Web đang phát triển với tốc độ thật sự khó mà hình dung hết. Mỗi ngày, hàng tỷ trang mới, sản phẩm mới, đánh giá mới và bộ dữ liệu mới được xuất bản — tiếp thêm nhiên liệu cho đủ kiểu nhu cầu, từ nghiên cứu thị trường, huấn luyện AI cho đến chuyến mua sắm Amazon tiếp theo của bạn. Là người đã làm việc nhiều năm trong mảng SaaS và tự động hóa, tôi đã tận mắt thấy dữ liệu phù hợp có thể quyết định sự thành bại của một thương vụ hay chiến lược kinh doanh như thế nào. Nhưng vấn đề là: việc thu thập, cập nhật và biến khối dữ liệu web khổng lồ này thành thông tin hữu ích đang ngày càng khó hơn, chứ không hề dễ hơn. Các web scraper truyền thống đang chật vật để theo kịp tốc độ thay đổi, còn doanh nghiệp thì cần một cách thông minh và nhanh hơn để biến Internet thành insight có thể hành động. Đó chính là lúc cloud crawler xuất hiện — một công cụ đang âm thầm thay đổi cách tổ chức khai thác và tận dụng dữ liệu web ở quy mô lớn.
Vậy cloud crawler thực chất là gì? Nó khác gì so với những web scraper mà bạn có thể đã biết? Và vì sao từ đội sales đến vận hành đều đang đặt cược vào công nghệ này để đi trước trong một thế giới vận hành bằng dữ liệu? Hãy cùng đi sâu vào khái niệm này, gỡ rối các thuật ngữ đang bị “thổi phồng”, và xem cloud crawler (đặc biệt là giải pháp của Thunderbit) đang làm thay đổi cuộc chơi cho doanh nghiệp hiện đại ra sao.
Cloud Crawler là gì? Bước tiến tiếp theo trong việc khám phá dữ liệu
Hãy hiểu đơn giản thế này: một cloud crawler không chỉ là web scraper được đặt trên cloud. Nó giống một “cỗ máy khám phá dữ liệu” hơn — một hệ thống thông minh chạy trên nền tảng đám mây, được thiết kế để tự động tìm, trích xuất và phân tích những tập dữ liệu khổng lồ trên Internet. Trong khi web scraper truyền thống chỉ lấy thông tin từ một vài trang (thường là từng trang một, và thường chạy trên một thiết bị duy nhất), cloud crawler hoạt động ở một cấp độ hoàn toàn khác. Nó chạy trong các trung tâm dữ liệu mạnh mẽ trên cloud, thu thập dữ liệu đồng thời từ hàng nghìn, thậm chí hàng triệu trang, và có thể xử lý mọi thứ từ văn bản, hình ảnh cho đến PDF — bất kể website mục tiêu phức tạp hay đồ sộ đến đâu.
Hãy hình dung thế này: nếu web scraper giống như một thủ thư đơn lẻ đang chép từng đoạn trong một cuốn sách, thì cloud crawler là một đội siêu máy tính đang quét toàn bộ thư viện cùng lúc, vừa gắn nhãn, vừa sắp xếp, vừa phân tích nội dung trong quá trình đó. Kết quả là gì? Doanh nghiệp nhận được dữ liệu phong phú hơn, mới hơn và dễ chuyển thành hành động hơn — mà không bị giới hạn bởi phần cứng tại chỗ hay công việc thủ công (, ).
Cloud Crawler vs. Web Scraper truyền thống: Khác biệt thực sự nằm ở đâu?
Nếu bạn từng dùng web scraper, bạn sẽ biết cách hoạt động cơ bản: trỏ nó vào một trang, xác định dữ liệu cần lấy, rồi để nó kéo dữ liệu về. Nhưng khi web ngày càng lớn và phức tạp, cách làm cũ bắt đầu lộ rõ giới hạn. Dưới đây là cách cloud crawler và web scraper truyền thống so sánh với nhau:
| Tính năng/Khía cạnh | Web Scraper truyền thống | Cloud Crawler |
|---|---|---|
| Triển khai | Chạy trên thiết bị hoặc máy chủ cục bộ của bạn | Chạy trên cloud (trung tâm dữ liệu từ xa) |
| Quy mô | Bị giới hạn bởi sức mạnh máy tính của bạn | Xử lý song song cực lớn — hàng nghìn trang cùng lúc |
| Tốc độ | Chậm hơn, đặc biệt với các tác vụ lớn | Xử lý hàng loạt tốc độ cao |
| Bảo trì | Cần cập nhật thường xuyên, dễ hỏng khi website thay đổi | Dựa trên cloud, tự cập nhật, ít dễ lỗi hơn |
| Loại dữ liệu | Thường là văn bản, đôi khi có hình ảnh | Văn bản, hình ảnh, PDF, bố cục phức tạp |
| Truy cập | Gắn với thiết bị/mạng của bạn | Truy cập được từ bất cứ đâu, trên bất kỳ thiết bị nào |
| Lập lịch | Thủ công hoặc tự động hóa cơ bản | Lập lịch nâng cao, tác vụ lặp lại |
| Phù hợp nhất | Dự án nhỏ, website đơn giản | Nhu cầu dữ liệu lớn, thường xuyên hoặc phức tạp |
Cloud crawler được xây dựng cho web hiện đại — nơi dữ liệu ở khắp mọi nơi, và tốc độ cùng khả năng mở rộng là điều không thể thương lượng (, ).
Cloud crawler giúp tăng tốc hiệu quả thu thập dữ liệu như thế nào
Đây là phần thú vị nhất. Cloud crawler tận dụng sức mạnh điện toán đám mây để xử lý hàng nghìn trang web song song. Điều đó có nghĩa là bạn có thể scrape toàn bộ catalog ecommerce, theo dõi giá đối thủ trên hàng chục website, hoặc tổng hợp danh sách bất động sản từ mọi cổng thông tin lớn — tất cả chỉ trong một phần nhỏ thời gian so với cách dùng scraper truyền thống.
Vì sao điều này quan trọng? Bởi trong các lĩnh vực như ecommerce, tài chính và bất động sản, độ mới của dữ liệu là yếu tố sống còn. Giá cả, tồn kho và xu hướng thị trường có thể thay đổi từng phút. Chờ hàng giờ, thậm chí hàng ngày, để một scraper chạy cục bộ hoàn tất là điều không thể chấp nhận. Cloud crawler không bị giới hạn bởi RAM của laptop hay mạng Wi‑Fi văn phòng — chúng tự mở rộng theo nhu cầu, giúp bạn xử lý những tác vụ khổng lồ mà không tốn sức (, ).
Các ngành hưởng lợi nhiều nhất từ hiệu quả này gồm:
- Ecommerce: Theo dõi giá, tổng hợp catalog sản phẩm, phân tích đánh giá
- Bất động sản: Gom dữ liệu tin đăng, theo dõi xu hướng thị trường, so sánh bất động sản
- Tài chính: Phân tích tin tức và cảm xúc thị trường, theo dõi cổ phiếu/crypto, giám sát quy định
- Sales & Marketing: Tìm lead, nghiên cứu đối thủ, phát hiện xu hướng
Và thật lòng mà nói, đó mới chỉ là bề nổi. Nếu bạn cần dữ liệu web ở quy mô lớn, cloud crawler chính là trợ thủ bạn đang tìm.
Giải pháp Cloud Crawler của Thunderbit: Nhanh, linh hoạt và mạnh mẽ
Cho phép tôi đội chiếc mũ Thunderbit một chút nhé (thật ra tôi gần như chẳng bao giờ tháo nó ra). Chế độ cloud scraping của là câu trả lời của chúng tôi cho bài toán dữ liệu hiện đại — một cloud crawler được xây dựng cho người dùng doanh nghiệp muốn kết quả, không muốn phiền toái.
Điều làm cloud crawler của Thunderbit nổi bật:
- Scrape hàng loạt tốc độ cao: Có thể scrape tới 50 trang cùng lúc, với cloud server đặt tại Mỹ, EU và châu Á để phủ sóng toàn cầu. Không còn cảnh chờ máy tính của bạn “gồng” qua cả danh sách dài.
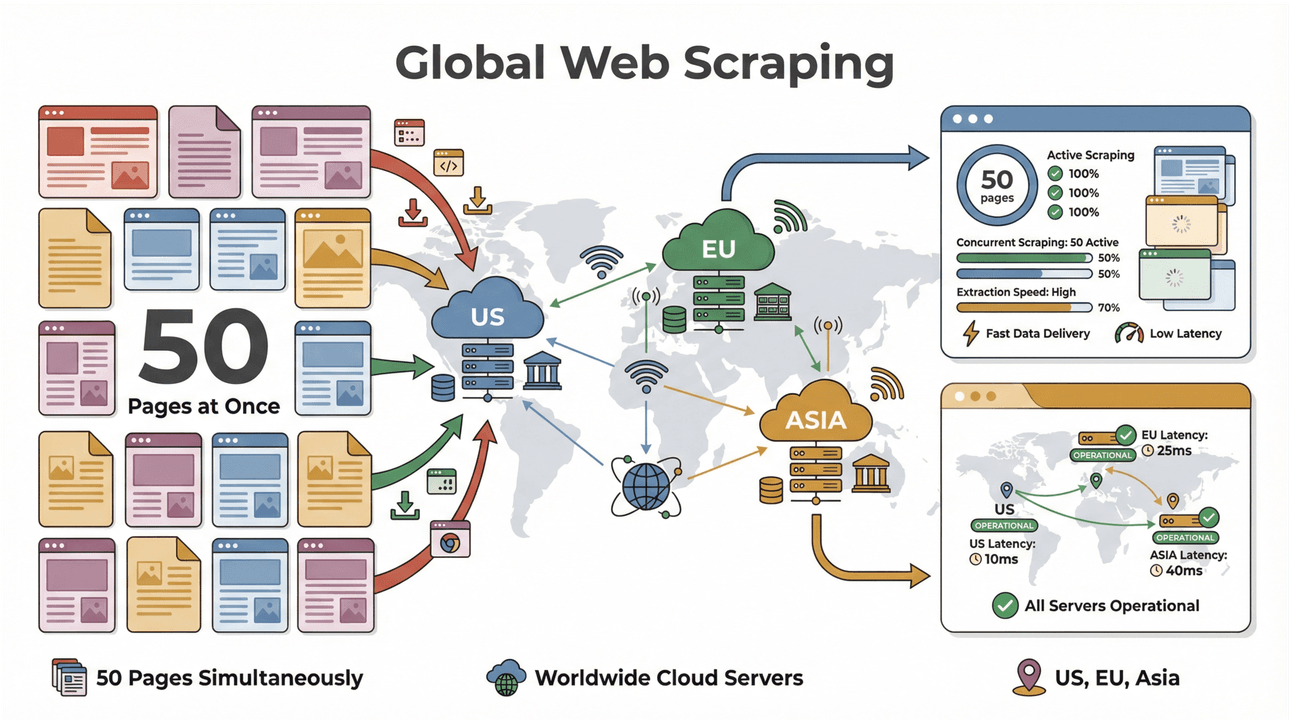
- Hỗ trợ trang phức tạp: AI của Thunderbit có thể xử lý từ các website ecommerce động cho đến PDF khó nhằn và cả trích xuất hình ảnh. Hễ có trên web thì Thunderbit có khả năng scrape được ().
- Thu thập subpage: Cần làm giàu dữ liệu bằng chi tiết từ các trang con như thông số sản phẩm hoặc tiểu sử tác giả? AI của Thunderbit có thể ghé từng subpage rồi gộp kết quả vào bộ dữ liệu chính ().
- Cấu trúc dữ liệu thông minh: Dùng “AI Suggest Fields” để Thunderbit đọc website và đề xuất các cột phù hợp nhất — không cần code hay tự dựng template.
- Xuất dữ liệu ở mọi nơi: Gửi dữ liệu thẳng sang Excel, Google Sheets, Airtable hoặc Notion. Hoặc tải về dưới dạng CSV/JSON — tùy workflow của bạn ().
- Không cần bảo trì: AI của Thunderbit tự thích ứng khi website thay đổi, nên bạn không phải liên tục sửa scraper bị hỏng ().
Và đúng vậy, bạn có thể thử tất cả những thứ này với — nên bạn không cần chỉ tin lời tôi nói.
Triển khai Cloud Crawler: Cloud hay local — đâu là lựa chọn phù hợp?
Một trong những lợi thế lớn nhất của cloud crawler là tính linh hoạt khi triển khai. Với crawler truyền thống (local), bạn bị ràng buộc vào một thiết bị, một mạng cụ thể, và thường là hàng loạt rắc rối thiết lập. Nếu máy tính ngủ hoặc mất internet, quá trình scrape sẽ dừng lại. Muốn mở rộng quy mô thì phải mua thêm phần cứng hoặc chạy nhiều script cùng lúc.
Cloud crawler đảo ngược hoàn toàn cách làm đó:
- Không cần phần cứng đặc biệt: Toàn bộ phần nặng đã được xử lý trên cloud. Bạn có thể khởi chạy những tác vụ scrape lớn từ Chromebook, Mac, hoặc thậm chí điện thoại.
- Truy cập mọi lúc, mọi nơi: Đi công tác? Làm việc từ xa? Không thành vấn đề — cloud crawler luôn sẵn sàng.
- Mở rộng dễ dàng: Cần scrape 10.000 trang thay vì 100? Chỉ cần tăng quy mô tác vụ — không cần IT can thiệp.
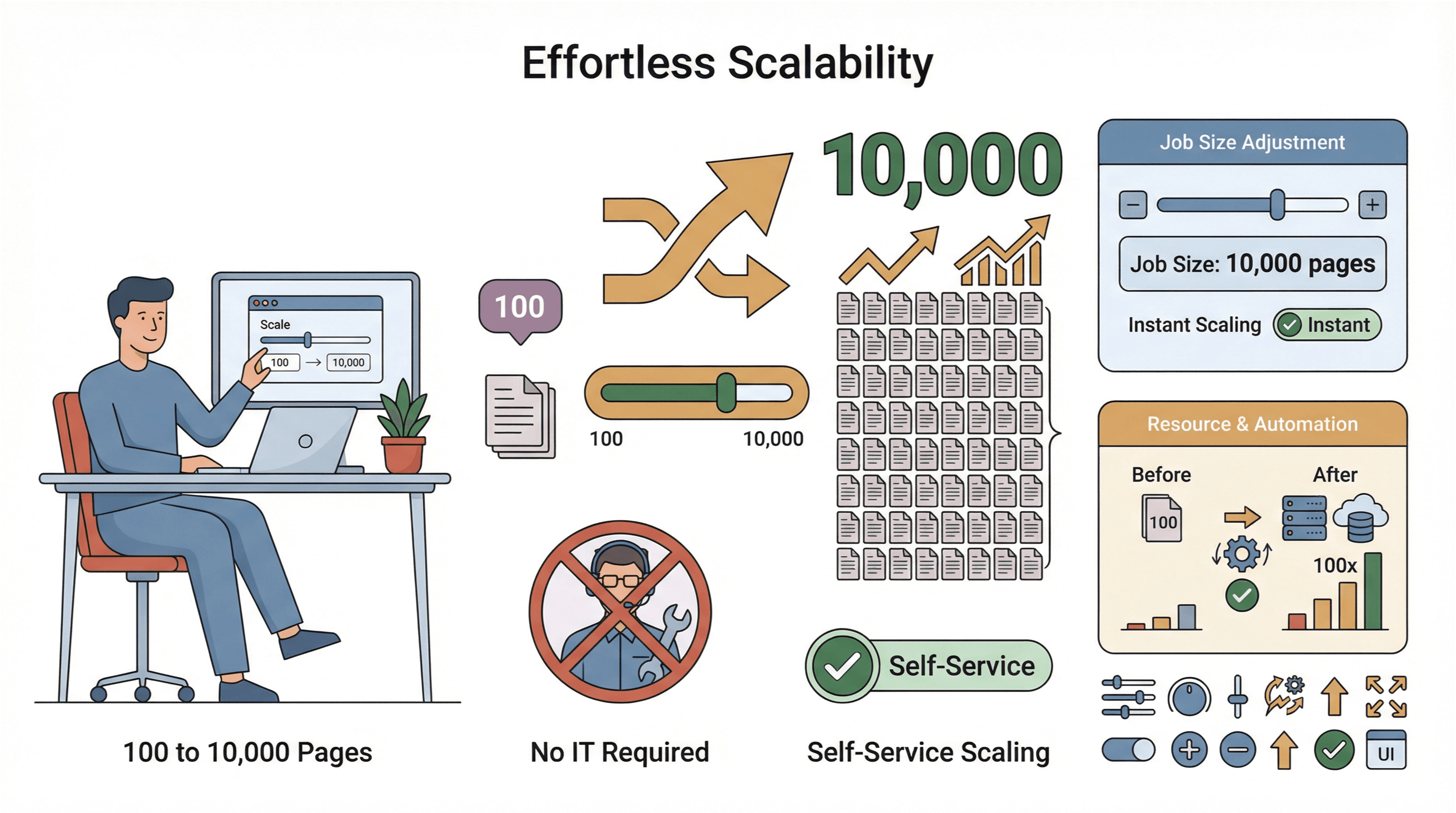
- Thu thập dữ liệu toàn cầu: Với cloud server đặt ở nhiều khu vực, bạn có thể truy cập nội dung bị giới hạn theo vùng địa lý và quản lý tuân thủ dễ hơn ().
Tất nhiên, bảo mật và tuân thủ luôn là mối quan tâm hàng đầu. Những cloud crawler tốt nhất (bao gồm Thunderbit) đều dùng kết nối mã hóa, tôn trọng điều khoản website và có các tính năng giúp bạn xử lý dữ liệu nhạy cảm một cách có trách nhiệm.
Tác động thực tế: Cloud crawler đang thay đổi chiến lược dữ liệu như thế nào
Hãy nói chuyện thực tế. Vì sao doanh nghiệp chuyển sang cloud crawler? Bởi họ đang thấy tác động rõ ràng, đo lường được:
- Phân tích thị trường theo thời gian thực: Nhà bán lẻ dùng cloud crawler để theo dõi giá và tồn kho của đối thủ ngay khi thay đổi, từ đó định giá linh hoạt và phản ứng nhanh hơn với biến động thị trường ().
- Dự đoán xu hướng tiêu dùng: Thương hiệu gom đánh giá, bài đăng mạng xã hội và thảo luận trên diễn đàn để phát hiện xu hướng mới và điều chỉnh chiến dịch kịp thời.
- Sales & tạo lead: Đội sales xây dựng danh sách lead cập nhật từ thư mục, trang sự kiện, thậm chí cả PDF — rồi đưa contact mới, đủ tiêu chuẩn vào CRM ().
- Vận hành & tuân thủ: Các công ty tài chính dùng cloud crawler để theo dõi cập nhật quy định, tin tức và hồ sơ nộp ở nhiều khu vực pháp lý — giảm rủi ro và đi trước thay đổi.
Điểm chung là gì? Cloud crawler giúp các team di chuyển nhanh hơn, ra quyết định thông minh hơn và vượt lên trước đối thủ vẫn còn mắc kẹt trong “làn chậm”.
Những tính năng quan trọng cần có ở một cloud crawler
Không phải cloud crawler nào cũng giống nhau. Nếu bạn đang cân nhắc lựa chọn, đây là những tính năng đáng chú ý nhất (và cũng là nơi Thunderbit tỏa sáng):
- Khả năng mở rộng: Có xử lý được hàng nghìn trang cùng lúc không? Có chậm đi khi job lớn hơn không?
- Dễ sử dụng: Giao diện có thân thiện với người không chuyên kỹ thuật không? Có thể thiết lập scrape chỉ với vài cú nhấp không?
- Hỗ trợ nhiều loại dữ liệu: Văn bản, hình ảnh, PDF, subpage — có xử lý được tất cả không?
- Tích hợp: Có xuất dữ liệu sang các công cụ bạn hay dùng như Excel, Sheets, Notion, Airtable không?
- Lập lịch: Có thể tạo tác vụ định kỳ để dữ liệu luôn mới không?
- Hỗ trợ AI: Có gợi ý trường dữ liệu thông minh, làm giàu dữ liệu và tự thích ứng khi website thay đổi không?
- Bảo mật & tuân thủ: Dữ liệu và thông tin đăng nhập có được bảo vệ không? Công cụ có giúp bạn tuân thủ luật riêng tư không?
Thunderbit đáp ứng đầy đủ các tiêu chí này, nên là lựa chọn hàng đầu cho những đội nhóm muốn sức mạnh mà không phải chịu sự phức tạp.
Bắt đầu thế nào: Cách dùng cloud crawler cho doanh nghiệp của bạn
Sẵn sàng bắt đầu chưa? Đây là cách một người dùng doanh nghiệp điển hình có thể bắt đầu với cloud crawler như Thunderbit:
- Cài đặt : Thiết lập nhanh, không cần IT.
- Chọn mục tiêu: Mở website, danh sách hoặc tài liệu bạn muốn scrape.
- Nhấp “AI Suggest Fields”: Để AI của Thunderbit quét trang và đề xuất các cột cần trích xuất.
- Tùy chỉnh nếu cần: Thêm, xóa hoặc đổi tên các trường cho phù hợp nhu cầu.
- Chọn chế độ cloud scraping: Với tác vụ lớn hoặc website phức tạp, chuyển sang cloud mode để đạt tốc độ tối đa.
- Khởi chạy tác vụ: Thunderbit sẽ xử lý tối đa 50 trang cùng lúc trên cloud.
- Kiểm tra và xuất dữ liệu: Xem trước kết quả, rồi xuất sang Excel, Google Sheets, Notion hoặc Airtable.
- Lập lịch tác vụ định kỳ: Với nhu cầu liên tục, hãy thiết lập scrape theo lịch — dữ liệu sẽ tự động được cập nhật ().
Mẹo nhỏ: Hãy bắt đầu với job nhỏ để làm quen, rồi tăng dần khi bạn đã tự tin hơn. Và đừng ngại dùng tài liệu hoặc đội ngũ hỗ trợ của Thunderbit — họ luôn sẵn sàng giúp bạn.
Tương lai của thu thập dữ liệu: Cloud crawler sẽ đi về đâu tiếp theo?
Cuộc cách mạng cloud crawler mới chỉ bắt đầu. Đây là những điều tôi đang theo dõi trong vài năm tới:
- Trích xuất AI thông minh hơn: Cloud crawler ngày càng hiểu tốt hơn ngữ cảnh, mối quan hệ và cả cảm xúc — khiến dữ liệu thu được giá trị hơn ().
- Hỗ trợ nhiều loại dữ liệu mới: Kỳ vọng khả năng xử lý video, âm thanh và nội dung tương tác tốt hơn — không chỉ dừng ở văn bản tĩnh và hình ảnh.
- Tự động hóa sâu hơn: Từ tự lên lịch đến cảnh báo thời gian thực, cloud crawler sẽ ngày càng ít cần can thiệp hơn cho người dùng doanh nghiệp.
- Tuân thủ tốt hơn: Khi luật riêng tư tiếp tục thay đổi, cloud crawler sẽ tích hợp thêm nhiều công cụ giúp đội nhóm đi đúng hướng quy định.
- Tích hợp với BI và AI tools: Luồng dữ liệu trực tiếp từ cloud crawler sang nền tảng phân tích, dashboard và machine learning.
Nói ngắn gọn, cloud crawler đang trên đường trở thành xương sống của chiến lược kinh doanh số — cung cấp nhiên liệu cho mọi thứ, từ ra mắt sản phẩm đến dự báo bằng AI ().
Kết luận: Vì sao cloud crawler là công cụ thiết yếu cho doanh nghiệp hiện đại
Tóm lại: web đang bùng nổ dữ liệu, và cách thu thập kiểu cũ không còn theo kịp nữa. Cloud crawler là bước tiến tiếp theo — mang đến tốc độ, quy mô và trí thông minh mà scraper truyền thống không thể sánh được. Những công cụ như giúp bất kỳ đội nhóm nào, dù có kỹ thuật hay không, cũng có thể khai thác toàn bộ tiềm năng của dữ liệu web — từ đó ra quyết định tốt hơn, phản ứng nhanh hơn và tạo lợi thế cạnh tranh rõ rệt.
Nếu bạn đã sẵn sàng rời xa kiểu scrape thủ công và các quy trình dữ liệu chậm chạp, thì bây giờ là lúc khám phá cloud crawler có thể làm gì cho doanh nghiệp của bạn. Hãy thử chế độ cloud scraping của Thunderbit và xem việc khám phá dữ liệu hiện đại dễ dàng — mà vẫn mạnh mẽ — đến mức nào. Và nếu muốn tìm hiểu sâu hơn, hãy xem để đọc thêm hướng dẫn, mẹo thực hành và các ví dụ thực tế.
Câu hỏi thường gặp
1. Cloud crawler là gì, hiểu đơn giản thì sao?
Cloud crawler là một công cụ dựa trên cloud, có thể tự động tìm kiếm, trích xuất và phân tích lượng dữ liệu lớn từ web. Khác với scraper truyền thống chạy trên thiết bị cục bộ, cloud crawler hoạt động trong các trung tâm dữ liệu mạnh mẽ, nhờ đó đạt quy mô và tốc độ rất lớn.
2. Cloud crawler khác gì so với web scraper thông thường?
Cloud crawler chạy trên cloud, xử lý hàng nghìn trang cùng lúc, hỗ trợ các loại dữ liệu phức tạp như hình ảnh và PDF, và không cần bảo trì hay phần cứng cục bộ. Web scraper truyền thống bị giới hạn bởi sức mạnh thiết bị của bạn và phù hợp hơn cho những tác vụ nhỏ, đơn giản.
3. Lợi ích chính của cloud crawler là gì?
Cloud crawler cho phép thu thập dữ liệu tốc độ cao, quy mô lớn, hỗ trợ website phức tạp, truy cập dễ dàng từ mọi nơi và có các tính năng nâng cao như lập lịch cùng trích xuất bằng AI. Đây là lựa chọn lý tưởng cho doanh nghiệp cần dữ liệu mới, hữu ích và nhanh.
4. Cloud crawler của Thunderbit hoạt động như thế nào đối với người dùng doanh nghiệp?
Cloud crawler của Thunderbit cho phép bạn thiết lập tác vụ scrape chỉ với vài cú nhấp — không cần viết code. Bạn có thể trích xuất dữ liệu từ website, PDF và hình ảnh, làm giàu dữ liệu bằng AI, rồi xuất thẳng sang Excel, Google Sheets, Notion hoặc Airtable. Công cụ này được thiết kế cho người không chuyên kỹ thuật nhưng vẫn muốn có kết quả, không muốn phức tạp.
5. Cloud crawling có an toàn và tuân thủ luật bảo vệ dữ liệu không?
Có. Những cloud crawler hàng đầu như Thunderbit sử dụng kết nối mã hóa và các thực hành tốt nhất về bảo mật dữ liệu. Tuy nhiên, bạn luôn nên chỉ scrape dữ liệu công khai và tôn trọng điều khoản sử dụng cũng như quy định về quyền riêng tư của website.
Sẵn sàng xem cloud crawler có thể làm được gì? và bắt đầu khám phá thế giới thu thập dữ liệu quy mô lớn trên cloud ngay hôm nay.
Tìm hiểu thêm