网页数据的增量简直像开了倍速,跟不上就会很有压力。我自己就见过不少销售、运营团队把大把时间耗在整理表格、在网站之间来回复制粘贴上,而不是把数据真正用来做决策。Salesforce 说得很扎心:销售代表现在;Asana 也提到,。换句话说,很多工时都被手动采集数据吃掉了——这些时间本来完全可以拿去推进成交、或者把营销活动更快上线。
好消息是:网页抓取早就不是程序员的专属技能了。Ruby 一直是自动化提取网页数据的热门路线;而当你把 Ruby 网页抓取和 这种现代 AI 网页爬虫搭配起来,就能同时吃到两边的红利——对开发者来说够灵活、可扩展;对非技术同学来说又足够简单,几乎就是“零代码 网页爬虫”的体验。无论你是市场同学、电商负责人,还是已经受够了无尽复制粘贴的普通用户,这篇指南都会带你用 Ruby + AI 把网页抓取玩明白——而且不需要写代码。
什么是 Ruby 网页抓取?通往自动化数据的入口
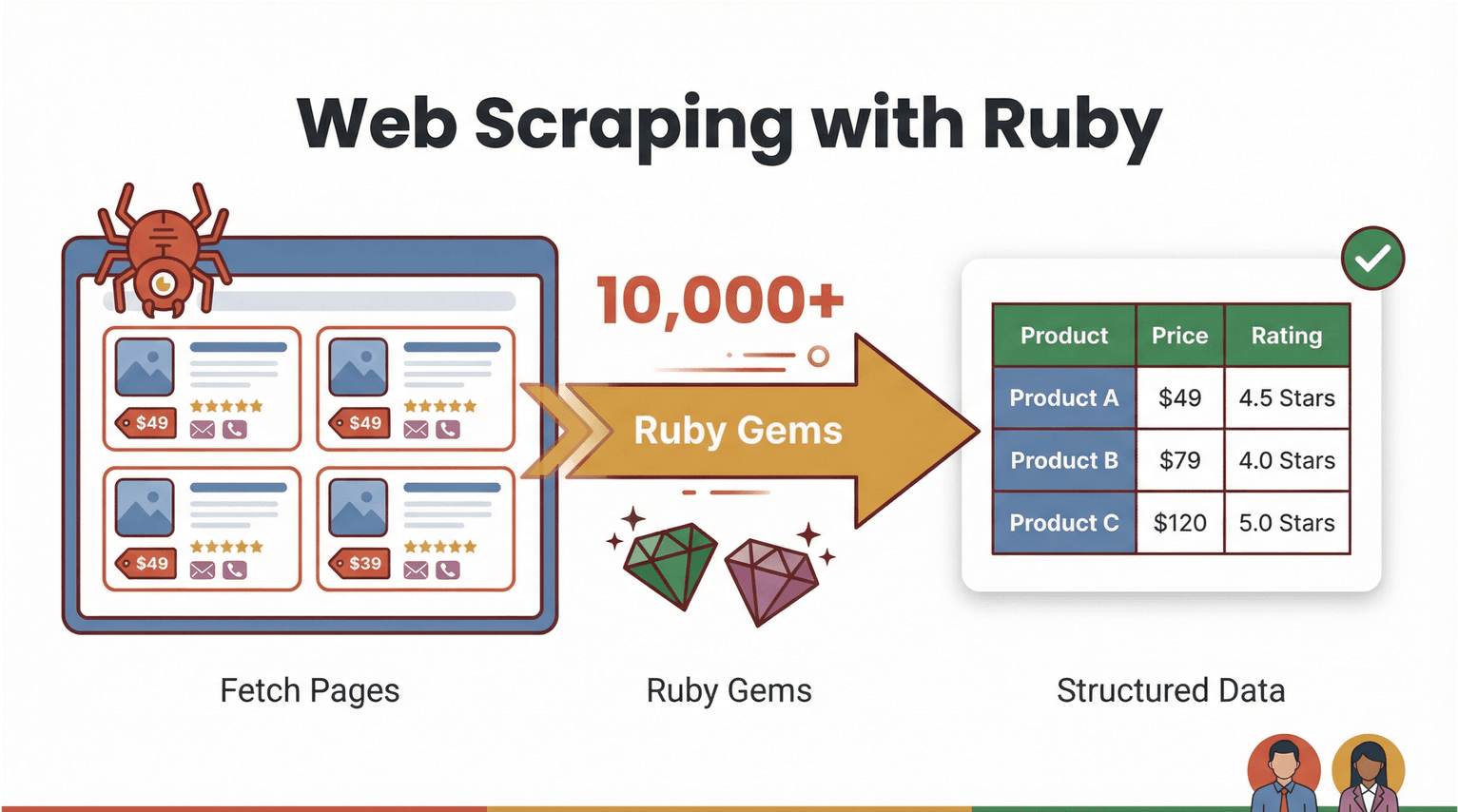
先把概念讲清楚。网页抓取(Web scraping),就是用软件去访问网页,把你关心的信息抓出来——比如商品价格、联系方式、用户评论——再整理成结构化数据(像 CSV、Excel 这种)。用 Ruby 做网页抓取的优势在于:语法很友好、可读性强,而且 gem(库)生态非常成熟,做自动化会很顺手()。
那“ruby 网页抓取”实际长什么样?比如你想从某个电商网站批量拿到商品名和价格,一般 Ruby 脚本会按这个流程走:
- 下载网页内容(比如用 )
- 解析 HTML 并定位目标数据(用 )
- 导出到表格或写入数据库
但更关键的是:现在很多场景其实根本不用写代码。像 这种 AI 驱动的 零代码 网页爬虫,已经能把“脏活累活”直接包圆——读懂网页结构、自动识别字段、导出成干净表格,你只要点几下就行。Ruby 依然很适合当“自动化胶水”去串联自定义流程,而 AI 网页爬虫则让更多业务同学也能轻松参与数据自动化。
为什么 Ruby 网页抓取对业务团队很重要

说真的,没人想把一整天都浪费在复制粘贴上。自动化网页数据提取的需求正在暴涨,而且理由非常现实。Ruby 网页抓取(再叠加 AI 工具)正在从这些方面改变业务团队的工作方式:
- 线索获取: 从目录站点或 LinkedIn 快速提取联系人信息,直接塞进销售漏斗。
- 竞品价格监控: 跨几百个 SKU 跟踪价格波动,不用再人工一个个点开看。
- 商品库搭建: 汇总商品信息和图片,用于自建商城或平台上架。
- 市场调研: 批量收集评论、评分或新闻,用来做趋势分析。
收益也很直观:自动化采集网页数据能每周省下大量时间、减少人为错误,还能拿到更及时、更可靠的数据。比如制造业,即便数据量两年翻倍,仍然有——这就是自动化的巨大空间。
下面用一张表把 Ruby + AI 工具的价值快速捋一遍:
| 使用场景 | 手动痛点 | 自动化带来的好处 | 常见结果 |
|---|---|---|---|
| 线索获取 | 逐个复制邮箱/电话 | 几分钟抓取成千上万条 | 线索量提升 10 倍,少做苦活 |
| 价格监控 | 每天人工巡检网站 | 定时自动拉取价格 | 实时掌握定价情报 |
| 商品库搭建 | 手动录入与整理 | 批量提取并自动格式化 | 上新更快、错误更少 |
| 市场调研 | 人工阅读评论与整理 | 规模化抓取并分析 | 洞察更深、数据更新更及时 |
而且这不只是“更快”这么简单——自动化还能显著降低错误、提升一致性。尤其当时,数据质量就更是硬指标了。
网页抓取方案怎么选:Ruby 脚本 vs. AI 网页爬虫工具
到底是自己写 Ruby 脚本更合适,还是直接上 AI 驱动的 零代码 网页爬虫?我们拆开对比一下。
Ruby 脚本:掌控力拉满,但维护成本也更高
Ruby 生态里抓取相关的 gem 很丰富:
- : 解析 HTML/XML 的经典首选。
- : 拉网页、调 API 都很顺手。
- : 适合需要 cookie、表单提交、页面跳转的站点。
- / : 自动化真实浏览器(对 JavaScript 很重的网站尤其关键)。
Ruby 脚本的优势是自由度极高:你可以写任意自定义逻辑、做数据清洗、还能和内部系统深度集成。但代价也很现实:网站结构一改,脚本就可能直接挂;而且对不熟代码的人来说,上手门槛确实不低。
AI 网页爬虫与零代码工具:更快、更友好,也更抗变化
像 这种 零代码 网页爬虫,把流程压缩得非常“傻瓜式”。你不需要写代码,只要:
- 打开 Chrome 扩展
- 点击“AI Suggest Fields”,让 AI 自动识别要提取的字段
- 点击“Scrape”,导出数据
Thunderbit 的 AI 能更好地适应网页布局变化,还支持抓取子页面(比如商品详情页),并且可以直接导出到 Excel、Google Sheets、Airtable 或 Notion。对想快速出结果的业务用户来说,这种 AI 网页爬虫真的很香。
一眼对比更清楚:
| 方式 | 优点 | 缺点 | 适合人群 |
|---|---|---|---|
| Ruby 脚本 | 掌控力强、可写自定义逻辑、灵活度高 | 学习成本高、需要持续维护 | 开发者/高级用户 |
| AI 网页爬虫 | 零代码、搭建快、能适应页面变化 | 细粒度控制较少、可能有功能边界 | 业务用户/运营团队 |
趋势也很明显:网站越来越复杂、反爬越来越强,AI 网页爬虫正在变成多数业务场景的优先选项。
入门准备:搭建 Ruby 网页抓取环境
如果你想试试 Ruby 脚本抓取,先把环境搭起来。好消息是:Ruby 安装不折腾,Windows、macOS、Linux 都能跑。
第 1 步:安装 Ruby
- Windows: 下载 按提示安装。记得勾选 MSYS2,用来编译原生扩展(像 Nokogiri 这类 gem 可能会用到)。
- macOS/Linux: 更推荐用 管理版本。在终端执行:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(最新稳定版以 为准。)
第 2 步:安装 Bundler 与常用 gem
Bundler 用来管理依赖:
1gem install bundler为项目创建 Gemfile:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'然后执行:
1bundle install这样环境就统一、可复现,随时开抓。
第 3 步:验证安装是否成功
在 IRB(Ruby 交互式命令行)里跑一下:
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSION能输出版本号就说明 OK。
手把手:写你的第一个 Ruby 网页爬虫
我们用一个真实练习站来演示——从 抓取商品数据,这是专门给大家练手的抓取网站。
下面这段 Ruby 脚本会提取书名、价格和库存状态:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"这个脚本会逐页抓取、解析 HTML、提取字段,然后写入 CSV。你可以直接用 Excel 或 Google Sheets 打开 books.csv。
常见坑:
- 如果提示缺少 gem,检查 Gemfile 后重新执行
bundle install。 - 如果网站数据是 JavaScript 动态加载的,你可能需要 Selenium 或 Watir 这种浏览器自动化方案。
用 Thunderbit 给 Ruby 抓取“加速”:AI 网页爬虫实战
接下来聊聊怎么用 把效率直接拉满——而且完全不用写代码。
Thunderbit 是一款 ,基本两次点击就能从任意网站提取结构化数据。流程是这样的:
- 在目标页面打开 Thunderbit 扩展。
- 点击 “AI Suggest Fields”:Thunderbit 的 AI 会扫描页面并推荐最合适的列(比如“商品名”“价格”“库存”)。
- 点击 “Scrape”:自动抓取数据、处理翻页;需要的话还会继续抓子页面拿更多详情。
- 导出数据:直接导出到 Excel、Google Sheets、Airtable 或 Notion。
Thunderbit 的核心亮点是:能应对复杂、动态网页——不需要脆弱的选择器,也不需要写代码。如果你想做混合流程,也可以先用 Thunderbit 把数据抓出来,再用 Ruby 脚本做进一步处理或补充。
小技巧: 对电商、房产团队来说,Thunderbit 的子页面抓取真的很省命。先抓列表页的链接,再让 Thunderbit 自动逐个打开详情页,把规格、图片、评论等字段补齐,相当于自动“丰富数据集”。
实战案例:用 Ruby + Thunderbit 抓取电商商品与价格
我们用电商团队最常见的工作流,把两者串起来跑一遍。
场景: 你要监控竞品在数百个 SKU 上的价格和商品信息。
第 1 步:用 Thunderbit 抓取商品列表页
- 打开竞品的商品列表页。
- 启动 Thunderbit,点击“AI Suggest Fields”(比如:商品名、价格、URL)。
- 点击“Scrape”,导出为 CSV。
第 2 步:用子页面抓取补全字段
- 在 Thunderbit 里用“Scrape Subpages”,逐个访问商品详情页,提取更多字段(如描述、库存、图片)。
- 导出补全后的表格。
第 3 步:用 Ruby 做清洗/分析
- 用 Ruby 脚本进一步清洗、转换或分析数据。例如:
- 把价格统一换算成同一币种
- 过滤缺货商品
- 生成汇总统计
下面是一个简单 Ruby 片段,用来筛选“有货”的商品:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6end结果:
你可以从原始网页直接拿到一张干净、可执行的数据表,用于定价分析、库存规划或营销投放——而且整个抓取过程你没有写任何一行抓取代码。
零代码也没问题:让每个人都能自动化提取网页数据
我特别喜欢 Thunderbit 的一点是:它真的把自动化带给了非技术用户。你不需要懂 Ruby、HTML 或 CSS——打开扩展,让 AI 自动识别字段,然后导出就完事。
上手成本: Ruby 脚本需要理解编程基础和网页结构;Thunderbit 的配置通常几分钟就能搞定。
集成能力: Thunderbit 可直接导出到业务团队常用工具——Excel、Google Sheets、Airtable、Notion;还支持定时抓取,适合做持续监控。
用户反馈: 我见过市场团队、销售运营、电商负责人用 Thunderbit 自动化完成从线索名单到价格追踪的各种任务,全程不需要找 IT 排期。
最佳实践:Ruby + AI 网页爬虫组合,做可扩展的自动化
想把抓取流程做得更稳、更可扩展?下面这些建议很落地:
- 应对网站改版: Thunderbit 这类 AI 网页爬虫通常能自动适配;如果用 Ruby 脚本,网站结构一变就要准备更新选择器。
- 定时抓取: 用 Thunderbit 的定时功能做周期性拉取;Ruby 则可以用 cron 或任务计划。
- 分批处理: 数据量大时分批抓取,降低被封风险,也避免系统压力过大。
- 数据格式化: 分析前务必清洗与校验数据——Thunderbit 导出已结构化,但自写 Ruby 脚本可能需要额外检查。
- 合规: 只抓取公开数据,尊重
robots.txt,并注意隐私法规(尤其在欧盟,)。 - 备选方案: 如果网站过于复杂或强力反爬,优先考虑官方 API 或替代数据源。
什么时候用哪种?
- 需要完全掌控、自定义逻辑或对接内部系统:用 Ruby 脚本。
- 追求速度、易用性与适应性(尤其一次性或周期性业务任务):用 Thunderbit。
- 高阶玩法:Thunderbit 负责提取,Ruby 负责丰富、质检或集成。
总结与要点回顾
Ruby 网页抓取一直是自动化采集数据的“硬核技能”;而现在有了 Thunderbit 这样的 AI 网页爬虫,这种能力也真正普及给了所有人。无论你是追求灵活性的开发者,还是只想快速拿到结果的业务用户,都能把网页数据提取自动化,省下大量手工时间,并更快做出更好的决策。
希望你带走这些关键点:
- Ruby 非常适合做网页抓取与自动化——Nokogiri、HTTParty 等 gem 能显著提效。
- Thunderbit 让非程序员也能轻松提取数据,比如“AI Suggest Fields”和子页面抓取等功能。
- Ruby + Thunderbit 组合能兼顾两端优势: 快速零代码提取 + 自定义自动化与分析。
- 对销售、市场、电商团队来说,自动化采集网页数据是高回报策略——减少手工、提升准确性、挖掘更多洞察。
准备开始了吗?去,再试试一个简单的 Ruby 脚本,看看你能省下多少时间。如果想继续深入,也可以逛逛 ,里面有更多指南、技巧与真实案例。
常见问题(FAQs)
1. 使用 Thunderbit 做网页抓取需要会写代码吗?
不需要。Thunderbit 面向非技术用户设计:打开扩展,点击“AI Suggest Fields”,剩下交给 AI。数据可直接导出到 Excel、Google Sheets、Airtable 或 Notion,全程无需写代码。
2. 用 Ruby 做网页抓取的主要优势是什么?
Ruby 有 Nokogiri、HTTParty 等强大库,适合搭建灵活、可定制的抓取流程。对需要完全控制、自定义逻辑并与其他系统集成的开发者来说尤其合适。
3. Thunderbit 的“AI Suggest Fields”是怎么工作的?
Thunderbit 的 AI 会扫描网页内容,识别最相关的数据字段(如商品名、价格、邮箱等),并自动建议一张结构化表格。抓取前你也可以按需调整列。
4. 能把 Thunderbit 和 Ruby 脚本结合起来做更复杂的流程吗?
当然可以。很多团队会用 Thunderbit 先把复杂/动态网站的数据提取出来,再用 Ruby 做进一步处理或分析。这种混合方式很适合自定义报表或数据补全。
5. 网页抓取用于商业场景是否合法、安全?
在抓取公开数据、遵守网站服务条款与隐私法规的前提下,网页抓取通常是合法的。请务必查看 robots.txt,并避免在没有适当授权的情况下抓取个人数据——尤其是欧盟用户需遵守 GDPR。
想看看网页抓取如何改变你的工作流?现在就试试 Thunderbit 的免费版本,或用 Ruby 脚本做个小实验。如果遇到问题, 和 里有大量教程与技巧,帮助你把网页数据自动化真正跑起来——无需写代码。
了解更多