Nếu bạn đang tìm hiểu các công cụ thu thập dữ liệu web bằng AI, rất có thể bạn đã từng nghe đến Crawl4AI. Đây là một dự án mã nguồn mở rất phổ biến, đang được cộng đồng lập trình viên chú ý nhờ tốc độ và tính linh hoạt. Nhưng nếu bạn không phải dân code — hoặc chỉ đơn giản muốn lấy dữ liệu thật nhanh, không muốn phải vật lộn với các script Python thì sao? Dù bạn đang cân nhắc Crawl4AI cho dự án tiếp theo, hay đang tìm một lựa chọn thân thiện hơn với người dùng, đặc biệt nếu bạn làm sales, marketing, thương mại điện tử hoặc bất động sản, bạn đã đến đúng chỗ. Trong bài đánh giá này, tôi sẽ phân tích Crawl4AI cung cấp gì, điểm mạnh của nó ở đâu, và những chỗ nó có thể khiến bạn thấy chưa đủ. Tôi cũng sẽ chỉ cho bạn cách nổi bật như một giải pháp hiện đại, không cần code dành cho người dùng doanh nghiệp muốn thu thập dữ liệu web chỉ với vài cú nhấp chuột.
Crawl4AI là gì?
Crawl4AI là một thư viện Python mã nguồn mở được thiết kế cho việc thu thập dữ liệu web và trích xuất dữ liệu, với trọng tâm đặc biệt vào các trường hợp sử dụng AI và mô hình ngôn ngữ lớn (LLM). Dự án này đã tạo được sức hút trên GitHub nhờ khả năng crawl song song tốc độ cao và xuất dữ liệu theo các định dạng thân thiện với AI như JSON và Markdown. Nói ngắn gọn, đây là bộ công cụ dành cho lập trình viên để thu thập dữ liệu từ website ở quy mô lớn, rồi đưa dữ liệu đó vào các mô hình AI, bảng điều khiển phân tích hoặc cơ sở dữ liệu tùy chỉnh.
![]()
Sản phẩm và tính năng chính:
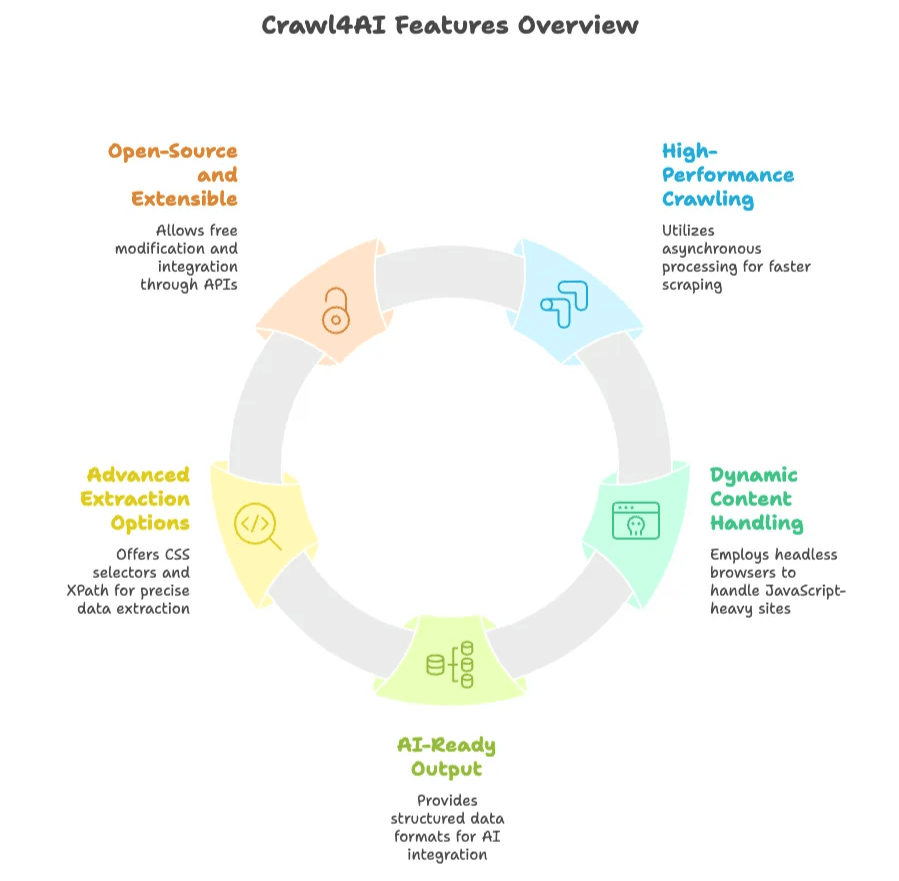
- Thu thập tốc độ cao: Dùng xử lý bất đồng bộ và song song để crawl nhiều trang cùng lúc, nhanh hơn nhiều công cụ scrape truyền thống.
- Xử lý nội dung động: Điều khiển trình duyệt headless (như Chromium qua Playwright) để chạy JavaScript và thu thập các website hiện đại, nhiều nội dung động.
- Đầu ra sẵn sàng cho AI: Xuất dữ liệu dưới dạng văn bản có cấu trúc (JSON, Markdown hoặc HTML đã làm sạch), sẵn sàng cho AI hoặc phân tích dữ liệu.
- Tùy chọn trích xuất nâng cao: Cho phép người dùng chỉ định quy tắc trích xuất bằng CSS selector hoặc XPath, thậm chí tích hợp LLM để tóm tắt hoặc trích xuất nội dung.
- Mã nguồn mở và dễ mở rộng: Miễn phí sử dụng, sửa đổi và phát triển thêm. Có Python API, giao diện dòng lệnh và REST API để tích hợp linh hoạt.
Triết lý của Crawl4AI là “dân chủ hóa dữ liệu” bằng cách trao cho lập trình viên một công cụ scrape nhanh, vận hành bằng code mà không có rào cản giá hay giới hạn như các công cụ thương mại. Nếu bạn rành Python, đây là một cách rất mạnh để thu thập lượng lớn dữ liệu web trong thời gian ngắn.
Crawl4AI dành cho ai?
Crawl4AI được xây dựng chủ yếu cho người dùng kỹ thuật — như lập trình viên, nhà khoa học dữ liệu, nhà nghiên cứu AI và bất kỳ ai thoải mái viết Python. Dưới đây là một số trường hợp sử dụng điển hình:
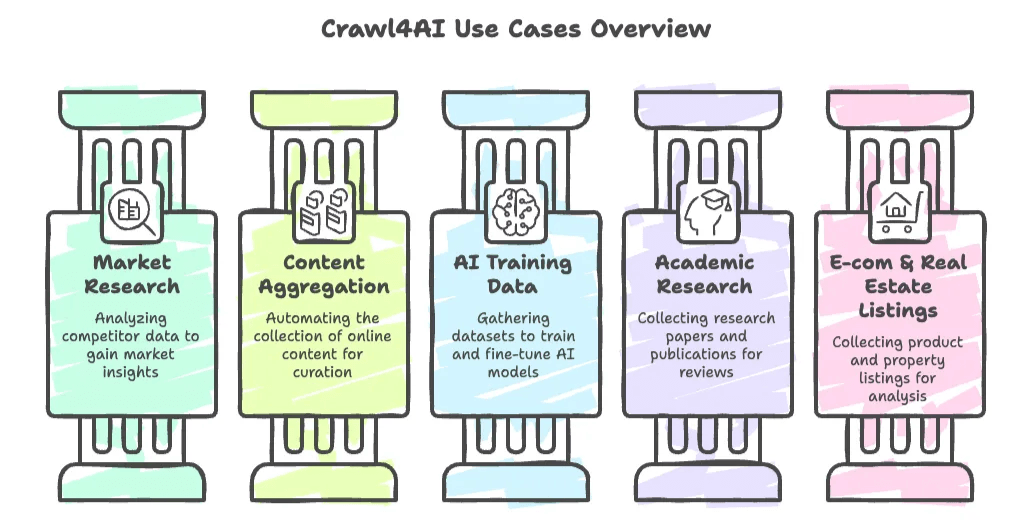
- Nghiên cứu thị trường & phân tích đối thủ: Thu thập dữ liệu từ website đối thủ, bài báo tin tức hoặc mạng xã hội để lấy insight.
- Tổng hợp nội dung: Tự động thu thập tin tức, blog hoặc bài đăng diễn đàn để biên tập hoặc theo dõi xu hướng.
- Thu thập dữ liệu huấn luyện AI: Gom các bộ dữ liệu lớn như tài liệu, hỏi đáp hoặc bài viết để huấn luyện hoặc tinh chỉnh mô hình ngôn ngữ.
- Nghiên cứu học thuật: Tự động thu thập bài nghiên cứu, án lệ hoặc ấn phẩm trực tuyến cho tổng quan tài liệu.
- Danh sách e-commerce & bất động sản: Lập trình viên có thể xây dựng crawler tùy chỉnh để thu thập danh sách sản phẩm hoặc bất động sản phục vụ phân tích.
Nhưng có một điểm cần lưu ý: Crawl4AI không được thiết kế cho người không có nền tảng kỹ thuật. Nếu bạn là quản lý sales, marketer hay môi giới bất động sản mà không có kinh nghiệm code, bạn có thể sẽ thấy việc cài đặt và sử dụng khá khó khăn. Công cụ này mặc định rằng bạn hiểu Python và biết cách cấu hình quy tắc trích xuất cũng như xử lý sự cố.
Gói giá của Crawl4AI
Một trong những điểm bán hàng lớn nhất của Crawl4AI là giá: hoàn toàn miễn phí. Là một dự án mã nguồn mở, không có phí bản quyền, không có các gói thuê bao hay tường phí. Bạn có thể cài bằng pip và dùng ngay.
Tuy nhiên, “miễn phí” vẫn đi kèm vài đánh đổi:
- Thiết lập và bảo trì: Bạn sẽ phải dành thời gian cài đặt môi trường, viết script và duy trì quy trình thu thập dữ liệu.
- Chi phí gián tiếp: Nếu bạn chạy crawl quy mô lớn, có thể sẽ phải trả cho proxy, server hoặc tài nguyên cloud.
- Hỗ trợ: Không có bộ phận chăm sóc khách hàng chính thức — chỉ có diễn đàn cộng đồng và các issue trên GitHub.
Với doanh nghiệp có nhân sự kỹ thuật nội bộ, đây có thể là một giải pháp tiết kiệm chi phí. Nhưng với các nhóm không chuyên về kỹ thuật, thời gian và công sức cần bỏ ra để triển khai thường nhanh chóng lớn hơn lợi ích của mức giá 0 đồng.
Phản hồi từ người dùng về Crawl4AI
Để có cái nhìn thực tế hơn về hiệu năng của Crawl4AI, tôi đã tìm hiểu các bài đánh giá trên blog công nghệ, danh mục công cụ AI và diễn đàn cộng đồng. Đây là những gì tôi ghi nhận được:
Người dùng thích gì
- Tốc độ và hiệu quả chi phí: Lập trình viên rất khen khả năng crawl các website lớn của Crawl4AI, nhiều khi còn vượt các công cụ trả phí. Việc nó miễn phí là một điểm cộng rất lớn.
- Linh hoạt nhờ mã nguồn mở: Người dùng thích việc có toàn quyền kiểm soát mã nguồn, không bị khóa vào nhà cung cấp hay bị giới hạn tính năng.
- Đầu ra sẵn sàng cho AI: Dữ liệu được xuất ra sạch và có cấu trúc, đặc biệt là JSON hoặc Markdown, giúp tiết kiệm thời gian cho những ai đưa dữ liệu vào mô hình AI hoặc công cụ phân tích.
Người dùng gặp khó ở đâu
Nhưng lời khen đi kèm với những lưu ý khá lớn — đặc biệt với người mới hoặc người không biết lập trình.
1. Đường cong học tập dốc
Một nhận xét lặp đi lặp lại là Crawl4AI không thân thiện với người mới. Nếu bạn mới làm quen với web scraping hoặc không thoải mái với Python, bạn sẽ gặp một đường cong học tập khá dốc. Không có giao diện bấm-chọn; mọi thứ đều thực hiện qua script và file cấu hình. Việc thiết lập môi trường, viết quy tắc trích xuất và xử lý crawl bất đồng bộ đều đòi hỏi kiến thức kỹ thuật. Một người đánh giá đã nói thẳng: “Nếu bạn không biết code, bạn sẽ bị lạc.”
2. Không thân thiện với người mới bắt đầu
Ngay cả với những người đã có chút nền tảng kỹ thuật, Crawl4AI vẫn có thể khó dùng. Tài liệu đang được cải thiện, nhưng cộng đồng vẫn còn nhỏ, nên tìm hỗ trợ có thể khá chậm. Người dùng cho biết họ gặp lỗi hoặc crash trên các website phức tạp, và việc xử lý sự cố thường đồng nghĩa với việc phải lục tìm trong issue GitHub hoặc Stack Overflow. Ngoài ra, công cụ này cũng thiếu các tính năng tích hợp sẵn cho nhu cầu kinh doanh phổ biến — như đăng nhập website, giải CAPTCHA hoặc lên lịch crawl định kỳ. Nếu bạn muốn thu thập dữ liệu theo lịch hoặc xử lý xác thực, bạn sẽ phải tự xây những tính năng đó.
Ví dụ thực tế:
- Một quản lý marketing ở một công ty thương mại điện tử quy mô vừa đã thử dùng Crawl4AI để theo dõi giá đối thủ. Sau nhiều ngày vật lộn với script Python và driver trình duyệt, họ bỏ cuộc và chuyển sang một công cụ không cần code. Những rào cản kỹ thuật và việc thiếu hỗ trợ khiến công cụ này không thực tế với đội của họ.
- Một môi giới bất động sản muốn thu thập danh sách nhà từ nhiều website. Họ thấy cách thiết lập của Crawl4AI quá phức tạp và không vượt qua được bước cấu hình ban đầu. Không có lập trình viên hỗ trợ, dự án bị đình trệ.
Tóm lại, dù Crawl4AI là một “cỗ máy” mạnh mẽ cho lập trình viên, nó lại là lựa chọn khó bán với người dùng doanh nghiệp chỉ muốn lấy dữ liệu mà không đau đầu.
Những điểm chính rút ra từ bài đánh giá Crawl4AI
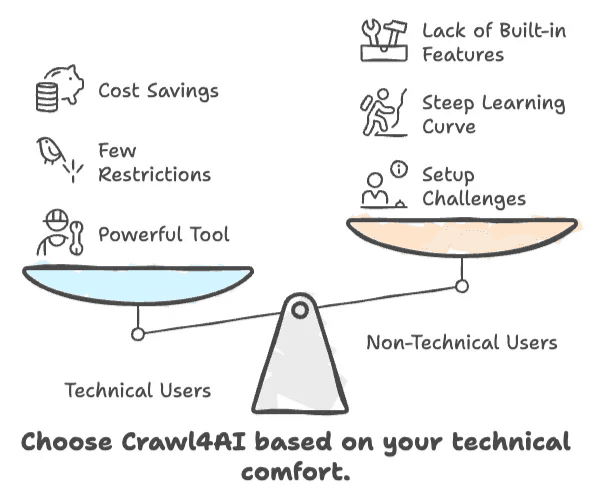
- Crawl4AI nhanh, linh hoạt và miễn phí — nhưng chỉ phù hợp nếu bạn thoải mái với code.
- Người không chuyên sẽ gặp khó với khâu thiết lập, đường cong học tập và thiếu các tính năng kinh doanh tích hợp sẵn.
- Nếu bạn cần giải pháp bấm-chọn, không cần code, Crawl4AI có lẽ không dành cho bạn.
- Với lập trình viên và người làm AI, đây là công cụ rất mạnh, ít bị giới hạn.
- Với người dùng doanh nghiệp, thời gian và công sức cần bỏ ra có thể lớn hơn khoản tiết kiệm chi phí.
Giới thiệu Thunderbit: Công cụ thu thập dữ liệu web bằng AI, không cần code cho người dùng doanh nghiệp
Sau khi thấy Crawl4AI còn hạn chế thế nào với người không chuyên, hãy nói về một lựa chọn tốt hơn: .
Thunderbit là một tiện ích Chrome thu thập dữ liệu web bằng AI được xây dựng riêng cho người dùng doanh nghiệp — sales, marketing, thương mại điện tử và bất động sản — những người muốn trích xuất dữ liệu từ bất kỳ website nào một cách nhanh chóng mà không cần viết code. Tôi đã thử rất nhiều công cụ scraping, và Thunderbit nổi bật nhờ sự đơn giản nhưng vẫn rất mạnh mẽ.
Điều gì làm Thunderbit khác biệt?
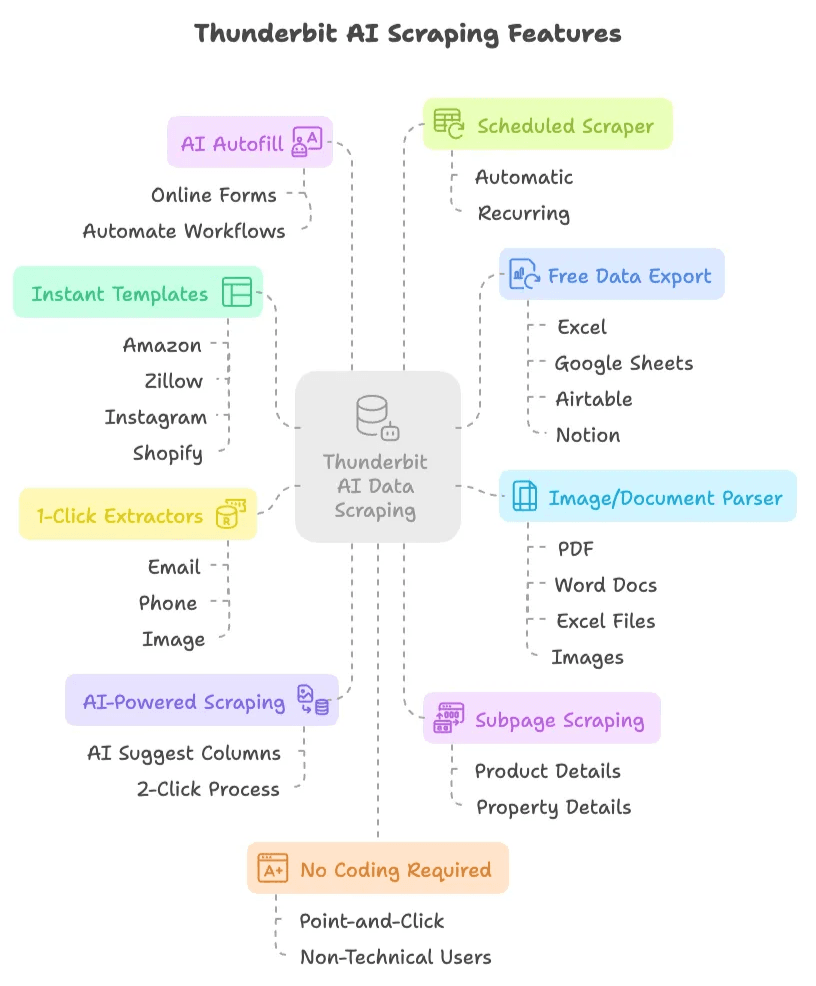
- Thu thập bằng AI, chỉ 2 cú nhấp: Chỉ cần bấm “AI Suggest Columns”, để AI gợi ý những gì nên trích xuất, rồi nhấn “Scrape”. Xong. Không script, không selector, không đau đầu.
- Thu thập trang con: AI của Thunderbit có thể tự động truy cập các trang con (như chi tiết sản phẩm hoặc bất động sản) và làm giàu bảng dữ liệu của bạn — không cần thiết lập thủ công.
- Mẫu trích xuất dữ liệu có sẵn ngay: Với các website phổ biến như Amazon, Zillow, Instagram và Shopify, bạn có thể xuất dữ liệu chỉ với một cú nhấp bằng các mẫu dựng sẵn.
- Xuất dữ liệu miễn phí: Xuất dữ liệu đã thu thập sang Excel, Google Sheets, Airtable hoặc Notion — không phải trả thêm phí.
- AI Autofill (hoàn toàn miễn phí): Dùng AI để điền biểu mẫu trực tuyến và tự động hóa quy trình làm việc. Chỉ cần chọn ngữ cảnh và để Thunderbit xử lý phần còn lại.
- Scheduled Scraper: Thiết lập các lần scrape tự động, định kỳ bằng lịch đơn giản — không cần cron job hay cài đặt server.
- Trình trích xuất email, số điện thoại và hình ảnh chỉ với 1 cú nhấp: Lấy ngay email, số điện thoại hoặc hình ảnh từ bất kỳ website nào.
- Trình phân tích hình ảnh/tài liệu: Trích xuất bảng từ PDF, file Word, Excel hoặc hình ảnh. Chỉ cần tải file lên, để AI cấu trúc dữ liệu, rồi bấm “Scrape”.
- Không cần code: Mọi thứ đều bấm-chọn, được thiết kế cho người dùng không chuyên.
Thunderbit được tạo ra để giúp dữ liệu web trở nên dễ tiếp cận với mọi người — không chỉ lập trình viên. Nếu bạn muốn xem cách nó hoạt động, hãy xem hoặc ghé để xem các trường hợp sử dụng thực tế.
Gói giá của Thunderbit
Thunderbit dùng hệ thống tín dụng đơn giản: 1 tín dụng = 1 dòng đầu ra. Dưới đây là cách các gói được chia:
| Gói | Giá hàng tháng | Giá năm (mỗi tháng) | Tín dụng (hàng tháng) |
|---|---|---|---|
| Miễn phí | Miễn phí | Miễn phí | 6 trang |
| Starter | $15 | $9 | 500 |
| Pro 1 | $38 | $16.5 | 3.000 |
| Pro 2 | $75 | $33.8 | 6.000 |
| Pro 3 | $125 | $68.4 | 10.000 |
| Pro 4 | $249 | $137.5 | 20.000 |
Bạn có thể bắt đầu miễn phí và thu thập tối đa 6 trang (hoặc 10 trang với bản dùng thử miễn phí). Các gói trả phí mở khóa thêm tín dụng và tính năng nâng cao, nhưng ngay cả gói miễn phí cũng khá hào phóng với người dùng nhẹ. Để biết thêm chi tiết, hãy xem trang .
Thunderbit so với Crawl4AI: So sánh song song
Hãy đặt Thunderbit và Crawl4AI lên bàn cân để bạn thấy mỗi công cụ mạnh ở đâu — và vì sao Thunderbit giúp người dùng doanh nghiệp nhẹ nhàng hơn rất nhiều.
| Tính năng / Tiêu chí | Thunderbit | Crawl4AI |
|---|---|---|
| Giao diện không cần code, bấm-chọn | ✅ | ❌ |
| AI Suggest Columns (tự động phát hiện) | ✅ | ❌ |
| Thu thập trang con (tự động) | ✅ | ❌ |
| Mẫu có sẵn ngay (Amazon, v.v.) | ✅ | ❌ |
| Xuất dữ liệu miễn phí (Excel, Sheets) | ✅ | ❌ |
| AI Autofill (điền biểu mẫu) | ✅ | ❌ |
| Scrape theo lịch (không cần code) | ✅ | ❌ |
| Trích xuất email/số điện thoại/hình ảnh 1 cú nhấp | ✅ | ❌ |
| Trích xuất bảng từ hình ảnh/tài liệu | ✅ | ❌ |
| Xử lý nội dung động | ✅ | ✅ |
| Mã nguồn mở | ❌ | ✅ |
| Cần viết code | ❌ | ✅ |
| Có gói miễn phí | ✅ | ✅ |
| Hỗ trợ cộng đồng | ✅ | ⚠️ (hạn chế) |
| Dành cho người dùng doanh nghiệp | ✅ | ❌ |
| Dành cho lập trình viên | ⚠️ | ✅ |
| Giá | $ (miễn phí & trả phí) | Miễn phí |
| Hỗ trợ khách hàng | ✅ | ❌ |
Chú giải:
✅ = Có
❌ = Không
⚠️ = Hạn chế / một phần
$ = Có gói trả phí
Kết luận
Nếu bạn là lập trình viên thích mày mò code và muốn toàn quyền kiểm soát, Crawl4AI là một công cụ miễn phí rất mạnh cho việc thu thập dữ liệu web quy mô lớn. Nhưng nếu bạn là người dùng doanh nghiệp — đặc biệt trong sales, marketing, thương mại điện tử hoặc bất động sản — chỉ muốn lấy dữ liệu mà không phải đau đầu, là lựa chọn thắng rõ ràng. Công cụ này được xây dựng cho người không chuyên, với tự động hóa bằng AI, mẫu có sẵn ngay và giao diện thân thiện giúp bạn đi từ website đến bảng tính chỉ trong vài giây.
Câu hỏi thường gặp
1. Thunderbit so sánh với các công cụ thu thập dữ liệu web bằng AI khác như Crawl4AI thế nào?
Thunderbit được thiết kế cho người không chuyên, cung cấp giao diện không cần code, bấm-chọn, trong khi Crawl4AI là một thư viện Python mã nguồn mở hướng đến lập trình viên. Thunderbit tự động hóa các tác vụ phức tạp bằng AI, giúp việc thu thập dữ liệu web trở nên dễ tiếp cận với mọi người.
2. Thunderbit có những tính năng độc đáo nào cho người dùng doanh nghiệp?
Thunderbit cung cấp gợi ý cột bằng AI, thu thập trang con, mẫu tức thì cho các website phổ biến và xuất dữ liệu miễn phí sang Excel hoặc Google Sheets — tất cả không cần code. Công cụ này còn có thu thập theo lịch và các trình trích xuất 1 cú nhấp cho email, số điện thoại và hình ảnh.
3. Thunderbit có xử lý được các tác vụ trích xuất dữ liệu phức tạp như PDF hoặc hình ảnh không?
Chắc chắn rồi! AI của Thunderbit có thể trích xuất bảng từ PDF, file Word, Excel và hình ảnh. Chỉ cần tải file lên, để AI cấu trúc dữ liệu, rồi bấm “Scrape” để có kết quả ngay. Tìm hiểu thêm trên .
Tìm hiểu thêm