Gần một nửa traffic Internet bây giờ đến từ bot. Mà đa phần tụi nó đang thu thập liên kết, dữ liệu và URL ở quy mô “khủng” luôn. Nếu bạn vẫn ngồi làm thủ công, thật sự là đang bị bỏ lại phía sau.
Mình đã test 12 công cụ trích xuất liên kết — từ Chrome extension có AI cho tới thư viện Python — để xem cái nào thật sự “làm được việc” khi bạn cần kéo hàng nghìn URL thật nhanh.
Dưới đây là những gì mình đúc kết được.
Vì sao công cụ trích xuất liên kết lại quan trọng
Nói thẳng cho nhanh: web thì ngập dữ liệu, còn doanh nghiệp thì chạy đua biến mớ hỗn độn đó thành insight dùng được ngay. và giờ gần như thành “hạ tầng thiết yếu” cho các team muốn:
- Tạo lead: Team sales có thể kéo link hồ sơ công ty từ các directory hoặc LinkedIn trong vài phút, rồi đem danh sách URL đó qua công cụ khác để lấy contact. Không còn cảnh click tới mỏi tay.
- Tổng hợp nội dung và tăng SEO: Marketer có thể gom toàn bộ URL bài viết từ blog, theo dõi backlink của đối thủ, hoặc audit cấu trúc website để tìm link hỏng.
- Theo dõi đối thủ và nghiên cứu thị trường: Team vận hành có thể tự động thu thập link sản phẩm mới, trang giá, hoặc thông cáo báo chí—bắt bài đối thủ mà không tốn công ngồi canh.
- Tự động hóa quy trình và tiết kiệm thời gian: Trình thu thập link hiện đại xử lý URL hàng loạt, crawl các trang con và xuất dữ liệu theo định dạng có cấu trúc (CSV, Excel, Google Sheets, Notion… cần gì cũng có). Nghĩa là khỏi “marathon” copy-paste hay dọn file text lộn xộn.
Trong bối cảnh , làm thủ công là chuyện bất khả thi. Một công cụ trích xuất liên kết ngon giống như trợ lý “siêu trâu”: không biết mệt, không bỏ sót link, cũng chẳng cần nghỉ cà phê.
Cách chúng tôi chọn ra các công cụ trích xuất liên kết tốt nhất
Giữa cả rừng lựa chọn, chọn đúng công cụ đôi khi giống kiểu “speed-dating” ở hội nghị công nghệ—ai cũng hứa hẹn đủ thứ, nhưng chỉ vài cái là làm được thật. Đây là cách mình lọc ra top 12:
- Dễ dùng: Người không biết code có dùng được không, hay phải có “bằng tiến sĩ regex”? Giải pháp no-code/low-code được cộng điểm.
- Thu thập hàng loạt & nhiều tầng: Có xử lý hàng trăm URL một lúc không? Có tự crawl trang con và tự bám theo liên kết không?
- Xuất dữ liệu & tích hợp: Có xuất CSV, Excel, Google Sheets, Notion, Airtable hoặc qua API không? Càng ít thao tác tay càng tốt.
- Đối tượng người dùng & độ linh hoạt: Dành cho business user, analyst hay developer? Có công cụ “ai cũng dùng được”, cũng có loại rất chuyên biệt.
- Tính năng nâng cao: Nhận diện bằng AI, lập lịch, mở rộng trên cloud, làm sạch dữ liệu, template cho các website phổ biến.
- Giá & khả năng mở rộng: Có gói miễn phí, trả theo mức dùng hay enterprise? Mình soi kỹ xem “đáng tiền” tới đâu.
Mình đưa vào cả extension trình duyệt lẫn nền tảng enterprise, nên dù bạn là founder solo hay team dữ liệu của Fortune 500, vẫn sẽ có lựa chọn hợp bài.
Thunderbit: Công cụ trích xuất liên kết thông minh nhất cho người dùng doanh nghiệp
Mở màn bằng lựa chọn top 1. là gợi ý mình ưu tiên cho bài toán trích xuất liên kết—và không chỉ vì mình có tham gia xây dựng. Thunderbit là một thiết kế cho người dùng doanh nghiệp muốn ra kết quả nhanh, gọn, lẹ.
Điểm làm Thunderbit khác biệt? Nó kiểu như một “thực tập sinh AI” biết nghe lời. Bạn chỉ cần mô tả bằng ngôn ngữ tự nhiên (“Lấy tất cả link sản phẩm và giá trên trang này”), AI của Thunderbit sẽ tự hiểu và làm phần còn lại. Không cần vọc selector hay viết script.
Và chưa hết:
- Hỗ trợ URL hàng loạt: Dán một URL hoặc cả danh sách hàng trăm URL—Thunderbit xử lý một lượt.
- Điều hướng trang con: Cần lấy link từ trang danh sách rồi vào từng trang chi tiết để lấy thêm URL? Logic thu thập nhiều tầng của Thunderbit đáp ứng ổn áp.
- Xuất dữ liệu có cấu trúc: Sau khi trích xuất, bạn có thể đổi tên trường, phân loại và xuất thẳng sang Google Sheets, Notion, Airtable, Excel hoặc CSV. Khỏi đau đầu hậu xử lý.
Thunderbit được hơn 30.000 người dùng toàn cầu tin tưởng—từ team sales, môi giới bất động sản tới các shop e-commerce nhỏ. Và đúng rồi, có (thu thập tối đa 6 trang, hoặc 10 trang nếu kích hoạt trial boost), nên bạn test gần như không rủi ro.
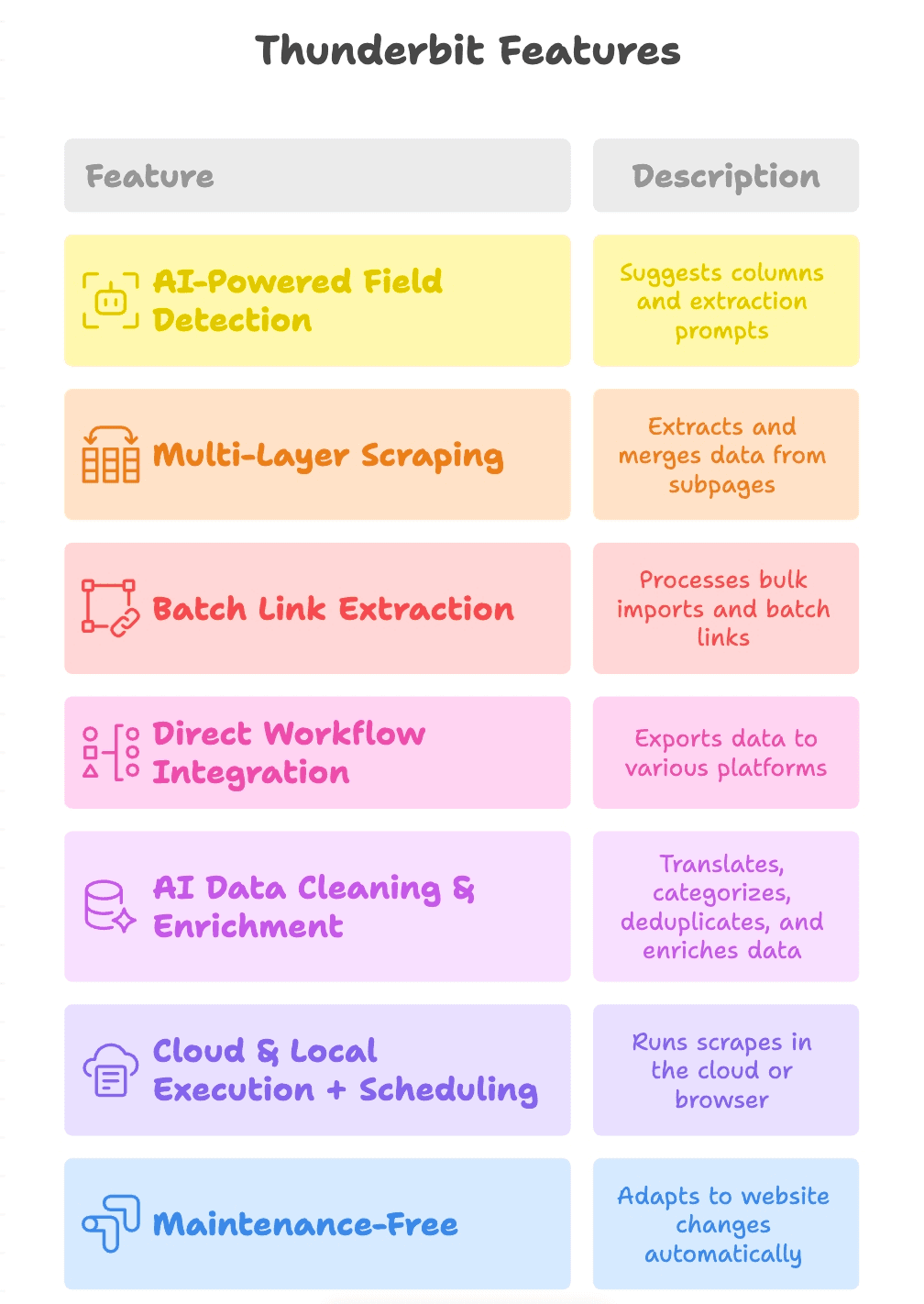
Những tính năng nổi bật của Thunderbit
Đi sâu thêm chút về lý do Thunderbit “đáng đồng tiền bát gạo”:
- AI tự nhận diện trường dữ liệu: Chỉ cần bấm “AI Suggest Fields”, Thunderbit đọc trang, gợi ý các cột (như “Product Link”, “PDF URL”, “Contact Email”) và còn tạo prompt trích xuất cho từng trường.
- Thu thập nhiều tầng (Multi-Layer): Thunderbit có thể đi theo link từ trang chính sang trang con (ví dụ trang chi tiết sản phẩm hoặc link tải PDF), trích xuất thêm liên kết và gộp tất cả vào một bảng.
- Trích xuất link theo lô: Dù bạn thu thập 1 trang hay 1.000 trang, Thunderbit vẫn xử lý import hàng loạt và trích xuất theo batch mượt mà.
- Tích hợp quy trình trực tiếp: Xuất kết quả sang Google Sheets, Notion, Airtable hoặc tải về CSV/Excel. Dữ liệu nằm đúng nơi team cần.
- AI làm sạch & làm giàu dữ liệu: Thunderbit có thể dịch, phân loại, loại trùng và thậm chí bổ sung thông tin ngay trong lúc thu thập—đầu ra sẵn dùng, không chỉ là “đống raw”.
- Chạy cloud & local + lập lịch: Chạy trên cloud để nhanh hơn, hoặc chạy trong trình duyệt cho các website cần đăng nhập. Lập lịch chạy định kỳ để dữ liệu luôn mới.
- Gần như không cần bảo trì: AI của Thunderbit thích nghi với thay đổi giao diện website, giúp bạn bớt thời gian sửa scraper hỏng và tập trung vào kết quả.
Octoparse: Trình thu thập link no-code cho mọi người
là “cây đa cây đề” trong thế giới scraping no-code. Đây là app desktop (Windows/Mac) với giao diện kiểu point-and-click rất trực quan. Bạn mở trang web, click vào các link cần lấy, Octoparse sẽ tự suy luận phần còn lại.
- Thân thiện với người mới: Không cần code. Click, trích xuất, xong.
- Xử lý phân trang & nội dung động: Có thể bấm nút “Next”, cuộn trang, thậm chí đăng nhập.
- Scrape trên cloud & lập lịch: Gói trả phí cho phép chạy job trên cloud và đặt lịch định kỳ.
- Tùy chọn xuất dữ liệu: Tải CSV, Excel, JSON hoặc đẩy vào database.
Gói miễn phí khá rộng rãi cho nhu cầu nhỏ (tối đa 10 task và 50.000 dòng/tháng), nhưng nếu dùng nặng thì sẽ cần gói trả phí (từ khoảng 75 USD/tháng).
Apify: Trình trích xuất URL linh hoạt cho workflow tùy biến
kiểu “dao đa năng Thụy Sĩ” của web scraping. Nền tảng có marketplace các “actor” dựng sẵn (công cụ scraping), đồng thời cho phép bạn tự viết script bằng JavaScript hoặc Python.
- Có sẵn & tùy biến được: Dùng actor cộng đồng cho tác vụ phổ biến, hoặc tự xây cho workflow riêng.
- Thu thập hàng loạt & lập lịch: Xếp hàng URL, chạy song song và đặt lịch chạy định kỳ.
- Ưu tiên API: Xuất JSON, CSV, Excel hoặc Google Sheets, dễ tích hợp vào pipeline dữ liệu.
- Trả theo mức dùng: Mỗi tháng có credit miễn phí, sau đó tính phí theo usage.
Apify hợp với team bán kỹ thuật và developer cần độ linh hoạt lẫn khả năng scale.
Bright Data URL Scraper: Thu thập link cấp doanh nghiệp
nhắm tới doanh nghiệp cần scraping quy mô lớn. Data Collector của họ có sẵn URL Scraper cho các job khối lượng cao.
- Chịu tải cực lớn: Thu thập hàng nghìn đến hàng triệu trang, kèm hạ tầng proxy mạnh để hạn chế bị chặn.
- Template dựng sẵn: Scraper cho e-commerce, social, bất động sản…
- Tính năng enterprise: Công cụ tuân thủ, hỗ trợ chuyên gia, chống chặn nâng cao.
- Giá: Từ khoảng 350 USD cho 100.000 lượt tải trang—rõ ràng nhắm tới doanh nghiệp lớn.
Nếu bạn là startup thì có thể hơi “quá tay”. Nhưng với scraping khối lượng lớn và quan trọng, Bright Data đúng là đáng gờm.
WebHarvy: Trình trích xuất link trực quan, click là chạy
là app desktop (Windows) cho phép bạn trích xuất link bằng cách click trực tiếp trong trình duyệt tích hợp.
- Cực đơn giản: Click một link, WebHarvy sẽ tự highlight các phần tử tương tự để trích xuất.
- Hỗ trợ Regular Expression: Có sẵn pattern cho tác vụ phổ biến, không cần code.
- Xuất Excel, CSV, JSON, XML, SQL: Hợp với người dùng doanh nghiệp muốn định dạng quen thuộc.
- Mua một lần dùng mãi: Trả phí một lần.
Rất hợp cho doanh nghiệp nhỏ, nhà nghiên cứu hoặc ai cần cách lấy link nhanh gọn mà không muốn đụng code.
Web Scraper (Chrome Extension): Thu thập link nhanh ngay trong trình duyệt
là công cụ miễn phí, mã nguồn mở, biến trình duyệt thành một scraper.
- Định nghĩa sitemap: Chỉ cho công cụ cách điều hướng và dữ liệu cần lấy.
- Hỗ trợ phân trang & crawl nhiều tầng: Crawl danh mục, danh mục con và trang chi tiết.
- Xuất CSV/XLSX: Tải dữ liệu trực tiếp từ trình duyệt.
- Template cộng đồng: Nhiều sitemap chia sẻ cho các website phổ biến.
Hợp cho các tác vụ nhanh, dùng một lần, hoặc sinh viên/nhóm nhỏ cần giải pháp tiết kiệm.
ScraperAPI: Trình thu thập link mở rộng tốt cho developer
dành cho developer muốn tải trang web ở quy mô lớn mà không phải đau đầu vì proxy, block hay CAPTCHA.
- Chạy qua API: Gửi URL, nhận về HTML hoặc dữ liệu đã thu thập.
- Xử lý quy mô & chống bot: Tự xoay proxy, render JS, giải CAPTCHA.
- Tích hợp vào code của bạn: Dùng với Python, Node.js hoặc ngôn ngữ bất kỳ.
- Giá: Có gói miễn phí (~1000 API call), sau đó tính theo request.
Rất hợp cho crawler tùy biến hoặc khi bạn cần độ ổn định và tốc độ ở quy mô lớn.
ParseHub: Trình thu thập link trực quan với lựa chọn nâng cao
là app desktop (Windows, Mac, Linux) cho phép bạn build dự án scraping bằng giao diện trực quan.
- Chọn phần tử & điều hướng nâng cao: Click, lặp, đặt điều kiện để trích xuất link—kể cả từ phần tử động hoặc bị ẩn.
- Xử lý trang lồng nhau: Crawl danh mục → trang chi tiết → trích xuất thêm link.
- Xuất CSV, Excel, JSON: Chạy cloud và API có trong gói trả phí.
- Gói miễn phí: 5 dự án, tối đa 200 trang mỗi lần chạy.
ParseHub được nhiều marketer và nhà nghiên cứu thích vì mạnh mà không cần code.
Scrapy: Trình trích xuất link Python cho developer
là “chuẩn vàng” cho developer Python muốn toàn quyền kiểm soát.
- Ưu tiên code: Tự build spider để crawl và trích xuất link ở mọi quy mô.
- Hỗ trợ crawl phân tán: Hiệu quả, bất đồng bộ và tùy biến sâu.
- Xuất CSV, JSON, XML hoặc Database: Bạn tự quyết định đầu ra.
- Mã nguồn mở & miễn phí: Nhưng bạn phải tự quản môi trường chạy.
Nếu bạn quen Python, Scrapy mạnh gần như không có đối thủ.
Diffbot: Trình thu thập link dùng AI cho dữ liệu có cấu trúc
là “bộ não AI” của web scraping. Nó phân tích trang và trả về dữ liệu có cấu trúc—bao gồm cả liên kết—mà không cần cấu hình thủ công.
- Tự nhận diện nội dung: Đưa URL vào, nhận dữ liệu có cấu trúc (bài viết, sản phẩm, link…).
- Crawlbot & Knowledge Graph: Crawl cả website hoặc truy vấn chỉ mục web khổng lồ của họ.
- Chạy qua API: Dễ tích hợp vào BI hoặc pipeline dữ liệu.
- Giá enterprise: Từ khoảng 299 USD/tháng, nhưng “tiền nào của nấy”.
Phù hợp cho doanh nghiệp muốn dữ liệu sạch, có cấu trúc mà không phải vận hành scraper.
Cheerio: Trình thu thập link gọn nhẹ cho Node.js
là HTML parser nhanh, cú pháp giống jQuery cho Node.js.
- Rất nhanh: Parse HTML chỉ trong vài mili-giây.
- Cú pháp quen thuộc: Biết jQuery là dùng được Cheerio.
- Hợp cho trang tĩnh: Không render JS, nhưng rất ổn với nội dung server-render.
- Mã nguồn mở & miễn phí: Thường kết hợp với axios hoặc fetch để request.
Hợp cho developer viết script tùy biến cần tốc độ và sự đơn giản.
Puppeteer: Tự động hóa trình duyệt cho scraping link nâng cao
là thư viện Node.js điều khiển Chrome ở chế độ headless.
- Tự động hóa trình duyệt đầy đủ: Tải trang, click, cuộn, tương tác như người dùng thật.
- Xử lý nội dung động & đăng nhập: Lý tưởng cho website nặng JavaScript hoặc workflow phức tạp.
- Kiểm soát chi tiết: Chờ phần tử, chụp màn hình, chặn/ghi nhận network request.
- Mã nguồn mở & miễn phí: Nhưng tốn tài nguyên và chậm hơn công cụ nhẹ.
Dùng Puppeteer khi bạn cần lấy link từ những website “khó chiều” với scraper cơ bản.
So sánh nhanh: Công cụ nào hợp với nhu cầu của bạn?
Dưới đây là bảng so sánh 12 công cụ:
| Công cụ | Phù hợp nhất cho | Hỗ trợ hàng loạt & trang con | Tùy chọn xuất dữ liệu | Giá |
|---|---|---|---|---|
| Thunderbit | Người không biết code, doanh nghiệp | Có (AI, nhiều tầng) | Excel, CSV, Sheets, Notion, Airtable | Dùng thử miễn phí, từ ~9 USD/tháng |
| Octoparse | Người dùng no-code, analyst | Có | CSV, Excel, JSON, lưu trữ cloud | Có gói miễn phí, ~75 USD/tháng |
| Apify | Đội bán kỹ thuật, dev | Có | CSV, JSON, Sheets qua API | Credit miễn phí, tính theo usage |
| Bright Data | Doanh nghiệp lớn | Có (khối lượng cao) | CSV, JSON, NDJSON qua API | ~350 USD/100k trang |
| WebHarvy | Người không biết code, desktop | Có | Excel, CSV, JSON, XML, SQL | Mua license |
| Web Scraper Extension | Ai cũng dùng, nhanh/miễn phí | Có | CSV, XLSX | Miễn phí, mã nguồn mở |
| ScraperAPI | Developer, người dùng API | Có | JSON (HTML qua API) | Miễn phí 1k request, có gói trả phí |
| ParseHub | Người không biết code, nhu cầu nâng cao | Có | CSV, Excel, JSON, API | Miễn phí 5 dự án, có gói trả phí |
| Scrapy | Dev, Python | Có | CSV, JSON, XML, DB | Miễn phí, mã nguồn mở |
| Diffbot | Doanh nghiệp, AI | Có (AI crawl) | JSON (dữ liệu có cấu trúc qua API) | ~299 USD/tháng+ |
| Cheerio | Dev, Node.js | Có (tự code) | Tùy biến (JSON, v.v.) | Miễn phí, mã nguồn mở |
| Puppeteer | Dev, website phức tạp | Có (tự động hóa đầy đủ) | Tùy biến (đầu ra theo script) | Miễn phí, mã nguồn mở |
Chọn trình thu thập link phù hợp cho doanh nghiệp
Vậy rốt cuộc chọn sao cho đúng? Đây là “phao cứu sinh” mình hay dùng:
- Không biết code? Bắt đầu với Thunderbit, Octoparse, ParseHub, WebHarvy hoặc Web Scraper extension.
- Cần workflow tùy biến? Apify, ScraperAPI hoặc Cheerio rất hợp cho dev.
- Quy mô enterprise? Bright Data hoặc Diffbot sinh ra cho bài toán này.
- Dev Python hoặc Node.js? Scrapy (Python) hoặc Cheerio/Puppeteer (Node.js) cho bạn toàn quyền.
- Muốn xuất thẳng sang Sheets/Notion? Thunderbit là lựa chọn sáng giá.
Cứ chọn theo mức độ thoải mái kỹ thuật, khối lượng dữ liệu và nhu cầu tích hợp. Đa số đều có dùng thử miễn phí, nên cứ test vài cái để tìm “chân ái”.
Giá trị khác biệt của Thunderbit cho trích xuất liên kết năm 2026
Quay lại lý do Thunderbit thật sự khác biệt:
- Đơn giản nhờ AI: Chỉ cần mô tả nhu cầu bằng tiếng Anh đời thường—AI của Thunderbit lo phần còn lại.
- Thu thập nhiều tầng: Lấy link từ trang chính, đi theo trang con và lấy thêm URL—trong một luồng.
- Nhập hàng loạt & xử lý theo batch: Dán hàng trăm URL, trích xuất link hàng loạt và xuất dữ liệu có cấu trúc ngay.
- Tích hợp workflow: Xuất thẳng sang Google Sheets, Notion, Airtable hoặc tải CSV/Excel.
- Không cần bảo trì: AI thích nghi khi website thay đổi, bạn không phải liên tục sửa scraper.
Thunderbit kéo gần khoảng cách giữa “chỉ thu thập dữ liệu” và “có dữ liệu thật sự dùng được”. Đây là công cụ mình ước có từ nhiều năm trước, hồi còn ngập trong các task dữ liệu thủ công.
Kết luận: Thu thập liên kết thông minh hơn, tối ưu workflow
Dữ liệu web là “nhiên liệu” cho tăng trưởng—và công cụ trích xuất liên kết phù hợp chính là động cơ. Dù bạn đang build danh sách lead, theo dõi đối thủ hay tự động hóa nghiên cứu, trong list này đều có lựa chọn hợp với nhu cầu và kỹ năng của bạn.
Nếu bạn muốn thấy trích xuất liên kết hiện đại trông như thế nào, hãy . Có thể bạn sẽ bất ngờ vì chỉ vài cú click đã làm được rất nhiều. Và nếu Thunderbit chưa phải lựa chọn hoàn hảo, cứ thử thêm vài công cụ khác trong danh sách—chưa bao giờ là thời điểm tốt hơn để tự động hóa việc nhàm chán và tập trung vào thứ quan trọng.
Chúc bạn scraping hiệu quả—và mong rằng các liên kết của bạn luôn sạch, có cấu trúc và sẵn sàng hành động. Nếu muốn đào sâu hơn về web scraping, ghé để xem thêm hướng dẫn và mẹo.
Câu hỏi thường gặp (FAQs)
1. Vì sao công cụ trích xuất liên kết lại thiết yếu?
Khi gần một nửa lưu lượng Internet đến từ bot và doanh nghiệp đang thu thập dữ liệu ngày càng mạnh, công cụ trích xuất liên kết trở nên quan trọng để biến “mớ hỗn độn” trên web thành insight có thể hành động. Chúng giúp tự động hóa các việc như tạo lead, tổng hợp nội dung, audit SEO và theo dõi đối thủ, tiết kiệm rất nhiều thời gian và công sức.
2. Điều gì khiến Thunderbit nổi bật so với các công cụ khác?
Thunderbit dùng AI để đơn giản hóa việc scraping—bạn chỉ cần mô tả mục tiêu bằng ngôn ngữ tự nhiên, phần còn lại công cụ tự xử lý. Thunderbit hỗ trợ nhập URL hàng loạt, thu thập nhiều tầng, nhận diện trường thông minh và xuất dữ liệu mượt mà sang Google Sheets, Notion… Rất phù hợp cho người không biết code và người dùng doanh nghiệp muốn kết quả mạnh mà không rườm rà kỹ thuật.
3. Có công cụ nào phù hợp cho developer và workflow tùy biến không?
Có. Apify, ScraperAPI, Cheerio, Puppeteer và Scrapy hướng đến developer. Chúng hỗ trợ scripting, tích hợp API và độ linh hoạt để xử lý tác vụ phức tạp, job quy mô lớn và tự động hóa nâng cao.
4. Công cụ nào tốt nhất cho người không có kinh nghiệm lập trình?
Thunderbit, Octoparse, ParseHub, WebHarvy và Web Scraper Chrome extension là những lựa chọn hàng đầu cho người không chuyên kỹ thuật. Các công cụ này có giao diện trực quan, template dựng sẵn và/hoặc tính năng AI giúp việc trích xuất liên kết trở nên dễ tiếp cận.
5. Tôi nên chọn công cụ trích xuất liên kết như thế nào cho đúng nhu cầu?
Hãy cân nhắc kỹ năng kỹ thuật, khối lượng dữ liệu và nhu cầu xuất/tích hợp. Người không biết code nên chọn Thunderbit hoặc Octoparse; developer có thể ưu tiên Scrapy hoặc Puppeteer. Doanh nghiệp lớn có thể xem Bright Data hoặc Diffbot cho vận hành quy mô lớn. Tốt nhất hãy bắt đầu bằng bản dùng thử miễn phí để kiểm tra mức phù hợp.