Trình cào tin tức














Dữ liệu tin tức, được thu thập nhanh hơn
Lấy dữ liệu tin tức sạch từ bài viết, danh sách và nguồn tin mà không cần làm thủ công mệt nhọc.
Lấy đầy đủ chi tiết bài viết
Trang danh sách tin tức chỉ cho bạn một đoạn nhử ngắn. Thunderbit sẽ ghé từng trang bài viết đầy đủ và lấy về mọi thứ quan trọng — tiêu đề, tóm tắt, tác giả, ngày đăng, nguồn tin và chuyên mục. Chuyển từ một danh sách liên kết đơn giản thành bộ dữ liệu có cấu trúc, đầy đủ mà không phải làm thủ công tẻ nhạt.
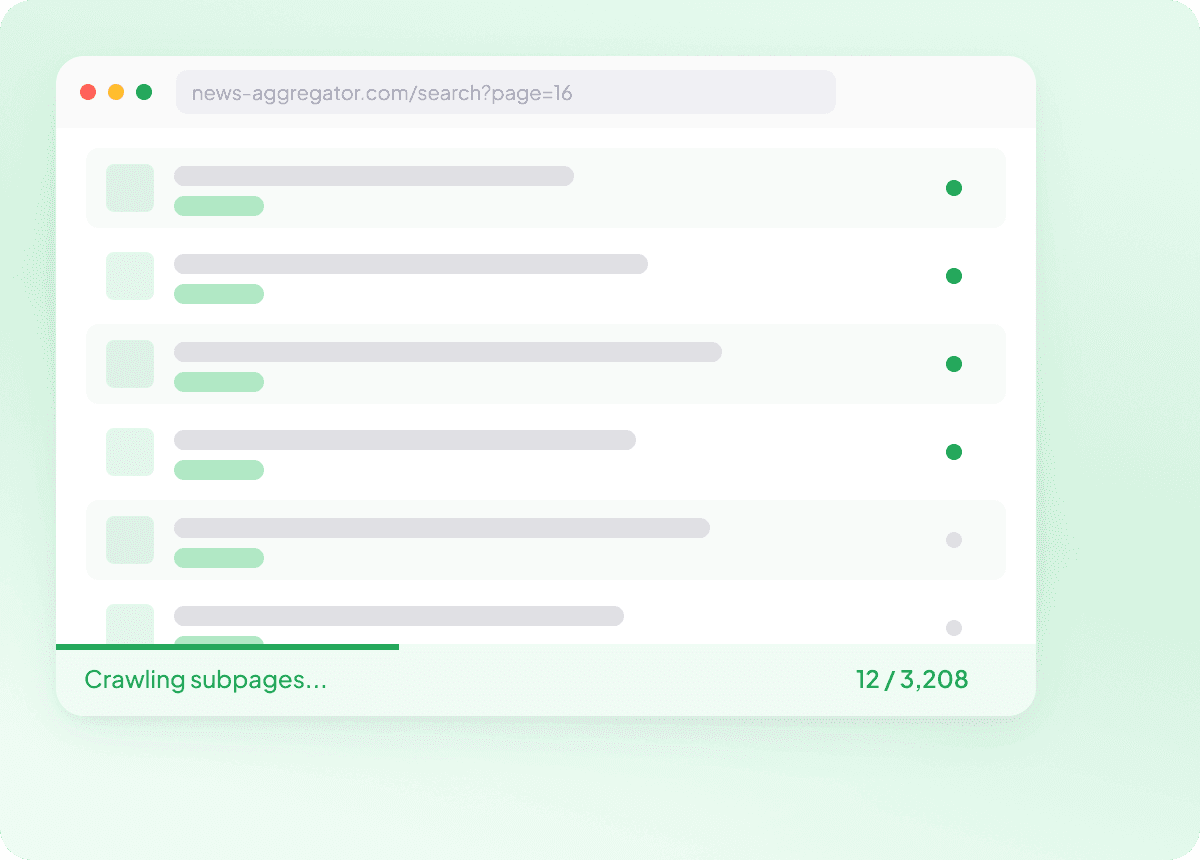
Cào hàng loạt danh sách URL News
Cào từng bài một không phải là quy trình làm việc — đó là một việc vặt. Chỉ cần dán danh sách URL bài viết, Thunderbit sẽ cào hàng trăm trang trong một lần chạy, thu thập mọi trường cần thiết ở từng bài. Việc gom dữ liệu tin tức quy mô lớn chưa bao giờ đơn giản đến thế.

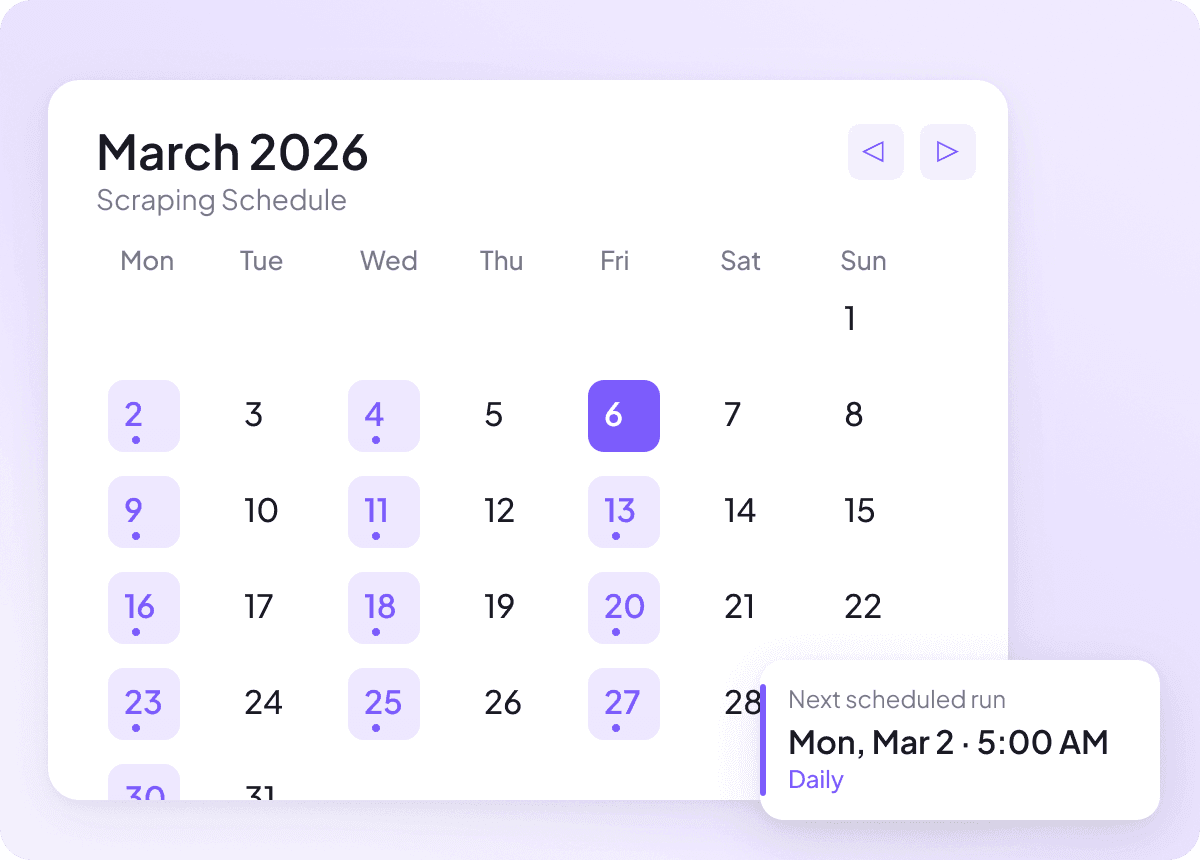
Giữ dữ liệu News luôn mới
Tin tức thay đổi rất nhanh, và dữ liệu của ngày hôm qua sẽ mất giá trị chỉ sau thời gian ngắn. Lên lịch cào và Thunderbit sẽ tự chạy — giữ cho bảng tính của bạn luôn có tiêu đề, tóm tắt, tác giả, ngày đăng, nguồn và chuyên mục mới nhất theo tần suất bạn đặt. Cập nhật định kỳ, không tốn công.
Vì sao Thunderbit khác với các trình cào tin tức truyền thống?
Một cách nhanh hơn để thu thập dữ liệu tin tức lộn xộn mà không bị hỏng liên tục.
Trình cào truyền thống
Cách làm cũThunderbit AI
Cách làm thông minh hơnĐừng chỉ nghe chúng tôi nói
Xem người dùng nói gì về Thunderbit.





Câu hỏi thường gặp
Liên quan trường hợp sử dụng
Khám phá thêm các trường hợp sử dụng của web scraper Thunderbit.

Priceline 爬虫
Chỉ với 2 cú nhấp chuột, Thunderbit AI giúp bạn trích xuất tên khách sạn, giá phòng, xếp hạng và tiện nghi từ Priceline — sau đó xuất ngay dữ liệu sạch, có cấu trúc sang Excel, Google Sheets hoặc Notion.
Tìm hiểu thêm ->Elgiganten Scraper
Chỉ với 2 cú nhấp chuột, bạn có thể trích xuất tên sản phẩm, giá và tình trạng còn hàng từ Elgiganten — rồi xuất thẳng sang Excel, Google Sheets hoặc Notion. AI của Thunderbit sẽ xử lý phần nặng nhọc, để bạn tập trung vào những insight quan trọng.
Tìm hiểu thêm ->
Trình thu thập PubMed
Trình thu thập PubMed của Thunderbit giúp bạn dùng AI để trích xuất dữ liệu có cấu trúc từ trang kết quả tìm kiếm và trang bài viết PubMed. Bạn có thể thu thập nghiên cứu y khoa đang nổi bật, bằng chứng thử nghiệm lâm sàng, tóm tắt, tác giả, đơn vị công tác, ngày xuất bản và liên kết, sau đó xuất sang Excel, Google Sheets, Airtable hoặc Notion.
Tìm hiểu thêm ->
Wikipedia 爬虫
只需 2 次点击,就能将 Wikipedia 的信息框数据、参考资料和文章正文整理成干净、结构化的表格——可立即导出到 Excel、Google Sheets 或 Notion,无需编写代码。
Tìm hiểu thêm ->Trình trích xuất Substack
Trích xuất số lượng người đăng ký Substack, tiêu đề bài viết và mô tả ấn phẩm chỉ với 2 cú nhấp chuột — rồi xuất sang Excel, Google Sheets hoặc Notion. Không cần viết code; AI của Thunderbit sẽ tự lo phần cấu trúc dữ liệu cho bạn.
Tìm hiểu thêm ->
HKTVmall Scraper
Chỉ với 2 cú nhấp, bạn có thể trích xuất tên sản phẩm, giá, đánh giá và nhiều dữ liệu khác từ các trang HKTVmall — không cần biết lập trình. Xuất trực tiếp sang Excel, Google Sheets hoặc Notion để biến dữ liệu HKTVmall thành những insight có thể hành động.
Tìm hiểu thêm ->Sẵn sàng tăng tốc việc trích xuất dữ liệu của bạn?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Bản dùng thử miễn phí cung cấp credit không giới hạn cho 8 trang web.



