
Một nghiên cứu dựa trên crawl về cách các website có lượng truy cập cao đang công bố hướng dẫn có thể đọc bằng máy cho các mô hình ngôn ngữ lớn, các triển khai ban đầu trông như thế nào, và vì sao muốn đo mức độ chấp nhận thì không thể chỉ đếm phản hồi HTTP 200.
- Bộ dữ liệu:
data/llms_probe_results_top_10000.csv - Danh sách Tranco được tải xuống: 6 tháng 5, 2026
- Phạm vi:
/llms.txtvà/llms-full.txtở cấp gốc
Chỉ số chính
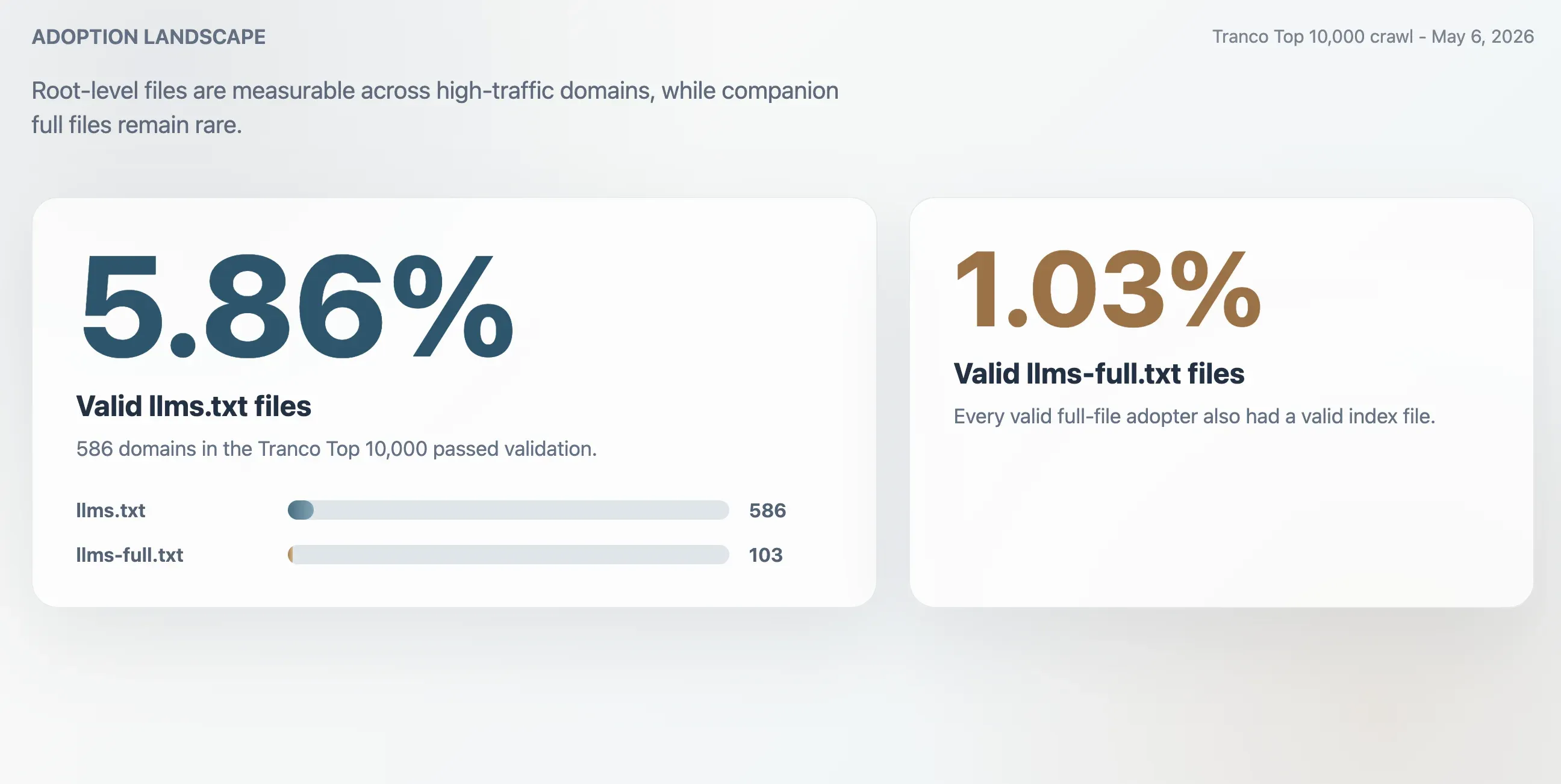
- 5,86%: Mức độ chấp nhận hợp lệ của
llms.txttrong Tranco Top 10.000, tương đương 586 miền. - 1,03%: Mức độ chấp nhận hợp lệ của
llms-full.txt, tương đương 103 miền. Mọi miền có tệp đầy đủ hợp lệ cũng đều có tệp chỉ mục hợp lệ. - 63,51%: Tỷ lệ phản hồi HTTP 200 cho
/llms.txtnhưng không vượt qua xác thực. - 2,74x: Mức độ đếm vượt nếu chỉ đo mức chấp nhận bằng phản hồi HTTP 200 thô.
Tóm tắt điều hành
llms.txt vẫn là một quy ước web còn rất sớm, nhưng không còn là thử nghiệm bên lề nữa. Trong lần crawl ngày 6 tháng 5 năm 2026 đối với Tranco Top 10.000 miền, nghiên cứu này tìm thấy 586 tệp llms.txt hợp lệ, tương đương tỷ lệ chấp nhận quan sát được là 5,86%. Tệp đi kèm llms-full.txt ít phổ biến hơn nhiều: chỉ 103 miền có tệp đầy đủ hợp lệ, tương đương tỷ lệ chấp nhận 1,03%.
Phát hiện phương pháp luận quan trọng nhất là mã trạng thái không phải đại diện tốt cho mức độ chấp nhận. Trình thu thập đã ghi nhận 1.606 phản hồi HTTP 200 cho /llms.txt, nhưng chỉ 586 phản hồi vượt qua xác thực. 1.020 phản hồi còn lại chủ yếu là chuyển hướng lệch mục tiêu, trang HTML chung chung, nội dung rỗng, hoặc các phản hồi không hợp lệ khác. Một trình crawl ngây thơ coi mọi phản hồi 200 là mức chấp nhận sẽ đánh giá cao hơn thực tế khoảng 2,74 lần.
Trong số các đơn vị chấp nhận hợp lệ, chất lượng triển khai cao hơn so với kiểu câu chuyện “placeholder” đơn thuần. Kích thước trung vị của tệp hợp lệ là khoảng 7,1 KB, 61,77% tệp hợp lệ lớn hơn 5 KB, 70,82% có từ 6 phần Markdown trở lên, và 77,47% có từ 11 liên kết Markdown trở lên. Nhóm người dùng sớm bao gồm Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog và Cloudinary.
llms.txtnên được hiểu là một tín hiệu giải thích và dẫn hướng cho hệ thống AI, chứ không phải bản thay thế chorobots.txt. Giá trị của nó không chỉ nằm ở chỗ có tệp, mà là ở chỗ tệp đó có giúp máy tìm ra thông tin chính thống, ngắn gọn và cập nhật hay không.
Bối cảnh: Web đang bổ sung các tín hiệu hướng tới AI
Các website từ lâu đã dùng robots.txt để thể hiện ưu tiên của trình thu thập, sitemap.xml để cải thiện khả năng phát hiện URL, và dữ liệu có cấu trúc để giúp công cụ tìm kiếm và các hệ thống nền tảng diễn giải trang. AI tạo sinh đặt ra một bài toán khác. Nội dung có thể được dùng để huấn luyện, truy xuất, tóm tắt, duyệt web theo tác vụ, hỗ trợ lập trình, hỗ trợ khách hàng và tạo câu trả lời. Điều đó tạo ra hai nhu cầu cùng lúc: nhà xuất bản muốn kiểm soát tốt hơn việc sử dụng tự động, nhưng họ cũng muốn hệ thống AI tìm đúng thông tin chuẩn khi những hệ thống này tương tác với website của họ.
Đề xuất gốc về llms.txt, do Jeremy Howard giới thiệu năm 2024, định nghĩa tệp này là một tài liệu Markdown đặt ở gốc website để cung cấp thông tin thân thiện với LLM tại thời điểm suy luận. Đề xuất cho rằng các trang HTML thường chứa điều hướng, quảng cáo, script và nhiều nhiễu khác khiến mô hình ngôn ngữ khó xử lý hơn. Một tệp Markdown ngắn gọn có thể dẫn mô hình tới các trang, tài liệu, API, ví dụ, chính sách và thông tin sản phẩm quan trọng nhất.
Nghiên cứu web bên ngoài cho thêm bối cảnh rộng hơn. “Consent in Crisis” của Data Provenance Initiative mô tả sự gia tăng nhanh chóng của các hạn chế liên quan đến AI trong robots.txt và điều khoản dịch vụ, đồng thời lập luận rằng các cơ chế đồng ý hiện có trên web không được thiết kế cho việc tái sử dụng dữ liệu AI ở quy mô lớn. Cloudflare Radar AI Insights cũng đã làm rõ các mô thức của trình thu thập AI và robots.txt ở cấp độ Top 10.000 miền. Trong bối cảnh đó, llms.txt đứng ở phía mang tính xây dựng của tín hiệu AI: không phải “đừng thu thập nội dung này”, mà là “nếu bạn cần hiểu website này, hãy bắt đầu từ đây”.
Bằng chứng bên ngoài và cuộc tranh luận về mức độ chấp nhận
Cuộc tranh luận công khai quanh llms.txt chia làm hai hướng. Quan điểm lạc quan cho rằng tệp này giúp hệ thống AI đi tới nội dung chính thống theo cách sạch hơn và hiệu quả hơn. Quan điểm hoài nghi cho rằng chưa có nhà cung cấp LLM lớn nào công khai cam kết dùng nó như tín hiệu xếp hạng, thu thập hay trích dẫn, nên nhà xuất bản không nên kỳ vọng tăng lưu lượng chỉ nhờ tệp này. Ba nguồn tham chiếu bên ngoài được xem xét trong bản cập nhật này ủng hộ một kết luận tinh tế hơn: llms.txt là hạ tầng hữu ích, nhưng bằng chứng về tác động trực tiếp tới lưu lượng vẫn còn hạn chế và phụ thuộc bối cảnh.
Các mốc chấp nhận bên ngoài đang thay đổi rất nhanh
Bảng theo dõi mức độ chấp nhận của Rankability ghi nhận tỷ lệ chấp nhận 0,3% trên 1.000 website hàng đầu tính đến ngày 22 tháng 6 năm 2025, tức 3 trên 1.000 site. Nguồn này mô tả việc quét tự động hàng tháng tại domain.com/llms.txt, với bước xác thực loại trừ chuyển hướng và phản hồi HTML. Phương pháp đó khá gần với cách xác thực thận trọng của nghiên cứu này.
Chênh lệch kết quả là rất lớn: nghiên cứu này tìm thấy 75 tệp llms.txt hợp lệ trong Tranco Top 1.000 vào ngày 6 tháng 5 năm 2026, tương đương 7,50%. Hai con số này không nên được xem như chuỗi thời gian nghiêm ngặt vì nguồn xếp hạng, chi tiết triển khai, logic xác thực và thời điểm crawl có thể khác nhau. Tuy vậy, sự tương phản cho thấy mức độ chấp nhận đã thay đổi đáng kể giữa giữa năm 2025 và tháng 5 năm 2026, đặc biệt ở các website về developer, SaaS, cloud, bảo mật và tài liệu kỹ thuật.
| Nguồn | Ảnh chụp | Mẫu | Mức chấp nhận hợp lệ được báo cáo | Diễn giải |
|---|---|---|---|---|
| Rankability | 22 tháng 6, 2025 | Top 1.000 website | 0,3% | Mốc công khai ban đầu cho thấy mức chấp nhận rất thấp vào giữa năm 2025. |
| Nghiên cứu này | 6 tháng 5, 2026 | Tranco Top 1.000 | 7,50% | Lần crawl muộn hơn cho thấy mức chấp nhận rõ rệt ở các website có lượng truy cập cao. |
| Nghiên cứu này | 6 tháng 5, 2026 | Tranco Top 10.000 | 5,86% | Mẫu rộng hơn cho thấy mức chấp nhận có thể đo được nhưng chưa phổ biến rộng rãi. |
Các thử nghiệm về lưu lượng vẫn cho kết quả lẫn lộn
Search Engine Land đã công bố một phân tích trên 10 website vào tháng 1 năm 2026, theo dõi các site trong 90 ngày trước và 90 ngày sau khi triển khai. Bài viết cho biết hai site có lưu lượng AI tăng 12,5% và 25%, tám site không có cải thiện đo được, và một site giảm 19,7%. Diễn giải chính của bài viết là phải thận trọng với quan hệ nhân quả: hai trường hợp thành công bề ngoài cũng đồng thời ra mắt mẫu thiết kế mới, xây lại trung tâm tài nguyên, thêm bảng so sánh có thể trích xuất, nhận được đưa tin báo chí, khắc phục sự cố kỹ thuật hoặc xuất bản nội dung kiểu FAQ mới. Trong cách nhìn đó, llms.txt ghi lại công việc nội dung và kỹ thuật mạnh hơn; nó dường như không tự mình tạo ra tăng trưởng.
Thử nghiệm trên blog cá nhân của Renat Alimbekov đưa ra kết luận tích cực hơn từ một quan sát ở quy mô nhỏ hơn. Bài viết so sánh hai giai đoạn bốn tháng trong Yandex.Metrica sau khi thêm cả llms.txt và llms-full.txt. Số phiên giới thiệu từ LLM tăng từ 75 lên 92, tương đương tăng 23%, trong khi số người dùng tăng từ 51 lên 64. Số phiên từ Perplexity tăng từ 29 lên 55, còn phiên từ ChatGPT giảm từ 31 xuống 26. Bài viết này cũng lưu ý rằng tổng lưu lượng giới thiệu tăng nhanh hơn, từ 160 lên 290 phiên, nên tỷ trọng phiên từ LLM giảm từ 47% xuống 32%.
| Loại bằng chứng | Kết quả quan sát được | Lưu ý chính | Tác động tới báo cáo này |
|---|---|---|---|
| Nghiên cứu trước/sau trên 10 site của Search Engine Land | Hai site tăng, tám site không đổi đáng kể, một site giảm. | Các trường hợp tích cực đồng thời có thay đổi nội dung, PR và kỹ thuật. | Ủng hộ cách xem llms.txt là hạ tầng, không phải đòn bẩy tăng trưởng độc lập. |
| Quan sát trước/sau trên blog cá nhân của Alimbekov | Phiên giới thiệu từ LLM tăng 23% trong giai đoạn sau. | Không có nhóm đối chứng; tổng lưu lượng giới thiệu tăng 81%, và tỷ trọng LLM giảm. | Gợi ý có thể có lợi cho blog kỹ thuật, nhất là qua Perplexity, nhưng chưa tách riêng được quan hệ nhân quả. |
| Nghiên cứu chấp nhận dựa trên crawl này | 586 tệp hợp lệ và nhiều triển khai có cấu trúc. | Đo sự hiện diện và cấu trúc, không đo tác động lưu lượng đầu ra. | Cho thấy mức độ chấp nhận và độ trưởng thành triển khai, nhưng chưa nói lên ROI. |
Cuộc tranh luận làm rõ điều gì
Bằng chứng bên ngoài giúp diễn giải bộ dữ liệu này rõ hơn. Một tệp llms.txt được cấu trúc tốt có thể giảm ma sát khi máy phân tích, đặc biệt với tài liệu dành cho developer, tham chiếu API và nội dung cơ sở tri thức. Nhưng các trường hợp tăng lưu lượng mạnh nhất dường như vẫn phụ thuộc vào nội dung hữu ích, dễ trích xuất, có tính chính thống và dễ được phát hiện bên ngoài tệp. Vì vậy, câu hỏi thực tế không phải là “llms.txt có quan trọng không?” nếu đứng một mình. Câu hỏi là liệu tệp này có là một phần của hệ thống nội dung có thể đọc bởi AI rộng hơn hay không.
Diễn giải cập nhật:
llms.txtnên được triển khai như hạ tầng hướng tới AI với chi phí thấp. Nó không nên được xem là phương án thay thế cho tài liệu tốt hơn, nội dung có cấu trúc, khả năng tiếp cận kỹ thuật, trích dẫn, liên kết hoặc uy tín thương hiệu.
Dùng Thunderbit để thu thập dữ liệu web bằng AI
Phương pháp
Nghiên cứu này sử dụng Tranco Top 10.000 miền làm mẫu. Tranco là một bảng xếp hạng top site phục vụ nghiên cứu, được thiết kế để ổn định hơn và chống thao túng tốt hơn nhiều danh sách top truyền thống. Tệp nguồn Tranco được tải xuống ngày 6 tháng 5 năm 2026, với dấu thời gian Last-Modified của nguồn là 5 tháng 5 năm 2026 lúc 22:17:59 GMT.
Trình thu thập đã kiểm tra hai đường dẫn ở cấp gốc cho mỗi miền:
https://example.com/llms.txt, với phương án dự phòng HTTP khi cần.https://example.com/llms-full.txt, với phương án dự phòng HTTP khi cần.
Với mỗi lần kiểm tra, trình thu thập ghi lại mã trạng thái, URL cuối cùng, phương thức fetch, số byte phản hồi, loại nội dung, thông báo lỗi, thời gian trôi qua và kết quả xác thực. Các phần nội dung phản hồi thành công được lưu dưới raw_llms_txt/ để xem xét và phân tích thứ cấp.
Quy tắc xác thực
Một phản hồi chỉ được tính là tệp hợp lệ nếu nó trả về phần thân thành công và không trông như một trang dự phòng web chung chung. Đường dẫn URL cuối cùng phải vẫn là /llms.txt hoặc /llms-full.txt. Nội dung rỗng bị từ chối. Các tài liệu HTML rõ ràng và app shell bị từ chối. Loại nội dung được xem như bằng chứng hỗ trợ chứ không phải quy tắc duy nhất, vì một số tệp dạng văn bản hợp lệ được phục vụ với content type bất thường.
Bức tranh mức độ chấp nhận
Lần crawl tìm thấy 586 tệp llms.txt hợp lệ trong Tranco Top 10.000. Điều này cho ra tỷ lệ chấp nhận hợp lệ là 5,86%. Tệp đi kèm nhỏ hơn llms-full.txt hiện diện và hợp lệ ở 103 miền, tương đương 1,03% mẫu.
| Chỉ số | Số lượng | Tỷ lệ trong Top 10.000 |
|---|---|---|
| Miền đã crawl | 10.000 | 100,00% |
| Tệp llms.txt hợp lệ | 586 | 5,86% |
| Tệp llms-full.txt hợp lệ | 103 | 1,03% |
| Phản hồi HTTP 200 cho /llms.txt | 1.606 | 16,06% |
| Phản hồi HTTP 200 bị từ chối vì không hợp lệ | 1.020 | 10,20% |
Mức độ chấp nhận không chỉ tập trung ở nhóm đầu bảng
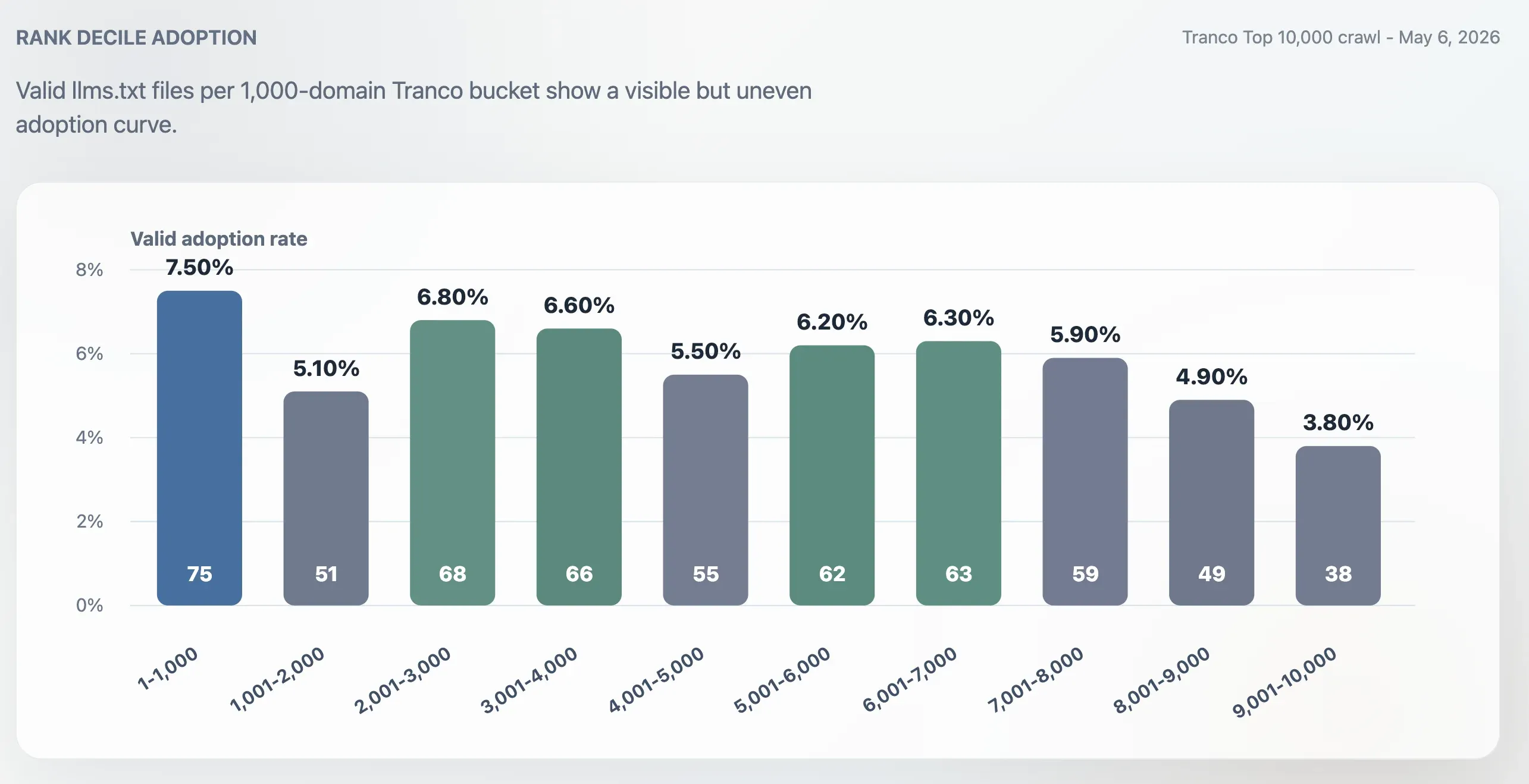
Mức độ chấp nhận ở Top 1.000 cao hơn so với toàn bộ Top 10.000, nhưng không chỉ giới hạn ở các site lớn nhất. Tỷ lệ chấp nhận trong Top 1.000 là 7,50%. Nhóm 1.000 miền cuối, tức hạng 9.001-10.000, giảm xuống 3,80%. Phần giữa bảng xếp hạng vẫn khá sôi động: các nhóm 2.001-3.000, 3.001-4.000, 5.001-6.000 và 6.001-7.000 đều quanh mức 6%.
Những người chấp nhận sớm
Miền chấp nhận hợp lệ có thứ hạng cao nhất là Cloudflare ở hạng Tranco 4. Các đơn vị chấp nhận có thứ hạng cao khác gồm Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink và OneSignal.
Những đơn vị chấp nhận này không hề ngẫu nhiên. Họ thường có bề mặt tài liệu lớn, danh mục sản phẩm cần giải thích, API hoặc hệ sinh thái developer, nội dung hỗ trợ, trang giá, tài liệu bảo mật và quyền riêng tư, cùng đủ uy tín thương hiệu để quan tâm tới cách hệ thống AI diễn giải website của họ.
| Hạng | Miền | Kích thước tệp | Mẫu quan sát được |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Mục lục gọn cho sản phẩm, developer, công ty và giá. |
| 26 | azure.com | 47.037 B | Công cụ developer, AI, compute, storage, bảo mật, giám sát và tài nguyên tùy chọn. |
| 28 | github.com | 27.108 B | Truy cập theo chương trình, Copilot, MCP, REST API, Actions, repository và liên kết CLI. |
| 248 | stripe.com | 64.229 B | Thanh toán, Connect, Checkout, Billing, Tax, Atlas, Radar và tài liệu developer. |
| 265 | salesforce.com | 1,02 MB | Danh mục liên kết sản phẩm và Agentforce rất lớn, không có tiêu đề phần Markdown. |
Phân loại nhóm chấp nhận trong Top 1.000
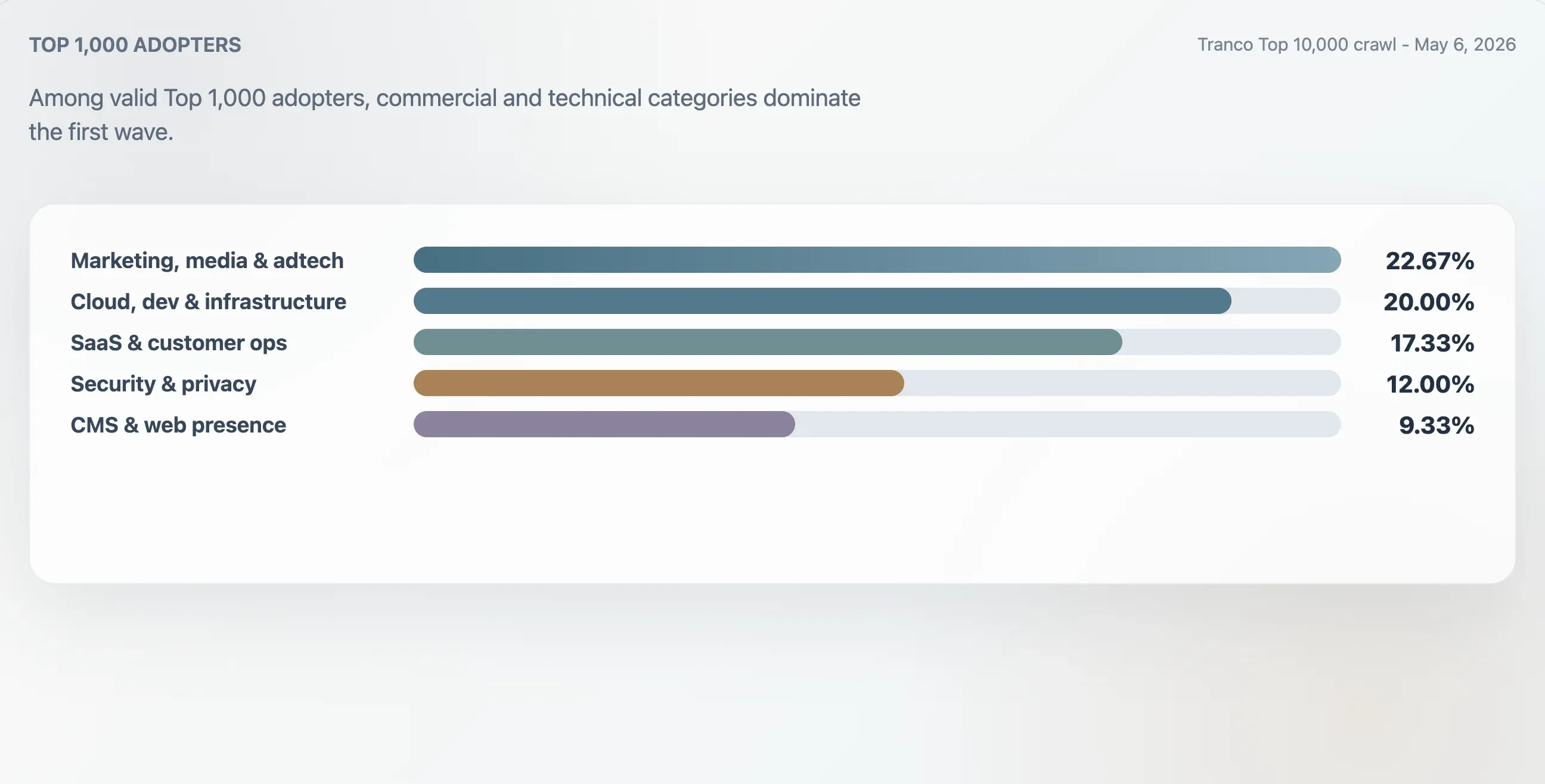
Nghiên cứu này phân loại 75 đơn vị chấp nhận hợp lệ trong Tranco Top 1.000 bằng bối cảnh miền, tiêu đề đầu tiên, cấu trúc tệp thô và từ khóa nội dung. Nhóm lớn nhất là marketing, media và adtech với 22,67%. Các website cloud, developer và hạ tầng chiếm 20,00%. SaaS, productivity và customer operations chiếm 17,33%. Các website bảo mật, danh tính và quyền riêng tư chiếm 12,00%.
| Danh mục | Miền | Tỷ lệ trong nhóm chấp nhận Top 1.000 | Điểm chất lượng trung vị | Liên kết trung vị |
|---|---|---|---|---|
| Marketing, media & adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev & infrastructure | 15 | 20,00% | 94 | 62 |
| SaaS, productivity & customer ops | 13 | 17,33% | 94 | 46 |
| Security, identity & privacy | 9 | 12,00% | 98 | 78 |
| CMS, hosting & web presence | 7 | 9,33% | 100 | 24 |
Mẫu TLD
Tên miền cấp cao không phải là nhãn ngành, nhưng là tín hiệu định hướng hữu ích. Trong số các TLD có ít nhất 50 miền trong mẫu, .io có tỷ lệ chấp nhận hợp lệ cao nhất ở mức 14,44%. .com theo sau ở mức 8,19%. Mức chấp nhận thấp hơn ở .gov, .edu và .net cho thấy nhóm chấp nhận sớm thiên về thương mại và kỹ thuật hơn là thể chế.
Chất lượng triển khai
Chấp nhận hợp lệ không đồng nghĩa với chất lượng triển khai đồng đều. Một số tệp là các mục lục ngắn gọn, được chia phần tốt. Một số chủ yếu là văn xuôi. Một số là danh mục liên kết thô. Một số gần như trống. Một số là các khối nội dung nhiều megabyte, có thể đầy đủ nhưng tốn kém để lấy và phân tích.
Trong số các tệp llms.txt hợp lệ, 362 tệp lớn hơn 5 KB, tức 61,77% số đơn vị chấp nhận hợp lệ. Kích thước trung vị của tệp là khoảng 7,1 KB. P90 là 156 KB, P95 là 356 KB, P99 là 2,54 MB, và tệp lớn nhất quan sát được là 7,97 MB.
Các tín hiệu nội dung phổ biến
Một lần quét theo từ khóa trên các tệp hợp lệ cho thấy nhiều website không chỉ đang công bố một tuyên bố, mà đang dẫn mô hình tới tài liệu hữu ích về vận hành. Các thuật ngữ hỗ trợ hoặc trợ giúp xuất hiện trong 70,31% tệp hợp lệ. Blog, hướng dẫn hoặc tutorial xuất hiện trong 67,92%. Bảo mật, quyền riêng tư, tuân thủ hoặc điều khoản xuất hiện trong 61,43%. Giá cả xuất hiện trong 53,92%, tài liệu trong 52,22%, API trong 33,96%, và tín hiệu changelog hoặc phát hành trong 27,30%.
Chấm điểm chất lượng và dạng mẫu
Để đi từ sự hiện diện sang mức độ trưởng thành, nghiên cứu này tạo một thang điểm triển khai nhẹ. Thang điểm xem xét loại nội dung, kích thước tệp, cấu trúc Markdown, số liên kết, phạm vi chủ đề và các dấu hiệu cảnh báo như thiếu tiêu đề, không có liên kết Markdown, loại nội dung bất thường, tệp quá nhỏ, tệp rất lớn và hành vi kiểu đổ liên kết. Đây không phải chuẩn chính thức. Nó là mô hình chấm điểm nghiên cứu để so sánh các triển khai quan sát được.
Theo mô hình này, 416 tệp hợp lệ được xếp là mục lục có cấu trúc mạnh, 107 là mục lục dùng được, 24 là mỏng hoặc bất thường, và 39 là mang tính biểu tượng hoặc giá trị thấp. Một phân tích archetype riêng cho thấy 296 mục lục có cấu trúc, 113 tệp văn bản có chia phần, 63 danh mục liên kết, 52 mục lục mỏng, 50 tệp mang tính biểu tượng hoặc placeholder, và 12 khối nội dung khổng lồ.
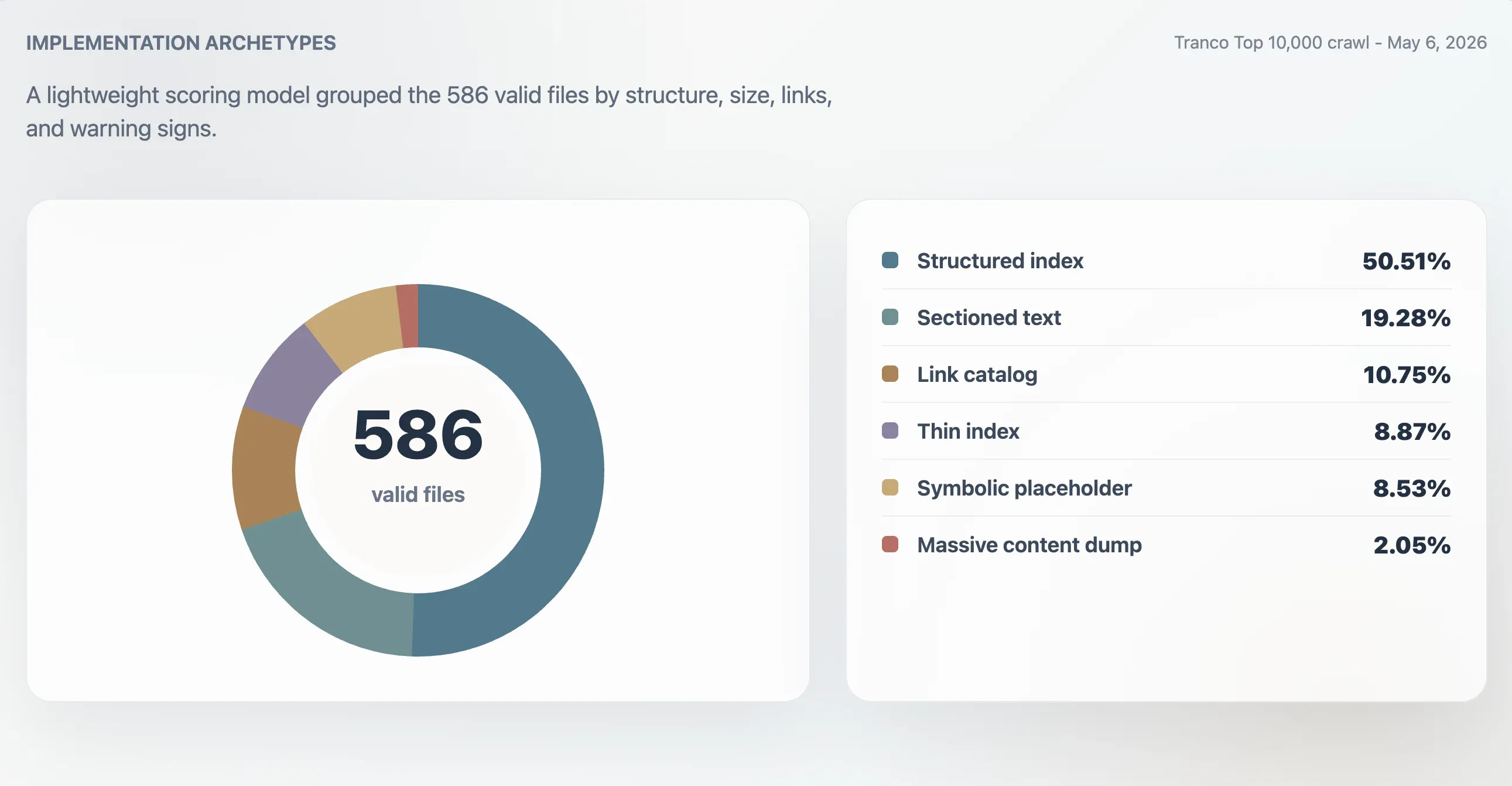
| Archetype | Miền | Tỷ lệ trong các tệp hợp lệ | Điểm trung vị | Kích thước tệp trung vị | Liên kết trung vị |
|---|---|---|---|---|---|
| Mục lục có cấu trúc | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Văn bản có chia phần | 113 | 19,28% | 78 | 4.718 B | 0 |
| Danh mục liên kết | 63 | 10,75% | 86 | 4.160 B | 23 |
| Mục lục mỏng | 52 | 8,87% | 66 | 2.814 B | 0 |
| Biểu tượng hoặc placeholder | 50 | 8,53% | 27 | 15 B | 0 |
| Khối nội dung khổng lồ | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
Các đơn vị chấp nhận hàng đầu có triển khai dày hơn
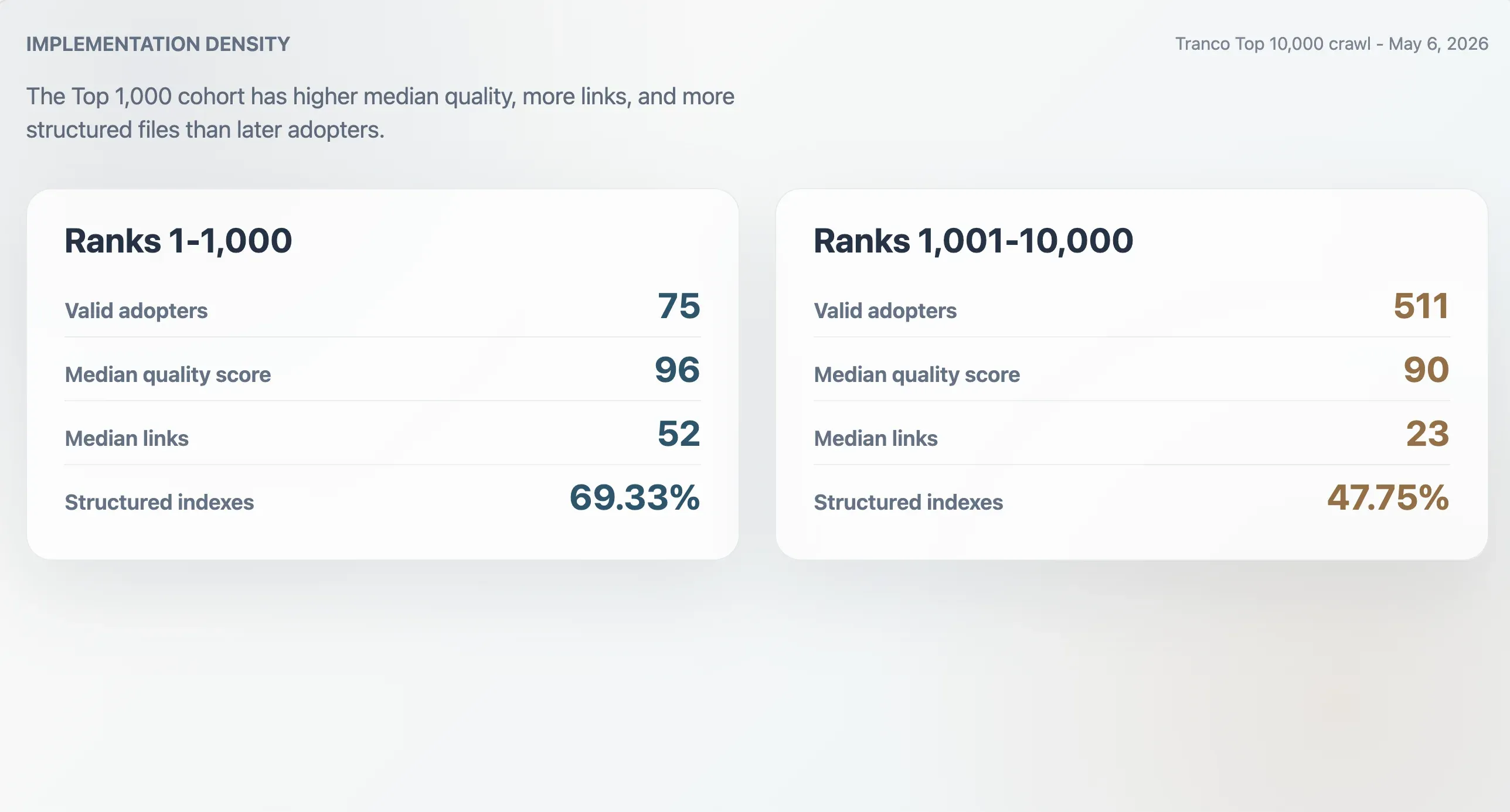
75 đơn vị chấp nhận hợp lệ trong Tranco Top 1.000 có điểm chất lượng trung vị là 96, kích thước tệp trung vị 9.068 byte, số liên kết Markdown trung vị là 52, và số phần trung vị là 11. 511 đơn vị chấp nhận xếp hạng 1.001-10.000 có trung vị thấp hơn: điểm 90, kích thước tệp 6.506 byte, 23 liên kết Markdown và 9 phần. Các đơn vị chấp nhận trong Top 1.000 cũng có xu hướng là mục lục có cấu trúc nhiều hơn: 69,33% so với 47,75% ở nhóm sau.
Vấn đề dương tính giả

Rủi ro đo lường lớn nhất là dương tính giả. Trong số 1.606 miền trả về HTTP 200 cho /llms.txt, có 1.020 miền không vượt qua xác thực. Lý do không hợp lệ phổ biến nhất là chuyển hướng lệch mục tiêu, với 618 trường hợp. 367 phản hồi khác là tài liệu HTML chung chung. 29 phản hồi trả về nội dung rỗng, và 6 phản hồi khác là không hợp lệ khác hoặc chưa phân loại.
Điều này quan trọng vì nhiều website lớn chuyển các đường dẫn lạ tới trang đăng nhập, trang chủ, app shell, trang theo khu vực, lớp consent, hoặc các trang dự phòng marketing. Những phản hồi này có thể trông “ổn” với một trình crawl chỉ nhìn mã trạng thái, nhưng thực tế không chứa tín hiệu llms.txt hợp lệ.
llms-full.txt: hiếm hơn và không đồng đều hơn
Tệp đi kèm llms-full.txt ít phổ biến hơn nhiều so với llms.txt. Lần crawl tìm thấy 103 tệp đầy đủ hợp lệ, tương đương 17,58% số đơn vị chấp nhận llms.txt hợp lệ và 1,03% của toàn bộ mẫu Top 10.000.
Các triển khai tệp đầy đủ khá không đồng đều. Trong số 103 đơn vị chấp nhận có cả hai tệp, 57 miền có llms-full.txt lớn hơn tệp chỉ mục, nhưng 46 miền либо có tệp đầy đủ không lớn hơn tệp chỉ mục, hoặc tệp đầy đủ dưới 100 byte. Tỷ lệ kích thước đầy đủ/chỉ mục trung vị là 1,43, nhưng các trường hợp cực đoan thì cao hơn rất nhiều. Tệp đầy đủ của Supabase lớn hơn tệp chỉ mục khoảng 7.139 lần. Made-in-China.com có tệp đầy đủ 89,89 MB.
| Miền | llms.txt | llms-full.txt | Tỷ lệ |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Khuyến nghị: chỉ nên xuất bản
llms-full.txtkhi website đã có quy trình tài liệu ổn định, kỷ luật versioning, và lý do rõ ràng để phơi bày khối lượng nội dung lớn trong một tệp có thể đọc bằng máy.
llms.txt, robots.txt và sitemap.xml
Không nên xem llms.txt là một robots.txt mới. Cả hai đều là tệp có thể đọc bằng máy ở cấp gốc, nhưng chúng truyền tải những điều khác nhau. robots.txt là tín hiệu về ưu tiên của trình thu thập và kiểm soát truy cập. sitemap.xml là tín hiệu khám phá URL. llms.txt là tín hiệu giải thích và dẫn hướng.
| Tín hiệu | Vai trò chính | Đối tượng đọc điển hình | Diễn giải trong nghiên cứu này |
|---|---|---|---|
robots.txt | Công bố ưu tiên của trình thu thập và các hạn chế theo đường dẫn. | Trình thu thập tìm kiếm, trình thu thập AI, trình thu thập lưu trữ, bot chung. | Tín hiệu quản trị và truy cập. |
sitemap.xml | Liệt kê các URL có thể khám phá cho hệ thống lập chỉ mục. | Công cụ tìm kiếm và pipeline lập chỉ mục. | Tín hiệu khám phá. |
llms.txt | Cung cấp bối cảnh ngắn gọn về website, liên kết quan trọng, tài liệu, API, ví dụ và tham chiếu chính sách. | Ứng dụng LLM, tác nhân AI, công cụ cho developer, hệ thống truy xuất. | Tín hiệu giải thích và điều hướng. |
Khuyến nghị
Với các website đang cân nhắc llms.txt, những triển khai mạnh nhất trong bộ dữ liệu này và bằng chứng lưu lượng bên ngoài cho thấy một mẫu thực dụng:
- Xuất bản
/llms.txtở gốc và giữ cho nó truy cập được mà không cần đăng nhập, thực thi JavaScript, rào cản consent, hay chuyển hướng lệch đường dẫn. - Nếu có thể, phục vụ dưới dạng
text/plainhoặctext/markdown. - Bắt đầu bằng một mô tả ngắn về website, rồi nhóm liên kết theo sản phẩm, tài liệu, API, giá, changelog, ví dụ, hỗ trợ, chính sách và tài nguyên công ty.
- Ưu tiên liên kết chuẩn hóa thay vì liệt kê toàn bộ URL.
- Tránh các tệp biểu tượng rỗng; cùng lắm chúng chỉ là tín hiệu yếu.
- Tránh các bản đổ dữ liệu khổng lồ, không phân biệt nếu không có trường hợp sử dụng rõ ràng cho việc tiêu thụ bởi máy và không có pipeline tạo ra đáng tin cậy.
- Xác thực URL cuối cùng, phần nội dung phản hồi, loại nội dung, cấu trúc Markdown, số liên kết và kích thước tệp sau khi xuất bản.
Các đội ngũ cũng nên đặt kỳ vọng một cách cẩn thận. Những thử nghiệm công khai hiện có chưa chứng minh rằng llms.txt tự nó làm tăng lưu lượng giới thiệu từ AI. Nếu một nhóm muốn kiểm tra tác động kinh doanh, họ nên theo dõi đồng thời lượt giới thiệu từ LLM, các trang được trích dẫn, yêu cầu bot, độ mới của chỉ mục và thay đổi nội dung. Một thử nghiệm hữu ích sẽ so sánh các nhóm trang tương đồng, giữ mức cập nhật nội dung ổn định khi có thể, và tách riêng lưu lượng theo nền tảng như Perplexity, ChatGPT, Gemini, Claude và Bing/Copilot.
Hạn chế
Đây là một ảnh chụp dựa trên crawl, không phải chân lý cố định vĩnh viễn. Website có thể thêm, xóa hoặc thay đổi tệp llms.txt bất cứ lúc nào. Một số miền có thể chặn yêu cầu tự động hoặc hành xử khác nhau tùy địa lý, cấu hình TLS, logic chuyển hướng, user agent hoặc cơ chế giảm thiểu bot. Nghiên cứu chỉ kiểm tra các tệp ở cấp gốc và không tìm kiếm subdomain hay các đường dẫn phi tiêu chuẩn.
Thang điểm chất lượng và các archetype là công cụ nghiên cứu, không phải nhãn tuân thủ chính thức. Phân tích chủ đề dựa trên từ khóa và nên được đọc như tín hiệu định hướng. Nghiên cứu này không chứng minh rằng bất kỳ nền tảng AI cụ thể nào hiện đang đọc, tôn trọng hay sử dụng llms.txt trong môi trường sản xuất.
Bằng chứng lưu lượng bên ngoài được xem xét trong phiên bản này cũng có giới hạn. Phân tích của Search Engine Land phù hợp hơn như một quan sát thận trọng nhiều website, hơn là một thí nghiệm ngẫu nhiên. Kết quả của Alimbekov hữu ích như một nghiên cứu trường hợp minh bạch ở cấp website, nhưng không có nhóm đối chứng và bao gồm giai đoạn tổng lưu lượng giới thiệu tăng mạnh. Những nguồn này giúp định hình cuộc tranh luận, nhưng không biến lần crawl này thành một nghiên cứu nhân quả về lưu lượng.
Tệp và khả năng tái lập
| Tệp | Mục đích |
|---|---|
crawl_llms_txt.py | Trình crawl cho /llms.txt và /llms-full.txt. |
analyze_llms_txt.py | Phân tích chấp nhận chính và tạo biểu đồ. |
deep_analyze_llms_txt.py | Phân tích thứ cấp cho các decile hạng, TLD, tín hiệu chủ đề, điểm chất lượng, archetype và hành vi tệp kép. |
deep_dive_early_quality.py | Phân loại người chấp nhận sớm và phân tích chuyên sâu về chất lượng triển khai. |
data/llms_probe_results_top_10000.csv | Bộ dữ liệu kết quả crawl chính. |
data/deep_analysis_top_10000.json | Tóm tắt phân tích thứ cấp. |
data/deep_early_quality_analysis.json | Danh mục người chấp nhận sớm, so sánh nhóm chất lượng, chi tiết archetype và nghiên cứu điển hình. |
Nguồn
- Tệp /llms.txt, Jeremy Howard, 2024.
- HTTP Archive Web Almanac 2024 Methodology.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation.
- Does llms.txt matter?, Search Engine Land, tháng 1 năm 2026.
- The State of llms.txt Adoption, Rankability, tháng 6 năm 2025.
- How LLMS.txt Increased AI Chat Traffic by 23%, Renat Alimbekov.
Hoan nghênh các chỉnh sửa về phương pháp, vấn đề bộ dữ liệu và phân tích tiếp theo tại support@thunderbit.com. Báo cáo này được xuất bản độc lập với bất kỳ lập trường thương mại nào của Thunderbit. Dữ liệu trong báo cáo này tự đứng vững. — Nhóm nghiên cứu Thunderbit, tháng 5 năm 2026.
Dùng Thunderbit để thu thập và phân tích dữ liệu web Get Started Free




