Link hỏng. Trang mồ côi. Một trang “test” từ năm 2019 mà chẳng hiểu sao Google vẫn index. Ai quản trị website chắc chắn từng “đứng hình” vì mấy ca như vậy.
Một crawler xịn sẽ tóm gọn hết các vấn đề đó — đồng thời vẽ lại toàn bộ bản đồ website để bạn sửa cho ra ngô ra khoai. Nhưng nhiều người lại hay nhầm “web crawler” với “web scraper”. Hai thứ này khác nhau một trời một vực.
Mình đã thử 10 crawler miễn phí trên các website thật. Có cái cực hợp để audit SEO. Có cái lại mạnh về trích xuất dữ liệu. Dưới đây là những gì thật sự hiệu quả — và những gì không.
Website Crawler là gì? Nắm vững khái niệm cơ bản
Nói thẳng cho rõ: website crawler không phải là web scraper. Mình biết hai thuật ngữ này hay bị dùng lẫn, nhưng bản chất khác nhau. Cứ tưởng tượng crawler như “người vẽ bản đồ” cho website: nó đi khắp mọi ngóc ngách, lần theo từng liên kết rồi dựng lên sơ đồ toàn bộ site. Nhiệm vụ chính của nó là khám phá: tìm URL, hiểu cấu trúc site và ghi nhận nội dung để lập chỉ mục. Đây cũng là cách các công cụ tìm kiếm như Google vận hành bot, và là nền tảng để các công cụ SEO kiểm tra “sức khỏe” website ().
Ngược lại, web scraping giống kiểu “thợ đào dữ liệu”. Nó không cần bản đồ tổng thể — nó chỉ tập trung lấy “vàng”: giá sản phẩm, tên công ty, review, email… bất cứ trường dữ liệu nào bạn cần. Scraper sẽ trích xuất các trường cụ thể từ những trang mà crawler tìm ra ().
Ví dụ cho dễ hình dung:
- Crawler: Người đi hết mọi dãy kệ trong siêu thị để lập danh sách toàn bộ mặt hàng.
- Scraper: Người đi thẳng tới kệ cà phê và ghi lại giá của từng loại cà phê organic.
Vì sao chuyện này quan trọng? Vì nếu bạn chỉ muốn tìm toàn bộ trang trên website (ví dụ để audit SEO), bạn cần crawler. Còn nếu bạn muốn kéo toàn bộ giá sản phẩm từ website đối thủ, bạn cần scraper — hoặc tốt nhất là một công cụ làm được cả hai.
Vì sao nên dùng Web Crawler online? Lợi ích kinh doanh nổi bật
Vậy tại sao phải dùng web crawler? Đơn giản vì web ngày càng phình to. Thực tế, hơn để tối ưu website, và có công cụ SEO crawl tới .
Crawler có thể giúp bạn:
- Audit SEO: Tìm link hỏng, thiếu title, trùng nội dung, trang mồ côi… ().
- Kiểm tra link & QA: Phát hiện 404 và vòng lặp redirect trước khi người dùng gặp phải ().
- Tạo sitemap: Tự động tạo XML sitemap cho công cụ tìm kiếm và cho việc lập kế hoạch ().
- Kiểm kê nội dung: Lập danh sách toàn bộ trang, phân cấp, metadata.
- Tuân thủ & accessibility: Quét toàn site theo WCAG, SEO và yêu cầu pháp lý ().
- Hiệu năng & bảo mật: Gắn cờ trang tải chậm, ảnh quá nặng hoặc vấn đề bảo mật ().
- Dữ liệu cho AI & phân tích: Đưa dữ liệu crawl vào hệ thống analytics hoặc AI ().
Bảng dưới đây tóm tắt các tình huống sử dụng theo vai trò công việc:
| Trường hợp sử dụng | Phù hợp nhất cho | Lợi ích / Kết quả |
|---|---|---|
| SEO & Audit website | Marketing, SEO, Chủ doanh nghiệp nhỏ | Phát hiện lỗi kỹ thuật, tối ưu cấu trúc, cải thiện thứ hạng |
| Kiểm kê nội dung & QA | Quản lý nội dung, Webmaster | Rà soát/di chuyển nội dung, bắt lỗi link/ảnh hỏng |
| Tạo lead (Scraping) | Sales, Biz Dev | Tự động tìm khách hàng tiềm năng, đổ lead mới vào CRM |
| Theo dõi đối thủ | E-commerce, Product Manager | Giám sát giá, sản phẩm mới, thay đổi tồn kho |
| Tạo sitemap & sao chép cấu trúc | Developer, DevOps, Consultant | Sao chép cấu trúc để redesign hoặc backup |
| Tổng hợp nội dung | Nghiên cứu, Media, Analyst | Gom dữ liệu từ nhiều site để phân tích/xu hướng |
| Nghiên cứu thị trường | Analyst, Nhóm huấn luyện AI | Thu thập dataset lớn để phân tích hoặc train mô hình AI |
()
Cách tôi chọn ra các công cụ Website Crawler miễn phí tốt nhất
Mình đã dành không ít đêm muộn (và uống cà phê nhiều hơn mức muốn thừa nhận) để “đào” các công cụ crawler, đọc tài liệu và chạy crawl thử. Đây là các tiêu chí mình dùng:
- Năng lực kỹ thuật: Có xử lý được website hiện đại (JavaScript, đăng nhập, nội dung động) không?
- Dễ dùng: Thân thiện với người không kỹ thuật hay phải “phù phép” command line?
- Giới hạn gói miễn phí: Miễn phí thật hay chỉ là bản dùng thử?
- Khả năng dùng online: Là công cụ cloud, app desktop hay thư viện code?
- Tính năng khác biệt: Có điểm mạnh riêng như trích xuất bằng AI, sitemap trực quan, crawling theo sự kiện…?
Mình test từng công cụ, đọc phản hồi người dùng và so sánh tính năng kiểu “đặt lên bàn cân”. Công cụ nào khiến mình muốn quăng laptop ra cửa sổ thì chắc chắn không có mặt trong danh sách.
Bảng so sánh nhanh: 10 Website Crawler miễn phí đáng chú ý
| Công cụ & loại | Tính năng chính | Dùng tốt nhất cho | Yêu cầu kỹ thuật | Chi tiết gói miễn phí |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling cấp doanh nghiệp, proxy, render JS, giải CAPTCHA | Thu thập dữ liệu quy mô lớn | Biết kỹ thuật sẽ lợi hơn | Dùng thử: 3 scraper, mỗi scraper 100 bản ghi (khoảng 300 bản ghi tổng) |
| Crawlbase (Cloud/API) | Crawling qua API, chống bot, proxy, render JS | Dev cần hạ tầng crawl backend | Tích hợp API | Miễn phí: ~5.000 API call trong 7 ngày, sau đó 1.000/tháng |
| ScraperAPI (Cloud/API) | Xoay proxy, render JS, crawl async, endpoint dựng sẵn | Dev, theo dõi giá, dữ liệu SEO | Thiết lập tối thiểu | Miễn phí: 5.000 API call trong 7 ngày, sau đó 1.000/tháng |
| Diffbot Crawlbot (Cloud) | Crawl + trích xuất bằng AI, knowledge graph, render JS | Dữ liệu có cấu trúc quy mô lớn, AI/ML | Tích hợp API | Miễn phí: 10.000 credit/tháng (khoảng 10k trang) |
| Screaming Frog (Desktop) | Audit SEO, phân tích link/meta, sitemap, trích xuất tùy chỉnh | Audit SEO, quản trị website | App desktop, GUI | Miễn phí: 500 URL mỗi lần crawl, chỉ tính năng cốt lõi |
| SiteOne Crawler (Desktop) | SEO, hiệu năng, accessibility, bảo mật, export offline, Markdown | Dev, QA, migration, tài liệu hóa | Desktop/CLI, GUI | Miễn phí & mã nguồn mở, báo cáo GUI 1.000 URL (có thể chỉnh) |
| Crawljax (Java, OpenSrc) | Crawl theo sự kiện cho site nặng JS, xuất bản tĩnh | Dev, QA cho web app động | Java, CLI/cấu hình | Miễn phí & mã nguồn mở, không giới hạn |
| Apache Nutch (Java, OpenSrc) | Crawl phân tán, plugin, tích hợp Hadoop, search tùy biến | Tự xây search engine, crawl quy mô lớn | Java, command-line | Miễn phí & mã nguồn mở, chỉ tốn chi phí hạ tầng |
| YaCy (Java, OpenSrc) | Crawl & tìm kiếm P2P, riêng tư, index web/intranet | Search riêng tư, phi tập trung | Java, giao diện trình duyệt | Miễn phí & mã nguồn mở, không giới hạn |
| PowerMapper (Desktop/SaaS) | Sitemap trực quan, accessibility, QA, tương thích trình duyệt | Agency, QA, mapping trực quan | GUI, dễ dùng | Dùng thử: 30 ngày, 100 trang (desktop) hoặc 10 trang (online) mỗi lần quét |
BrightData: Website Crawler cloud “hạng nặng” cho doanh nghiệp

BrightData đúng kiểu “đồ nghề hạng nặng” trong thế giới crawling. Đây là nền tảng cloud với mạng proxy cực lớn, render JavaScript, giải CAPTCHA và có IDE để tùy biến crawl. Nếu bạn cần thu thập dữ liệu quy mô lớn — ví dụ theo dõi giá trên hàng trăm website e-commerce — hạ tầng của BrightData thật sự khó có đối thủ ().
Điểm mạnh:
- Xử lý tốt các website có chống bot
- Mở rộng quy mô theo nhu cầu doanh nghiệp
- Có template dựng sẵn cho nhiều website phổ biến
Hạn chế:
- Không có gói miễn phí vĩnh viễn (chỉ có trial: 3 scraper, mỗi scraper 100 bản ghi)
- Có thể “quá tay” nếu chỉ audit đơn giản
- Người không kỹ thuật sẽ cần thời gian làm quen
Nếu bạn cần crawl quy mô lớn, BrightData giống như thuê xe F1. Chỉ là sau “chạy thử” thì khó mà miễn phí được ().
Crawlbase: Web Crawler miễn phí dạng API dành cho developer

Crawlbase (trước đây là ProxyCrawl) tập trung vào crawling theo kiểu lập trình. Bạn gọi API kèm URL, hệ thống trả về HTML — còn proxy, định tuyến theo khu vực và CAPTCHA sẽ được xử lý “hậu trường” ().
Điểm mạnh:
- Tỷ lệ thành công cao (99%+)
- Hỗ trợ website nặng JavaScript
- Phù hợp để nhúng vào app hoặc workflow nội bộ
Hạn chế:
- Cần tích hợp API/SDK
- Gói miễn phí: ~5.000 API call trong 7 ngày, sau đó 1.000/tháng
Nếu bạn là developer muốn crawl (và có thể scrape) quy mô lớn mà không phải tự quản proxy, Crawlbase là lựa chọn đáng cân nhắc ().
ScraperAPI: Đơn giản hóa việc crawl website động

ScraperAPI đúng kiểu “cứ lấy hộ tôi trang này”. Bạn đưa URL, nó lo proxy, headless browser và chống bot, rồi trả về HTML (hoặc dữ liệu có cấu trúc cho một số website). Công cụ này đặc biệt hợp với trang động và có gói miễn phí khá thoáng ().
Điểm mạnh:
- Rất dễ cho developer (chỉ cần gọi API)
- Xử lý CAPTCHA, chặn IP, JavaScript
- Miễn phí: 5.000 API call trong 7 ngày, sau đó 1.000/tháng
Hạn chế:
- Không có báo cáo crawl dạng trực quan
- Nếu muốn lần theo link, bạn vẫn cần tự viết logic crawl
Nếu bạn muốn tích hợp web crawling vào codebase trong vài phút, ScraperAPI là lựa chọn “khỏi nghĩ nhiều”.
Diffbot Crawlbot: Tự động khám phá cấu trúc website

Diffbot Crawlbot bắt đầu “thông minh” thật sự. Nó không chỉ crawl — mà còn dùng AI để phân loại trang và trích xuất dữ liệu có cấu trúc (bài viết, sản phẩm, sự kiện…) ra JSON. Cảm giác như có một thực tập sinh robot đọc hiểu nội dung thay bạn ().
Điểm mạnh:
- Trích xuất bằng AI, không chỉ dừng ở crawling
- Hỗ trợ JavaScript và nội dung động
- Miễn phí: 10.000 credit/tháng (khoảng 10k trang)
Hạn chế:
- Thiên về developer (cần tích hợp API)
- Không phải công cụ SEO trực quan; phù hợp dự án dữ liệu hơn
Nếu bạn cần dữ liệu có cấu trúc ở quy mô lớn cho AI/analytics, Diffbot rất “đáng gờm”.
Screaming Frog: Crawler SEO desktop miễn phí

Screaming Frog là “huyền thoại” crawler desktop cho audit SEO. Bản miễn phí crawl tối đa 500 URL mỗi lần và cho bạn gần như mọi thứ: link hỏng, thẻ meta, nội dung trùng, sitemap… ().
Điểm mạnh:
- Nhanh, kỹ, được giới SEO tin dùng
- Không cần code — nhập URL là chạy
- Miễn phí tới 500 URL mỗi lần crawl
Hạn chế:
- Chỉ chạy trên desktop (không có bản cloud)
- Tính năng nâng cao (render JS, lên lịch) cần mua license
Nếu bạn làm SEO nghiêm túc, Screaming Frog gần như là công cụ “phải có” — chỉ là đừng kỳ vọng nó crawl miễn phí cho website 10.000 trang.
SiteOne Crawler: Xuất site tĩnh và tài liệu hóa

SiteOne Crawler giống “dao đa năng” cho audit kỹ thuật. Mã nguồn mở, chạy đa nền tảng, vừa crawl vừa audit, thậm chí xuất website sang Markdown để làm tài liệu hoặc dùng offline ().
Điểm mạnh:
- Bao phủ SEO, hiệu năng, accessibility, bảo mật
- Xuất site để lưu trữ hoặc phục vụ migration
- Miễn phí & mã nguồn mở, không giới hạn sử dụng
Hạn chế:
- Kỹ thuật hơn so với nhiều công cụ GUI thuần
- Báo cáo GUI mặc định giới hạn 1.000 URL (có thể cấu hình)
Nếu bạn là developer/QA/consultant muốn đào sâu (và mê open-source), SiteOne đúng là một “viên ngọc ẩn”.
Crawljax: Web crawler Java mã nguồn mở cho trang động
Crawljax là công cụ chuyên trị: nó được thiết kế để crawl các web app hiện đại nặng JavaScript bằng cách mô phỏng tương tác người dùng (click, điền form…). Cơ chế theo sự kiện và còn có thể xuất bản tĩnh từ một site động ().
Điểm mạnh:
- Rất mạnh khi crawl SPA và site nhiều AJAX
- Mã nguồn mở, dễ mở rộng
- Không giới hạn sử dụng
Hạn chế:
- Cần Java và một chút lập trình/cấu hình
- Không phù hợp người không kỹ thuật
Nếu bạn cần crawl app React/Angular theo đúng hành vi người dùng, Crawljax là “đồng đội” đáng tin.
Apache Nutch: Website crawler phân tán, mở rộng quy mô lớn

Apache Nutch là “cây đa cây đề” trong nhóm crawler mã nguồn mở. Nó sinh ra để crawl phân tán quy mô cực lớn — kiểu tự xây search engine hoặc index hàng triệu trang ().
Điểm mạnh:
- Có thể mở rộng tới hàng tỷ trang khi kết hợp Hadoop
- Cấu hình sâu, mở rộng linh hoạt
- Miễn phí & mã nguồn mở
Hạn chế:
- Độ khó cao (Java, command-line, cấu hình)
- Không dành cho website nhỏ hoặc người dùng phổ thông
Nếu bạn muốn crawl web ở quy mô lớn và không ngại “đụng” command line, Nutch là lựa chọn đúng bài.
YaCy: Web crawler và công cụ tìm kiếm dạng peer-to-peer
YaCy là một lựa chọn rất khác: crawler và search engine phi tập trung. Mỗi instance sẽ crawl và index website, và bạn có thể tham gia mạng P2P để chia sẻ chỉ mục với người khác ().
Điểm mạnh:
- Ưu tiên quyền riêng tư, không có máy chủ trung tâm
- Hợp để xây search nội bộ/intranet
- Miễn phí & mã nguồn mở
Hạn chế:
- Chất lượng kết quả phụ thuộc độ phủ của mạng
- Cần thiết lập ban đầu (Java, giao diện trình duyệt)
Nếu bạn quan tâm mô hình phi tập trung hoặc muốn tự vận hành search engine, YaCy là một lựa chọn rất thú vị.
PowerMapper: Tạo sitemap trực quan cho UX và QA

PowerMapper tập trung vào việc “nhìn thấy” cấu trúc website. Nó crawl site và tạo sitemap tương tác, đồng thời kiểm tra accessibility, tương thích trình duyệt và các yếu tố SEO cơ bản ().
Điểm mạnh:
- Sitemap trực quan rất hợp cho agency và designer
- Có kiểm tra accessibility và tuân thủ
- GUI dễ dùng, không cần kỹ thuật
Hạn chế:
- Chỉ có bản dùng thử (30 ngày, 100 trang desktop/10 trang online mỗi lần quét)
- Bản đầy đủ là trả phí
Nếu bạn cần trình bày sơ đồ site cho khách hàng hoặc kiểm tra tuân thủ, PowerMapper là công cụ khá tiện.
Chọn Web Crawler miễn phí phù hợp với nhu cầu của bạn
Nhiều lựa chọn quá thì chọn sao? Đây là gợi ý nhanh của mình:
- Audit SEO: Screaming Frog (site nhỏ), PowerMapper (trực quan), SiteOne (audit sâu)
- Web app động: Crawljax
- Quy mô lớn / search tùy biến: Apache Nutch, YaCy
- Developer cần API: Crawlbase, ScraperAPI, Diffbot
- Tài liệu hóa / lưu trữ: SiteOne Crawler
- Quy mô doanh nghiệp (dùng thử): BrightData, Diffbot
Các yếu tố nên cân nhắc:
- Khả năng mở rộng: Website/công việc crawl của bạn lớn tới đâu?
- Độ dễ dùng: Bạn muốn click là chạy hay sẵn sàng viết code?
- Xuất dữ liệu: Cần CSV, JSON hay tích hợp với công cụ khác?
- Hỗ trợ: Có cộng đồng/tài liệu để tự xử khi kẹt không?
Khi Web Crawling gặp Web Scraping: Vì sao Thunderbit là lựa chọn “khôn” hơn
Thực tế là: đa số người crawl website không phải để có một “bản đồ đẹp”. Mục tiêu cuối thường là dữ liệu có cấu trúc — như danh sách sản phẩm, thông tin liên hệ, hay kiểm kê nội dung. Đây là lúc phát huy.
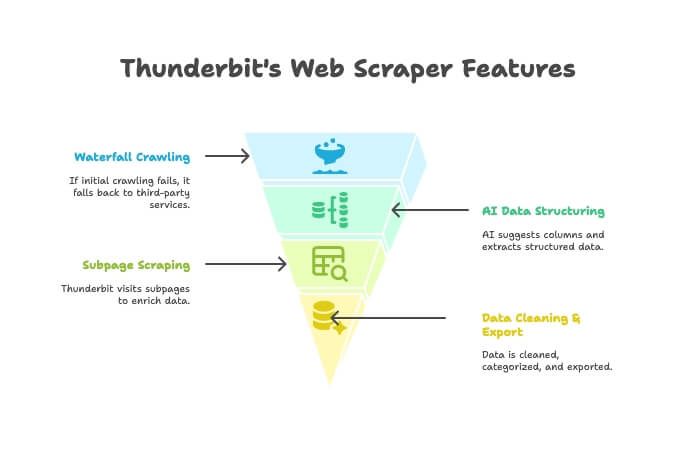
Thunderbit không chỉ là crawler hay scraper — mà là tiện ích Chrome dùng AI, kết hợp cả hai. Cách hoạt động:
- AI Crawler: Thunderbit khám phá website giống như một crawler.
- Waterfall Crawling: Nếu engine của Thunderbit không lấy được trang (ví dụ gặp tường chống bot), nó tự động chuyển sang dịch vụ crawling bên thứ ba — không cần bạn cấu hình thủ công.
- AI cấu trúc hóa dữ liệu: Khi đã có HTML, AI của Thunderbit gợi ý cột phù hợp và trích xuất dữ liệu có cấu trúc (tên, giá, email…) mà bạn không phải viết selector.
- Scrape trang con: Cần lấy chi tiết từ từng trang sản phẩm? Thunderbit có thể tự vào từng subpage và làm giàu bảng dữ liệu.
- Làm sạch & xuất dữ liệu: Có thể tóm tắt, phân loại, dịch và xuất sang Excel, Google Sheets, Airtable hoặc Notion chỉ với một cú click.
- No-code, dễ dùng: Biết dùng trình duyệt là dùng được Thunderbit. Không code, không proxy, không đau đầu.
Khi nào nên dùng Thunderbit thay vì crawler truyền thống?
- Khi bạn cần một bảng tính sạch, dùng được ngay — không chỉ danh sách URL.
- Khi bạn muốn tự động hóa trọn quy trình (crawl, trích xuất, làm sạch, xuất dữ liệu) trong một nơi.
- Khi bạn muốn tiết kiệm thời gian và đỡ “mất sức”.
Bạn có thể để tự trải nghiệm vì sao nhiều người dùng doanh nghiệp đang chuyển sang giải pháp này.
Kết luận: Tận dụng tối đa các Website Crawler miễn phí
Website crawler đã “lên trình” rất nhiều. Dù bạn là marketer, developer hay chỉ muốn giữ website luôn “khỏe”, lúc nào cũng có một lựa chọn miễn phí (hoặc ít nhất miễn phí để thử) hợp nhu cầu. Từ nền tảng cấp doanh nghiệp như BrightData và Diffbot, đến các “viên ngọc” mã nguồn mở như SiteOne và Crawljax, hay công cụ vẽ sơ đồ trực quan như PowerMapper — lựa chọn giờ đa dạng hơn bao giờ hết.
Nhưng nếu bạn muốn một cách làm thông minh và liền mạch hơn để đi từ “tôi cần dữ liệu này” đến “đây là file spreadsheet của tôi”, hãy thử Thunderbit. Nó được thiết kế cho người dùng doanh nghiệp cần kết quả, không chỉ báo cáo.
Sẵn sàng bắt đầu crawl? Hãy tải một công cụ, chạy thử một lượt và xem bạn đã bỏ lỡ những gì. Và nếu bạn muốn biến crawling thành dữ liệu dùng được chỉ trong hai cú click, .
Muốn đọc thêm các bài phân tích sâu và hướng dẫn thực chiến, ghé .
FAQ
Khác nhau giữa website crawler và web scraper là gì?
Crawler có nhiệm vụ phát hiện và lập bản đồ toàn bộ trang trên website (giống như tạo mục lục). Scraper thì trích xuất các trường dữ liệu cụ thể (như giá, email, review) từ những trang đó. Crawler đi tìm, scraper đi “đào” ().
Web crawler miễn phí nào phù hợp nhất cho người không rành kỹ thuật?
Với website nhỏ và audit SEO, Screaming Frog khá dễ dùng. Nếu cần sơ đồ trực quan, PowerMapper rất ổn (trong thời gian dùng thử). Còn nếu mục tiêu là dữ liệu có cấu trúc và bạn muốn trải nghiệm no-code ngay trên trình duyệt, Thunderbit là lựa chọn dễ nhất.
Có website nào chặn web crawler không?
Có — một số website dùng robots.txt hoặc cơ chế chống bot (CAPTCHA, chặn IP…) để ngăn crawler. Các công cụ như ScraperAPI, Crawlbase và Thunderbit (nhờ waterfall crawling) thường có thể vượt qua một phần, nhưng hãy crawl có trách nhiệm và tôn trọng quy định của website ().
Website crawler miễn phí có giới hạn số trang hoặc tính năng không?
Phần lớn là có. Ví dụ, Screaming Frog bản miễn phí giới hạn 500 URL mỗi lần crawl; PowerMapper bản trial là 100 trang. Các công cụ dạng API thường giới hạn credit theo tháng. Công cụ mã nguồn mở như SiteOne hay Crawljax thường không có “trần” cứng, nhưng sẽ bị giới hạn bởi phần cứng của bạn.
Dùng web crawler có hợp pháp và tuân thủ quyền riêng tư không?
Nhìn chung, crawl các trang công khai là hợp pháp, nhưng bạn nên kiểm tra điều khoản sử dụng và robots.txt của website. Không crawl dữ liệu riêng tư hoặc nội dung sau đăng nhập khi chưa được phép, và lưu ý luật bảo vệ dữ liệu cá nhân nếu bạn trích xuất thông tin nhạy cảm ().