
Thu thập dữ liệu Facebook vẫn đáng để làm trong năm 2026, nhưng chỉ khi bạn chọn đúng cách làm. Pew Research Center cho biết vào ngày 20/11/2025 rằng 71% người trưởng thành tại Mỹ dùng Facebook, và Meta nói vào ngày 29/4/2026 rằng Family of Apps đạt 3,56 tỷ người dùng hoạt động hằng ngày trong tháng 3/2026. Quy mô đó khiến Facebook vẫn rất hữu ích để theo dõi Marketplace, nghiên cứu trang công khai, tạo khách hàng tiềm năng và theo dõi đối thủ. Điều khó không phải là tìm ra trường hợp sử dụng. Điều khó là lấy được dữ liệu sạch mà không vướng tường đăng nhập, nội dung tải động, chặn tạm thời hoặc các thiết lập thu thập dữ liệu dễ hỏng.
Danh sách rút gọn hằng năm này được xây dựng để giúp bạn ra quyết định nhanh hơn. Tôi đã kiểm tra lại các trang sản phẩm chính thức, tài liệu hướng dẫn và tín hiệu giá vào ngày 8/5/2026, rồi chỉ giữ lại những công cụ vẫn thực sự phù hợp với người dùng doanh nghiệp. Nếu quy trình của bạn chủ yếu là “lấy dữ liệu trên trang này và gửi vào bảng tính”, hãy bắt đầu với Thunderbit. Nếu bạn cần hạ tầng ở quy mô API, Bright Data, Apify và Nimble by Nimbleway nên nằm gần đầu danh sách. Nếu công việc của bạn bao gồm tự động hóa trên cloud hoặc thực hiện hành động sau khi thu thập, PhantomBuster rất đáng xem kỹ hơn.
Lựa chọn nhanh theo nhu cầu
- Cần xuất dữ liệu Facebook hoặc Marketplace nhanh nhất, không cần code? Bắt đầu với Thunderbit.
- Cần quy mô API cấp doanh nghiệp và cơ chế gỡ chặn được quản lý? Hãy đưa Bright Data vào danh sách rút gọn.
- Cần quy trình thu thập dữ liệu trên cloud linh hoạt? Xem kỹ Apify.
- Cần thu thập dữ liệu web công khai theo hướng API-first, ít phải bảo trì scraper hơn? Cân nhắc Nimble by Nimbleway.
- Cần API tiết kiệm cho các công việc nhẹ hơn? ScrapingBot vẫn còn rất phù hợp.
- Cần vừa thu thập dữ liệu vừa tự động hóa quy trình? PhantomBuster là lựa chọn hợp hơn.
- Cần trình xây dựng workflow kiểu kéo-thả kèm lập lịch? Octoparse vẫn là một lựa chọn no-code vững vàng.
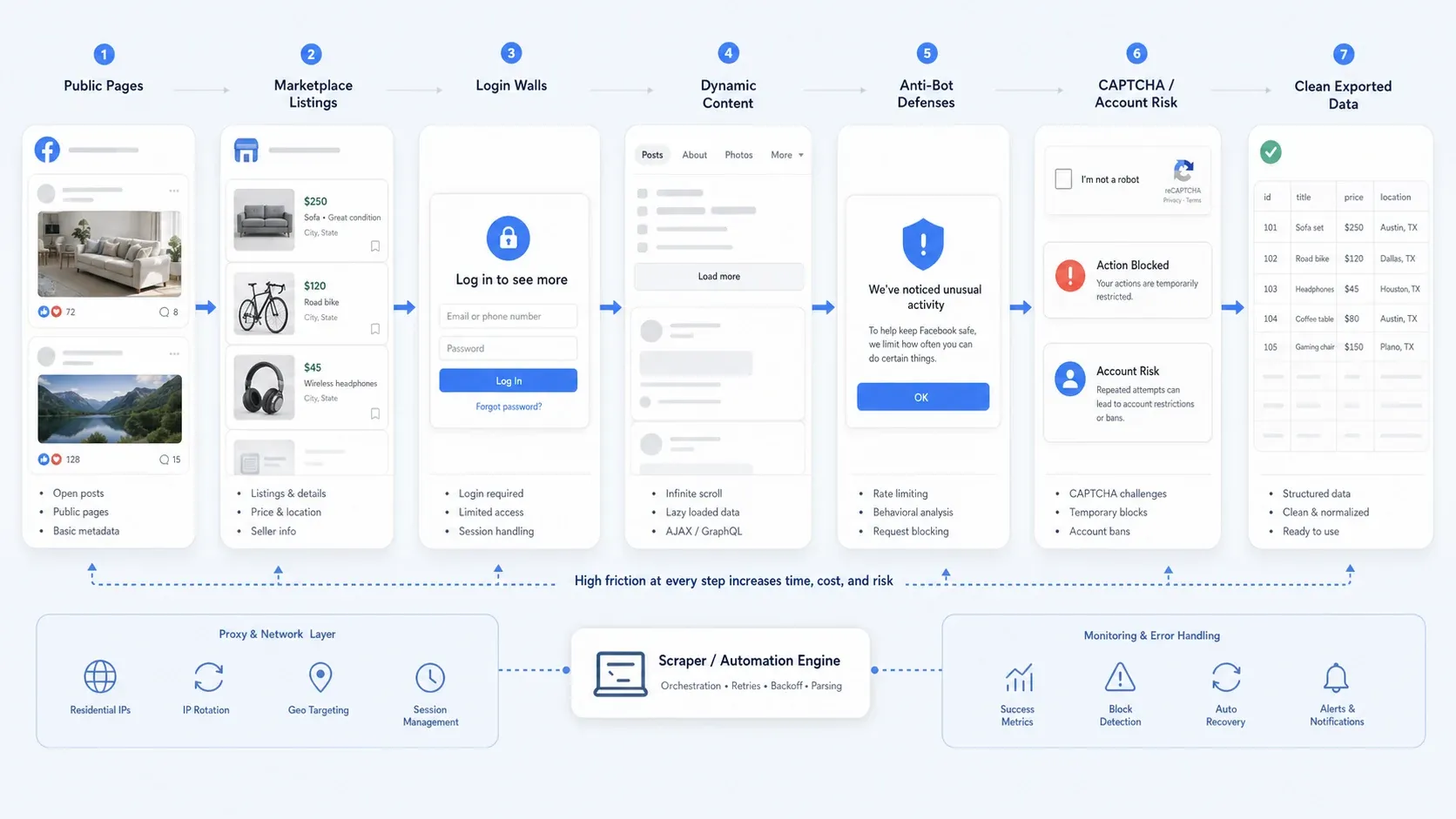
Vì sao thu thập dữ liệu Facebook vẫn khó trong năm 2026
Việc thu thập dữ liệu Facebook hiếm khi chỉ còn là bài toán chọn selector. Trên thực tế, hầu hết đội ngũ sẽ gặp một hoặc nhiều vấn đề sau:
- Truy cập công khai một phần: Một số trang vẫn công khai, nhưng các luồng khác sẽ đẩy bạn sang đăng nhập để xem chi tiết hơn.
- Nội dung động: Màn hình Marketplace, chuỗi bình luận dài và nội dung trang thường tải theo từng đợt.
- Chống bot: Giới hạn tốc độ, kiểm tra hành vi, CAPTCHA và chặn tạm thời có thể làm hỏng các tự động hóa ngây thơ.
- Rủi ro vận hành: Thu thập dữ liệu chỉ khi đăng nhập rủi ro hơn nhiều so với scrape trang công khai, nhất là nếu bạn quan tâm đến an toàn tài khoản và khả năng lặp lại.
Tôi đã đánh giá các công cụ này như thế nào
Tôi tối ưu trang này cho việc chọn danh sách rút gọn, chứ không phải để nhồi nhét tính năng. Các công cụ dưới đây được so sánh dựa trên:
- Mức độ phù hợp với quy trình: Sản phẩm có thực sự khớp với các công việc thu thập dữ liệu Facebook và Marketplace mà đội ngũ thực tế đang làm không?
- Mức độ dễ dùng: Người không phải lập trình viên hoặc đội ngũ nhỏ có thể nhanh chóng tạo ra đầu ra dùng được không?
- Quy mô và độ tin cậy: Công cụ có còn hợp lý khi bạn vượt qua một lần scrape đơn lẻ không?
- Chống bot và xử lý phiên: Sản phẩm gỡ bỏ bao nhiêu gánh nặng hạ tầng?
- Chất lượng đầu ra: Có đưa được dữ liệu có cấu trúc vào CSV, Sheets hoặc các hệ thống phía sau mà không cần dọn dẹp nhiều không?
- Tín hiệu giá: Sản phẩm có thực tế để đánh giá không, hay đòi hỏi quy trình doanh nghiệp nặng nề?
- Tư thế tuân thủ: Công cụ có rõ ràng hướng đến thu thập dữ liệu công khai và sử dụng có trách nhiệm không?
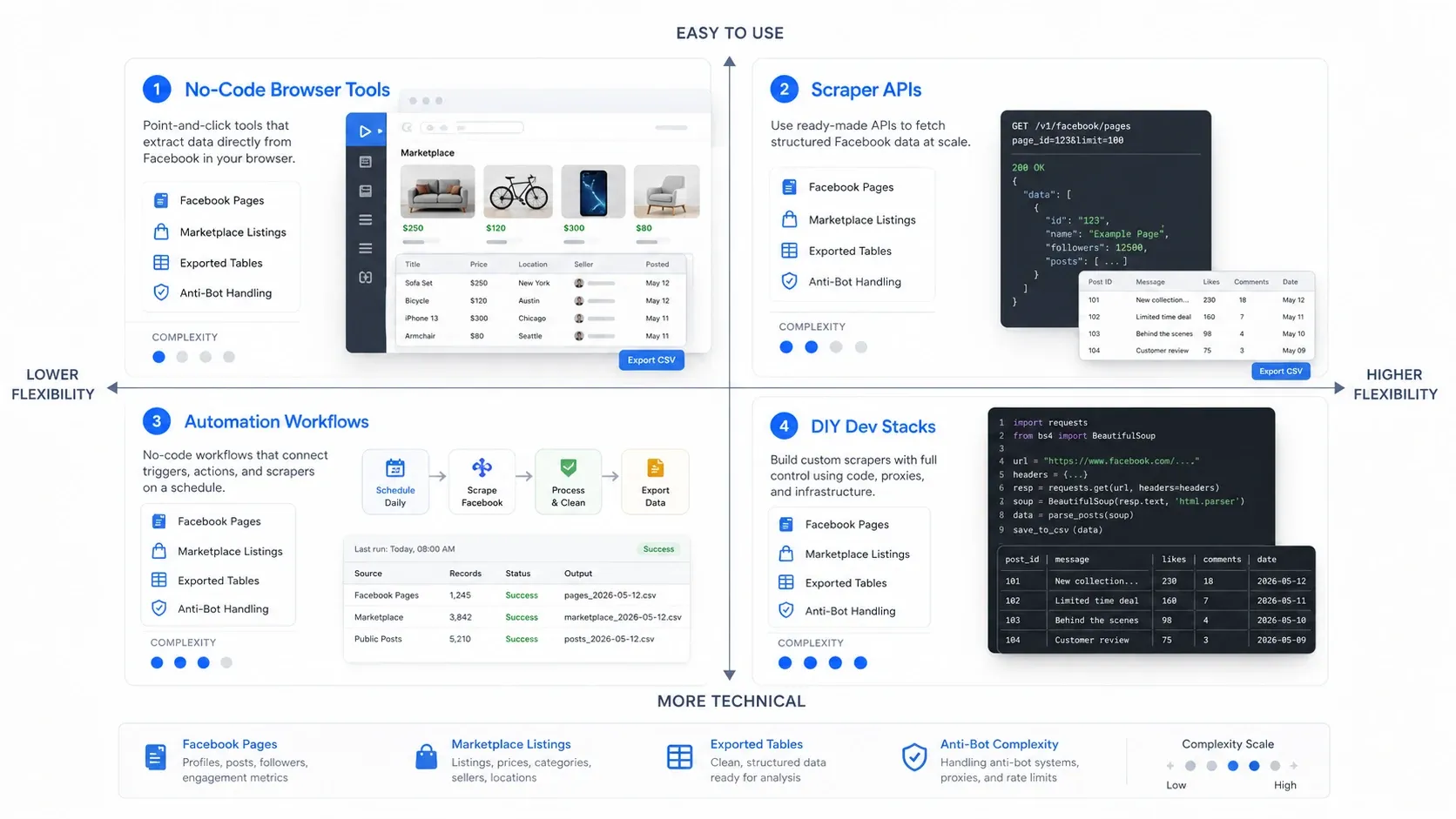
Bạn cần loại Facebook scraper nào?
Cách chọn nhanh nhất là chọn đúng nhóm trước. Các công cụ thu thập dữ liệu Facebook thường rơi vào bốn mô hình vận hành:
- Công cụ no-code trên trình duyệt: Phù hợp nhất khi bạn muốn trích xuất nhanh từ chính trang đang mở trước mặt.
- API scraper: Phù hợp nhất khi bạn cần thu thập dữ liệu ổn định, lặp lại được ở khối lượng lớn hơn.
- Workflow tự động hóa: Phù hợp nhất khi scrape chỉ là một bước trong quy trình go-to-market rộng hơn.
- Stack tự làm cho lập trình viên: Phù hợp nhất khi đội ngũ muốn kiểm soát tối đa và sẵn sàng tự gánh phần bảo trì.
Bảng so sánh
| Công cụ | Phù hợp nhất cho | Vì sao có mặt trong danh sách rút gọn | Tín hiệu giá |
|---|---|---|---|
| Thunderbit | Đội ngũ không chuyên kỹ thuật và các việc phát sinh nhanh | Nhận diện trường bằng AI, xử lý trang động ngay trên trình duyệt, xuất dữ liệu nhanh | Dùng thử miễn phí; gói trả phí theo credit |
| Bright Data | Pipeline dữ liệu xã hội công khai quy mô lớn | API scraper mạng xã hội chuyên dụng, gỡ chặn được quản lý, khả năng mở rộng mạnh | Giá theo mức sử dụng và theo doanh nghiệp |
| Apify | Workflow thu thập dữ liệu trên cloud linh hoạt | Actor Facebook dựng sẵn, lập lịch, truy cập API, không gian tùy biến | Gói nền tảng trả phí kèm mức dùng tính riêng |
| Nimble by Nimbleway | Thu thập dữ liệu web công khai theo hướng API-first | Luồng API ưu tiên URL và giảm gánh nặng bảo trì scraper | Giá bán theo tư vấn |
| ScrapingBot | Công việc dữ liệu công khai nhỏ và bản mẫu thử nghiệm | API đơn giản, hỗ trợ render, mức giá đầu vào thấp hơn | Có gói miễn phí; gói trả phí từ khoảng 22 USD/tháng |
| PhantomBuster | Workflow tự động hóa GTM | Tự động hóa trên cloud, workflow hành động trình duyệt, phù hợp tạo lead | Dùng thử miễn phí; gói trả phí từ khoảng 56 USD/tháng |
| Octoparse | Scrape theo lịch bằng giao diện no-code | Trình dựng kéo-thả, trích xuất trên cloud, workflow lặp lại được | Có gói miễn phí; gói trả phí từ khoảng 119 USD/tháng |
1. Thunderbit
Thunderbit là lựa chọn mạnh nhất ở đây nếu mục tiêu của bạn là biến một trang Facebook hoặc danh sách kết quả Marketplace thành dữ liệu có cấu trúc thật nhanh mà không cần xây hay bảo trì scraper. Ưu điểm cốt lõi của nó là trích xuất ngữ nghĩa: công cụ đọc trang, gợi ý các trường hữu ích và cho phép xuất kết quả mà không phải xử lý selector, proxy hay code.
Điểm nổi bật:
- AI Suggest Fields: Thunderbit nhận diện các trường có khả năng cần thiết như tiêu đề, giá, người bán, vị trí, thông tin liên hệ và URL.
- Xử lý ngay trên trình duyệt: Vì chạy ở nơi trang được render, công cụ hoạt động tốt trên các trang động, phải cuộn nhiều.
- Làm giàu dữ liệu ở trang con: Bạn có thể thu thập dữ liệu danh sách trước, rồi mở từng tin đăng hoặc trang để lấy chi tiết phong phú hơn.
- Xuất dữ liệu tiện lợi: Excel, Google Sheets, Airtable và Notion đều là đích đến tự nhiên.
Nếu bạn muốn xem một video trước khi tự thử workflow ngay trên trình duyệt, phần hướng dẫn thực hành Thunderbit này là nơi nên bắt đầu vì nó cho thấy luồng trích xuất thực tế thay vì chỉ dừng ở mức tính năng được quảng bá:
Phù hợp nhất cho: người không chuyên kỹ thuật, đội ngũ sales, vận hành và nhà nghiên cứu muốn có kết quả nhanh.
Tín hiệu giá: Có bản dùng thử miễn phí; các gói trả phí tính theo credit. Xem bảng giá chính thức.
Chạy mẫu dữ liệu Facebook miễn phí
2. Bright Data
Bright Data là lựa chọn thiên về hạ tầng. Tài liệu của Bright Data cho biết Social Media Scraper APIs của họ bao phủ 10 nền tảng và 68 endpoint chuyên dụng, bao gồm cả Facebook. Nếu công việc của bạn là thu thập dữ liệu công khai ở quy mô lớn, một stack API được quản lý như vậy thường thực tế hơn nhiều so với việc cố gắng mở rộng một tiện ích trình duyệt hoặc scraper tự viết thủ công.
Vì sao nó xứng đáng vào danh sách rút gọn:
- Endpoint scrape mạng xã hội chuyên dụng
- Gỡ chặn và trích xuất được quản lý
- Giao đầu ra có cấu trúc cho pipeline dữ liệu
- Phù hợp hơn với các công việc giám sát và phân tích nhạy cảm về độ tin cậy
Phù hợp nhất cho: nhà phân tích, đội dữ liệu, dự án giám sát lớn và tập dữ liệu xã hội công khai ở quy mô lớn.
Tín hiệu giá: Giá thay đổi theo sản phẩm và khối lượng. Hãy kiểm tra bảng giá hiện tại của Bright Data.
3. Apify
Apify vẫn còn rất phù hợp vì nó mang lại điểm cân bằng tốt giữa template và khả năng tùy biến đầy đủ. Actor Facebook Pages Scraper của nó là một điểm khởi đầu hữu ích, trong khi nền tảng Apify rộng hơn cung cấp chạy trên cloud, lập lịch, API và không gian để mở rộng workflow nếu nhu cầu của bạn phức tạp hơn.
Vì sao nó vào danh sách:
- Actor Facebook dựng sẵn
- Chạy trên cloud và có lịch định kỳ
- Xuất dữ liệu linh hoạt và có API
- Dễ mở rộng hơn một workflow no-code thuần trình duyệt
Phù hợp nhất cho: marketer kỹ thuật, agency, đội vận hành và các công việc thu thập định kỳ trên nhiều website.
Tín hiệu giá: Gói nền tảng là trả phí và mức dùng của actor được tính riêng. Xem bảng giá Apify.
4. Nimble by Nimbleway
Nimble by Nimbleway là lựa chọn API-first cho các đội muốn gửi một URL rồi để nền tảng xử lý truy cập, render và giao dữ liệu. Nimble định vị Web Scraper API của mình như một giải pháp thu thập dữ liệu web công khai đầu-cuối, nên rất hữu ích khi Facebook scraping chỉ là một phần trong một stack dữ liệu rộng hơn.
Điều đáng để đánh giá:
- Luồng API ưu tiên URL
- Giảm gánh nặng bảo trì scraper cho đội kỹ thuật
- Phù hợp với việc trích xuất web công khai bền vững
- Hữu ích khi dữ liệu scrape đi vào sản phẩm nội bộ hoặc dashboard
Phù hợp nhất cho: đội ngũ do kỹ thuật dẫn dắt, pipeline dữ liệu sản phẩm và các tổ chức muốn trừu tượng hóa hạ tầng thay vì dùng công cụ điểm lẻ.
Tín hiệu giá: Nimble không nhấn mạnh mức giá tự phục vụ công khai trên các trang API cốt lõi, vì vậy hãy chuẩn bị cho mô hình bán hàng theo tư vấn và xác minh trực tiếp với Nimble by Nimbleway.
5. ScrapingBot
ScrapingBot là lựa chọn API tiết kiệm trong danh sách này. Nó không phải nền tảng chuyên sâu nhất cho Facebook ở đây, nhưng vẫn hợp lý cho các công việc dữ liệu công khai nhỏ hơn, khi bạn muốn có API, hỗ trợ render và mức chi phí đầu vào thấp hơn hạ tầng scrape cấp doanh nghiệp.
Phù hợp ở đâu:
- Thu thập dữ liệu công khai đơn giản dựa trên API
- Giá khởi điểm thấp hơn
- Bao gồm render và xử lý proxy
- Hợp hơn cho bản mẫu và các lần kéo định kỳ nhẹ so với các chương trình tình báo dữ liệu lớn
Phù hợp nhất cho: startup, doanh nghiệp nhỏ và lập trình viên thử các trường hợp thu thập dữ liệu trang công khai nhẹ hơn.
Tín hiệu giá: Có gói miễn phí; trang giá công khai hiện tại bắt đầu gói trả phí từ khoảng 22 USD/tháng.
6. PhantomBuster
PhantomBuster không tập trung nhiều vào hạ tầng scrape thô mà tập trung vào những gì xảy ra sau khi đã thu thập. Nếu trường hợp sử dụng của bạn là “thu thập dữ liệu, rồi kích hoạt outreach, enrichment hoặc các hành động theo sau”, PhantomBuster thường hữu ích hơn một công cụ trích xuất thuần túy vì nó được thiết kế xoay quanh tự động hóa trên cloud và các workflow hành động trình duyệt.
Vì sao các đội vẫn đưa nó vào danh sách rút gọn:
- Workflow tự động hóa dựa trên cloud
- Hữu ích cho tạo lead và vận hành GTM
- Phù hợp hơn khi scraping chỉ là một bước trong quy trình rộng hơn
- Thực dụng cho đội vận hành quan tâm đến hành động chứ không chỉ xuất dữ liệu
Phù hợp nhất cho: đội GTM, đội tăng trưởng, nhà tuyển dụng và đội vận hành muốn nối việc thu thập dữ liệu với hành động phía sau.
Tín hiệu giá: Có bản dùng thử miễn phí; các gói trả phí trên trang giá hiện tại bắt đầu từ khoảng 56 USD/tháng.
7. Octoparse
Octoparse vẫn là một trong những công cụ thu thập dữ liệu trực quan no-code tốt hơn cho người dùng muốn có workflow lặp lại và chạy định kỳ trên cloud. Nó không nhẹ như Thunderbit cho các việc Facebook một lần, nhưng lại cho người không phải lập trình viên khả năng kiểm soát rõ ràng hơn về cách logic trích xuất được xây dựng và lặp lại.
Vì sao nó vẫn phù hợp:
- Trình xây dựng workflow trực quan kiểu kéo-thả
- Trích xuất trên cloud và có lập lịch
- Tốt cho các tác vụ có cấu trúc, lặp lại nhiều lần
- Hợp hơn với nhà phân tích muốn tính lặp lại mà không cần code
Phù hợp nhất cho: nhà phân tích không chuyên kỹ thuật, đội vận hành SMB và các tác vụ thu thập lặp lại với logic workflow rõ ràng hơn.
Tín hiệu giá: Trang giá công khai của Octoparse niêm yết gói trả phí từ khoảng 119 USD/tháng.
Danh sách rút gọn theo đội ngũ
Nếu bạn đã biết workflow sẽ do kiểu đội nào phụ trách, hãy bắt đầu ở đây:
- Người vận hành đơn lẻ hoặc doanh nghiệp nhỏ: Thunderbit, ScrapingBot hoặc Octoparse
- Đội sales / GTM: Thunderbit hoặc PhantomBuster
- Nhà phân tích vận hành: Thunderbit, Apify hoặc Octoparse
- Đội tự động hóa tăng trưởng: PhantomBuster hoặc Apify
- Đội kỹ thuật dữ liệu: Bright Data, Nimble hoặc Apify

Cách chọn đúng Facebook scraper
- Chọn Thunderbit nếu tốc độ và sự đơn giản quan trọng hơn quy mô tối đa.
- Chọn Bright Data nếu bạn cần quy mô dữ liệu công khai và độ tin cậy được quản lý.
- Chọn Apify nếu bạn muốn sự linh hoạt của nền tảng và workflow dựa trên actor.
- Chọn Nimble nếu bạn muốn một lớp trừu tượng API-first với ít phải bảo trì scraper hơn.
- Chọn PhantomBuster nếu scraping chỉ là một bước trong workflow tự động hóa GTM rộng hơn.
- Chọn Octoparse nếu bạn muốn khả năng lặp lại trực quan mà không cần code.
- Chọn ScrapingBot nếu ngân sách quan trọng và công việc tương đối đơn giản.
Kết luận cuối cùng
Sự phân hóa của thị trường trong năm 2026 đã rõ hơn một năm trước rất nhiều. Thực ra bạn không phải đang chọn một “Facebook scraper tốt nhất” dùng cho mọi thứ. Bạn đang chọn một mô hình thu thập: trích xuất no-code nhanh, quy mô API được quản lý, tự động hóa trên cloud, hoặc kiểm soát workflow trực quan thực hành. Bắt đầu từ đó thì danh sách rút gọn sẽ dễ hơn nhiều.
Nếu đội của bạn muốn đi từ một trang Facebook hoặc một tin đăng Marketplace đến dữ liệu có cấu trúc dùng được nhanh nhất, Thunderbit vẫn là nơi dễ bắt đầu nhất. Nếu khối lượng hoặc yêu cầu kỹ thuật của bạn nặng hơn nhiều, Bright Data, Apify và Nimble hợp lý hơn. Nếu workflow của bạn bắt đầu bằng scrape nhưng kết thúc bằng hành động theo sau, PhantomBuster là danh sách rút gọn thông minh hơn.
Câu hỏi thường gặp
1. Công cụ thu thập dữ liệu Facebook nào dễ nhất cho người không chuyên kỹ thuật?
Thunderbit là điểm khởi đầu dễ nhất cho hầu hết người không chuyên kỹ thuật vì nó chạy ngay trong trình duyệt, tự động gợi ý trường và xuất dữ liệu nhanh mà không cần code.
2. Công cụ thu thập dữ liệu Facebook nào tốt nhất cho việc thu thập dữ liệu công khai ở quy mô lớn?
Bright Data là lựa chọn hạ tầng mạnh nhất trong danh sách này khi công việc là thu thập dữ liệu xã hội công khai ở quy mô lớn và độ tin cậy quan trọng hơn sự dễ dùng.
3. Nếu tôi cần vừa scrape vừa tự động hóa hành động theo sau thì sao?
PhantomBuster là lựa chọn phù hợp hơn khi việc thu thập dữ liệu chỉ là một bước trong workflow tạo lead hoặc GTM rộng hơn.
4. Thu thập dữ liệu Facebook vẫn còn khó trong năm 2026 không?
Có. Nội dung động, tường đăng nhập, giới hạn tốc độ, hệ thống chống bot và rủi ro tài khoản vẫn khiến Facebook khó hơn nhiều so với các website công khai đơn giản.
5. Các đội nên nghĩ về tuân thủ như thế nào?
Hãy tập trung vào dữ liệu công khai, dùng tốc độ hợp lý, tránh lạm dụng thông tin đăng nhập và xem lại điều khoản nền tảng cũng như các quy định quyền riêng tư áp dụng trước khi mở rộng workflow.
Đọc thêm:
- Cách tìm bài viết Facebook theo từ khóa (Hướng dẫn 2025)
- 55 thống kê Facebook quan trọng bạn cần biết
- Cách thu thập dữ liệu bất kỳ website nào bằng AI
Dùng thử Thunderbit cho việc thu thập dữ liệu Facebook & Marketplace Get Started Free




