
在数字时代,能把网站上每个页面都一一列出来,简直比洗衣服时能配对所有袜子还让人有成就感。但如果你曾经为了内容盘点、网站迁移,或者单纯想看看网站“角落”里还藏着哪些页面而试图整理网站页面,你一定明白,这事远比想象中复杂。我见过不少团队花上好几个小时甚至几天,东拼西凑地从 sitemap、Google 搜索和 CMS 导出页面列表,最后才发现还有隐藏页面或动态页面被漏掉。更别说我帮朋友导出 WordPress 所有 URL 的那次,咖啡喝了不少,心态也差点崩了。
好消息是,你不用再和自己的网站玩“数字捉迷藏”了。这篇指南会带你了解各种主流获取网站 URL 的方法——不管是传统方式还是新一代 AI 工具,比如 ,都能让这个过程变得更快、更全面,甚至有点意思。不管你是市场、开发,还是被分配到“把所有页面都找出来”这项任务的倒霉蛋,这里都有实用步骤、真实案例和方法对比,帮你选出最适合团队的方案。
为什么要获取网站页面?这些场景你肯定遇到过
在聊“怎么做”之前,先说说“为什么”。为什么这么多团队都要整理网站 URL?其实,这不仅仅是 SEO 的需求,市场、销售、IT、运营等部门都经常会用到。常见的场景包括:
- SEO 内容盘点与策略调整: 内容盘点已经成了常规操作,。完整的 URL 列表是评估内容表现、更新旧内容、提升排名的基础。事实上,。
- 网站改版与迁移: ),每次迁移都需要梳理现有 URL,避免死链和 SEO 损失。
- 合规与维护: 运维团队需要找出孤立或过时页面——有时候早年的活动页还在悄悄上线,随时可能“翻车”。
- 竞品分析: 市场和销售团队会爬取竞品网站,整理产品页、价格页或博客,寻找市场空白或潜在客户。
- 获客与外联: 销售团队经常需要整理门店、经销商、会员页面等资源,方便外联。
- 内容资产盘点: 内容团队需要持续维护所有博客、落地页、PDF 等列表,避免重复、提升价值。
下面这张表简单总结了这些场景:
| 场景 | 需求方 | 为什么需要完整页面列表 |
|---|---|---|
| SEO/内容盘点 | SEO 专家、内容市场 | 全面评估内容,遗漏页面=分析不全、错失优化机会 |
| 网站迁移/改版 | 开发、SEO、IT、市场 | 旧新 URL 映射、设置重定向,防止死链和 SEO 损失 |
| 竞品分析 | 市场、销售 | 全面了解竞品页面,隐藏页面可能带来新机会 |
| 获客 | 销售团队 | 整理外联资源,确保不漏掉潜在客户 |
| 内容资产盘点 | 内容市场 | 维护最新内容库,发现空白,避免重复,复查旧页面 |
如果遗漏了隐藏页面,后果可不小。比如改版时忘了一个还在转化的落地页,或者内容盘点时漏掉 5% 没被收录的页面——这都可能导致收入损失、SEO 受罚,甚至公关危机。
常见获取网站 URL 的传统方法
那大家通常怎么获取网站页面?有几种常用方法——有的简单粗暴,有的更全面但也更繁琐。下面一一介绍:
Google 搜索与搜索指令
操作方式:
在 Google 输入 site:yourwebsite.com,Google 会显示它收录的所有页面。你还可以加关键词或子目录(比如 site:yourwebsite.com/blog)。
结果:
能看到 Google 已收录的页面列表。
局限:
- 只显示已收录页面,遗漏未收录内容
- 结果通常几百条就截止,大站更明显
- 新页面、隐藏页、未收录页都看不到
适用场景:
适合快速查看或小型网站,不适合全面盘点。
检查 robots.txt 和 Sitemap.xml
操作方式:
访问 yourwebsite.com/robots.txt,查找“Sitemap:”字段。打开 sitemap(通常是 yourwebsite.com/sitemap.xml 或 /sitemap_index.xml)。sitemap 会列出站长希望被收录的页面。
结果:
能看到主要页面列表——比如所有博客、产品页等。。
局限:
- 只包含站长希望收录的页面,隐藏页、孤立页常常遗漏
- sitemap 可能过时,未及时更新
- 有的网站有多个 sitemap,需要逐个查找
适用场景:
适合自有网站或快速了解竞品主要页面。但你看到的只是站长想让你看到的内容。
SEO 爬虫工具与网站爬虫
操作方式:
用 Screaming Frog、Sitebulb、DeepCrawl 等工具模拟搜索引擎爬虫。输入网站 URL,工具会跟随所有内链,生成页面列表。
结果:
理论上能抓到所有有内链的页面,还能获取状态码、元标签等数据。
局限:
- 孤立页面(无内链)除非手动导入,否则抓不到
- 动态或 JS 渲染页面,工具不支持 headless 浏览时会遗漏
- 大型网站爬取慢、占用内存高
- 需要一定技术基础
适用场景:
适合 SEO 专业人士或开发者做深度审查。对非技术用户不太友好。
Google Search Console 与 Analytics
操作方式:
有站点权限时,Google Search Console(GSC)和 Analytics 可导出 URL 列表。
- GSC: Index Coverage 和 Performance 报告可导出收录和排除的 URL(每次最多 1,000 条,API 可更多)。
- Analytics: 可导出一定时间内有流量的所有页面(GA4 最多 10 万行)。
局限:
- 只显示 Google 已知或有流量的页面
- 导出有上限(GSC 1,000 条,GA4 10 万条)
- 需站点所有权/验证,无法用于竞品分析
- 零流量或未收录页面不会显示
适用场景:
适合自有网站,尤其是迁移或盘点前。不适合竞品分析。
CMS 后台导出
操作方式:
WordPress、Shopify 等 CMS 通常可直接从后台导出页面和文章(有时需插件)。
结果:
能导出所有内容项——页面、文章、产品等。
局限:
- 需管理员权限
- 可能不包含非内容页或动态页
- 多系统(如博客、商城、文档)需合并导出
适用场景:
适合站长做内容盘点或备份。不适合竞品分析。
传统方法的局限性
说实话,这些方法都不完美。主要问题有:
- 技术门槛高: 很多方法需要技术能力或专用工具。对非技术成员来说,门槛很高。大站手动盘点甚至可能。
- 覆盖不全: 各方法都可能遗漏部分页面——Google 索引漏掉未收录或新页面,sitemap 漏掉孤立页,爬虫漏掉无内链或动态页,CMS 导出漏掉系统外内容。
- 手动繁琐: 经常需要合并多方数据、去重、清洗——既枯燥又容易出错。有人甚至用“复制粘贴到 Excel”或命令行脚本来“凑数”。
- 维护难: 列表很快就过时。传统方法每次网站变动都要重做一遍。
- 权限受限: 有些方法需要管理员权限或站点所有权——竞品分析时用不了。
- 数据冗余: SEO 爬虫常常输出一堆技术数据,而你只想要简单的 URL 列表。
总之,传统流程就像“烤蛋糕时食谱随时变,烤箱还偶尔锁门”。(内容策略师的真实比喻——我深有体会。)
认识 Thunderbit:AI 驱动的网页 URL 获取新方式
终于到有趣的部分了。如果你能像吩咐助手一样说“帮我把这个网站所有页面都列出来”,而且它真的能做到——无需写代码、无需折腾设置,这就是 的价值所在。
Thunderbit 是一款为非技术用户设计的 AI 网页爬虫 Chrome 插件(当然也足够强大,适合专业人士)。它用 AI“读懂”网站结构,自动整理并导出所有网站 URL——包括隐藏、动态和子页面内容。你无需写代码,也不用配置复杂参数。只需打开网站,点击“AI 智能识别字段”,剩下的交给 Thunderbit。
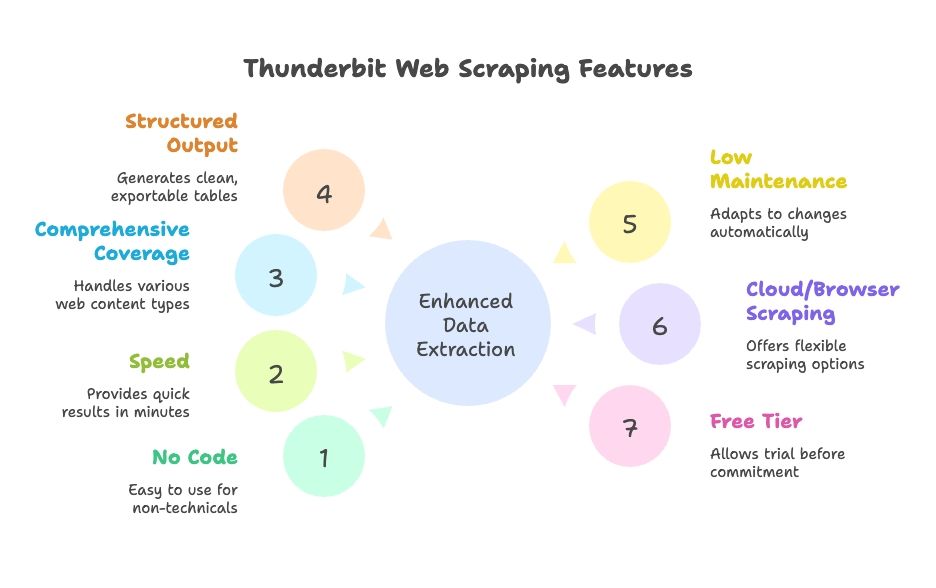
Thunderbit 的优势:
- 零代码、零配置: 自然语言界面,AI 引导,团队任何人都能用
- 速度快: 几分钟出结果,不用等半天
- 覆盖全面: 动态内容、分页、无限滚动、子页面都能抓
- 结构化输出: 干净表格,一键导出到 Google Sheets、Excel、Airtable、Notion、CSV、JSON
- 低维护: AI 自动适应网站变化,极少需要手动调整
- 云端或本地爬取: 灵活选择,适配不同工作流
- 免费试用: 有免费额度,先用再说
Thunderbit 如何让获取网站页面变得简单
下面带你实际体验 Thunderbit,从“我需要所有页面列表”到“老板,这里是表格”只需几步。
步骤 1:安装并启动 Thunderbit
下载 ,固定到浏览器。进入你要抓取的网站(比如首页),点击 Thunderbit 图标打开界面。
小贴士:Thunderbit 新用户有免费额度,注册即可体验,无需绑定信用卡。
步骤 2:选择数据源
Thunderbit 默认抓取当前页面,你也可以输入一组 URL(比如 sitemap 或分类页),从特定板块开始。
- 大多数网站建议从首页或 sitemap 开始
- 电商网站可从分类页或产品列表页入手
步骤 3:用“AI 智能识别字段”检测 URL
AI 魔法来了。点击“AI 智能识别字段”(或“AI 智能识别列”),Thunderbit 的 AI 会扫描页面,自动识别并建议“页面标题”“页面 URL”等字段。你可以根据需要调整这些列。
- 在首页,通常能抓到导航、底部、推荐等链接
- 在 sitemap 页面,能直接获得干净的 URL 列表
- 你可以增删字段,或细化提取内容
Thunderbit 的 AI 帮你搞定了繁琐的 XPaths 或 CSS 选择器。就像有个懂你需求的机器人实习生。
步骤 4:开启子页面爬取
大多数网站不会在首页列出所有页面。这时就用上 Thunderbit 的子页面爬取功能。把 URL 列标记为“跟随”链接,Thunderbit 会自动点击每个链接,继续抓取这些页面上的更多 URL。你还可以设置多层模板,实现多级爬取。
- 对于分页列表或“加载更多”按钮,开启分页与滚动,Thunderbit 会自动翻页直到抓全
- 有子域名或分区(比如 ),Thunderbit 也能跟进,只需你指定
步骤 5:运行爬取
点击“开始爬取”,看 Thunderbit 自动填充表格(包括你选的其他字段)。大站可以后台运行,等它完成再回来查看。
步骤 6:复查与导出
爬取完成后,直接在应用内筛选、排序、去重。然后一键导出到 Google Sheets、Excel、CSV、Airtable、Notion 或 JSON。再也不用手动复制粘贴或整理格式。
整个流程? 中小型网站 10 分钟内就能搞定完整 URL 列表。大站也比传统方法快得多,省心不少。
Thunderbit 如何发现隐藏和动态页面
Thunderbit 最让我喜欢的一点,就是它能抓到传统工具常常遗漏的页面:
- JavaScript 渲染内容: Thunderbit 在真实浏览器中运行,能抓到动态加载的页面(比如无限滚动的招聘板、产品列表)
- 孤立或无内链页面: 只要你有线索(比如 sitemap 或站内搜索),Thunderbit 就能帮你找出这些页面
- 子域名或分区: Thunderbit 可跨子域名跟踪,帮你全面梳理网站结构
- 模拟用户操作: 需要填写搜索框或点击筛选才能显示的页面?Thunderbit 的AI 自动填表也能搞定
真实案例: 某市场团队需要找出所有旧落地页——很多页面没有内链但还在上线。用 Thunderbit 抓取 Google 搜索结果并输入已知 URL 规律,最终挖出了几十个被遗忘的页面,避免了公司混乱和损失。
Thunderbit 与传统方法对比:速度、易用性与覆盖率
来看看 Thunderbit 和传统方法的正面对比:
| 维度 | Google “site:” 搜索 | XML Sitemap | SEO 爬虫(Screaming Frog) | Google Search Console | CMS 导出 | Thunderbit AI 网页爬虫 |
|---|---|---|---|---|---|---|
| 速度 | 很快但有限 | 有就秒出 | 视规模而定(几分钟到几小时) | 小站快 | 小站快 | 快,几分钟配置,自动爬取 |
| 易用性 | 非常简单 | 简单 | 需配置,略复杂 | 需权限,操作中等 | 管理员易用 | 极易用,无需代码 |
| 覆盖率 | 低(仅收录页) | 主要页面高 | 内链页面高 | 收录页高,导出有限 | 内容页中等 | 极高,动态/子页面全覆盖 |
| 输出与集成 | 手动复制 | XML(需解析) | CSV,数据杂 | CSV/Excel,最多 1,000 行 | CSV/XML,需整理 | 干净表格,一键导出 Sheets、Excel 等 |
| 维护 | 手动重做 | 需更新 | 网站变动需重爬 | 定期导出 | 变动后导出 | 低——AI 自动适应,可定时爬取 |
Thunderbit 在易用性、完整性和集成方面表现突出。传统方法各有优点,但需要多次合并、手动维护。Thunderbit 的 AI 能自动适应网站变化,无需频繁调整或重复导出。
如何选择:不同角色适合哪种方法?
那哪种方法最适合你?结合多年帮团队梳理网站数据的经验,给你几点建议:
- SEO 专业/开发者: 需要深度技术数据(比如元标签、死链)或超大站点时,爬虫或自定义脚本依然有用。但 Thunderbit 能快速导出 URL 列表,供你后续分析。
- 市场、内容、项目经理: Thunderbit 是救星。无需等 IT 跑脚本或合并导出,内容盘点、竞品分析、快速审查都能自助完成。
- 销售/获客团队: Thunderbit 轻松抓取门店、活动、会员目录等列表,无需写代码。
- 小型网站/简单任务: 小站手动查或用 sitemap 也行。但 Thunderbit 配置极快,避免遗漏。
- 预算有限: 传统方法几乎免费(但耗时)。Thunderbit 有免费版,付费方案也适合大多数企业。别忘了:你的时间也很宝贵!
- 高度定制需求: 需要极其复杂的数据或逻辑时,可能要自写爬虫。但 Thunderbit 的 AI 已能满足绝大多数场景。
决策建议:
- 自有网站且页面少于 1,000,可先用 Google Search Console 导出,但要核查完整性
- 没有站点权限或需竞品数据,Thunderbit 或爬虫更合适
- 重视效率、希望方案可扩展,Thunderbit 是首选
- 团队协作时,Thunderbit 可直接导出到 Google Sheets,非常方便
很多企业会混合使用:Thunderbit 负责快速任务和非技术成员,传统工具用于深度审查。
核心总结:满足各类业务需求的网站页面获取
最后总结一下:
- 完整的网站页面列表至关重要,无论是 SEO、内容策略、迁移还是销售研究。它能避免意外、死链和错失机会。现在大多数市场人员每年至少做一次内容盘点()。
- 传统方法各有短板。 没有一种方法能保证完整、实时的列表,且常需技术能力和多方合并。
- AI 网页爬虫(Thunderbit)是现代解决方案。 Thunderbit 用 AI 自动“思考”和点击,让网页爬取人人可用。它能抓取动态内容、子页面,并以可用格式导出数据——省时省力,减少错误。实际对比中,Thunderbit 往往几分钟搞定过去要花数小时的工作,几乎没有学习门槛()。
- 按需选择方法。 大型网站可多工具结合,但对大多数企业用户,Thunderbit 就能满足绝大多数需求。
- 保持更新。 定期盘点能及时发现问题,让网站高效运转。Thunderbit 支持定时爬取,手动流程则常常因繁琐被搁置。
最后一句: 别再为“不知道自己网站上有什么”找借口了。用对方法,你就能全面掌控所有页面,用这些数据提升 SEO、用户体验和业务决策。让 AI 帮你省力,确保每个页面都不被遗漏。
下一步
如果你不想再为“把所有 URL 都找出来”而头疼,,在自己或竞品网站上试试。你会惊讶于节省下来的时间和精力。如果想深入了解网页爬取,欢迎阅读 的其他指南,比如或。
常见问题
1. 为什么需要获取网站所有页面的列表?
SEO、市场、销售、IT 等团队经常需要完整的 URL 列表,用于内容盘点、网站迁移、获客和竞品分析。完整准确的列表能避免死链、内容重复或遗漏,并发现隐藏机会。
2. 传统方法有哪些?
常见方法包括用 Google 的 site: 搜索、查 sitemap.xml 和 robots.txt、用 SEO 工具(如 Screaming Frog)爬取、从 CMS(如 WordPress)导出、以及用 Google Search Console 和 Analytics 导出收录/有流量页面。但每种方法在覆盖率和易用性上都有局限。
3. 传统方法的局限性有哪些?
传统方法常常遗漏动态、孤立或未收录页面。需要技术知识,数据合并和清洗耗时,且不适合大站或重复盘点。有些还需要站点权限或管理员账号,竞品分析时无法使用。
4. Thunderbit 如何简化网站页面获取?
Thunderbit 是一款 AI 网页爬虫,像真人一样浏览网站——点击子页面、处理 JavaScript、自动结构化数据。无需写代码,通过 Chrome 插件几分钟内即可导出干净的 URL 列表到 Google Sheets、Excel、CSV 等。
5. 哪些人适合用 Thunderbit,哪些适合传统工具?
Thunderbit 适合市场、内容、销售和非技术用户,快速获取完整 URL 列表。传统工具适合需要深度元数据或自定义脚本的技术审查。很多团队会两者结合——Thunderbit 负责高效、易用,传统工具做深入分析。