Lần đầu tôi thử tự động hóa trình duyệt: đêm muộn, cà phê đã nguội, và một bảng tính đầy những liên kết sản phẩm mà tôi ngán ngẩm không muốn copy-paste. Chắc chắn phải có cách tốt hơn.
Và đúng là có. Tự động hóa trình duyệt đã đi từ một mẹo nhỏ dành cho lập trình viên thành công cụ kinh doanh thiết yếu. Nhưng web ngày càng phức tạp hơn — trang thì tải nội dung động, dữ liệu bị giấu sau các nút bấm, và pop-up thì cứ liên tục bật lên.
Dưới đây là 15 công cụ tự động hóa trình duyệt mà tôi đã thử — bao gồm các AI scraper như — được đối chiếu theo từng mức kỹ năng và nhu cầu sử dụng khác nhau.
Tự động hóa trình duyệt là gì? Khai mở sức mạnh của tự động hóa web và thu thập dữ liệu web
Hãy tách nó ra cho dễ hiểu: tự động hóa trình duyệt đơn giản là phần mềm mô phỏng những gì bạn làm trong trình duyệt của mình — nhấp liên kết, điền biểu mẫu, cuộn trang, tải tệp — mà bạn không cần động tay. Hãy xem nó như trợ lý số của bạn, kiên nhẫn lặp lại những tác vụ web mà bạn chẳng muốn tự làm ().
Thu thập dữ liệu web là một biến thể đặc biệt của tự động hóa trình duyệt, tập trung vào việc trích xuất dữ liệu từ website và biến nó thành dạng có cấu trúc — như bảng tính hoặc cơ sở dữ liệu — để bạn thực sự dùng được. Không còn copy-paste nữa. Tự động hóa web là khái niệm bao trùm cả hai: tự động hóa mọi tương tác với ứng dụng web, từ trích xuất dữ liệu đến gửi biểu mẫu hay thậm chí vận hành cả một quy trình làm việc ().
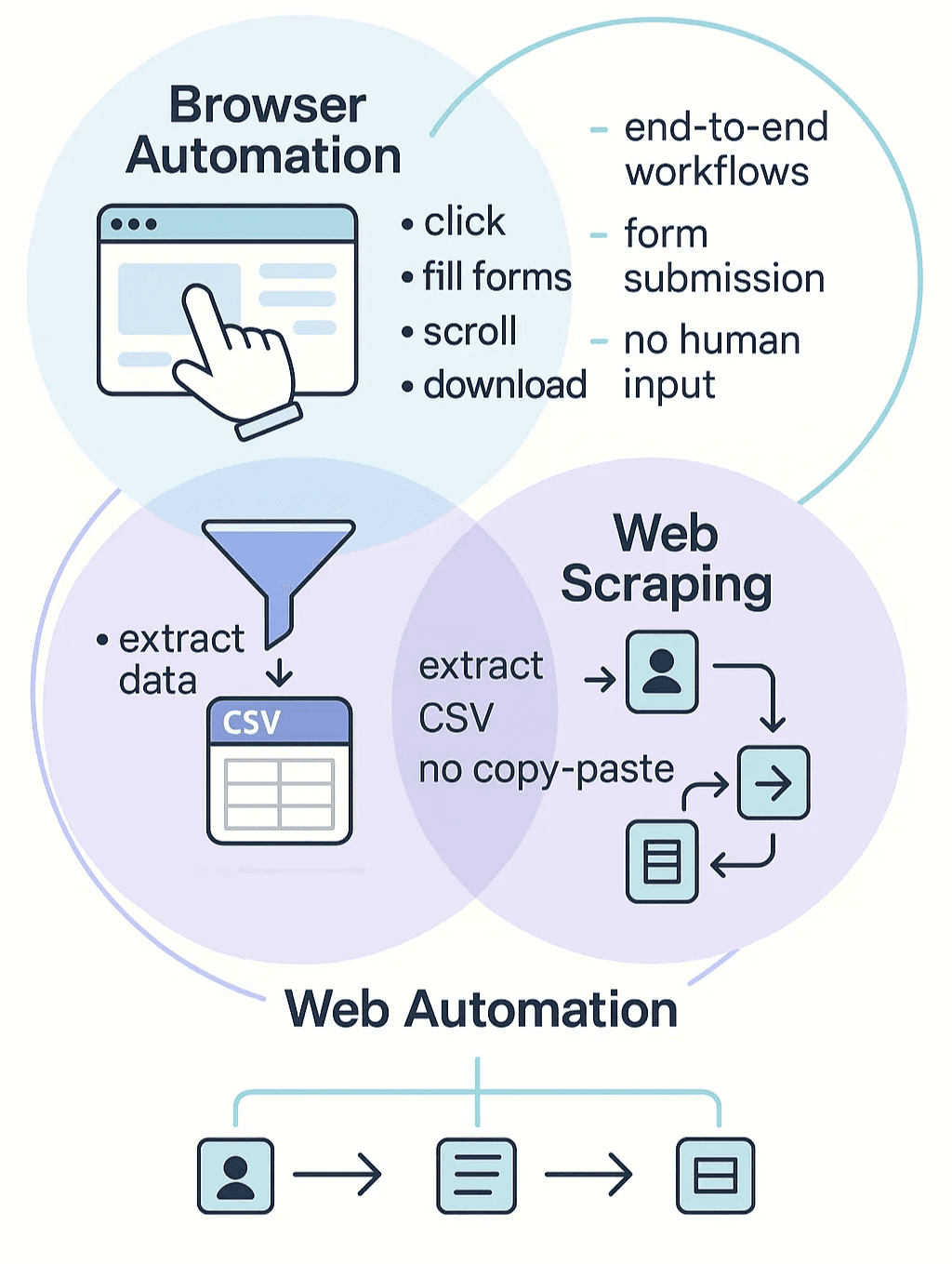
Vì sao tự động hóa trình duyệt lại quan trọng đến vậy lúc này? Website hiện đại mang tính động và phụ thuộc nhiều vào JavaScript. Nội dung tải dần khi bạn cuộn xuống, nút bấm mở khóa thông tin ẩn, và đôi khi bạn phải đăng nhập hoặc bấm qua vài bước mới lấy được dữ liệu. Các scraper kiểu cũ chỉ lấy HTML tĩnh đã không còn theo kịp. Công cụ tự động hóa trình duyệt thực sự điều khiển một trình duyệt thật (đôi khi ở chế độ headless — không có giao diện), nên có thể xử lý nội dung động và mô phỏng hành động người dùng thật ().
Tóm lại: tự động hóa trình duyệt là “gia vị bí mật” để trích xuất và tương tác với web hiện đại, nhất là khi mọi thứ trở nên lộn xộn.
Vì sao tự động hóa trình duyệt quan trọng với doanh nghiệp hiện đại
Hãy nói về giá trị kinh doanh. Tự động hóa trình duyệt và thu thập dữ liệu web không chỉ dành cho dân kỹ thuật — giờ đây nó còn quan trọng với sales, ecommerce, vận hành, và gần như mọi đội nhóm dựa vào dữ liệu web.
Lý do là:
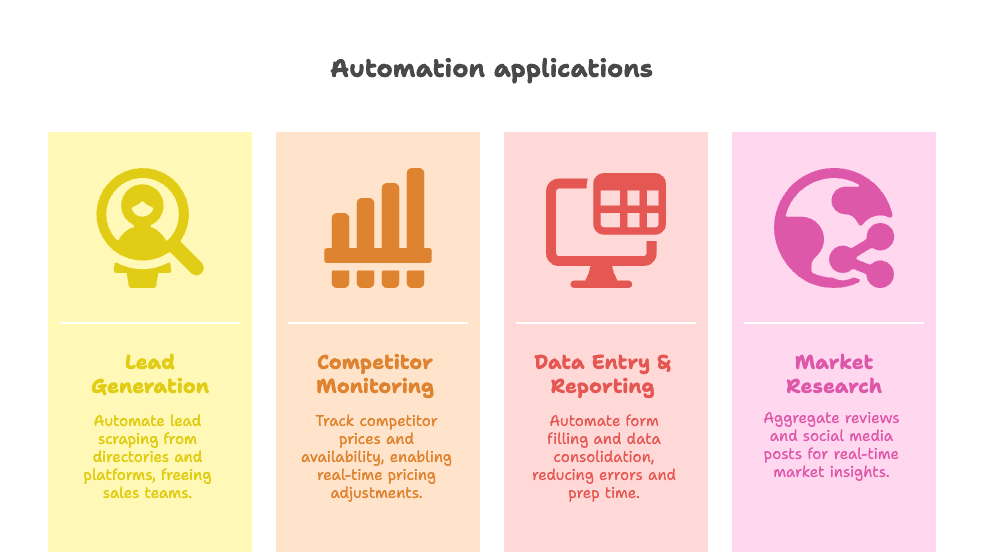
- Tạo lead: Thu thập danh bạ doanh nghiệp, LinkedIn hoặc Google Maps để có lead mới ngay cả khi bạn đang ngủ. Các đội sales dùng tự động hóa báo cáo rằng họ dành nhiều hơn 82% thời gian cho việc bán hàng thực sự, thay vì đi tìm thông tin liên hệ ().
- Theo dõi đối thủ & giá cả: Các đội ecommerce dùng bot để theo dõi giá đối thủ và tình trạng hàng hóa hằng ngày, rồi điều chỉnh giá của mình gần như theo thời gian thực ().
- Nhập liệu & báo cáo: Tự động điền biểu mẫu, tổng hợp dữ liệu từ nhiều nguồn, và loại bỏ lỗi do con người. Một công ty y tế đã cắt giảm 60% nhập liệu thủ công và giảm 40% thời gian chuẩn bị báo cáo ().
- Nghiên cứu thị trường: Gom đánh giá, danh sách niêm yết hoặc bài đăng mạng xã hội để có cái nhìn thời gian thực mà làm thủ công gần như không thể.
Và các con số cũng xác nhận điều đó:
- Gần hiện nay là bot — phần lớn là tự động hóa và scraping.
- dùng thu thập dữ liệu web để nuôi các dự án AI và phân tích.
- trong năm đầu là khá phổ biến với các khoản đầu tư vào tự động hóa số.
Đây là bảng nhanh về các kịch bản kinh doanh phổ biến và lợi ích của tự động hóa trình duyệt:
| Kịch bản kinh doanh | Lợi ích của tự động hóa |
|---|---|
| Tạo lead | Nhanh chóng xây dựng danh sách lead, giúp sales tập trung chốt đơn |
| Theo dõi giá | Nắm bắt thị trường theo thời gian thực, định giá linh hoạt, phản ứng tức thì với thay đổi của đối thủ |
| Nhập liệu & báo cáo | Loại bỏ việc copy-paste tẻ nhạt, giảm lỗi, giữ dữ liệu luôn cập nhật |
| Nghiên cứu thị trường & phân tích đối thủ | Gom dữ liệu lớn để rút ra insight, hỗ trợ chiến lược dựa trên dữ liệu |
Nói ngắn gọn: tự động hóa trình duyệt là cách để doanh nghiệp hiện đại vận hành nhanh hơn, chính xác hơn và cạnh tranh hơn.
Các nhóm công cụ tự động hóa trình duyệt: Từ AI Web Scraper đến giải pháp no-code
Không phải công cụ tự động hóa trình duyệt nào cũng giống nhau. Tùy vào nền tảng và nhu cầu, bạn sẽ muốn chọn từ bốn nhóm chính:
- Công cụ dành cho lập trình viên: Dành cho những người thích code (như Selenium, Puppeteer, Playwright, Cypress). Linh hoạt tối đa, nhưng bạn cần có kỹ năng lập trình.
- Nền tảng no-code/low-code: Các trình dựng trực quan và công cụ ghi thao tác (như Browserflow, Axiom.ai, UI Vision) cho phép người không chuyên tự động hóa bằng cách bấm và kéo thả.
- Bộ RPA cấp doanh nghiệp: Các nền tảng nặng đô (UiPath, Automation Anywhere, Microsoft Power Automate) được thiết kế cho tự động hóa quy trình kinh doanh quy mô lớn, đầu-cuối.
- Giải pháp dùng AI: Tân binh của thị trường — như — dùng AI để “đọc” trang web, thích ứng với thay đổi, và cho phép bạn tự động hóa chỉ bằng vài cú nhấp hoặc hướng dẫn bằng tiếng Anh đơn giản.
Mỗi nhóm đều có thế mạnh riêng. Lập trình viên có toàn quyền kiểm soát, người dùng doanh nghiệp có tốc độ và sự đơn giản, còn các công cụ dùng AI đang thu hẹp khoảng cách — biến tự động hóa mạnh mẽ thành thứ ai cũng có thể dùng.
Thunderbit: AI Web Scraper dành cho mọi người
Nói thật nhé: tôi có thiên vị, nhưng là có lý do. là công cụ mà tôi ước mình đã có từ nhiều năm trước. Đây là một tiện ích mở rộng Chrome dùng AI, cho phép bất kỳ ai — vâng, kể cả khi bạn không biết một dòng code nào — trích xuất dữ liệu có cấu trúc từ bất kỳ website nào chỉ với hai cú nhấp.
Điểm khiến Thunderbit nổi bật:
- AI gợi ý trường dữ liệu: Chỉ cần bấm “AI Suggest Fields”, Thunderbit sẽ đọc trang, đề xuất các cột phù hợp nhất và tự thiết lập scraper cho bạn.
- Thu thập trang con: Cần thêm chi tiết? Thunderbit có thể tự động truy cập từng trang con (như trang sản phẩm hoặc hồ sơ) và làm giàu bảng dữ liệu của bạn.
- Thu thập theo lịch: Thiết lập một lần rồi để đó. Lên lịch chạy scrape theo chu kỳ — rất phù hợp cho theo dõi giá, kiểm tra tồn kho hoặc kéo lead định kỳ.
- Mẫu scraper dữ liệu tức thì: Với các site phổ biến như Amazon, Zillow hoặc Instagram, chỉ cần chọn mẫu và xuất dữ liệu trong một cú nhấp.
- Xuất dữ liệu miễn phí: Tải kết quả xuống CSV, Excel hoặc đẩy trực tiếp sang Google Sheets, Airtable, hoặc Notion — không có tường phí cho tính năng xuất dữ liệu.
- Biến đổi dữ liệu bằng AI: Tóm tắt, phân loại, dịch hoặc định dạng lại dữ liệu ngay trong lúc scrape — AI sẽ xử lý phần nặng nhất ().
Phù hợp với ai? Các đội sales, vận hành ecommerce, môi giới bất động sản, marketer — nói chung là bất kỳ ai cần dữ liệu web nhưng không muốn vật lộn với code hay các scraper cũ dễ hỏng.
Điều tôi thích nhất: Thunderbit thích ứng với thay đổi của website (không còn script bị gãy), xử lý được các trang nặng JavaScript, và biến việc scrape trở nên dễ như gọi đồ ăn mang về. Thêm nữa, bạn có thể dùng thử miễn phí, còn gói trả phí chỉ từ 9 USD/tháng (). Nếu muốn xem nó hoạt động thế nào, hãy xem hoặc đọc thêm mẹo trên .
Selenium: Khung tự động hóa trình duyệt kinh điển
Selenium là “OG” của tự động hóa trình duyệt — hãy xem nó như con dao đa năng Thụy Sĩ dành cho lập trình viên và kỹ sư QA. Đây là mã nguồn mở, hỗ trợ mọi trình duyệt lớn, và cho phép bạn viết script bằng Java, Python, C#, JavaScript, v.v.

Điểm mạnh:
- Đa trình duyệt, đa nền tảng: Chạy ở khắp nơi, tích hợp với CI/CD, và là nền tảng của nhiều bộ test tự động.
- Hệ sinh thái trưởng thành: Rất nhiều plugin, nhà cung cấp grid trên cloud và cộng đồng hỗ trợ.
- Miễn phí và mã nguồn mở: Không mất phí bản quyền.
Hạn chế: Cần kỹ năng lập trình, có thể khó bảo trì (đặc biệt khi website thay đổi), và không phải là lựa chọn nhanh nhất cho các job scrape cực lớn. Nhưng nếu bạn là lập trình viên hoặc chuyên gia QA, Selenium vẫn là công cụ bắt buộc phải biết.
Puppeteer: Tự động hóa trình duyệt headless cho thu thập dữ liệu web
Puppeteer, từ Google, là một thư viện Node.js điều khiển Chrome hoặc Chromium — mặc định ở chế độ headless. Đây là lựa chọn yêu thích của các lập trình viên muốn tự động hóa Chrome, thu thập nội dung động hoặc tạo PDF/screenshot.
Điểm mạnh:
- API JavaScript hiện đại: Dễ viết script cho các tác vụ trình duyệt phức tạp.
- Chế độ headless: Nhanh và tiết kiệm tài nguyên cho việc scrape hoặc test.
- Rất hợp với site động: Xử lý dễ dàng các trang nặng JavaScript.
Hạn chế: Chủ yếu dành cho người dùng JavaScript/Node.js, và tập trung vào Chrome/Chromium (hỗ trợ Firefox đang cải thiện). Nếu bạn cần Safari hoặc Edge, hãy xem Playwright.
Playwright: Tự động hóa đa trình duyệt cho ứng dụng web hiện đại
Playwright, từ Microsoft, là tân binh nhưng rất mạnh. Nó hỗ trợ Chromium, Firefox và WebKit (engine của Safari) với một API duy nhất, và hoạt động trên JavaScript, Python, Java và .NET.

Điểm mạnh:
- Tự động hóa thực sự đa trình duyệt: Một script, mọi trình duyệt.
- Auto-wait và độ tin cậy cao: Giảm test lỗi ngẫu nhiên và lỗi scrape.
- Công cụ gỡ lỗi tuyệt vời: Inspector, trace viewer và codegen.
Hạn chế: Hệ sinh thái còn trẻ hơn Selenium một chút, nhưng đang bắt kịp rất nhanh. Nếu bạn bắt đầu một dự án mới, Playwright là lựa chọn rất đáng giá.
Cypress: Tự động hóa web và kiểm thử tinh gọn
Cypress là công cụ kiểm thử end-to-end thân thiện với lập trình viên, được xây cho các ứng dụng web hiện đại. Nó chạy test ngay trong trình duyệt, có gỡ lỗi theo thời gian thực, và được các đội front-end rất yêu thích.
Điểm mạnh:
- Bộ chạy test tất cả trong một: Trực quan, tương tác tốt và nhanh.
- Tự động chờ: Ít test lỗi vặt hơn, ít phải viết mã canh thời gian thủ công hơn.
- Rất tốt cho SPA: Xử lý mượt hành vi bất đồng bộ.
Hạn chế: Trước đây chủ yếu tập trung vào Chrome (nay đã hỗ trợ Firefox/WebKit), không được thiết kế cho scraping hay workflow nhiều tab. Tốt nhất là để kiểm thử ứng dụng của chính bạn, không phải thu thập dữ liệu từ site của bên thứ ba.
Các công cụ tự động hóa trình duyệt no-code và low-code
Browserflow
Browserflow là một tiện ích Chrome cho phép bạn xây dựng các “flow” tự động hóa bằng giao diện trực quan — không cần code. Bấm, ghi lại thao tác, chỉnh bước, rồi tự động hóa các việc như thu thập dữ liệu, điền biểu mẫu hoặc nhập liệu.
Điểm nổi bật:
- Trình dựng flow trực quan: Kéo thả các bước, thêm vòng lặp hoặc điều kiện.
- Tích hợp Google Sheets: Xuất dữ liệu trực tiếp sang Sheets.
- Lập lịch trên cloud: Chạy flow theo lịch (gói trả phí).
Rất phù hợp cho người không chuyên muốn tự động hóa các tác vụ web lặp đi lặp lại mà không cần làm phiền IT.
Axiom.ai
Axiom.ai là một tiện ích Chrome no-code khác, tập trung vào tự động hóa quy trình kinh doanh (). Bạn có thể xây bot từng bước, tích hợp với Google Sheets, API, và cả Zapier.
Điểm nổi bật:
- Giao diện xây bot: Ghép các hành động bằng trực quan.
- Mẫu dựng sẵn: Bắt đầu nhanh với các quy trình phổ biến.
- Lập lịch và tích hợp trên cloud: Tự động hóa xuyên suốt các ứng dụng web.
Rất hợp với đội vận hành hoặc bất kỳ ai muốn tự động hóa chuyển dữ liệu và tác vụ web mà không cần viết code.
UI Vision, Browser Automation Studio, TagUI
- UI Vision: Tiện ích trình duyệt mã nguồn mở với các lệnh kiểu Selenium IDE và tự động hóa trực quan (nhận diện hình ảnh, OCR). Miễn phí, đa nền tảng, và thậm chí có thể tự động hóa ứng dụng desktop.
- Browser Automation Studio: Ứng dụng Windows với IDE lập trình trực quan, đa luồng, và có thể biên dịch bot độc lập. Mạnh mẽ, nhưng đường cong học tập khá dốc.
- TagUI: Công cụ RPA dòng lệnh mã nguồn mở cho phép bạn viết script tự động hóa bằng tiếng Anh đơn giản (hoặc ngôn ngữ khác). Rất hợp với người rành kỹ thuật muốn một giải pháp miễn phí, linh hoạt.
Các công cụ RPA cấp doanh nghiệp
UiPath
UiPath là nền tảng RPA hạng nặng để tự động hóa từ tác vụ trên trình duyệt đến ứng dụng desktop. Trình thiết kế workflow trực quan, AI computer vision và khả năng điều phối mạnh giúp nó được nhiều tổ chức lớn yêu thích.
Điểm mạnh: Quy mô doanh nghiệp, cộng đồng mạnh, hỗ trợ cả tự động hóa có người giám sát và không giám sát.
Hạn chế: Đắt, và các tính năng nâng cao có độ phức tạp cao. Phù hợp nhất với các công ty có tham vọng tự động hóa lớn.
Automation Anywhere
Một bộ RPA hàng đầu khác, Automation Anywhere cung cấp tự động hóa ưu tiên cloud, trình dựng bot trực quan và tích hợp mạnh với các ứng dụng doanh nghiệp ().
Điểm mạnh: Dễ dùng, native trên cloud, phù hợp cho tự động hóa cả front office lẫn back office.
Hạn chế: Chi phí và độ phức tạp tương tự UiPath, nhưng vẫn là lựa chọn vững cho doanh nghiệp.
Microsoft Power Automate
Nếu bạn đang ở trong hệ sinh thái Microsoft, Power Automate mang tự động hóa trình duyệt và desktop đến với người dùng Office 365 ().
Điểm mạnh: Tích hợp chặt với ứng dụng Microsoft, giá hợp lý cho khách hàng hiện có, dễ dùng với người dùng doanh nghiệp.
Hạn chế: Thiên về Windows, chưa thật trưởng thành cho các tính năng RPA nâng cao, nhưng đang cải thiện rất nhanh.
BrowserStack Automate
BrowserStack Automate không phải trình dựng script — đây là nền tảng cloud để chạy script Selenium, Playwright hoặc Cypress của bạn trên hàng nghìn tổ hợp trình duyệt/thiết bị ().
Điểm mạnh: Phủ cực rộng, chạy test song song, không phải tự duy trì hạ tầng.
Hạn chế: Không dùng để xây automation, nhưng lại cực kỳ cần thiết cho kiểm thử đa trình duyệt ở quy mô lớn.
Cách chọn công cụ tự động hóa trình duyệt tốt nhất cho nhu cầu của bạn
Chọn đúng công cụ đôi khi giống như chọn điện thoại mới — ai cũng có ý kiến riêng, và còn tùy bạn thực sự cần gì. Đây là cách tôi sẽ làm từng bước:
- Xác định mục tiêu: Bạn đang thu thập dữ liệu, tự động hóa quy trình kinh doanh hay kiểm thử ứng dụng web?
- Đánh giá kỹ năng của đội ngũ: Có lập trình viên không? Hãy chọn công cụ dựa trên code. Là người dùng doanh nghiệp? Chọn no-code hoặc công cụ dùng AI như Thunderbit.
- Xem xét độ phức tạp: Chỉ scrape đơn giản? Hãy thử Thunderbit hoặc Browserflow. Workflow phức tạp, nhiều ứng dụng? Hãy xem UiPath hoặc Power Automate.
- Kiểm tra khả năng tương thích trình duyệt: Cần đa trình duyệt? Chọn Playwright hoặc Selenium. Chỉ cần Chrome là đủ? Puppeteer, Cypress, hoặc hầu hết công cụ no-code đều ổn.
- Nghĩ về quy mô: Với job rất lớn, công cụ dựa trên code hoặc RPA doanh nghiệp sẽ scale tốt nhất. Với nhu cầu vừa phải, tiện ích trình duyệt là đã quá đủ.
- Ngân sách: Công cụ mã nguồn mở thì miễn phí nhưng cần cấu hình nhiều hơn. Công cụ no-code và AI có giá hợp lý cho SMB. Bộ RPA là một khoản đầu tư.
Đây là bảng so sánh nhanh:
| Nhóm công cụ | Dễ sử dụng | Tính năng & sức mạnh | Người dùng lý tưởng |
|---|---|---|---|
| Khung dựa trên code | Khó học | Linh hoạt tối đa | Lập trình viên, kỹ sư QA |
| Công cụ no-code | Rất dễ | Độ phức tạp vừa phải | Người dùng doanh nghiệp, nhà phân tích |
| RPA doanh nghiệp | Trung bình (cần đào tạo) | Tự động hóa đầu-cuối | Tổ chức lớn, đội RPA |
| Công cụ dùng AI | Dễ nhất | Thu thập dữ liệu thông minh, thích ứng tốt | Sales, vận hành, người không chuyên kỹ thuật |
Xu hướng tương lai của tự động hóa trình duyệt, thu thập dữ liệu web và công nghệ AI Web Scraper
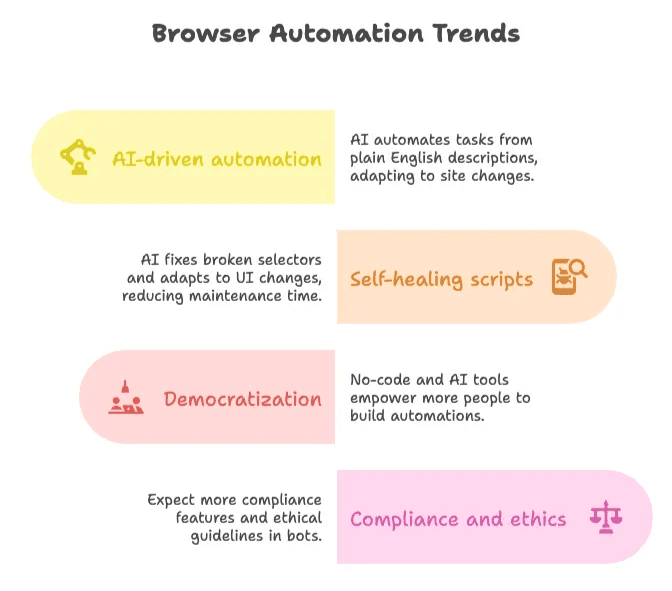
- Tự động hóa do AI dẫn dắt: Các công cụ như Thunderbit đang đi đầu, cho phép người dùng mô tả tác vụ bằng tiếng Anh đơn giản và tự thích ứng với thay đổi của website ().
- Script tự phục hồi: AI giờ đây có thể sửa selector bị hỏng và thích ứng với thay đổi UI, cắt giảm tới 50% thời gian bảo trì ().
- Phổ cập hóa: Ngày càng có nhiều “citizen developer” tự xây automation của riêng mình nhờ các công cụ no-code và dùng AI ().
- Tuân thủ và đạo đức: Khi bot ngày càng phổ biến, hãy kỳ vọng sẽ có thêm các tính năng tuân thủ tích hợp sẵn và hướng dẫn đạo đức rõ hơn ().
Kết luận ngắn gọn: tự động hóa trình duyệt chỉ ngày càng mạnh hơn và thân thiện hơn. Nếu bạn vẫn chưa tự động hóa, tức là bạn đang bỏ lại thời gian và tiền bạc trên bàn.
Kết luận: Tăng tốc doanh nghiệp của bạn với công cụ tự động hóa trình duyệt phù hợp
Tự động hóa trình duyệt không chỉ là một xu hướng công nghệ — nó là xương sống của doanh nghiệp hiện đại, vận hành dựa trên dữ liệu. Dù bạn là người làm một mình hay thuộc một công ty Fortune 500, công cụ phù hợp có thể giúp bạn tiết kiệm hàng giờ, tăng độ chính xác và mở ra những insight mà trước đây bạn chưa từng nghĩ tới.
Lời khuyên của tôi? Hãy bắt đầu nhỏ. Chọn một công cụ trong danh sách này — nếu bạn muốn thu thập dữ liệu web dễ nhất và chính xác nhất mà không cần code, là nơi bắt đầu rất tuyệt. Hãy thử nó với một việc thực tế, tự xem ROI, rồi mở rộng khi bạn phát triển.
Và nhớ nhé: tương lai thuộc về những người biết tự động hóa. Vậy nên hãy nắm lấy trợ lý số của bạn, nói lời tạm biệt với những công việc web lặp lại nhàm chán, và quay lại với những phần thú vị hơn.
Câu hỏi thường gặp
-
Sự khác nhau giữa tự động hóa trình duyệt, thu thập dữ liệu web và tự động hóa web là gì?
Tự động hóa trình duyệt mô phỏng hành động của con người trong trình duyệt — nhấp, cuộn và điền biểu mẫu. Thu thập dữ liệu web tập trung vào việc trích xuất dữ liệu có cấu trúc (như bảng) từ website. Tự động hóa web là khái niệm rộng hơn, bao gồm cả hai, bao trùm mọi tác vụ được tự động hóa qua trình duyệt — như gửi biểu mẫu, thu thập dữ liệu hoặc cả workflow hoàn chỉnh.
-
Vì sao doanh nghiệp đầu tư vào tự động hóa trình duyệt?
Vì nó tiết kiệm thời gian, giảm lỗi và nâng hiệu suất. Đội sales thu thập lead, ecommerce theo dõi giá, còn vận hành thì tự động nhập liệu. Các nghiên cứu cho thấy ROI năm đầu có thể đạt 30–200%, và 65% công ty đang dùng dữ liệu web để phục vụ các dự án AI và phân tích.
-
Tôi không phải lập trình viên — tôi vẫn có thể scrape website chứ?
Có chứ! Các công cụ như được xây cho người không biết code. Chỉ cần cài tiện ích Chrome, bấm “AI Suggest Fields”, và Thunderbit sẽ trích xuất dữ liệu có cấu trúc cho bạn — kể cả từ các trang động. Nhanh, chính xác và có thể dùng thử miễn phí. Rất hợp cho đội sales, ecommerce và nghiên cứu.
Tìm hiểu thêm: