
如果你正在找 AI 驱动的网页爬虫工具,大概率已经听说过 Crawl4AI。它是一个很受欢迎的开源项目,凭借速度和灵活性,在开发者圈里讨论度很高。不过,如果你不是程序员,或者你只是想快点拿到数据,不想和 Python 脚本死磕呢?不管你是在考虑把 Crawl4AI 用在下一个项目里,还是在找一个更容易上手的替代方案,尤其是你从事销售、市场、跨境电商或房地产工作,这篇文章都很适合你。在这篇评测里,我会拆解 Crawl4AI 能做什么、优势在哪里,以及它可能在哪些地方让你觉得还差点意思。我也会告诉你,Thunderbit 作为一款现代化的免代码解决方案,是怎么帮助那些想用几次点击就抓取网页的商务用户的。
什么是 Crawl4AI?
Crawl4AI 是一个开源 Python 库,专为网页爬取和数据提取而设计,尤其面向 AI 和大语言模型(LLM)使用场景。它在 GitHub 上吸引了不少关注,因为它支持高速、并行抓取,而且可以把数据输出为 JSON、Markdown 这类更适合 AI 处理的格式。简单来说,它是一套给开发者用的工具,既能大规模抓取网站数据,也能把这些数据喂给 AI 模型、数据分析看板或自定义数据库。
![]()
主要产品和功能:
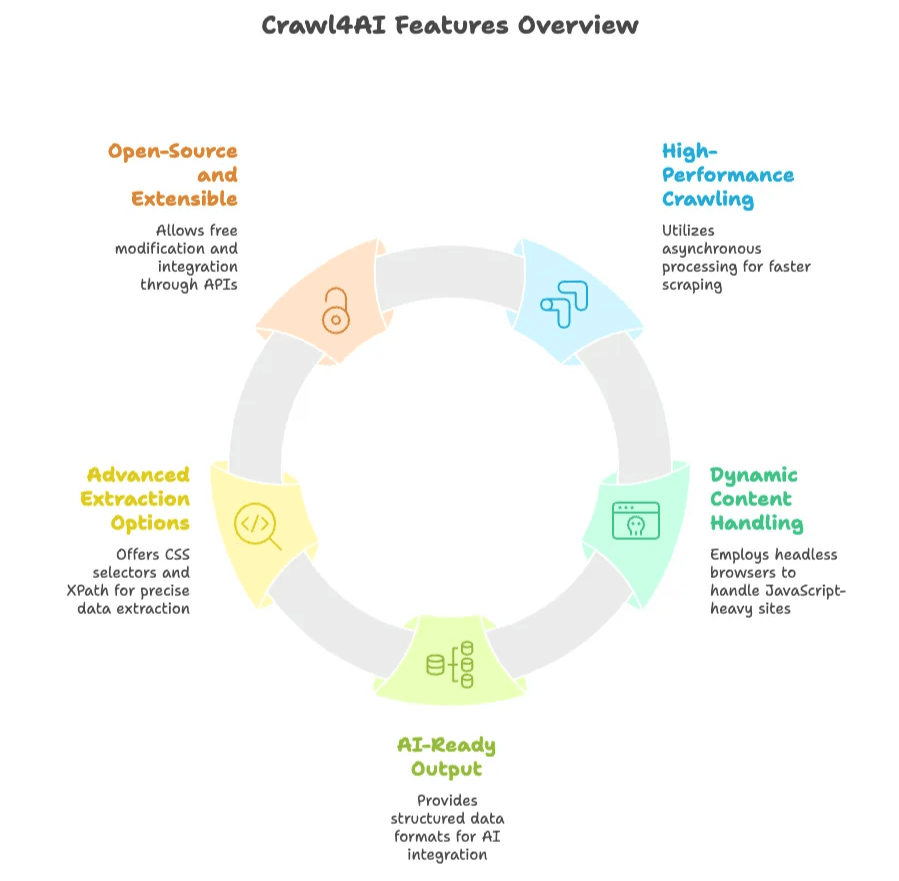
- 高性能抓取: 采用异步并行处理,一次可以抓取多个页面,所以比很多传统爬虫快得多。
- 动态内容处理: 通过无头浏览器(例如借助 Playwright 控制 Chromium)执行 JavaScript,抓取现代化动态网站。
- AI 就绪输出: 将数据输出为结构化文本(JSON、Markdown 或清洗后的 HTML),可直接用于 AI 或数据分析。
- 高级提取选项: 允许用户通过 CSS 选择器或 XPath 指定提取规则,甚至还能集成 LLM 做内容总结或提取。
- 开源且可扩展: 免费使用、修改和扩展。提供 Python API、命令行接口和 REST API,方便灵活集成。
Crawl4AI 的理念,是通过给开发者提供一个快速、代码驱动的爬虫,而不加商业工具那种付费墙或限制,来“让数据民主化”。如果你熟悉 Python,它确实是快速收集海量网页数据的强大方式。
Crawl4AI 适合谁?
Crawl4AI 主要面向技术用户——比如开发者、数据科学家、AI 研究人员,以及任何熟悉编写 Python 脚本的人。下面是一些典型用例:
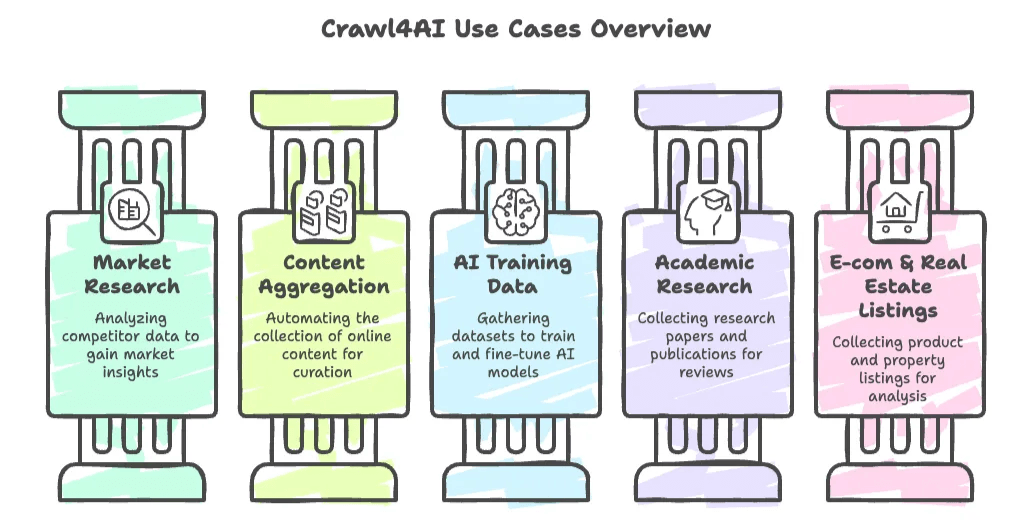
- 市场研究与竞品分析: 抓取竞争对手网站、新闻文章或社交媒体,获取洞察。
- 内容聚合: 自动收集新闻、博客或论坛帖子,用于内容整理或趋势追踪。
- AI 训练数据采集: 收集大规模数据集(例如文档、问答或文章),用于训练或微调语言模型。
- 学术研究: 自动收集研究论文、判例法或在线出版物,用于文献综述。
- 电商与房地产列表: 开发者可以构建自定义爬虫,收集商品或房源列表用于分析。
但问题在于:Crawl4AI 不是为非技术用户设计的。 如果你是没有编程经验的销售经理、市场人员或房产经纪人,大概率会觉得它的配置和使用门槛很高。这个工具默认你熟悉 Python,也能自己配置提取规则并排查问题。
Crawl4AI 价格方案
Crawl4AI 最吸引人的一点就是价格:完全免费。作为开源项目,它没有许可证费用、订阅档位或付费墙。你可以通过 pip 安装后立刻开始使用。
不过,“免费”也有一些前提:
- 部署和维护: 你需要投入时间搭建环境、编写脚本,并维护抓取流程。
- 间接成本: 如果你要做大规模抓取,可能还要为代理、服务器或云资源付费。
- 支持: 没有官方客服支持,只有社区论坛和 GitHub issues。
对于拥有内部技术人员的企业来说,这可能是个很划算的方案。但对非技术团队来说,真正上手所需的时间和精力,很快就会抵消“零成本”的吸引力。
Crawl4AI 用户反馈
为了更真实地了解 Crawl4AI 的表现,我查阅了技术博客、AI 工具目录和社区论坛中的用户评价。结果如下:
用户喜欢什么
- 速度快、成本低: 开发者普遍称赞 Crawl4AI 在抓取大型网站时非常快,很多时候甚至比付费工具还强。它免费这一点更是巨大加分项。
- 开源灵活: 用户喜欢对代码拥有完全控制权,没有厂商锁定,也没有功能限制。
- AI 就绪输出: 结构化、干净的数据输出(尤其是 JSON 或 Markdown)能为那些要把数据喂给 AI 模型或分析工具的人节省大量时间。
用户遇到的困难
不过,这些好评后面也伴随着不少限制——尤其是对新手或非程序员来说。
1. 学习曲线陡峭
一个反复出现的评价是:Crawl4AI 对新手不友好。如果你刚接触网页爬取,或者不熟悉 Python,就会面临很高的学习门槛。它没有那种点点鼠标就能完成操作的界面;所有事情都要通过脚本和配置文件来做。搭建环境、编写提取规则,以及处理异步抓取,都需要技术能力。有位评测者直说:“如果你不是程序员,你会完全摸不着头脑。”
2. 对初学者不够友好
即使你有一定技术背景,Crawl4AI 也未必轻松。文档虽然在持续完善,但社区规模仍然较小,遇到问题时求助速度可能比较慢。用户反馈在复杂网站上会碰到 bug 或崩溃,而排查问题往往意味着要翻 GitHub issues 或 Stack Overflow。它也缺少很多常见商业场景所需的内置功能,比如网站登录、验证码处理,或者定时运行任务。如果你想按计划抓取数据,或者处理认证流程,就需要自己把这些功能搭起来。
真实案例:
- 某中型电商公司的市场经理尝试用 Crawl4AI 监控竞品价格。折腾了几天 Python 脚本和浏览器驱动后,他还是放弃了,转而使用免代码工具。技术门槛高、又缺少支持,让这个方案对团队来说不现实。
- 一位房产经纪人想从多个网站抓取房源信息,但发现 Crawl4AI 的配置太复杂,连初始设置都没能顺利完成。没有开发者在旁协助,这个项目就卡住了。
总之,虽然 Crawl4AI 对开发者来说很强大,但对于只是想省心拿到数据的商务用户而言,它并不算一个好选项。
Crawl4AI 评测要点总结
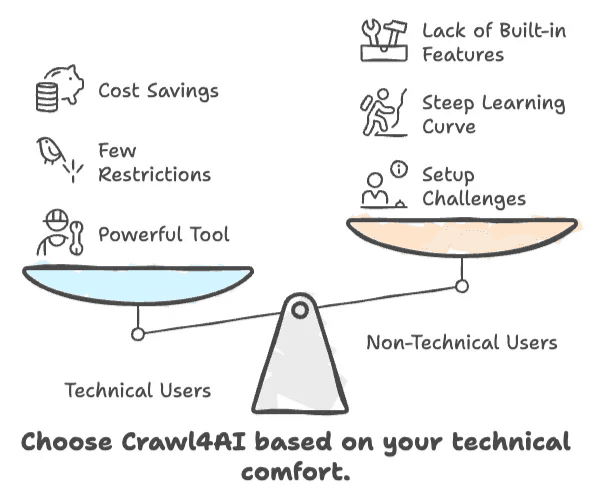
- Crawl4AI 快速、灵活、免费——前提是你会写代码。
- 非技术用户会在配置、学习曲线和缺少内置业务功能这几方面遇到困难。
- 如果你需要点点鼠标就能用的免代码方案,Crawl4AI 大概率不适合你。
- 对开发者和 AI 从业者来说,它是一款限制很少的强大工具。
- 对商务用户来说,投入的时间和精力可能会超过省下的钱。
介绍 Thunderbit:面向商务用户的免代码 AI 网页爬虫
看完 Crawl4AI 在非技术用户场景下的短板后,我们来聊聊一个更好的替代方案:Thunderbit。
Thunderbit 是一款AI 网页爬虫 Chrome 扩展,专为商务用户打造——销售、市场、电商和房地产专业人士都能用它快速从任何网站提取数据,而且完全不需要写代码。我测过不少爬虫工具,而 Thunderbit 的简洁性和强大能力都很突出。
Thunderbit 有什么不同?
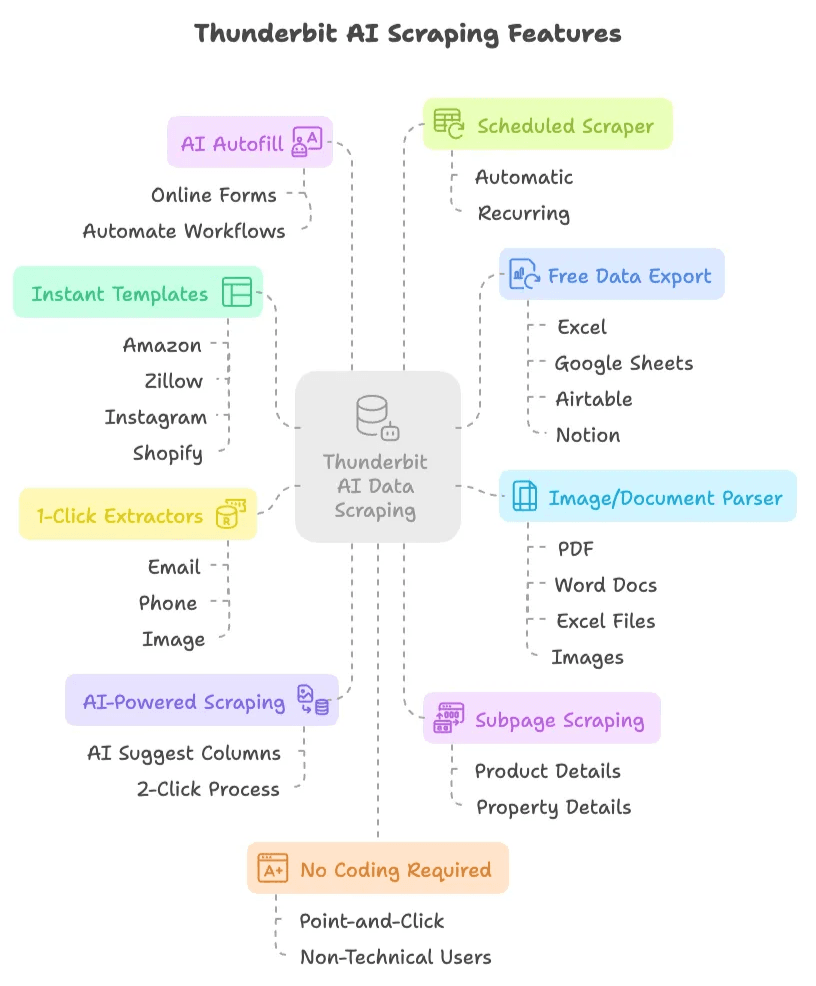
- AI 驱动,2 步抓取: 只要点“AI 建议列”,让 AI 推荐要提取哪些字段,然后再点“抓取”就行。没有脚本、没有选择器、没有烦恼。
- 子页面抓取: Thunderbit 的 AI 可以自动访问子页面(例如商品详情页或房源详情页),并丰富你的数据表,无需手动配置。
- 即时数据爬虫模板: 对于 Amazon、Zillow、Instagram 和 Shopify 等热门网站,你可以使用预置模板一键导出数据。
- 免费数据导出: 你可以把抓取的数据导出到 Excel、Google Sheets、Airtable 或 Notion,而且不用额外付费。
- AI 自动填表(完全免费): 用 AI 填写在线表单并自动化工作流。只要选中上下文,剩下的交给 Thunderbit。
- 定时爬虫: 只需简单设置计划,就能自动、周期性抓取,不需要 cron 任务或服务器配置。
- 一键邮箱、电话和图片提取器: 立即从任何网站抓取邮箱、电话号码或图片。
- 图片/文档解析器: 从 PDF、Word 文档、Excel 文件或图片中提取表格。上传文件,让 AI 结构化数据,然后点击“抓取”即可。
- 无需编程: 一切都支持点选操作,专为非技术用户设计。
使用 AI 从任何网站抓取数据 Get Started Free
Thunderbit 的目标,就是让网页数据人人都能用,不只是开发者。如果你想看看它怎么工作,可以访问 Thunderbit Chrome 扩展下载页 或浏览 Thunderbit 博客 查看真实用例。
Thunderbit 价格方案
Thunderbit 采用简单的积分系统:1 积分 = 1 条输出行。方案如下:
| 档位 | 月付价格 | 年付价格(月均) | 积分(每月) |
|---|---|---|---|
| 免费版 | 免费 | 免费 | 6 页 |
| 入门版 | $15 | $9 | 500 |
| 专业版 1 | $38 | $16.5 | 3,000 |
| 专业版 2 | $75 | $33.8 | 6,000 |
| 专业版 3 | $125 | $68.4 | 10,000 |
| 专业版 4 | $249 | $137.5 | 20,000 |
你可以从免费版开始,最多抓取 6 页(免费试用可达 10 页)。付费方案会解锁更多积分和高级功能,但即使是免费档,对轻度用户来说也已经相当慷慨。更多详情请查看 Thunderbit 价格 页面。
Thunderbit vs Crawl4AI:对比一览
我们把 Thunderbit 和 Crawl4AI 放在一起,看看各自擅长什么,以及 Thunderbit 是怎么让商务用户的工作更轻松的。
| 功能 / 标准 | Thunderbit | Crawl4AI |
|---|---|---|
| 免代码、点选式界面 | ✅ | ❌ |
| AI 建议列(自动识别) | ✅ | ❌ |
| 子页面抓取(自动) | ✅ | ❌ |
| 即时模板(Amazon 等) | ✅ | ❌ |
| 免费数据导出(Excel、Sheets) | ✅ | ❌ |
| AI 自动填表(表单填写) | ✅ | ❌ |
| 定时抓取(无需代码) | ✅ | ❌ |
| 一键提取邮箱/电话/图片 | ✅ | ❌ |
| 图片/文档表格提取 | ✅ | ❌ |
| 处理动态内容 | ✅ | ✅ |
| 开源 | ❌ | ✅ |
| 需要编程 | ❌ | ✅ |
| 有免费档 | ✅ | ✅ |
| 社区支持 | ✅ | ⚠️(有限) |
| 为商务用户打造 | ✅ | ❌ |
| 为开发者打造 | ⚠️ | ✅ |
| 价格 | $(免费与付费) | 免费 |
| 客户支持 | ✅ | ❌ |
图例:
✅ = 是
❌ = 否
⚠️ = 有限/部分支持
$ = 提供付费方案
结论
如果你是一个喜欢折腾代码、追求完全掌控的开发者,Crawl4AI 是一款强大且免费的海量网页爬取工具。但如果你是商务用户——尤其是销售、市场、电商或房地产从业者——只想省心拿到数据,Thunderbit 显然是更好的选择。它专为非技术用户打造,配备 AI 自动化、即时模板和友好的界面,能让你在几秒内把网站数据变成表格。
常见问题
1. Thunderbit 与 Crawl4AI 这类其他 AI 网页爬虫相比如何?
Thunderbit 面向非技术用户,提供免代码、点选式界面;而 Crawl4AI 是面向开发者的开源 Python 库。Thunderbit 借助 AI 自动化复杂任务,让每个人都能轻松进行网页爬取。
2. Thunderbit 为商务用户提供了哪些独特功能?
Thunderbit 提供 AI 驱动的列建议、子页面抓取、热门网站即时模板,以及可免费导出到 Excel 或 Google Sheets 的功能——全部无需编程。它还包含定时抓取,以及一键提取邮箱、电话号码和图片的功能。
3. Thunderbit 能处理 PDF 或图片这类复杂数据提取吗?
当然可以!Thunderbit 的 AI 能从 PDF、Word 文档、Excel 文件和图片中提取表格。只要上传文件,让 AI 结构化数据,然后点击“抓取”,就能立即得到结果。更多信息请查看 Thunderbit 博客。
了解更多
- 什么是数据爬取,以及 2025 年如何操作 – Thunderbit 博客
- 2025 年最佳网页爬虫工具与软件 – Thunderbit 博客
- 适用于模型级数据集的顶级 AI 数据采集工具 – Medium
- AI 网页爬虫如何帮助进行数据提取和分析 - Forbes
试用 AI 网页爬虫 Get Started Free




