

Mạng web đang ngập tràn dữ liệu giá trị — dù bạn làm sales, ecommerce hay nghiên cứu thị trường, thu thập dữ liệu web chính là “vũ khí bí mật” để tạo khách hàng tiềm năng, theo dõi giá cả và phân tích đối thủ. Nhưng có một điểm đáng chú ý: khi ngày càng nhiều doanh nghiệp tận dụng web scraping, các website cũng phản ứng mạnh tay hơn bao giờ hết. Sự thay đổi này là có thật: một phân tích của ppc.land năm 2024 cho thấy hơn một phần ba trong top 1.000 website đã chặn riêng crawler của OpenAI — và bộ công cụ phòng vệ rộng hơn gồm chặn IP, CAPTCHA và nhận diện dấu vân tay trình duyệt giờ đã trở thành chuyện rất bình thường, không còn là ngoại lệ.
Nếu bạn từng nhìn script Python chạy trơn tru suốt 20 phút — rồi bất ngờ đâm vào một bức tường lỗi 403 — bạn sẽ hiểu cảm giác bực bội đó là thật.
Tôi đã làm việc nhiều năm trong SaaS và tự động hóa, và tôi đã tận mắt thấy các dự án scraping chuyển từ “ồ, dễ thế à” sang “sao mình bị chặn khắp nơi vậy?” chỉ trong chớp mắt. Vậy nên, hãy đi thẳng vào thực tế: tôi sẽ hướng dẫn bạn cách thu thập dữ liệu web bằng Python không bị chặn, chia sẻ các kỹ thuật và đoạn code hữu ích, đồng thời chỉ ra khi nào nên cân nhắc các lựa chọn dùng AI như Thunderbit. Dù bạn là cao thủ Python hay chỉ đang “cào dữ liệu” thôi (xin phép chơi chữ), bạn cũng sẽ mang về một bộ công cụ để trích xuất dữ liệu ổn định, ít bị chặn.
Thu thập dữ liệu web bằng Python mà không bị chặn là gì?
Về bản chất, thu thập dữ liệu web mà không bị chặn nghĩa là lấy dữ liệu từ website theo cách không kích hoạt hệ thống phòng vệ chống bot của họ. Trong thế giới Python, điều này không chỉ đơn giản là viết một vòng lặp requests.get() — mà còn là hòa lẫn vào môi trường, giả lập người dùng thật và luôn đi trước một bước so với hệ thống phát hiện.
Vì sao lại là Python? Python là ngôn ngữ phổ biến nhất cho web scraping — nhờ cú pháp đơn giản, hệ sinh thái khổng lồ (như requests, BeautifulSoup, Scrapy, Selenium) và sự linh hoạt cho mọi thứ, từ script nhanh gọn đến crawler phân tán. Nhưng độ phổ biến cũng có cái giá của nó: nhiều hệ thống chống bot hiện nay đã được tinh chỉnh để nhận ra các mẫu scraping viết bằng Python.
Vì vậy, nếu muốn scraping ổn định, bạn cần đi xa hơn mức cơ bản. Nghĩa là phải hiểu các website phát hiện bot như thế nào, và làm sao để “qua mặt” chúng — mà vẫn không vượt qua ranh giới đạo đức hay pháp lý.
Vì sao tránh bị chặn lại quan trọng với các dự án web scraping Python
Bị chặn không chỉ là một trục trặc kỹ thuật — nó có thể làm sập cả quy trình kinh doanh. Cùng tách ra xem:
| Trường hợp sử dụng | Tác động khi bị chặn |
|---|---|
| Tạo khách hàng tiềm năng | Danh sách khách hàng không đầy đủ hoặc lỗi thời, mất doanh số |
| Theo dõi giá | Bỏ lỡ thay đổi giá của đối thủ, ra quyết định giá kém chính xác |
| Tổng hợp nội dung | Thiếu tin tức, đánh giá hoặc dữ liệu nghiên cứu |
| Tình báo thị trường | Mù thông tin trong việc theo dõi đối thủ hoặc ngành |
| Danh sách bất động sản | Dữ liệu nhà đất sai lệch hoặc cũ, bỏ lỡ cơ hội |
Khi một scraper bị chặn, bạn không chỉ mất dữ liệu — bạn còn đang lãng phí tài nguyên, đối mặt với rủi ro tuân thủ, và có thể ra quyết định kinh doanh sai vì thông tin không đầy đủ. Trong bối cảnh 79% doanh nghiệp dựa vào web scraping để tạo khách hàng tiềm năng, độ tin cậy là tất cả.
Website phát hiện và chặn web scraper Python như thế nào
Các website giờ đã rất “khôn” trong việc nhận ra bot. Đây là những cơ chế chống scraping phổ biến nhất mà bạn sẽ gặp (Medium, Bright Data):
- Chặn IP: Quá nhiều yêu cầu từ cùng một IP? Chặn.
- Kiểm tra User-Agent và header: Các request thiếu header hoặc dùng header quá chung chung (như
python-requests/2.25.1mặc định của Python) sẽ rất dễ lộ. - Giới hạn tần suất: Quá nhiều request trong thời gian ngắn sẽ bị bóp tốc độ hoặc cấm truy cập.
- CAPTCHA: Những bài “chứng minh bạn là con người” mà bot thì khó lòng giải được.
- Phân tích hành vi: Website theo dõi các mẫu hành vi máy móc — như bấm cùng một nút đúng theo một khoảng thời gian cố định.
- Honeypot: Những liên kết hoặc trường nhập ẩn chỉ bot mới chạm vào.
- Nhận diện dấu vân tay trình duyệt: Thu thập chi tiết về trình duyệt và thiết bị của bạn để phát hiện công cụ tự động hóa.
- Theo dõi cookie và phiên đăng nhập: Bot không xử lý cookie hoặc session đúng cách sẽ bị đánh dấu.
Hãy tưởng tượng như kiểm tra an ninh sân bay: nếu bạn nhìn, hành động và di chuyển giống mọi người khác, bạn sẽ qua rất nhanh. Nhưng nếu bạn xuất hiện với áo trench coat và kính râm, đừng ngạc nhiên khi bị hỏi thêm vài câu.
Kỹ thuật Python thiết yếu để thu thập dữ liệu web mà không bị chặn
Giờ vào phần hay nhất: làm sao để thực sự tránh bị chặn khi scraping bằng Python. Đây là những chiến lược cốt lõi mà mọi scraper nên biết:

Xoay vòng proxy và địa chỉ IP
Vì sao quan trọng: Nếu toàn bộ request của bạn đều đến từ cùng một IP, bạn sẽ là mục tiêu quá dễ cho lệnh chặn IP. Proxy xoay vòng giúp phân bổ request qua nhiều IP khác nhau, khiến việc chặn bạn khó hơn nhiều.
Cách làm trong Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...nhiều proxy hơn
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# xử lý response
Bạn có thể dùng dịch vụ proxy trả phí (như residential proxy hoặc rotating proxy) để tăng độ ổn định (ScrapingBee).
Thiết lập User-Agent và header tùy chỉnh
Vì sao quan trọng: Header mặc định của Python gần như hét lên rằng “tôi là bot”. Hãy mô phỏng trình duyệt thật bằng cách đặt user-agent và các header khác.
Mã mẫu:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Hãy xoay vòng user-agent để tăng độ “ẩn mình” (ZenRows).
Ngẫu nhiên hóa thời gian và mẫu gửi request
Vì sao quan trọng: Bot thì nhanh và dễ đoán; con người thì chậm và thất thường. Hãy thêm độ trễ và thay đổi cách bạn điều hướng.
Mẹo Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Chờ 2–7 giây
Nếu dùng Selenium, bạn cũng có thể ngẫu nhiên hóa đường bấm chuột và kiểu cuộn trang.
Quản lý cookie và session
Vì sao quan trọng: Nhiều website yêu cầu cookie hoặc token phiên để truy cập nội dung. Bot bỏ qua phần này rất dễ bị chặn.
Cách quản lý trong Python:
import requests
session = requests.Session()
response = session.get(url)
# session sẽ tự xử lý cookie
Với luồng phức tạp hơn, hãy dùng Selenium để lấy và tái sử dụng cookie.
Mô phỏng hành vi con người bằng trình duyệt headless
Vì sao quan trọng: Một số website dùng JavaScript, chuyển động chuột hoặc cuộn trang như tín hiệu của người dùng thật. Trình duyệt headless như Selenium hoặc Playwright có thể mô phỏng các hành động này.
Ví dụ với Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Điều này giúp bạn vượt qua phân tích hành vi và nội dung động (ScrapingBee).
Chiến lược nâng cao: vượt qua CAPTCHA và honeypot trong Python
CAPTCHA được thiết kế để chặn bot ngay từ đầu. Dù một số thư viện Python có thể giải các CAPTCHA đơn giản, đa số scraper nghiêm túc sẽ dựa vào dịch vụ bên thứ ba (như 2Captcha hoặc Anti-Captcha) để giải hộ với một khoản phí (Medium).
Ví dụ tích hợp:
# Mã giả để dùng API của 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Chờ có lời giải rồi gửi lại cùng request của bạn
Honeypot là các trường hoặc liên kết ẩn mà chỉ bot mới tương tác. Hãy tránh bấm hoặc gửi bất cứ thứ gì không nhìn thấy được trong trình duyệt thật (ZenRows).
Thiết kế header request vững chắc bằng thư viện Python
Ngoài user-agent, bạn có thể xoay vòng và ngẫu nhiên hóa các header khác (như Referer, Accept, Origin, v.v.) để trông giống người dùng thật hơn.
Với Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Thêm header khác
}
}
Với Selenium: Dùng profile trình duyệt hoặc extension để đặt header, hoặc chèn chúng qua JavaScript.
Hãy giữ danh sách header luôn được cập nhật — sao chép các request thật từ trình duyệt bằng DevTools để lấy cảm hứng.
Khi scraping Python truyền thống không còn đủ: sự trỗi dậy của công nghệ chống bot
Thực tế là thế này: web scraping càng phổ biến thì công nghệ chống bot cũng càng nâng cấp. Các website lớn giờ không chỉ chặn bot lộ liễu, mà còn chặn cả headless browser tinh vi và proxy xoay vòng. Phát hiện bằng AI, ngưỡng request động và nhận diện dấu vân tay trình duyệt đang khiến ngay cả các script Python nâng cao cũng ngày càng khó tránh bị phát hiện (Medium).
Đôi khi, dù code của bạn khéo đến đâu, bạn vẫn sẽ gặp bức tường. Và đó là lúc nên cân nhắc một hướng khác.
Thunderbit: lựa chọn AI Web Scraper thay thế cho scraping bằng Python
Khi Python chạm tới giới hạn, Thunderbit bước vào như một AI Web Scraper không cần code, được thiết kế cho người dùng doanh nghiệp chứ không chỉ lập trình viên. Thay vì phải vật lộn với proxy, header và CAPTCHA, tác nhân AI của Thunderbit sẽ đọc website, gợi ý những trường tốt nhất để trích xuất, và xử lý mọi thứ từ điều hướng trang con đến xuất dữ liệu.
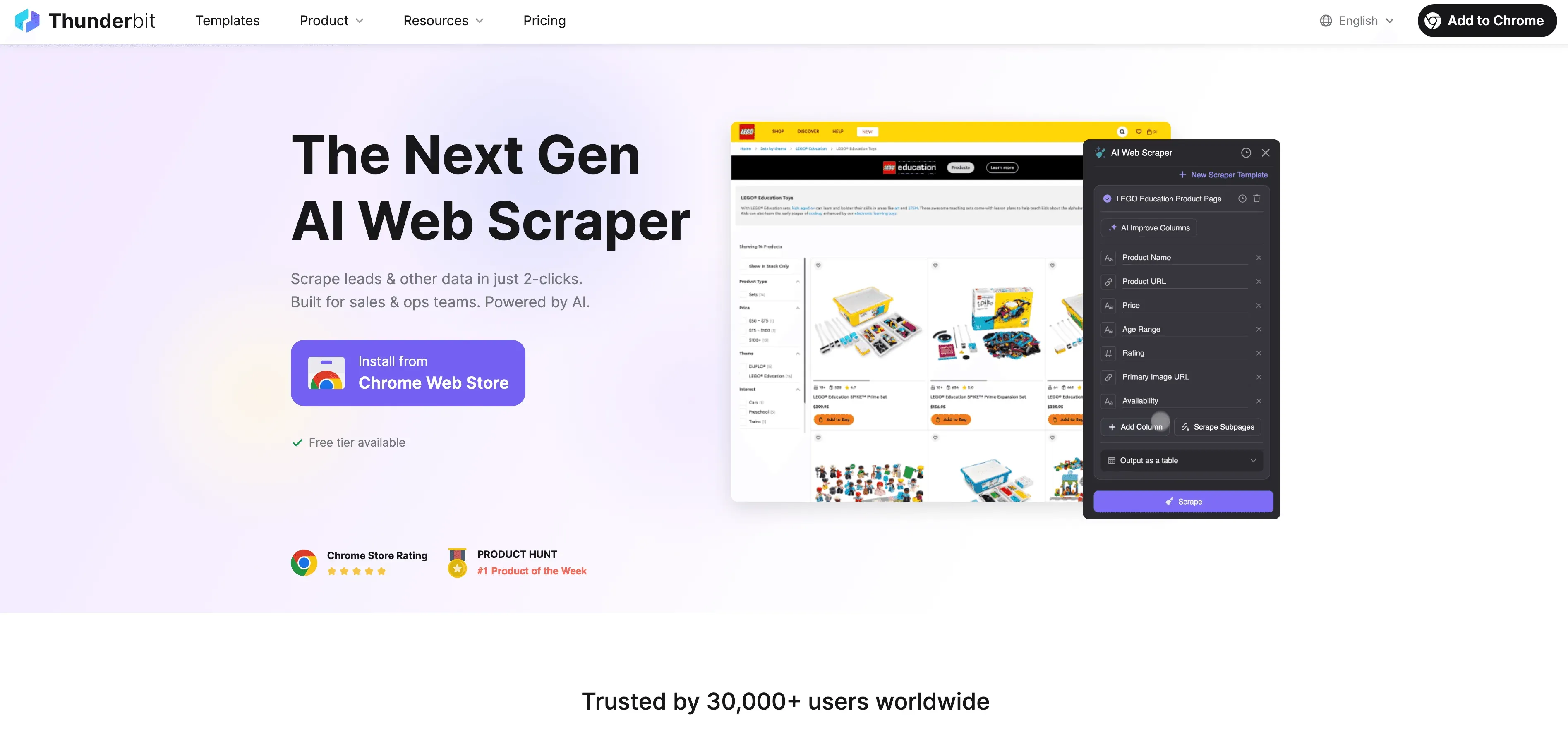
Điều gì làm Thunderbit khác biệt?
- Gợi ý trường bằng AI: Nhấn “AI Suggest Fields” và Thunderbit sẽ quét trang, đề xuất cột, thậm chí tạo luôn hướng dẫn trích xuất.
- Thu thập trang con: Thunderbit có thể ghé từng trang con (như chi tiết sản phẩm hoặc hồ sơ LinkedIn) và tự động làm giàu bảng dữ liệu của bạn.
- Thu thập trên cloud hoặc trong trình duyệt: Chọn tùy chọn nhanh nhất — cloud cho website công khai, trình duyệt cho trang có đăng nhập.
- Thu thập theo lịch: Đặt lịch rồi để đó — Thunderbit có thể chạy theo lịch, giúp dữ liệu của bạn luôn mới.
- Mẫu có sẵn tức thì: Với các website phổ biến (Amazon, Zillow, Shopify, v.v.), Thunderbit có template 1 click — không cần cấu hình.
- Xuất dữ liệu miễn phí: Xuất sang Excel, Google Sheets, Airtable hoặc Notion — không tính phí thêm.
Thunderbit đang được tin dùng bởi hơn 100.000 người dùng trên toàn thế giới, và bạn không cần viết dù chỉ một dòng code.
Thu thập dữ liệu từ bất kỳ website nào bằng AI Get Started Free
Thunderbit giúp người dùng tránh bị chặn và tự động hóa trích xuất dữ liệu như thế nào
AI của Thunderbit không chỉ giả lập hành vi con người — nó còn thích ứng theo từng website trong thời gian thực, giảm nguy cơ bị chặn. Cụ thể là:
- AI thích ứng với thay đổi giao diện: Ít phải làm lại khi website cập nhật thiết kế — bạn không cần quay lại tinh chỉnh selector mỗi tuần.
- Xử lý trang con và phân trang: Thunderbit tự theo liên kết và danh sách nhiều trang cho bạn, giống như một người thật đang click từng bước.
- Thu thập trên cloud theo lô: Chạy job từ cloud của Thunderbit thay vì máy tính của bạn, với kích thước lô tùy theo gói (xem trang giá để biết giới hạn hiện tại).
- Ít code phải bảo trì hơn: Bạn không phải thức đêm đi sửa selector gãy khi website đổi giao diện; AI sẽ đọc lại trang.
Nếu muốn tìm hiểu sâu hơn, hãy xem Cách thu thập dữ liệu từ bất kỳ website nào bằng AI.
So sánh scraping bằng Python và Thunderbit: nên chọn gì?
Đặt chúng cạnh nhau xem sao:
| Tính năng | Scraping bằng Python | Thunderbit |
|---|---|---|
| Thời gian thiết lập | Trung bình đến cao (script, proxy, v.v.) | Thấp (2 cú click, AI làm phần còn lại) |
| Kỹ năng kỹ thuật | Cần biết lập trình | Không cần code |
| Độ tin cậy | Thay đổi (dễ hỏng) | Cao (AI thích ứng khi có thay đổi) |
| Rủi ro bị chặn | Trung bình đến cao | Thấp (AI mô phỏng người dùng, tự thích ứng) |
| Khả năng mở rộng | Cần code tùy chỉnh/cấu hình cloud | Có sẵn cloud và thu thập theo lô |
| Bảo trì | Thường xuyên (website đổi, bị chặn) | Tối thiểu (AI tự điều chỉnh) |
| Tùy chọn xuất dữ liệu | Thủ công (CSV, DB) | Xuất trực tiếp sang Sheets, Notion, Airtable, CSV |
| Chi phí | Miễn phí (nhưng tốn thời gian) | Có gói miễn phí, gói trả phí cho quy mô lớn |
Khi nào nên dùng Python:
- Bạn cần toàn quyền kiểm soát, logic tùy chỉnh hoặc tích hợp với các workflow Python khác.
- Bạn đang scraping những website có cơ chế chống bot tối thiểu.
Khi nào nên dùng Thunderbit:
- Bạn muốn tốc độ, độ tin cậy và không phải cài đặt gì.
- Bạn đang scraping những website phức tạp hoặc thay đổi thường xuyên.
- Bạn không muốn đụng tới proxy, CAPTCHA hay code.
Dùng thử miễn phí Thunderbit AI Web Scraper
Hướng dẫn từng bước: thiết lập web scraping mà không bị chặn trong Python
Hãy đi qua một ví dụ thực tế: thu thập dữ liệu sản phẩm từ một website mẫu, đồng thời áp dụng các thực hành tốt nhất để tránh bị chặn.
1. Cài các thư viện cần thiết
pip install requests beautifulsoup4 fake-useragent
2. Chuẩn bị script
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Thay bằng URL của bạn
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Trích xuất dữ liệu ở đây
print(soup.title.text)
else:
print(f"Bị chặn hoặc lỗi ở {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Độ trễ ngẫu nhiên
3. Thêm xoay vòng proxy (tùy chọn)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Nhiều proxy hơn
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...phần code còn lại
4. Xử lý cookie và session
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...phần code còn lại
5. Mẹo xử lý sự cố
- Nếu bạn thấy quá nhiều lỗi 403/429, hãy giảm tốc độ request hoặc thử proxy mới.
- Nếu gặp CAPTCHA, hãy cân nhắc dùng Selenium hoặc dịch vụ giải CAPTCHA.
- Luôn kiểm tra
robots.txtvà điều khoản dịch vụ của website.
Kết luận & những điểm chính cần nhớ
Thu thập dữ liệu web bằng Python rất mạnh — nhưng bị chặn luôn là rủi ro thường trực khi công nghệ chống bot ngày càng tiến bộ. Cách tốt nhất để tránh bị chặn là gì? Kết hợp các thực hành kỹ thuật tốt nhất (xoay vòng proxy, header thông minh, độ trễ ngẫu nhiên, xử lý session và trình duyệt headless) với sự tôn trọng đầy đủ đối với quy định và đạo đức của website.
Nhưng đôi khi, ngay cả các mẹo Python tốt nhất cũng chưa đủ. Đó là lúc các công cụ AI như Thunderbit phát huy tác dụng — không cần code, được thiết kế để xử lý thay đổi giao diện và phân trang vốn làm hỏng các script cứng nhắc, và hướng đến người dùng doanh nghiệp không muốn dành cả buổi tối để “trông” một job Selenium.
Muốn thấy việc scraping có thể dễ đến mức nào không? Tải tiện ích mở rộng Chrome của Thunderbit và tự thử ngay — hoặc xem thêm blog của chúng tôi để có thêm mẹo và hướng dẫn về scraping.
Thu thập dữ liệu mà không bị chặn
Câu hỏi thường gặp
1. Vì sao các website chặn web scraper Python?
Website chặn scraper để bảo vệ dữ liệu, ngăn máy chủ bị quá tải và chặn các bot tự động lạm dụng dịch vụ. Script Python rất dễ bị nhận ra nếu dùng header mặc định, không xử lý cookie, hoặc gửi quá nhiều request trong thời gian quá ngắn.
2. Cách hiệu quả nhất để tránh bị chặn khi scraping bằng Python là gì?
Hãy dùng proxy xoay vòng, đặt user-agent và header hợp lý, ngẫu nhiên hóa thời gian gửi request, quản lý cookie/session, và mô phỏng hành vi con người bằng công cụ như Selenium hoặc Playwright.
3. Thunderbit giúp tránh bị chặn như thế nào so với script Python?
Thunderbit dùng AI để thích ứng với bố cục website, mô phỏng cách duyệt web của con người và tự động xử lý trang con cùng phân trang. Nó giảm rủi ro bị chặn bằng cách hòa lẫn vào môi trường và cập nhật cách tiếp cận theo thời gian thực — không cần code hay proxy.
4. Khi nào nên dùng Python scraping thay vì công cụ AI như Thunderbit?
Hãy dùng Python khi bạn cần logic tùy chỉnh, tích hợp với code Python khác, hoặc đang scraping những website đơn giản. Hãy dùng Thunderbit để scraping nhanh, đáng tin cậy và có khả năng mở rộng — đặc biệt khi website phức tạp, thay đổi thường xuyên, hoặc chặn script rất gắt.
5. Web scraping có hợp pháp không?
Web scraping là hợp pháp với dữ liệu công khai, nhưng bạn phải tôn trọng điều khoản dịch vụ, chính sách quyền riêng tư và các luật liên quan của từng website. Đừng bao giờ thu thập dữ liệu nhạy cảm hoặc riêng tư, và hãy luôn scraping một cách có đạo đức, có trách nhiệm.
Sẵn sàng scraping thông minh hơn, thay vì vất vả hơn chưa? Hãy thử Thunderbit và bỏ lại mọi rào chặn phía sau.
Tìm hiểu thêm:
- Hướng dẫn từng bước về thu thập dữ liệu Google News bằng Python
- Xây dựng công cụ theo dõi giá Best Buy bằng Python
- 14 cách thu thập dữ liệu web mà không bị chặn
- 10 mẹo hay nhất để không bị chặn khi thu thập dữ liệu web
Dùng thử AI Web Scraper Get Started Free




