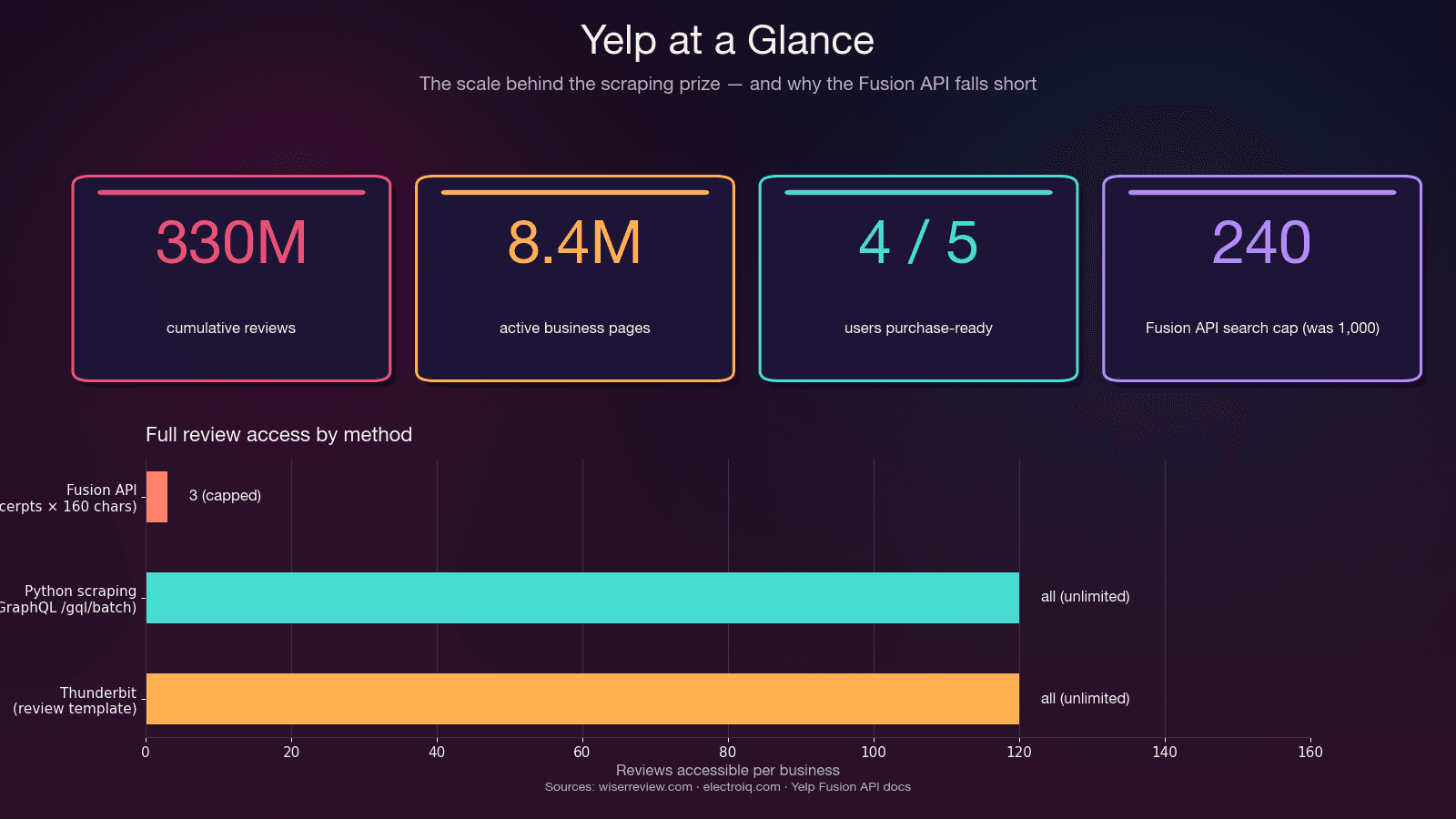
Yelp hiện có trên — và việc kéo dữ liệu đó về một định dạng có thể dùng được chưa bao giờ khó đến vậy. Đợt siết chặt chống bot của Yelp trong giai đoạn 2024–2025 đã âm thầm làm hỏng phần lớn các hướng dẫn scrape Yelp bằng Python hiện có.
Nếu gần đây bạn từng thử chạy một Yelp scraper rồi gặp hàng loạt lỗi 403, phản hồi HTML trống, hoặc CAPTCHA vốn nửa năm trước còn chưa từng xuất hiện, thì bạn không hề tự nghĩ ra đâu. Yelp giờ dùng TLS/JA3 fingerprinting, xoay vòng tên lớp CSS bị làm rối, và chấm điểm độ tin cậy IP rất gắt — nghĩa là cách làm cũ requests + BeautifulSoup mà mọi tutorial vẫn khuyên dùng sẽ chết ngay ở request đầu tiên. Tôi đã dành nhiều tuần để test các cách tiếp cận khác nhau trên hệ thống hiện tại của Yelp, và bài hướng dẫn này sẽ đi qua tất cả những gì thực sự hoạt động trong 2025: API Fusion chính thức (và lý do vì sao nó có lẽ vẫn chưa đủ), một quy trình scrape bằng Python hoàn chỉnh với chiến lược chống chặn nhiều lớp, và một giải pháp no-code chỉ với 2 cú nhấp bằng cho những ai chỉ muốn lấy dữ liệu mà không muốn sa lầy vào debug.
Vì Sao Nên Scrape Yelp bằng Python (và Ai Thực Sự Hưởng Lợi)
Trước khi viết bất kỳ dòng code nào, hãy tự hỏi: dữ liệu Yelp thực sự phục vụ bài toán kinh doanh nào? Nền tảng này không chỉ là một website đánh giá nhà hàng — mà thực chất là một cơ sở dữ liệu sống về doanh nghiệp địa phương với thông tin liên hệ có cấu trúc, điểm đánh giá, danh mục ngành nghề, giờ mở cửa, và hàng trăm triệu bài review của khách hàng.
Đây là những nhóm người hưởng lợi nhiều nhất và họ thường trích xuất gì:
| Trường hợp sử dụng | Trường dữ liệu chính | Vì sao quan trọng |
|---|---|---|
| Bán hàng & tạo lead | Tên doanh nghiệp, số điện thoại, website, địa chỉ, ngành, điểm đánh giá | Xây dựng danh sách khách hàng tiềm năng có mục tiêu cho SMB địa phương — 4/5 người dùng Yelp sẵn sàng mua hàng ngay khi truy cập |
| Phân tích đối thủ | Bài review, số sao, số lượng review, cảm xúc | Theo dõi danh tiếng đối thủ, phát hiện lỗ hổng dịch vụ, bám xu hướng |
| Nghiên cứu thị trường & NLP | Nội dung review đầy đủ, ngày tháng, metadata người đánh giá | Phân tích cảm xúc, mô hình chủ đề — review Yelp là một trong những bộ dữ liệu NLP được dùng nhiều nhất trong nghiên cứu học thuật |
| Bất động sản & chọn vị trí | Mật độ doanh nghiệp, mix danh mục, chất lượng review theo khu vực | Chọn địa điểm cho chuỗi cửa hàng và bán lẻ — Yelp còn bán Location Intelligence như một sản phẩm B2B được cấp phép cho đúng nhu cầu này |
| Ecommerce & vận hành | Tín hiệu giá, khiếu nại của khách, giờ phục vụ | Theo dõi cách đối thủ được đánh giá, nhận diện mô hình vận hành |
Điểm chung ở đây là: mục tiêu thật sự là dữ liệu có cấu trúc, còn Python chỉ là một công cụ để lấy nó. Có người cần quyền kiểm soát lập trình toàn diện. Có người chỉ cần một bảng Excel chứa thông tin liên hệ của thợ sửa ống nước ở Austin. Bài này sẽ bao trùm cả hai hướng.
Yelp Fusion API vs. Scrape Yelp bằng Python: Nên Chọn Cách Nào?
Phần lớn bài viết bỏ qua bước quyết định này và nhảy thẳng vào code, không hề đánh giá xem chính thức (nay được đổi tên thành "Yelp Places API") có đủ dùng hay không. Theo kinh nghiệm của tôi, việc đánh giá này tiết kiệm hàng giờ công vô ích — vì API rất tốt cho một số nhu cầu, nhưng lại hoàn toàn không đủ cho những nhu cầu khác.
Fusion API Thực Sự Cung Cấp Gì?
Fusion API cung cấp tìm kiếm doanh nghiệp có cấu trúc, chi tiết doanh nghiệp, autocomplete và một endpoint cho review. Nó hợp lệ, có tài liệu rõ ràng, và không đòi hỏi bạn phải “nhảy múa” để vượt anti-bot.
Nhưng mọi thứ vỡ ra ở endpoint review. Đây là điều chính nhân viên Yelp cũng đã xác nhận trên GitHub:
"Yelp API không trả về toàn bộ nội dung review. Mặc định chỉ cung cấp ba đoạn trích review, mỗi đoạn 160 ký tự." —
Đó không phải lỗi — mà là thiết kế có chủ đích. API chỉ giới hạn tối đa 3 đoạn trích review (7 ở gói Premium), mỗi đoạn bị cắt còn khoảng 160 ký tự. Không có metadata review (phiếu hữu ích/hài hước/ngầu), không có lịch sử người đánh giá, không có phản hồi của chủ doanh nghiệp. Và sau tháng 5/2023 — từ mức 5.000 trước đó. Giá khởi điểm là .
Khung Quyết Định
| Yếu tố | Yelp Fusion API | Scrape bằng Python | Thunderbit (No-Code) |
|---|---|---|---|
| Review đầy đủ | ❌ Chỉ 3 đoạn trích (~160 ký tự mỗi đoạn) | ✅ Tất cả review qua GraphQL | ✅ Tất cả review hiển thị |
| Giới hạn tốc độ | 300–500/ngày (mới); 5.000 (cũ) | Tự quản lý (ngân sách proxy) | Dựa trên credit |
| Công sức thiết lập | ~15 phút (API key + SDK) | Vài giờ đến vài ngày | ~2 phút |
| Trường dữ liệu doanh nghiệp | ~20 trường có cấu trúc | Không giới hạn (parse HTML/JSON) | Trường gợi ý bằng AI |
| Xử lý anti-bot | N/A (được cấp quyền) | Phải tự xây | Tự động xử lý |
| Rủi ro pháp lý | ✅ Được cấp phép | ⚠️ Vùng xám theo ToS | ⚠️ Tương tự scraping |
| Chi phí | Tối thiểu $29/tháng | Miễn phí (+ chi phí proxy $0.75–$4/GB) | Có gói miễn phí |
| Bảo trì | Thấp (API ổn định) | Cao (selector dễ hỏng, anti-bot ngày càng gắt) | Thấp (AI tự thích ứng lại) |
Dùng Fusion API nếu: bạn chỉ cần thông tin doanh nghiệp cơ bản, tra cứu quy mô nhỏ, hoặc một tích hợp được cấp phép — và 3 đoạn review ngắn là đủ.
Dùng scrape bằng Python nếu: bạn cần toàn bộ nội dung review, tất cả review của một doanh nghiệp, metadata review, hơn 240 kết quả mỗi lần tìm kiếm, hoặc ngân sách của bạn thấp hơn $29/tháng.
Dùng Thunderbit nếu: bạn muốn có dữ liệu thật nhanh mà không phải viết hay bảo trì code. Phần no-code bên dưới sẽ nói rõ hơn.
Lối Tắt No-Code: Scrape Yelp bằng Thunderbit (Không Cần Python)
Trước khi đi sâu vào Python, đây là con đường nhanh nhất cho những ai mục tiêu thật sự là dữ liệu chứ không phải bài tập lập trình. Mọi bài hướng dẫn của đối thủ đều mặc định bạn đã biết Python, nhưng trong công việc của tôi tại Thunderbit, tôi thấy rất nhiều người tìm kiếm "scrape Yelp" thực ra là nhân viên sales, quản lý vận hành, và chủ doanh nghiệp nhỏ — họ chỉ muốn một bảng tính chứa doanh nghiệp địa phương, chứ không phải một khóa học cấp tốc về TLS fingerprinting.
đã có sẵn các template Yelp dựng sẵn:
- — trích xuất tên doanh nghiệp, điểm đánh giá, thông tin liên hệ, địa chỉ, giờ mở cửa, danh mục
- — trích xuất tên người đánh giá, nội dung review, điểm số, ngày tháng, vị trí người đánh giá
Cách Hoạt Động Trong Thực Tế
- Mở một trang kết quả tìm kiếm Yelp hoặc trang doanh nghiệp trong Chrome
- Nhấp AI Suggest Fields trong — AI sẽ đọc trang và đề xuất các cột (tên doanh nghiệp, điểm số, số lượng review, khoảng giá, danh mục, địa chỉ, số điện thoại, URL)
- Nhấp Scrape — xong
Với các template Yelp dựng sẵn thì còn đơn giản hơn: mở template, nhấp Scrape.
Subpage scraping tự động xử lý vòng mở rộng dữ liệu — bắt đầu từ trang kết quả tìm kiếm Yelp, bật subpage scraping, và Thunderbit sẽ lần lượt vào từng trang doanh nghiệp để lấy giờ mở cửa, review đầy đủ, website, ảnh, và tiện ích. Không cần thiết lập thêm.
Phân trang là tự động — cả kiểu nhấp và kiểu cuộn đều được xử lý sẵn. (Muốn hiểu sâu hơn, xem của chúng tôi.)
Xuất dữ liệu miễn phí ở mọi gói — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Không cần pandas, không cần code ghi file CSV.
So Sánh Thời Gian
| Thời gian | Python Scraper | Thunderbit |
|---|---|---|
| Lần chạy đầu tiên | Vài giờ đến vài ngày (viết selector, xử lý phân trang, proxy, retry logic) | ~30 giây với template Yelp dựng sẵn |
| Khi Yelp đổi markup | Viết lại selector thủ công | Nhấn lại AI Suggest Fields — tự thích ứng lại |
| Khi IP bị chặn | Debug, xoay vòng proxy, test lại | Chế độ cloud xử lý xoay IP |
| Xuất sang Google Sheets | Viết OAuth + glue code bằng pandas | Một cú nhấp, miễn phí |
Nếu bạn thử Thunderbit trước và thấy nó đáp ứng đủ nhu cầu, bạn có thể bỏ qua phần còn lại của bài này. Nếu bạn cần kiểm soát lập trình hoàn toàn, trường dữ liệu tùy chỉnh, hoặc quy mô lớn hơn vài nghìn bản ghi mỗi tháng — hãy đọc tiếp.
Nên Chọn Thư Viện Python Nào Để Scrape Yelp?
"Nên dùng Scrapy, BS4+requests, hay Selenium?" là một trong những câu hỏi phổ biến nhất trong các thread r/webscraping về Yelp. Nhưng hầu như tutorial nào cũng chỉ chọn một thư viện rồi đi tiếp, không giải thích vì sao. Đây là bức tranh thật.
Thực Tế Năm 2025: requests + BeautifulSoup Đã Hỏng Với Yelp
Stack mà mọi tutorial Yelp kinh điển khuyên dùng — pip install requests beautifulsoup4 — sẽ bị chặn ngay ở request đầu tiên trong 2025. Không phải request thứ 50. Là request đầu tiên.
Lý do: thư viện requests của Python mang một TLS/JA3 fingerprint không khớp với bất kỳ trình duyệt thật nào. Lớp chống bot của Yelp phát hiện nó ở tầng bắt tay TLS, trước cả khi User-Agent được đọc. Tôi đã test đi test lại — IP mới, header giống thật, delay ngẫu nhiên — nhưng vẫn dính 403 Forbidden ngay lập tức với requests thuần.
Bảng Quyết Định Thư Viện
| Thư viện | Phù hợp nhất cho | Xử lý JS? | Chống bot? | Độ khó học | Tốc độ |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Rất thấp | Nhanh (cho tới khi bị chặn) | |
httpx async + parsel | Scrape không đồng bộ quy mô lớn | ❌ | ❌ | Thấp | Rất nhanh |
curl_cffi + parsel | Riêng cho Yelp: giả lập TLS | ❌ | ✅ TLS/JA3/HTTP2 | Thấp | Rất nhanh |
Scrapy 2.14 | Pipeline crawl đầy đủ với phân trang | Một phần (qua scrapy-playwright) | AutoThrottle, retry middleware | Trung bình-cao | Nhanh |
Selenium 4.43 / Playwright 1.58 | Trang nặng JS, workaround CAPTCHA | ✅ | Một phần | Trung bình | Chậm (~10–30 trang/phút) |
| Thunderbit | Người không biết code, cần trích xuất nhanh | ✅ (trình duyệt) | Tích hợp sẵn (Cloud mode) | Rất thấp | Nhanh |
“Bước Ngoặt” curl_cffi
Thư viện đã thay đổi quy trình scrape Yelp của tôi là — một Python binding cho curl-impersonate. Nó tạo ra đúng fingerprint TLS/JA3 + HTTP/2 như Chrome thật, và API của nó dùng thay thế trực tiếp cho requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Chỉ một thay đổi này — from curl_cffi import requests cộng với impersonate="chrome131" — đã vượt qua của Yelp mà không cần khởi chạy trình duyệt. Trong các thử nghiệm của tôi, nó tạo ra khác biệt giữa lỗi 403 ngay lập tức và phản hồi 200 sạch sẽ.
Stack tôi khuyên dùng cho Yelp trong 2025: curl_cffi + parsel + jmespath + residential proxy. Nếu bạn cần một pipeline crawl hoàn chỉnh có lịch chạy, hãy bọc nó trong Scrapy 2.14 với downloader middleware dựa trên curl_cffi.
Thiết Lập Môi Trường Python Để Scrape Yelp
- Độ khó: Trung bình
- Thời gian cần thiết: ~15 phút để cài đặt, 1–2 giờ để có scraper hoạt động
- Bạn cần gì: Python 3.10+ (khuyên dùng 3.12), terminal, và tùy chọn là một nhà cung cấp residential proxy
Bước 1: Tạo Virtual Environment và Cài Package
1python3.12 -m venv .venv
2source .venv/bin/activate # Trên Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasChức năng của từng package:
curl_cffi— gửi HTTP request với TLS fingerprint của Chrome (bypass anti-bot)parsel— selector CSS/XPath để phân tích HTML (cùng engine với Scrapy, nhưng nhẹ hơn)jmespath— truy vấn JSON theo kiểu khai báo (gọn hơn truy cập dict lồng nhau cho JSON nhúng của Yelp)pandas— xuất dữ liệu ra CSV/Excel
Tùy chọn nhưng hữu ích:
1pip install fake-useragent # Lưu ý: repo đã được lưu trữ từ tháng 4/2026 nhưng vẫn cài đượcHướng Dẫn Từng Bước: Cách Scrape Yelp bằng Python
Đây là phần hướng dẫn cốt lõi. Ý tưởng quan trọng giúp mọi thứ bền vững hơn: bỏ qua CSS selector, lấy JSON ẩn thay vào đó. Yelp làm rối tên lớp CSS ở thời điểm build (y-css-14xwok2 tuần này, y-css-hcq7b9 tuần sau), nên scraper nào bám vào chúng sẽ hỏng chỉ sau vài tuần. Các payload JSON nhúng — application/ld+json schema và react-root-props — lại ổn định.
Bước 2: Scrape Kết Quả Tìm Kiếm Yelp
URL tìm kiếm Yelp có cấu trúc khá dễ đoán: https://www.yelp.com/search?find_desc={term}&find_loc={location}. Dữ liệu kết quả tìm kiếm được nhúng trong thẻ <script data-id="react-root-props"> dưới dạng JSON — chứ không phải nằm trong mớ CSS class hỗn độn.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Bị chặn ở trang {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"Không tìm thấy react-root-props ở trang {page} — có thể là block mềm")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsBạn sẽ nhận lại một danh sách dict chứa tên doanh nghiệp, URL, điểm đánh giá, và số lượng review. Nếu react-root-props không có trong phản hồi, rất có thể bạn đã bị đưa một “block shell” — hãy đổi IP và thử lại.
Header Cookie: intl_splash=false là cách xử lý tiêu chuẩn cho trang chuyển vùng quốc gia của Yelp. Nếu thiếu nó, IP ngoài Mỹ sẽ gặp trang splash trông như block mềm nhưng thực ra không hẳn.
Bước 3: Scrape Trang Doanh Nghiệp Yelp
Mỗi URL doanh nghiệp từ kết quả tìm kiếm sẽ dẫn tới trang chi tiết có dữ liệu phong phú hơn. Điểm trích xuất ổn định nhất là khối <script type="application/ld+json"> — nó chứa dữ liệu schema.org có cấu trúc mà Yelp duy trì vì SEO và không làm rối nó.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}Giá trị meta[name="yelp-biz-id"] là business ID đã mã hóa mà bạn sẽ cần cho endpoint review. Hãy lấy nó ở đây — bạn sẽ dùng ở bước tiếp theo.
Bước 4: Scrape Review Yelp với Phân Trang
Đây là lúc API Fusion lộ rõ giới hạn, còn scraping thì phát huy sức mạnh. Endpoint GraphQL nội bộ của Yelp trả về toàn bộ nội dung review, thông tin người đánh giá, ngày tháng, điểm số, và số phiếu vote — tất cả những gì API không cung cấp.
Endpoint là https://www.yelp.com/gql/batch, và nó dùng một documentId tĩnh cho operation GetBusinessReviewFeed. Phân trang hoạt động qua cursor được mã hóa base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Lấy review thất bại ở offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Đi theo cấu trúc response để trích review
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsMỗi trang trả về 10 review. Tăng offset trong cursor base64 để phân trang. Tham số sortBy chấp nhận DATE_DESC (mới nhất trước), RATING_ASC, RATING_DESC, và một số kiểu khác.
Bước 5: Xuất Dữ Liệu Yelp Đã Scrape
1import pandas as pd
2# Giả sử bạn đã thu thập xong businesses và reviews
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Hoặc lưu dưới dạng JSON để linh hoạt hơn
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Với những ai đi theo hướng no-code, Thunderbit sẽ xuất dữ liệu tương tự thẳng sang Excel, Google Sheets, Airtable, hoặc Notion — không cần pandas hay code ghi file CSV.
Sổ Tay Chống Chặn: Cách Scrape Yelp Mà Không Bị Block
Đây là phần quan trọng nhất của toàn bài. Các biện pháp chống bot của Yelp đã trở nên gắt hơn đáng kể từ cuối 2024 — đều đang được dùng. Phần lớn các hướng dẫn cũ đã lỗi thời vì được viết trước đợt siết này.
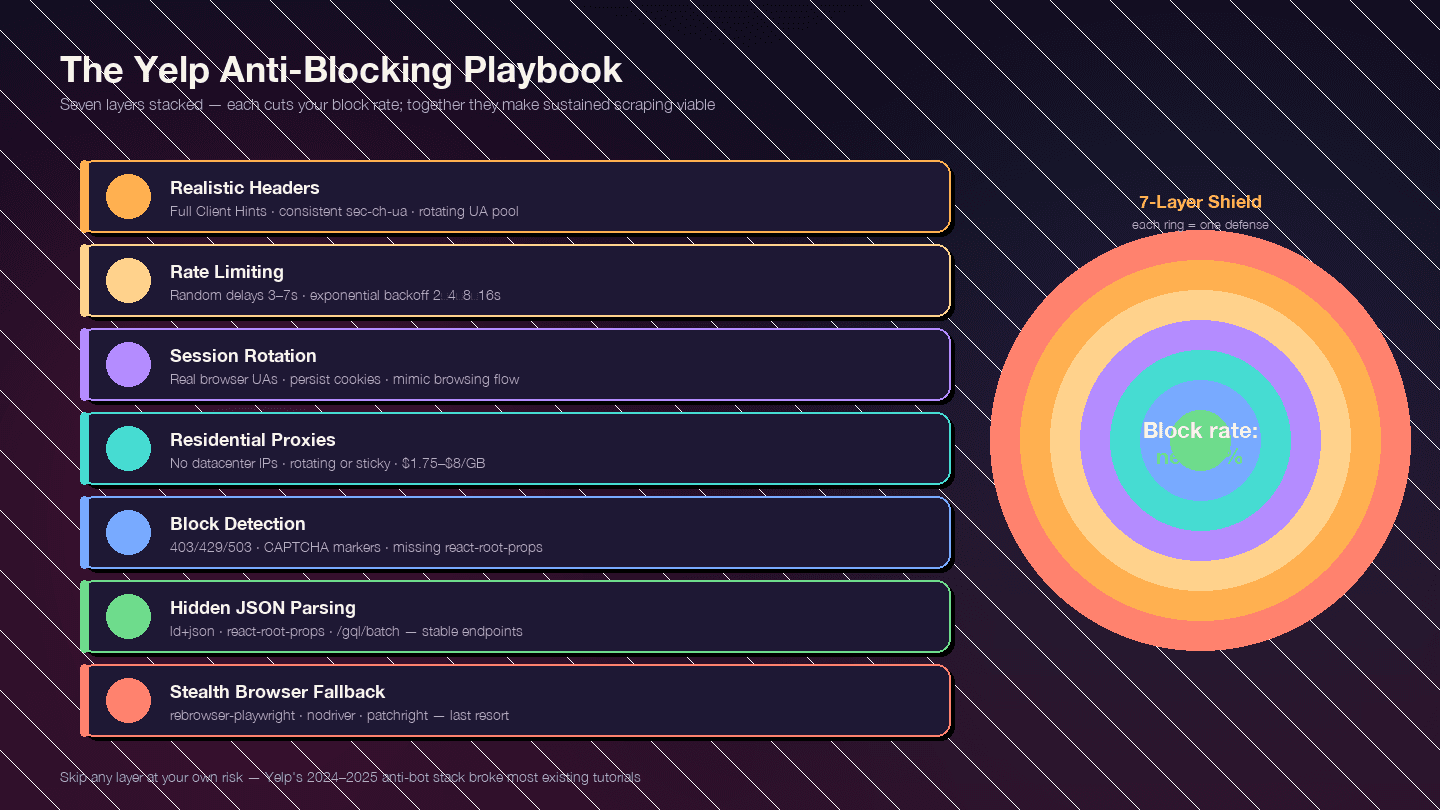
Chiến lược ở đây là nhiều lớp. Mỗi lớp sẽ giảm tỉ lệ bị chặn; kết hợp lại, chúng giúp việc scrape bền vững hơn.
Lớp 1: Header Request Giống Thật
Header mặc định của Python requests gửi User-Agent: python-requests/2.x — bị chặn ngay. Nhưng một User-Agent trông có vẻ thật vẫn chưa đủ. Yelp kiểm tra toàn bộ bộ header để xem có nhất quán hay không.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Ba lỗi khiến bạn bị gắn cờ:
- UA nói là Chrome nhưng
sec-ch-uabị thiếu hoặc mâu thuẫn với phiên bản UA sec-ch-ua-platformnói "Windows" nhưng chuỗi UA lại là macOS- Cùng một UA y hệt trên hàng nghìn request từ một IP — hãy xoay một pool gồm 10–20 chuỗi Chrome/Firefox/Safari mới
Lớp 2: Giới Hạn Tốc Độ và Delay Ngẫu Nhiên
Mẫu thời gian quá đều là dấu hiệu bất thường. Hãy thêm khoảng sleep ngẫu nhiên và cơ chế exponential backoff khi gặp lỗi.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Bị chặn sau {attempt + 1} lần thử trên {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Gặp {r.status_code}, tạm dừng {backoff:.1f}s (lần thử {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Tham số | Giá trị khuyến nghị |
|---|---|
| Nghỉ ngẫu nhiên giữa các request | random.uniform(3, 7) giây |
| Backoff khi gặp 429/403/503 | 2 → 4 → 8 → 16 giây, tối đa 5 lần thử |
| Số worker đồng thời trên mỗi IP | 1 (tuần tự theo IP; dùng proxy để chạy song song) |
| Tốc độ bền vững tối đa trên một residential IP | ~1 request / 5 giây (~12 rpm) |
Lớp 3: Xoay Vòng User-Agent và Session
Hãy xoay qua một pool các chuỗi User-Agent của trình duyệt thật. Duy trì session và cookie để mô phỏng hành vi duyệt web thực — Yelp dùng phát hiện dựa trên cookie, nên tạo session mới cho từng request cũng đáng ngờ không kém.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Thêm 5-10 chuỗi mới hơn nữa
8]Lớp 4: Xoay Vòng Proxy
Khi làm ở quy mô thực sự, bạn cần residential proxy. Datacenter proxy và proxy miễn phí không hoạt động với Yelp — lớp đánh giá IP của Yelp sẽ 403 sớm các dải IP AWS, GCP và DigitalOcean.
| Nhà cung cấp | Giá khởi điểm $/GB | Ghi chú |
|---|---|---|
| IPRoyal | $1.75/GB | Rẻ nhất; đang chạy tutorial Yelp được trích dẫn nhiều nhất |
| Decodo (trước đây là Smartproxy) | $3.20–$3.50 | Tỷ lệ GB/$ tốt nhất khi dùng ở quy mô lớn |
| Bright Data | $4.00 (PAYG) | Kho IP hơn 150M; có trang Yelp Proxies riêng |
| Oxylabs | $6.00–$8.00 | Cao cấp; hơn 10M IPs |
| Aluvia (mobile SIM) | $3.00 | IP di động nhà mạng US thật, định vị cho Yelp |
Rotating residential (đổi IP mỗi request) hoạt động tốt nhất cho crawl kết quả tìm kiếm khối lượng cao. Sticky session (giữ một IP trong 10 phút) phù hợp hơn khi bạn cần duy trì cookie xuyên suốt flow từ trang doanh nghiệp → review → phân trang.
Lớp 5: Phát Hiện và Xử Lý Block
Không phải block nào cũng giống nhau. Yelp thường trả về một shell chung kiểu "page not available" thay vì CAPTCHA, vì thế scraper ngây thơ có thể tưởng là mình đang nhận dữ liệu trong khi thực ra chỉ là phản hồi rỗng.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Nếu đây là trang search/business nhưng thiếu react-root-props,
12 # Yelp đã trả về phản hồi block bị cắt bỏ
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Tín hiệu | Ý nghĩa |
|---|---|
| HTTP 403 | Chặn cứng — IP/header/TLS đã bị đốt |
| HTTP 429 | Bị giới hạn tốc độ — thường còn cứu được bằng backoff |
| HTTP 503 | Block chung hoặc hệ thống tạm xả tải |
Chuyển hướng sang /error hoặc body có "page not available" | Block mềm |
| rỗng chỉ có | Trang challenge đang chờ JS |
captcha / g-recaptcha / px-captcha trong body | Leo thang — bắt buộc CAPTCHA |
Thiếu react-root-props trên trang listing | Phản hồi block đã bị cắt bỏ |
Lớp 6: Mẹo Parse Bền Vững — Ưu Tiên JSON Ẩn Thay Vì CSS Selector
Nhắc lại lần nữa: Yelp làm rối tên lớp CSS ở thời điểm build. Một scraper bám vào h3.y-css-14xwok2 sẽ hỏng chỉ sau vài tuần khi Yelp triển khai lại thành h3.y-css-hcq7b9.
Những payload không thay đổi:
<script type="application/ld+json">— dữ liệu có cấu trúc schema.org (tên, địa chỉ, số điện thoại, điểm đánh giá, giờ mở cửa)<script data-id="react-root-props">— toàn bộ dữ liệu kết quả tìm kiếm ở dạng JSONhttps://www.yelp.com/gql/batch— endpoint GraphQL reviews vớidocumentIdổn định
Nếu bạn đang parse CSS class, bạn đang xây trên cát. Hãy parse JSON thay vào đó.
Lớp 7: Phương Án Dự Phòng Bằng Trình Duyệt Ẩn
Chỉ chuyển sang headless browser khi curl_cffi + residential proxy không vượt qua được — thường là lúc Yelp trả về trang challenge JavaScript hoặc CAPTCHA.
Với 95% nhu cầu scrape doanh nghiệp/tìm kiếm/review, curl_cffi + JSON ẩn + residential proxy nhanh hơn, rẻ hơn và đáng tin hơn browser. Nhưng khi thật sự cần browser:
| Công cụ | Trạng thái (2025) | Ghi chú |
|---|---|---|
| rebrowser-playwright | Điểm khởi đầu được khuyên dùng | Bản vá Playwright dùng luôn, sửa rò rỉ CDP |
| nodriver | Tốt nhất cho độ ẩn danh Chrome | Kế thừa undetected-chromedriver; tránh protocol WebDriver hoàn toàn |
| patchright | Fork Playwright còn được duy trì tích cực | Vượt qua các bài test phát hiện hiện đại |
| playwright-stealth | Trưởng thành | Vá navigator.webdriver, loại HeadlessChrome khỏi UA |
Hãy bỏ Selenium thuần cho Yelp. Nó quá dễ bị fingerprint.
Yelp Fusion API vs. Scrape Python vs. Thunderbit: So Sánh Toàn Diện
| Khía cạnh | Yelp Fusion API | Scrape bằng Python | Thunderbit |
|---|---|---|---|
| Full review text | ❌ 3 đoạn trích × ~160 ký tự | ✅ Không giới hạn (GraphQL) | ✅ Template review dựng sẵn |
| Metadata review (vote, phản hồi của chủ) | ❌ | ✅ | ✅ Qua các trường gợi ý bằng AI |
| Ảnh | ❌ (0 ở Base) | ✅ Không giới hạn | ✅ |
| Số kết quả tối đa mỗi tìm kiếm | 240 (trước 2024 là 1.000) | Không giới hạn (có phân trang) | Không giới hạn |
| Giới hạn hằng ngày | 300–500 (mới) / 5.000 (cũ) | Chỉ phụ thuộc vào ngân sách proxy | Dựa trên credit (3.000/tháng ở Pro) |
| Công sức thiết lập | ~15 phút | Vài giờ đến vài ngày | ~2 phút |
| Xử lý anti-bot | N/A | Vấn đề của bạn | Đã xử lý (Cloud mode) |
| Rủi ro pháp lý | Thấp (được cấp phép) | Trung bình (vùng xám ToS) | Trung bình (giống scraping) |
| Chi phí (khởi điểm) | $29/tháng | ~proxy $0.75–$4/GB + công phát triển | Gói miễn phí |
| Chi phí (dùng nặng) | $643+/tháng | $50–$500/tháng proxy + công dev | $38–$49/tháng |
| Xuất dữ liệu | JSON | CSV/JSON (bạn tự viết) | Excel / Sheets / Airtable / Notion — miễn phí |
| Bảo trì | Thấp | Cao (selector dễ hỏng, anti-bot ngày càng gắt) | Thấp (AI tự thích ứng lại) |
Mẹo Pháp Lý và Đạo Đức Khi Scrape Yelp
Tôi không phải luật sư, và đây không phải tư vấn pháp lý. Nhưng bối cảnh pháp lý đã thay đổi khá nhiều trong hai năm qua, nên bạn nên nắm những nguyên tắc cơ bản trước khi đầu tư thời gian vào một dự án scrape Yelp.
Điều khoản dịch vụ của Yelp nói gì: Bản nêu rõ cấm dùng "bất kỳ robot, spider... hay thiết bị tự động nào khác" để "truy cập, lấy, sao chép, scrape hoặc index bất kỳ phần nào của Dịch vụ." Nó cũng bổ sung ngôn ngữ liên quan đến "AI Technologies và/hoặc các công cụ tự động khác."
: "Yelp không cho phép bất kỳ hình thức scraping nào trên site."
robots.txt nói gì: của Yelp có wildcard User-agent: * / Disallow: / và chặn riêng GPTBot, ClaudeBot, PerplexityBot, CCBot, và Meta-ExternalAgent. Chỉ Googlebot, Bingbot và vài crawler mạng xã hội được whitelist.
Tiền lệ pháp lý đáng chú ý: Trong vụ (N.D. Cal. tháng 1/2024), tòa kết luận rằng scraping dữ liệu công khai khi đã đăng xuất không vi phạm ToS của Meta. Điểm phân biệt then chốt là: dữ liệu công khai khi đăng xuất vs. dữ liệu khi đăng nhập. Vụ cho thấy việc scrape dữ liệu công khai có lẽ không vi phạm CFAA, nhưng hiQ vẫn thua ở các cáo buộc dân sự cấp bang (trespass to chattels, misappropriation) và bị phán quyết bồi thường $500,000.
Nguyên tắc thực tế:
- Chỉ scrape những trang công khai, ở trạng thái đã đăng xuất
- Giới hạn tốc độ request của bạn (delay trong bài này cũng là giới hạn tốc độ mang tính đạo đức)
- Không bán lại raw review text gắn với tên người dùng — hãy tôn trọng quyền riêng tư của người đánh giá
- Tuân thủ luật bảo vệ dữ liệu địa phương (CCPA, GDPR)
- Đừng đăng nhập để scrape — như vậy là vượt qua ranh giới cấp phép
- Xem thông tin doanh nghiệp (tên/địa chỉ/số điện thoại/điểm đánh giá) là dữ liệu факт công khai; còn review text thì nhạy cảm hơn
Hãy tham khảo chuyên gia pháp lý cho tình huống cụ thể của bạn.
Kết Luận
Ba con đường, một mục tiêu.
Yelp Fusion API là lựa chọn được cấp phép, ít phải bảo trì — nhưng bị giới hạn ở 3 đoạn review và giá khởi điểm $29/tháng. Scrape bằng Python cho bạn quyền kiểm soát toàn bộ dữ liệu trên Yelp, nhưng đòi hỏi đầu tư nghiêm túc: curl_cffi để giả lập TLS, residential proxy, delay ngẫu nhiên, parse JSON ẩn, và bảo trì liên tục khi lớp phòng thủ của Yelp thay đổi. Thunderbit đưa bạn từ "tôi cần dữ liệu Yelp" tới "đây là spreadsheet của tôi" chỉ trong khoảng 30 giây, không cần code, không cần cấu hình proxy.
Những yếu tố chống chặn thực sự hiệu quả trong 2025 là: header giống thật với đầy đủ Client Hints, curl_cffi để giả lập TLS fingerprint, delay ngẫu nhiên với exponential backoff, xoay vòng residential proxy, và trên hết là parse JSON ẩn (application/ld+json và react-root-props) thay vì bám vào CSS selector mong manh.
Chưa chắc con đường nào hợp với bạn? Hãy thử trước . Nếu nó đáp ứng nhu cầu, bạn đã tiết kiệm được hàng giờ. Nếu bạn cần kiểm soát nhiều hơn — pipeline lập trình đầy đủ, trường tùy chỉnh, tích hợp CRM chặt chẽ — phần hướng dẫn Python ở trên đã bao phủ đủ. Và nếu muốn nhìn rộng hơn về bức tranh công cụ scraping, hãy xem bài tổng hợp hoặc hướng dẫn .
Câu Hỏi Thường Gặp
Tôi có thể scrape Yelp miễn phí bằng Python không?
Có — bằng các thư viện miễn phí như curl_cffi, parsel, và jmespath. Nhưng ở bất kỳ quy mô thực tế nào (hơn vài chục trang), bạn sẽ cần residential proxy trả phí, bắt đầu khoảng . Thunderbit cũng có gói miễn phí với 6 trang/tháng cho nhu cầu trích xuất nhanh, không cần code.
Yelp có chặn scraper không?
Có, và khá mạnh tay. Yelp dùng . requests thuần sẽ bị chặn ngay ở lần chạm đầu tiên. Chiến lược chống chặn nhiều lớp trong bài này — curl_cffi để giả lập TLS, header giống thật, delay ngẫu nhiên, và residential proxy — là cách hoạt động trong 2025.
Yelp Fusion API có tốt hơn scraping không?
Tùy nhu cầu của bạn. API được cấp phép và ít rủi ro, nhưng chỉ trả về , giới hạn kết quả tìm kiếm ở 240, và giá khởi điểm $29/tháng. Nếu bạn cần toàn bộ nội dung review, metadata review, hoặc hơn vài trăm bản ghi mỗi ngày, scraping là lựa chọn duy nhất.
Làm sao để scrape review Yelp bằng Python?
Dùng curl_cffi với impersonate="chrome131" để lấy trang doanh nghiệp, trích business ID đã mã hóa từ <meta name="yelp-biz-id">, rồi POST tới https://www.yelp.com/gql/batch với operation GetBusinessReviewFeed và phân trang qua cursor after mã hóa base64. Phần code từng bước nằm ở mục hướng dẫn phía trên. Repo cũng là một tài liệu tham khảo tốt.
Tôi có thể scrape Yelp mà không cần code không?
Có — có sẵn template và . Mở trang Yelp, nhấp AI Suggest Fields, rồi nhấp Scrape. Xuất sang Google Sheets, Excel, Airtable, và Notion đều miễn phí ở mọi gói, kể cả gói miễn phí.
Tìm hiểu thêm