
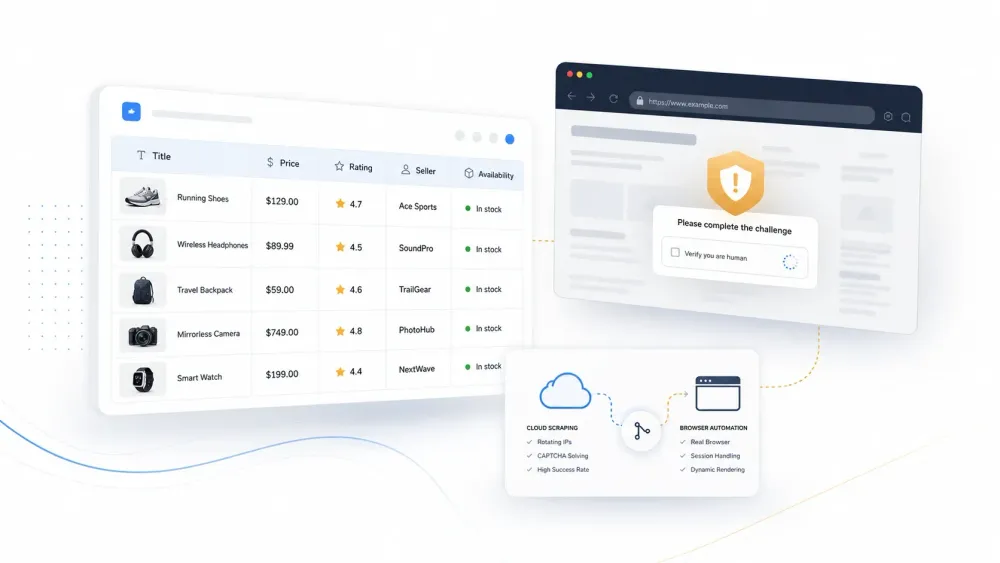
Mọi AI web scraper đều trông rất ấn tượng trong phần demo sản phẩm. Nhưng khi bạn đưa nó vào một trang web thực tế có bảo vệ Cloudflare, nó lại trả về trang thử thách và vẫn tự tin khẳng định rằng nó đã tìm thấy 47 danh sách sản phẩm.
Trong vài tháng qua, tôi đã dành thời gian đánh giá các công cụ scraping cho đội ngũ của Thunderbit. Khoảng cách giữa hiệu năng demo và độ ổn định khi chạy thực tế luôn là nguồn gây bực bội lớn nhất mà tôi thấy trong cộng đồng. Một người dùng Reddit đã tóm gọn rất hay: "Cái gì giữ được trong môi trường thực tế, và cái gì chỉ chạy được cho demo trước khi chết sau hai tuần?" Với 31 sản phẩm được liệt kê trên Capterra chỉ riêng trong danh mục web scraping, cộng thêm hàng chục tiện ích Chrome, nhà cung cấp API và chợ actor khác, nghịch lý lựa chọn là có thật. Vì vậy tôi đã thử 12 công cụ.
Bài viết này đánh giá 12 công cụ AI web scraper theo các tiêu chí thực chiến: xử lý anti-bot, khả năng mở rộng, chất lượng đầu ra có cấu trúc, hiệu quả chi phí, hỗ trợ site động và tính linh hoạt cho nhà phát triển. Không bảng tính năng. Không ảnh marketing. Chỉ là những gì thực sự hoạt động sau khi demo kết thúc.
Xem một AI Web Scraper sẵn sàng cho môi trường thực tế trông như thế nào
Vì sao hầu hết AI Web Scraper thất bại sau phần demo
Mô típ rất dễ đoán. Trang marketing của một công cụ cho thấy nó trích xuất các cột sạch sẽ từ một trang danh sách sản phẩm đơn giản. Bạn cài đặt nó, thử trên một trang thương mại điện tử có phòng thủ, và nhận được một trong các kết quả sau:
- Phản hồi
200 OKnhưng chứa trang thử thách Cloudflare thay vì dữ liệu thật - Kết quả sạch cho 5 trang đầu, sau đó âm thầm lỗi hoặc tạo ra các dòng dữ liệu bịa
- Trích xuất hoàn hảo hôm nay, nhưng tuần sau selector hỏng chỉ vì layout thay đổi nhẹ
Đây không phải các trường hợp hiếm. Đây là điều bình thường.
Như một người thực hành đã nói trên Reddit: "Scraper trả về mã 200 với một trang thử thách Cloudflare, agent của bạn cố suy luận từ đó, bịa ra dữ liệu, và bạn chẳng hiểu vì sao."
Vấn đề cốt lõi nằm ở kiến trúc. Phần lớn demo chỉ trình diễn lớp phân tích trên các trang công khai sạch sẽ, trong khi công việc thực lại thất bại ở lớp truy xuất. Các trang production có thêm bảo vệ bot, render động, trang chi tiết lồng nhau, cuộn vô hạn, trạng thái đăng nhập, khác biệt theo locale và bố cục thay đổi liên tục.
Một công cụ có thể trông rất tuyệt trong phần trình diễn sản phẩm, nhưng vẫn sụp đổ ngay trong quy trình làm việc đầu tiên có tính thực chiến.
Đó là lý do bài viết này đánh giá từng công cụ theo góc nhìn sẵn sàng cho production thay vì danh sách tính năng. Sáu tiêu chí tôi dùng:
| Tiêu chí | Vì sao quan trọng |
|---|---|
| Xử lý anti-bot/CAPTCHA | Trang được bảo vệ sẽ thất bại trước cả khi chất lượng trích xuất trở nên quan trọng |
| Khả năng mở rộng sau demo | Các job hàng loạt và chạy song song phơi bày giới hạn vận hành |
| Chất lượng đầu ra có cấu trúc | Người dùng cần JSON/CSV sạch, không phải HTML thô cần dọn thủ công |
| Hiệu quả token/chi phí | Trích xuất bằng AI có thể đắt hơn cả việc scraping |
| Hỗ trợ site động/nặng JavaScript | Các trang hiện đại cần DOM đã render, không phải HTML tĩnh |
| Linh hoạt giữa no-code và API | Đội sales và kỹ sư dữ liệu có nhu cầu khác nhau |
Nếu bạn muốn có cái nhìn nhanh ở cấp độ thị trường về cách web scraping đã thay đổi trong hai năm qua, bài nói chuyện của Browserless là một phần mở đầu rất tốt trước khi bạn so sánh từng công cụ một.
AI thực sự hữu ích ở đâu trong quy trình scraping, và ở đâu thì không
Một hiểu lầm dai dẳng trong thị trường này là “AI web scraper” có nghĩa AI sẽ lo mọi thứ từ đầu đến cuối. Đồng thuận trong cộng đồng lại khá rõ ràng: scraper trước, LLM sau. Một người dùng nói thẳng: “Bạn dùng AI để đọc ảnh chụp màn hình của trang web. Bạn không dùng AI để tự viết scraper.”
Quy trình scraping có ba lớp riêng biệt, và giá trị của AI thay đổi rất nhiều giữa các lớp đó:
Thu thập và truy xuất: Lớp hạ tầng
Đây là nơi các request diễn ra: proxy, trình duyệt headless, quản lý session, giải CAPTCHA, retry. AI hầu như không giúp được gì ở đây. Bạn vẫn cần pool proxy, fingerprint trình duyệt và hạ tầng vượt chặn. Đây là nơi phần lớn công cụ thất bại đầu tiên trong môi trường thực.
Phân tích và trích xuất: Nơi AI tỏa sáng
Khi bạn đã có nội dung trang sạch, AI rất mạnh trong việc biến HTML phi cấu trúc thành các trường dữ liệu có cấu trúc. Trích xuất dựa trên schema, phát hiện trường thích ứng và xử lý biến thể layout mà không cần XPath cứng nhắc là thế mạnh của AI trong scraping.
Hậu xử lý: Gắn nhãn, dịch, phân loại
Sau khi trích xuất, AI tạo giá trị bằng cách phân loại sản phẩm, dịch văn bản, chuẩn hóa số điện thoại hoặc tóm tắt mô tả. Đây là mảng rất phù hợp, nhưng chỉ khi dữ liệu đầu vào đã chính xác.
Đây là cách 12 công cụ phân bố trên các lớp đó:
| Công cụ | Thu thập/Truy xuất | Phân tích/Trích xuất | Hậu xử lý | Mô tả tốt nhất |
|---|---|---|---|---|
| Thunderbit | Mạnh | Mạnh | Mạnh | AI scraper no-code full-stack |
| Octoparse | Mạnh | Trung bình | Thấp | Scraper trực quan dựa trên quy tắc với hạ tầng cloud |
| Browse AI | Trung bình | Trung bình | Trung bình | Nền tảng robot cloud ưu tiên giám sát |
| Firecrawl | Trung bình | Mạnh | Thấp-Trung bình | API trích xuất dành cho nhà phát triển |
| Apify | Mạnh | Trung bình-Mạnh | Trung bình | Chợ actor và lớp điều phối |
| Gumloop | Trung bình | Trung bình | Mạnh | Tự động hóa workflow với các node scraper |
| Bright Data | Rất mạnh | Trung bình | Thấp-Trung bình | Bộ hạ tầng cấp doanh nghiệp |
| Bardeen | Trung bình | Trung bình | Mạnh | Tự động hóa trình duyệt cho workflow GTM |
| Diffbot | Thấp-Trung bình | Rất mạnh | Trung bình | Trích xuất huấn luyện sẵn kèm knowledge graph |
| ScrapingBee | Mạnh | Thấp-Trung bình | Thấp | API truy xuất và vượt chặn |
| Instant Data Scraper | Thấp | Trung bình (trang đơn giản) | Thấp | Scraper nhanh dựa trên heuristic trong trình duyệt |
| ParseHub | Trung bình | Trung bình | Thấp | Scraper trực quan trên desktop cho tương tác phức tạp |
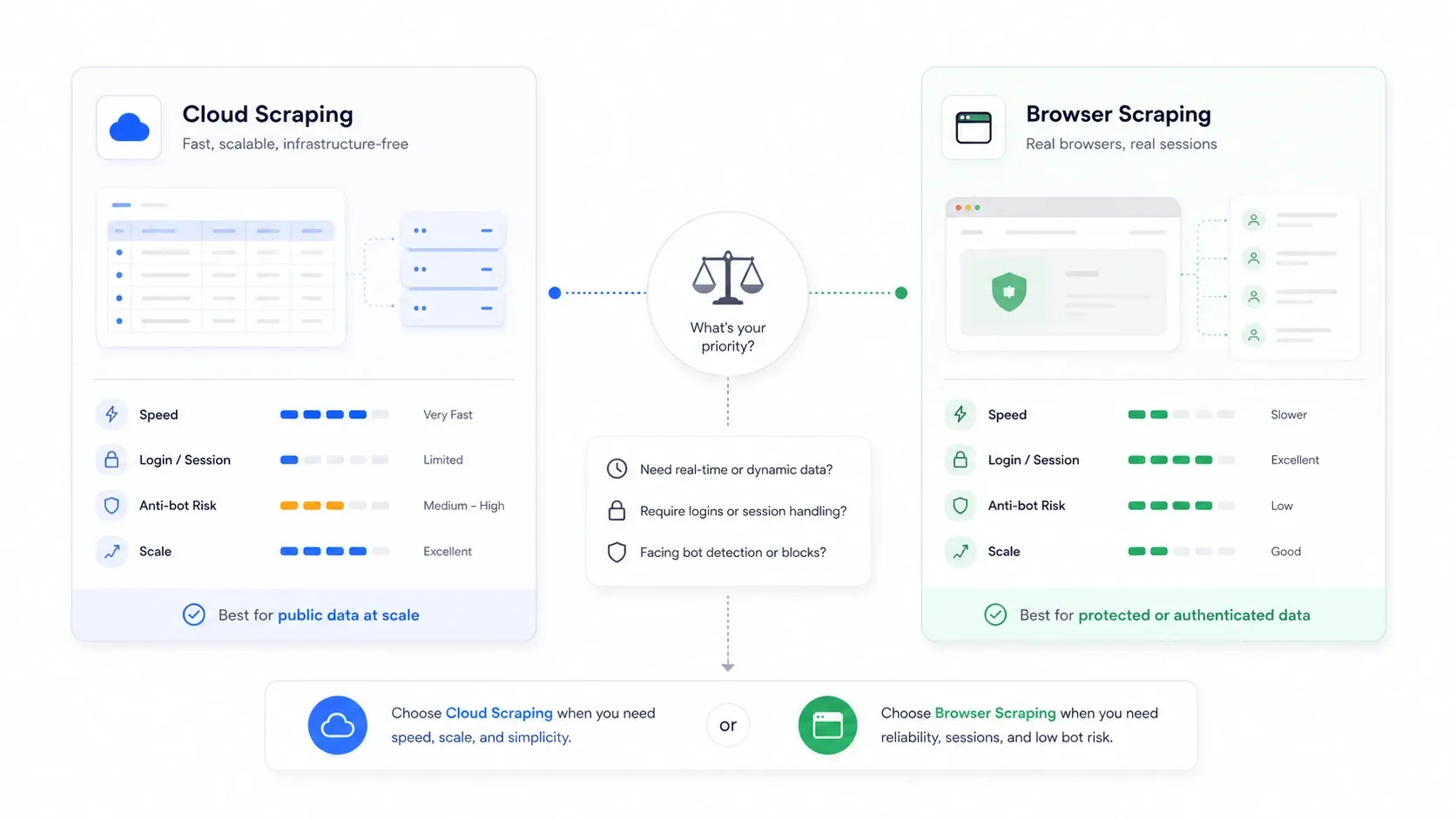
Scraping trên cloud vs scraping bằng trình duyệt: lựa chọn mà không ai giải thích rõ
Đây là quyết định kiến trúc mà hầu hết bài tổng hợp đều bỏ qua, và nó thường quan trọng hơn cả việc bạn chọn công cụ nào.
Scraping trên cloud nghĩa là máy chủ từ xa sẽ tải trang thay bạn. Scraping bằng trình duyệt nghĩa là việc trích xuất diễn ra trong phiên trình duyệt của chính bạn, dùng cookie, IP và trạng thái đã đăng nhập của bạn.
| Tình huống | Chế độ tốt hơn | Vì sao |
|---|---|---|
| Site thương mại điện tử và danh sách công khai ở quy mô lớn | Cloud | Song song nhanh hơn và không bị nghẽn bởi máy cục bộ |
| Site cần đăng nhập hoặc xác thực | Trình duyệt | Tái sử dụng cookie phiên thật của bạn |
| Site phạt IP từ datacenter | Trình duyệt | Trông giống lưu lượng người dùng bình thường |
| Job giám sát định kỳ quy mô lớn | Cloud | Lập lịch và duy trì dễ hơn |
| Job đơn lẻ, mong manh, nhạy với anti-bot | Trình duyệt | Dễ kiểm tra xem site thực sự đã render gì |
Điều này cũng có ý nghĩa về kinh tế. Báo cáo State of Web Scraping 2026 của Apify cho thấy 65,8% người thực hành tăng mức dùng proxy theo năm, và hơn 62% báo cáo chi phí hạ tầng cao hơn. Anti-bot không chỉ là vấn đề kỹ thuật. Nó còn là vấn đề ngân sách.
Phần lớn công cụ chỉ cung cấp một chế độ. Đây là bức tranh tổng quát:
| Công cụ | Cloud | Trình duyệt | Cả hai |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Chỉ thiết lập | — |
| Firecrawl | ✅ | API cho tương tác | — |
| Apify | ✅ | ✅ (qua actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Hạn chế (trang công khai) | ✅ | Một phần |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (trả phí) | ✅ (desktop) | ✅ |
12 AI Web Scraper nhìn qua là thấy ngay
Đây là bảng so sánh tổng giữa cả 12 công cụ:
| Công cụ | Phù hợp nhất cho | Gói miễn phí | Cloud/Trình duyệt | Có API | Scraping theo lịch | Xử lý anti-bot |
|---|---|---|---|---|---|---|
| Thunderbit | Đội không kỹ thuật | ✅ (6 trang) | Cả hai | ✅ | ✅ | Mạnh |
| Octoparse | Scraping nhiều template | ✅ (hạn chế) | Cả hai | ✅ | ✅ | Trung bình-Mạnh |
| Browse AI | Giám sát thay đổi | ✅ (hạn chế) | Chủ yếu cloud | ✅ | ✅ | Trung bình |
| Firecrawl | Pipeline trích xuất cho dev | ✅ (1.000 credit/tháng) | Cloud cộng API trình duyệt | ✅ | Không | Trung bình |
| Apify | Đội dev và marketplace | ✅ (5 USD dùng thử) | Cả hai | ✅ | ✅ | Mạnh khi có add-on |
| Gumloop | Tự động hóa workflow | ✅ (5.000 credit/tháng) | Cả hai | ✅ | ✅ | Trung bình |
| Bright Data | Truy cập dữ liệu doanh nghiệp | Dùng thử / credit | Cả hai | ✅ | Bên ngoài | Rất mạnh |
| Bardeen | Tự động hóa trình duyệt cho sales/ops | ✅ (100 credit) | Ưu tiên trình duyệt | Hạn chế | ✅ | Trung bình-Thấp |
| Diffbot | API trích xuất có cấu trúc | ✅ (10.000 credit) | Cloud | ✅ | Không | Thấp ở khâu truy xuất / cao ở khâu trích xuất |
| ScrapingBee | Truy xuất và vượt chặn cho dev | ✅ (1.000 credit) | Cloud | ✅ | Không | Mạnh |
| Instant Data Scraper | Scrape nhanh miễn phí, một lần | ✅ (miễn phí hoàn toàn) | Chỉ trình duyệt | Không | Không | Thấp |
| ParseHub | Workflow trực quan phức tạp | ✅ (5 dự án) | Desktop cộng cloud | ✅ | ✅ (trả phí) | Trung bình |
Hiểu cách trích xuất bằng AI phù hợp vào một quy trình scraping thực tế
1. Thunderbit
Thunderbit là AI web scraper mà chúng tôi xây dựng riêng cho các đội không kỹ thuật, những người cần dữ liệu chất lượng production mà không phải viết code hay quản lý hạ tầng. Quy trình cốt lõi thực sự chỉ gồm hai cú nhấp: AI Suggest Fields đọc trang và đề xuất các cột, sau đó Scrape sẽ chạy trích xuất ở chế độ cloud hoặc trình duyệt.
Điều làm nó khác với các scraper no-code khác là kiến trúc. Thunderbit tách các mối quan tâm về crawling như hạ tầng cloud, xoay vòng proxy, xử lý anti-bot và render JavaScript ra khỏi phần trích xuất bằng AI đọc HTML và xuất ra các cột có cấu trúc. Điều này khớp với mô hình mà chuyên gia khuyến nghị: “scraper trước, LLM sau”, nhưng được đóng gói trong một workflow tiện ích Chrome mà nhân viên sales và quản lý vận hành có thể dùng được ngay.
Điểm mạnh chính
- Có cả scraping cloud và bằng trình duyệt trong cùng một giao diện. Chuyển đổi giữa các chế độ tùy theo site đích là công khai hay cần phiên đăng nhập của bạn. Chế độ cloud xử lý song song tới 50 trang.
- AI đọc lại cấu trúc trang mỗi lần. Không cần bảo trì XPath. Khi site cập nhật layout, Thunderbit sẽ tự thích ứng ở lần chạy tiếp theo.
- Scrape trang con. AI truy cập các trang chi tiết được liên kết và làm giàu bảng dữ liệu chính mà không cần cấu hình thủ công.
- Field AI Prompts. Gắn nhãn, dịch và phân loại tùy chỉnh ngay trong lúc trích xuất thay vì là một bước hậu xử lý riêng.
- Xuất miễn phí sang Google Sheets, Excel, Airtable và Notion.
- Mẫu scraper tức thì cho các site phổ biến như Amazon, Zillow và LinkedIn.
- Lên lịch bằng ngôn ngữ tự nhiên. Chỉ cần nói “scrape mỗi thứ Hai lúc 9 giờ sáng” và hệ thống sẽ chuyển thành lịch lặp lại.
- Open API với các endpoint Distill và Extract, xử lý theo lô tới 100 URL, và mức song song công khai từ 2 ở gói miễn phí đến 50 ở Pro 1.
Điểm có thể cải thiện
- Gói miễn phí được giới hạn nhỏ có chủ đích.
- Trải nghiệm no-code dựa nhiều vào tiện ích Chrome. Nhà phát triển muốn workflow chỉ dùng API sẽ cần dùng Open API riêng.
- Không phải lựa chọn phù hợp nếu nhu cầu chính của bạn chỉ là hạ tầng proxy thô mà không cần trích xuất.
Giá
Có gói miễn phí. Các gói no-code bắt đầu từ 9 USD/tháng khi thanh toán theo năm hoặc 15 USD/tháng khi thanh toán theo tháng cho gói Starter. Giá API là riêng: miễn phí một lần 600 units, sau đó 16 USD/tháng khi thanh toán theo năm cho Starter API và 40 USD/tháng khi thanh toán theo năm cho Pro 1 API. Xem Thunderbit Pricing và API Pricing.
Phù hợp nhất cho: Đội sales, thương mại điện tử và vận hành cần dữ liệu web có cấu trúc mà không cần hỗ trợ kỹ thuật.
2. Octoparse
Octoparse là một công cụ dựng workflow trực quan cho web scraping với thư viện mẫu dựng sẵn rất lớn. Nó đã tồn tại đủ lâu để có hạ tầng cloud trưởng thành, và xử lý phân trang tốt trên những website có cấu trúc rõ ràng, dễ dự đoán.
Điểm mạnh chính
- Nhiều mẫu scraping dựng sẵn cho các site phổ biến
- Trích xuất trên cloud với chạy theo lịch
- Xoay vòng IP và giải CAPTCHA là add-on trả phí
- Có API ở các gói cao hơn
Điểm có thể cải thiện
- Khả năng AI nhẹ hơn so với các công cụ native LLM. Gợi ý trường vẫn dựa nhiều vào template hơn là đọc thích ứng.
- Layout phức tạp hoặc khác thường đòi hỏi tinh chỉnh thủ công đáng kể trong trình dựng trực quan.
- Độ khó học tăng lên khi bạn cần logic điều kiện hoặc mẹo vượt chặn.
Giá
Có gói miễn phí vĩnh viễn. Trang trợ giúp chính thức hiện đang dẫn tới mức giá Standard từ 75 USD/tháng khi thanh toán theo năm và Professional từ 208 USD/tháng khi thanh toán theo năm, trong khi một số trang bản địa hóa và luồng nâng cấp lại hiển thị mức quy đổi tháng cao hơn. Điểm quan trọng là giá của Octoparse hiện kết hợp giữa phí thuê bao và add-on trả phí như proxy dân cư và giải CAPTCHA.
Phù hợp nhất cho: Chuyên viên phân tích và đội vận hành scrape các site có cấu trúc, phù hợp template ở quy mô vừa phải.
3. Browse AI
Browse AI là một nền tảng no-code trên cloud được xây dựng chủ yếu cho việc giám sát thay đổi của website theo thời gian, như giá đối thủ, tình trạng còn hàng và cập nhật nội dung. Scraping là một phần của sản phẩm, nhưng điểm khác biệt thực sự là hệ thống giám sát và cảnh báo định kỳ.
Điểm mạnh chính
- Phát hiện thay đổi và cảnh báo tích hợp sẵn
- Robot ghi lại thao tác no-code với thiết lập point-and-click
- Robot dựng sẵn cho các site phổ biến
- Hỗ trợ proxy cao cấp ở các gói cao hơn
Điểm có thể cải thiện
- Giá tính theo credit sẽ tăng rất nhanh khi giám sát các trang chi tiết ở quy mô lớn
- Kém hấp dẫn hơn cho trích xuất hàng loạt một lần so với các công cụ ưu tiên API
- Xử lý anti-bot ở mức trung bình; một số site vẫn cần proxy cao cấp hoặc workaround
Giá
Có tài khoản miễn phí. Gói trả phí bắt đầu khoảng 19 USD/tháng khi thanh toán theo năm cho Starter, với các mức credit và giám sát cao hơn phía trên.
Phù hợp nhất cho: Đội cần giám sát liên tục giá đối thủ, thay đổi nội dung hoặc mức tồn kho thay vì trích xuất hàng loạt một lần.
4. Firecrawl
Firecrawl là một API ưu tiên nhà phát triển, chuyển các trang web thành Markdown sạch hoặc JSON có cấu trúc. Nó nằm chủ yếu ở lớp trích xuất và rất phù hợp với đội xây dựng pipeline RAG hoặc đưa nội dung web vào LLM.
Điểm mạnh chính
- Chất lượng đầu ra Markdown rất tốt cho workflow LLM phía sau
- API gọn với các chức năng scrape, crawl, map, search, extract và browser actions
- Hỗ trợ xử lý theo lô
- Mức song song từ 2 ở gói miễn phí đến 100 ở Growth
Điểm có thể cải thiện
- Không có giao diện no-code và đòi hỏi kỹ năng dev
- Có hỗ trợ proxy và anti-bot tích hợp, nhưng Firecrawl không được định vị như một nhà cung cấp chuyên vượt chặn
- Không có scheduler chính chủ cho job định kỳ
- Không kinh tế cho người không phải dev chỉ muốn một bảng dữ liệu
Giá
Gói miễn phí gồm 1.000 credit mỗi tháng. Gói trả phí bắt đầu từ 16 USD/tháng khi thanh toán theo năm cho Hobby và mở rộng theo số credit, mức song song và mức dùng trình duyệt. Phiên trình duyệt được tính phí riêng bằng credit.
Phù hợp nhất cho: Nhà phát triển xây dựng pipeline LLM, hệ thống RAG hoặc workflow trích xuất tùy chỉnh, cần Markdown hoặc JSON sạch từ các trang web.
5. Apify
Apify là một nền tảng có marketplace các actor scraping dựng sẵn cùng công cụ để tự xây dựng actor riêng. Hãy xem nó như một lớp điều phối: bạn chọn hoặc tự tạo scraper chuyên biệt cho từng site, rồi lên lịch và quản lý chúng qua một API thống nhất.
Điểm mạnh chính
- Marketplace actor khổng lồ với các scraper do cộng đồng xây dựng cho hàng trăm site
- API và SDK mạnh cho nhà phát triển
- Quản lý proxy và lập lịch tích hợp sẵn
- Tích hợp với nhiều công cụ downstream
Điểm có thể cải thiện
- “No-code” chỉ đúng một phần khi bạn rời marketplace và cần logic tùy chỉnh
- Độ tin cậy của actor phụ thuộc vào việc cộng đồng duy trì
- Giá có thể tăng vì compute, chi phí actor và proxy cộng dồn
Giá
Gói miễn phí bao gồm 5 USD credit nền tảng mỗi tháng. Gói trả phí bắt đầu từ 39 USD/tháng cho Starter, với các gói hướng tới quy mô ở phía trên.
Phù hợp nhất cho: Đội ngũ dev muốn workflow scraping có thể tái sử dụng, có lịch chạy, cùng một hệ sinh thái giải pháp dựng sẵn lớn.
6. Gumloop
Gumloop là một nền tảng tự động hóa workflow no-code có bao gồm node web scraping. Giá trị thật không chỉ nằm ở scraping. Nó nằm ở việc kết nối trích xuất với LLM, Google Sheets, CRM và các công cụ khác trong cùng một canvas trực quan.
Điểm mạnh chính
- Trình dựng workflow kéo-thả trực quan
- Tích hợp scraping với LLM và công cụ kinh doanh phía sau trong cùng một luồng
- Gói miễn phí hiện được quảng bá ở mức 5.000 credit/tháng
- Lập lịch theo thời gian cho workflow định kỳ
- Chế độ scraping cơ bản và Web Agent tương tác bao phủ cả luồng đơn giản lẫn giàu ngữ cảnh
Điểm có thể cải thiện
- Bộ máy scraping kém vững hơn so với các công cụ AI web scraper chuyên dụng
- Khả năng anti-bot và proxy hạn chế hơn so với nhà cung cấp chuyên biệt
- Giới hạn concurrency và trigger chặt hơn trên gói miễn phí
- Không lý tưởng nếu use case chính là scraping quy mô lớn, số lượng cao
Giá
Có gói miễn phí. Gumloop đã gộp cấu trúc Solo và Team cũ vào một gói Pro vào cuối năm 2025, và thông điệp công khai từ đó tập trung vào credit miễn phí hào phóng hơn cùng các gói trả phí hợp nhất thay vì định giá theo kiểu scraper thuần túy.
Phù hợp nhất cho: Đội muốn đưa scraping vào một workflow tự động rộng hơn: scrape, phân tích, rồi đẩy vào các công cụ kinh doanh.
Nếu bạn muốn xem cảm giác của một workflow trích xuất native AI trong thực tế trước khi đọc tiếp, bài hướng dẫn Thunderbit này là demo sản phẩm phù hợp nhất cho đội không kỹ thuật.
7. Bright Data
Bright Data là bộ hạ tầng cấp doanh nghiệp trong danh sách này. Nếu vấn đề của bạn là “tôi không thể vượt qua lớp bảo vệ bot của site này dù đã thử mọi cách”, Bright Data có lẽ là câu trả lời, nhưng nó đi kèm độ phức tạp và mức giá cấp doanh nghiệp tương ứng.
Điểm mạnh chính
- Mạng proxy dẫn đầu ngành trên residential, datacenter và mobile IP
- Web Unlocker để vượt anti-bot và CAPTCHA
- Scraping Browser với cơ chế vượt chặn tích hợp
- Có sẵn bộ dữ liệu đã thu thập để mua
- Toàn quyền điều khiển bằng API và SDK
Điểm có thể cải thiện
- Không được thiết kế cho người dùng không kỹ thuật
- Giá phản ánh đúng định vị doanh nghiệp
- Trích xuất AI không phải lý do chính để mua nền tảng
Giá
Browser API bắt đầu từ 8 USD/GB theo dạng trả theo mức dùng, với đơn giá/GB thấp hơn ở các cam kết tháng lớn hơn. Các sản phẩm Bright Data khác như Unlocker, Scraper APIs, datasets và proxy pools dùng đơn vị giá khác nhau.
Phù hợp nhất cho: Đội dữ liệu doanh nghiệp cần scrape các site được bảo vệ mạnh ở quy mô lớn và có nhân sự kỹ thuật để quản lý hạ tầng.
8. Bardeen
Bardeen là một công cụ tự động hóa trình duyệt tập trung vào click, điền form và scraping với lớp trích xuất dữ liệu dùng AI bên trên. Có thể hiểu nó như một công cụ workflow GTM tình cờ có scraping, chứ không phải một scraper tình cờ làm GTM.
Điểm mạnh chính
- Tự động hóa kiểu playbook trực quan, với scraping chỉ là một bước trong chuỗi
- Các scraper chính thức do đội Bardeen duy trì cho các site phổ biến
- Tích hợp mạnh với CRM, Google Sheets, Slack và các công cụ kinh doanh khác
- Phù hợp cho workflow scrape lead, làm giàu dữ liệu và xuất sang CRM
Điểm có thể cải thiện
- Kiến trúc ưu tiên trình duyệt hạn chế scraping không giám sát ở quy mô lớn
- Scraping trên cloud chỉ hoạt động với trang công khai, không phải trang có chặn
- Xử lý anti-bot phần lớn phụ thuộc vào những gì phiên trình duyệt của bạn đã có sẵn
- AI extraction có thể gặp khó với layout trang phức tạp hoặc phi chuẩn
Giá
Gói miễn phí gồm 100 credit mỗi tháng. Tài liệu hỗ trợ công khai nhắc tới mức giá Pro di sản 15 USD/tháng cho người dùng cũ, trong khi gói thương mại hiện tại của Bardeen thiên về doanh nghiệp và workflow hơn là kiểu giá scraper thấp truyền thống.
Phù hợp nhất cho: Đội sales và vận hành cần scraping như một phần của workflow tự động hóa trình duyệt rộng hơn.
9. Diffbot
Diffbot dùng computer vision và NLP để đọc trang web như con người, rồi xuất dữ liệu có cấu trúc cho bài viết, sản phẩm, thảo luận và tổ chức. Đây là một trong những API trích xuất chất lượng cao nhất hiện có nếu trang của bạn khớp với mô hình đã huấn luyện sẵn của nó.
Điểm mạnh chính
- Mô hình trích xuất huấn luyện sẵn cho bài viết, sản phẩm, thảo luận và nhiều loại khác
- Knowledge Graph với hàng tỷ thực thể để làm giàu dữ liệu
- Chất lượng đầu ra có cấu trúc rất tốt trên các loại trang được hỗ trợ
- API rõ ràng cho nhà phát triển, có công bố giới hạn rate
Điểm có thể cải thiện
- Không có giao diện no-code
- Không có crawling, quản lý proxy hay xử lý anti-bot tích hợp
- Đắt với các đội nhỏ
- Ít linh hoạt hơn với các loại trang phi chuẩn so với các extractor dựa trên schema prompt
Giá
Gói miễn phí bao gồm 10.000 credit. Startup là 299 USD/tháng cho 250.000 credit, và Plus là 899 USD/tháng cho 1.000.000 credit.
Phù hợp nhất cho: Đội dev cần trích xuất có cấu trúc độ chính xác cao từ các loại trang tiêu chuẩn và sẵn sàng tự xử lý phần truy xuất.
10. ScrapingBee
ScrapingBee là một API web scraping tập trung vào lớp truy xuất và vượt chặn. Bạn gửi URL cho nó, nó xử lý proxy, render trình duyệt headless và các lớp phòng thủ anti-bot, rồi trả về HTML hoặc dữ liệu đã trích xuất tùy chọn.
Điểm mạnh chính
- Xoay vòng proxy và xử lý anti-bot tích hợp
- Hỗ trợ render JavaScript
- API REST đơn giản
- Endpoint scraping Google Search
- Công bố mức concurrency theo gói
Điểm có thể cải thiện
- Tính năng trích xuất AI còn hạn chế
- Không có giao diện no-code
- Không có lịch chạy hay giám sát tích hợp sẵn
- Phản hồi
200với trang chặn vẫn có thể bị tính là request thành công
Giá
Gói miễn phí gồm 1.000 API credit. Gói trả phí bắt đầu từ 49 USD/tháng và tăng theo concurrency và lưu lượng request cao hơn.
Phù hợp nhất cho: Nhà phát triển chủ yếu cần truy xuất trang web ổn định vượt qua anti-bot và sẽ tự xử lý phần trích xuất bằng code riêng hoặc công cụ khác.
11. Instant Data Scraper
Instant Data Scraper là một tiện ích Chrome miễn phí với hơn 1.000.000 người dùng, tự động phát hiện mẫu dữ liệu trên trang và cho phép bạn xuất sang CSV hoặc Excel. Không có gợi ý trường theo kiểu AI/LLM. Nó dùng phát hiện mẫu theo heuristic.
Điểm mạnh chính
- Hoàn toàn miễn phí, không cần tài khoản
- Phát hiện dữ liệu chỉ với một cú nhấp trên nhiều trang danh sách và bảng
- Xử lý phân trang trên một số site
- Rào cản sử dụng cực thấp
- Vẫn được duy trì, với các bản cập nhật trên Chrome Web Store trong năm 2026
Điểm có thể cải thiện
- Không có gợi ý trường hay gắn nhãn dữ liệu bằng AI
- Không có scraping trên cloud, lập lịch hay API
- Khó xử lý layout phức tạp, nội dung động và site nặng JavaScript
- Không có xử lý anti-bot ngoài những gì trình duyệt của bạn vốn tải được
- Xuất chỉ giới hạn ở CSV và Excel
Giá
Miễn phí. Mãi mãi.
Phù hợp nhất cho: Bất kỳ ai cần scrape nhanh, một lần, từ một trang danh sách đơn giản và không muốn tạo tài khoản hay trả tiền.
12. ParseHub
ParseHub là một ứng dụng desktop với giao diện trực quan point-and-click để xây dựng các dự án scraping. Nó có thể xử lý dữ liệu lồng nhau phức tạp, nội dung tải bằng AJAX, cuộn vô hạn và tương tác dropdown mà nhiều tiện ích đơn giản thường bỏ sót.
Điểm mạnh chính
- Giao diện chọn phần tử trực quan để định nghĩa quy tắc trích xuất
- Xử lý dữ liệu lồng nhau, dropdown, cuộn vô hạn và nội dung AJAX
- Gói miễn phí với tối đa 5 dự án
- Xuất sang JSON, CSV và Excel
- Có lập lịch trên cloud và xoay vòng IP ở gói trả phí
Điểm có thể cải thiện
- Quy trình chỉ trên desktop, không tiện như tiện ích trình duyệt
- Tốc độ thực thi chậm hơn so với các công cụ native cloud
- Dự án dễ hỏng khi layout site thay đổi vì không có lớp AI đọc lại
- Khả năng AI hạn chế và cảm giác của scraper trực quan kiểu cũ khá rõ
Giá
Có gói miễn phí với 5 dự án và 200 trang cho mỗi lần chạy. Gói trả phí bắt đầu từ 189 USD/tháng với lập lịch, xoay vòng IP và giới hạn cao hơn.
Phù hợp nhất cho: Người dùng không kỹ thuật cần scrape các site tương tác phức tạp và sẵn sàng đầu tư thời gian vào thiết lập workflow trực quan.
Cách bắt đầu với một AI Web Scraper trong 5 bước
Mỗi công cụ trong danh sách này có một luồng onboarding khác nhau. Tôi sẽ dùng Thunderbit làm ví dụ cụ thể vì nó khớp nhất với ý định tìm kiếm kiểu “tôi chỉ cần nó chạy được trên một trang thực”.
Bước 1: Cài đặt và mở trang
Cài đặt Thunderbit Chrome Extension và mở trang bạn muốn scrape: trang danh sách sản phẩm, thư mục doanh nghiệp hoặc cổng bất động sản.
Bước 2: Để AI đề xuất trường dữ liệu
Nhấn AI Suggest Fields. AI sẽ đọc trang hiện tại và đề xuất tên cột cùng kiểu dữ liệu. Trên trang sản phẩm, nó có thể đề xuất Tên sản phẩm, Giá, Đánh giá, URL ảnh và Mô tả.
Bước 3: Tùy chỉnh trường bằng AI Prompts
Điều chỉnh các cột nếu mặc định chưa thật chính xác. Thêm Field AI Prompts cho các biến đổi tùy chỉnh như “dịch mô tả sang tiếng Tây Ban Nha”, “phân loại thành Electronics, Home hoặc Fashion”, hoặc “chỉ trích xuất giá trị số”.
Bước 4: Chọn chế độ Cloud hoặc Trình duyệt và scrape
Chọn scraping trên cloud cho site công khai hoặc scraping bằng trình duyệt cho mục tiêu cần đăng nhập hay được bảo vệ mạnh. Sau đó nhấn Scrape.
Bước 5: Xuất dữ liệu đi bất kỳ đâu
Xuất kết quả sang Google Sheets, Excel, Airtable hoặc Notion. Việc xuất dữ liệu là miễn phí.
Nếu bố cục site thay đổi thì sao?
Đây là lợi thế thực chiến quan trọng nhất của các extractor native AI so với công cụ dựa trên quy tắc. Các scraper truyền thống như ParseHub và những workflow Octoparse đời cũ dựa vào selector XPath hoặc đường dẫn CSS. Khi site cập nhật cấu trúc HTML, các selector đó sẽ gãy và bạn phải cấu hình lại thủ công.
Các extractor dùng AI như Thunderbit đọc lại cấu trúc trang mỗi lần. Điều đó có nghĩa là không cần bảo trì XPath và không có selector mong manh. AI tự thích ứng với thay đổi layout ở lần chạy tiếp theo.
Scraping theo lịch và quyền truy cập API: những tính năng cho power user mà chẳng ai review
Scrape một lần thì ổn cho nghiên cứu. Nhưng các use case thực tế như giám sát giá, làm mới danh sách lead và theo dõi tồn kho lại cần trích xuất lặp lại và quyền truy cập theo chương trình. Những tính năng này phân biệt đồ chơi với công cụ.
Hỗ trợ lập lịch
| Công cụ | Lập lịch gốc | Ghi chú |
|---|---|---|
| Thunderbit | ✅ | Thiết lập bằng ngôn ngữ tự nhiên |
| Octoparse | ✅ | Chạy theo lịch trên cloud |
| Browse AI | ✅ | Tính năng cốt lõi |
| Firecrawl | ❌ | Dùng cron bên ngoài |
| Apify | ✅ | Biểu thức cron đầy đủ |
| Gumloop | ✅ | Trigger workflow theo thời gian |
| Bright Data | Bên ngoài | Thường điều phối qua hệ thống của khách hàng |
| Bardeen | ✅ | Lập lịch theo playbook |
| Diffbot | ❌ | Ưu tiên API, điều phối bên ngoài |
| ScrapingBee | ❌ | Chỉ API |
| Instant Data Scraper | ❌ | Công cụ thủ công trong trình duyệt |
| ParseHub | ✅ (trả phí) | Tính năng cao cấp |
So sánh API dành cho nhà phát triển
| Công cụ | Tín hiệu concurrency hoặc rate | Mô hình giá |
|---|---|---|
| Thunderbit | 2 → 50 luồng đồng thời | Tính theo credit |
| Firecrawl | 2 → 100 luồng đồng thời | Tính theo credit |
| Apify | Phụ thuộc gói | Compute units |
| Gumloop | Concurrency workflow bị giới hạn theo gói | Tính theo credit |
| Diffbot | 5 calls/phút → 25 calls/giây | Tính theo credit |
| ScrapingBee | 10 → 200 luồng đồng thời | Credit API |
| Bright Data | Browser API quảng bá số request đồng thời không giới hạn | Tính theo GB |
Nếu use case của bạn thiên về kỹ thuật hơn và bạn đang cố quyết định mức độ hạ tầng muốn tự sở hữu, bài hướng dẫn Firecrawl này là một bổ sung rất hữu ích, thiên về triển khai, cho các so sánh sản phẩm ở trên.
Cách chọn đúng AI Web Scraper
Sau khi thử cả 12 công cụ, đây là cách tôi sẽ quyết định:
- Đội không kỹ thuật cần dữ liệu nhanh: Bắt đầu với Thunderbit. Workflow hai cú nhấp, xuất miễn phí và chuyển đổi giữa trình duyệt/cloud bao phủ hầu hết nhu cầu scraping doanh nghiệp mà không cần hỗ trợ kỹ thuật.
- Cần giám sát và cảnh báo liên tục: Browse AI được xây cho việc này. Nó không phải extractor một lần mạnh nhất, nhưng phát hiện thay đổi là tính năng hạng nhất.
- Nhà phát triển xây pipeline LLM: Firecrawl để trích xuất Markdown hoặc JSON, hoặc Diffbot cho trích xuất có cấu trúc đã huấn luyện sẵn. Kết hợp một trong hai với ScrapingBee hoặc Bright Data nếu bạn cần xử lý anti-bot mạnh ở lớp truy xuất.
- Cần marketplace scraper dựng sẵn: Apify có hệ sinh thái actor lớn nhất. Chỉ cần chuẩn bị tinh thần cho việc bảo trì khi actor hỏng.
- Mục tiêu quy mô doanh nghiệp, được bảo vệ rất mạnh: Bright Data. Không công cụ nào khác sánh được hạ tầng proxy của nó, nhưng hãy cân nhắc ngân sách và nhân sự kỹ thuật tương ứng.
- Muốn scraping là một phần của tự động hóa lớn hơn: Gumloop hoặc Bardeen, tùy bạn đang tự động hóa workflow hay các tác vụ GTM dựa trên trình duyệt.
- Chỉ cần một lần scrape nhanh, miễn phí: Instant Data Scraper. Không cài đặt, không chi phí, không phức tạp, nhưng cũng không có lịch chạy, không AI và không cloud.
- Site tương tác phức tạp có dropdown và AJAX: ParseHub vẫn xử lý các trường hợp này tốt hơn hầu hết tiện ích, dù gánh nặng bảo trì là có thật.
Thử Thunderbit trên một trang thật trước khi bạn đầu tư vào một bộ công cụ lớn hơn
Kết luận
Thị trường AI web scraper năm 2026 đang đông đúc với những công cụ nhìn rất ấn tượng trong demo nhưng lại gây thất vọng khi chạy thực tế. Khoảng cách giữa “chạy được trên ảnh marketing” và “chạy được trên một site thương mại điện tử được bảo vệ lúc 3 giờ sáng theo lịch” chính là nơi phần lớn người mua lãng phí thời gian và tiền bạc.
Điều cốt lõi rút ra từ việc đánh giá cả 12 công cụ rất đơn giản: lớp truy xuất vẫn là phần khó nhất. AI rất giỏi ở trích xuất và hậu xử lý, nhưng nó không thay thế được hạ tầng proxy, xử lý anti-bot hay quản lý session. Những công cụ tốt nhất либо giải quyết cả hai lớp, như Thunderbit và Bright Data, hoặc nói rất rõ chúng xử lý lớp nào, như Firecrawl cho trích xuất và ScrapingBee cho truy xuất.
Nếu bạn muốn xem một AI web scraper sẵn sàng cho production trông như thế nào mà không cần viết code, hãy thử Thunderbit. Gói miễn phí đủ để bạn kiểm tra toàn bộ workflow trên các trang thật. Nếu nhu cầu của bạn thiên về nhà phát triển hơn, hãy ghép một API trích xuất với một dịch vụ truy xuất chuyên dụng và tự cứu mình khỏi nỗi bực bội khi kỳ vọng một công cụ làm được tất cả.
Câu hỏi thường gặp
Vì sao hầu hết AI web scraper đều thất bại trên website thực tế dù chạy rất tốt trong demo?
Demo thường chỉ trình diễn trích xuất trên các trang sạch và không bị bảo vệ. Website thực tế có thêm Cloudflare protection, render JavaScript động, phân trang, yêu cầu đăng nhập và layout thay đổi thường xuyên. Phần lớn công cụ xử lý tốt lớp phân tích và trích xuất, nhưng thiếu hạ tầng vững cho lớp truy xuất.
Sự khác nhau giữa scraping trên cloud và scraping bằng trình duyệt là gì, và khi nào nên dùng từng loại?
Scraping trên cloud dùng máy chủ từ xa để tải trang, nên nhanh hơn, song song tốt hơn và mở rộng dễ hơn. Scraping bằng trình duyệt chạy trong phiên trình duyệt của chính bạn và phù hợp hơn cho site cần xác thực hoặc có phát hiện bot mạnh. Thunderbit là một trong số ít công cụ cung cấp cả hai chế độ trong cùng một giao diện.
Tôi có thể dùng AI web scraper cho các tác vụ lặp lại như theo dõi giá không?
Có, nhưng chỉ khi công cụ hỗ trợ scraping theo lịch. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen và ParseHub ở gói trả phí đều có hỗ trợ lập lịch.
AI web scraper nào là tốt nhất nếu tôi không biết lập trình?
Thunderbit mang lại con đường nhanh nhất để có dữ liệu dùng được cho người không kỹ thuật. Instant Data Scraper hoàn toàn miễn phí nhưng chỉ phù hợp với các trang đơn giản. Browse AI và Octoparse có giao diện trực quan nhưng cần thiết lập nhiều hơn. ParseHub mạnh cho site tương tác phức tạp nhưng đường cong học tập dốc hơn.
Scraping AI web ở mức production thực sự tốn bao nhiêu?
Mức giá rất rộng. Instant Data Scraper là miễn phí. Thunderbit, Firecrawl và Browse AI có các điểm vào miễn phí với gói trả phí chi phí thấp. Các công cụ tầm trung như Octoparse, ParseHub và ScrapingBee có thể từ khoảng 49 đến 189 USD mỗi tháng. Các giải pháp doanh nghiệp như Bright Data và Diffbot bắt đầu ở mức cao hơn nhiều.




