Simplescraper 抓取时,怎样避免被封?
三个关键做法:第一,控制节奏,页面之间保持 2 到 5 秒延迟,反爬很强的网站(如 Amazon 或 Yelp)要更慢。第二,把浏览器模式作为备用方案,用在那些对云端 IP 封得很严的网站上——你的浏览器会话看起来更像正常流量。第三,在敏感目标的大批量任务中启用代理轮换,但在依赖它之前,先确认你的方案是否包含这些代理选项。
了解更多