

Có một cảm giác rất “vượt thời gian” khi mở terminal, gõ một lệnh duy nhất rồi nhìn dữ liệu web thô tràn ra, như thể bạn vừa mở bung Ma Trận. Với lập trình viên và người dùng kỹ thuật nâng cao, cURL chính là cây đũa thần đó — một công cụ dòng lệnh tưởng chừng đơn giản nhưng âm thầm chạy trên hàng tỷ thiết bị, từ máy chủ đám mây đến cả tủ lạnh thông minh. Và ngay cả trong năm 2026, giữa vô số công cụ thu thập dữ liệu không cần code và các công cụ AI hào nhoáng, web-scraping-with-curl vẫn là lựa chọn quen thuộc cho bất kỳ ai cần tốc độ, khả năng kiểm soát và tự động hóa bằng script.
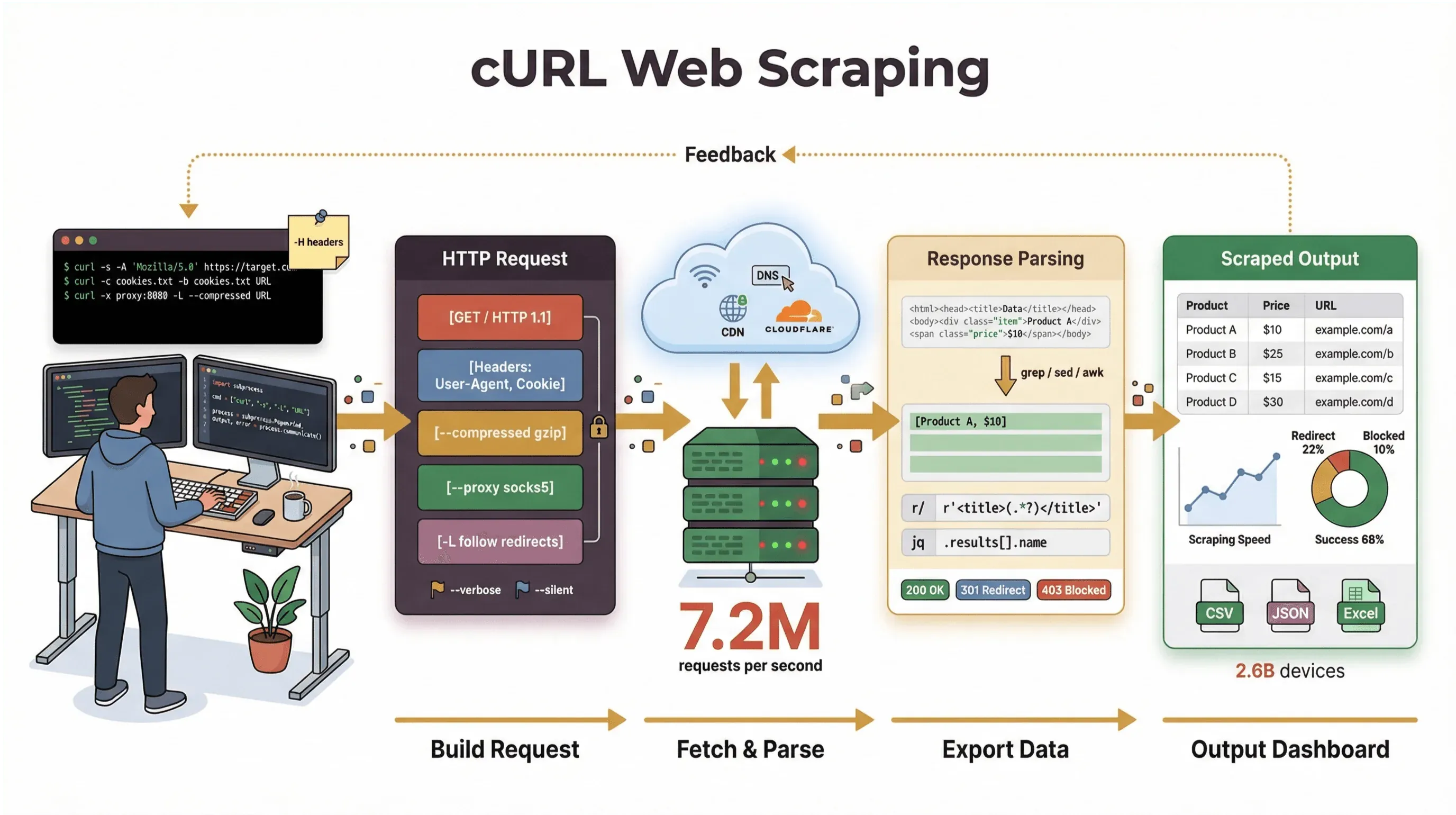 Tôi đã dành nhiều năm xây dựng công cụ tự động hóa và hỗ trợ các đội nhóm xử lý dữ liệu web, và đến giờ vẫn thường chọn cURL khi cần lấy một trang, gỡ lỗi API, hoặc phác thảo nhanh một quy trình thu thập dữ liệu. Trong hướng dẫn này, tôi sẽ đưa bạn đi qua một bài hướng dẫn cURL web scraping, bao gồm cả kiến thức nền tảng lẫn mẹo nâng cao — kèm ví dụ lệnh thực tế, mẹo hữu ích, và cái nhìn rõ ràng về chỗ cURL tỏa sáng (và chỗ nó bế tắc). Nếu bạn là người dùng thiên về kinh doanh và không muốn đụng đến dòng lệnh, tôi cũng sẽ chỉ cho bạn cách Thunderbit — công cụ thu thập dữ liệu web dùng AI của chúng tôi — có thể đưa bạn từ “tôi cần dữ liệu này” đến “đây là bảng tính của tôi” chỉ trong hai cú nhấp, không cần viết code.
Tôi đã dành nhiều năm xây dựng công cụ tự động hóa và hỗ trợ các đội nhóm xử lý dữ liệu web, và đến giờ vẫn thường chọn cURL khi cần lấy một trang, gỡ lỗi API, hoặc phác thảo nhanh một quy trình thu thập dữ liệu. Trong hướng dẫn này, tôi sẽ đưa bạn đi qua một bài hướng dẫn cURL web scraping, bao gồm cả kiến thức nền tảng lẫn mẹo nâng cao — kèm ví dụ lệnh thực tế, mẹo hữu ích, và cái nhìn rõ ràng về chỗ cURL tỏa sáng (và chỗ nó bế tắc). Nếu bạn là người dùng thiên về kinh doanh và không muốn đụng đến dòng lệnh, tôi cũng sẽ chỉ cho bạn cách Thunderbit — công cụ thu thập dữ liệu web dùng AI của chúng tôi — có thể đưa bạn từ “tôi cần dữ liệu này” đến “đây là bảng tính của tôi” chỉ trong hai cú nhấp, không cần viết code.
Hãy cùng tìm hiểu vì sao cURL vẫn còn phù hợp cho việc thu thập dữ liệu web trong năm 2026, cách dùng nó hiệu quả, và khi nào đã đến lúc chuyển sang một công cụ mạnh hơn nữa.
cURL là gì? Nền tảng của web-scraping-with-curl
Về cốt lõi, cURL là một công cụ dòng lệnh và thư viện dùng để truyền dữ liệu qua URL. Nó đã tồn tại gần 30 năm rồi (đúng vậy, thật đấy), và xuất hiện ở khắp nơi — được nhúng trong hệ điều hành, vận hành các script, và âm thầm xử lý việc truyền dữ liệu trong hơn hai mươi tỷ lượt cài đặt. Nếu từng chạy một lệnh nhanh để lấy một trang web, thử API, hoặc tải xuống một tệp, rất có thể bạn đã dùng cURL.
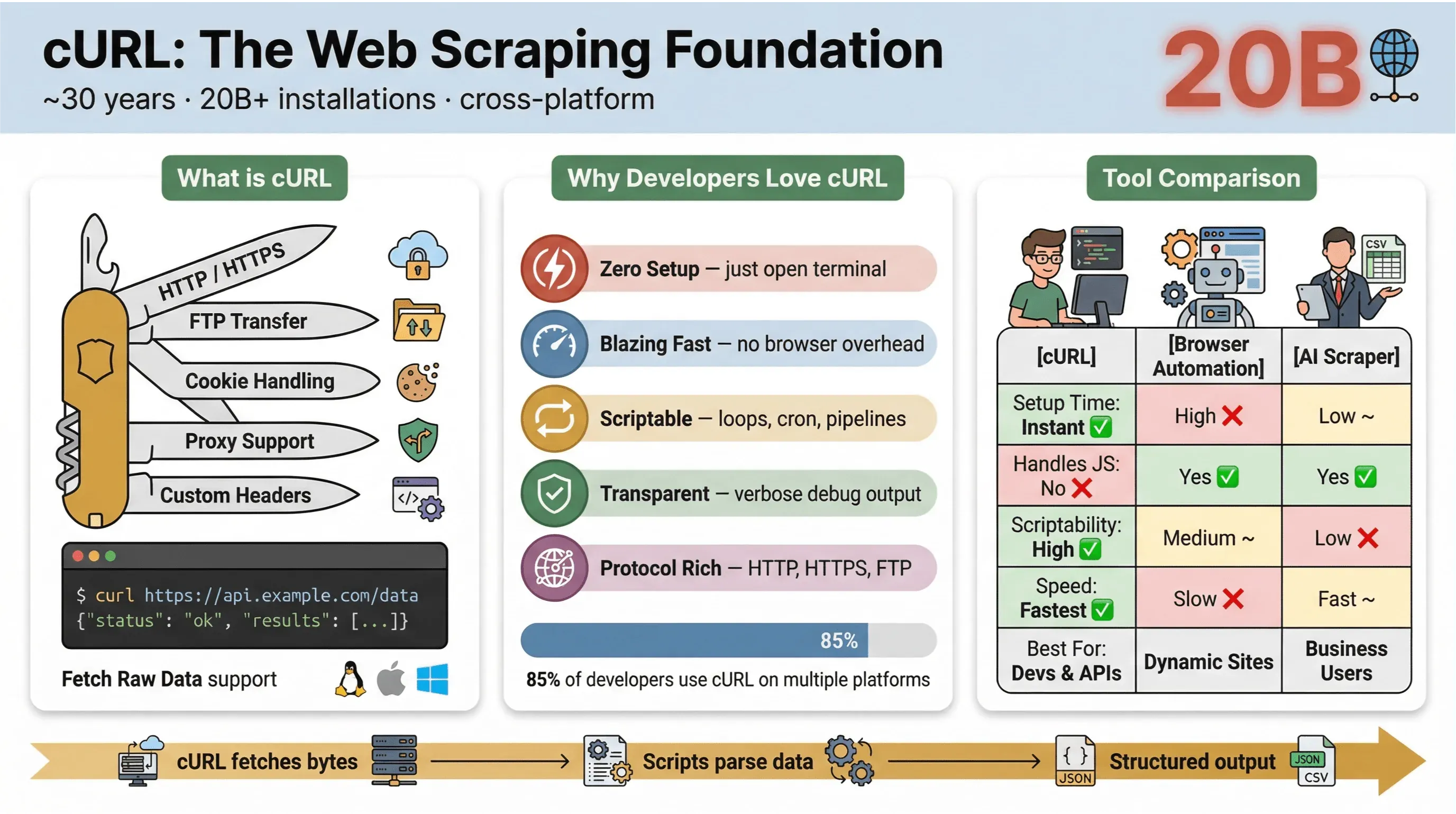 Đây là lý do khiến cURL rất được ưa chuộng cho việc thu thập dữ liệu web:
Đây là lý do khiến cURL rất được ưa chuộng cho việc thu thập dữ liệu web:
- Nhẹ và đa nền tảng: Chạy trên Linux, macOS, Windows, thậm chí cả thiết bị nhúng.
- Hỗ trợ nhiều giao thức: Xử lý HTTP, HTTPS, FTP, v.v.
- Dùng được trong script: Rất hợp cho tự động hóa, cron job và các đoạn mã kết nối.
- Không cần tương tác người dùng: Được thiết kế cho môi trường không tương tác — rất phù hợp cho xử lý hàng loạt và các pipeline.
Nhưng cần nói rõ: nhiệm vụ chính của cURL là lấy dữ liệu thô — HTML, JSON, hình ảnh, bất cứ thứ gì. Nó không phân tích, không render, cũng không cấu trúc dữ liệu đó giúp bạn. Hãy xem cURL như “chặng đầu tiên” của quy trình thu thập dữ liệu web: nó đưa bạn đến được byte dữ liệu, nhưng bạn sẽ cần công cụ khác (như script Python, grep/sed/awk, hoặc một công cụ thu thập dữ liệu web bằng AI) để biến dữ liệu đó thành thông tin có cấu trúc.
Nếu muốn xem tài liệu chính thức, hãy tham khảo hướng dẫn scripting HTTP của cURL.
Vì sao nên dùng cURL để thu thập dữ liệu web? (hướng dẫn cURL web scraping)
Vậy tại sao các lập trình viên và người dùng kỹ thuật vẫn quay lại với cURL để thu thập dữ liệu web, dù ngoài kia đã có rất nhiều công cụ mới? Đây là những điểm khiến cURL nổi bật:
- Thiết lập tối giản: Không cần cài đặt thêm, không phụ thuộc gì — chỉ việc mở terminal và chạy.
- Tốc độ: Lấy dữ liệu ngay lập tức, không phải chờ trình duyệt tải trang.
- Dễ tự động hóa bằng script: Dễ dàng lặp qua nhiều URL, tự động hóa request và nối chuỗi lệnh.
- Hỗ trợ giao thức và tính năng: Xử lý cookie, proxy, chuyển hướng, header tùy chỉnh, v.v.
- Minh bạch: Xem chính xác điều gì đang xảy ra với đầu ra verbose/debug.
Trong khảo sát người dùng cURL năm 2025, 85,7% người tham gia cho biết họ dùng công cụ dòng lệnh cURL, và 96,2% nói rằng họ dùng nó trên Linux — vẫn là nền tảng hàng đầu cho cURL với khoảng cách rất lớn.
--- cURL vẫn là con dao đa năng kiểu Swiss Army knife cho các request HTTP, lấy dữ liệu nhanh và xử lý sự cố.
Dưới đây là bảng so sánh nhanh giữa cURL và các phương pháp thu thập dữ liệu khác:
| Tính năng | cURL | Tự động hóa trình duyệt (ví dụ: Selenium) | Công cụ thu thập dữ liệu web bằng AI (ví dụ: Thunderbit) |
|---|---|---|---|
| Thời gian thiết lập | Ngay lập tức | Cao | Thấp |
| Dễ tự động hóa bằng script | Cao | Trung bình | Thấp (không cần code) |
| Xử lý JavaScript | Không | Có | Có (Thunderbit: qua trình duyệt) |
| Hỗ trợ cookie/session | Thủ công | Tự động | Tự động |
| Cấu trúc hóa dữ liệu | Thủ công (phân tích sau) | Thủ công (phân tích sau) | Dựa trên AI/template |
| Phù hợp nhất cho | Lập trình viên, lấy dữ liệu nhanh | Trang phức tạp, động | Người dùng kinh doanh, xuất dữ liệu có cấu trúc |
Tóm lại: cURL không có đối thủ khi cần lấy dữ liệu nhanh và có thể tự động hóa bằng script — nhất là với trang tĩnh, API, hoặc khi bạn muốn tự động hóa các quy trình đơn giản. Nhưng ngay khi bạn cần phân tích HTML phức tạp, xử lý JavaScript, hoặc xuất dữ liệu có cấu trúc, bạn sẽ cần một công cụ chuyên dụng hơn.
Bắt đầu: Ví dụ lệnh cURL cơ bản để thu thập dữ liệu web
Giờ thì thực hành nhé. Sau đây là cách dùng cURL cho các tác vụ thu thập dữ liệu web cơ bản, từng bước một.
Lấy HTML thô bằng cURL
Trường hợp đơn giản nhất: lấy HTML của một trang web.
curl https://books.toscrape.com/
Lệnh này lấy trang chủ của Books to Scrape, một trang demo công khai cho việc thu thập dữ liệu web. Bạn sẽ thấy đầu ra HTML thô trong terminal — hãy để ý các thẻ như <title> hoặc những đoạn như “In stock.”
Lưu đầu ra ra tệp
Muốn lưu HTML đó để phân tích sau? Dùng cờ -o:
curl -o page.html https://books.toscrape.com/
Bây giờ bạn sẽ có một tệp page.html chứa toàn bộ nội dung HTML. Rất phù hợp để phân tích tiếp hoặc dùng công cụ khác xử lý.
Gửi yêu cầu POST bằng cURL
Cần gửi form hoặc tương tác với API? Dùng cờ -d cho yêu cầu POST. Đây là ví dụ dùng httpbin, một trang được thiết kế để kiểm thử HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Bạn sẽ nhận về phản hồi JSON lặp lại dữ liệu đã gửi — rất hữu ích để kiểm thử và phác thảo nhanh.
Kiểm tra header và gỡ lỗi
Đôi khi bạn muốn xem các response header hoặc gỡ lỗi request:
-
Chỉ header (HEAD request):
curl -I https://books.toscrape.com/ -
Bao gồm header cùng nội dung:
curl -i https://httpbin.org/get -
Đầu ra verbose/debug:
curl -v https://books.toscrape.com/
Những cờ này giúp bạn hiểu điều gì đang diễn ra phía dưới — cực kỳ cần thiết khi xử lý sự cố.
Dưới đây là bảng tham khảo nhanh cho các lệnh này:
| Tác vụ | Ví dụ lệnh | Ghi chú |
|---|---|---|
| Lấy HTML | curl URL | In HTML ra terminal |
| Lưu vào tệp | curl -o file.html URL | Ghi đầu ra vào tệp |
| Kiểm tra header | curl -I URL hoặc curl -i URL | -I chỉ lấy HEAD, -i gồm cả header và body |
| Gửi dữ liệu form | curl -d "a=1&b=2" URL | Gửi dữ liệu mã hóa theo form |
| Gỡ lỗi request/response | curl -v URL | Hiển thị thông tin request/response chi tiết |
Để xem thêm ví dụ, hãy đọc tài liệu scripting chính thức của cURL.
Nâng cấp: Thu thập dữ liệu web nâng cao với cURL (web-scraping-with-curl)
Khi đã quen với các thao tác cơ bản, cURL mở ra cả một thế giới tính năng nâng cao cho những tác vụ thu thập dữ liệu phức tạp hơn.
Xử lý cookie và phiên làm việc
Nhiều trang web cần cookie để duy trì phiên đăng nhập hoặc theo dõi người dùng. Với cURL, bạn có thể lưu và tái sử dụng cookie giữa các request:
# Lưu cookie sau khi đăng nhập
curl -c cookies.txt https://example.com/login
# Dùng cookie cho các request tiếp theo
curl -b cookies.txt https://example.com/account
Cách này cho phép bạn mô phỏng phiên trình duyệt và truy cập các trang phía sau lớp đăng nhập (miễn là không có thử thách JavaScript).
Giả lập User-Agent và header tùy chỉnh
Một số website trả về nội dung khác nhau dựa trên User-Agent hoặc header của bạn. Mặc định, cURL nhận diện mình là “curl/VERSION”, điều này có thể gây chặn hoặc dẫn đến nội dung khác. Để mô phỏng trình duyệt:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Bạn cũng có thể đặt header tùy chỉnh, ví dụ ngôn ngữ ưu tiên:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Cách này giúp bạn nhận được đúng nội dung mà một trình duyệt thật sẽ thấy.
Dùng proxy cho việc thu thập dữ liệu web
Cần chuyển hướng request qua proxy (để kiểm thử theo khu vực hoặc tránh bị chặn IP)? Dùng cờ -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Chỉ cần đảm bảo bạn dùng proxy một cách có trách nhiệm và đúng với điều khoản dịch vụ của website.
Tự động hóa việc thu thập nhiều trang
Muốn thu thập nhiều trang — chẳng hạn danh sách sản phẩm có phân trang? Dùng một vòng lặp shell đơn giản:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Lệnh này lấy các trang từ 2 đến 5 của danh mục Books to Scrape và lưu mỗi trang vào một tệp riêng. (Trang 1 là trang chủ.)
Hạn chế của web-scraping-with-curl: Những điều bạn cần biết
Dù tôi rất thích cURL, nó không phải “viên đạn bạc”. Đây là những điểm nó còn thiếu:
- Không thực thi JavaScript: cURL không xử lý được các trang cần JavaScript để hiển thị nội dung hoặc vượt qua thử thách chống bot (developers.cloudflare.com).
- Cần tự phân tích dữ liệu: Bạn nhận được HTML hoặc JSON thô, nhưng sẽ phải tự parse — thường bằng script hoặc công cụ bổ sung.
- Xử lý session còn hạn chế: Quản lý đăng nhập phức tạp, token, hoặc form nhiều bước có thể rất rối.
- Không tự động cấu trúc dữ liệu: cURL không biến trang web thành hàng, bảng hay bảng tính.
- Dễ bị hệ thống chống bot phát hiện: Nhiều trang hiện dùng cơ chế phòng thủ bot tiên tiến (JavaScript, fingerprinting, CAPTCHA) mà cURL đơn giản là không vượt qua được (datadome.co).
Dưới đây là bảng so sánh nhanh:
| Hạn chế | Chỉ cURL | Công cụ thu thập dữ liệu hiện đại (ví dụ: Thunderbit) |
|---|---|---|
| Hỗ trợ JavaScript | Không | Có |
| Cấu trúc hóa dữ liệu | Thủ công | Tự động (AI/Template) |
| Xử lý session | Thủ công | Tự động |
| Vượt qua chống bot | Hạn chế | Nâng cao (dựa trên trình duyệt/AI) |
| Dễ sử dụng | Dành cho kỹ thuật | Không cần kỹ thuật |
Với các trang tĩnh và API, cURL rất tuyệt. Còn với mọi thứ động hơn hoặc được bảo vệ tốt hơn, bạn sẽ muốn nâng cấp lên bộ công cụ phù hợp hơn.
Thunderbit vs. cURL: Cách tiếp cận thu thập dữ liệu web tốt nhất cho người dùng không chuyên kỹ thuật
Giờ thì nói về Thunderbit — tiện ích Chrome thu thập dữ liệu web dùng AI của chúng tôi. Nếu bạn là nhân viên sales, marketer, hoặc người làm vận hành chỉ muốn lấy dữ liệu từ website vào Excel, Google Sheets hoặc Notion — mà không muốn chạm vào dòng lệnh — Thunderbit được tạo ra cho bạn.
Đây là cách Thunderbit so với cURL:
| Tính năng | cURL | Thunderbit |
|---|---|---|
| Giao diện người dùng | Dòng lệnh | Nhấp để dùng (tiện ích Chrome) |
| Gợi ý trường bằng AI | Không | Có (AI đọc trang, gợi ý cột) |
| Xử lý phân trang/trang con | Viết script thủ công | Tự động (AI phát hiện và thu thập) |
| Xuất dữ liệu | Thủ công (phân tích + lưu) | Xuất trực tiếp sang Excel, Google Sheets, Notion, Airtable |
| Trang JavaScript/được bảo vệ | Không | Có (thu thập dựa trên trình duyệt) |
| Không cần code | Không (cần viết script) | Có (ai cũng dùng được) |
| Gói miễn phí | Luôn miễn phí | Miễn phí tối đa 6 trang (10 trang với ưu đãi dùng thử) |
Với Thunderbit, bạn chỉ cần mở tiện ích, nhấp “AI Suggest Fields”, rồi để AI xác định dữ liệu cần lấy. Bạn có thể thu thập bảng, danh sách, chi tiết sản phẩm, thậm chí tự động đi qua các trang con. Sau đó, xuất dữ liệu trực tiếp sang công cụ kinh doanh bạn thích — không cần parse, không đau đầu.
Thunderbit được hơn 100.000 người dùng trên toàn thế giới tin dùng, và đặc biệt phổ biến với các đội sales, ecommerce và bất động sản cần dữ liệu có cấu trúc thật nhanh.
Dùng thử tiện ích Chrome Thunderbit để thu thập dữ liệu web
Bạn muốn thử ngay? Tải tiện ích Chrome tại đây.
Kết hợp cURL và Thunderbit: Chiến lược thu thập dữ liệu web linh hoạt
Nếu bạn là người dùng kỹ thuật, không nhất thiết phải chọn chỉ một công cụ. Thực tế, nhiều đội nhóm dùng cURL và Thunderbit cùng nhau để có độ linh hoạt tối đa:
- Phác thảo nhanh bằng cURL: Dùng cURL để kiểm thử endpoint, xem header và hiểu cách website phản hồi.
- Mở rộng bằng Thunderbit: Khi cần dữ liệu có cấu trúc, thu thập nhiều trang, hoặc một quy trình lặp lại được, hãy chuyển sang Thunderbit để trích xuất bằng nhấp chuột và xuất dữ liệu trực tiếp.
Đây là quy trình mẫu cho nghiên cứu thị trường:
- Dùng cURL để lấy vài trang và kiểm tra cấu trúc HTML.
- Xác định các trường dữ liệu bạn muốn (ví dụ: tên sản phẩm, giá, đánh giá).
- Mở Thunderbit, nhấp “AI Suggest Fields”, và để AI thiết lập scraper.
- Thu thập tất cả các trang (bao gồm trang con hoặc danh sách phân trang) và xuất sang Google Sheets.
- Phân tích, chia sẻ và hành động dựa trên dữ liệu — không cần tự parse thủ công.
Đây là bảng quyết định nhanh:
| Tình huống | Dùng cURL | Dùng Thunderbit | Dùng cả hai |
|---|---|---|---|
| Lấy nhanh API hoặc trang tĩnh | ✅ | ||
| Cần dữ liệu có cấu trúc trong bảng tính | ✅ | ||
| Gỡ lỗi header/cookie | ✅ | ||
| Thu thập trang động/nhiều JavaScript | ✅ | ||
| Xây dựng quy trình không cần code, có thể lặp lại | ✅ | ||
| Phác thảo trước, rồi mở rộng quy mô | ✅ | ✅ | Quy trình kết hợp |
Những thách thức và cạm bẫy thường gặp khi thu thập dữ liệu web bằng cURL
Trước khi bạn “bung hết công lực” với cURL, hãy nói về những thách thức thực tế bạn sẽ gặp:
- Hệ thống chống bot: Nhiều website hiện dùng cơ chế phòng thủ nâng cao (thử thách JavaScript, CAPTCHA, fingerprinting) mà cURL không thể vượt qua (developers.cloudflare.com).
- Vấn đề chất lượng dữ liệu: HTML thay đổi, thiếu trường, hoặc bố cục không nhất quán có thể làm hỏng script của bạn.
- Chi phí bảo trì: Mỗi khi website thay đổi, bạn sẽ phải cập nhật logic parse.
- Rủi ro pháp lý và tuân thủ: Luôn kiểm tra điều khoản dịch vụ của website, robots.txt, và các luật liên quan trước khi thu thập dữ liệu. Dữ liệu công khai không có nghĩa là được phép dùng thoải mái (calawyers.org, polsinelli.com).
- Giới hạn khi mở rộng quy mô: cURL rất tốt cho các tác vụ nhỏ, nhưng khi thu thập dữ liệu ở quy mô lớn, bạn sẽ cần quản lý proxy, giới hạn tốc độ và xử lý lỗi.
Mẹo khắc phục sự cố và duy trì tuân thủ:
- Luôn bắt đầu với các trang demo hoặc trang đã được cho phép (như Books to Scrape).
- Tôn trọng giới hạn tốc độ — đừng bắn request dồn dập.
- Tránh thu thập dữ liệu cá nhân nếu không có cơ sở pháp lý.
- Nếu gặp rào cản JavaScript hoặc CAPTCHA, hãy cân nhắc chuyển sang công cụ dựa trên trình duyệt như Thunderbit.
Tóm tắt từng bước: Cách thu thập dữ liệu từ website bằng cURL
Đây là checklist tham khảo nhanh cho web-scraping-with-curl:
- Xác định URL mục tiêu: Bắt đầu với trang tĩnh hoặc endpoint API.
- Lấy trang:
curl URL - Lưu đầu ra vào tệp:
curl -o file.html URL - Kiểm tra header/gỡ lỗi:
curl -I URL,curl -v URL - Gửi dữ liệu POST:
curl -d "a=1&b=2" URL - Xử lý cookie/phiên:
curl -c cookies.txt ...,curl -b cookies.txt ... - Đặt header tùy chỉnh/User-Agent:
curl -A "..." -H "..." URL - Theo dõi chuyển hướng:
curl -L URL - Dùng proxy (nếu cần):
curl -x proxy:port URL - Tự động hóa thu thập nhiều trang: Dùng vòng lặp shell hoặc script.
- Phân tích và cấu trúc dữ liệu: Dùng thêm công cụ/script nếu cần.
- Chuyển sang Thunderbit khi cần thu thập có cấu trúc, không cần code hoặc trang động.
Kết luận và điểm mấu chốt: Chọn công cụ thu thập dữ liệu web phù hợp
Thu thập dữ liệu từ bất kỳ website nào bằng AI Get Started Free
web-scraping-with-curl vẫn là một kỹ năng rất mạnh với người dùng kỹ thuật trong năm 2026 — đặc biệt cho việc lấy dữ liệu nhanh, phác thảo nhanh và tự động hóa. Tốc độ, khả năng viết script và độ phổ biến của cURL khiến nó trở thành công cụ không thể thiếu trong bộ đồ nghề của mọi lập trình viên. Nhưng khi web ngày càng động hơn và được bảo vệ chặt hơn, và khi người dùng kinh doanh đòi hỏi dữ liệu có cấu trúc mà không cần code, những công cụ như Thunderbit đang định nghĩa lại điều có thể làm được.
Điểm mấu chốt:
- Dùng cURL cho trang tĩnh, API và phác thảo nhanh — đặc biệt khi bạn muốn toàn quyền kiểm soát.
- Chuyển sang Thunderbit (hoặc các công cụ thu thập dữ liệu web bằng AI tương tự) khi bạn cần dữ liệu có cấu trúc, xử lý trang động/nhiều JavaScript, hoặc muốn quy trình không cần code, thân thiện với người dùng kinh doanh.
- Kết hợp cả hai để linh hoạt tối đa: phác thảo bằng cURL, mở rộng và cấu trúc bằng Thunderbit.
- Luôn thu thập dữ liệu một cách có trách nhiệm — tôn trọng điều khoản website, giới hạn tốc độ và ranh giới pháp lý.
Bạn tò mò muốn xem việc thu thập dữ liệu web có thể dễ đến mức nào? Hãy thử tiện ích Chrome miễn phí của Thunderbit và tự trải nghiệm trích xuất dữ liệu bằng AI. Và nếu bạn muốn đào sâu hơn, hãy xem Thunderbit Blog để có thêm hướng dẫn, mẹo và phân tích ngành. Bạn cũng có thể thích:
- Cách thu thập dữ liệu từ bất kỳ website nào bằng AI
- Cách thu thập dữ liệu website vào Excel bằng AI
- Data Scraping là gì và cách thực hiện trong năm 2025
Chúc bạn thu thập dữ liệu vui vẻ — và mong dữ liệu của bạn luôn sạch, có cấu trúc, và chỉ cách bạn một lệnh (hoặc một cú nhấp) là có được.
Khám phá các gói Thunderbit cho web scraping ở quy mô lớn
Câu hỏi thường gặp
1. cURL có xử lý được các trang web render bằng JavaScript không?
Không, cURL không thể thực thi JavaScript. Nó chỉ lấy HTML thô do máy chủ trả về. Nếu một trang cần JavaScript để hiển thị nội dung hoặc vượt qua thử thách chống bot, cURL sẽ không thể truy cập dữ liệu đó. Trong các trường hợp đó, hãy dùng công cụ dựa trên trình duyệt như Thunderbit.
2. Làm sao để lưu đầu ra cURL trực tiếp vào tệp?
Dùng cờ -o: curl -o filename.html URL. Lệnh này ghi phần nội dung phản hồi vào tệp thay vì hiển thị trong terminal.
3. Khác nhau giữa cURL và Thunderbit trong thu thập dữ liệu web là gì?
cURL là công cụ dòng lệnh để lấy dữ liệu web thô — rất phù hợp cho người dùng kỹ thuật và tự động hóa. Thunderbit là tiện ích Chrome dùng AI, được thiết kế cho người dùng kinh doanh muốn trích xuất dữ liệu có cấu trúc từ bất kỳ website nào, xử lý trang động và xuất trực tiếp sang các công cụ như Excel hoặc Google Sheets — không cần code.
4. Thu thập dữ liệu website bằng cURL có hợp pháp không?
Việc thu thập dữ liệu công khai nhìn chung là hợp pháp ở Mỹ sau các phán quyết gần đây của tòa án, nhưng bạn luôn nên kiểm tra điều khoản dịch vụ của website, robots.txt và các luật liên quan. Tránh thu thập dữ liệu cá nhân hoặc dữ liệu được bảo vệ khi chưa có sự cho phép, và hãy tôn trọng giới hạn tốc độ cũng như các nguyên tắc đạo đức (calawyers.org, polsinelli.com).
5. Khi nào tôi nên chuyển từ cURL sang công cụ nâng cao hơn như Thunderbit?
Nếu bạn cần thu thập các trang động/nhiều JavaScript, muốn dữ liệu có cấu trúc trong bảng tính, hoặc thích quy trình không cần code, Thunderbit là lựa chọn tốt hơn. Dùng cURL cho các tác vụ kỹ thuật nhanh; dùng Thunderbit cho việc trích xuất dữ liệu lặp lại, thân thiện với người dùng kinh doanh.
Để xem thêm mẹo và hướng dẫn về thu thập dữ liệu web, hãy truy cập Thunderbit Blog hoặc xem kênh YouTube của chúng tôi.
Dùng thử Thunderbit AI Web Scraper Get Started Free




