Hầu hết các hướng dẫn scrape eBay chỉ “sống” được chừng ba tháng. Tôi biết điều đó vì đội ngũ Thunderbit đã chứng kiến không ít developer liên tục đụng phải đoạn code hỏng, CSS selector lỗi thời và những repo GitHub “có vẻ chạy được” nhưng thực ra đã chết ngầm từ hai lần eBay đổi giao diện trước.
eBay hiện có — là bộ dữ liệu định giá long-tail lớn nhất trên web mở, chỉ sau Amazon. Nguồn dữ liệu này hỗ trợ đủ mọi thứ, từ định giá cho reseller đến phân tích cạnh tranh. Nhưng để lấy được dữ liệu đó theo cách lập trình lại là một mục tiêu luôn thay đổi: frontend của eBay chạy trên React nên class CSS đổi xoành xoạch, A/B test khiến mỗi người dùng nhìn thấy một cấu trúc DOM khác nhau, và Akamai Bot Manager luôn đứng giữa bạn và HTML. Bài viết này sẽ đưa cho bạn mã Python có thể dùng ngay hôm nay, giải thích vì sao scraper hay hỏng để bạn xây được công cụ bền hơn, so sánh thẳng thắn giữa eBay API và scraping, đồng thời giới thiệu một lối thoát không cần code khi Python không đáng để tốn công thiết lập.
Scrape eBay bằng Python nghĩa là gì?
Scrape eBay bằng Python tức là viết script để tự động tải trang web eBay, phân tích HTML (hoặc JSON ẩn bên trong), rồi trích xuất dữ liệu có cấu trúc — như tiêu đề, giá, thông tin người bán, ngày bán, chi tiết biến thể — sang định dạng bạn có thể dùng được, chẳng hạn CSV, spreadsheet hoặc database.
Bạn có thể scrape nhiều loại trang eBay khác nhau:
- Trang kết quả tìm kiếm (ví dụ: toàn bộ listing “AirPods Pro”)
- Trang chi tiết sản phẩm (thông số đầy đủ, hình ảnh, thông tin người bán)
- Listing đã bán/đã hoàn tất (giá giao dịch thực tế và ngày bán)
- Trang hồ sơ người bán và đánh giá
Python là ngôn ngữ rất phù hợp cho việc này. Hệ sinh thái của nó — Requests, BeautifulSoup, lxml, pandas — giúp việc lấy trang, phân tích HTML và xử lý dữ liệu trở nên khá trực quan. Tuy nhiên, vẫn có một khác biệt quan trọng giữa việc scrape HTML của website và dùng API chính thức của eBay — tôi sẽ nói kỹ ngay sau đây.
Vì sao cần scrape eBay? Các ứng dụng thực tế cho đội ngũ kinh doanh
Nếu bạn đang đọc đến đây, chắc hẳn bạn đã có lý do riêng. Dù vậy, vẫn nên đặt câu chuyện này trong bối cảnh giá trị kinh doanh cụ thể, vì ROI từ dữ liệu eBay thực sự rất ấn tượng. Bain cho thấy chỉ cần trên hàng nghìn doanh nghiệp. McKinsey ước tính pricing động có thể tạo ra trong bán lẻ.
Các trường hợp sử dụng tôi thấy nhiều nhất:
| Trường hợp sử dụng | Dữ liệu cần có | Kết quả kinh doanh |
|---|---|---|
| Theo dõi giá & điều chỉnh giá bán | Giá listing đang hoạt động, phí ship, tình trạng | Định giá cạnh tranh, bảo vệ biên lợi nhuận |
| Phân tích đối thủ | Danh mục sản phẩm, khuyến mãi, điều kiện giao hàng | Định vị chiến lược, phát hiện khoảng trống danh mục |
| Nghiên cứu thị trường & phát hiện xu hướng | Tốc độ lên listing, xu hướng danh mục, mẫu nhu cầu | Xác định sản phẩm mới, dự báo nhu cầu |
| Định giá cho reseller / thẩm định | Giá đã bán, ngày bán, tình trạng | Xác định giá trị thị trường hợp lý, quyết định mua vào |
| Phân tích cảm xúc | Review, đánh giá, chính sách đổi trả | Hiểu chất lượng sản phẩm, mức độ hài lòng khách hàng |
| Tìm lead | Hồ sơ người bán, thông tin cửa hàng, dữ liệu liên hệ | Tiếp cận B2B với các seller có GMV cao |
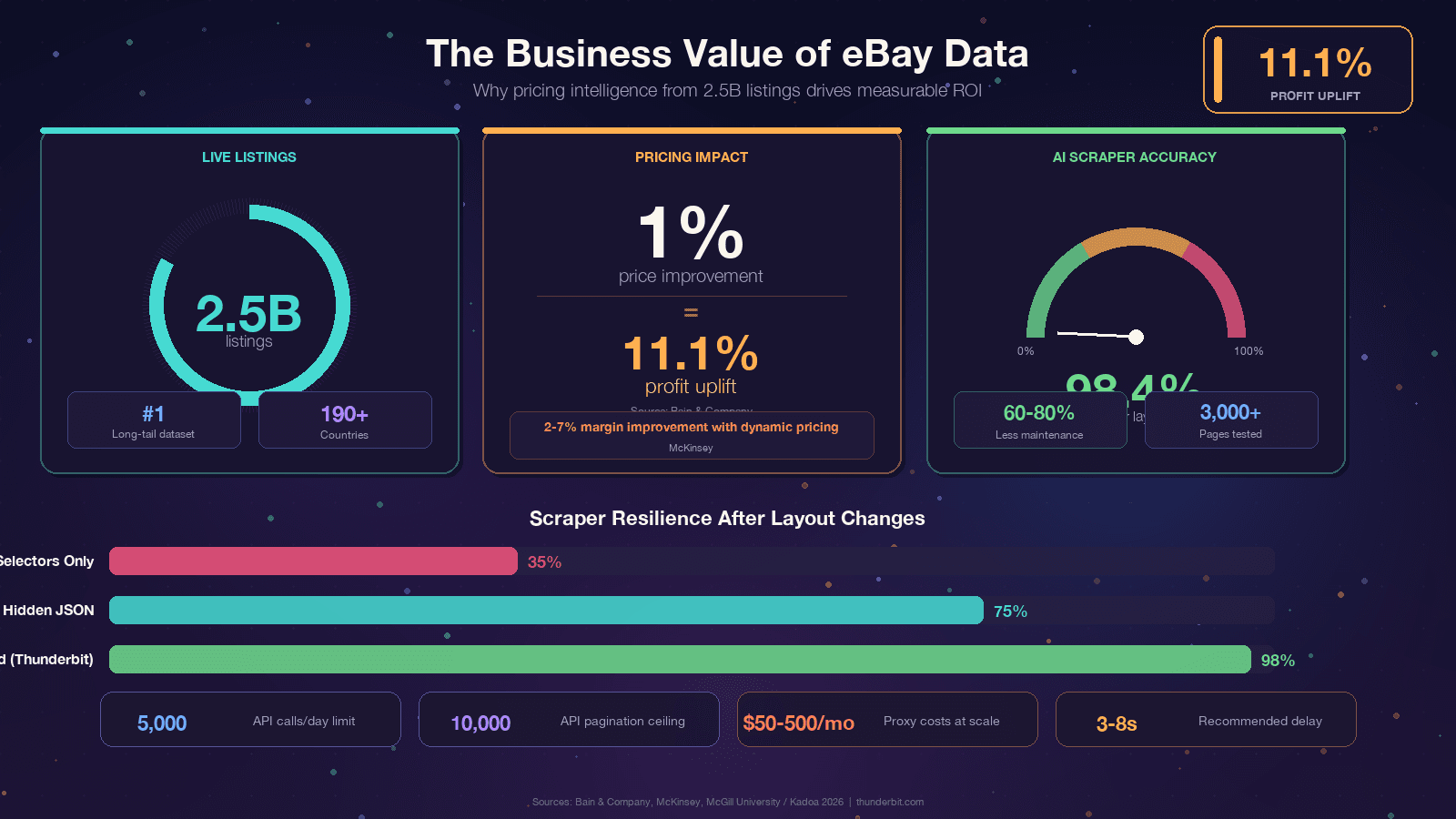
Điểm chung rất rõ: eBay có dữ liệu, nhưng dữ liệu đó đang bị khóa trong các trang web.
Scraping chính là cách biến nó thành lợi thế cạnh tranh.
eBay API chính thức vs. scrape bằng Python: Nên chọn gì?
Đây là câu hỏi mà tôi ước nhiều hướng dẫn hơn có thể trả lời một cách trung thực. eBay có API chính thức — chủ yếu là — và nhiều người dùng băn khoăn nên dùng API hay scrape trực tiếp. Câu trả lời phụ thuộc hoàn toàn vào loại dữ liệu bạn cần.
| Tiêu chí | eBay Browse/Finding API | Python Web Scraping |
|---|---|---|
| Listing đã bán/đã hoàn tất | Hạn chế — có Marketplace Insights API nhưng thường bị từ chối quyền truy cập | Truy cập đầy đủ qua tham số URL LH_Sold=1&LH_Complete=1 |
| Giới hạn gọi API | 5.000 lần/ngày ở gói cơ bản | Tự quản lý (phụ thuộc proxy) |
| Trường dữ liệu | Xác định sẵn (title, giá, category, thông tin seller cơ bản) | Bất kỳ thứ gì hiển thị trên trang (review, thông số đầy đủ, bảng biến thể) |
| Độ phức tạp thiết lập | OAuth 2.0, đăng ký app, API key | pip install + code |
| Độ ổn định | Endpoint ổn định | Hỏng khi HTML thay đổi |
| Chi phí | Có gói miễn phí, trả phí nếu dùng nhiều | Code miễn phí, nhưng quy mô lớn sẽ tốn proxy |
| Dữ liệu biến thể/MSKU | Một phần — nhiều trường hợp chỉ có parent SKU | Đầy đủ (thông qua phân tích JSON ẩn) |
| Độ sâu phân trang | Giới hạn cứng 10.000 items | Về lý thuyết là không giới hạn |
Lưu ý nhanh: Finding API cũ (có findCompletedItems) đã . Nếu bạn đang dùng ebaysdk-python hoặc bất kỳ thư viện nào gọi vào Finding module, nó hiện đã hỏng trên production.
Khuyến nghị của tôi: dùng Browse API cho các truy vấn catalog ổn định, khối lượng vừa phải trên listing đang hoạt động. Dùng Python scraping khi bạn cần giá đã bán, review, dữ liệu biến thể hoặc bất kỳ trường nào API không cung cấp. Nhiều đội ngũ thực tế dùng cả hai.
Các công cụ và thư viện cần có để scrape eBay bằng Python
Trước khi viết code, đây là bộ công cụ cần chuẩn bị. Bạn không cần headless browser cho phần lớn trang eBay — dữ liệu đã được nhúng sẵn trong HTML render từ server.
| Thư viện | Mục đích |
|---|---|
requests hoặc httpx | HTTP client để tải trang eBay |
curl_cffi | HTTP client với TLS fingerprint giống trình duyệt thật (rất quan trọng để vượt Akamai) |
beautifulsoup4 | HTML parser để trích xuất bằng CSS selector |
lxml | Backend parser nhanh cho BeautifulSoup |
jmespath | Ngôn ngữ truy vấn để phân tích JSON lồng nhau |
pandas | Xử lý dữ liệu và xuất CSV/Excel |
gspread | Tích hợp Google Sheets |
Cài tất cả trong một dòng:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadHãy dùng Python 3.11+ — pandas 3.0 yêu cầu từ 3.10 trở lên, và Python 3.11 còn giúp tăng tốc 10–60% cho các tác vụ phụ thuộc I/O.
Có một thư viện đặc biệt đáng nhắc đến: curl_cffi là bản nâng cấp có tác động lớn nhất mà một eBay scraper năm 2026 có thể có. eBay dùng , và dấu hiệu phát hiện chính của Akamai là TLS fingerprinting. requests thuần thường phát ra JA3 fingerprint “mang mùi Python” và bị chặn ngay. curl_cffi giả lập TLS handshake của trình duyệt Chrome thật, nên có thể xử lý khoảng 90% mục tiêu được bảo vệ bởi Akamai mà không cần đến headless browser.
Từng bước: Cách scrape kết quả tìm kiếm eBay bằng Python
Đây là phần hướng dẫn chính. Chúng ta sẽ scrape trang kết quả tìm kiếm eBay để lấy danh sách sản phẩm.
- Độ khó: Cơ bản – Trung bình
- Thời gian cần thiết: khoảng 30 phút để có bản scrape đầu tiên chạy được
- Bạn cần: Python 3.11+, các thư viện ở trên, terminal và một URL tìm kiếm eBay mục tiêu
Bước 1: Tạo project Python
Tạo thư mục project và cài dependencies:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasTạo một file tên scrape_ebay.py. Đó sẽ là workspace của bạn.
Bước 2: Tạo URL tìm kiếm eBay
Cấu trúc URL tìm kiếm của eBay khá đơn giản. Tham số quan trọng nhất là _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # số item mỗi trang: 60, 120 hoặc 240 (240 có thể kích hoạt bot flag)
7 "_pgn": "1", # số trang
8}
9url = f"\{base_url\}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Một số tham số hữu ích khác:
LH_BIN=1— chỉ hiển thị Buy It Now_sacat=175673— category cụ thể_sop=12— sắp xếp theo độ khớp nhất (10 = giá + ship thấp nhất, 13 = mới đăng)LH_Complete=1&LH_Sold=1— listing đã bán/đã hoàn tất (sẽ nói kỹ ở phần riêng bên dưới)
Bước 3: Gửi request và xử lý phản hồi
Đây là lúc curl_cffi phát huy tác dụng. requests.get() thuần thường sẽ bị Akamai trả về 403. Với curl_cffi, ta giả lập trình duyệt Chrome thật:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status \{r.status_code\}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: \{e\}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after \{max_retries\} retries: \{url\}")Exponential backoff kèm jitter là rất quan trọng — khoảng nghỉ cố định tự nó cũng là một dấu hiệu bot.
Bước 4: Phân tích danh sách sản phẩm trên trang tìm kiếm
eBay hiện đang trong giai đoạn chuyển đổi giữa hai layout kết quả tìm kiếm. Một scraper bền phải xử lý được cả hai:
| Trường | Layout cũ | Layout mới |
|---|---|---|
| Container của card | li.s-item | li.s-card hoặc div.su-card-container |
| Tiêu đề | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Giá | span.s-item__price | .s-card__price |
Code phân tích hỗ trợ cả hai layout:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Tiêu đề — thử cả hai layout
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Bỏ qua card placeholder ảo “Shop on eBay”
11 if not title or "Shop on eBay" in title:
12 continue
13 # Giá
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Ảnh
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Phí ship
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsBẫy card ảo ở vị trí đầu tiên là lỗi kinh điển. Nhiều trang kết quả eBay đặt li.s-item đầu tiên là placeholder ẩn với tiêu đề “Shop on eBay” và không có giá thật. Luôn luôn lọc nó ra.
Bước 5: Xử lý phân trang để scrape nhiều trang
eBay phân trang bằng tham số _pgn. Link sang trang tiếp theo dùng a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page \{page_num\}: \{url\}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No results on page \{page_num\}, stopping.")
12 break
13 all_results.extend(results)
14 print(f" Found {len(results)} listings (total: {len(all_results)})")
15 # Nghỉ hợp lý — 3 đến 8 giây với jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsKhoảng nghỉ ngẫu nhiên 3–8 giây là không tùy chọn.
eBay Akamai layer sẽ gắn cờ nếu một IP gửi liên tục hơn 1 request/giây.
Bước 6: Xuất dữ liệu scrape sang CSV hoặc JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Đã xuất {len(df)} listing sang CSV và JSON.")Bây giờ bạn sẽ có một bảng dữ liệu sạch về listing eBay. Trên máy của tôi, scrape 3 trang (360 listing) mất khoảng 45 giây, đã tính cả thời gian chờ.
Cách scrape trang chi tiết sản phẩm eBay bằng Python
Trang kết quả tìm kiếm chỉ cho bạn phần tóm tắt. Trang chi tiết sản phẩm mới là nơi chứa thứ “đáng tiền”: mô tả đầy đủ, điểm phản hồi của người bán, thông số item, carousel ảnh và dữ liệu biến thể.
Phân tích một trang listing sản phẩm đơn lẻ
Trang item của eBay nằm ở /itm/<ITEM_ID>. Cách trích xuất ổn định nhất là dùng JSON-LD — eBay nhúng block schema Product, và block này sống sót trước hầu hết các lần đổi CSS:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — đường trích xuất ổn định nhất
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. CSS fallback cho các field không có trong JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Thông số item
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemMẫu ở đây — ưu tiên JSON-LD trước, rồi mới đến CSS fallback — chính là chìa khóa để xây scraper không hỏng mỗi quý. Tôi sẽ nói thêm về điều này bên dưới.
Scrape biến thể sản phẩm eBay (dữ liệu MSKU)
Một số listing trên eBay có nhiều biến thể — màu sắc khác nhau, size khác nhau, dung lượng lưu trữ khác nhau. DOM hiển thị chỉ cho thấy khoảng giá như “$899 đến $1,099” cho tới khi người dùng bấm chọn một biến thể. Giá thực tế theo từng biến thể nằm trong một object JavaScript ẩn tên là MSKU.
Đây là một khu vực mà eBay API chỉ cung cấp dữ liệu một phần (parent SKU), nên scraping lại là cách tốt hơn.
1import re, json
2def extract_variants(html):
3 # Non-greedy là cực kỳ quan trọng — .+ tham lam sẽ nuốt cả trang
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusRegex (.+?) non-greedy chính là chỗ rất nhiều scraper eBay bị vấp. .+ greedy sẽ nuốt mọi thứ cho đến "QUANTITY" cuối cùng trên trang, khiến JSON bị méo. Tôi đã thấy lỗi này ở ít nhất ba hướng dẫn “chạy được”.
Cách scrape listing đã bán và đã hoàn tất của eBay bằng Python
Đây là trường hợp sử dụng đủ mạnh để biện minh cho việc scrape thay vì dùng API. Dữ liệu item đã bán — thứ đã thực sự giao dịch, với mức giá nào, vào ngày nào — là chuẩn vàng cho nghiên cứu thị trường, định giá reseller và thẩm định. eBay Browse API không cung cấp dữ liệu này. về mặt kỹ thuật thì có, nhưng quyền truy cập chỉ ở dạng “Limited Release” và .
Các tham số URL bạn cần là LH_Complete=1 (listing đã hoàn tất) và LH_Sold=1 (chỉ lấy item thực sự đã bán). Bạn phải truyền cả hai. Nếu chỉ truyền LH_Sold=1, ở một số category nó sẽ âm thầm quay về listing đang hoạt động — đây là lỗi phổ biến nhất trong cộng đồng.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping sold page \{page_num\}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Chỉ lấy item thực sự đã bán (giá xanh POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Listing đã hoàn tất nhưng chưa bán — bỏ qua
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Parse ngày bán
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]\{2\}\s+\d{1,2},\s*\d\{4\})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldKhác biệt quan trọng trong HTML là: item đã bán hiển thị giá màu xanh (nằm trong wrapper .POSITIVE), còn listing đã hoàn tất nhưng chưa bán thì hiển thị giá màu đỏ và gạch ngang. Luôn luôn lọc theo class .POSITIVE này.
Vì sao scraper eBay hay hỏng, và làm sao xây scraper bền hơn
Nếu scraper eBay của bạn từng ngừng hoạt động, bạn không hề đơn độc. Đây là nỗi đau số 1 trong mọi thread về scraping eBay mà tôi từng đọc. Câu hỏi không phải là liệu scraper có hỏng hay không — mà là khi nào.
Vì sao xảy ra:
- eBay dùng React rendering với class name tạo động và thay đổi mỗi khi deploy
- A/B test khiến các user khác nhau nhìn thấy cấu trúc DOM khác nhau (layout
s-item/s-cardkép chính là ví dụ sống động hiện tại) - Các lần redesign định kỳ thay đổi cấu trúc lồng HTML, dù dữ liệu vẫn giữ nguyên
- Những selector cũ như
#itemTitlevà#prcIsumđã bị loại bỏ từ nhiều năm trước nhưng vẫn xuất hiện trong các tutorial
Như viết: “Thách thức thật sự của web scraping eBay là xử lý việc thay đổi CSS selector. eBay cập nhật frontend thường xuyên, làm hỏng scraper phụ thuộc vào class name cụ thể.”
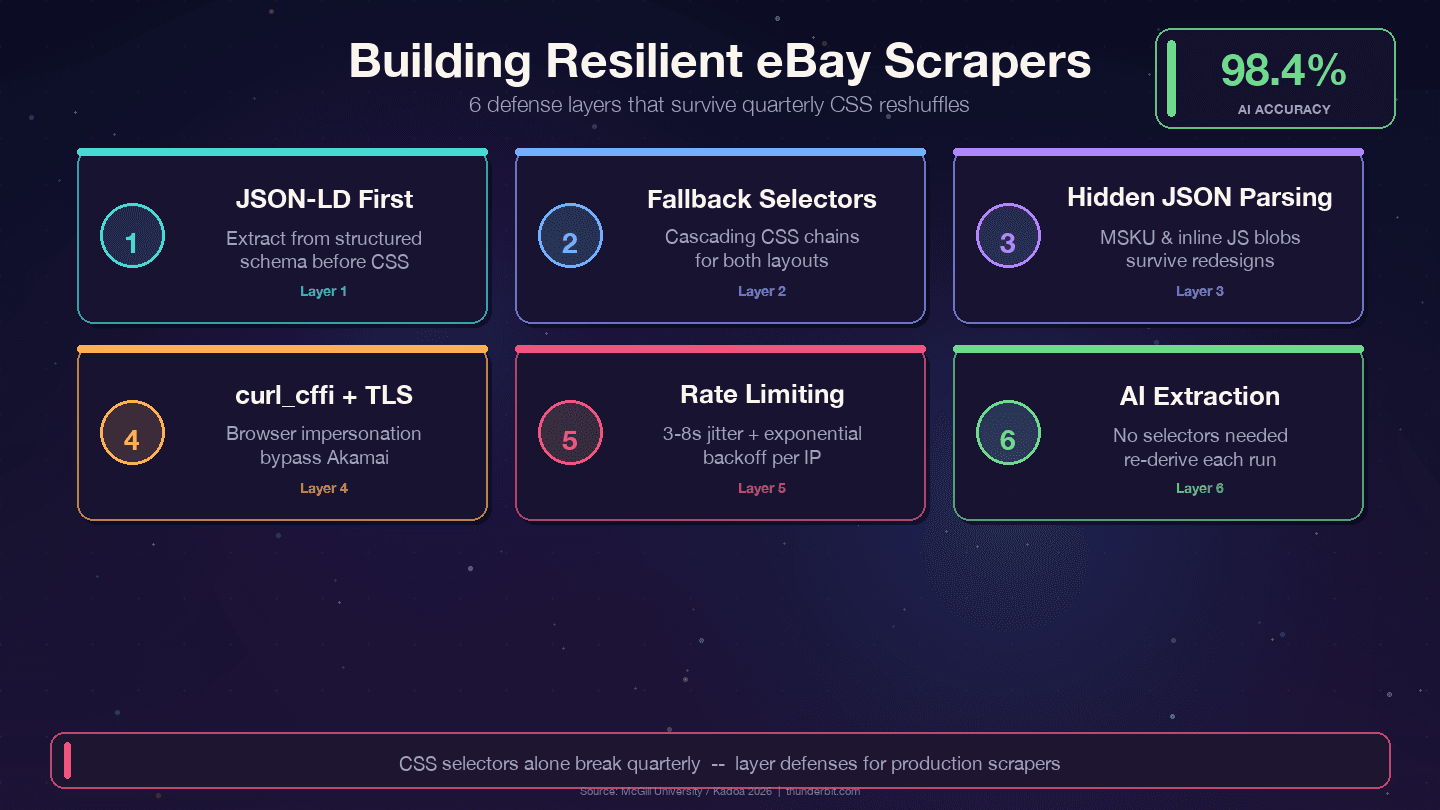
Chiến lược phòng thủ cho scraper eBay có tuổi thọ cao
Bốn chiến lược có thể sống sót qua các đợt thay đổi giao diện hàng quý của eBay:
1. Ưu tiên JSON-LD hơn CSS selector. eBay nhúng dữ liệu schema Product có cấu trúc trong mỗi trang item. Tầng dữ liệu thay đổi ít hơn tầng hiển thị rất nhiều — designer có thể refactor CSS mỗi quý, nhưng các field backend như price, name, seller lại map với internal API và hiếm khi đổi tên.
2. Dùng selector dự phòng theo tầng. Đừng bao giờ phụ thuộc vào một CSS selector duy nhất. Hãy luôn có lựa chọn thay thế:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Phân tích JSON ẩn. Object biến thể MSKU và dữ liệu JavaScript inline sống sót qua thay đổi CSS vì chúng được tạo từ phía server. Dùng regex để trích xuất từ thẻ <script> mất công hơn lúc đầu, nhưng giảm công bảo trì rất mạnh.
4. Ghi log khi selector lỗi. Thêm monitoring để biết khi nào selector ngừng match, thay vì chỉ thấy dữ liệu trống:
1if title is None:
2 print(f"WARNING: title selector failed for \{url\}")5. Dùng curl_cffi với browser impersonation. Cách này xử lý TLS fingerprinting của Akamai mà không cần headless browser.
Giải pháp thay thế bằng AI: Không cần bảo trì selector
Nếu bạn đã chán việc vá selector vài tháng một lần, có một hướng đi hoàn toàn khác. Những công cụ như dùng AI để đọc lại trang mỗi lần và tự suy ra logic trích xuất ngay lúc chạy. Một nghiên cứu của McGill University so sánh scraper dùng AI với scraper dựa trên selector trên 3.000 trang và cho thấy , trong khi các benchmark trong ngành ghi nhận .
| Cách tiếp cận | Có hỏng khi eBay đổi HTML không? | Công bảo trì |
|---|---|---|
| CSS selector hardcoded | Có, theo quý | Cao — phải vá liên tục |
| Trích xuất JSON ẩn / JSON-LD | Hiếm khi | Thấp |
| Scraping bằng AI (Thunderbit) | Không — AI suy luận lại selector mỗi lần chạy | Gần như không |
Tôi sẽ nói kỹ hơn về quy trình Thunderbit ở phần sau. Tạm thời, điều cần nhớ là: nếu bạn đang xây scraper dự định chạy trong nhiều tháng, hãy đầu tư vào chiến lược trích xuất ưu tiên JSON và selector dự phòng. Nếu bạn không muốn phải bảo trì selector, cách tiếp cận bằng AI rất đáng để cân nhắc.
Tự động hóa scrape eBay định kỳ để theo dõi giá
Một lần scrape đơn lẻ thì hữu ích. Nhưng theo dõi giá, kiểm tra tồn kho và phân tích đối thủ lại cần thu thập dữ liệu định kỳ. Hầu hết bài viết đối thủ đều có nhắc đến price monitoring như một use case, nhưng rất ít nơi chỉ cách tự động hóa thực sự.
Cách 1: Cron Job (Linux/macOS) hoặc Task Scheduler (Windows)
Đây là cách đơn giản nhất. Bọc script Python của bạn bằng cron job. Luôn dùng đường dẫn tuyệt đối tới Python trong venv — cron chạy với môi trường rất tối giản:
1crontab -e
2# Hàng ngày lúc 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Trên Windows, dùng PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TCách này đòi hỏi một máy luôn bật, và bạn phải tự quản lý proxy cùng các biện pháp chống bot.
Cách 2: Cloud Functions (serverless)
AWS Lambda hoặc Google Cloud Functions cho phép chạy scraper mà không cần server riêng. Tuy nhiên, phần thiết lập khó hơn — bạn phải đóng gói dependencies, xử lý timeout (Lambda giới hạn 15 phút), và vẫn phải quản lý proxy. Bù lại là không phải bảo trì server.
Cách 3: Lên lịch không cần code với Thunderbit
Tính năng cho phép bạn mô tả tần suất bằng ngôn ngữ tự nhiên (ví dụ: “mỗi ngày lúc 8 giờ sáng”), nhập URL eBay, rồi bấm Schedule. Nó chạy trên cloud và có sẵn cơ chế chống bot.
| Cách tiếp cận | Mức độ thiết lập | Cần server không? | Có xử lý anti-bot không? |
|---|---|---|---|
| Cron + Python script | Trung bình | Có (máy luôn bật) | Bạn tự quản lý proxy |
| Cloud function (Lambda) | Cao | Không (serverless) | Bạn tự quản lý proxy |
| Thunderbit Scheduled Scraper | Thấp (mô tả bằng lời) | Không (chạy trên cloud) | Có sẵn |
Để lưu dữ liệu scrape định kỳ, SQLite cục bộ là lựa chọn hợp lý cho lịch sử giá. Hãy dùng ON CONFLICT ... DO UPDATE (không dùng INSERT OR REPLACE, vì nó ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Không muốn code? Cách scrape eBay trong 2 phút với Thunderbit
Tôi đã dành hơn 2.000 từ cho code Python. Bây giờ tôi muốn nói thật về lúc bạn không cần đến nó.
Nếu bạn là người dùng kinh doanh chỉ làm nghiên cứu thị trường một lần, một reseller cần so sánh giá, hay một đội ecommerce cần dữ liệu ngay hôm nay mà không muốn chờ sprint dev, thì Python là quá tay. Khâu setup, bảo trì selector, quản lý proxy — tất cả đều là quá nhiều overhead cho câu chuyện “tôi chỉ cần 200 listing này trong một file spreadsheet”.
Thunderbit scrape eBay như thế nào? (Từng bước)
- Cài — không cần thẻ tín dụng.
- Mở bất kỳ trang kết quả tìm kiếm hoặc trang sản phẩm eBay nào trong Chrome.
- Bấm “AI Suggest Fields” trong sidebar của Thunderbit. AI sẽ đọc trang và đề xuất các cột: Title, Price, Condition, Shipping, Seller, Rating.
- Bấm “Scrape.” Extension sẽ tự đi qua phân trang và điền dữ liệu vào bảng. Riêng với eBay, Thunderbit có chạy một chạm.
- Xuất dữ liệu sang Google Sheets, Airtable, Notion, CSV, JSON hoặc Excel — miễn phí.
Toàn bộ quy trình này mất chưa đến 2 phút.
Tôi đã bấm giờ rồi.
Mở rộng sang trang con: lấy dữ liệu detail page mà không cần code thêm
Sau khi scrape xong trang kết quả tìm kiếm, Thunderbit có thể tự vào từng trang chi tiết của listing và bổ sung thêm các trường như thông số đầy đủ, thông tin người bán, mô tả, toàn bộ ảnh. Việc này thay thế hơn 20 dòng code Python để scrape subpage bằng đúng một cú click.
Khi nào vẫn nên dùng Python
Python phù hợp hơn khi bạn cần:
- Scraping quy mô lớn (hàng chục nghìn trang mỗi lần chạy)
- Logic phân tích hoặc biến đổi dữ liệu thật sự tùy biến
- Tích hợp vào pipeline dữ liệu sẵn có (Airflow, dbt, Kafka)
- Kiểm soát TLS/session ở mức chi tiết cho các bài toán anti-bot nâng cao
- Unit economics — ở quy mô hàng triệu dòng, stack tự duy trì sẽ rẻ hơn SaaS tính theo credit
Với đa số dự án một lần hoặc quy mô vừa, Thunderbit nhanh hơn và dễ hơn. Với pipeline production ở quy mô lớn, Python cho bạn toàn quyền kiểm soát.
Mẹo tránh bị chặn khi scrape eBay bằng Python
eBay có lớp Akamai là thật. Những gì thực sự hiệu quả trong thực tế:
- Dùng
curl_cffivớiimpersonate="chrome124"— đây là cải thiện lớn nhất so vớirequeststhuần - Luân phiên User-Agent từ danh sách các phiên bản trình duyệt hiện tại (Chrome 143, Firefox 124, Safari 26)
- Thêm độ trễ ngẫu nhiên — khoảng thời gian cố định là một dấu hiệu bot
- Dùng residential proxy hoặc rotating proxy nếu scrape hơn vài chục trang. IP của datacenter (AWS, GCP, DigitalOcean) rất nhanh bị Akamai phát hiện.
- Tôn trọng
robots.txt— nhiều URL browse có lọc đều bị Disallow rõ ràng; còn trang chi tiết item (/itm/<id>) thì không - Xử lý CAPTCHA một cách mềm dẻo — phát hiện CAPTCHA rồi thử lại bằng IP khác, hoặc dùng dịch vụ giải CAPTCHA
- Đừng bắn liên tục vào server. Tiền lệ cho thấy hành vi trespass to chattels có thể áp dụng khi scraping làm suy giảm server. Giữ ở mức 1 request/giây/IP sẽ giúp bạn rất xa ngưỡng đó.
Với mục đích thương mại khối lượng lớn, nên cân nhắc dùng Browse API cho listing đang hoạt động và chỉ scrape mục tiêu cho sold comps cùng dữ liệu API không cung cấp. Cách làm hybrid này sạch hơn cả về kỹ thuật lẫn pháp lý.
Scrape eBay bằng Python có hợp pháp không?
Tôi không phải luật sư, và bài viết này không phải tư vấn pháp lý. Nên tôi sẽ nói ngắn gọn.
Bối cảnh pháp lý hiện nay đang nghiêng nhiều hơn về phía việc scraping dữ liệu công khai. Các án lệ quan trọng gồm:
- (9th Cir., 2022): scrape dữ liệu công khai không vi phạm CFAA
- Van Buren v. United States (SCOTUS, 2021): thu hẹp cách hiểu về điều khoản “exceeds authorized access” của CFAA
- (N.D. Cal., 2024): scraping khi đã đăng xuất không vi phạm TOS nền tảng vì scraper không phải là “user”
Dù vậy, bản cập nhật lại cấm rõ ràng các “buy-for-me agents, LLM-driven bots, hoặc bất kỳ luồng end-to-end nào cố gắng đặt hàng mà không có con người kiểm tra”. Ranh giới khá rõ: scraping chỉ đọc dữ liệu công khai thì tương đối vững; tự động hóa bước checkout thì không.
Thực hành tốt nhất: chỉ scrape dữ liệu công khai hiển thị trên trang. Đừng tạo tài khoản giả hay vượt qua lớp đăng nhập. Đừng bán lại hàng loạt ảnh listing có bản quyền. Và hãy hỏi cố vấn pháp lý nếu bạn làm ở quy mô thương mại.
Kết luận và điểm chính cần nhớ
Python là cách linh hoạt nhất để scrape eBay, nhưng nó đòi hỏi bảo trì liên tục vì HTML của site thay đổi. Khung ra quyết định như sau:
- Dùng eBay Browse API cho truy vấn ổn định, khối lượng vừa phải trên listing đang hoạt động
- Dùng Python scraping cho listing đã bán, review, dữ liệu biến thể và bất kỳ dữ liệu nào API không có
- Dùng nếu bạn muốn có dữ liệu eBay mà không cần viết hay bảo trì code
Code trong bài này ưu tiên độ bền: trích xuất JSON-LD trước, fallback CSS selector nhiều lớp sau, và phân tích JSON ẩn cho biến thể. Cách làm nhiều tầng như vậy giúp scraper của bạn không “chết” ngay khi frontend team của eBay tung ra bản redesign tiếp theo.
Nếu bạn muốn thử hướng không cần code, cho phép bạn test ngay trên trang eBay. Và nếu bạn muốn xem hoạt động thế nào, chỉ cần một cú click.
Để tìm hiểu thêm về công cụ web scraping, hãy xem các hướng dẫn của chúng tôi về , và . Bạn cũng có thể xem video hướng dẫn trên .
Câu hỏi thường gặp
1. Tôi có thể scrape eBay miễn phí bằng Python không?
Có. Tất cả thư viện (Requests, BeautifulSoup, curl_cffi, pandas) đều miễn phí và mã nguồn mở. Chi phí phát sinh là ở quy mô lớn — proxy residential cho khối lượng cao thường tốn khoảng 50–500 USD/tháng tùy bandwidth. Với dự án nhỏ (vài trăm trang), bạn có thể scrape từ IP nhà riêng nếu rate limit cẩn thận.
2. Làm sao để scrape item đã bán và listing đã hoàn tất trên eBay bằng Python?
Thêm LH_Complete=1&LH_Sold=1 vào tham số URL tìm kiếm. Bạn phải truyền cả hai — chỉ LH_Sold=1 thôi sẽ âm thầm quay về listing đang hoạt động ở một số category. Lọc kết quả bằng cách kiểm tra class CSS .POSITIVE trên phần giá, vì đó là dấu hiệu item thực sự đã bán chứ không phải listing hết hạn mà chưa giao dịch.
3. eBay có chặn web scraping không?
eBay dùng Akamai Bot Manager, chủ yếu phát hiện scraper qua TLS fingerprinting và phân tích hành vi. Các lệnh requests thuần thường bị trả 403. Dùng curl_cffi với browser impersonation, luân phiên User-Agent và thêm độ trễ ngẫu nhiên 3–8 giây giữa các request sẽ vượt qua phần lớn cơ chế chặn. Proxy residential giúp nhiều hơn khi scale lớn.
4. Nên dùng eBay API hay web scraping?
Dùng Browse API cho truy vấn ổn định, khối lượng vừa phải trên listing đang hoạt động (tối đa 5.000 cuộc gọi/ngày). Dùng scraping khi bạn cần lịch sử giá đã bán, toàn bộ dữ liệu biến thể/MSKU, review, hoặc bất kỳ trường nào API không hiển thị. Marketplace Insights API về mặt kỹ thuật có dữ liệu sold, nhưng quyền truy cập bị hạn chế và .
5. Cách dễ nhất để scrape eBay mà không cần code là gì?
dùng AI để đọc trang eBay, gợi ý cột dữ liệu và trích xuất listing chỉ bằng một cú click. Nó xử lý phân trang, mở rộng dữ liệu ở trang con, và xuất sang Google Sheets, Excel, Airtable hoặc Notion. Các dựng sẵn còn giúp làm nhanh hơn cho các use case phổ biến.
Tìm hiểu thêm