
Eğer içerik kaydırdıkça yüklenen, fiyatları giriş ekranının arkasına saklayan ya da neredeyse her hafta yerleşimini değiştiren bir web sitesinden veri çekmeye çalıştıysanız, mücadelenin ne kadar gerçek olduğunu bilirsiniz. Statik scraper’lar artık yetmiyor. Nitekim, ABD’deki yatırım danışmanlarının %67’sinden fazlası alternatif veri için web scraping’e güveniyor ve ABD’deki perakendecilerin %81’i rakip fiyat takibini otomatikleştiriyor. Ama işin püf noktası şu: bu verilerin önemli bir kısmı, JavaScript ile yüklenen ve kullanıcı etkileşimlerinin arkasına gizlenen dinamik sitelerde duruyor. Headless browser otomasyonu ve Puppeteer gibi araçlar tam da burada devreye giriyor.
Yıllarını otomasyon ve AI araçları geliştirerek geçirmiş biri olarak (evet, satış ve operasyon ekipleri için epey site de kazıdım), Puppeteer’ın geleneksel scraper’ların kaçırdığı verileri nasıl ortaya çıkarabildiğini bizzat gördüm. Ama bununla birlikte, kod yazma yükünün iş kullanıcıları için ne kadar caydırıcı olabildiğini de gördüm. Bu rehberde, Puppeteer scraper’ın ne olduğunu, web scraping için nasıl kullanılacağını ve ne zaman bunun yerine çok daha basit bir şeye — bizim AI destekli, kodsuz web scraper’ımız gibi — yönelmenin daha mantıklı olacağını anlatacağım.
Puppeteer Scraper Nedir? Hızlı Bir Genel Bakış
 Önce temel kavramlardan başlayalım. , Google’ın açık kaynaklı bir Node.js kütüphanesidir ve JavaScript kullanarak headless Chrome ya da Chromium tarayıcısını kontrol etmenizi sağlar. Kısacası, ekranınızda hiçbir şey göstermeden web sayfalarını açabilen, butonlara tıklayabilen, formları doldurabilen, kaydırma yapabilen ve en önemlisi veri çekebilen bir robotunuz varmış gibi düşünebilirsiniz.
Önce temel kavramlardan başlayalım. , Google’ın açık kaynaklı bir Node.js kütüphanesidir ve JavaScript kullanarak headless Chrome ya da Chromium tarayıcısını kontrol etmenizi sağlar. Kısacası, ekranınızda hiçbir şey göstermeden web sayfalarını açabilen, butonlara tıklayabilen, formları doldurabilen, kaydırma yapabilen ve en önemlisi veri çekebilen bir robotunuz varmış gibi düşünebilirsiniz.
Puppeteer’ı özel kılan nedir?
- Dinamik içeriği render edebilir — yani gerçek bir kullanıcı gibi JavaScript’in yüklenmesini bekler.
- Kullanıcı hareketlerini taklit edebilir: tıklama, yazma, kaydırma ve hatta açılır pencereleri yönetme.
- Verinin yalnızca etkileşimden sonra göründüğü e-ticaret listeleri, sosyal akışlar veya panolar gibi siteleri kazımak için idealdir.
Diğer araçlarla karşılaştırınca nasıldır?
- Selenium: Tarayıcı otomasyonunun öncüsü. Birçok tarayıcı ve dil ile çalışır, ancak daha ağırdır ve biraz daha eski usuldür. Çapraz tarayıcı testleri için çok iyidir; fakat Chrome/Node.js projelerinde Puppeteer daha çeviktir.
- Thunderbit: Benim heyecanlandığım kısım burası. Thunderbit, tarayıcınızda çalışan, kodsuz ve AI destekli bir web scraper’dır. Script yazmak yerine sadece “AI Suggest Fields”e tıklarsınız; hangi verilerin çekileceğine AI karar verir. Kod yazmadan sonuç almak isteyen iş kullanıcıları için birebirdir (birazdan buna daha fazla değineceğim).
Kısacası: Puppeteer = maksimum kontrol (kod yazıyorsanız). Thunderbit = maksimum kullanım kolaylığı (kod yazmak istemiyorsanız).
Puppeteer Web Scraping İş Kullanıcıları İçin Neden Önemli?
Gerçekçi olalım: web scraping artık yalnızca hacker’lar veya veri bilimcileri için değil. Satış, operasyon, pazarlama ve hatta gayrimenkul ekipleri iş verisini öne geçmek için kullanıyor. Ve iş açısından kritik bu kadar çok bilgi dinamik sitelerin arkasına kilitlenmişken, onu açmanın anahtarı çoğu zaman Puppeteer oluyor.
İşte gerçek dünyadan bazı kullanım örnekleri:
| Kullanım Senaryosu | Kimler İçin Faydalı | Etki / ROI |
|---|---|---|
| Lead generation | Satış, İş Geliştirme | Potansiyel müşteri listesi oluşturmayı otomatikleştirir; temsilci başına haftada 8+ saat kazandırır (vaka çalışması) |
| Fiyat takibi | E-ticaret, Ürün Operasyonları | Rakipleri gerçek zamanlı izleme; bir kurumsal şirket yılda 3,8 milyon dolar tasarruf etti (kaynak) |
| Pazar araştırması | Pazarlama, Strateji, Finans | Yatırım danışmanlarının %67’si web’den kazınmış verileri kullanıyor; bazı durumlarda %890’a kadar ROI (kaynak) |
| Emlak veri toplama | Emlakçılar, Analistler | 50’den fazla ilan sayfasını saatler yerine dakikalar içinde kazıyın (kaynak) |
| Uyum takibi | Operasyon, Hukuk | İzlemeyi otomatikleştirir; bir sigorta şirketi 50 milyon dolarlık cezadan kurtuldu (kaynak) |
Ve unutmayalım: çalışanların %40’ından fazlası haftalarının dörtte birini veri toplama gibi tekrarlayan işlere harcıyor. Bunu web scraping ile otomatikleştirmek sadece hoş bir ek özellik değil, aynı zamanda rekabet avantajı.
Başlarken: Puppeteer Scraper’ınızı Kurma
Kolları sıvamaya hazır mısınız? Biraz JavaScript bilginiz varsa, Puppeteer’ı 10 dakikadan kısa sürede ayağa kaldırmanın yolu şöyle:
1. Node.js yükleyin
Puppeteer, Node.js üzerinde çalışır. En güncel LTS sürümünü adresinden indirin.
2. Yeni bir proje klasörü oluşturun
Terminali açın ve şunu çalıştırın:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteer’ı yükleyin
1npm install puppeteerBu işlem uyumlu bir Chromium sürümünü de indirecektir (yaklaşık 100 MB).
4. İlk script’inizi oluşturun
scrape.js adlı bir dosya oluşturun:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Sayfa başlığı:', title);
8 await browser.close();
9})();Bunu şu komutla çalıştırın:
1node scrape.js“Sayfa başlığı: Example Domain” görüyorsanız tebrikler — Chrome’u yeni otomatikleştirdiniz!
İlk Puppeteer Web Scraping Script’inizi Oluşturma
Biraz pratik yapalım. Diyelim ki sitesinden alıntıları kazımak istiyorsunuz (scraper’lar için demo site).
Adım 1: Sayfaya gidin
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Adım 2: Veriyi çekin
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Adım 3: Sayfalama işlemini yönetin
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Yukarıdaki gibi alıntıları çıkarın
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Adım 4: JSON olarak kaydedin
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Ve işte bu kadar — gezinip veri çıkaran, sayfalar arasında dolaşan ve veriyi kaydeden temel bir Puppeteer scraper’ınız oldu.
İleri Seviye Puppeteer Scraper Teknikleri: Dinamik İçerikle Başa Çıkma
Gerçek dünya sitelerinin çoğu statik bir liste kadar basit değildir. Zor kısımları nasıl aşacağınız şöyle:
1. Dinamik öğeleri beklemek
1await page.waitForSelector('.product-list-item');Bu, çekmek istediğiniz içeriğin gerçekten yüklenmesini sağlar.
2. Kullanıcı hareketlerini taklit etmek
- Bir butona tıklayın:
await page.click('#load-more'); - Bir alana yazın:
await page.type('#search', 'laptop'); - Sonsuz kaydırma için kaydırın:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Giriş işlemlerini yönetmek
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. AJAX ile yüklenen verilerle uğraşmak Bazen veri DOM içinde olmaz, bir API çağrısından gelir. Ağ yanıtlarını şöyle yakalayabilirsiniz:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Veriyi işle
5 }
6});Gerçek Dünya Örneği: Bir E-ticaret Sitesinden Ürün Verisi Kazımak
Şimdi bunların hepsini bir araya getirelim. Diyelim ki giriş yaptıktan sonra bir (demo) e-ticaret sitesinden ürün adlarını, fiyatları ve görselleri çekmek istiyorsunuz.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Adım 1: Giriş yap
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Adım 2: Kategori sayfasına git
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Adım 3: Ürünleri çıkar
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Adım 4: JSON olarak kaydet
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Bu script giriş yapar, gezinir, veri çıkarır ve kaydeder — hepsi otomatik olarak. Daha gelişmiş ihtiyaçlar için sayfalama döngüleri ekleyebilir ya da daha fazla ayrıntı için her bir ürüne tek tek tıklayabilirsiniz.
Thunderbit: Puppeteer Scraper’ı AI ile Daha Basit Hale Getirmek
Şimdi buraya kadar geldiyseniz ve “Bu güzel, ama her yeni veri seti için sürekli kod yazmak istemiyorum” diye düşünüyorsanız, yalnız değilsiniz. Thunderbit’i tam da bu yüzden geliştirdik: .
Thunderbit’i farklı kılan nedir?
- Kod gerekmez: Sadece yükleyin, kazımak istediğiniz sayfayı açın ve “AI Suggest Fields”e tıklayın.
- AI destekli alan tespiti: Thunderbit sayfayı okur ve çıkarılacak en iyi sütunları önerir — örneğin “Ürün Adı”, “Fiyat”, “Görsel” gibi.
- Dinamik içeriği yönetir: Sonsuz kaydırma, açılır pencereler ve alt sayfalar mı var? Thunderbit’in AI’ı bunları yönetebilir; sayfalar arasında tıklayarak ilerler, hatta verinizi zenginleştirmek için ürünün ayrıntı sayfasını ziyaret eder.
- Anında dışa aktarma: Verilerinizi tek tıklamayla Excel, Google Sheets, Notion veya Airtable’a gönderin. Dışa aktarma için ekstra ücret yok.
- Popüler siteler için şablonlar: Amazon, Zillow veya LinkedIn’i mi kazımanız gerekiyor? Thunderbit’in anında kullanıma hazır şablonları var — kurulum gerekmez.
- Bulut veya tarayıcıdan kazıma: Büyük işler için Thunderbit bulutta aynı anda 50 sayfaya kadar kazıyabilir.
Kullanıcıların “Keşke bu veriyi alabilsem” noktasından “İşte tablom” noktasına beş dakikadan kısa sürede geldiğini gördüm. Ve en iyi kısmı ne mi? Site değiştiğinde script’lerin kırılması konusunda artık endişelenmenize gerek yok — Thunderbit’in AI’ı anında uyum sağlar.
Puppeteer vs. Thunderbit: Doğru Web Scraping Aracını Seçmek
Peki hangisini kullanmalısınız? Ekipler için bunu şöyle ayırıyorum:
| Kriter | Puppeteer (Kod) | Thunderbit (Kodsuz, AI) |
|---|---|---|
| Kullanım Kolaylığı | JavaScript ve DOM bilgisi gerektirir | Tıkla-seç, AI alanları önerir |
| Kurulum Hızı | Karmaşık işler için saatlerden günlere kadar sürebilir | Dakikalar sürer — yükle ve başla |
| Kontrol / Esneklik | Maksimum: her türlü özel mantığı yazabilir, başka kodlarla entegre edebilirsiniz | Standart senaryolarda yüksek; son derece özelleştirilmiş iş akışları için daha az uygundur |
| Dinamik İçerik | Bekleme, tıklama, kaydırma için manuel script gerekir | Yerleşik AI; dinamik içerik, sayfalama ve alt sayfaları otomatik olarak yönetir |
| Bakım | Script’ler sizindir — site değiştikçe güncellemeniz gerekir | AI yerleşim değişikliklerine uyum sağlar; kullanıcı için daha az bakım yükü |
| Veri Dışa Aktarma | Kendi dışa aktarma mantığınızı yazarsınız | Excel, Sheets, Notion, Airtable, CSV, JSON’a tek tıkla aktarım |
| En Uygun Olduğu Durum | Geliştiriciler, yüksek derecede özelleştirilmiş veya büyük ölçekli kazımalar | İş kullanıcıları, hızlı teslim gereken projeler, teknik olmayan ekipler |
| Maliyet | Ücretsiz (zamanınız ve altyapı hariç) | Ücretsiz katman mevcut; kredi bazlı ücretli planlar (Thunderbit Fiyatlandırma) |
Kısacası:
- Tam kontrol, kodlama özgürlüğü veya scraping’i daha büyük bir uygulamaya gömme ihtiyacınız varsa Puppeteer kullanın.
- Hız, sadelik ve daha az bakım istiyorsanız ya da teknik olmayan ekip arkadaşlarınıza güç vermek istiyorsanız Thunderbit deneyin.
Açıkçası, ekiplerin ikisini birden kullandığını gördüm: hızlı kazanımlar ve prototipler için Thunderbit, derin entegrasyonlar ya da uç senaryolar için Puppeteer.
Adım Adım Kontrol Listesi: Başarılı Bir Puppeteer Web Scraping Projesi Yürütmek
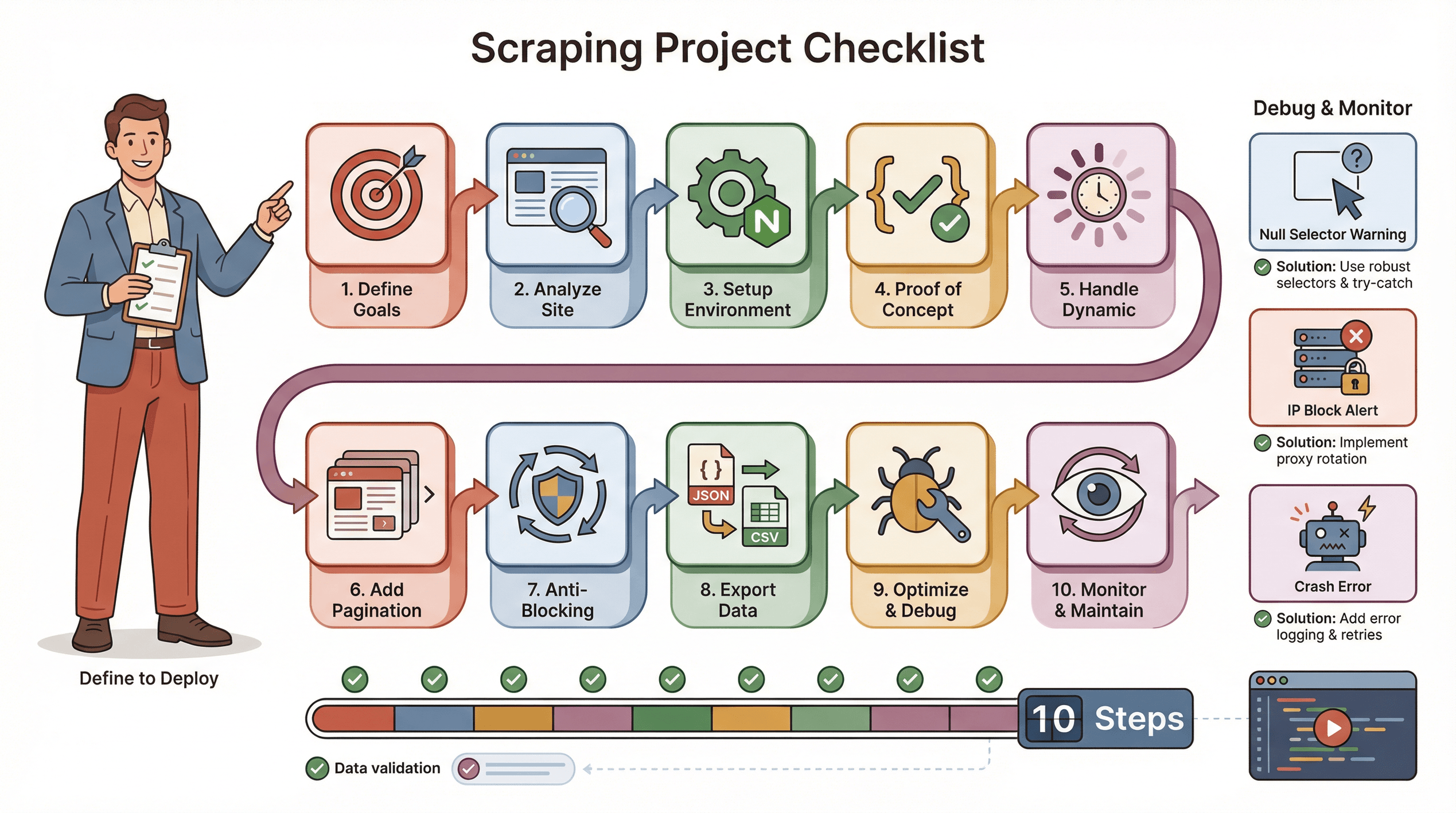 Sorunsuz bir Puppeteer scraping projesi için benim sık kullandığım kontrol listesi:
Sorunsuz bir Puppeteer scraping projesi için benim sık kullandığım kontrol listesi:
- Hedeflerinizi tanımlayın: Hangi verilere ihtiyacınız var? Nerede duruyor?
- Siteyi analiz edin: Dinamik mi? Giriş gerekiyor mu? Anti-bot önlemleri var mı?
- Ortamınızı kurun: Node.js, Puppeteer ve yardımcı kütüphaneler.
- Bir ön prototip yazın: Tek sayfayla başlayın, selector’ları doğru yakalayın.
- Dinamik içeriği yönetin: Gerekirse
waitForSelectorkullanın, tıklama/kaydırmayı taklit edin. - Sayfalama veya döngüler ekleyin: Sadece bir sayfayı değil, tüm sayfaları kazıyın.
- Engellenmeyi önleme taktikleri uygulayın: Gecikmeleri rastgeleleştirin, gerçek bir User-Agent ayarlayın, gerekirse proxy kullanın.
- Veriyi dışa aktarın ve doğrulayın: JSON/CSV olarak kaydedin, eksiksizliğini kontrol edin.
- Optimize edin ve hata yönetimi ekleyin: try/catch ekleyin, ilerlemeyi kaydedin, eksik verileri zarif şekilde yönetin.
- İzleyin ve bakım yapın: Siteler değişir — script’inizi güncellemeye hazır olun.
Sorun giderme ipuçları:
- Selector’lar
nulldöndürüyorsa HTML’i bir kez daha kontrol edin ve beklemeler ekleyin. - Engelleniyorsanız yavaşlayın, IP değiştirin ya da stealth eklentileri kullanın.
- Script’iniz çöküyorsa bellek sızıntılarını veya yakalanmamış istisnaları kontrol edin.
Sonuç ve Temel Çıkarımlar
Web scraping, veri odaklı ekipler için vazgeçilmez bir beceri haline geldi. Puppeteer, en dinamik ve JavaScript ağırlıklı sitelerden bile veri çekme gücü verir — ancak bunun için biraz kod yazma becerisi ve sürekli bakım gerekir. Kodu atlayıp doğrudan veriye ulaşmak isteyen iş kullanıcıları için Thunderbit, hızlı, esnek ve şaşırtıcı derecede sağlam bir AI destekli, kodsuz alternatif sunar.
Benim önerim şu olurdu:
- Teknikseniz ve derin özelleştirmeye ihtiyacınız varsa, Puppeteer ile başlayın.
- Hız, sadelik ve daha az bakım istiyorsanız, ’i deneyin ( başlamak için harika bir nokta).
- Çoğu ekip için ikisinin birleşimi, web verisi ihtiyaçlarının %99’unu karşılar.
Buna benzer daha fazla rehber görmek ister misiniz? Eğitimler, karşılaştırmalar ve AI destekli web scraping’in en yeni gelişmeleri için sayfasına göz atın.
SSS
1. Puppeteer scraper nedir ve web scraping için neden kullanılır?
Puppeteer, JavaScript ile headless Chrome tarayıcısını kontrol etmenizi sağlayan bir Node.js kütüphanesidir. Dinamik içeriği yükleyebildiği, kullanıcı hareketlerini taklit edebildiği ve geleneksel scraper’ların başa çıkamadığı sitelerden veri çekebildiği için web scraping’de kullanılır.
2. Puppeteer, Selenium ve Thunderbit ile nasıl karşılaştırılır?
Selenium birden fazla tarayıcı ve dil ile çalışır ama daha ağırdır. Puppeteer, Chrome/Node.js için daha akıcıdır ve birçok scraping işinde daha hızlıdır. Thunderbit ise teknik olmayan kullanıcıların yalnızca birkaç tıklamayla veri çekmesini sağlayan kodsuz, AI destekli bir araçtır.
3. Puppeteer ile web scraping’in başlıca iş avantajları nelerdir?
Veri toplama sürecini otomatikleştirmek zaman kazandırır, hataları azaltır ve satış, pazarlama, operasyon ve daha fazlası için gerçek zamanlı içgörüler sağlar. Kullanım alanları lead generation’dan fiyat takibine ve pazar araştırmasına kadar uzanır.
4. Puppeteer scraping’de en büyük zorluklar nelerdir?
Başlıca zorluklar dinamik içeriği yönetmek, anti-bot engellerinden kaçınmak ve siteler değiştiğinde script’leri güncel tutmaktır. Beklemeleri yönetmek, etkileşimleri taklit etmek ve hataları ele almak için kod yazmanız gerekir.
5. Puppeteer yerine ne zaman Thunderbit kullanmalıyım?
Kod yazmayı atlamak, sonuçları hızlı almak veya teknik olmayan ekip arkadaşlarınızı güçlendirmek istiyorsanız Thunderbit kullanın. Standart scraping işleri, hızlı teslim gereken projeler veya veriyi minimum uğraşla Excel ya da Google Sheets’e aktarmak istediğiniz durumlar için idealdir.
Daha akıllı bir scraping yöntemi denemeye hazır mısınız? ya da üzerindeki daha fazla rehbere göz atın. Keyifli scraping’ler!
Daha Fazla Bilgi