Tumblr 爬虫
Được các chuyên gia tại những công ty hàng đầu tin dùng














Mở khóa dữ liệu Tumblr với Thunderbit
Dễ dàng trích xuất dữ liệu Tumblr như nội dung bài đăng và số lượt thích.
Nắm trọn câu chuyện Tumblr
Các trang danh sách trên Tumblr chỉ hiển thị một phần nội dung. Muốn có bức tranh đầy đủ, bạn cần toàn bộ nội dung bài đăng, thông tin tác giả và toàn bộ dữ liệu liên quan. Thunderbit sẽ tự động truy cập từng trang con được liên kết, trích xuất chi tiết và thêm chúng thành các cột mới, giúp bạn dễ dàng lấy post_id, post_date và nhiều thông tin khác mà không cần nhấp thủ công.
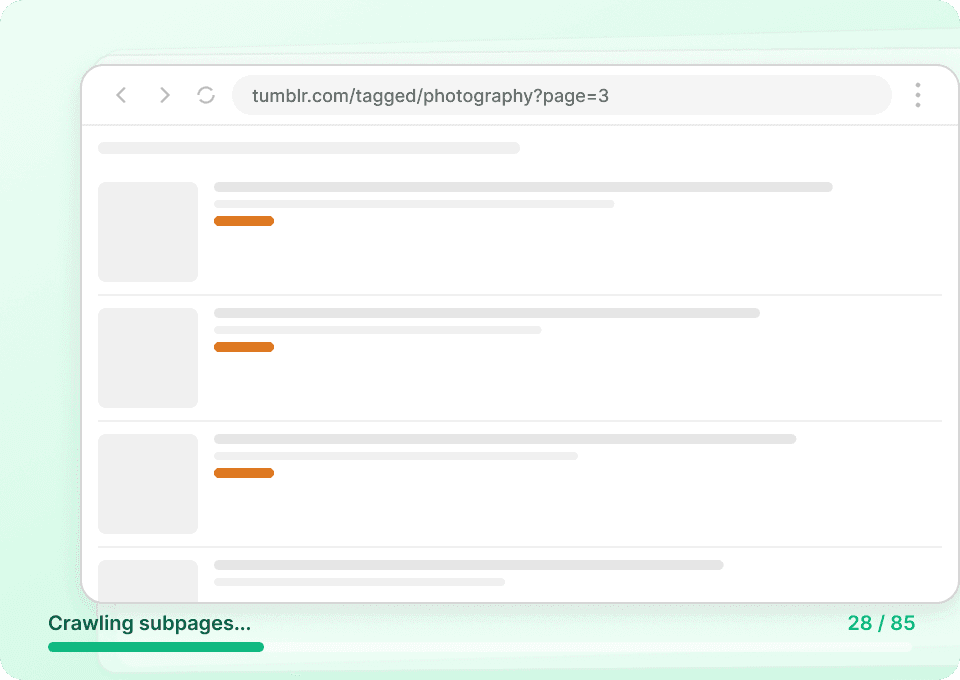
Tự động hóa việc thu thập dữ liệu Tumblr
Dữ liệu Tumblr thay đổi liên tục. Việc lặp đi lặp lại scrape cùng một blog theo cách thủ công rất tốn công. Với tính năng scheduled scraping của Thunderbit, bạn có thể thiết lập các tác vụ định kỳ chạy tự động. Dữ liệu mới như like_count và post_content sẽ được gửi thẳng đến Google Sheets mà bạn không cần động tay.
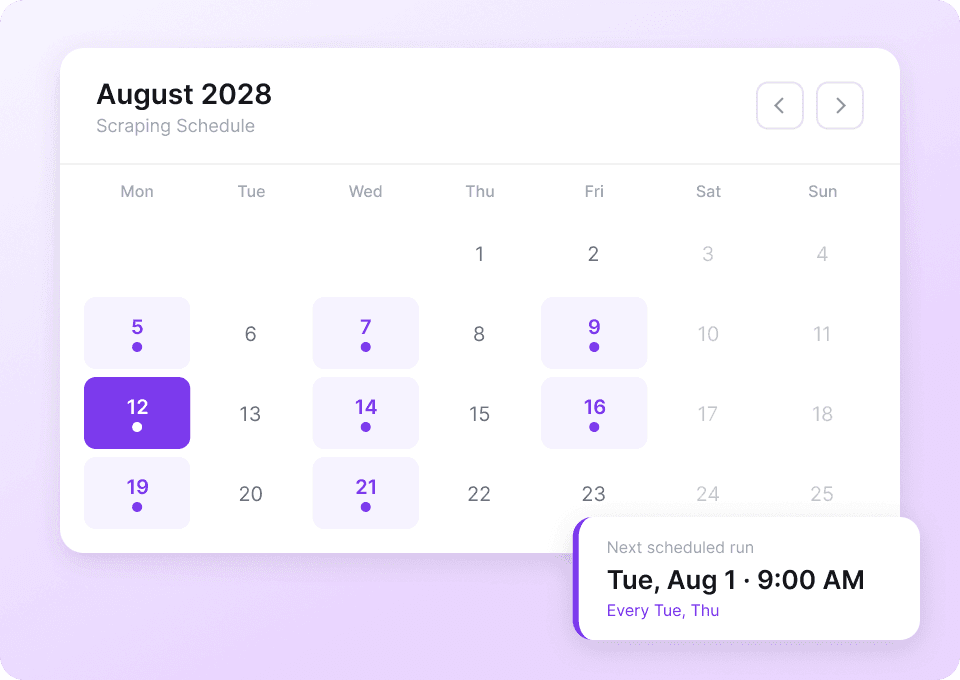
Scrape bài đăng Tumblr chỉ trong 2 cú nhấp
Quên đi những đoạn code phức tạp hay CSS selector rắc rối. Thunderbit cho phép bạn trích xuất dữ liệu Tumblr chỉ trong 2 cú nhấp. Chỉ cần trỏ vào dữ liệu bạn muốn, AI ngữ nghĩa của Thunderbit sẽ nhận diện các trường liên quan như post_type và post_author, rồi tiến hành trích xuất. Không cần code để lấy dữ liệu bạn cần từ Tumblr.
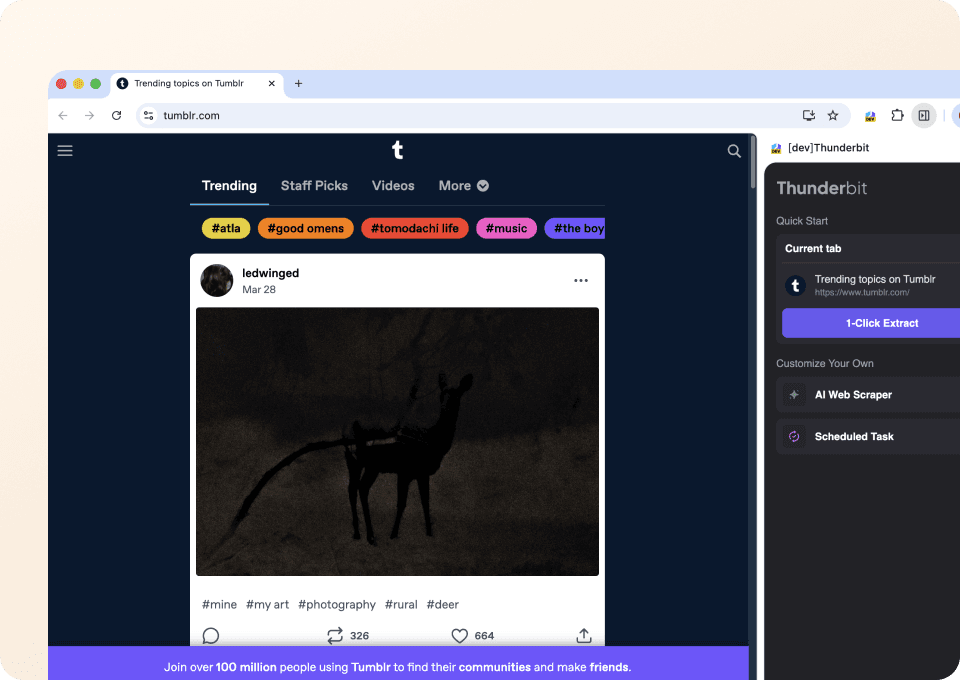
Vì sao Thunderbit khác với các tumblr scrapers truyền thống?
Trích xuất dữ liệu Tumblr dễ dàng, ngay cả khi giao diện thay đổi hoặc bố cục bất ngờ bị xáo trộn.
Các scraper truyền thống
Cách làm cũThunderbit AI
Cách tiếp cận thông minh hơnĐừng chỉ nghe chúng tôi nói
Xem người dùng nói gì về Thunderbit.







Các câu hỏi thường gặp
Liên quan trường hợp sử dụng
Khám phá thêm các trường hợp sử dụng của web scraper Thunderbit.

Trình quét số điện thoại Craigslist
Craigslist Phone Number Scraper của Thunderbit giúp bạn trích xuất số điện thoại và thông tin chi tiết của tin đăng từ kết quả tìm kiếm Craigslist bằng AI. Quét danh sách, mở từng bài đăng để lấy thông tin liên hệ và các trường bổ sung, sau đó xuất sang Excel, Google Sheets, Airtable, Notion, CSV hoặc JSON.
Tìm hiểu thêm ->
Sports Direct Scraper
Chạm để lấy tên sản phẩm, giá bán và phần trăm giảm giá từ Sports Direct bằng AI của Thunderbit — không cần cài đặt phức tạp hay viết mã.
Tìm hiểu thêm ->Công cụ thu thập dữ liệu PeopleWhiz
Công cụ thu thập dữ liệu PeopleWhiz của Thunderbit giúp bạn trích xuất dữ liệu từ kết quả tìm kiếm và hồ sơ PeopleWhiz bằng gợi ý trường dữ liệu do AI hỗ trợ. Thu thập tên, thông tin liên hệ, địa điểm và nhiều dữ liệu khác cho nghiên cứu, marketing hoặc tạo lead. Biến dữ liệu PeopleWhiz thành bộ dữ liệu có cấu trúc nhanh chóng và hiệu quả.
Tìm hiểu thêm ->
United Airlines Scraper
Chỉ cần trỏ và nhấp để thu thập dữ liệu chuyến bay của United Airlines như số hiệu chuyến bay, giờ đến và sân bay khởi hành — phần còn lại để Thunderbit AI lo.
Tìm hiểu thêm ->
Công cụ thu thập dữ liệu Trustpilot
Biến các trang Trustpilot thành một bảng tính gọn gàng với đánh giá, xếp hạng và tên người đánh giá. Chúng tôi đọc từng trang thay bạn, nên bạn không cần viết code hay copy-paste.
Tìm hiểu thêm ->
Công cụ thu thập dữ liệu Coupang
Lấy tên sản phẩm, giá và tỷ lệ giảm giá từ Coupang chỉ với hai cú nhấp — không cần lập trình.
Tìm hiểu thêm ->Sẵn sàng tăng tốc trích xuất dữ liệu chưa?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Dùng thử miễn phí với tín dụng không giới hạn cho 8 trang web.