

Dữ liệu web đang bùng nổ, kéo theo áp lực phải bắt kịp cũng tăng lên từng ngày. Tôi đã tận mắt thấy nhiều đội sales và vận hành dành nhiều thời gian hơn để vật lộn với bảng tính, copy-paste từ website, thay vì thật sự ngồi ra quyết định. Theo Salesforce, hiện nay nhân viên sales có thể dành tới 70% thời gian cho các việc không trực tiếp bán hàng, còn Asana cho biết 60% công việc chỉ là “làm việc về công việc”. Đó là quá nhiều giờ bị lãng phí cho việc thu thập dữ liệu thủ công — những giờ mà lẽ ra có thể dùng để chốt đơn hoặc triển khai chiến dịch.
Tin vui là: web scraping đã trở thành xu hướng rất phổ biến, và bạn không cần phải là lập trình viên mới tận dụng được sức mạnh của nó. Ruby từ lâu đã là lựa chọn quen thuộc để tự động hóa việc trích xuất dữ liệu web, nhưng khi kết hợp với các AI web scraper hiện đại như Thunderbit, bạn sẽ có cả hai thế giới: sự linh hoạt cho người biết code và sự đơn giản không cần code cho tất cả mọi người khác. Dù bạn là marketer, quản lý ecommerce hay đơn giản là đã quá ngán việc copy-paste không dứt, hướng dẫn này sẽ cho bạn thấy cách làm chủ web scraping với Ruby và AI — hoàn toàn không cần code.
Dùng thử Thunderbit để Web Scraping không cần code
Web Scraping với Ruby là gì? Cửa ngõ dẫn đến tự động hóa dữ liệu
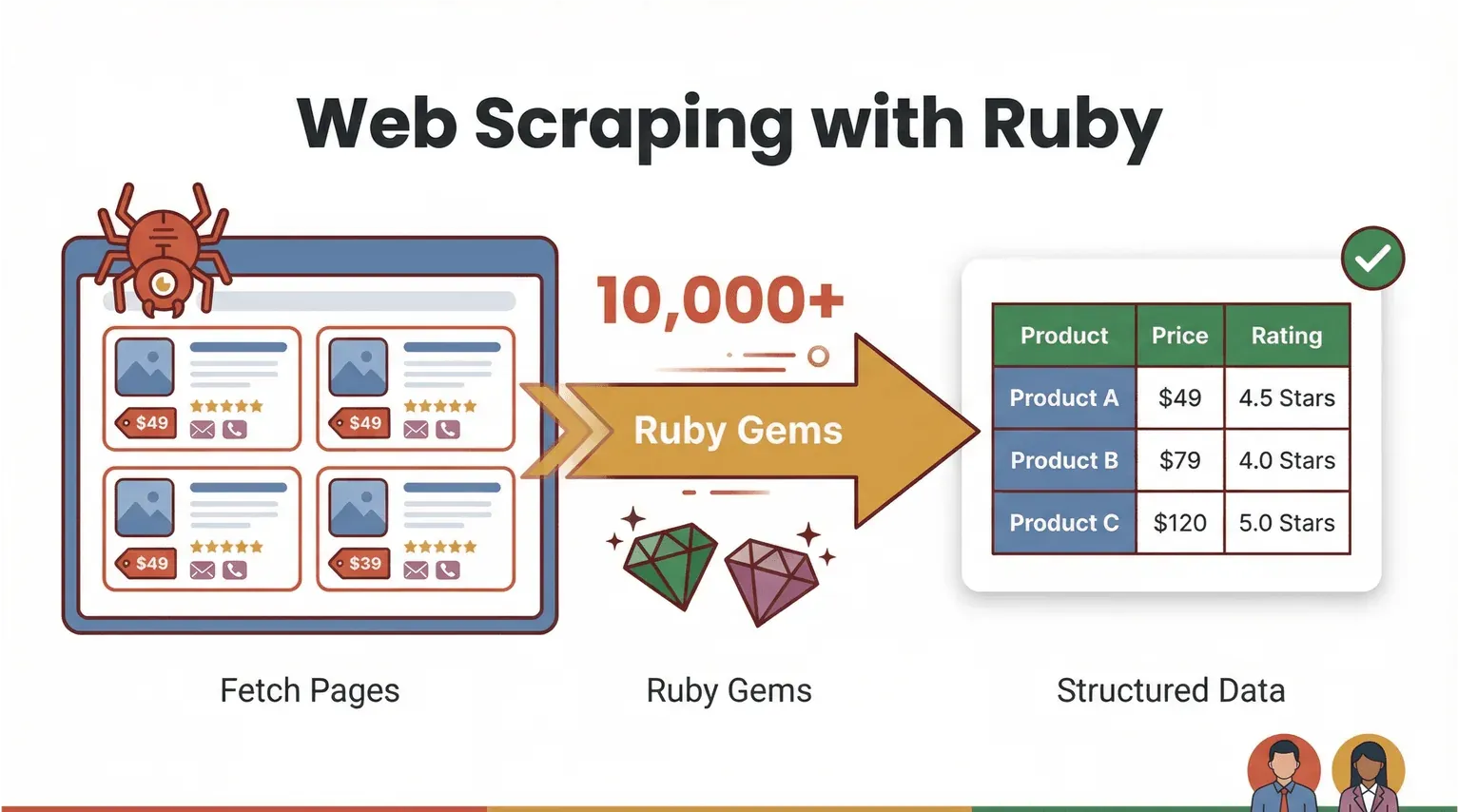
Hãy bắt đầu từ những điều cơ bản. Web scraping đơn giản là dùng phần mềm để lấy dữ liệu từ trang web và trích xuất thông tin cụ thể — như giá sản phẩm, thông tin liên hệ hoặc đánh giá — rồi đưa vào định dạng có cấu trúc (ví dụ CSV hoặc Excel). Với Ruby, web scraping vừa mạnh mẽ vừa dễ tiếp cận. Ngôn ngữ này nổi tiếng vì cú pháp dễ đọc và hệ sinh thái “gem” (thư viện) cực kỳ phong phú, giúp tự động hóa trở nên nhẹ nhàng hơn rất nhiều (Ruby Programming Language).
Vậy “web scraping với Ruby” trên thực tế trông như thế nào? Hãy hình dung bạn muốn lấy toàn bộ tên sản phẩm và giá từ một website ecommerce. Với Ruby, bạn có thể viết một đoạn script để:
- Tải trang web về (dùng thư viện như HTTParty)
- Phân tích HTML để tìm dữ liệu cần lấy (Nokogiri)
- Xuất dữ liệu ra bảng tính hoặc cơ sở dữ liệu
Nhưng điểm thú vị là: bạn không phải lúc nào cũng cần viết code. Các công cụ web scraper không cần code được hỗ trợ bởi AI như Thunderbit giờ đây có thể gánh phần việc nặng — đọc trang web, nhận diện trường dữ liệu và xuất bảng dữ liệu sạch chỉ bằng vài cú click. Ruby vẫn là “chất keo tự động hóa” rất tốt cho các quy trình tùy biến, nhưng AI web scraper đang mở ra cơ hội để cả người dùng kinh doanh cũng tham gia cuộc chơi.
Data Scraping là gì? Get Started Free
Vì sao Web Scraping với Ruby lại quan trọng với các đội kinh doanh

Nói thẳng nhé: chẳng ai muốn dành cả ngày để copy và paste dữ liệu. Nhu cầu trích xuất dữ liệu web tự động đang tăng vọt, và điều đó hoàn toàn có lý do. Đây là cách web scraping với Ruby (và các công cụ AI) đang thay đổi cách các doanh nghiệp vận hành:
- Tạo lead: Lấy ngay thông tin liên hệ từ danh bạ hoặc LinkedIn cho pipeline sales.
- Theo dõi giá đối thủ: Cập nhật biến động giá trên hàng trăm SKU ecommerce — không còn phải kiểm tra thủ công nữa.
- Xây dựng catalog sản phẩm: Tổng hợp thông tin và hình ảnh sản phẩm cho cửa hàng hoặc marketplace của bạn.
- Nghiên cứu thị trường: Thu thập review, rating hoặc bài viết tin tức để phân tích xu hướng.
Hiệu quả đầu tư (ROI) rất rõ: các đội tự động hóa thu thập dữ liệu web tiết kiệm được hàng giờ mỗi tuần, giảm sai sót và có dữ liệu mới, đáng tin cậy hơn. Ví dụ trong ngành sản xuất, 70% doanh nghiệp vẫn nhập dữ liệu thủ công, dù lượng dữ liệu đã tăng gấp đôi chỉ trong hai năm. Đây là một cơ hội rất lớn cho tự động hóa.
Dưới đây là tóm tắt nhanh về giá trị mà web scraping với Ruby và các công cụ AI mang lại:
| Ứng dụng | Nỗi đau khi làm thủ công | Lợi ích của tự động hóa | Kết quả thường thấy |
|---|---|---|---|
| Tạo lead | Copy email từng cái một | Quét hàng nghìn dữ liệu chỉ trong vài phút | Nhiều lead hơn gấp 10 lần, ít việc tay chân hơn |
| Theo dõi giá | Kiểm tra website mỗi ngày | Tự động lấy giá theo lịch | Nắm bắt giá theo thời gian thực |
| Xây dựng catalog | Nhập dữ liệu thủ công | Trích xuất hàng loạt & định dạng tự động | Ra mắt nhanh hơn, ít lỗi hơn |
| Nghiên cứu thị trường | Đọc review bằng tay | Quét và phân tích ở quy mô lớn | Insight sâu hơn, cập nhật hơn |
Và lợi ích không chỉ là tốc độ — tự động hóa còn giúp giảm lỗi và tăng tính nhất quán của dữ liệu, điều cực kỳ quan trọng khi 58% lãnh đạo cho biết quyết định của họ dựa trên dữ liệu thiếu chính xác hoặc không nhất quán.
Khám phá các giải pháp Web Scraping: Ruby script vs. AI Web Scraper
Vậy nên tự viết Ruby script hay dùng một web scraper không cần code được hỗ trợ bởi AI? Hãy cùng bóc tách từng lựa chọn.
Ruby Scripting: Toàn quyền kiểm soát, nhưng cần bảo trì nhiều hơn
Hệ sinh thái Ruby có rất nhiều gem phục vụ cho mọi nhu cầu scraping:
- Nokogiri: Công cụ phổ biến nhất để phân tích HTML và XML.
- HTTParty: Dùng để tải trang web và API.
- Mechanize: Phù hợp với các trang cần cookie, form và điều hướng.
- Selenium / Watir: Dùng để tự động hóa trình duyệt thật (rất hợp với site nhiều JavaScript).
Với Ruby script, bạn có toàn bộ quyền kiểm soát — logic tùy biến, làm sạch dữ liệu và tích hợp với hệ thống riêng. Nhưng đổi lại, bạn cũng phải gánh phần bảo trì: khi website đổi giao diện, script có thể hỏng. Và nếu bạn chưa quen với code, bạn sẽ cần một khoảng thời gian để học.
AI Web Scraper & công cụ không cần code: Nhanh, dễ dùng và linh hoạt
Những công cụ web scraper không cần code hiện đại như Thunderbit đã thay đổi hoàn toàn cách làm. Thay vì viết code, bạn chỉ cần:
- Mở tiện ích Chrome
- Click “AI Suggest Fields” để AI tự nhận diện dữ liệu cần lấy
- Nhấn “Scrape” và xuất dữ liệu
AI của Thunderbit có thể thích ứng với bố cục web thay đổi, xử lý subpage (như trang chi tiết sản phẩm), và xuất trực tiếp sang Excel, Google Sheets, Airtable hoặc Notion. Đây là lựa chọn lý tưởng cho người dùng kinh doanh muốn có kết quả nhanh mà không phải đau đầu.
Đây là bảng so sánh trực quan:
| Cách tiếp cận | Ưu điểm | Nhược điểm | Phù hợp nhất với |
|---|---|---|---|
| Ruby Scripting | Toàn quyền kiểm soát, logic tùy biến, linh hoạt | Đường cong học tập cao hơn, cần bảo trì | Lập trình viên, người dùng nâng cao |
| AI Web Scraper | Không cần code, thiết lập nhanh, thích ứng với thay đổi | Ít kiểm soát chi tiết hơn, có một số giới hạn | Người dùng kinh doanh, đội vận hành |
Xu hướng khá rõ ràng: khi website ngày càng phức tạp (và phòng thủ nhiều hơn), AI web scraper đang dần trở thành lựa chọn mặc định cho phần lớn quy trình kinh doanh.
Bắt đầu như thế nào: Thiết lập môi trường Web Scraping bằng Ruby
Nếu bạn muốn thử viết Ruby script, hãy cùng thiết lập môi trường. Tin tốt là: Ruby rất dễ cài đặt và chạy tốt trên Windows, macOS và Linux.
Bước 1: Cài Ruby
- Windows: Tải RubyInstaller và làm theo hướng dẫn. Nhớ include MSYS2 để build native extensions (cần cho các gem như Nokogiri).
- macOS/Linux: Dùng rbenv để quản lý phiên bản. Trong Terminal:
brew install rbenv ruby-build
rbenv install 4.0.4
rbenv global 4.0.4
(Hãy kiểm tra trang tải Ruby để xem phiên bản ổn định mới nhất.)
Bước 2: Cài Bundler và các gem thiết yếu
Bundler giúp quản lý dependencies:
gem install bundler
Tạo file Gemfile cho dự án của bạn:
source 'https://rubygems.org'
gem 'nokogiri'
gem 'httparty'
Sau đó chạy:
bundle install
Điều này giúp môi trường của bạn nhất quán và sẵn sàng để scraping.
Bước 3: Kiểm tra thiết lập
Thử chạy đoạn này trong IRB (Ruby interactive shell):
require 'nokogiri'
require 'httparty'
puts Nokogiri::VERSION
Nếu bạn thấy số phiên bản hiện ra, tức là mọi thứ đã sẵn sàng!
Từng bước: Xây dựng web scraper Ruby đầu tiên của bạn
Hãy cùng đi qua một ví dụ thực tế — scraping dữ liệu sản phẩm từ Books to Scrape, một website được tạo riêng cho mục đích thực hành scraping.
Đây là một Ruby script đơn giản để trích xuất tiêu đề sách, giá và trạng thái còn hàng:
require "net/http"
require "uri"
require "nokogiri"
require "csv"
BASE_URL = "https://books.toscrape.com/"
def fetch_html(url)
uri = URI.parse(url)
res = Net::HTTP.get_response(uri)
raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
res.body
end
def scrape_list_page(list_url)
html = fetch_html(list_url)
doc = Nokogiri::HTML(html)
products = doc.css("article.product_pod").map do |pod|
title = pod.css("h3 a").first["title"]
price = pod.css(".price_color").text.strip
stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
{ title: title, price: price, stock: stock }
end
next_rel = doc.css("li.next a").first&.[]("href")
next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
[products, next_url]
end
rows = []
url = "#{BASE_URL}catalogue/page-1.html"
while url
products, url = scrape_list_page(url)
rows.concat(products)
end
CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
end
puts "Wrote #{rows.length} rows to books.csv"
Script này sẽ tải từng trang, phân tích HTML, trích xuất dữ liệu và ghi vào file CSV. Bạn có thể mở books.csv trong Excel hoặc Google Sheets.
Các lỗi thường gặp:
- Nếu gặp lỗi thiếu gem, hãy kiểm tra lại Gemfile và chạy
bundle install. - Với những website dùng JavaScript để tải dữ liệu, bạn sẽ cần công cụ tự động hóa trình duyệt như Selenium hoặc Watir.
Tăng tốc Ruby scraping với Thunderbit: AI Web Scraper trong thực tế
Bây giờ hãy nói về cách Thunderbit có thể đưa scraping của bạn lên một tầm cao mới — không cần code.
Thunderbit là một tiện ích Chrome AI web scraper cho phép bạn trích xuất dữ liệu có cấu trúc từ bất kỳ website nào chỉ trong hai cú click. Cách hoạt động như sau:
- Mở tiện ích Thunderbit trên trang bạn muốn scrape.
- Click “AI Suggest Fields.” AI của Thunderbit quét trang và gợi ý các cột tốt nhất để lấy dữ liệu (như “Product Name,” “Price,” “Stock”).
- Click “Scrape.” Thunderbit lấy dữ liệu, xử lý phân trang và thậm chí đi qua subpage nếu bạn cần thêm chi tiết.
- Xuất dữ liệu trực tiếp sang Excel, Google Sheets, Airtable hoặc Notion.
Điểm làm Thunderbit khác biệt là khả năng xử lý các trang web phức tạp, động — không cần selector dễ vỡ hay code. Và nếu bạn muốn kết hợp quy trình, bạn có thể dùng Thunderbit để lấy dữ liệu trước, rồi dùng Ruby script để xử lý hoặc làm giàu dữ liệu tiếp.
Mẹo hay: Tính năng scrape subpage của Thunderbit là cứu cánh cho các đội ecommerce và bất động sản. Hãy scrape danh sách link sản phẩm, rồi để Thunderbit tự truy cập từng link để lấy thông số chi tiết, hình ảnh hoặc review — giúp làm giàu dữ liệu một cách tự động.
Cách Scrape bất kỳ website nào bằng AI Get Started Free
Ví dụ thực tế: Scrape dữ liệu sản phẩm và giá ecommerce bằng Ruby và Thunderbit
Hãy ghép mọi thứ lại với nhau bằng một quy trình thực tế dành cho đội ecommerce.
Tình huống: Bạn muốn theo dõi giá đối thủ và thông tin sản phẩm trên hàng trăm SKU.
Bước 1: Dùng Thunderbit để scrape danh sách sản phẩm chính
- Mở trang listing sản phẩm của đối thủ.
- Khởi chạy Thunderbit, click “AI Suggest Fields” (ví dụ: Product Name, Price, URL).
- Click “Scrape” và xuất kết quả ra CSV.
Bước 2: Làm giàu dữ liệu bằng scrape subpage
- Trong Thunderbit, dùng tính năng “Scrape Subpages” để truy cập từng trang chi tiết sản phẩm và lấy thêm các trường như mô tả, tồn kho hoặc hình ảnh.
- Xuất bảng dữ liệu đã làm giàu.
Bước 3: Xử lý hoặc phân tích bằng Ruby
- Dùng Ruby script để làm sạch, chuyển đổi hoặc phân tích dữ liệu tiếp. Ví dụ, bạn có thể muốn:
- Chuyển giá sang cùng một loại tiền
- Lọc các sản phẩm hết hàng
- Tạo thống kê tổng hợp
Dưới đây là một đoạn Ruby đơn giản để lọc sản phẩm còn hàng:
require 'csv'
rows = CSV.read('products.csv', headers: true)
in_stock = rows.select { |row| row['stock'].include?('In stock') }
CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
in_stock.each { |row| csv << row }
end
Kết quả:
Bạn đi từ các trang web thô sang một bảng dữ liệu sạch, có thể hành động ngay — sẵn sàng cho phân tích giá, lập kế hoạch tồn kho hoặc chạy chiến dịch marketing. Và tất cả được thực hiện mà không cần viết một dòng code scraping nào.
Không cần code, không vấn đề: Tự động hóa trích xuất dữ liệu web cho mọi người
Một trong những điều tôi thích nhất ở Thunderbit là nó trao quyền cho người dùng không chuyên. Bạn không cần biết Ruby, HTML hay CSS — chỉ cần mở tiện ích, để AI làm việc và xuất dữ liệu.
Đường cong học tập: Với Ruby script, bạn sẽ cần học những kiến thức cơ bản về lập trình và cấu trúc web. Với Thunderbit, thời gian thiết lập chỉ tính bằng phút, không phải ngày.
Tích hợp: Thunderbit xuất dữ liệu trực tiếp sang các công cụ mà đội kinh doanh đã quen dùng — Excel, Google Sheets, Airtable, Notion. Bạn thậm chí có thể lên lịch scrape định kỳ để theo dõi liên tục.
Phản hồi từ người dùng: Tôi đã thấy các đội marketing, sales ops và ecommerce dùng Thunderbit để tự động hóa đủ thứ, từ xây dựng danh sách lead đến theo dõi giá — mà không cần gọi IT.
Best practices: Kết hợp Ruby và AI Web Scraper để tự động hóa ở quy mô lớn
Muốn xây dựng một quy trình scraping bền vững và có khả năng mở rộng? Đây là những lời khuyên hàng đầu của tôi:
- Xử lý thay đổi website: AI web scraper như Thunderbit có thể tự thích ứng, nhưng nếu bạn dùng Ruby script thì hãy sẵn sàng cập nhật selector khi website thay đổi.
- Lên lịch scraping: Dùng tính năng lên lịch của Thunderbit cho các lần lấy dữ liệu định kỳ. Với Ruby, bạn có thể dùng cron job hoặc task scheduler.
- Xử lý theo lô: Với tập dữ liệu lớn, hãy chia scraping thành nhiều batch để tránh bị chặn hoặc làm quá tải hệ thống.
- Định dạng dữ liệu: Luôn làm sạch và kiểm tra dữ liệu trước khi phân tích — dữ liệu xuất từ Thunderbit đã có cấu trúc, nhưng Ruby script tùy chỉnh có thể cần kiểm tra thêm.
- Tuân thủ quy định: Chỉ scrape dữ liệu công khai, tôn trọng
robots.txtvà chú ý luật bảo mật dữ liệu (đặc biệt tại EU — GDPR áp dụng cho dữ liệu cá nhân được scrape). - Phương án dự phòng: Nếu một website quá phức tạp hoặc chặn scraping, hãy tìm API chính thức hoặc nguồn dữ liệu thay thế.
Khi nào nên dùng cái gì?
- Dùng Ruby script khi bạn cần toàn quyền kiểm soát, logic tùy biến hoặc tích hợp với hệ thống nội bộ.
- Dùng Thunderbit khi bạn cần tốc độ, dễ sử dụng và khả năng thích ứng — đặc biệt cho các tác vụ kinh doanh một lần hoặc định kỳ.
- Kết hợp cả hai cho các workflow nâng cao: để Thunderbit xử lý trích xuất, rồi dùng Ruby cho làm giàu dữ liệu, QA hoặc tích hợp.
Kết luận & điểm chính cần nhớ
Web scraping với Ruby từ lâu đã là một “siêu năng lực” để tự động hóa thu thập dữ liệu — nhưng giờ đây, với các AI web scraper như Thunderbit, sức mạnh đó đã đến gần với tất cả mọi người. Dù bạn là lập trình viên cần sự linh hoạt hay người dùng kinh doanh chỉ muốn có kết quả, bạn đều có thể tự động hóa việc trích xuất dữ liệu web, tiết kiệm hàng giờ làm thủ công và ra quyết định tốt hơn, nhanh hơn.
Đây là những điều tôi hy vọng bạn sẽ ghi nhớ:
- Ruby là công cụ tuyệt vời cho web scraping và tự động hóa — đặc biệt khi kết hợp với các gem như Nokogiri và HTTParty.
- AI web scraper như Thunderbit giúp người không biết code cũng có thể trích xuất dữ liệu, với các tính năng như “AI Suggest Fields” và scrape subpage.
- Kết hợp Ruby và Thunderbit cho bạn lợi ích kép: trích xuất nhanh, không cần code, cộng với khả năng tự động hóa và phân tích tùy biến.
- Tự động hóa thu thập dữ liệu web là chiến lược rất đáng làm cho đội sales, marketing và ecommerce — giảm công sức thủ công, tăng độ chính xác và mở ra insight mới.
Sẵn sàng bắt đầu chưa? Tải Thunderbit, thử một Ruby script đơn giản và xem bạn tiết kiệm được bao nhiêu thời gian. Và nếu muốn tìm hiểu sâu hơn, hãy xem Thunderbit Blog để có thêm hướng dẫn, mẹo và ví dụ thực tế.
Tải tiện ích Thunderbit trên Chrome
Câu hỏi thường gặp
1. Tôi có cần biết code để dùng Thunderbit cho web scraping không?
Không. Thunderbit được thiết kế cho người không chuyên. Chỉ cần mở tiện ích, click “AI Suggest Fields” và để AI xử lý phần còn lại. Bạn có thể xuất dữ liệu sang Excel, Google Sheets, Airtable hoặc Notion — không cần code.
2. Những lợi thế chính của việc dùng Ruby cho web scraping là gì?
Ruby có các thư viện mạnh như Nokogiri và HTTParty cho những workflow scraping linh hoạt, tùy biến. Đây là lựa chọn rất tốt cho lập trình viên muốn toàn quyền kiểm soát, logic riêng và tích hợp với hệ thống khác.
3. Tính năng “AI Suggest Fields” của Thunderbit hoạt động như thế nào?
AI của Thunderbit sẽ quét trang web, nhận diện những trường dữ liệu phù hợp nhất (như tên sản phẩm, giá, email) và gợi ý một bảng có cấu trúc cho bạn. Bạn có thể chỉnh sửa các cột trước khi scrape nếu cần.
4. Tôi có thể kết hợp Thunderbit với Ruby script cho workflow nâng cao không?
Hoàn toàn có thể. Nhiều đội dùng Thunderbit để trích xuất dữ liệu (đặc biệt từ các website phức tạp hoặc động), sau đó xử lý hoặc phân tích tiếp bằng Ruby script. Cách làm kết hợp này rất phù hợp cho báo cáo tùy biến hoặc làm giàu dữ liệu.
5. Web scraping có hợp pháp và an toàn cho mục đích kinh doanh không?
Web scraping là hợp pháp khi bạn thu thập dữ liệu công khai và tuân thủ điều khoản dịch vụ của website cũng như luật bảo mật. Luôn kiểm tra robots.txt và tránh scrape dữ liệu cá nhân nếu chưa có sự đồng ý phù hợp — đặc biệt với người dùng EU theo GDPR.
Bạn tò mò web scraping có thể thay đổi quy trình làm việc của mình như thế nào? Hãy thử gói miễn phí của Thunderbit hoặc tự tay chạy một Ruby script ngay hôm nay. Nếu gặp khó khăn, Thunderbit Blog và Kênh YouTube Thunderbit có rất nhiều hướng dẫn và mẹo giúp bạn làm chủ tự động hóa dữ liệu web — hoàn toàn không cần code.
Dùng thử Thunderbit AI Web Scraper Get Started Free
Tìm hiểu thêm




