Sephora 爬虫

Được tin dùng bởi các chuyên gia tại những công ty hàng đầu














Khám phá dữ liệu Sephora chỉ với hai cú nhấp
Thu thập dữ liệu Sephora dễ dàng trong 2 bước
Bạn đã chán ngán những công cụ scrape phức tạp? Thunderbit giúp bạn lấy dữ liệu sản phẩm Sephora mà không cần viết bất kỳ dòng code nào. Chỉ cần trỏ vào tên sản phẩm, thương hiệu, giá bán, xếp hạng, số lượng đánh giá và loại da bạn cần, rồi nhấp để trích xuất. Đơn giản đến thế thôi.
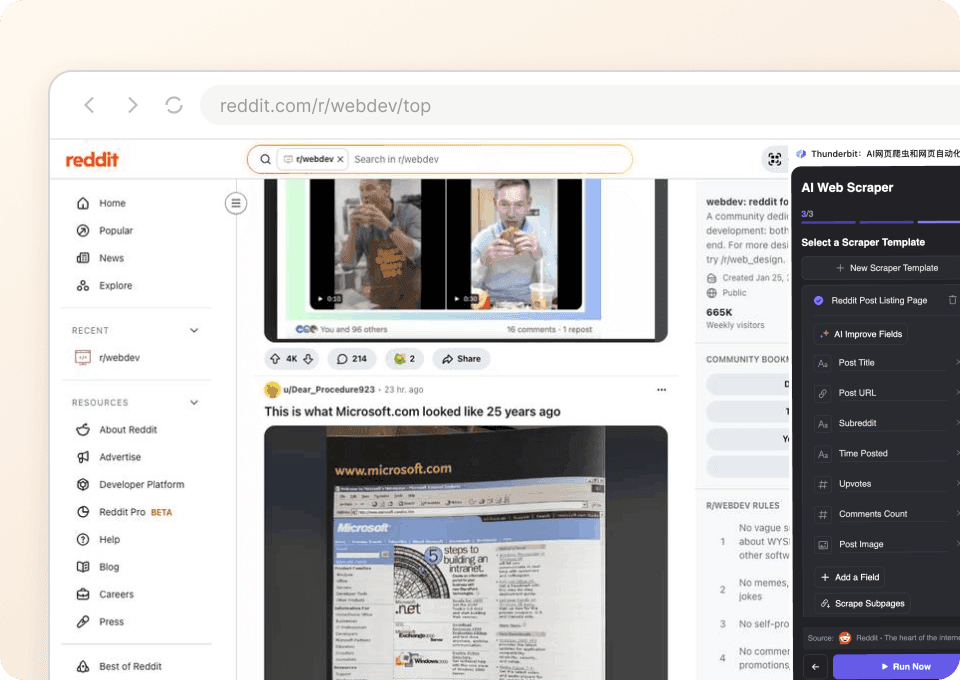
Tự động nhận dữ liệu Sephora sạch và có cấu trúc
Dữ liệu Sephora thường khá lộn xộn, nhưng việc làm sạch nó thì không nhất thiết phải vất vả. Thunderbit sẽ tự động sắp xếp và định dạng dữ liệu ngay trong lúc trích xuất, giúp bạn không phải mất hàng giờ dọn dẹp thủ công. Xuất thẳng sang Google Sheets, Notion hoặc Airtable và bắt đầu phân tích ngay.
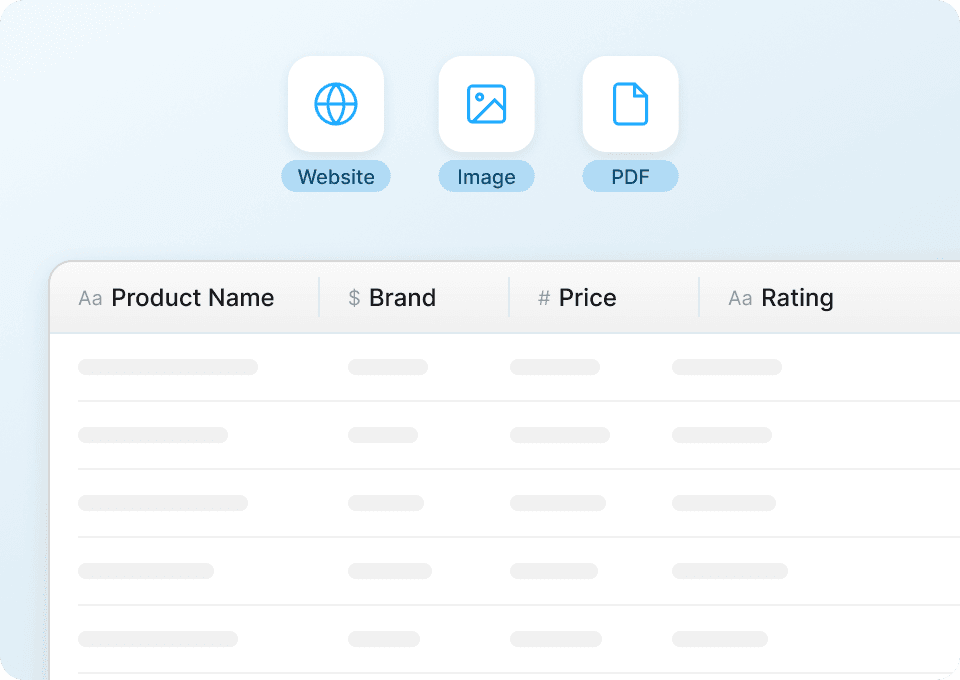
Mở rộng quy mô scrape Sephora dễ dàng
Việc tự tay lấy thông tin sản phẩm từ từng trang Sephora thật sự rất tốn công. Với Thunderbit, bạn có thể scrape hàng trăm trang sản phẩm cùng lúc. Chỉ cần cung cấp cho Thunderbit một danh sách URL Sephora, công cụ sẽ tự động trích xuất dữ liệu như tên sản phẩm, giá và xếp hạng từ từng trang.
抓取 Sephora 商品数据遇到困难?
看看 Thunderbit 与传统抓取方式相比表现如何。
传统爬虫
沿用旧方法Thunderbit
更智能的选择Đừng chỉ nghe chúng tôi nói
Xem người dùng của chúng tôi nói gì về Thunderbit.







Các câu hỏi thường gặp
Liên quan use cases
Khám phá thêm các use case của web scraper Thunderbit.

PlayStation Scraper
Chỉ với vài cú nhấp chuột, bạn có thể lấy dữ liệu game PlayStation như tên game, thể loại và giá đang giảm — không còn phải sao chép thủ công rồi dán lại nữa.
Tìm hiểu thêm ->
Carousell 爬虫
Lấy dữ liệu Carousell như tiêu đề sản phẩm, mô tả và giá cả mà không cần thiết lập phức tạp hay viết code.
Tìm hiểu thêm ->Công cụ lấy giá Amazon
Đưa giá Amazon, xếp hạng và ASIN vào Google Sheets bằng thao tác trỏ và nhấp — không cần thiết lập phức tạp.
Tìm hiểu thêm ->
PubMed Scraper
PubMed Scraper của Thunderbit giúp bạn trích xuất dữ liệu có cấu trúc từ trang kết quả tìm kiếm và trang bài viết trên PubMed bằng AI. Thu thập các nghiên cứu y khoa đang thịnh hành, bằng chứng thử nghiệm lâm sàng, tóm tắt (abstract), tác giả, cơ quan/đơn vị (affiliations), ngày xuất bản và liên kết, rồi xuất sang Excel, Google Sheets, Airtable hoặc Notion.
Tìm hiểu thêm ->
Wikipedia scraper
Lấy dữ liệu infobox, tài liệu tham khảo và nội dung bài viết từ Wikipedia vào một bảng tính sạch sẽ — không cần code, AI sẽ lo phần cấu trúc cho bạn.
Tìm hiểu thêm ->Công cụ thu thập dữ liệu PeopleWhiz
Công cụ thu thập dữ liệu PeopleWhiz của Thunderbit giúp bạn trích xuất dữ liệu từ kết quả tìm kiếm và hồ sơ PeopleWhiz bằng gợi ý trường dữ liệu do AI hỗ trợ. Thu thập tên, thông tin liên hệ, địa điểm và nhiều dữ liệu khác cho nghiên cứu, marketing hoặc tạo lead. Biến dữ liệu PeopleWhiz thành bộ dữ liệu có cấu trúc nhanh chóng và hiệu quả.
Tìm hiểu thêm ->Sẵn sàng tăng tốc trích xuất dữ liệu của bạn chưa?
Tham gia cùng hơn 100.000 chuyên gia đang dùng Thunderbit để tự động hóa quy trình web scraping của họ.
Bản dùng thử miễn phí cung cấp credit không giới hạn cho 8 trang web.