

Bạn nên dùng ngôn ngữ lập trình nào cho web scraping? Câu trả lời còn tùy vào dự án của bạn — và tôi đã thấy không ít dev bỏ cuộc trong cay đắng chỉ vì chọn sai ngôn ngữ.
Thị trường phần mềm web scraping đã đạt 1,01 tỷ USD vào năm 2024 và dự kiến sẽ hơn gấp đôi vào năm 2032. Chọn đúng ngôn ngữ có thể giúp bạn ra kết quả nhanh hơn và đỡ phải bảo trì hơn. Chọn sai thì chỉ nhận về scraper hỏng và những cuối tuần bị lãng phí.
Tôi đã xây dựng các công cụ tự động hóa trong nhiều năm. Dưới đây là bảy ngôn ngữ tôi đã dùng để scraping — kèm ví dụ code, những đánh đổi thực tế và cả lúc nào bạn nên bỏ qua việc viết code để dùng Thunderbit thay thế.
Cách Chúng Tôi Chọn Ngôn Ngữ Tốt Nhất Cho Web Scraping
Khi nói đến web scraping, không phải ngôn ngữ lập trình nào cũng như nhau. Tôi đã thấy nhiều dự án thăng hoa — và cũng có những dự án sụp đổ — chỉ vì vài yếu tố then chốt:
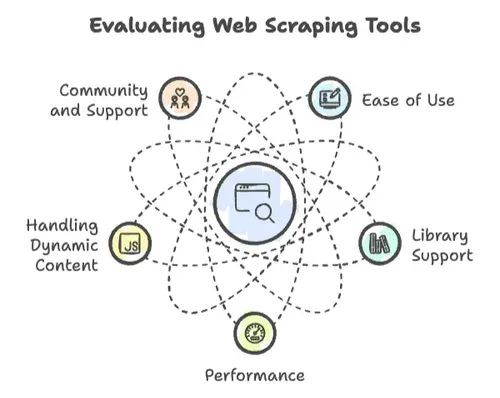
- Dễ sử dụng: Bạn có thể bắt đầu nhanh đến đâu? Cú pháp có thân thiện không, hay bạn phải có bằng tiến sĩ khoa học máy tính mới in được “Hello, World”?
- Hỗ trợ thư viện: Có các thư viện đủ mạnh cho HTTP request, phân tích HTML và xử lý nội dung động không? Hay bạn phải tự làm lại bánh xe?
- Hiệu năng: Nó có thể xử lý việc scraping hàng triệu trang không, hay chỉ chịu nổi vài trăm trang là đuối?
- Xử lý nội dung động: Website hiện đại rất thích JavaScript. Ngôn ngữ của bạn có theo kịp không?
- Cộng đồng và hỗ trợ: Khi bạn gặp bế tắc — mà chắc chắn sẽ gặp — có cộng đồng nào giúp không?
Dựa trên những tiêu chí đó — cộng thêm rất nhiều đêm test muộn — đây là bảy ngôn ngữ tôi sẽ đề cập:
- Python: Lựa chọn mặc định cho cả người mới lẫn dân chuyên.
- JavaScript & Node.js: Vua của nội dung động.
- Ruby: Cú pháp gọn, script nhanh.
- PHP: Đơn giản ở phía server.
- C++: Khi bạn cần tốc độ thô.
- Java: Sẵn sàng cho doanh nghiệp và dễ mở rộng.
- Go (Golang): Nhanh và đồng thời tốt.
Và nếu bạn đang nghĩ: “Shuai, tôi không muốn viết code chút nào cả,” thì cứ ở lại nhé — Thunderbit sẽ xuất hiện ở phần cuối.
Web Scraping bằng Python: Cỗ Máy Mạnh Mẽ, Dễ Cho Người Mới
Hãy bắt đầu với ngôn ngữ được yêu thích nhất: Python. Nếu bạn hỏi một phòng đầy người làm dữ liệu rằng: “Ngôn ngữ lập trình nào tốt nhất cho web scraping?” — rất có thể họ sẽ đồng thanh gọi tên Python như đang hô vang trong một concert của Taylor Swift.
Vì sao là Python?
- Cú pháp thân thiện với người mới: Bạn có thể đọc code Python thành tiếng và nó gần như nghe như tiếng Anh.
- Hệ sinh thái thư viện gần như vô đối: Từ BeautifulSoup để phân tích HTML, Scrapy cho crawling quy mô lớn, Requests cho HTTP, đến Selenium cho tự động hóa trình duyệt — Python có đủ cả.
- Cộng đồng cực lớn: Chỉ riêng web scraping đã có hơn 33.000 câu hỏi trên Stack Overflow.
Ví dụ Python: Scraping tiêu đề trang
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Tiêu đề trang: {title}")
Ưu điểm:
- Phát triển và thử nghiệm nhanh.
- Rất nhiều hướng dẫn và hỏi đáp.
- Tuyệt vời cho phân tích dữ liệu — scraping bằng Python, phân tích bằng pandas, trực quan hóa bằng matplotlib.
- Thư viện vẫn liên tục được cải tiến: bản Scrapy 2.14 (tháng 1/2026) đã mang
async/awaitgốc vào toàn bộ framework, nên câu chuyện async không còn chỉ là sân chơi của Selenium/Playwright nữa.
Hạn chế:
- Chậm hơn các ngôn ngữ biên dịch khi chạy khối lượng rất lớn.
- Xử lý các site siêu động có thể hơi rối (dù Selenium và Playwright có thể giúp).
- Không lý tưởng nếu bạn cần scrape hàng triệu trang với tốc độ cực cao.
Kết luận ngắn gọn:
Nếu bạn mới bắt đầu scraping, hoặc chỉ muốn làm xong việc thật nhanh, Python là ngôn ngữ tốt nhất cho web scraping — không cần bàn cãi. Vì sao Python thống trị web scraping.
JavaScript & Node.js: Scraping Website Động Dễ Như Chơi
Nếu Python là dao đa năng Thụy Sĩ, thì JavaScript (và Node.js) là máy khoan điện — đặc biệt hữu ích khi scraping các website hiện đại, nhiều JavaScript.
Vì sao là JavaScript/Node.js?
- Sinh ra cho nội dung động: Nó chạy trong trình duyệt, nên có thể thấy đúng những gì người dùng thấy — kể cả khi trang được xây bằng React, Angular hay Vue.
- Async là mặc định: Node.js có thể xử lý hàng trăm request cùng lúc.
- Quen thuộc với dân web: Nếu bạn từng làm website, bạn đã biết sẵn một phần JavaScript rồi.
Thư viện chính:
- Playwright: Hỗ trợ nhiều trình duyệt (Chromium, Firefox, WebKit), tự chờ và proxy theo từng context. Nếu bạn bắt đầu một Node scraper mới trong năm 2026, đây là lựa chọn mặc định.
- Puppeteer: Headless Chrome thông qua Chrome DevTools Protocol. Vẫn rất ổn cho những job chỉ dùng Chrome và muốn phụ thuộc nhẹ hơn.
- Cheerio: Phân tích HTML kiểu jQuery cho Node khi bạn không cần trình duyệt thật.
Ví dụ Node.js: Scraping tiêu đề trang bằng Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Tiêu đề trang: ${title}`);
await browser.close();
})();
Ưu điểm:
- Xử lý nội dung render bằng JavaScript một cách tự nhiên.
- Rất hợp để scrape infinite scroll, pop-up và các site tương tác.
- Hiệu quả cho scraping quy mô lớn, chạy đồng thời.
Hạn chế:
- Lập trình async có thể khó với người mới.
- Trình duyệt headless ngốn bộ nhớ nếu bạn chạy quá nhiều cùng lúc.
- Công cụ phân tích dữ liệu ít hơn so với Python.
Khi nào JavaScript/Node.js là ngôn ngữ tốt nhất cho web scraping?
Khi website mục tiêu của bạn là dạng động, hoặc khi bạn muốn tự động hóa các thao tác trong trình duyệt. Thêm về Node.js cho scraping nội dung động.
Ruby: Cú Pháp Sạch Sẽ Cho Những Script Web Scraping Nhanh
Ruby không chỉ dành cho app Rails và những đoạn code đẹp như thơ. Nó cũng là một lựa chọn tốt cho web scraping — đặc biệt nếu bạn thích code mình dễ đọc như một bài haiku.
Vì sao là Ruby?
- Cú pháp dễ đọc, giàu biểu đạt: Bạn có thể viết scraper bằng Ruby mà gần như dễ đọc như danh sách đi chợ.
- Rất hợp để thử nghiệm nhanh: Viết nhanh, chỉnh cũng nhanh.
- Thư viện chính: Nokogiri để phân tích, Mechanize để tự động điều hướng.
Ví dụ Ruby: Scraping tiêu đề trang
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Tiêu đề trang: #{title}"
Ưu điểm:
- Rất dễ đọc và ngắn gọn.
- Tuyệt vời cho dự án nhỏ, script một lần, hoặc nếu bạn vốn đã dùng Ruby.
Hạn chế:
- Chậm hơn Python hoặc Node.js khi làm việc lớn.
- Ít thư viện scraping hơn và cộng đồng scraping cũng nhỏ hơn.
- Không lý tưởng cho site nặng JavaScript (dù bạn có thể dùng Watir hoặc Selenium).
Phù hợp nhất:
Nếu bạn là dân Ruby hoặc chỉ muốn viết một script nhanh, Ruby rất thú vị. Còn nếu scraping quy mô lớn, nhiều động, hãy tìm lựa chọn khác.
PHP: Đơn Giản Ở Phía Server Cho Việc Trích Xuất Dữ Liệu Web
PHP có vẻ như một di tích từ thời đầu của web, nhưng nó vẫn sống khỏe — đặc biệt nếu bạn muốn scrape dữ liệu ngay trên server của mình.
Vì sao là PHP?
- Chạy ở mọi nơi: Phần lớn web server đều đã có PHP.
- Dễ tích hợp với web app: Vừa scrape vừa hiển thị trên site trong một lần làm.
- Thư viện chính: cURL cho HTTP, Guzzle cho request, Symfony Panther cho tự động hóa trình duyệt headless.
Ví dụ PHP: Scraping tiêu đề trang
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Tiêu đề trang: $title\n";
?>
Ưu điểm:
- Dễ triển khai trên web server.
- Tốt cho việc scraping gắn với quy trình web.
- Nhanh với các tác vụ scraping đơn giản phía server.
Hạn chế:
- Hỗ trợ thư viện cho scraping nâng cao còn hạn chế.
- Không sinh ra cho concurrency cao hay scraping quy mô lớn.
- Xử lý site nặng JavaScript khá khó (dù Panther có hỗ trợ).
Phù hợp nhất:
Nếu stack của bạn đã là PHP, hoặc bạn muốn scrape rồi hiển thị dữ liệu ngay trên website, PHP là lựa chọn thực tế. So sánh PHP và Python cho scraping.
C++: Web Scraping Hiệu Năng Cao Cho Dự Án Quy Mô Lớn
C++ là chiếc xe cơ bắp của thế giới lập trình. Nếu bạn cần tốc độ thô và khả năng kiểm soát cao, và không ngại một chút lao động thủ công, C++ có thể đưa bạn đi rất xa.
Vì sao là C++?
- Cực nhanh: Vượt trội hơn đa số ngôn ngữ trong các tác vụ bị giới hạn bởi CPU.
- Kiểm soát chi tiết: Quản lý bộ nhớ, thread và các tối ưu hiệu năng.
- Thư viện chính: libcurl cho HTTP, htmlcxx cho phân tích.
Ví dụ C++: Scraping tiêu đề trang
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Tiêu đề trang: " << title << std::endl;
} else {
std::cout << "Không tìm thấy thẻ title" << std::endl;
}
return 0;
}
Ưu điểm:
- Tốc độ gần như không có đối thủ cho các job scraping khổng lồ.
- Rất hợp để tích hợp scraping vào hệ thống hiệu năng cao.
Hạn chế:
- Đường cong học tập khá dốc (nhớ chuẩn bị cà phê).
- Phải quản lý bộ nhớ thủ công.
- Ít thư viện cấp cao; không lý tưởng cho nội dung động.
Phù hợp nhất:
Khi bạn cần scrape hàng triệu trang, hoặc hiệu năng là yếu tố sống còn. Nếu không, bạn có thể sẽ dành nhiều thời gian debug hơn là scraping.
Java: Giải Pháp Web Scraping Sẵn Sàng Cho Doanh Nghiệp
Java là con ngựa thồ của thế giới doanh nghiệp. Nếu bạn đang xây một thứ phải chạy mãi, xử lý lượng dữ liệu khổng lồ và sống sót qua tận ngày tận thế zombie, Java là người bạn đáng tin.
Vì sao là Java?
- Bền bỉ và dễ mở rộng: Rất hợp cho các dự án scraping lớn, chạy dài.
- Typing chặt và xử lý lỗi tốt: Ít bất ngờ hơn khi lên production.
- Thư viện chính: Jsoup để phân tích, Selenium WebDriver cho tự động hóa trình duyệt, Apache HttpClient cho HTTP.
Ví dụ Java: Scraping tiêu đề trang
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Tiêu đề trang: " + title);
}
}
Ưu điểm:
- Hiệu năng cao và xử lý đồng thời tốt.
- Tuyệt vời cho codebase lớn, cần bảo trì lâu dài.
- Hỗ trợ khá tốt cho nội dung động (qua Selenium hoặc HtmlUnit).
Hạn chế:
- Cú pháp dài dòng; cần nhiều thiết lập hơn các ngôn ngữ script.
- Quá mức cần thiết đối với script nhỏ, dùng một lần.
Phù hợp nhất:
Scraping quy mô doanh nghiệp, hoặc khi bạn cần độ tin cậy và khả năng mở rộng cực vững.
Go (Golang): Web Scraping Nhanh Và Đồng Thời Tốt
Go là “tay chơi mới” trên thị trường, nhưng đã tạo được tiếng vang — nhất là trong scraping tốc độ cao và chạy đồng thời.
Vì sao là Go?
- Tốc độ biên dịch: Gần nhanh như C++.
- Đồng thời tích hợp sẵn: Goroutines giúp song song hóa việc scraping rất dễ dàng.
- Thư viện chính: Colly cho scraping, Goquery cho phân tích.
Ví dụ Go: Scraping tiêu đề trang
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Tiêu đề trang:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Lỗi:", err)
}
}
Ưu điểm:
- Cực nhanh và hiệu quả cho scraping quy mô lớn.
- Dễ triển khai (một file binary duy nhất).
- Rất hợp cho crawling đồng thời.
Hạn chế:
- Cộng đồng nhỏ hơn Python hoặc Node.js.
- Ít thư viện scraping cấp cao hơn.
- Xử lý site nặng JavaScript cần thêm thiết lập (Chromedp hoặc Selenium).
Phù hợp nhất:
Khi bạn cần scraping ở quy mô lớn, hoặc khi Python đơn giản là không đủ nhanh. Go so với Python cho scraping: so sánh hiệu năng.
So Sánh Những Ngôn Ngữ Lập Trình Tốt Nhất Cho Web Scraping
Hãy ghép mọi thứ lại với nhau. Dưới đây là bảng so sánh song song để giúp bạn chọn ngôn ngữ tốt nhất cho web scraping trong năm 2026:
| Ngôn ngữ/Công cụ | Dễ sử dụng | Hiệu năng | Hỗ trợ thư viện | Xử lý nội dung động | Trường hợp sử dụng tốt nhất |
|---|---|---|---|---|---|
| Python | Rất cao | Trung bình | Xuất sắc | Tốt (Selenium/Playwright) | Mục đích chung, người mới, phân tích dữ liệu |
| JavaScript/Node.js | Trung bình | Cao | Mạnh | Xuất sắc (gốc) | Site động, scraping async, dân web dev |
| Ruby | Cao | Trung bình | Khá | Hạn chế (Watir) | Script nhanh, thử nghiệm |
| PHP | Trung bình | Trung bình | Tạm ổn | Hạn chế (Panther) | Phía server, tích hợp web app |
| C++ | Thấp | Rất cao | Hạn chế | Rất hạn chế | Cần hiệu năng, quy mô cực lớn |
| Java | Trung bình | Cao | Tốt | Tốt (Selenium/HtmlUnit) | Doanh nghiệp, dịch vụ chạy dài |
| Go (Golang) | Trung bình | Rất cao | Đang phát triển | Trung bình (Chromedp) | Scraping tốc độ cao, chạy đồng thời |
Khi Nào Nên Bỏ Qua Việc Viết Code: Thunderbit Như Một Giải Pháp Web Scraping No-Code
Hãy thử Thunderbit AI Web Scraper Web scraping no-code, dùng AI cho người làm kinh doanh, marketer và đội sales. Get Started Free
Được rồi, nói thật nhé: đôi khi bạn chỉ muốn có dữ liệu — không muốn code, không muốn debug, cũng không muốn đau đầu với câu hỏi “tại sao selector này không chạy”. Đó là lúc Thunderbit phát huy tác dụng.
Là đồng sáng lập Thunderbit, tôi muốn xây một công cụ giúp web scraping dễ như gọi đồ ăn mang về. Đây là những điểm khiến Thunderbit nổi bật:
- Thiết lập chỉ 2 cú nhấp: Chỉ cần bấm “AI Suggest Fields” và “Scrape”. Không cần lo HTTP request, proxy hay mánh chống bot.
- Mẫu thông minh: Một mẫu scraper có thể thích ứng với nhiều bố cục trang khác nhau. Không cần viết lại scraper mỗi khi website thay đổi.
- Scraping trên trình duyệt & trên cloud: Bạn có thể chọn scrape ngay trong trình duyệt (rất tốt cho site cần đăng nhập) hoặc trên cloud (cực nhanh cho dữ liệu công khai).
- Xử lý nội dung động: AI của Thunderbit điều khiển một trình duyệt thật — nên xử lý được infinite scroll, pop-up, đăng nhập và nhiều thứ khác.
- Xuất đi mọi nơi: Tải về Excel, Google Sheets, Airtable, Notion, hoặc chỉ cần copy vào clipboard.
- Không cần bảo trì: Nếu website thay đổi, chỉ cần chạy lại gợi ý AI. Không còn những đêm khuya debug nữa.
- Lập lịch & tự động hóa: Thiết lập scraper chạy theo lịch — không cần cron job, không cần dựng server.
- Bộ trích xuất chuyên dụng: Cần email, số điện thoại hoặc hình ảnh? Thunderbit cũng có bộ trích xuất một chạm cho những thứ đó.
Và điều tuyệt nhất là gì? Bạn không cần biết dù chỉ một dòng code. Thunderbit được tạo ra cho người dùng doanh nghiệp, marketer, đội sales, người làm bất động sản — bất kỳ ai cần dữ liệu thật nhanh.
Muốn xem Thunderbit hoạt động thế nào? Tải tiện ích Chrome Extension hoặc xem kênh YouTube của chúng tôi để xem demo.
Dùng thử Thunderbit AI Web Scraper miễn phí
Kết Luận: Chọn Ngôn Ngữ Tốt Nhất Cho Web Scraping Năm 2026
Data Scraping là gì và cách thực hiện Get Started Free
Web scraping trong năm 2026 dễ tiếp cận hơn — và mạnh hơn — bao giờ hết. Đây là những gì tôi rút ra sau nhiều năm lăn lộn trong mảng tự động hóa:
- Python vẫn là ngôn ngữ tốt nhất cho web scraping nếu bạn muốn bắt đầu nhanh và có vô số tài nguyên trong tay.
- JavaScript/Node.js gần như không thể bị đánh bại khi scraping các site động, nhiều JavaScript.
- Ruby và PHP rất hợp cho script nhanh và tích hợp web, đặc biệt nếu bạn đã dùng sẵn chúng.
- C++ và Go là bạn tốt của bạn khi cần tốc độ và quy mô.
- Java là lựa chọn hàng đầu cho các dự án doanh nghiệp, chạy dài hạn.
- Và nếu bạn muốn bỏ qua việc viết code hoàn toàn? Thunderbit chính là vũ khí bí mật của bạn.
Trước khi bắt tay vào làm, hãy tự hỏi:
- Dự án của mình lớn đến mức nào?
- Mình có cần xử lý nội dung động không?
- Mức độ thoải mái về kỹ thuật của mình tới đâu?
- Mình muốn xây công cụ, hay chỉ muốn lấy dữ liệu?
Hãy thử một đoạn code ở trên, hoặc dùng Thunderbit cho dự án tiếp theo của bạn. Và nếu muốn đi sâu hơn, hãy xem Thunderbit Blog của chúng tôi để có thêm hướng dẫn, mẹo và những câu chuyện scraping thực tế.
Chúc bạn scraping vui vẻ — và mong dữ liệu của bạn luôn sạch, có cấu trúc, và chỉ cách bạn một cú nhấp.
P.S. Nếu bạn từng bị mắc kẹt trong mê cung web scraping lúc 2 giờ sáng, hãy nhớ: luôn có Thunderbit. Hoặc cà phê. Hoặc cả hai.
Dùng Thunderbit AI Web Scraper ngay Get Started Free
Câu hỏi thường gặp
1. Ngôn ngữ lập trình nào tốt nhất cho web scraping trong năm 2026?
Python vẫn là lựa chọn hàng đầu nhờ cú pháp dễ đọc, thư viện mạnh (như BeautifulSoup, Scrapy và Selenium) và cộng đồng rất lớn. Nó lý tưởng cho cả người mới lẫn người dùng chuyên nghiệp, đặc biệt khi kết hợp scraping với phân tích dữ liệu.
2. Ngôn ngữ nào tốt nhất để scrape các website nặng JavaScript?
JavaScript (Node.js) là lựa chọn hàng đầu cho site động. Các công cụ như Puppeteer và Playwright cho bạn quyền kiểm soát trình duyệt đầy đủ, cho phép tương tác với nội dung được tải bằng React, Vue hoặc Angular.
3. Có lựa chọn no-code nào cho web scraping không?
Có — Thunderbit là AI web scraper no-code có thể xử lý mọi thứ từ nội dung động đến lập lịch. Chỉ cần bấm “AI Suggest Fields” và bắt đầu scraping. Nó rất phù hợp cho đội sales, marketing hoặc vận hành cần dữ liệu có cấu trúc thật nhanh.
4. Nếu tác nhân lập trình AI có thể viết scraper giúp tôi, tôi còn cần chọn ngôn ngữ không?
Đây là câu hỏi hợp lý trong năm 2026. Những công cụ như Claude Code, Cursor và OpenAI Codex hoàn toàn có thể tạo ra một Scrapy spider, một script Playwright, hoặc một crawler Go + Colly chỉ từ một prompt dài một đoạn — nên ma sát của câu hỏi “tôi nên học ngôn ngữ nào trước” thực sự đã thấp hơn hai năm trước. Nhưng tác nhân đó vẫn sẽ sinh ra code bằng một ngôn ngữ nào đó, và bạn (hoặc người tiếp quản dự án) vẫn phải đọc, debug và triển khai nó. Vì vậy, việc chọn ngôn ngữ vẫn quan trọng; chỉ là nó quan trọng hơn cho khâu bảo trì hơn là cho 30 dòng code đầu tiên. Nếu bạn không muốn đụng vào code chút nào, đó chính là lúc Thunderbit phù hợp — nó bỏ qua luôn câu chuyện ngôn ngữ.
Tìm hiểu thêm:




