
Nói thẳng nhé—Amazon về cơ bản là trung tâm thương mại, siêu thị và cửa hàng điện tử của cả Internet. Nếu bạn làm sales, e-commerce hay operations, hẳn bạn đã biết những gì diễn ra trên Amazon không chỉ dừng lại ở Amazon—nó còn tác động đến giá bán, tồn kho, thậm chí cả lần ra mắt sản phẩm lớn tiếp theo của bạn. Nhưng vấn đề là: tất cả thông tin sản phẩm hấp dẫn đó, từ giá cả, đánh giá đến review, đều bị khóa sau một giao diện web được xây cho người mua hàng, chứ không phải cho các team cần dữ liệu. Vậy làm sao lấy được dữ liệu đó mà không phải ngồi cuối tuần copy-paste như đang ở năm 1999?
Đó là lúc web scraping phát huy tác dụng. Trong bài hướng dẫn này, tôi sẽ chỉ bạn hai cách để trích xuất dữ liệu sản phẩm Amazon: cách kinh điển “xắn tay áo lên và code bằng Python”, và cách hiện đại “để AI làm phần nặng” với một công cụ thu thập dữ liệu web không cần code như . Tôi sẽ đi qua code Python thực tế (kèm toàn bộ bẫy và cách xử lý), rồi cho bạn thấy Thunderbit có thể lấy cùng loại dữ liệu đó chỉ trong vài cú nhấp chuột—không cần viết code. Dù bạn là developer, business analyst hay chỉ là người đã chán nhập liệu thủ công, bài này đều dành cho bạn.
Tại sao nên trích xuất dữ liệu sản phẩm Amazon? (amazon scraper python, web scraping with python)
Amazon không chỉ là nhà bán lẻ trực tuyến lớn nhất thế giới—mà còn là khu chợ ngoài trời lớn nhất thế giới cho tình báo cạnh tranh. Với và , Amazon là mỏ vàng cho bất kỳ ai muốn:

- Theo dõi giá (và điều chỉnh giá của bạn theo thời gian thực)
- Phân tích đối thủ (theo dõi sản phẩm mới ra mắt, đánh giá và review của họ)
- Tạo lead (tìm nhà bán hàng, nhà cung cấp, hoặc thậm chí đối tác tiềm năng)
- Dự báo nhu cầu (bằng cách theo dõi mức tồn kho và thứ hạng bán hàng)
- Phát hiện xu hướng thị trường (bằng cách khai thác review và kết quả tìm kiếm)
Và đây không chỉ là lý thuyết—doanh nghiệp thực tế đang thấy ROI rõ ràng. Ví dụ, một nhà bán lẻ điện tử đã dùng dữ liệu giá Amazon được thu thập để , trong khi một thương hiệu khác ghi nhận sau khi tự động hóa việc theo dõi giá đối thủ.
Dưới đây là bảng nhanh về các trường hợp sử dụng và mức ROI bạn có thể kỳ vọng:
| Trường hợp sử dụng | Ai dùng | ROI / Lợi ích điển hình |
|---|---|---|
| Theo dõi giá | E-commerce, Vận hành | Tăng biên lợi nhuận 15%+, tăng doanh số 4%, giảm 30% thời gian analyst |
| Phân tích đối thủ | Sales, Sản phẩm, Vận hành | Điều chỉnh giá nhanh hơn, tăng sức cạnh tranh |
| Nghiên cứu thị trường (Review) | Sản phẩm, Marketing | Lặp lại sản phẩm nhanh hơn, copy quảng cáo tốt hơn, insight SEO |
| Tạo lead | Sales | Hơn 3.000 lead/tháng, tiết kiệm hơn 8 giờ/tuần cho mỗi nhân viên sales |
| Dự báo tồn kho & nhu cầu | Vận hành, Chuỗi cung ứng | Giảm 20% hàng tồn, ít hết hàng hơn |
| Phát hiện xu hướng | Marketing, Ban lãnh đạo | Phát hiện sớm sản phẩm và danh mục đang hot |
Và đây mới là điểm đáng nói: hiện báo cáo rằng phân tích dữ liệu mang lại giá trị đo lường được. Nếu bạn không thu thập dữ liệu từ Amazon, bạn đang để tuột mất insight (và tiền bạc).
Tổng quan: Amazon Scraper Python vs. các công cụ thu thập dữ liệu web không cần code
Có hai cách chính để đưa dữ liệu Amazon ra khỏi trình duyệt và vào bảng tính hoặc dashboard của bạn:
-
Amazon Scraper Python (web scraping with python):
Tự viết script bằng các thư viện Python như Requests và BeautifulSoup. Cách này cho bạn toàn quyền kiểm soát, nhưng bạn cần biết code, xử lý biện pháp chống bot và duy trì script khi Amazon thay đổi giao diện.
-
Công cụ thu thập dữ liệu web không cần code (như Thunderbit):
Dùng công cụ cho phép bạn trỏ, nhấp và trích xuất dữ liệu—không cần lập trình. Các công cụ hiện đại như thậm chí còn dùng AI để tự nhận diện dữ liệu cần lấy, xử lý subpage và phân trang, rồi xuất thẳng sang Excel hoặc Google Sheets.
So sánh nhanh như sau:
| Tiêu chí | Python Scraper | Không cần code (Thunderbit) |
|---|---|---|
| Thời gian thiết lập | Cao (cài đặt, code, debug) | Thấp (cài extension) |
| Kỹ năng cần có | Cần biết code | Không cần (trỏ & nhấp) |
| Tính linh hoạt | Không giới hạn | Cao cho các nhu cầu phổ biến |
| Bảo trì | Bạn tự sửa code | Công cụ tự cập nhật |
| Xử lý chống bot | Bạn tự lo proxy, header | Tích hợp sẵn, công cụ lo giúp |
| Khả năng mở rộng | Thủ công (thread, proxy) | Thu thập trên cloud, chạy song song |
| Xuất dữ liệu | Tùy chỉnh (CSV, Excel, DB) | Một cú nhấp để xuất sang Excel, Sheets |
| Chi phí | Miễn phí (thời gian của bạn + proxy) | Freemium, trả phí khi mở rộng quy mô |
Ở các phần tiếp theo, tôi sẽ dẫn bạn qua cả hai cách—đầu tiên là cách xây Amazon scraper bằng Python (có code thật), rồi cách làm tương tự bằng AI web scraper của Thunderbit.
Bắt đầu với Amazon Scraper Python: Yêu cầu và thiết lập
Trước khi đi vào code, hãy chuẩn bị môi trường của bạn.
Bạn sẽ cần:
- Python 3.x (tải từ )
- Một trình soạn thảo code (tôi thích VS Code, nhưng bất kỳ cái nào cũng được)
- Các thư viện sau:
requests(cho HTTP requests)beautifulsoup4(cho phân tích HTML)lxml(trình phân tích HTML nhanh)pandas(cho bảng dữ liệu/xuất file)re(biểu thức chính quy, có sẵn)
Cài các thư viện:
1pip install requests beautifulsoup4 lxml pandasThiết lập dự án:
- Tạo một thư mục mới cho dự án.
- Mở trình soạn thảo, tạo một file Python mới (ví dụ:
amazon_scraper.py). - Sẵn sàng bắt đầu!
Từng bước: Web scraping bằng Python cho dữ liệu sản phẩm Amazon
Hãy cùng scrape một trang sản phẩm Amazon đơn lẻ. (Đừng lo, lát nữa chúng ta sẽ nói đến việc scrape nhiều sản phẩm và nhiều trang.)
1. Gửi request và lấy HTML
Trước tiên, hãy lấy HTML của một trang sản phẩm. (Thay URL bằng bất kỳ sản phẩm Amazon nào.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Lưu ý: Request cơ bản này rất có thể sẽ bị Amazon chặn. Bạn có thể gặp lỗi 503 hoặc CAPTCHA thay vì trang sản phẩm. Vì sao? Vì Amazon biết bạn không phải là một trình duyệt thật.
Xử lý các biện pháp chống bot của Amazon
Amazon không thích bot. Để tránh bị chặn, bạn sẽ cần:
- Thiết lập header User-Agent (giả làm Chrome hoặc Firefox)
- Luân phiên User-Agent (đừng dùng một cái duy nhất mãi)
- Giới hạn tốc độ request (thêm độ trễ ngẫu nhiên)
- Dùng proxy (cho các chiến dịch scrape quy mô lớn)
Đây là cách đặt header:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Muốn làm “xịn” hơn? Hãy dùng danh sách User-Agent và luân phiên mỗi lần request. Với tác vụ lớn, bạn sẽ muốn dùng dịch vụ proxy (có rất nhiều), nhưng với scraping quy mô nhỏ, header và độ trễ thường là đủ.
Trích xuất các trường sản phẩm quan trọng
Khi đã có HTML, đến lúc phân tích nó bằng BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Giờ hãy lấy những thông tin quan trọng:
Tiêu đề sản phẩm
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NoneGiá
Giá trên Amazon có thể nằm ở vài vị trí. Hãy thử các cách sau:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textĐánh giá và số lượng review
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # ví dụ: "1,554 ratings"URL ảnh chính
Đôi khi Amazon giấu ảnh độ phân giải cao trong JSON nằm bên trong HTML. Đây là một cách dùng regex nhanh:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneHoặc lấy thẻ ảnh chính:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneThông tin sản phẩm
Các thông số như thương hiệu, trọng lượng và kích thước thường nằm trong một bảng:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueHoặc nếu Amazon dùng định dạng “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()In kết quả ra:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)Scrape nhiều sản phẩm và xử lý phân trang
Một sản phẩm thì ổn, nhưng nhiều khả năng bạn muốn cả một danh sách. Đây là cách scrape trang kết quả tìm kiếm và nhiều trang liên tiếp.
Lấy link sản phẩm từ trang tìm kiếm
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Xử lý phân trang
URL tìm kiếm của Amazon dùng &page=2, &page=3, v.v.
1for page in range(1, 6): # scrape 5 trang đầu
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... trích xuất link sản phẩm như trên ...Lặp qua các trang sản phẩm và xuất ra CSV
Thu thập dữ liệu sản phẩm vào một danh sách các dict, rồi dùng pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # danh sách dict
3df.to_csv("amazon_products.csv", index=False)Hoặc xuất sang Excel:
1df.to_excel("amazon_products.xlsx", index=False)Best practices cho dự án Amazon Scraper Python
Nói thật nhé—Amazon liên tục thay đổi website và chống lại scraper. Đây là cách giữ cho dự án của bạn chạy ổn:
- Luân phiên header và User-Agent (dùng thư viện như
fake-useragent) - Dùng proxy cho scraping quy mô lớn
- Giới hạn tốc độ request (thêm
time.sleep()ngẫu nhiên giữa các request) - Xử lý lỗi một cách mềm dẻo (thử lại khi gặp 503, giảm tốc nếu bị chặn)
- Viết logic phân tích linh hoạt (tìm nhiều selector cho mỗi trường)
- Theo dõi thay đổi HTML (nếu script đột nhiên trả về
Nonecho mọi thứ, hãy kiểm tra lại trang) - Tôn trọng robots.txt (Amazon không cho scrape nhiều phần—hãy làm có trách nhiệm)
- Làm sạch dữ liệu ngay khi thu thập (loại bỏ ký hiệu tiền tệ, dấu phẩy, khoảng trắng)
- Giữ kết nối với cộng đồng (forum, Stack Overflow, Reddit r/webscraping)
Checklist để duy trì scraper của bạn:
- [ ] Luân phiên User-Agent và header
- [ ] Dùng proxy nếu scrape ở quy mô lớn
- [ ] Thêm độ trễ ngẫu nhiên
- [ ] Tổ chức code theo module để dễ cập nhật
- [ ] Theo dõi việc bị chặn hoặc CAPTCHA
- [ ] Xuất dữ liệu thường xuyên
- [ ] Ghi lại selector và logic của bạn
Nếu muốn tìm hiểu sâu hơn, hãy xem của tôi.
Giải pháp không cần code: Scraping Amazon với Thunderbit AI Web Scraper
Được rồi, bạn đã xem cách làm bằng Python. Nhưng nếu bạn không muốn code—hoặc chỉ muốn lấy dữ liệu trong hai cú nhấp chuột rồi tiếp tục công việc của mình—thì đó là lúc phát huy tác dụng.
Thunderbit là một tiện ích Chrome AI web scraper cho phép bạn trích xuất dữ liệu sản phẩm Amazon (và gần như mọi trang web khác) mà không cần viết code. Đây là lý do tôi thích nó:
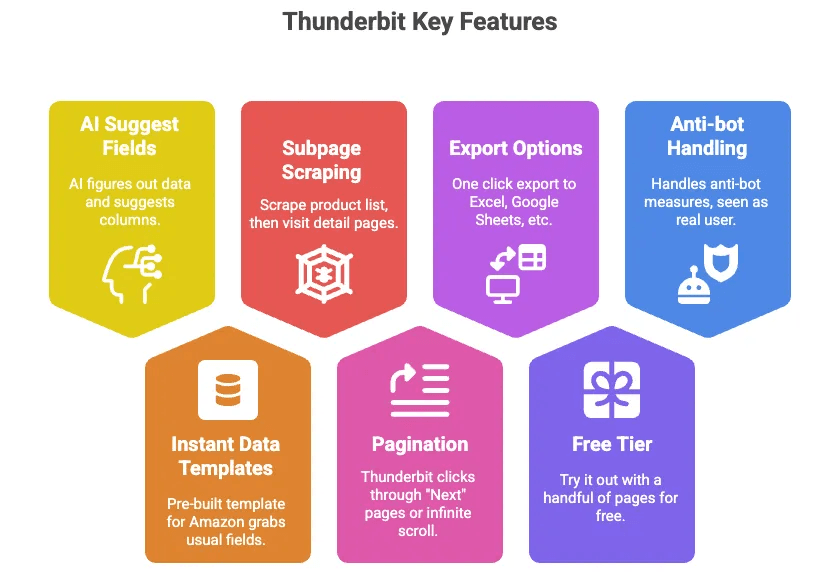
- AI gợi ý trường dữ liệu: Chỉ cần nhấp một nút, AI của Thunderbit sẽ nhận ra dữ liệu trên trang và gợi ý các cột (như Tiêu đề, Giá, Đánh giá, v.v.).
- Mẫu dữ liệu tức thì: Với Amazon, đã có sẵn template dựng sẵn để lấy các trường thường dùng—không cần thiết lập.
- Scrape subpage: Scrape danh sách sản phẩm, rồi để Thunderbit tự vào từng trang chi tiết sản phẩm và kéo thêm thông tin.
- Phân trang: Thunderbit có thể tự bấm qua các trang “Tiếp theo” hoặc cuộn vô hạn giúp bạn.
- Xuất sang Excel, Google Sheets, Airtable, Notion: Chỉ một cú nhấp là dữ liệu sẵn sàng sử dụng.
- Gói miễn phí: Dùng thử miễn phí với một số trang nhất định.
- Xử lý phần chống bot giúp bạn: Vì công cụ chạy trong trình duyệt của bạn (hoặc trên cloud), Amazon sẽ nhìn thấy như người dùng thật.
Từng bước: Dùng Thunderbit để scrape dữ liệu sản phẩm Amazon
Rất đơn giản như sau:
-
Cài Thunderbit:
Tải và đăng nhập.
-
Mở Amazon:
Đi tới trang Amazon mà bạn muốn scrape (kết quả tìm kiếm, trang chi tiết sản phẩm, gì cũng được).
-
Nhấp “AI Suggest Fields” hoặc dùng template:
Thunderbit sẽ gợi ý các cột cần trích xuất (hoặc bạn có thể chọn template Amazon Product).
-
Xem lại các cột:
Điều chỉnh cột nếu muốn (thêm/xóa trường, đổi tên, v.v.).
-
Nhấp “Scrape”:
Thunderbit lấy dữ liệu từ trang và hiển thị trong một bảng.
-
Xử lý subpage & phân trang:
Nếu bạn scrape một danh sách, hãy nhấp “Scrape Subpages” để vào từng trang chi tiết sản phẩm và lấy thêm thông tin. Thunderbit cũng có thể tự bấm qua các trang “Next”.
-
Xuất dữ liệu của bạn:
Nhấp “Export to Excel” hoặc “Export to Google Sheets.” Xong.
-
(Tuỳ chọn) Lên lịch scrape:
Cần dữ liệu này mỗi ngày? Dùng bộ lập lịch của Thunderbit để tự động hóa.
Xong. Không code, không debug, không proxy, không đau đầu. Nếu muốn xem hướng dẫn trực quan, hãy xem hoặc .
Amazon Scraper Python vs. No Code Web Scraper: So sánh trực tiếp
Hãy ghép tất cả lại:
| Tiêu chí | Python Scraper | Thunderbit (Không cần code) |
|---|---|---|
| Thời gian thiết lập | Cao (cài đặt, code, debug) | Thấp (cài extension) |
| Kỹ năng cần có | Cần biết code | Không cần (trỏ & nhấp) |
| Tính linh hoạt | Không giới hạn | Cao cho các nhu cầu phổ biến |
| Bảo trì | Bạn tự sửa code | Công cụ tự cập nhật |
| Xử lý chống bot | Bạn tự lo proxy, header | Tích hợp sẵn, công cụ lo giúp |
| Khả năng mở rộng | Thủ công (thread, proxy) | Thu thập trên cloud, chạy song song |
| Xuất dữ liệu | Tùy chỉnh (CSV, Excel, DB) | Một cú nhấp để xuất sang Excel, Sheets |
| Chi phí | Miễn phí (thời gian của bạn + proxy) | Freemium, trả phí khi mở rộng quy mô |
| Phù hợp nhất với | Developer, nhu cầu tùy biến cao | Người dùng doanh nghiệp, cần kết quả nhanh |
Nếu bạn là developer thích mày mò và cần thứ gì đó siêu tùy chỉnh, Python là lựa chọn phù hợp. Nếu bạn muốn tốc độ, sự đơn giản và không cần code, Thunderbit là con đường nên đi.
Khi nào nên chọn Python, no code, hoặc AI web scraper cho dữ liệu Amazon
Chọn Python nếu:
- Bạn cần logic tùy chỉnh hoặc muốn tích hợp scraping vào hệ thống backend
- Bạn scrape ở quy mô rất lớn (hàng chục nghìn sản phẩm)
- Bạn muốn hiểu cách scraping hoạt động từ bên trong
Chọn Thunderbit (không cần code, AI web scraper) nếu:
- Bạn muốn có dữ liệu nhanh, không cần lập trình
- Bạn là người dùng doanh nghiệp, analyst, hoặc marketer
- Bạn cần trao quyền cho đội nhóm tự lấy dữ liệu
- Bạn muốn tránh rắc rối của proxy, biện pháp chống bot và bảo trì
Dùng cả hai nếu:
- Bạn muốn prototype nhanh bằng Thunderbit, rồi xây một giải pháp Python tùy chỉnh cho production
- Bạn muốn dùng Thunderbit để thu thập dữ liệu và Python để làm sạch/phân tích dữ liệu
Với đa số người dùng doanh nghiệp, Thunderbit sẽ đáp ứng 90% nhu cầu scrape Amazon của bạn trong một phần rất nhỏ thời gian. Với 10% còn lại—những thứ siêu tùy biến, quy mô lớn hoặc tích hợp sâu—Python vẫn là vua.
Kết luận & điểm chính cần nhớ
Scrape dữ liệu sản phẩm Amazon là một “siêu năng lực” đối với bất kỳ team sales, e-commerce hay operations nào. Dù bạn đang theo dõi giá, phân tích đối thủ hay chỉ muốn đội nhóm của mình thoát khỏi cảnh copy-paste vô tận, đều có giải pháp cho bạn.
- Scraping bằng Python cho bạn toàn quyền kiểm soát, nhưng đi kèm đường cong học tập và việc bảo trì liên tục.
- Công cụ thu thập dữ liệu web không cần code như Thunderbit giúp mọi người đều có thể trích xuất dữ liệu Amazon—không cần code, không đau đầu, chỉ cần kết quả.
- Cách tốt nhất? Dùng công cụ phù hợp với kỹ năng, tiến độ và mục tiêu kinh doanh của bạn.
Nếu bạn tò mò, hãy thử Thunderbit—bắt đầu miễn phí, và bạn sẽ ngạc nhiên vì lấy được dữ liệu mình cần nhanh đến mức nào. Và nếu bạn là developer, đừng ngại kết hợp linh hoạt: đôi khi cách nhanh nhất để build là để AI lo phần nhàm chán.
Câu hỏi thường gặp
1. Vì sao doanh nghiệp muốn scrape dữ liệu sản phẩm Amazon?
Scraping Amazon cho phép doanh nghiệp theo dõi giá, phân tích đối thủ, thu thập review để nghiên cứu sản phẩm, dự báo nhu cầu và tạo lead bán hàng. Với hơn 600 triệu sản phẩm và gần 2 triệu người bán trên Amazon, đây là nguồn tình báo cạnh tranh rất phong phú.
2. Điểm khác biệt chính giữa dùng Python và các công cụ không cần code như Thunderbit để scrape Amazon là gì?
Python scraper mang lại độ linh hoạt tối đa nhưng cần kỹ năng lập trình, thời gian thiết lập và bảo trì liên tục. Thunderbit, một AI web scraper không cần code, cho phép người dùng trích xuất dữ liệu Amazon ngay lập tức qua Chrome extension—không cần code, có sẵn xử lý chống bot và tùy chọn xuất sang Excel hoặc Sheets.
3. Scrape dữ liệu từ Amazon có hợp pháp không?
Điều khoản dịch vụ của Amazon thường cấm scraping, và họ chủ động triển khai các biện pháp chống bot. Tuy nhiên, nhiều doanh nghiệp vẫn scrape dữ liệu công khai trong phạm vi vận hành có trách nhiệm, chẳng hạn tôn trọng giới hạn tốc độ và tránh gửi quá nhiều request.
4. Tôi có thể trích xuất loại dữ liệu nào từ Amazon bằng các công cụ web scraping?
Các trường dữ liệu phổ biến gồm tiêu đề sản phẩm, giá, đánh giá, số lượng review, hình ảnh, thông số sản phẩm, tình trạng còn hàng và cả thông tin người bán. Thunderbit cũng hỗ trợ scrape subpage và phân trang để lấy dữ liệu từ nhiều listing và nhiều trang.
5. Khi nào nên chọn scraping bằng Python thay vì dùng công cụ như Thunderbit, hoặc ngược lại?
Hãy dùng Python nếu bạn cần toàn quyền kiểm soát, logic tùy chỉnh hoặc dự định tích hợp scraping vào hệ thống backend. Hãy dùng Thunderbit nếu bạn muốn kết quả nhanh không cần code, cần mở rộng dễ dàng hoặc là người dùng doanh nghiệp muốn một giải pháp ít phải bảo trì.
Muốn tìm hiểu sâu hơn? Xem các tài nguyên sau:
Chúc bạn scrape vui vẻ—và mong bảng tính của bạn luôn được cập nhật.