
如果你曾经尝试从一个会在你滚动时加载内容、把价格藏在登录后面,或者几乎每隔一周就改一次布局的网站抓取数据,你一定知道这有多折腾。静态爬虫早就不够用了。事实上,如今有超过 依赖网页爬取获取替代数据, 也在自动监控竞品价格。但关键问题来了:这些数据中很大一部分都在动态网站上,由 JavaScript 加载,还被用户交互隐藏着。这就是无头浏览器自动化——以及 Puppeteer 这类工具——发挥作用的地方。
作为一个多年从事自动化和 AI 工具开发的人(没错,也替销售和运营团队抓过不少网站的数据),我亲眼见过 Puppeteer 如何解锁传统爬虫抓不到的数据。但我也见过,编码门槛如何让业务用户直接望而却步。所以在这篇指南里,我会带你一步步了解 Puppeteer 爬虫到底是什么、怎么用它做网页爬取,以及什么时候你可能更想直接用更简单的方案——比如 ,我们这款由 AI 驱动、无需编程的网页爬虫。
什么是 Puppeteer 爬虫?快速了解一下
 先从基础说起。 是 Google 推出的一个开源 Node.js 库,可以让你用 JavaScript 控制无头的 Chrome 或 Chromium 浏览器。简单来说,它就像一个机器人,能打开网页、点击按钮、填写表单、滚动页面,而且最重要的是——还能抓取数据,整个过程完全不需要把内容显示在你的屏幕上。
先从基础说起。 是 Google 推出的一个开源 Node.js 库,可以让你用 JavaScript 控制无头的 Chrome 或 Chromium 浏览器。简单来说,它就像一个机器人,能打开网页、点击按钮、填写表单、滚动页面,而且最重要的是——还能抓取数据,整个过程完全不需要把内容显示在你的屏幕上。
Puppeteer 为什么特别?
- 它可以渲染动态内容——也就是说,它会像真实用户一样等待 JavaScript 加载完成。
- 它可以模拟用户操作:点击、输入、滚动,甚至处理弹窗。
- 对于那些数据只有在交互后才出现的网站,它特别适合,比如电商列表、社交动态或仪表盘。
它和其他工具相比怎么样?
- Selenium:浏览器自动化界的老牌选手。支持很多浏览器和语言,但体积更大,也更“传统”。非常适合跨浏览器测试,不过在 Chrome/Node.js 项目里,Puppeteer 往往更轻快。
- Thunderbit:这就是让我兴奋的地方。Thunderbit 是一款无需编程、由 AI 驱动的网页爬虫,直接在浏览器里使用。你不用写脚本,只要点一下“AI 建议字段”,让 AI 自己判断该抓什么。对于想要结果、但不想写代码的业务用户来说,它特别合适(后面我会详细说)。
一句话总结:Puppeteer = 控制力最强(如果你会写代码)。Thunderbit = 使用最方便(如果你不想写代码)。
为什么 Puppeteer 网页爬取对业务用户很重要
说实话:网页爬取早就不只是黑客或数据科学家的专利了。销售、运营、市场,甚至房地产团队,都在用网页数据抢占先机。而当大量关键业务信息都被动态网站锁住时,Puppeteer 往往就是打开它的钥匙。
下面是一些真实的使用场景:
别忘了还有这一点: 会把每周四分之一的时间花在数据收集这类重复任务上。用网页爬取来自动化这件事,已经不只是“锦上添花”,而是竞争优势。
开始动手:搭建你的 Puppeteer 爬虫
准备好上手了吗?下面教你如何在 10 分钟内跑起 Puppeteer(前提是你对一点 JavaScript 不排斥):
1. 安装 Node.js
Puppeteer 运行在 Node.js 上。去 下载最新的 LTS 版本。
2. 创建一个新的项目文件夹
打开终端,执行:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. 安装 Puppeteer
1npm install puppeteer这一步还会下载一个兼容版本的 Chromium(大约 100MB)。
4. 创建你的第一个脚本
新建一个名为 scrape.js 的文件:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('页面标题:', title);
8 await browser.close();
9})();运行它:
1node scrape.js如果你看到“页面标题:Example Domain”,那就恭喜你——你已经成功自动化 Chrome 了!
编写你的第一个 Puppeteer 网页爬取脚本
我们来实操一下。假设你想从 抓取名言(这是一个专门给爬虫练手的演示网站)。
步骤 1:访问页面
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });步骤 2:提取数据
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);步骤 3:处理分页
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // 按上面的方式提取名言
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}步骤 4:保存为 JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));到这里,你就已经有了一个基础的 Puppeteer 爬虫:能访问页面、提取数据、翻页并保存结果。
进阶 Puppeteer 爬虫技巧:处理动态内容
真实世界的网站通常不会像一个静态列表那么简单。下面这些方法能帮你应对更棘手的情况:
1. 等待动态元素加载
1await page.waitForSelector('.product-list-item');这样可以确保你要抓取的内容已经加载完成,再去提取。
2. 模拟用户操作
- 点击按钮:
await page.click('#load-more'); - 在字段中输入:
await page.type('#search', 'laptop'); - 处理无限滚动:
1// 注意:Puppeteer v22 已移除 page.waitForTimeout。请改用普通 promise。 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. 处理登录**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. 处理通过 AJAX 加载的数据 有时候数据并不在 DOM 里,而是来自某个 API 请求。你可以通过下面方式拦截网络响应:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // 处理数据
5 }
6});真实案例:从电商网站抓取商品数据
把前面的内容串起来。假设你想在登录后,从一个(演示用)电商网站抓取商品名称、价格和图片。
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // 第 1 步:登录
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // 第 2 步:进入分类页
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // 第 3 步:提取商品
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // 第 4 步:保存为 JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();这个脚本会自动完成登录、跳转、抓取和保存。对于更高级的需求,你还可以加入分页循环,甚至点进每个商品详情页获取更多信息。
Thunderbit:用 AI 让 Puppeteer 爬虫更简单
如果你看到这里,心里正想着:“这很酷,但我不想每次要新数据集都写一遍代码。”那你并不孤单。这正是我们打造 的原因。
Thunderbit 为什么不一样?
- 无需编程:只要安装 ,打开你想抓取的页面,然后点击“AI 建议字段”。
- AI 驱动的字段识别:Thunderbit 会读取页面并推荐最适合提取的列,比如“商品名称”“价格”“图片”等。
- 可处理动态内容:无限滚动、弹窗、子页面?Thunderbit 的 AI 都能处理,它会自动点击翻页,甚至访问每个商品详情页来丰富你的数据。
- 一键导出:直接把数据导出到 Excel、Google Sheets、Notion 或 Airtable,无需额外收费。
- 热门网站模板:想抓 Amazon、Zillow 或领英?Thunderbit 提供现成模板,几乎不用设置。
- 云端或浏览器抓取:对于大任务,Thunderbit 最多可在云端同时抓取 50 个页面。
我见过用户在不到五分钟内,从“真希望能拿到这些数据”变成“这是我的表格”。最棒的是?再也不用担心网站改版把脚本弄坏——Thunderbit 的 AI 会自动适应变化。
Puppeteer vs. Thunderbit:如何选择合适的网页爬取工具
那么,到底该用哪个?我是这样给团队分析的:
| 因素 | Puppeteer(代码) | Thunderbit(无代码,AI) |
|---|---|---|
| 易用性 | 需要掌握 JavaScript 和 DOM 知识 | 点选式操作,AI 自动建议字段 |
| 上手速度 | 复杂任务通常要几小时到几天 | 几分钟即可——安装后直接开始 |
| 控制力 / 灵活性 | 最高:可以写任何自定义逻辑,并与其他代码集成 | 标准场景下很强;但不太适合高度定制化的工作流 |
| 动态内容处理 | 需要手动编写等待、点击、滚动逻辑 | 内置 AI 可自动处理动态内容、分页和子页面 |
| 维护成本 | 脚本归你维护——网站一变就得更新 | AI 会自动适应布局变化;用户维护更少 |
| 数据导出 | 需要自己写导出逻辑 | 一键导出到 Excel、Sheets、Notion、Airtable、CSV、JSON |
| 最适合谁 | 开发者、高度定制或大规模抓取 | 业务用户、快速交付项目、非技术团队 |
| 成本 | 免费(但会消耗你的时间,以及基础设施成本) | 提供免费版;付费计划按积分计费(见 Thunderbit 定价) |
一句话总结:
- 如果你需要完全控制、有编程资源,或者要把爬取集成到更大的应用里,就用 Puppeteer。
- 如果你想快速出结果、不想写代码,或者想让非技术同事也能上手,那就用 Thunderbit。
说实话,我见过很多团队同时用这两种:Thunderbit 用来快速验证和原型设计,Puppeteer 用来做深度集成或处理边缘场景。
分步清单:成功运行 Puppeteer 网页爬取项目
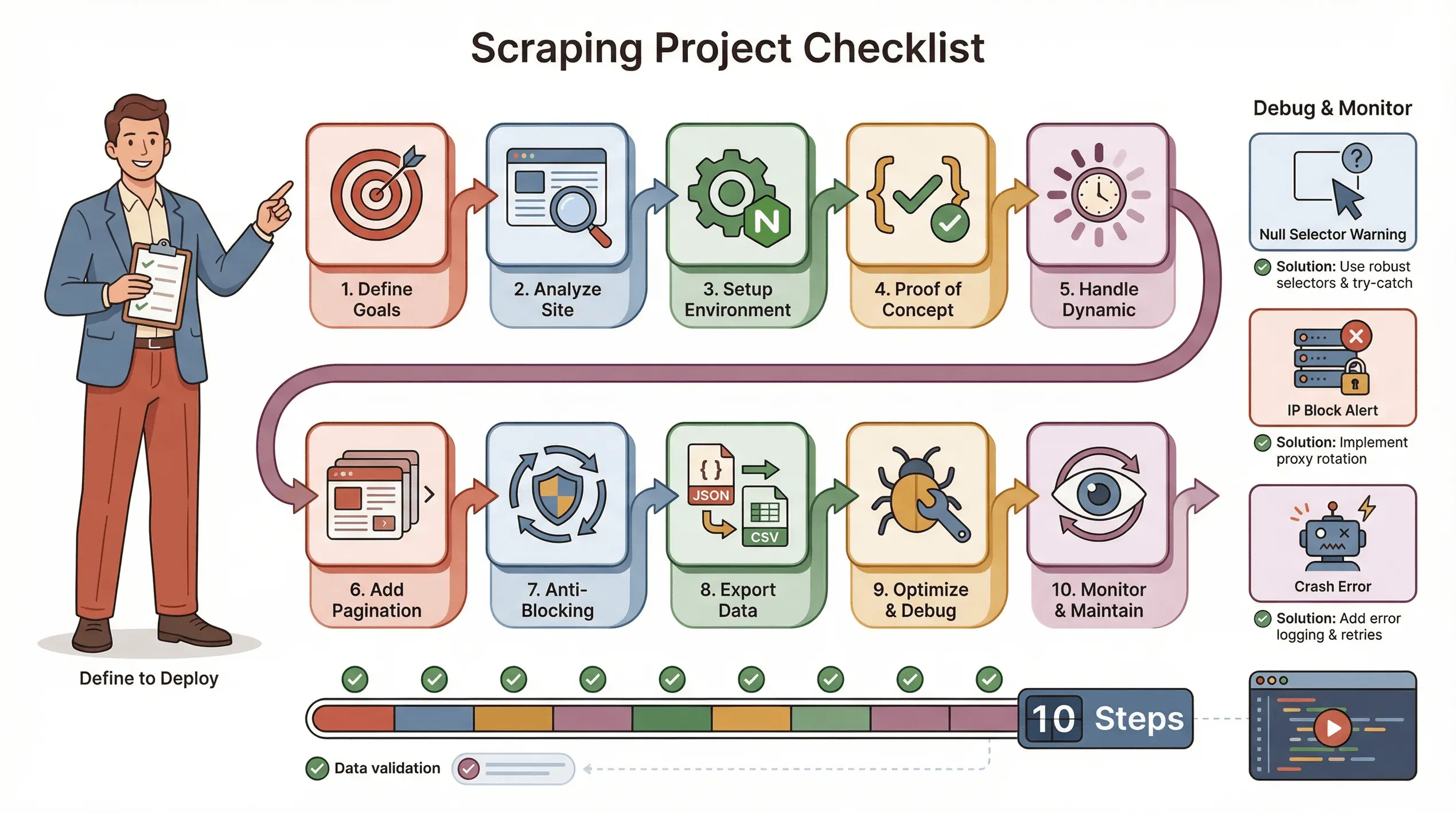 下面是我常用的 Puppeteer 爬取项目检查清单:
下面是我常用的 Puppeteer 爬取项目检查清单:
- 定义目标:你需要什么数据?它在哪里?
- 分析网站:它是不是动态的?是否需要登录?有没有反爬措施?
- 搭建环境:Node.js、Puppeteer,以及任何辅助库。
- 先做一个最小可行原型:从一个页面开始,先把选择器选对。
- 处理动态内容:根据需要使用
waitForSelector,模拟点击和滚动。 - 加入分页或循环:把所有页面都抓下来,而不只是第一页。
- 实现反封禁策略:随机延迟、设置真实的 User-Agent,必要时使用代理。
- 导出并校验数据:保存为 JSON/CSV,检查是否完整。
- 优化并处理错误:加入 try/catch,记录进度,优雅处理缺失数据。
- 持续监控和维护:网站会变——随时准备更新脚本。
排查建议:
- 如果选择器返回 null,先检查 HTML,再确认是否加了等待。
- 如果被封,放慢速度、轮换 IP,或者使用 stealth 插件。
- 如果脚本崩溃,检查是否有内存泄漏或未处理的异常。
结论与核心要点
网页爬取已经成为数据驱动团队的必备技能。Puppeteer 让你有能力从最动态、最重 JavaScript 的网站中提取数据——但它确实需要一定的编码能力和持续维护。对于那些想跳过代码、直接拿数据的业务用户来说,Thunderbit 提供了一个由 AI 驱动、无需编程的替代方案,速度快、灵活,而且出乎意料地稳定。
我的建议是:
- 如果你有技术背景,并且需要深度定制,先从 Puppeteer 开始。
- 如果你想要速度、简单和更少维护,不妨试试 ( 是很好的起点)。
- 对大多数团队来说,两者结合使用,基本能覆盖 99% 的网页数据需求。
想看更多类似指南?去看看 吧,那里有教程、对比,以及最新的 AI 网页爬取内容。
常见问题
1. 什么是 Puppeteer 爬虫,为什么它常用于网页爬取?
Puppeteer 是一个 Node.js 库,可以让你用 JavaScript 控制无头 Chrome 浏览器。它之所以常用于网页爬取,是因为它能加载动态内容、模拟用户操作,并从传统爬虫难以处理的网站中提取数据。
2. Puppeteer 和 Selenium、Thunderbit 相比如何?
Selenium 支持多种浏览器和语言,但体积更大。Puppeteer 针对 Chrome/Node.js 做了优化,在许多爬取任务中速度更快。Thunderbit 则是一个无需编程、由 AI 驱动的工具,让非技术用户只需几次点击就能抓取数据。
3. Puppeteer 网页爬取对业务有哪些主要好处?
自动化数据收集可以节省时间、减少错误,并为销售、市场、运营等团队提供实时洞察。使用场景包括潜在客户开发、价格监控和市场调研等。
4. 使用 Puppeteer 爬取时最大的挑战是什么?
主要挑战包括处理动态内容、避免反爬封锁,以及在网站改版后维护脚本。你需要写代码来处理等待、模拟交互和错误。
5. 什么时候我应该用 Thunderbit 而不是 Puppeteer?
如果你想跳过编程、快速拿到结果,或者希望让非技术同事也能使用,就选 Thunderbit。它非常适合标准爬取任务、快节奏项目,或者你只是想最省事地把数据导出到 Excel 或 Google Sheets。
准备好试试更聪明的爬取方式了吗? 或者继续阅读 的更多指南。祝你抓取顺利!
了解更多