Quý trước, đội vận hành của chúng tôi mất 40 giờ mỗi tuần để copy-paste dữ liệu đối thủ vào bảng tính. Quý này, chỉ còn 20 phút.
Điều gì đã thay đổi? Các công cụ thu thập dữ liệu web tự động. Từ chỗ chỉ dành cho nhà phát triển, giờ đây chúng đã trở thành thứ mà bất kỳ nhân viên sales hay marketer nào cũng có thể thiết lập trong giờ nghỉ trưa.
Tôi đã xây dựng các công cụ SaaS và tự động hóa suốt nhiều năm (và đúng vậy, tôi đồng sáng lập ). Làn sóng công cụ ra mắt năm 2026 là mạnh nhất từ trước đến nay — native AI, tự chữa lỗi, và thật sự dễ dùng cho người không rành kỹ thuật.
Dưới đây là 10 công cụ tôi đã tự tay đánh giá, so sánh theo từng trường hợp sử dụng và mức độ kỹ năng.
Vì sao công cụ thu thập dữ liệu web tự động quan trọng với người dùng doanh nghiệp
Nói thẳng nhé: thời phải tự tay copy-paste dữ liệu từ website đã qua rồi (trừ khi bạn thích đau mỏi lặp đi lặp lại và cảm giác tuyệt vọng hiện sinh). Công cụ thu thập dữ liệu web tự động đã trở thành hạ tầng sống còn cho doanh nghiệp ở mọi quy mô. Thực tế, , và web scraping là một phần quan trọng của chiến lược đó.
Đây là lý do những công cụ này cực kỳ hữu ích:
- Tiết kiệm thời gian & giảm công việc thủ công: Các công cụ thu thập tự động có thể xử lý hàng nghìn bản ghi chỉ trong vài phút, giải phóng đội ngũ cho những việc có giá trị cao hơn. Một người dùng cho biết đã tiết kiệm “hàng trăm giờ” nhờ tự động hóa việc thu thập dữ liệu ().
- Nâng cao độ chính xác của dữ liệu: Không còn lỗi chính tả hay bỏ sót dòng nữa. Trích xuất tự động giúp dữ liệu sạch hơn và đáng tin cậy hơn.
- Hỗ trợ ra quyết định nhanh hơn: Với luồng dữ liệu thời gian thực, bạn có thể theo dõi đối thủ, cập nhật giá, hoặc xây dựng danh sách khách hàng tiềm năng mà không phải chờ báo cáo hàng tháng từ thực tập sinh.
- Trao quyền cho các nhóm không rành kỹ thuật: Nhờ các công cụ no-code và AI, ngay cả những người nghĩ “XPath” là một tư thế yoga giờ cũng có thể xây dựng pipeline dữ liệu web ().
Không có gì ngạc nhiên khi , và gần 80% nói rằng tổ chức của họ sẽ khó vận hành hiệu quả nếu thiếu nó. Năm 2026, nếu bạn vẫn chưa tự động hóa việc thu thập dữ liệu, rất có thể bạn đang để lại tiền bạc — và cả insight — trên bàn.
Cách chúng tôi chọn ra các công cụ thu thập dữ liệu web tự động tốt nhất
Khi thị trường phần mềm web scraping được dự báo sẽ , việc chọn đúng công cụ có cảm giác như đi mua giày trong một cửa hàng có tới 10.000 lựa chọn. Đây là cách tôi thu hẹp danh sách:
- Dễ sử dụng: Người không phải lập trình viên có thể bắt đầu nhanh không? Có đường cong học tập dốc không?
- Khả năng AI: Công cụ có dùng AI để tự phát hiện trường dữ liệu, xử lý website động, hoặc cho phép bạn mô tả nhu cầu bằng tiếng Anh tự nhiên không?
- Xuất dữ liệu & tích hợp: Bạn có thể đưa dữ liệu vào Excel, Google Sheets, Airtable, Notion, hay CRM của mình dễ đến đâu?
- Giá cả: Có dùng thử miễn phí không? Các gói trả phí có phù hợp với cá nhân và nhóm nhỏ không, hay chỉ dành cho doanh nghiệp lớn?
- Khả năng mở rộng: Công cụ có xử lý được cả tác vụ nhỏ lẻ một lần lẫn các lần trích xuất lớn, theo lịch không?
- Đối tượng mục tiêu: Công cụ được xây cho người dùng doanh nghiệp, nhà phát triển, hay cả hai?
- Điểm mạnh riêng: Điều gì làm công cụ này nổi bật so với phần còn lại?
Tôi đã đưa vào danh sách các công cụ cho mọi cấp độ kỹ năng — từ “tôi chỉ muốn một bảng tính” cho tới “tôi muốn quét cả internet”. Cùng vào danh sách nhé.
1. Thunderbit: công cụ web scraper chạy bằng AI dành cho mọi người
Để tôi bắt đầu bằng công cụ mà tôi hiểu rõ nhất — bởi vì, à, đội của tôi và tôi đã xây dựng nó để giải quyết đúng những rắc rối mà tôi đã thấy người dùng doanh nghiệp gặp phải suốt nhiều năm. không phải kiểu scraper “kéo-thả” hay “tự viết selector” thông thường. Nó là một trợ lý dữ liệu chạy bằng AI, cho phép bạn mô tả điều bạn muốn, rồi nó sẽ làm phần nặng nhọc — không code, không vọc XPath, không nước mắt.
Vì sao Thunderbit đứng đầu danh sách
Thunderbit là thứ gần nhất tôi từng thấy với khái niệm “biến bất kỳ website nào thành cơ sở dữ liệu”. Cách nó hoạt động như sau:
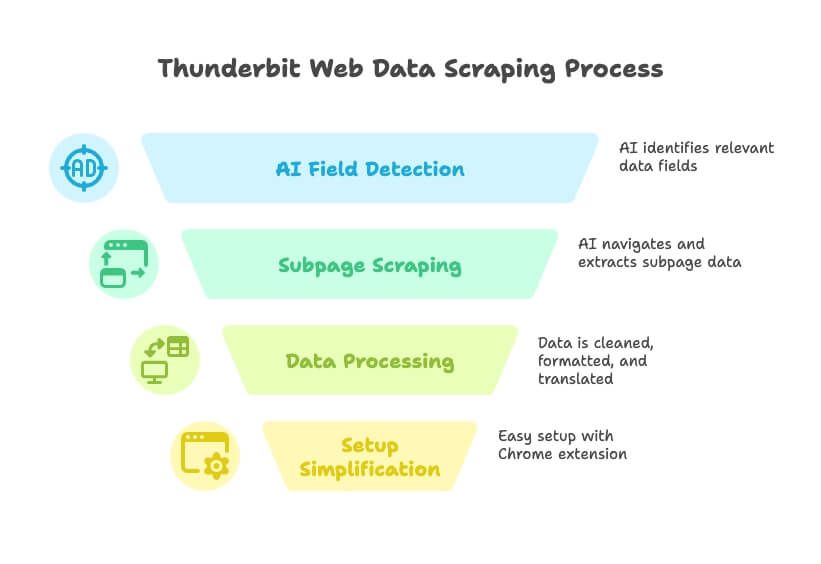
- Điều khiển bằng ngôn ngữ tự nhiên: Chỉ cần nói với Thunderbit bạn cần dữ liệu gì (“tôi muốn tất cả tên công ty, email và số điện thoại từ thư mục này”), và AI sẽ tự phát hiện các trường liên quan.
- AI gợi ý trường dữ liệu: Chỉ với một cú nhấp, Thunderbit đọc trang và gợi ý những cột tốt nhất để trích xuất — không còn đoán mò hay thử-sai nữa.
- Thu thập trang con & đa cấp: Bạn cần chi tiết từ trang con của từng mục? Thunderbit có thể nhấp qua từng trang, lấy thêm thông tin và ghép vào bảng của bạn.
- Làm sạch, dịch và phân loại dữ liệu: Thunderbit không chỉ lấy dữ liệu thô — nó còn có thể làm sạch, định dạng, dịch và thậm chí phân loại các trường ngay trong lúc thu thập.
- Không đau đầu khi thiết lập: Cài , nhấp “AI Suggest Fields”, và bạn đã có thể scrape trong chưa đầy một phút.
- Dùng thử miễn phí & chi phí thấp: Gói miễn phí rất hào phóng (có thể scrape miễn phí tới 6 trang), với các gói trả phí chỉ từ 9 USD/tháng. Thấp hơn cả số tiền tôi thường tiêu cho cà phê trong một tuần.
Thunderbit được xây cho các đội sales, marketing và vận hành cần dữ liệu — thật nhanh. Không cần code, không plugin, không đào tạo. Nó giống như có một thực tập sinh dữ liệu thực sự biết nghe lời và chẳng bao giờ than phiền.
Những tính năng nổi bật của Thunderbit
- Scraping bằng AI: AI hiểu cấu trúc trang, thích ứng với thay đổi bố cục, và thậm chí xử lý tự động phân trang và trang con ().
- Xuất dữ liệu tức thì: Gửi kết quả thẳng sang Excel, Google Sheets, Airtable, Notion, hoặc tải xuống dạng CSV/JSON.
- Chạy trên cloud hoặc cục bộ: Chạy tác vụ trên cloud để nhanh và mở rộng tốt, hoặc chạy ngay trong trình duyệt nếu bạn cần dùng phiên đăng nhập của mình.
- Thu thập theo lịch: Thiết lập các tác vụ lặp lại để giữ dữ liệu luôn mới — rất hợp cho việc theo dõi giá hoặc cập nhật lead thường xuyên.
- Không cần bảo trì: AI của Thunderbit thích ứng với thay đổi trên website, nên bạn tốn ít thời gian hơn để sửa những scraper bị hỏng ().
Dành cho ai? Bất kỳ ai muốn đi từ “tôi cần dữ liệu này” đến “đây là bảng tính của bạn” trong vài phút — đặc biệt là người không rành kỹ thuật. Với và điểm đánh giá 4,9★, Thunderbit đang nhanh chóng trở thành lựa chọn hàng đầu cho các đội ngũ doanh nghiệp muốn kết quả, không phải rắc rối.
Muốn xem nó hoạt động thế nào? Hãy xem hoặc đọc thêm các .
2. Clay: kết hợp làm giàu dữ liệu tự động với web scraping
Clay giống như con dao đa năng Thụy Sĩ dành cho các đội growth. Nó không chỉ là web scraper — mà là một bảng tính tự động hóa kết nối với hơn 50 nguồn dữ liệu trực tiếp (như Apollo, LinkedIn, Crunchbase) và dùng AI tích hợp để làm giàu lead, viết email tiếp cận, và chấm điểm khách hàng tiềm năng.
- Tự động hóa quy trình làm việc: Mỗi hàng là một lead, mỗi cột có thể kéo dữ liệu hoặc kích hoạt một hành động. Muốn scrape danh sách công ty, làm giàu bằng hồ sơ LinkedIn, rồi gửi email cá nhân hóa? Clay lo được.
- Tích hợp AI: Dùng GPT-4 để viết câu mở đầu, tóm tắt tiểu sử, và nhiều thứ khác.
- Tích hợp sẵn: Kết nối nguyên bản với HubSpot, Salesforce, Gmail, Slack, và nhiều công cụ khác.
- Giá: Gói chuyên nghiệp bắt đầu khoảng 99 USD/tháng, có dùng thử miễn phí cho nhu cầu nhẹ.
Phù hợp nhất cho: Sales outbound, growth hacker, và marketer muốn xây dựng pipeline lead tùy chỉnh — kết hợp scraping, làm giàu dữ liệu, và tiếp cận trong cùng một nơi. Công cụ này rất mạnh, nhưng sẽ có đường cong học tập nếu bạn mới với các công cụ tự động hóa ().
3. Bardeen: công cụ web scraper chạy trên trình duyệt cho tự động hóa quy trình
Bardeen giống như một robot trình duyệt có thể thu thập dữ liệu và tự động hóa các tác vụ web lặp đi lặp lại — tất cả từ một tiện ích mở rộng Chrome.
- Tự động hóa no-code: Hơn 500 “Playbook” cho việc scraping, điền form, chuyển dữ liệu giữa các ứng dụng, và hơn thế nữa.
- AI Command Builder: Mô tả tác vụ của bạn bằng ngôn ngữ tự nhiên, và Bardeen sẽ tạo quy trình làm việc.
- Tích hợp: Làm việc với Notion, Trello, Slack, Salesforce, và hơn 100 ứng dụng khác.
- Giá: Miễn phí cho nhu cầu nhẹ (100 automation credit/tháng), với các gói trả phí bắt đầu từ 99 USD/tháng cho nhóm.
Phù hợp nhất cho: Người dùng nâng cao và các đội go-to-market muốn tự động hóa scraping lẫn các hành động theo sau trên nhiều ứng dụng. Công cụ này rất linh hoạt, nhưng người mới có thể thấy đường cong học tập hơi dốc ().
4. Bright Data: công cụ thu thập dữ liệu web tự động chuẩn doanh nghiệp
Bright Data (trước đây là Luminati) là “máy hạng nặng” của web scraping — hãy nghĩ tới mạng proxy toàn cầu, API nâng cao, và khả năng crawl hàng nghìn trang mỗi ngày.
- Quy mô doanh nghiệp: Hơn 100 triệu IP, Web Scraper IDE, Web Unlocker để vượt qua các biện pháp chống bot.
- Tùy biến cao: Xây dựng các luồng trích xuất phức tạp, quy mô lớn với độ tin cậy cao.
- Giá: Bắt đầu từ 499 USD/tháng cho Web Scraper IDE, với các gói “micro” nhỏ hơn.
Phù hợp nhất cho: Doanh nghiệp lớn, đơn vị tổng hợp dữ liệu, và người dùng nâng cao cần giải pháp mạnh, có khả năng mở rộng. Nếu bạn đang crawl hàng nghìn trang mỗi ngày và cần tránh bị chặn IP, Bright Data được sinh ra cho bạn ().
5. Octoparse: công cụ web scraper trực quan cho người dùng trung cấp
Octoparse là một công cụ no-code phổ biến với giao diện trực quan, nhấp là dùng — rất phù hợp cho những ai muốn sức mạnh mà không cần lập trình.
- Giao diện kéo-thả: Nhấp vào phần tử để xác định thứ cần trích xuất, xử lý đăng nhập, phân trang, và nhiều thứ khác.
- Mẫu có sẵn: Hơn 500 mẫu dựng sẵn cho các website phổ biến (Amazon, Twitter, v.v.).
- Scraping trên cloud: Chạy tác vụ trên máy chủ của Octoparse, lên lịch trích xuất, và dùng xoay vòng IP.
- Giá: Có gói miễn phí giới hạn; gói trả phí bắt đầu từ 119 USD/tháng.
Phù hợp nhất cho: Người không lập trình và nhà phân tích dữ liệu muốn một scraper đủ mạnh mà không phải viết code. Rất tốt cho việc theo dõi giá, danh sách sản phẩm và các dự án nghiên cứu ().
6. : nền tảng trích xuất dữ liệu cho doanh nghiệp
là một trong những “cây đại thụ” của web scraping, nay đã phát triển thành một nền tảng trích xuất dữ liệu quy mô lớn.
- Trích xuất nhấp-là-dùng: Xử lý đăng nhập, danh sách thả xuống, và các phần tử tương tác.
- Dựa trên cloud: Xử lý hàng nghìn URL đồng thời, lên lịch trích xuất, và truy cập API.
- Tập trung vào doanh nghiệp: Dùng cho theo dõi giá, nghiên cứu thị trường, và xây dựng bộ dữ liệu cho machine learning.
- Giá: Gói Starter 199 USD/tháng, Standard 599 USD/tháng, Advanced 1.099 USD/tháng.
Phù hợp nhất cho: Doanh nghiệp vừa đến lớn và đội dữ liệu cần giải pháp đáng tin cậy, được duy trì tốt cho các tác vụ lớn. Có thể hơi quá tay cho dự án sở thích cá nhân, nhưng là cỗ máy mạnh cho nhu cầu quy mô doanh nghiệp ().
7. Parsehub: công cụ web scraper linh hoạt với trình chỉnh sửa trực quan
Parsehub là một ứng dụng desktop (Windows, Mac, Linux) cho phép bạn xây dựng scraper bằng cách nhấp qua giao diện của website.
- Quy trình trực quan: Chọn phần tử, thiết lập quy tắc trích xuất, và xử lý đăng nhập, danh sách thả xuống, cùng cuộn vô hạn.
- Tính năng cloud: Chạy scraping trên cloud, lên lịch tác vụ, và dùng truy cập API.
- Giá: Có gói miễn phí cho tác vụ nhỏ; gói trả phí bắt đầu từ 149 USD/tháng.
Phù hợp nhất cho: Nhà nghiên cứu, doanh nghiệp nhỏ, hoặc cá nhân muốn có nhiều kiểm soát hơn tiện ích trình duyệt nhưng chưa sẵn sàng tự viết scraper ().
8. Common Crawl: dữ liệu web mở cho AI và nghiên cứu
Common Crawl không phải là một công cụ theo nghĩa truyền thống — mà là một bộ dữ liệu mở khổng lồ về dữ liệu crawl web, được cập nhật hàng tháng.
- Quy mô: Khoảng 400 TB dữ liệu web, bao phủ hàng tỷ trang web.
- Miễn phí & mở: Không cần tự chạy crawler của riêng bạn.
- Cần kỹ năng kỹ thuật: Bạn sẽ cần các công cụ dữ liệu lớn và một số kỹ năng kỹ thuật để lọc và phân tích dữ liệu.
Phù hợp nhất cho: Nhà khoa học dữ liệu và kỹ sư đang xây dựng mô hình AI hoặc làm nghiên cứu quy mô lớn. Nếu bạn cần văn bản web tổng quát hoặc kho lưu trữ dài hạn, đây là một mỏ vàng ().
9. Crawly: công cụ thu thập dữ liệu web tự động nhẹ cho startup
Crawly (của Diffbot) là một crawler dựa trên cloud, chạy bằng AI, có thể lấy dữ liệu từ hàng triệu website và trả về kết quả có cấu trúc — không cần viết quy tắc phân tích.
- Trích xuất bằng AI: Dùng machine vision và NLP để nhận diện và trích xuất nội dung.
- Truy cập API: Truy vấn dữ liệu đã thu thập và tích hợp với hệ thống phân tích hoặc cơ sở dữ liệu.
- Giá: Ở cấp doanh nghiệp; liên hệ để biết giá.
Phù hợp nhất cho: Startup và các đội có một số kỹ năng kỹ thuật, cần trích xuất dữ liệu web thông minh ở quy mô lớn mà không muốn tự xây scraper của riêng mình ().
10. Apify: công cụ web scraper thân thiện với developer có marketplace
Apify là một nền tảng cloud nơi bạn có thể tự xây scraper (“Actors”) hoặc dùng thư viện scraper dựng sẵn từ cộng đồng.
- Linh hoạt cho nhà phát triển: Hỗ trợ scraping bằng JavaScript/Python, headless Chrome, quản lý proxy, và lập lịch.
- Marketplace: Thư viện phong phú các scraper dựng sẵn cho những website phổ biến.
- Giá: Gói miễn phí với 5 USD/tháng credit; gói trả phí bắt đầu từ 49 USD/tháng.
Phù hợp nhất cho: Nhà phát triển và nhà phân tích am hiểu công nghệ muốn toàn quyền kiểm soát và khả năng mở rộng. Ngay cả người không biết code cũng có thể dùng các Actors dựng sẵn cho các tác vụ phổ biến ().
Bảng so sánh các công cụ thu thập dữ liệu web tự động
| Công cụ | Dễ sử dụng | Tính năng AI | Giá khởi điểm | Người dùng mục tiêu | Điểm mạnh riêng |
|---|---|---|---|---|---|
| Thunderbit | ★★★★★ | Ngôn ngữ tự nhiên, AI Suggest Fields, thu thập trang con | 9 USD/tháng | Người dùng doanh nghiệp không rành kỹ thuật | Thiết lập 2 cú nhấp, không cần code, xuất dữ liệu tức thì, dùng thử miễn phí |
| Clay | ★★★★☆ | Làm giàu dữ liệu bằng AI, GPT-4 | 99 USD/tháng | Growth / sales ops | Bảng tính tự động hóa, làm giàu dữ liệu, tiếp cận |
| Bardeen | ★★★★☆ | AI command builder | 99 USD/tháng | Người dùng nâng cao, đội GTM | RPA trên trình duyệt, hơn 500 playbook, tích hợp sâu |
| Bright Data | ★★☆☆☆ | Xoay vòng proxy, AI chống bot | 499 USD/tháng | Doanh nghiệp, dev | Quy mô, độ tin cậy, proxy toàn cầu |
| Octoparse | ★★★★☆ | Nhận diện AI trực quan | 119 USD/tháng | Nhà phân tích, người không code | Kéo-thả, mẫu sẵn, scraping trên cloud |
| Import.io | ★★★☆☆ | Trình trích xuất tương tác | 199 USD/tháng | Doanh nghiệp, đội dữ liệu | Đồng thời cao, lập lịch, API, hỗ trợ |
| Parsehub | ★★★★☆ | Quy trình trực quan | 149 USD/tháng | Nhà nghiên cứu, SMB | Ứng dụng desktop, xử lý website động |
| Common Crawl | ★☆☆☆☆ | Không có (chỉ là bộ dữ liệu) | Miễn phí | Nhà khoa học dữ liệu, kỹ sư | Bộ dữ liệu mở khổng lồ, kho lưu trữ ở quy mô web |
| Crawly | ★★☆☆☆ | Trích xuất bằng AI | Tùy chỉnh/Doanh nghiệp | Startup, đội kỹ thuật | Chạy bằng AI, không cần quy tắc phân tích, truy cập API |
| Apify | ★★★★☆ | Marketplace cho Actors | 49 USD/tháng | Nhà phát triển, nhà phân tích am hiểu kỹ thuật | Xây dựng/marketplace, tự động hóa cloud, linh hoạt |
Cách chọn đúng công cụ web scraper cho nhu cầu của bạn
Việc chọn công cụ thu thập dữ liệu web tự động tốt nhất phụ thuộc vào quy mô đội ngũ, kỹ năng kỹ thuật, và mục tiêu kinh doanh của bạn. Đây là hướng dẫn nhanh của tôi:
- Cho người không rành kỹ thuật (Sales, Marketing, Ops): Hãy chọn . Công cụ này được xây cho bạn — không cần code, không cần thiết lập, chỉ cần kết quả. Rất phù hợp cho tạo lead, theo dõi giá, và các dự án dữ liệu nhanh.
- Cho đội ngũ ám ảnh với tự động hóa: Clay và Bardeen rất nổi bật nếu bạn muốn kết hợp scraping với làm giàu dữ liệu, tiếp cận, hoặc tự động hóa quy trình.
- Cho doanh nghiệp lớn & nhà phát triển: Bright Data, , và Apify là những lựa chọn tốt nhất cho các dự án quy mô lớn, tùy biến cao.
- Cho nhà nghiên cứu & nhà phân tích: Octoparse và Parsehub cung cấp giao diện trực quan và nhiều tính năng mạnh mà không cần code.
- Cho dự án AI & khoa học dữ liệu: Common Crawl và Crawly cung cấp bộ dữ liệu khổng lồ và khả năng trích xuất bằng AI cho những ai muốn xây hoặc huấn luyện mô hình.
Hãy tự hỏi: bạn muốn bắt đầu trong vài phút, hay bạn cần xây một giải pháp tùy chỉnh cấp doanh nghiệp? Nếu chưa chắc, hãy bắt đầu bằng bản dùng thử miễn phí — hầu hết công cụ đều có.
Giá trị khác biệt của Thunderbit: trợ lý AI cho dữ liệu doanh nghiệp
Trong tất cả các công cụ này, Thunderbit nổi bật là công cụ duy nhất thực sự đóng vai trò như một “trợ lý AI” cho web scraping và chuyển đổi dữ liệu. Nó không chỉ là chuyện lấy dữ liệu — mà là biến các website rối rắm thành insight sạch sẽ, có cấu trúc, mà không có rào cản kỹ thuật nào.
- Giao diện ngôn ngữ tự nhiên: Mô tả nhu cầu của bạn bằng tiếng Anh đơn giản, và Thunderbit sẽ lo phần còn lại.
- Tự động hóa toàn bộ quy trình: Từ trích xuất đến làm sạch, dịch và xuất dữ liệu — Thunderbit bao trọn toàn bộ quy trình.
- Hoàn hảo cho thử nghiệm nhanh: Cần kiểm chứng thị trường mới, xây danh sách lead, hay theo dõi đối thủ? Thunderbit là điểm khởi đầu nhanh nhất và tiết kiệm nhất.
Nó giống như có một nhà phân tích dữ liệu được tích hợp ngay trong trình duyệt — người không bao giờ đòi tăng lương hay nghỉ phép.
Kết luận: khởi đầu thông minh hơn với công cụ thu thập dữ liệu web tự động phù hợp
Bức tranh scraping năm 2026 khác xa cách đây hai năm. Các AI scraper tự chữa lỗi, pipeline native LLM, và các công cụ no-code thực sự dễ dùng đã thay đổi cuộc chơi. Dù bạn là nhà sáng lập độc lập, một đội sales linh hoạt, hay một nhà khoa học dữ liệu ở doanh nghiệp lớn, luôn có một công cụ trong danh sách này phù hợp với nhu cầu của bạn. Điều quan trọng là ghép đúng quy trình làm việc và kỹ năng của bạn với nền tảng phù hợp — để bạn ngừng vật lộn với code và bắt đầu khai thác insight.
Nếu bạn sẵn sàng bỏ qua việc copy-paste thủ công và bắt đầu thông minh hơn, hãy và xem web scraping có thể dễ đến mức nào. Hoặc, hãy khám phá các lựa chọn khác ở trên dựa trên mục tiêu của bạn. Dù theo cách nào, tương lai của kinh doanh dựa trên dữ liệu sẽ thuộc về những ai tự động hóa.
Muốn tìm hiểu thêm? Hãy xem để đọc các bài phân tích sâu, hướng dẫn, và mẹo tận dụng tối đa dữ liệu web của bạn. Chúc bạn scraping vui vẻ — và nhớ rằng, mong dữ liệu của bạn luôn sạch và scraper của bạn không bao giờ hỏng (nhưng nếu có, cứ để AI lo).
Câu hỏi thường gặp
1. Vì sao công cụ thu thập dữ liệu web tự động quan trọng với người dùng doanh nghiệp trong năm 2026?
Công cụ thu thập dữ liệu web tự động giúp tinh gọn việc thu thập dữ liệu, tiết kiệm thời gian và giảm công việc thủ công. Chúng nâng cao độ chính xác của dữ liệu, hỗ trợ ra quyết định theo thời gian thực, và trao quyền cho các đội ngũ không rành kỹ thuật để trích xuất và sử dụng dữ liệu web mà không cần viết code. Hiện nay, các công cụ này đã trở nên thiết yếu cho sales, marketing, và vận hành.
2. Thunderbit khác gì so với các công cụ web scraping khác?
Thunderbit dùng AI để cho phép người dùng mô tả dữ liệu họ muốn bằng tiếng Anh tự nhiên. Nó tự động phát hiện các trường dữ liệu, xử lý trang con và phân trang, và xuất kết quả tức thì sang các nền tảng như Excel và Airtable. Công cụ này được thiết kế cho người không rành kỹ thuật và cung cấp các tính năng mạnh như làm sạch dữ liệu và thu thập theo lịch với mức giá thấp.
3. Công cụ nào tốt nhất cho các dự án scraping quy mô lớn ở doanh nghiệp?
Bright Data và là lựa chọn lý tưởng cho doanh nghiệp. Chúng cung cấp các tính năng như xoay vòng proxy, biện pháp chống bot, đồng thời quy mô lớn, và truy cập API, phù hợp với các tổ chức cần xử lý hàng nghìn trang web một cách đáng tin cậy và ở quy mô lớn.
4. Có công cụ nào kết hợp scraping với tự động hóa và tiếp cận khách hàng không?
Có. Các công cụ như Clay và Bardeen không chỉ thu thập dữ liệu web mà còn tích hợp dữ liệu đó vào quy trình làm việc. Clay làm giàu lead và tự động hóa outreach, trong khi Bardeen cho phép người dùng tự động hóa các tác vụ và quy trình trên trình duyệt bằng các playbook do AI điều khiển.
5. Lựa chọn tốt nhất cho người không có nền tảng kỹ thuật là gì?
Thunderbit nổi bật cho người không rành kỹ thuật nhờ giao diện ngôn ngữ tự nhiên, thiết lập bằng AI, và sự dễ dùng. Nó không cần code hay thiết lập phức tạp, và rất phù hợp cho người dùng doanh nghiệp cần dữ liệu nhanh, đáng tin cậy mà không phải xử lý sự phức tạp kỹ thuật.