Tốc độ của tin tức số bây giờ đúng kiểu “chạy như vũ bão”. Chỉ trong một phút thôi, đã có hàng nghìn headline được đăng mới, cập nhật, hoặc lặng lẽ chỉnh sửa—từ các tờ báo lớn, blog ngách cho tới newsfeed mạng xã hội. Để dễ hình dung, tiếp nhận hơn 4 triệu bài báo mỗi ngày, còn theo dõi tin tức bằng hơn 100 ngôn ngữ và refresh nguồn tin toàn cầu mỗi 15 phút. Với bất kỳ ai làm truyền thông, nghiên cứu hay business intelligence, cố gắng theo kịp “dòng thác” này bằng tay chẳng khác nào tát nước con thuyền đang chìm bằng… một chiếc cốc cà phê.
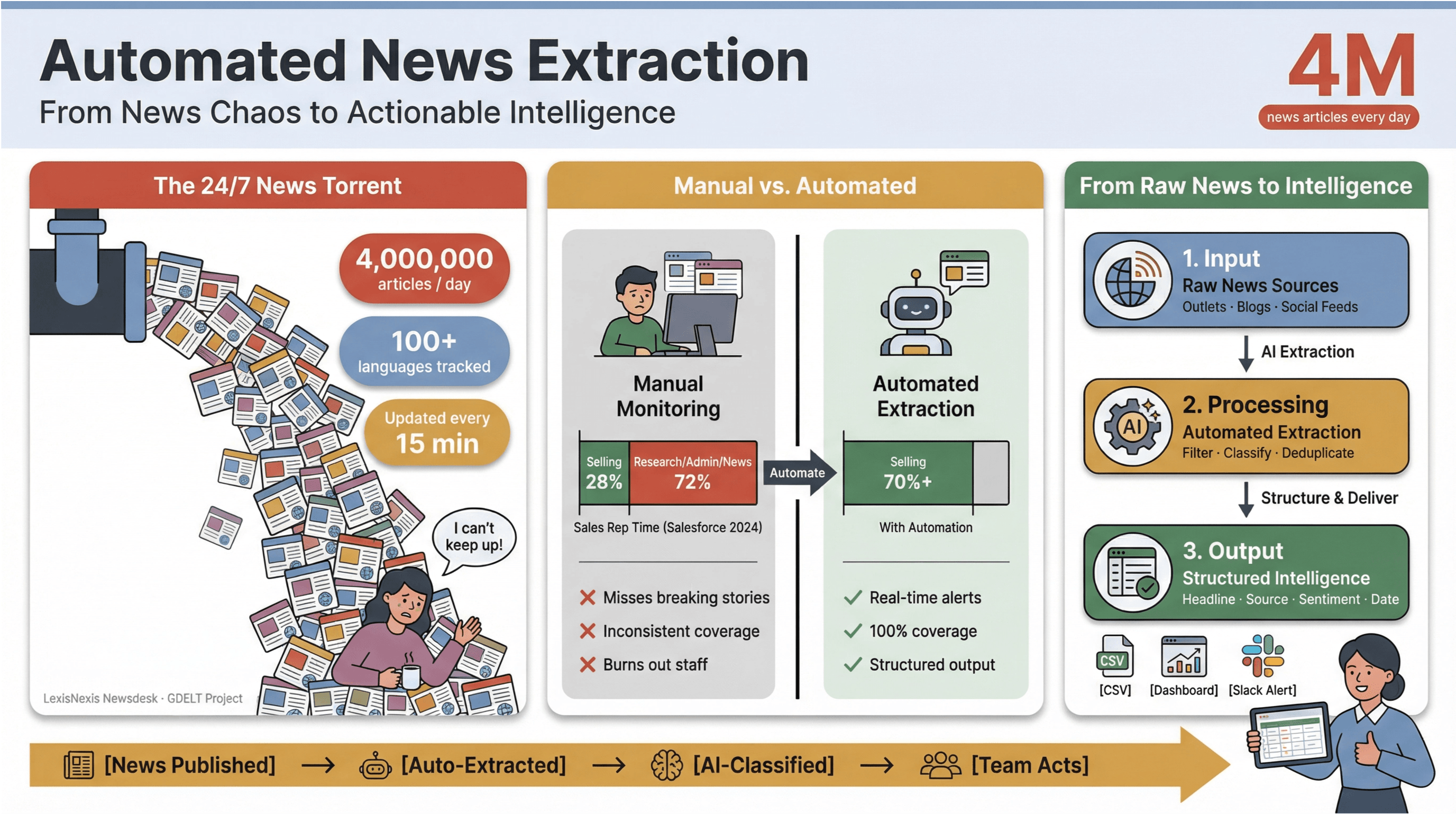
Tôi đã thấy tận mắt việc theo dõi tin tức thủ công “ăn” thời gian và bào mòn nguồn lực ra sao. Đội sales thường chưa tới một phần ba tuần là dành cho việc bán hàng thật sự——phần còn lại bị “đốt” vào research, việc hành chính và, đúng vậy, mở/đóng tab tin tức không hồi kết. Vì thế, trích xuất tin tức tự động dần thành “vũ khí bí mật” của các team hiện đại: gần như là cách duy nhất để biến sự hỗn loạn của chu kỳ tin tức 24/7 thành dữ liệu có cấu trúc, có thể action—mà không làm nhân sự kiệt sức hay bỏ lỡ những câu chuyện quan trọng.
Mình cùng bóc tách xem trích xuất tin tức tự động thực chất là gì, vì sao nó “must-have” với bất kỳ ai cần dữ liệu tin tức real-time, và cách dựng một quy trình vững, đúng luật bằng những công cụ tốt nhất (kèm cả cách làm mọi thứ đơn giản đến mức bất ngờ—kể cả với người không rành công nghệ như mẹ tôi).
Trích xuất tin tức tự động: Vì sao là điều bắt buộc với tòa soạn hiện đại
Trích xuất tin tức tự động đúng như tên gọi: dùng phần mềm để thu thập nội dung tin tức một cách tự động và chuyển nó thành dữ liệu có cấu trúc, dễ search—hãy tưởng tượng dạng bảng hàng/cột thay vì một trang web lộn xộn hay PDF khó nhằn. Thực tế, bạn có thể theo dõi hàng trăm (thậm chí hàng nghìn) nguồn, lấy các field quan trọng như tiêu đề, thời gian, tác giả, nội dung bài viết, rồi đẩy dữ liệu vào dashboard, alert hoặc hệ thống phân tích phía sau—mà không cần đụng tới Ctrl+C/Ctrl+V.
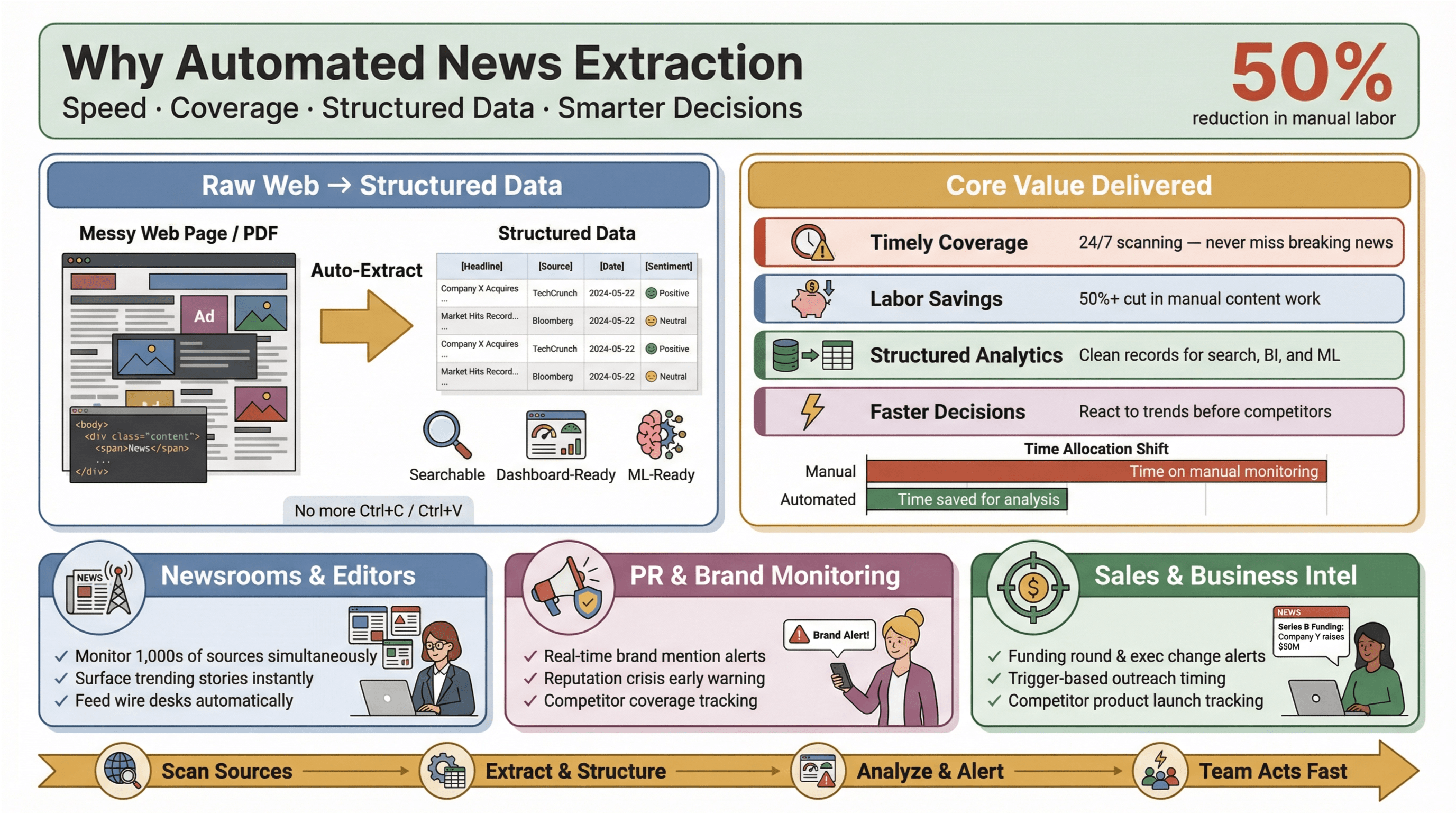 Vì sao chuyện này quan trọng? Vì trong bối cảnh tin tức hiện nay, tốc độ là tất cả. Dù bạn là biên tập viên, quản lý PR theo dõi brand mention, hay analyst theo dõi động thái đối thủ, biết sớm hơn đôi khi là ranh giới giữa chớp cơ hội và chạy theo sau. Công cụ trích xuất tự động giúp cả những team nhỏ cũng “đánh vượt hạng cân”—gom dữ liệu tin tức real-time khắp web, giảm tải việc tay chân và làm nổi bật những câu chuyện đáng chú ý nhất.
Vì sao chuyện này quan trọng? Vì trong bối cảnh tin tức hiện nay, tốc độ là tất cả. Dù bạn là biên tập viên, quản lý PR theo dõi brand mention, hay analyst theo dõi động thái đối thủ, biết sớm hơn đôi khi là ranh giới giữa chớp cơ hội và chạy theo sau. Công cụ trích xuất tự động giúp cả những team nhỏ cũng “đánh vượt hạng cân”—gom dữ liệu tin tức real-time khắp web, giảm tải việc tay chân và làm nổi bật những câu chuyện đáng chú ý nhất.
Tác động thấy rất rõ: nhiều nghiên cứu chỉ ra tự động hóa có thể giảm ít nhất 50% công sức thủ công cho việc cập nhật nội dung, giải phóng thời gian cho phân tích và ra quyết định.
Giá trị cốt lõi của trích xuất tin tức tự động trong ngành tin tức
Đi vào phần “được gì”: trích xuất tin tức tự động mang lại gì cho tòa soạn và các team kinh doanh?
- Phủ tin kịp thời, toàn diện: Không còn bỏ lỡ breaking news chỉ vì ai đó quên check một nguồn. Tool tự động quét 24/7, giúp bạn không bị “lạc nhịp”.
- Tiết kiệm nhân lực và chi phí: Team nhỏ/vừa vẫn theo dõi được số lượng nguồn ngang các “ông lớn”—mà không cần tuyển cả đội intern.
- Dữ liệu có cấu trúc để phân tích: Thay vì mò mẫm trong bài viết phi cấu trúc, bạn có bản ghi sạch, chuẩn hóa để search, làm dashboard và machine learning.
- Quyết định nhanh và thông minh hơn: Dữ liệu tin tức real-time giúp phản ứng sớm với biến động thị trường, khủng hoảng PR hoặc trend mới trước đối thủ.
Trong PR & truyền thông, các nền tảng như và xem media monitoring real-time là yếu tố sống còn để bảo vệ danh tiếng và xử lý nhanh tin bất lợi. Với sales, alert tin tức real-time trở thành “context card” khi prospecting—như vòng gọi vốn, thay đổi lãnh đạo, hay ra mắt sản phẩm để kích hoạt tiếp cận đúng thời điểm.
Chọn công cụ Scrape tin tức phù hợp cho từng kịch bản
Không phải công cụ Scrape tin tức nào cũng “một khuôn”. Chọn đúng còn tùy mục tiêu, mức độ thoải mái về kỹ thuật và loại tin bạn quan tâm. Dưới đây là khung tham chiếu để bạn pick cho chuẩn:
Đánh giá mức độ dễ dùng và khả năng tiếp cận
Với đa số người dùng doanh nghiệp và nhà báo, dễ dùng là điều không thể mặc cả. Bạn cần một công cụ “cài là chạy”, không phải ngồi viết code hay cấu hình lằng nhằng. Các nền tảng no-code/low-code như , và cho phép tạo scraper theo kiểu trực quan—chỉ cần trỏ, bấm và trích xuất.
Riêng Thunderbit nổi bật nhờ quy trình 2 bước: mô tả thứ bạn muốn, để AI gợi ý các trường dữ liệu, rồi bấm “Scrape”. Ngay cả người không chuyên kỹ thuật cũng có thể dựng pipeline dữ liệu tin tức trong vài phút thay vì vài giờ.
Cân nhắc bảo mật và quyền riêng tư dữ liệu
Dữ liệu càng nhiều, trách nhiệm càng nặng. Công cụ Scrape tin tức thường đụng tới nội dung nhạy cảm, nên bảo mật và tuân thủ phải được ưu tiên. Hãy để ý:
- Mã hóa dữ liệu (khi truyền và khi lưu)
- Chính sách quyền riêng tư rõ ràng (ví dụ Thunderbit nêu rõ không bán dữ liệu người dùng và chỉ truy cập nội dung bạn chọn để scrape)
- Phân quyền chi tiết (đặc biệt với extension trình duyệt—luôn check xem công cụ có thể truy cập dữ liệu gì)
- Tuân thủ luật địa phương (GDPR, CCPA và với người dùng EU là )
Muốn yên tâm hơn, hãy chọn nhà cung cấp uy tín, kiểm tra quyền extension và chỉ cấp quyền tối thiểu cần thiết.
Ghép công cụ với loại tin và nhu cầu từng ngành
Một số công cụ “đúng bài” ở các mảng tin cụ thể:
- Tài chính: API như và có clustering, sentiment và phát hiện sự kiện cho tin tài chính.
- Công nghệ & startup: Scrape tùy biến với Thunderbit hoặc Octoparse giúp nhắm blog ngách, thông cáo báo chí hoặc danh sách sự kiện.
- Chính trị & chính sách: CSDL có bản quyền như và cung cấp nguồn premium và kho lưu trữ.
Nếu bạn cần theo dõi hỗn hợp nguồn chính thống, ngách và quốc tế—kể cả những nơi không có API—các scraper linh hoạt, có AI như Thunderbit thường là lựa chọn “ngon - gọn - hiệu quả”.
Lợi thế khác biệt của Thunderbit khi trích xuất dữ liệu tin tức theo thời gian thực
Giờ nói thẳng về điểm khiến trở thành lựa chọn nổi bật cho trích xuất tin tức tự động—đặc biệt nếu bạn muốn dữ liệu tin tức theo thời gian thực mà không phải đau đầu vì kỹ thuật.
Thunderbit là một AI Web Scraper dạng Chrome Extension dành cho người dùng doanh nghiệp, nhà báo và nhà phân tích cần nội dung tin tức mới nhất, có cấu trúc từ bất kỳ website nào. Đây là những lý do nó là tool tôi hay dùng:
- AI Suggest Fields: Thunderbit đọc trang tin và tự gợi ý các cột nên trích xuất—tiêu đề, thời gian, tác giả, tóm tắt… Không cần vật lộn với selector hay template.
- Subpage Scraping: Cần full article chứ không chỉ headline? Thunderbit có thể vào từng link bài, lấy nội dung, thực thể, thẻ tag và gộp vào một bảng dữ liệu thống nhất.
- Xuất hàng loạt & cập nhật tức thì: Xuất dữ liệu trực tiếp sang Excel, Google Sheets, Airtable hoặc Notion chỉ với một cú nhấp. Không còn “marathon” copy-paste hay vật lộn với CSV.
- Scheduled Scraper: Thiết lập chạy định kỳ (theo giờ, theo ngày hoặc tùy chỉnh) để pipeline luôn fresh—rất hợp cho tin nóng, theo dõi thị trường hoặc nghiên cứu dài hạn.
- Khả năng thích ứng: AI của Thunderbit thích nghi với thay đổi giao diện và các trang tin “đuôi dài”, giúp bạn bớt thời gian sửa scraper hỏng và tập trung phân tích.
Với hơn và điểm 4,8 sao, Thunderbit được các team toàn cầu tin dùng cho đủ bài toán từ theo dõi PR đến competitive intelligence.
Nhận diện trường dữ liệu bằng AI và Subpage Scraping
Một tính năng “đáng đồng tiền bát gạo” của Thunderbit là nhận diện trường dữ liệu bằng AI. Chỉ cần bấm “AI Suggest Fields”, công cụ sẽ scan trang tin và nhận ra các trường quan trọng như tiêu đề, ngày, tác giả, tóm tắt. Bạn có thể chỉnh sửa hoặc thêm trường tùy biến (ví dụ: “gắn nhãn bài là ‘earnings’ nếu có nhắc kết quả theo quý”), và AI của Thunderbit sẽ lo phần còn lại.
Subpage scraping đặc biệt hợp với tin tức: scrape trang chủ hoặc trang chuyên mục để lấy danh sách headline, sau đó để Thunderbit vào từng URL bài viết để lấy toàn văn, thực thể và thậm chí cả hình ảnh. Nhờ vậy bạn có bản ghi tin tức đầy đủ, giàu ngữ cảnh—sẵn sàng cho search, dashboard hoặc phân tích AI phía sau.
Xuất hàng loạt và cập nhật tức thì
Thunderbit làm phần xuất dữ liệu tin tức nhẹ như “búng tay”. Chỉ một cú nhấp, bạn có thể đẩy feed tin đã cấu trúc sang Google Sheets, Airtable, Notion hoặc tải về CSV/Excel. Với các team “sống” trong spreadsheet hay BI, đây là khoản tiết kiệm thời gian cực lớn.
Và vì Thunderbit hỗ trợ Scheduled Scraper, bạn có thể đặt chạy mỗi giờ, mỗi ngày hoặc theo lịch riêng—đảm bảo dữ liệu luôn mới. Không còn cảnh ngồi chờ Google Alerts index chậm vài ngày.
Vượt qua thách thức vận hành khi triển khai giải pháp dữ liệu tin tức thời gian thực
Ngay cả khi có tool xịn, trích xuất tin tức real-time vẫn có những “bài toán vận hành” riêng. Dưới đây là cách xử lý các vấn đề hay gặp:
Quản lý độ trễ và độ “tươi” của dữ liệu
- Lên lịch scrape theo tốc độ cập nhật của mảng tin: Với tin nóng, đặt chạy mỗi 15–30 phút (tương ứng chu kỳ cập nhật của ). Với mảng tin chậm hơn, theo giờ hoặc theo ngày là đủ.
- Theo dõi chênh lệch giữa thời điểm đăng và thời điểm lấy dữ liệu: Đo khoảng cách giữa lúc bài được xuất bản và lúc hệ thống của bạn thu thập. Nếu độ trễ tăng, kiểm tra khả năng bị chặn hoặc bị làm chậm.
- Scrape lại để bắt “chỉnh sửa âm thầm”: Bài báo hay được update sau khi đăng. Hãy lên lịch scrape lần hai sau 24 giờ để bắt các đính chính hoặc chỉnh sửa kín ().
Xử lý giới hạn API và sự khác biệt giữa các nguồn
- Tôn trọng hạn mức API: Nếu dùng news API, chú ý rate limit—dàn đều request theo thời gian và cache kết quả khi có thể ().
- Khử trùng lặp và chuẩn hóa URL: Tin thường xuất hiện ở nhiều URL hoặc được cập nhật. Hãy lưu canonical URL và dùng hash (ví dụ: tiêu đề + ngày) để tránh trùng ().
- Xử lý nội dung động: Với site có infinite scroll hoặc lazy loading, dùng công cụ hỗ trợ render động và theo dõi thay đổi layout ().
Phân tích dữ liệu tin tức thông minh: Vai trò của AI và machine learning
Trích xuất tin tức mới chỉ là “màn khởi động”. Giá trị thật nằm ở phân tích và hành động dựa trên dữ liệu—và đây là sân chơi của AI/machine learning.
- Trích xuất thực thể: Dùng NLP để lấy tên người, tổ chức, địa điểm được nhắc trong bài ().
- Phân loại chủ đề: Tự động gắn nhãn theo chủ đề, cảm xúc hoặc mức độ khẩn cấp—giúp dashboard và alert thông minh hơn ().
- Gom cụm sự kiện: Nhóm các bài trùng/liên quan giữa nhiều báo để thấy bức tranh tổng thể (thay vì ngập trong các headline gần như giống nhau).
- Cá nhân hóa và nhắm mục tiêu: Dùng dữ liệu tin tức real-time để phân khúc đối tượng, tối ưu nhắm quảng cáo hoặc gợi ý nội dung—tăng tương tác và ROI.
Ví dụ, team PR dùng phân tích tin tức real-time để phát hiện khủng hoảng sớm trước khi bùng nổ, còn team sales làm giàu danh sách khách hàng tiềm năng bằng “trigger event” như gọi vốn hay tuyển lãnh đạo cấp cao.
Checklist thực hành tốt nhất cho trích xuất tin tức tự động
Dưới đây là checklist nhanh để pipeline trích xuất tin tức chạy ổn định, ít “toang”:
| Thực hành tốt nhất | Vì sao quan trọng | Cách triển khai |
|---|---|---|
| Lên lịch scrape thường xuyên | Giảm độ trễ dữ liệu, bắt tin nóng | Điều chỉnh tần suất theo tốc độ cập nhật (vd: mỗi 15 phút cho mảng tin nhanh) |
| Dùng trích xuất dựa trên AI | Thích nghi thay đổi layout, giảm thời gian thiết lập | Công cụ như Thunderbit, Diffbot, Zyte API |
| Khử trùng lặp và chuẩn hóa | Tránh cảnh báo trùng, dữ liệu sạch | Lưu canonical URL, dùng hash để loại trùng |
| Giám sát chất lượng trích xuất | Phát hiện thiếu trường, lệch mẫu hoặc lỗi | Theo dõi % bản ghi đầy đủ, độ trễ và tỷ lệ lỗi |
| Tôn trọng ranh giới pháp lý/tuân thủ | Giảm rủi ro pháp lý, giữ niềm tin | Ưu tiên API/feed chính thức, xem điều khoản, hạn chế dữ liệu cá nhân |
| Xuất ra định dạng có cấu trúc | Phục vụ phân tích phía sau | CSV, Excel, Sheets, Notion, Airtable |
| Lên lịch scrape lại để bắt chỉnh sửa | Bắt thay đổi sau khi đăng | Quay lại bài sau 24h/1w (mô hình GDELT) |
| Bảo mật pipeline | Bảo vệ dữ liệu nhạy cảm | Mã hóa, kiểm soát truy cập, dùng công cụ uy tín |
Xây dựng quy trình trích xuất tin tức tự động vững chắc
Sẵn sàng dựng “hộp đen” dữ liệu tin tức của riêng bạn chưa? Đây là quy trình từng bước:
- Xác định nguồn: Liệt kê các trang báo, blog hoặc API bạn muốn theo dõi.
- Thiết lập trích xuất: Dùng Thunderbit hoặc công cụ bạn chọn để định nghĩa các trường (AI Suggest Fields giúp việc này cực nhanh).
- Lên lịch scrape: Chọn tần suất theo tốc độ cập nhật—mỗi giờ cho tin nóng, mỗi ngày cho mảng tin chậm.
- Làm giàu bằng subpage: Với mỗi tiêu đề, scrape toàn văn để lấy nội dung, thực thể và tag.
- Khử trùng lặp và chuẩn hóa: Lưu canonical URL, hash bản ghi và chuẩn hóa các trường.
- Xuất và tích hợp: Đẩy dữ liệu có cấu trúc sang Excel, Google Sheets, Airtable hoặc Notion để phân tích.
- Giám sát và thích nghi: Theo dõi chất lượng trích xuất, quan sát thay đổi layout và điều chỉnh khi cần.
- Tuân thủ: Xem điều khoản, tôn trọng robots.txt và hạn chế thu thập dữ liệu cá nhân.
Nếu hình dung theo luồng:
Nguồn → Trích xuất (trường AI) → Làm giàu subpage → Khử trùng lặp → Xuất → Phân tích/Cảnh báo → Giám sát
Kết luận & điểm cần nhớ
Trích xuất tin tức tự động giờ không còn là kiểu “có thì tốt” nữa—mà là điều bắt buộc nếu bạn muốn đi trước trong một thế giới nơi tin tức bùng nổ (và đổi chiều) từng phút. Khi áp dụng đúng best practice và chọn đúng công cụ, bạn có thể biến “vòi cứu hỏa” tin tức số thành một dòng dữ liệu ổn định, có cấu trúc và có thể action.
Điểm chính:
- Quy mô và tốc độ của tin tức online buộc phải tự động hóa—giám sát thủ công không thể theo kịp.
- Công cụ trích xuất tin tức tự động tiết kiệm thời gian, giảm chi phí và giúp team nhỏ đạt độ phủ như tổ chức lớn.
- Chọn công cụ phù hợp là bài toán cân bằng giữa dễ dùng, bảo mật và khả năng thích ứng—Thunderbit nổi bật nhờ sự đơn giản dựa trên AI và tùy chọn xuất dữ liệu real-time.
- Xây workflow xoay quanh độ tươi, khử trùng lặp, tuân thủ và giám sát chất lượng để dữ liệu tin tức luôn đáng tin và hữu ích.
- AI và machine learning mở khóa giá trị lớn hơn—giúp nhắm mục tiêu, cá nhân hóa và ra quyết định thông minh hơn.
Nếu bạn vẫn đang copy-paste headline hoặc ngồi chờ Google Alerts “đuổi kịp”, thì đã đến lúc nâng cấp. Hãy để thấy trích xuất tin tức tự động có thể dễ đến mức nào. Muốn thêm mẹo, workflow và bài phân tích sâu, ghé .
Câu hỏi thường gặp (FAQs)
1. Trích xuất tin tức tự động là gì và hoạt động ra sao?
Trích xuất tin tức tự động là quá trình dùng phần mềm thu thập bài báo và chuyển thành dữ liệu có cấu trúc (như bảng hoặc JSON) để phân tích, tìm kiếm hoặc tạo cảnh báo. Các công cụ như Thunderbit dùng AI để nhận diện các trường quan trọng (tiêu đề, thời gian, tác giả, nội dung) và tự động trích xuất từ trang web hoặc API.
2. Vì sao dữ liệu tin tức thời gian thực lại quan trọng với doanh nghiệp?
Dữ liệu tin tức thời gian thực giúp doanh nghiệp phản ứng nhanh trước sự kiện thị trường, khủng hoảng PR hoặc động thái đối thủ. Dù bạn làm sales, PR hay nghiên cứu, tin tức cập nhật liên tục giúp ra quyết định nhanh hơn, tốt hơn và đi trước cạnh tranh.
3. Thunderbit giúp người không rành kỹ thuật Scrape tin tức dễ hơn như thế nào?
Thunderbit có quy trình 2 bước đơn giản: mô tả dữ liệu bạn cần và để AI gợi ý các trường. Nhờ subpage scraping và xuất nhanh sang Excel/Google Sheets, ngay cả người không chuyên cũng có thể dựng pipeline dữ liệu tin tức vững chắc chỉ trong vài phút.
4. Cần lưu ý gì về pháp lý và tuân thủ khi Scrape tin tức?
Luôn đọc điều khoản dịch vụ của website mục tiêu, ưu tiên API/feed chính thức khi có, và tôn trọng chỉ dẫn robots.txt. Tránh scrape nội dung yêu cầu đăng nhập hoặc paywall khi chưa được phép, đồng thời hạn chế thu thập dữ liệu cá nhân để tuân thủ luật quyền riêng tư.
5. Làm sao để workflow trích xuất tin tức luôn ổn định theo thời gian?
Hãy lên lịch scrape đều đặn, giám sát chất lượng trích xuất và dùng công cụ có khả năng thích nghi khi layout thay đổi (như trích xuất dựa trên AI của Thunderbit). Khử trùng lặp bản ghi, theo dõi độ trễ giữa thời điểm đăng và thời điểm trích xuất, và thiết lập cảnh báo khi lỗi/thiếu trường để pipeline luôn “khỏe” và cập nhật.
Tìm hiểu thêm