

Bảng điều khiển OpenRouter của tôi báo đã tiêu hết 47 USD trước bữa trưa vào một ngày thứ Ba. Tôi mới chạy chừng hơn chục tác vụ lập trình — chẳng có gì quá ghê gớm, chỉ là vài lần refactor và sửa lỗi lặt vặt. Đến lúc đó tôi mới nhận ra cấu hình mặc định của OpenClaw đang âm thầm đẩy mọi tương tác, kể cả các ping heartbeat nền, qua Claude Opus với mức giá hơn 15 USD cho mỗi triệu token.
Nếu bạn từng gặp những cú sốc tương tự — và nhìn qua các diễn đàn thì có vẻ rất nhiều người đã gặp rồi (“Tôi đã tốn 40 đô mà còn chẳng dùng mấy,” một người dùng viết) — thì bài này sẽ hướng dẫn bạn cách tôi audit và tối ưu toàn bộ hệ thống để giảm chi phí hàng tháng khoảng 90%. Không chỉ đơn giản là “đổi sang model rẻ hơn”, mà là bóc tách có hệ thống: token thực sự chảy đi đâu, theo dõi chúng thế nào, các model tiết kiệm nào vẫn đủ sức xử lý công việc agentic thực tế, và ba bộ cấu hình có thể sao chép dán ngay hôm nay. Toàn bộ quy trình chỉ mất một buổi chiều.
Mức dùng token của OpenClaw là gì, và vì sao mặc định lại cao như vậy?
Token là đơn vị tính phí cho mọi tương tác AI trong OpenClaw. Bạn có thể hiểu chúng như những mảnh văn bản rất nhỏ — khoảng 4 ký tự tiếng Anh cho mỗi token. Mỗi tin nhắn bạn gửi, mỗi phản hồi bạn nhận, mỗi tiến trình nền được kích hoạt: tất cả đều được tính theo token.
Vấn đề là cấu hình mặc định của OpenClaw được tối ưu cho năng lực tối đa, không phải chi phí tối thiểu. Ngay khi cài xong, model chính được đặt là anthropic/claude-opus-4-5 — lựa chọn đắt nhất hiện có. Heartbeat ping cũng chạy trên Opus. Các sub-agent sinh ra để xử lý việc phụ cũng dùng Opus. Dùng Opus cho một heartbeat ping chẳng khác nào thuê bác sĩ phẫu thuật thần kinh để dán băng cá nhân. Về mặt kỹ thuật thì vẫn làm được, nhưng cái giá thì quá phi lý.
Phần lớn người dùng không nhận ra họ đang trả mức premium cho những tác vụ nền rất nhỏ. Cấu hình mặc định gần như giả định rằng bạn luôn muốn model tốt nhất cho mọi thứ, mọi lúc — và hóa đơn sẽ phản ánh đúng điều đó.
Vì sao giảm mức dùng token của OpenClaw không chỉ giúp tiết kiệm tiền
Lợi ích rõ nhất là giảm chi phí. Nhưng còn nhiều hiệu quả phụ tích lũy dần theo thời gian.
Các model rẻ hơn thường còn nhanh hơn. Gemini 2.5 Flash-Lite chạy khoảng 214 token mỗi giây so với khoảng 51 token/giây của Opus — tức nhanh hơn 4 lần ở mỗi tương tác. GPT-OSS-120B trên Cerebras đạt 1.917 token mỗi giây, nhanh hơn Opus khoảng 35 lần. Trong một vòng lặp agentic với hơn 50 lượt gọi công cụ, chênh lệch tốc độ này đồng nghĩa bạn hoàn thành trong vài phút thay vì phải chờ đợi với thời gian phản hồi đầu tiên đau đầu 13,6 giây của Opus ở mỗi lượt đi-về.
Bạn cũng có thêm “dư địa” trước khi chạm giới hạn rate limit, ít phiên bị nghẽn hơn, và có thể mở rộng mức dùng mà không phải mở rộng luôn nỗi lo hóa đơn.
Ước tính mức tiết kiệm theo từng nhóm người dùng:
| Nhóm người dùng | Chi tiêu hàng tháng ước tính (mặc định) | Sau tối ưu toàn diện | Tiết kiệm hàng tháng |
|---|---|---|---|
| Nhẹ (~10 truy vấn/ngày) | ~$100 | ~$12 | ~88% |
| Trung bình (~50 truy vấn/ngày) | ~$500 | ~$90 | ~82% |
| Nhiều (~200+ truy vấn/ngày) | ~$1,750 | ~$220 | ~87% |
Đây không phải số liệu giả định. Một nhà phát triển đã ghi lại việc giảm từ $600–750/tháng xuống còn $3–4/ngày — thực sự giảm 90% — bằng cách kết hợp routing model với các bản vá cho những nguồn “rút máu” ẩn được trình bày phía sau.
Phân tích cấu trúc mức dùng token của OpenClaw: token thật sự chảy đi đâu
Đây là phần hầu hết các hướng dẫn tối ưu bỏ qua, nhưng lại là phần quan trọng nhất. Bạn không thể sửa thứ mình không nhìn thấy.
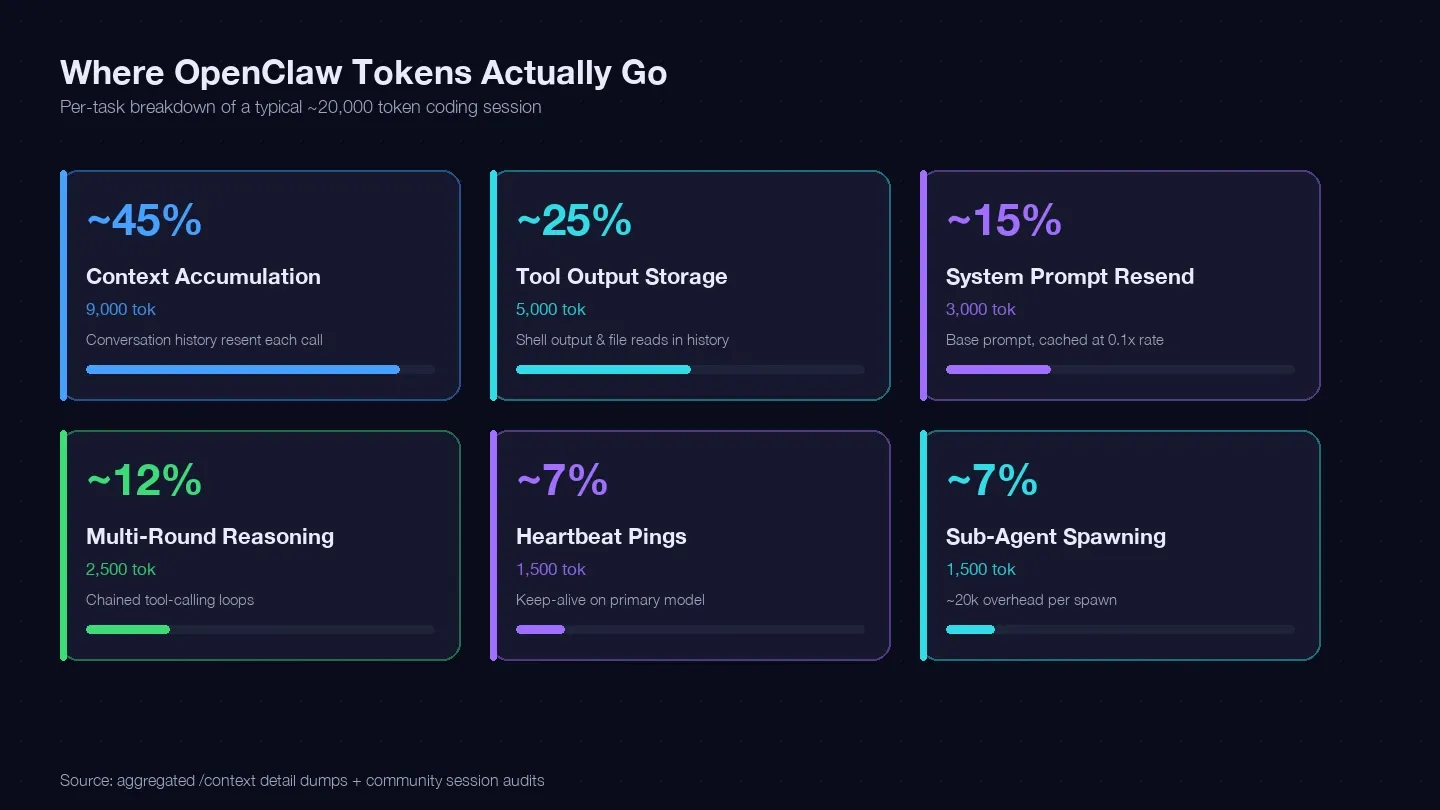
Tôi đã audit nhiều phiên làm việc và đối chiếu với hướng dẫn tối ưu chi phí của LaoZhang cùng các dump /context từ cộng đồng để dựng lại bảng phân bổ token cho một tác vụ code điển hình. Dưới đây là khoảng 20.000 token đã thực sự đi đâu:
| Nhóm token | Tỷ lệ điển hình trên tổng | Ví dụ (1 tác vụ lập trình) | Có kiểm soát được không? |
|---|---|---|---|
| Tích lũy ngữ cảnh (lịch sử hội thoại được gửi lại mỗi lần gọi) | ~40–50% | ~9.000 token | Có — /clear, /compact, phiên ngắn hơn |
| Lưu đầu ra công cụ (output shell, đọc file vẫn bị giữ trong lịch sử) | ~20–30% | ~5.000 token | Có — đọc ít hơn, giới hạn scope công cụ chặt hơn |
| Gửi lại system prompt (~15K base) | ~10–15% | ~3.000 token | Một phần — cache đọc với tỷ lệ 0.1x |
| Suy luận nhiều vòng (chuỗi loop gọi công cụ) | ~10–15% | ~2.500 token | Chọn model + prompt tốt hơn |
| Heartbeat / keep-alive ping | ~5–10% | ~1.500 token | Có — đổi cấu hình |
| Lời gọi sub-agent | ~5–10% | ~1.500 token | Có — routing model |
Khoản lớn nhất — tích lũy ngữ cảnh — chính là lịch sử hội thoại của bạn bị gửi lại trong mọi API call. Một dump phiên làm việc thực tế cho thấy riêng bucket Messages đã có tới 185.400 token, trong khi model còn chưa kịp trả lời. System prompt và tool còn cộng thêm khoảng 35.800 token overhead cố định nữa.
Kết luận: nếu bạn không xóa phiên giữa các tác vụ không liên quan, bạn đang trả tiền để truyền lại toàn bộ lịch sử hội thoại ở mọi lượt.
Cách theo dõi mức dùng token của OpenClaw (không thấy thì không thể cắt)
Trước khi đổi bất cứ thứ gì, hãy tạo khả năng quan sát xem token đang đi đâu. Nhảy ngay vào “dùng model rẻ hơn” mà không theo dõi chẳng khác nào muốn giảm cân nhưng không bao giờ bước lên cân.
Kiểm tra bảng điều khiển OpenRouter của bạn
Nếu bạn route qua OpenRouter, trang Activity là dashboard dễ dùng nhất mà không cần setup gì. Bạn có thể lọc theo model, provider, API key và khoảng thời gian. Mục Usage Accounting tách riêng prompt, completion, reasoning và cached token cho từng request. Có nút Export (CSV hoặc PDF) để phân tích dài hạn.
Cần nhìn gì: model nào tiêu nhiều token nhất, và liệu heartbeat hay sub-agent request có đang xuất hiện như những khoản bất thường lớn hay không.
Audit log API cục bộ của bạn
OpenClaw lưu dữ liệu phiên trong ~/.openclaw/agents.main/sessions/sessions.json, bao gồm totalTokens theo từng session. Bạn cũng có thể chạy openclaw logs --follow --json để log theo thời gian thực cho từng request.
Một lưu ý quan trọng: sessions.json totalTokens không được cập nhật sau khi compact, nên dashboard có thể hiển thị giá trị cũ trước compaction. Hãy tin vào /status và /context detail hơn là các tổng số đã lưu.
Dùng công cụ theo dõi bên thứ ba (cho người dùng trung bình đến nhiều)
LiteLLM proxy cung cấp một endpoint tương thích OpenAI ở phía trước hơn 100 provider và tự động ghi lại chi tiêu theo virtual key, model, người dùng và team. Tính năng ăn tiền nhất: hạn mức cứng theo từng key, vẫn giữ nguyên dù bạn dùng /clear — một sub-agent chạy mất kiểm soát cũng không thể vượt quá mức bạn đặt.
Helicone còn đơn giản hơn — chỉ cần đổi base URL bằng một dòng là có ngay view Sessions để nhóm các request liên quan. Một prompt “sửa lỗi này” nhưng tỏa ra hơn 8 lời gọi sub-agent sẽ hiện thành một dòng session với tổng chi phí thật. Gói miễn phí: 10.000 request/tháng.
Kiểm tra nhanh ngay trong OpenClaw
Để theo dõi hằng ngày, bốn lệnh trong session là đủ:
/status— hiển thị mức dùng context, token input/output gần nhất, chi phí ước tính/usage full— footer usage cho từng phản hồi/context detail— phân rã token theo file, skill, tool/compact [guidance]— buộc compact với chuỗi hướng dẫn tùy chọn
Hãy chạy /context detail trước và sau khi thay đổi cấu hình. Đó là cách bạn đo xem tối ưu của mình có thật sự hiệu quả hay không.
Cuộc so tài model rẻ nhất của OpenClaw: model nào thực sự xử lý tốt công việc agentic?
Nhiều hướng dẫn thường sai ở chỗ này. Họ đưa một bảng giá, chỉ vào dòng rẻ nhất rồi coi như xong. Benchmark không dự đoán được hiệu năng agentic ngoài đời — điều cộng đồng đã nhấn mạnh rất nhiều lần. Như một người dùng nói: “benchmarks không giúp gì nhiều để hiểu model nào hợp nhất cho AI agentic.”
Điểm mấu chốt: model rẻ nhất chưa chắc là kết quả rẻ nhất. Một model thất bại rồi retry bốn lần sẽ tốn hơn model tầm trung nhưng thành công ngay lần đầu. Trong hệ thống agent production, hãy tính sẵn tỷ lệ retry 5–10% — và nếu năm lượt LLM được nối chuỗi mà bước bốn lỗi, một lần retry ngây thơ sẽ chạy lại toàn bộ năm bước.
Dưới đây là ma trận năng lực của tôi, với “Điểm agentic thực tế” dựa trên báo cáo thật của người dùng thay vì benchmark tổng hợp:
| Model | Input $/1M | Output $/1M | Độ tin cậy khi gọi công cụ | Suy luận nhiều bước | Điểm agentic thực tế (1–5) | Phù hợp nhất cho |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Trung bình — thỉnh thoảng bị loop | Cơ bản | ⭐2.5 | Heartbeat, tra cứu đơn giản |
| GPT-OSS-120B | $0.04 | $0.19 | Đủ dùng | Đủ dùng | ⭐3.0 | Thử nghiệm tiết kiệm, cần tốc độ |
| DeepSeek V3.2 | $0.26 | $0.38 | Không ổn định (6 issue mở) | Tốt | ⭐3.0 | Nặng suy luận, ít gọi công cụ |
| Kimi K2.5 | $0.38 | $1.72 | Tốt (qua :exacto) | Đủ dùng | ⭐3.5 | Lập trình đơn giản đến trung bình |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Tốt | Tốt | ⭐4.0 | Model dùng hằng ngày cho code |
| Claude Haiku 4.5 | $1.00 | $5.00 | Rất tốt | Tốt | ⭐4.5 | Fallback tầm trung đáng tin cậy |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Rất tốt | Rất tốt | ⭐5.0 | Tác vụ nhiều bước phức tạp |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Rất tốt | Rất tốt | ⭐5.0 | Chỉ dành cho bài toán khó nhất |
Cảnh báo về DeepSeek và Gemini Flash khi gọi công cụ
DeepSeek V3.2 nhìn trên giấy tờ rất hấp dẫn — 72–74% trên SWE-Bench, rẻ hơn Sonnet 11–36 lần. Nhưng trong thực tế, sáu issue GitHub riêng biệt từ Cline, Roo Code, Continue và NVIDIA NIM đã ghi nhận hành vi gọi công cụ bị lỗi. Kết luận đối đầu từ Composio: “DeepSeek V3.2 tạo được một phần ứng dụng nhưng vấp ở khâu thực thi, tốc độ và độ tin cậy.” Câu chốt gọn của Zvi Mowshowitz: “ổn và rẻ, nhưng.”
Gemini 2.5 Flash cũng có khoảng trống tương tự. Một chủ đề trên Google AI Developers Forum có tiêu đề “Very frustrating experience with Gemini 2.5 function calling performance” mở đầu rằng: “hành vi function calling của các model Gemini đã trở nên hoàn toàn không ổn định và khó đoán.”
OpenRouter lưu ý một điểm rất quan trọng: “xu hướng gọi công cụ của một model và độ chính xác của các lệnh gọi đó có thể thay đổi rất mạnh giữa các host dùng cùng trọng số model.” Nếu bạn route các model rẻ qua OpenRouter, hãy để ý tag :exacto — chỉ cần đổi provider âm thầm cũng có thể biến một model rẻ ổn định thành một vòng lặp retry đắt đỏ chỉ sau một đêm.
Khi nào nên dùng từng model
- Gemini Flash-Lite: Heartbeat, keep-alive ping, hỏi đáp đơn giản. Không dùng cho multi-step tool calling.
- MiniMax M2.5/M2.7: Model chính cho các tác vụ code hằng ngày của bạn. SWE-Pro 56,22, Terminal-Bench 2 57,0% với chi phí chỉ bằng một phần nhỏ so với Sonnet.
- Claude Haiku 4.5: Fallback đáng tin khi model rẻ bị vấp ở lệnh gọi công cụ. Độ tin cậy tool calling rất tốt, rẻ hơn Sonnet khoảng 3 lần.
- Claude Sonnet 4.6: Công việc agentic nhiều bước, phức tạp. Đây là nơi bạn thực sự thấy giá trị tương xứng.
- Claude Opus: Chỉ để dành cho bài toán khó nhất. Đừng để nó trở thành mặc định cho bất cứ thứ gì.
(Giá model thay đổi thường xuyên — hãy kiểm tra mức giá hiện tại trên OpenRouter hoặc trang provider trực tiếp trước khi chốt cấu hình.)
Những khoản “rút máu” token ẩn mà hầu hết hướng dẫn đều bỏ qua
Người dùng trên diễn đàn báo rằng chỉ cần tắt vài tính năng nhất định là chi phí giảm mạnh, nhưng chưa có hướng dẫn nào tôi thấy tổng hợp đầy đủ toàn bộ các khoản drain ẩn cùng tác động token thực tế của chúng. Bóc tách đầy đủ như sau:
| Khoản drain ẩn | Chi phí token mỗi lần xảy ra | Cách khắc phục | Khóa cấu hình |
|---|---|---|---|
| Heartbeat mặc định chạy trên Opus | ~100.000 token/lần nếu không cô lập | Override sang Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Sinh sub-agent | ~20.000 token mỗi lần sinh trước khi làm gì | Route sub-agent sang Haiku | subagents.model |
| Load toàn bộ context codebase | ~3.000–15.000 token cho mỗi lần auto-explore | Dùng .clawignore cho node_modules, dist, lockfiles | .clawrules + .clawignore |
| Tự tóm tắt memory | ~500–2.000 token/session | Tắt hoặc giảm tần suất | memory: false hoặc memory.max_context_tokens |
| Tích lũy lịch sử hội thoại | ~500+ token/lượt (cộng dồn) | Tạo session mới giữa các việc không liên quan | Kỷ luật dùng /clear |
| Overhead tool của MCP server | ~7.000 token cho 4 server; 50.000+ cho 5+ | Giữ MCP ở mức tối thiểu | Gỡ các MCP không dùng |
| Khởi tạo skill/plugin | 200–1.000 token cho mỗi skill được load | Tắt skill không dùng | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7 lần chi phí session tiêu chuẩn | Chỉ dùng khi thực sự cần song song | Ưu tiên tuần tự |
Khoản hao hụt từ heartbeat xứng đáng có một lưu ý riêng. Theo mặc định, heartbeat sẽ chạy trên model chính (Opus) mỗi 30 phút. Đặt isolatedSession: true sẽ giảm từ khoảng ~100.000 token mỗi lần xuống còn 2.000–5.000 token — tức giảm 95–98% ở riêng bucket này.
Ba cú tối ưu nhanh tiết kiệm token nhất trong chưa đến hai phút
Cả ba đều gần như không rủi ro và đều làm dưới hai phút:
-
/cleargiữa các tác vụ không liên quan (5 giây). Đây là cách tiết kiệm token lớn nhất. Đồng thuận từ diễn đàn ước tính giảm 50–70% chỉ bằng việc xóa lịch sử session trước khi làm việc mới. Nhớ bucket Messages 185k token từ dump /context chứ?/clearsẽ xóa nó. -
/model haiku-4.5cho việc vặt (10 giây). Chuyển model đúng lúc mang lại giảm chi phí 60–80% cho các tác vụ thường ngày. Haiku xử lý rất ổn đa số việc code đơn giản, tra file, và viết commit message. -
Giảm
.clawrulesxuống dưới 200 dòng + thêm.clawignore(90 giây). File rules của bạn được load ở mọi tin nhắn. Nếu 200 dòng thì khoảng 1.500–2.000 token mỗi lượt; nếu 1.000 dòng thì 8.000–10.000 token cứ thế “ăn” vào mọi request. Kết hợp thêm.clawignoreloạinode_modules/,dist/, lockfile và code sinh ra, một nhà phát triển cho biết chỉ riêng kỷ luật này đã giúp giảm 92% token.
Từng bước: ba cấu hình sẵn sàng sao chép để cắt mạnh mức dùng token của OpenClaw

Dưới đây là ba cấu hình openclaw.json hoàn chỉnh, có chú thích — từ mức “chỉ cần bắt đầu” đến “stack tối ưu toàn diện.” Mỗi cấu hình đều có comment trong dòng và ước tính chi phí hàng tháng.
Trước khi bắt đầu:
- Độ khó: Cơ bản (Config A) → Trung bình (Config B) → Nâng cao (Config C)
- Thời gian cần thiết: ~5 phút cho Config A, ~15 phút cho Config C
- Bạn cần gì: OpenClaw đã cài, một trình soạn thảo văn bản, quyền truy cập
~/.openclaw/openclaw.json
Config A: Cơ bản — chỉ cần tiết kiệm tiền
Năm dòng. Không phức tạp. Đổi model mặc định từ Opus sang Sonnet, tắt overhead memory, và cô lập heartbeat sang Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // trước là Opus — tiết kiệm ngay 3-5x
"heartbeat": {
"every": "55m", // khớp TTL cache 1h để tối đa cache hit
"model": "anthropic/claude-haiku-4-5", // dùng Haiku cho ping, không phải Opus
"isolatedSession": true // ~100k → 2-5k token mỗi lần
}
}
},
"memory": { "enabled": false } // tiết kiệm ~500-2k token/session
}
Sau khi áp dụng, bạn nên thấy gì: Chạy /status trước và sau. Chi phí mỗi request sẽ giảm rõ rệt, và các mục heartbeat trong trang OpenRouter Activity của bạn sẽ hiện Haiku thay vì Opus.
| Tầng sử dụng | Mặc định (Opus) | Config A (Sonnet + heartbeat Haiku) | Tiết kiệm |
|---|---|---|---|
| Nhẹ (~10 q/ngày) | ~$100 | ~$35 | 65% |
| Trung bình (~50 q/ngày) | ~$500 | ~$250 | 50% |
| Nhiều (~200 q/ngày) | ~$1,750 | ~$900 | 49% |
Config B: Trung cấp — routing thông minh 3 tầng
Sonnet làm model chính cho công việc thật. Haiku cho sub-agent và compaction. Gemini Flash-Lite làm fallback giá rẻ khi Claude bị throttle. Chuỗi fallback tự động xử lý khi provider gặp sự cố.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // nếu Sonnet bị throttle
"google/gemini-2.5-flash-lite" // phương án dự phòng siêu rẻ
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 phút < TTL cache 1h = có cache hit
"model": "google/gemini-2.5-flash-lite", // rẻ như vài xu cho mỗi ping
"isolatedSession": true,
"lightContext": true // ngữ cảnh tối thiểu trong heartbeat
},
"subagents": {
"maxConcurrent": 4, // giảm từ mặc định 8
"model": "anthropic/claude-haiku-4-5" // sub-agent không cần Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // tóm tắt compaction qua Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Kết quả kỳ vọng: Các mục sub-agent trong log của bạn sẽ hiển thị giá Haiku. Heartbeat gần như không tốn chi phí. Chuỗi fallback giúp một lần Claude outage không làm treo session của bạn — nó sẽ hạ cấp mượt sang Gemini.
| Tầng sử dụng | Mặc định | Config B | Tiết kiệm |
|---|---|---|---|
| Nhẹ | ~$100 | ~$20 | 80% |
| Trung bình | ~$500 | ~$150 | 70% |
| Nhiều | ~$1,750 | ~$500 | 71% |
Config C: Power user — stack tối ưu toàn diện
Gán model riêng cho từng sub-agent, pin context compaction vào Haiku, route tác vụ vision sang Gemini Flash, .clawrules + .clawignore chặt chẽ, tắt các skill không dùng. Đây là cấu hình đưa bạn về vùng tiết kiệm 85–90%.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // provider khác làm backup
"minimax/minimax-m2-7", // fallback rẻ cho công việc hằng ngày
"anthropic/claude-haiku-4-5" // lựa chọn cuối cùng
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // không chạy heartbeat qua đêm
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // giảm từ mặc định 20000
"imageModel": "google/gemini-3-flash" // tác vụ vision qua model rẻ
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // memory tối thiểu
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Ví dụ override model cho từng sub-agent — dán vào ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Chạy lint/format và áp dụng các sửa lỗi đơn giản
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore tối thiểu nhưng đủ dùng — riêng phần này đã giúp giảm bootstrap điển hình từ 150k ký tự xuống còn khoảng 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Tầng sử dụng | Mặc định | Config C | Tiết kiệm |
|---|---|---|---|
| Nhẹ | ~$100 | ~$12 | 88% |
| Trung bình | ~$500 | ~$90 | 82% |
| Nhiều | ~$1,750 | ~$220 | 87% |
Các con số này khớp với hai báo cáo thực tế từ người dùng độc lập: trường hợp của Praney Behl từ $600–750/tháng → $3–4/ngày (giảm 90%), và các case study của LaoZhang cho thấy $943 → $347 (63%), $1,750 → $1,000 (64%), $200 → $70 (65%) với mức tối ưu một phần.
Dùng lệnh /model để điều khiển mức dùng token của OpenClaw ngay trong lúc làm việc
Lệnh /model đổi model đang hoạt động cho lượt tiếp theo nhưng giữ nguyên toàn bộ ngữ cảnh hội thoại — không reset, không mất lịch sử. Đây là thói quen hằng ngày có tác dụng cộng dồn lên mức tiết kiệm theo thời gian.
Quy trình thực tế:
- Đang xử lý một refactor nhiều file rối rắm? Giữ Sonnet.
- Chỉ hỏi nhanh “regex này làm gì?”?
/model haiku, hỏi xong rồi/model sonnetđể quay lại. - Cần commit message hoặc chỉnh tài liệu cho gọn?
/model flash-lite, xong.
Bạn có thể tạo alias trong openclaw.json dưới commands.aliases để map tên ngắn (haiku, sonnet, opus, flash) thành chuỗi provider đầy đủ. Tiết kiệm vài phím gõ cho mỗi lần chuyển.
Tính toán rất đơn giản: 50 truy vấn/ngày trên Sonnet vào khoảng 3 USD/ngày. Cùng 50 truy vấn nhưng phân bổ 70/20/10 giữa Haiku/Sonnet/Opus thì khoảng 1,10 USD/ngày. Tính theo tháng, đó là từ 90 USD còn 33 USD — rẻ hơn 63% mà không đổi công cụ, chỉ đổi thói quen.
Bonus: Theo dõi giá model OpenClaw giữa các provider bằng Thunderbit
Theo dõi giá model giữa các provider bằng AI Get Started Free
Vì có quá nhiều model và provider — OpenRouter, Anthropic API trực tiếp, Google AI Studio, DeepSeek, MiniMax — giá cả thay đổi liên tục. Anthropic có thể giảm giá output của Opus đến gần 67% chỉ sau một đêm. Google từng cắt giới hạn free-tier của Gemini 50–80% vào tháng 12/2025. Cố giữ một bảng giá tĩnh bằng tay là cuộc chiến rất khó thắng.
Thunderbit giải quyết việc này mà không cần viết scraping code. Đây là một Chrome extension dạng AI web scraper, được thiết kế đúng cho kiểu trích xuất dữ liệu có cấu trúc như thế này.
Quy trình tôi dùng:
- Mở trang model của OpenRouter trong Chrome và bấm “AI Suggest Fields” của Thunderbit. Nó sẽ đọc trang và đề xuất các cột — tên model, giá input, giá output, cửa sổ context, provider.
- Nhấn Scrape, rồi xuất thẳng sang Google Sheets.
- Thiết lập lịch scrape bằng tiếng Anh tự nhiên — “mỗi thứ Hai lúc 9 giờ sáng, scrape lại danh sách model OpenRouter” — và nó sẽ chạy tự động trên cloud.
Từ đó trở đi, bộ theo dõi giá cá nhân của bạn sẽ tự cập nhật. Bất kỳ model nào đột nhiên rẻ hơn 30% — hoặc bất kỳ provider nào có tag Exacto — sẽ xuất hiện trong bảng tính sáng thứ Hai mà bạn không phải làm gì cả. Chúng tôi có viết thêm về AI data extraction cho doanh nghiệp trên blog.
Nếu bạn muốn so sánh giá giữa các trang provider trực tiếp (Anthropic, Google, DeepSeek), tính năng scrape subpage của Thunderbit sẽ đi theo từng link model sang trang chi tiết và lấy mức giá theo từng provider — rất hữu ích khi bạn muốn biết route Kimi K2.5 qua OpenRouter có rẻ hơn đi thẳng qua NVIDIA Build hay không. Xem giá Thunderbit để biết gói miễn phí và chi tiết plan.
Những điểm chính cần nhớ để cắt giảm mức dùng token của OpenClaw
Khung tư duy: Hiểu → Theo dõi → Route → Tối ưu.
Các hành động có tác động lớn nhất, xếp theo thứ tự:
- Đừng mặc định dùng Opus. Đổi model chính sang Sonnet hoặc MiniMax M2.7. Riêng bước này đã giúp giảm chi phí 3–5 lần.
- Cô lập heartbeat. Đặt
isolatedSession: truevà route heartbeat sang Gemini Flash-Lite. Một khoản hao ~100k token sẽ biến thành khoảng 2–5k. - Route sub-agent sang Haiku. Mỗi lần sinh sub-agent sẽ load khoảng 20k token ngữ cảnh trước khi làm gì. Đừng để việc đó diễn ra trên Opus.
- Dùng
/clearthường xuyên. Miễn phí, chỉ mất 5 giây, và đồng thuận từ cộng đồng cho rằng đây là hành động tiết kiệm hiệu quả nhất. - Thêm
.clawignore. Loạinode_modules, lockfile và artifact build ra khỏi context bootstrap sẽ giảm đáng kể tải ngữ cảnh. - Theo dõi bằng
/context detailtrước và sau khi đổi cấu hình. Không đo được thì không cải thiện được.
Model rẻ nhất còn tùy vào tác vụ. Gemini Flash-Lite cho heartbeat. MiniMax M2.7 cho code hằng ngày. Haiku cho gọi công cụ đáng tin cậy. Sonnet cho công việc nhiều bước phức tạp. Opus chỉ dành cho những bài toán thật sự khó — và không gì khác.
Phần lớn độc giả có thể đạt mức tiết kiệm 50–70% chỉ sau một buổi chiều với Config A hoặc B. Mức 85–90% đầy đủ đòi hỏi ghép tất cả lại — routing model, xử lý các drain ẩn, .clawignore, kỷ luật session — nhưng điều đó hoàn toàn làm được, và hiệu quả sẽ bền.
Câu hỏi thường gặp
1. OpenClaw tốn bao nhiêu mỗi tháng?
Điều này phụ thuộc hoàn toàn vào cấu hình, khối lượng sử dụng và lựa chọn model. Người dùng nhẹ (~10 truy vấn/ngày) thường chi khoảng 5–30 USD/tháng nếu tối ưu, hoặc hơn 100 USD nếu để mặc định. Người dùng trung bình (~50 truy vấn/ngày) thường ở mức 90–400 USD/tháng. Người dùng nhiều có thể chạm 600–2.000+ USD/tháng nếu để mặc định — một trường hợp cực đoan được ghi nhận là 5.623 USD chỉ trong một tháng. Telemetry nội bộ của Anthropic cho thấy mức trung vị khoảng 13 USD/nhà phát triển/ngày hoạt động.
2. Model rẻ nhất của OpenClaw mà vẫn ổn cho lập trình là gì?
MiniMax M2.5/M2.7 là lựa chọn daily driver tốt nhất cho mục đích chung — độ tin cậy gọi công cụ ổn, SWE-Pro 56,22, với giá khoảng 0,28/1,10 USD cho mỗi triệu token. Với heartbeat và tra cứu đơn giản, Gemini 2.5 Flash-Lite ở mức 0,10/0,40 USD gần như không có đối thủ. Claude Haiku 4.5 ở mức 1/5 USD là fallback tầm trung đáng tin cậy khi bạn cần gọi công cụ tốt mà không phải trả giá Sonnet.
3. Tôi có thể dùng model free-tier với OpenClaw không?
Về mặt kỹ thuật là có. GPT-OSS-120B miễn phí qua tag :free của OpenRouter và NVIDIA Build. Gemini Flash-Lite có free tier (15 RPM, 1.000 request/ngày). DeepSeek tặng 5 triệu token miễn phí khi đăng ký. Nhưng free tier thường có giới hạn rate rất gắt, tốc độ chậm và độ sẵn có không ổn định. Các model trả phí rẻ — chỉ vài xu cho mỗi triệu token — đáng tin cậy hơn nhiều cho nhu cầu dùng thường xuyên.
4. Chuyển model giữa chừng bằng /model có làm mất ngữ cảnh không?
Không. /model giữ nguyên toàn bộ context của session — lượt tiếp theo sẽ được route sang model mới nhưng vẫn mang theo đầy đủ lịch sử. Điều này được xác nhận trong tài liệu khái niệm của OpenClaw và hoạt động tương tự trong Claude Code. Bạn có thể thoải mái đổi qua lại giữa Haiku cho câu hỏi nhanh và Sonnet cho việc phức tạp mà không mất gì.
5. Cách nhanh nhất để giảm hóa đơn OpenClaw hôm nay là gì?
Gõ /clear giữa các tác vụ không liên quan. Cách này miễn phí, mất năm giây, và xóa lịch sử hội thoại vốn bị gửi lại ở mọi API call. Một session thực tế cho thấy có 185.000 token lịch sử tin nhắn tích lũy — tất cả đều bị truyền lại và bị tính phí ở mọi lượt. Xóa sạch trước khi bắt đầu việc mới là thói quen có ROI cao nhất bạn có thể xây.
Dùng Thunderbit để AI Web Scraping Get Started Free




