

想象一下:周一早上,你的咖啡还冒着热气,HR 团队已经开始在表格里埋头苦干,从十几个不同网站上复制粘贴职位信息。LinkedIn、Indeed、公司官网、垂直招聘平台——每个网站的页面结构都不一样。等你好不容易整理出一小部分岗位,咖啡早就凉了,眼睛也看花了,不禁怀疑:难道没有更高效的办法吗?(剧透:当然有!)
我在 SaaS 和自动化领域摸爬滚打了很多年,亲眼见证了数字化招聘的爆发式增长。现在,全球在线职位数量已经达到数千万,光是 LinkedIn 上就有大约 6000 万条活跃职位。招聘信息量之大让人咋舌,HR 团队的压力也随之水涨船高。但问题是:大多数 HR 并不懂编程,传统的爬虫工具或者 API 根本不适合他们。这时候,像 Thunderbit 这样的 AI 工具就派上了用场,让职位抓取变得轻松又有趣(真的!)。
用 AI 从任意网站抓取职位招聘信息 Get Started Free
接下来,我们聊聊为什么职位抓取这么重要,HR 团队为什么总觉得难搞,以及 AI 如何彻底改变这一切——尤其是当你已经厌倦了无休止的复制粘贴时。
什么是职位招聘信息抓取?
简单来说,职位招聘信息抓取就是用软件自动从网站上批量收集职位数据——比如职位名称、公司、地点、薪资、岗位描述、任职要求等。与其一条条手动复制,不如让爬虫“读懂”页面,自动提取结构化数据,方便后续分析或导入 HR 系统。
数据来源五花八门:
- LinkedIn(重头戏)
- 公司官网招聘页(比如 Netflix、OpenAI)
- 主流招聘平台(Indeed、Monster)
- 垂直细分平台(如科技、医疗、学术等领域)
真正的价值在于:你可以自建专属的职位数据库,用于薪酬对标、竞品分析,或者实时掌握行业招聘动态。
为什么要抓取职位招聘信息?核心场景与价值
那 HR 团队为什么要费心抓取职位信息?归根结底,是为了把原始数据转化为可落地的洞察。常见应用场景包括:
| 应用场景 | 价值 | ROI / 影响举例 |
|---|---|---|
| 薪酬对标 | 提供有竞争力的薪资方案 | 避免薪资偏低导致候选人流失,确保 offer 具备市场竞争力。最新薪酬数据有助于留住人才。 |
| 竞品招聘监测 | 洞察同行招聘策略 | 及时发现竞争对手扩张或新岗位,提前调整招聘或留才计划。通过职位数据分析市场趋势,发现新兴岗位和技能需求。 |
| 内部职位数据库 | HR 一站式掌握市场动态 | 数据采集效率大幅提升。自动化每天可抓取 1 万+ 职位,手动仅约 100 条,HR 从繁琐中解放出来,实现实时分析。自动化爬虫每天可采集数千条职位。 |
| 技能缺口分析 | 培训/招聘精准对标市场 | 数据驱动人才发展。例如,抓取数据显示本行业 70% 职位要求 Python,便可有针对性地培训或招聘。帮助企业制定培训或招聘策略。 |
总之,职位抓取让现代 HR 团队从“拍脑袋”转向数据驱动决策。现在,38% 的 HR 决策者已经把 AI 融入日常工作,而且这个趋势还在加速。
传统职位抓取方式及其痛点
接下来聊聊 HR 团队以前是怎么抓取职位信息的——以及为什么总是让人头大。
API 方式
不少 HR 团队(尤其是不懂技术的)会尝试用官方 API(如果有的话)。理论上,连上招聘平台的 API,拉取结构化数据就搞定了。实际操作呢?远没那么简单。
API 抓取职位的主要难题:

- 权限受限: 很多主流网站(比如 LinkedIn)根本没有公开职位 API。
- 请求频率限制: 就算有权限,每天能拉取的数据量也有限。
- 字段不全: API 可能不提供你需要的全部信息(比如完整职位描述或薪资)。
- 技术门槛高: 集成 API 需要开发资源,处理 JSON/XML,还要持续维护。
- 接口随时变动: API 可能随时调整或下线,导致流程中断。
对大多数 HR 来说,这就像拿到一艘飞船的钥匙——很酷,但你得有“飞行执照”和十足的耐心。
自定义代码爬虫
有些团队有开发资源,会用 Python(比如 BeautifulSoup、Scrapy)写脚本。虽然灵活,但耗时且易碎。只要网站页面结构一变,脚本就失效,得重新维护。更别提还要应对登录、无限滚动、反爬机制等麻烦。
正如有人形容的那样,这就像“没有说明书拼装宜家家具”——能搞定,但过程常常让人崩溃(详细解读)。
传统无代码爬虫工具(无 AI)
还有一些经典的无代码工具,可以通过点击选择页面字段。但你还是得为每个网站手动设置规则,需要一定技术直觉和反复试错。一旦页面变动,配置就得重来。遇到弹窗、无限滚动等复杂页面,操作起来也很混乱(用户评价)。
手动复制粘贴
当然,还有最原始的方式:把职位信息复制到 Excel。慢、容易出错,而且说实话,“极其消磨意志”(我也经历过)。一天能整理 100 条算幸运,但面对数百万职位,这根本不是办法。
Thunderbit:用 AI 无代码抓取职位招聘信息
这正是 Thunderbit 登场的时刻。作为联合创始人兼 CEO,我或许有点偏爱 Thunderbit,但我开发它正是因为看到 HR 团队在传统爬虫工具面前的无力。Thunderbit 是一款AI 驱动、无代码的职位爬虫,专为 HR 和招聘团队设计,无需依赖工程师,几分钟就能搞定。
Thunderbit 如何颠覆传统:
- 无代码,两步搞定: 只需点击“AI 智能识别字段”,让 AI 自动读取页面,然后点“抓取”即可。无需选择器、无需脚本、无需折腾。
- 无需等 IT 支援: HR 自己就能抓取职位,业务节奏不再受限于技术资源。
- 适配任意招聘网站或公司页面: Thunderbit 的 AI 能理解不同页面结构,无需为每个网站单独建模板。
- 数据智能加工: 不止抓取原始数据,Thunderbit 还能自动标注、翻译、摘要、格式化数据。
下面看看实际操作效果。
Thunderbit 实战:从任意网站抓取职位信息
职位抓取最大难点之一就是来源多样。LinkedIn、Netflix 招聘、OpenAI 职位页——每个页面结构、字段名称都不同,还经常变动。
用 Thunderbit,无需担心这些。AI 会像人一样“读懂”页面,自动识别并提取关键字段,无论页面怎么变都能搞定。
案例:抓取 Netflix 与 OpenAI 招聘页面
我们以两个真实案例演示:
1. Netflix 机器学习工程师职位
Netflix 的职位页面基于 ATS 系统,包含如下板块:

- 职位名称: “Machine Learning Engineer”
- 工作地点: “USA, Remote”
- 团队: “Machine Learning Platform”
- 职位描述: 包含要求、职责、福利等详细内容。
Thunderbit 的 AI 能自动扫描页面,建议提取“职位名称”“地点”“团队”“描述”等字段,甚至能拆分出岗位要求和福利,无需你手动点击每个字段。
2. OpenAI 机器学习工程师(Integrity)

OpenAI 的招聘页面完全不同——静态内容,分为“About the Role”“You might thrive in this role if you”“Benefits”等板块。
Thunderbit 能识别“ You might thrive in this role if you ”其实就是“岗位要求”,即使和 Netflix 的“ What we are looking for ”叫法不同,AI 也能统一归类。最终输出表格里,“岗位要求”字段始终一致,无论每家公司怎么命名。
总结: 用 Thunderbit,你可以用同一套流程抓取 Netflix、OpenAI 及更多网站的职位信息,无需单独配置。
数据智能加工:Thunderbit 的 AI 后处理能力
抓取只是第一步,数据清洗、标准化和智能加工才是真正的价值所在,否则你只会得到一堆难以分析的杂乱表格。
Thunderbit 支持为每个字段添加自定义 AI 提示,实现:
- 薪资单位标准化: 自动将“$4,000/月”“£50k per annum”统一换算为年薪美元。
- 岗位要求字段统一: 把“ What we are looking for ”、“ You might thrive in this role if you ”、“ Qualifications ”等合并为“岗位要求”。
- 描述翻译/摘要: 一键翻译职位描述或生成一句话摘要。
- 技能/岗位标签提取: 用 AI 自动识别并标注所需技能或部门分类。
案例:薪资信息标准化
假设你抓取了两条职位:
- Netflix:“$4,000/月”
- OpenAI:“£50,000 per annum”
用 Thunderbit 设置提示后,AI 会自动换算为:
- Netflix:“$48,000”
- OpenAI:“$62,000”
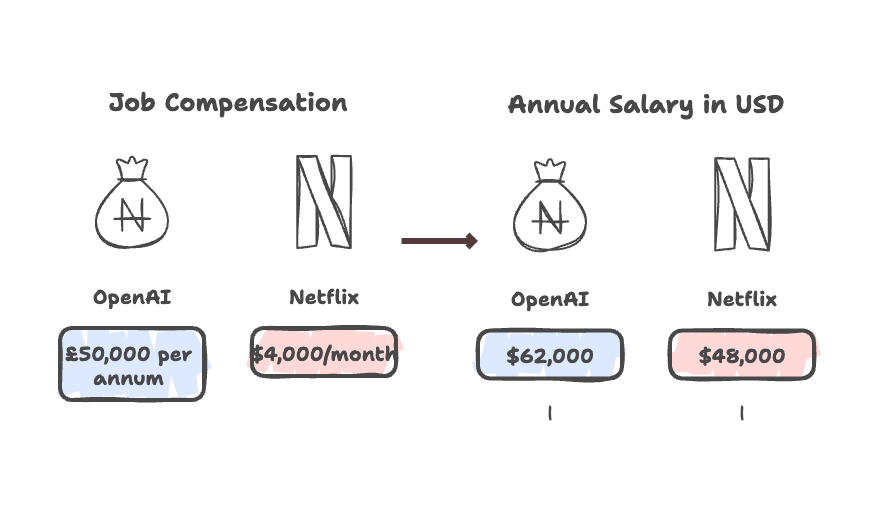
这样你就能轻松横向对比,无需手动整理(Propellum 的 AI 套件也有类似功能)。
案例:不同标签下的岗位要求统一
比如 Netflix 用“ What we are looking for ”,OpenAI 用“ You might thrive in this role if you ”,Thunderbit 的 AI 都能识别为“岗位要求”,合并到同一列。无需再费力找字段,数据一目了然。
用 Thunderbit 抓取 LinkedIn 职位信息:快速指南
LinkedIn 是职位数据的“金矿”,但抓取难度极高。没有公开 API,页面无限滚动且动态加载。手动抓取?几乎不可能。
Thunderbit 针对 LinkedIn 的特点做了优化:
- 自动滚动并点击职位列表: AI 代理模拟人工操作,自动滚动并点击每条职位,加载详情。
- 支持分页与子页面: 只需点击“抓取子页面”,Thunderbit 会自动访问每个职位详情页,提取完整描述、公司信息等。
- 自动提取联系方式(如有): 如果职位描述中有邮箱或电话,Thunderbit 会自动抓取。
小贴士: 建议使用 LinkedIn 的公开职位列表(无需登录),先手动滚动加载部分职位,然后交给 Thunderbit 自动处理。几分钟内即可获得结构化职位表格——包括职位、公司、地点、描述等。
Thunderbit 与传统职位爬虫方案对比
我们来横向对比一下 Thunderbit 和传统方案:
| 对比维度 | Thunderbit(AI 爬虫) | 传统爬虫(API/手动/无代码) |
|---|---|---|
| 易用性 | 无代码,两步操作,非技术人员也能用 | 需编程、API 集成或手动选字段,上手难度大 |
| 配置时间 | 秒级,AI 自动识别字段 | 每个网站都需手动配置,耗时数小时 |
| 适应性 | 页面变动也能应对,适配任意网站 | 页面结构变就失效,需频繁维护 |
| 数据准确性 | AI 理解上下文和标签,准确率高 | 配置不当易出错,数据易遗漏 |
| 速度与规模 | 开发快、运行快,可高效抓取上百页面 | 配置慢,扩展需复杂设置或高价套餐 |
| 技术门槛 | 极低,面向非技术用户 | 中高,常需 IT 支持 |
| 成本 | 免费+付费,基础功能免费 | 价格不一,大规模时成本高 |
对 HR 团队来说,Thunderbit 就像一个永不疲倦、不会被页面难倒的数据助手。
步骤详解:用 Thunderbit 抓取职位招聘信息
准备好了吗?HR 团队只需几步就能用 Thunderbit 抓取职位信息。
步骤 1:安装 Thunderbit Chrome 插件
前往 Thunderbit Chrome 插件下载页 ,一键添加到浏览器。轻量、快速、免费试用。
步骤 2:打开目标职位页面
进入你想抓取的招聘网站或公司官网——LinkedIn、Netflix、OpenAI 等都可以。
步骤 3:点击“AI 智能识别字段”
点击 Thunderbit 图标,选择“AI 智能识别字段”。AI 会自动扫描页面,推荐可提取的字段——比如职位、公司、地点、薪资、要求等。
步骤 4:点击“抓取”收集职位数据
确认字段后,点击“抓取”。Thunderbit 会自动整理数据为结构化表格,支持自动翻页和子页面抓取。
步骤 5:导出或智能加工数据

一键导出到 Excel、Google Sheets、Notion 或 Airtable。想要清洗数据、标准化薪资、标注技能?添加自定义 AI 提示,Thunderbit 会在抓取时自动处理。
想深入了解?可以参考我们的AI 抓取任意网站指南或网站数据抓取到 Excel 步骤详解。
总结与要点回顾
- **职位抓取已成 HR 团队必备利器,**助力薪酬对标、竞品监测、人才库建设。
- **传统抓取方式慢、技术门槛高且易失效,**对 HR 非技术人员极不友好。
- **Thunderbit 的 AI 无代码方案,**让职位抓取人人可用,两步搞定。
- **Thunderbit 可适配任意招聘网站,**自动清洗、加工数据,随时导出到你需要的平台。
- **HR 团队获得速度、准确性和自主性,**无需等 IT、无需手动复制粘贴、无需再面对杂乱表格。
更多 HR 网页抓取实用指南 Get Started Free
想体验更智能的职位抓取方式?立即下载 Thunderbit,让网页职位数据成为你的战略优势。
想了解更多关于网页抓取、自动化和 HR AI 应用的技巧?欢迎访问 Thunderbit 博客,获取实用指南、测评与最佳实践。
祝你抓取顺利,咖啡常热,表格常新!
常见问题解答:
1. HR 团队为什么要抓取职位招聘信息?
抓取职位信息可以让 HR 团队从 LinkedIn、Indeed、公司官网等多个渠道批量收集结构化数据,无需手动复制粘贴。这样有助于薪酬对标、竞品监测、技能缺口分析和内部职位数据库建设。
2. 传统职位抓取方式的最大难点是什么?
传统方式(如 API、写代码、无代码工具)需要技术能力,页面结构一变就容易失效,还常常遗漏关键信息。手动复制粘贴则慢且易出错,无法应对大规模数据。
3. Thunderbit 如何让非技术用户轻松抓取职位?
Thunderbit 利用 AI 自动识别并提取网页上的职位字段。用户只需点击“AI 智能识别字段”和“抓取”,无需编程或复杂配置,适用于 LinkedIn、公司官网、招聘平台等。
4. Thunderbit 能应对 LinkedIn 或 Netflix 这类复杂网站吗?
可以。Thunderbit 能自动滚动职位列表、访问子页面、提取职位描述、识别职位、地点、薪资等字段,无论页面结构如何变化,都能像人工一样高效抓取。
5. Thunderbit 与其他无代码爬虫工具有何不同?
Thunderbit 不同于传统点选工具,它用 AI 理解内容语义,能适应页面变动,自动加工数据(如标准化薪资、标注技能),并支持一键导出到 Google Sheets、Airtable 等平台,几乎无需配置。
试用 AI 网页爬虫抓取职位招聘信息 Get Started Free




