Một “cuộc cách mạng thầm lặng” đang lan ra khắp các văn phòng—không phải nhờ bàn bóng bàn hay kombucha miễn phí đâu. Mà là nhờ làn sóng “easy web extract”: khả năng để bất kỳ ai, không chỉ dân dev, có thể trích xuất dữ liệu web dễ dàng trong vài phút thay vì mất vài ngày. Nếu bạn từng nhìn một trang web rồi thầm nghĩ “giá mà mình gom hết tên, giá, email… rồi thả thẳng vào spreadsheet”, thì yên tâm, bạn không cô đơn. Thực tế, tôi đã nói chuyện với sales, marketer và đội vận hành—ai cũng chung một câu: “Ủa sao tới giờ vẫn khó dữ vậy?”
Sự thật là nhu cầu về các phương pháp web scraping đơn giản đang bùng nổ. Theo , 65% tổ chức hiện đã dùng AI tạo sinh trong ít nhất một chức năng kinh doanh, và trích xuất dữ liệu web đang nhanh chóng trở thành một trong những ứng dụng “hot” nhất. Thị trường web scraping được dự báo chạm mốc , và người dùng doanh nghiệp—đặc biệt là những người không có nền tảng kỹ thuật—đang dẫn dắt làn sóng tìm kiếm công cụ giúp trích xuất dữ liệu “dễ như copy-paste”. Vậy “easy web extract” thực sự nghĩa là gì, và bạn có thể dùng nó để đơn giản hóa quy trình làm việc ra sao? Cùng mổ xẻ nhé.
Easy Web Extract cho người không chuyên: Không cần code, không đau đầu
Bắt đầu từ gốc rễ: “easy web extract” là gì? Nói đơn giản, đây là cách biến dữ liệu web vốn lộn xộn, thay đổi xoành xoạch thành bảng dữ liệu sạch, có cấu trúc—mà không cần viết một dòng code nào. Với người dùng doanh nghiệp không chuyên kỹ thuật, đây đúng kiểu “game changer”. Không còn phải nhờ IT, không còn vật lộn với Python script, và cũng không còn bỏ cuộc chỉ vì website đổi giao diện qua một đêm.
Vì sao chuyện này lại quan trọng ngay lúc này? Vì web ngày càng “động” (dynamic) hơn. Nhiều trang dùng cuộn vô hạn, pop-up và JavaScript phức tạp khiến các công cụ kiểu cũ dễ “toang” liên tục. Trong khi đó, áp lực phải ra insight nhanh cho các team kinh doanh thì chưa bao giờ căng như bây giờ. Trong , 98% tổ chức cho biết dữ liệu web công khai là yếu tố then chốt hoặc rất quan trọng đối với vận hành, và hơn một nửa dùng hằng ngày.
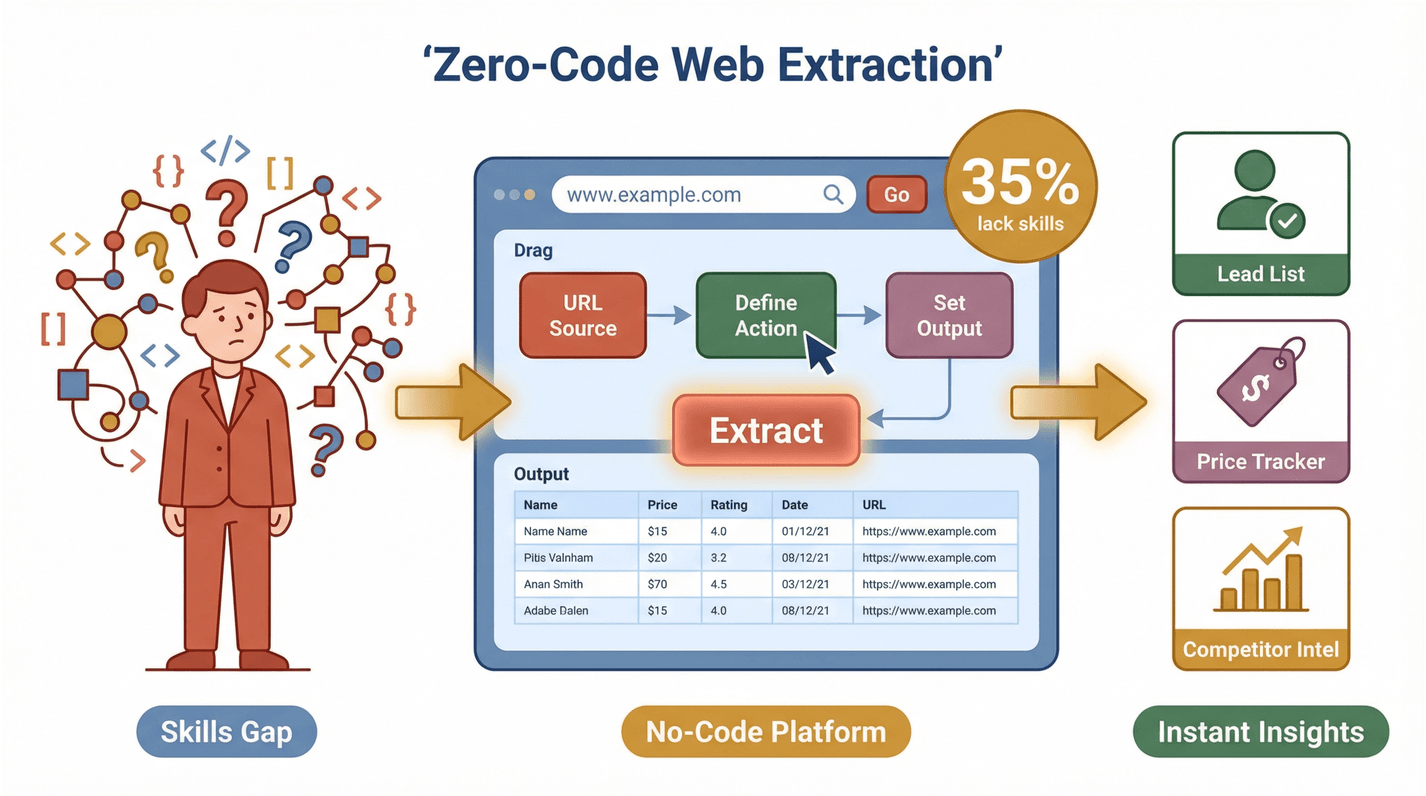
Nhưng mấu chốt nằm ở đây: phần lớn các team này không phải dân kỹ thuật. Một khảo sát gần đây cho thấy 35% tổ chức thiếu kỹ năng phù hợp để trích xuất dữ liệu web, và 33% không có công cụ phù hợp. Đây là “đất diễn” cực lớn cho các giải pháp no-code. Khi ai cũng có thể trích xuất và dùng dữ liệu web, năng suất sẽ bật lên rõ rệt—dù bạn đang build danh sách lead, theo dõi đối thủ hay canh giá.
Làn sóng No-code/Low-code: Vì sao đáng quan tâm
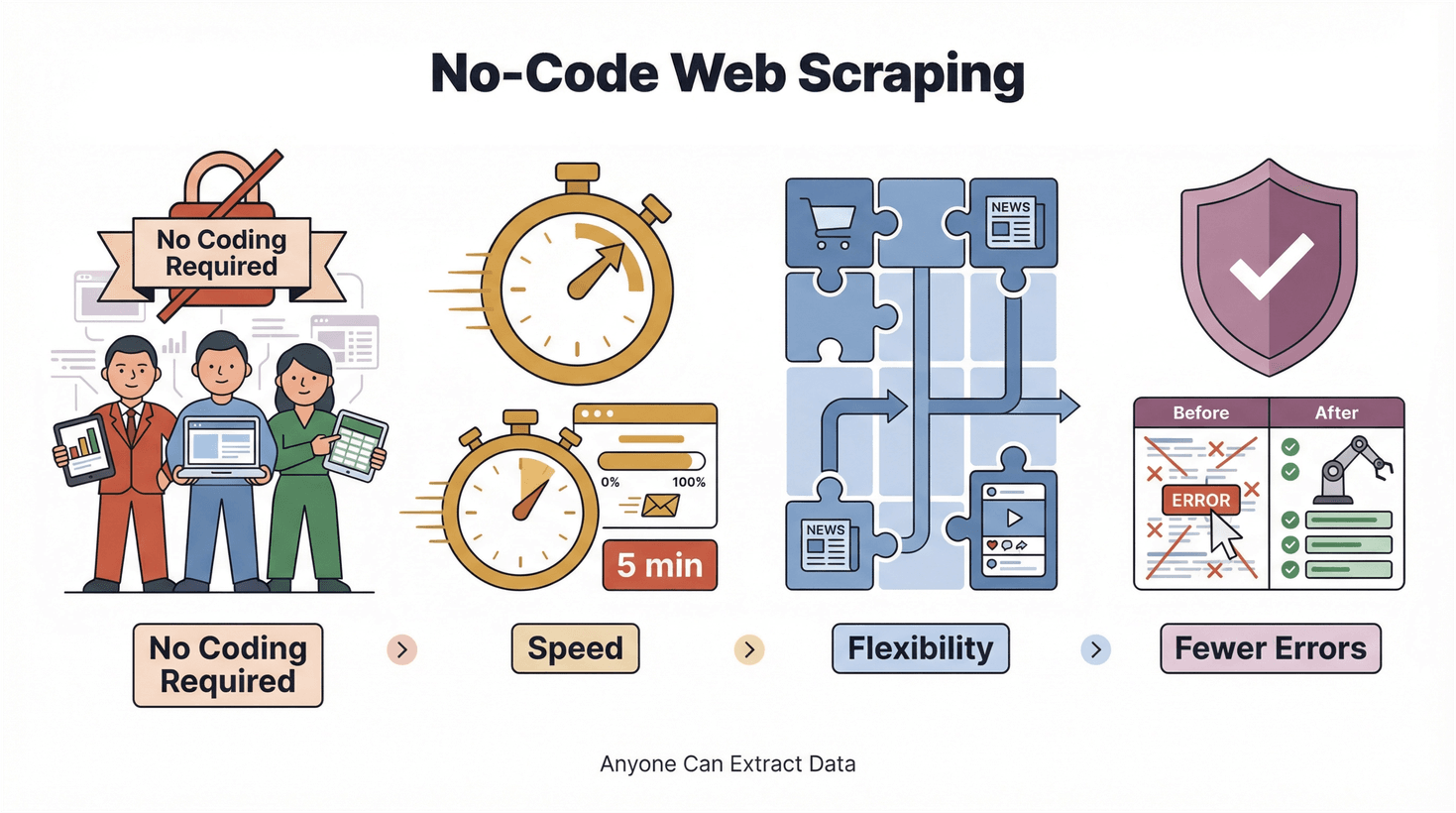
Sự phát triển của công cụ no-code và low-code nhằm “phổ cập” công nghệ. Đây không chỉ là khẩu hiệu kiểu Silicon Valley; nó là một thay đổi thật sự trong cách công việc được hoàn thành. Với web scraping, điều đó đồng nghĩa:
- Không cần lập trình: Ai cũng có thể trích xuất dữ liệu, không chỉ kỹ sư.
- Tốc độ: Có kết quả trong vài phút thay vì vài ngày.
- Linh hoạt: Thích ứng nhanh với website mới và nhu cầu dữ liệu mới.
- Giảm sai sót: Tự động hóa giúp hạn chế lỗi do copy-paste.
Và hay nhất là: bạn không cần trở thành “phù thủy công nghệ” mới theo kịp cuộc chơi này.
Vì sao công cụ web scraping truyền thống gây ức chế
Nói thẳng luôn: nhiều công cụ web scraping truyền thống giống như sinh ra cho lập trình viên, chứ không phải người dùng doanh nghiệp. Tôi đã thấy cảnh này quá nhiều lần—cả team hào hứng kick-off dự án, rồi “đứng hình” khi công cụ bắt nhập CSS selector, XPath hay regex. Thế là ai nấy mắt chữ A mồm chữ O, và email “để quý sau tính” bắt đầu xuất hiện.
Những vấn đề thường gặp:
- Phải biết code: Nhiều công cụ cũ yêu cầu viết script hoặc cấu hình template phức tạp.
- Thiết lập mệt mỏi: Phải map từng trường dữ liệu, xử lý luồng đăng nhập, cấu hình proxy để tránh bị chặn.
- Logic mong manh: Website đổi layout là scraper hỏng. Bạn lại đi debug thay vì làm việc chính.
- Gánh nặng bảo trì: Mỗi lần site cập nhật là gần như làm lại từ đầu.
Không lạ khi theo , các thách thức kỹ thuật hàng đầu của web scraping là bị chặn/cấm IP (56%), nội dung động (55%) và CAPTCHA (52%). Ngay cả team “xịn” cũng còn đuối, nói gì người dùng business.
Trong khi đó, người dùng doanh nghiệp chỉ cần một cách đơn giản, ổn định để đưa dữ liệu vào spreadsheet hoặc CRM. Đây chính là lúc easy web extract và các phương pháp web scraping đơn giản phát huy tác dụng.
Thunderbit giúp “easy web extract” trở nên khả thi như thế nào
Đây là phần khiến tôi thật sự hào hứng—vì đúng là bài toán mà chúng tôi muốn giải quyết tại . Sứ mệnh của chúng tôi là biến web scraping trở nên đơn giản đến mức ai cũng làm được, bất kể nền tảng kỹ thuật.
Thunderbit là một biến việc trích xuất dữ liệu web thành quy trình chỉ cần hai cú nhấp. Cách hoạt động:
- Mô tả điều bạn cần: Dùng ngôn ngữ tự nhiên để nói với Thunderbit bạn muốn lấy dữ liệu gì. Ví dụ: “Trích xuất toàn bộ tên sản phẩm và giá trên trang này.”
- Nhấn “AI Suggest Fields”: AI của Thunderbit đọc trang và gợi ý các cột phù hợp để trích xuất—như “Tên”, “Giá”, “Email” hoặc “Hình ảnh”.
- Nhấn “Scrape”: Thunderbit xử lý phần còn lại, bao gồm phân trang, trang con, thậm chí cả nội dung cần đăng nhập nếu cần.
Chỉ vậy thôi. Không code, không template, không đau đầu thiết lập. Giao diện được thiết kế cho người dùng doanh nghiệp—sales, marketing, ecommerce, bất động sản—những người cần kết quả nhanh, gọn, lẹ.
Quy trình dựa trên AI của Thunderbit: Làm thông minh hơn, không vất vả hơn
Điểm “đỉnh” nằm ở AI. Thunderbit không phải kiểu đoán mò—nó đọc trang, hiểu ngữ cảnh và tự động cấu trúc dữ liệu. Nếu muốn nâng cao, bạn có thể thêm hướng dẫn riêng cho từng trường (như “phân loại cột này” hoặc “dịch sang tiếng Anh”), nhưng đa số người dùng chỉ cần bấm là chạy.
Cách tiếp cận dựa trên AI mang lại:
- Ít lỗi hơn: AI thích ứng với nhiều layout khác nhau, nên kết quả ổn định hơn ngay cả khi website thay đổi.
- Thiết lập nhanh: Không cần dựng template hay viết script.
- Dữ liệu dùng được ngay: Thunderbit có thể gắn nhãn, phân loại và thậm chí làm giàu dữ liệu ngay trong lúc trích xuất.
Muốn tìm hiểu sâu hơn, xem hoặc . Bạn cũng có thể đọc thêm trên , như và .
Tính năng nổi bật của Thunderbit cho các phương pháp web scraping đơn giản
Điều làm Thunderbit khác biệt không chỉ là AI—mà là toàn bộ flow được thiết kế theo nhu cầu thực tế của doanh nghiệp. Dưới đây là những tính năng người dùng cực thích:
- Tự động phân trang: Thunderbit xử lý website nhiều trang và cuộn vô hạn mà không cần cấu hình.
- Scrape trang con: Cần thêm chi tiết? Thunderbit có thể vào từng trang con (như trang chi tiết sản phẩm hoặc hồ sơ LinkedIn) và tự động làm giàu dataset.
- Xuất dữ liệu mọi nơi: Đẩy thẳng sang Excel, Google Sheets, Airtable, Notion hoặc tải về CSV/JSON. Không còn “marathon” copy-paste.
- Hoạt động trên trang cần đăng nhập: Trích xuất dữ liệu từ site yêu cầu login—Thunderbit chạy trong trình duyệt nên thấy đúng những gì bạn thấy.
- Gắn nhãn & phân loại bằng AI: Thêm hướng dẫn để phân loại, gắn tag hoặc dịch dữ liệu ngay khi trích xuất.
- Scheduled scraping: Lên lịch chạy định kỳ để dữ liệu luôn mới—rất hợp cho theo dõi giá hoặc tracking lead.
Và đúng vậy, tất cả nằm trong một công cụ được hơn tin dùng.
Tự động phân trang và trích xuất trang con
Một trong những nỗi đau lớn nhất của web scraping là xử lý danh sách có phân trang hoặc các trang chi tiết lồng nhau. Với Thunderbit, bạn không cần lăn tăn. AI sẽ nhận diện phân trang (dù là nút “Next” hay cuộn vô hạn) và tự động theo link sang trang con. Nhờ đó, bạn có thể trích xuất hàng trăm đến hàng nghìn bản ghi trong một lần—không cần bấm tay.
Ví dụ, nếu bạn scrape danh sách sản phẩm trên Amazon, Thunderbit có thể lấy toàn bộ sản phẩm qua nhiều trang, rồi vào từng trang sản phẩm để lấy review, rating hoặc thông tin người bán. Kiểu như có một trợ lý “trâu bò”, không biết mệt và cũng không bao giờ chán.
Xuất nhiều định dạng và tích hợp CRM
Dữ liệu chỉ có giá trị khi bạn dùng được. Thunderbit cho phép xuất kết quả theo đúng định dạng team của bạn cần—Excel, Google Sheets, Airtable, Notion hoặc CSV/JSON. Bạn thậm chí có thể đẩy dữ liệu trực tiếp vào CRM hoặc công cụ workflow để sales và ops luôn có thông tin mới nhất.
Tích hợp trực tiếp giúp tiết kiệm cực nhiều thời gian. Không còn phải dọn dẹp file xuất lộn xộn hay chỉnh lại cột—AI của Thunderbit xử lý gọn hết.
Tình huống ứng dụng thực tế của easy web extract
Vậy easy web extract tạo tác động lớn nhất ở đâu? Dưới đây là một số kịch bản thực tế tôi thấy từ người dùng Thunderbit:
Trích xuất lead cho đội Sales
Đội sales sống còn nhờ danh sách lead. Với Thunderbit, bạn có thể scrape thông tin liên hệ từ LinkedIn, Google Maps hoặc các danh bạ doanh nghiệp chỉ trong vài phút. Chỉ cần mở trang, bấm “AI Suggest Fields”, Thunderbit sẽ kéo tên, email, số điện thoại và thông tin công ty vào một bảng tính sẵn dùng.
Một quản lý sales nói với tôi rằng trước đây họ mất hàng giờ mỗi tuần để copy-paste lead. Giờ với Thunderbit, họ tạo danh sách mục tiêu nhanh hơn rất nhiều—và team tập trung vào tiếp cận khách hàng thay vì nhập liệu.
Ecommerce và theo dõi thị trường
Các team ecommerce dùng Thunderbit để theo dõi SKU, giá và đánh giá của đối thủ trên Amazon, Shopify và nhiều nền tảng khác. Cần giám sát biến động giá hoặc sản phẩm mới? Hãy lên lịch scrape và nhận dữ liệu mới vào Google Sheet mỗi sáng.
Tính năng scrape trang con đặc biệt hữu ích: bạn có thể lấy chi tiết sản phẩm, hình ảnh, thậm chí review khách hàng mà gần như không phải động tay.
Thu thập dữ liệu bất động sản
Chuyên viên bất động sản dùng Thunderbit để thu thập tin đăng, giá và thông tin môi giới từ các trang như Zillow hoặc Realtor.com. AI xử lý phân trang và trang con, giúp bạn có bức tranh thị trường đầy đủ, cập nhật—rất phù hợp để phân tích hoặc làm báo cáo cho khách.
Một nhà phân tích bất động sản chia sẻ rằng việc từng mất cả buổi chiều giờ chỉ còn vài cú nhấp. Đó chính là sức mạnh của các phương pháp web scraping đơn giản.
So sánh công cụ truyền thống và phương pháp web scraping đơn giản
Hãy tổng hợp bằng bảng so sánh trực quan:
| Tính năng | Scraper truyền thống | Easy Web Extract (Thunderbit) |
|---|---|---|
| Cần lập trình | Có (script, selector) | Không (AI + ngôn ngữ tự nhiên) |
| Thời gian thiết lập | Cao (template, cấu hình) | Thấp (2 cú nhấp) |
| Bảo trì | Thường xuyên (hỏng khi site đổi) | Tối thiểu (AI tự thích ứng) |
| Xử lý phân trang | Thiết lập thủ công | Tự động |
| Trích xuất trang con | Logic phức tạp | 1 cú nhấp |
| Định dạng xuất | Thường hạn chế | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Hoạt động trên trang cần đăng nhập | Đôi khi (cần cấu hình) | Có (chạy trong trình duyệt) |
| Gắn nhãn/phân loại dữ liệu | Xử lý thủ công sau đó | AI hỗ trợ, tích hợp sẵn |
| Lên lịch/giám sát | Đôi khi (nâng cao) | Có (thiết lập dễ) |
Sự khác biệt đúng kiểu “một trời một vực”. Với Thunderbit, ai cũng có thể trích xuất, sắp xếp và sử dụng dữ liệu web—không cần kỹ năng kỹ thuật.
Xu hướng tương lai của easy web extract và các phương pháp web scraping đơn giản
Nhìn về phía trước, tương lai của easy web extract rất sáng. AI ngày càng “xịn”, và nhu cầu công cụ no-code đang tăng nhanh. Theo , 78% tổ chức hiện dùng AI trong ít nhất một chức năng, và các hệ thống “agentic”—công cụ AI có thể xử lý quy trình web nhiều bước—đang phát triển mạnh.
Điều này có ý nghĩa gì với người dùng doanh nghiệp? Nhiều sức mạnh hơn, ít phiền toái hơn. Khi AI tiếp tục cải thiện, chúng ta sẽ thấy:
- Nhận diện trường dữ liệu thông minh hơn: AI hiểu dữ liệu phức tạp và mối quan hệ tốt hơn.
- Tích hợp tốt hơn: Kết nối trực tiếp với nhiều công cụ và nền tảng doanh nghiệp hơn.
- Độ tin cậy cao hơn: Ít “gãy” hơn, kết quả ổn định hơn, kể cả với site động hoặc có bảo vệ.
- Dễ tiếp cận hơn: Trích xuất dữ liệu web sẽ trở thành kỹ năng phổ thông, không chỉ dành cho dân kỹ thuật.
Và đúng vậy, Thunderbit đang ở tuyến đầu của xu hướng này.
Kết luận & điểm cần nhớ
Web là cơ sở dữ liệu lớn nhất thế giới—nhưng cho đến gần đây, chỉ dân lập trình mới “đào” được. Điều đó đang đổi rất nhanh. Với easy web extract và các phương pháp web scraping đơn giản, bất kỳ ai cũng có thể biến website thành dữ liệu có thể hành động trong vài phút.
Dưới đây là những điều tôi rút ra (và hy vọng bạn cũng sẽ nhớ):
- Trích xuất web không cần code sẽ còn phát triển: Công cụ như Thunderbit giúp ai cũng có thể thu thập và dùng dữ liệu web—không cần kỹ năng kỹ thuật.
- AI là “gia vị bí mật”: Tự động chọn trường, phân trang, trích xuất trang con và gắn nhãn dữ liệu giúp tiết kiệm thời gian và giảm lỗi.
- Tác động kinh doanh là thật: Các team sales, ecommerce và bất động sản đã thấy năng suất tăng, dữ liệu mới hơn và quyết định tốt hơn.
- Tương lai còn sáng hơn nữa: Khi AI và no-code tiếp tục tiến hóa, trích xuất dữ liệu web sẽ phổ biến như gửi email.
Nếu bạn đã mệt vì copy-paste thủ công, bực vì scraper hay hỏng, hoặc chỉ tò mò về những gì có thể làm được, hãy thử . Bạn có thể và bắt đầu trích xuất dữ liệu miễn phí—không cần thiết lập, không cần code, không rườm rà.
Nếu muốn tìm hiểu sâu hơn, hãy ghé để xem thêm hướng dẫn, mẹo và ví dụ thực tế.
Câu hỏi thường gặp (FAQs)
1. “easy web extract” là gì và dành cho ai?
Easy web extract là các phương pháp web scraping không cần code, có AI hỗ trợ, giúp bất kỳ ai—đặc biệt là người dùng doanh nghiệp không chuyên kỹ thuật—trích xuất dữ liệu có cấu trúc từ website một cách nhanh và dễ. Rất phù hợp cho sales, marketing, ecommerce và đội vận hành cần dữ liệu “dùng được ngay” mà không phải đau đầu kỹ thuật.
2. Thunderbit khác gì so với công cụ web scraping truyền thống?
Thunderbit dùng AI để tự động hóa việc chọn trường dữ liệu, xử lý phân trang và trích xuất trang con. Khác với scraper truyền thống thường yêu cầu code hoặc template phức tạp, Thunderbit cho phép bạn mô tả nhu cầu bằng ngôn ngữ thường và trích xuất dữ liệu chỉ với hai cú nhấp.
3. Thunderbit có xử lý được website động hoặc nhiều trang không?
Có. Thunderbit tự động phát hiện và xử lý phân trang (bao gồm cuộn vô hạn) và có thể theo link sang trang con để trích xuất sâu hơn—với thiết lập tối thiểu.
4. Thunderbit hỗ trợ xuất dữ liệu theo những định dạng nào?
Thunderbit cho phép xuất dữ liệu trực tiếp sang Excel, Google Sheets, Airtable, Notion, CSV hoặc JSON. Bạn cũng có thể tích hợp với CRM và các công cụ workflow khác để quy trình doanh nghiệp liền mạch.
5. Dùng công cụ easy web extract như Thunderbit có an toàn và đúng đạo đức không?
Thunderbit khuyến khích web scraping có trách nhiệm và đúng đạo đức. Hãy luôn tôn trọng điều khoản sử dụng của website, tránh scrape dữ liệu cá nhân khi chưa có sự đồng ý, và dùng giới hạn tốc độ để không gây gián đoạn dịch vụ. Xem thêm best practices tại .
Sẵn sàng khai thác sức mạnh của dữ liệu web? Hãy thử Thunderbit ngay hôm nay và xem easy web extract có thể thay đổi quy trình làm việc của bạn đơn giản đến mức nào.
Tìm hiểu thêm