

เว็บในปี 2026 มีขนาดใหญ่ ซับซ้อน และเต็มไปด้วยโอกาสมากกว่าที่เคย—and ถ้าคุณทำงานด้านขายหรือการตลาด คุณย่อมรู้ดีว่า “ทองคำ” ไม่ได้อยู่แค่ในเว็บไซต์ของคุณเอง แต่อยู่ในข้อมูลที่ดึงมาจากแหล่งอื่นได้ด้วย ผมเห็นมากับตาว่า ข้อมูลที่ใช่ ในเวลาที่ใช่ สามารถเป็นตัวตัดสินได้เลยว่าจะปิดดีลได้หรือพลาดโอกาสไป แต่เอาเข้าจริง ใครก็ไม่อยากเสียเวลาหลายชั่วโมงกับการก็อปปี้-วางข้อมูลลีดหรือราคาจากเว็บเป็นสิบ ๆ แห่ง นี่จึงเป็นเหตุผลที่ระบบอัตโนมัติกำลังมาแรง และทำไมคำว่า “Zapier web scraping” ถึงกลายเป็นหัวข้อที่ทีมงานสายทำงานฉลาด ไม่ทำงานหนัก ให้ความสนใจมากขึ้นเรื่อย ๆ
แต่มีจุดที่น่าสนใจอยู่คือ แม้ Zapier จะกลายเป็นเครื่องมืออัตโนมัติแบบ no-code ตัวเลือกแรก ๆ สำหรับผู้ใช้หลายล้านคน แต่ความสามารถด้านการดึงข้อมูลจากเว็บของมันก็ไม่ได้วิเศษอย่างที่หลายคนคาดหวัง ข่าวดีก็คือ เมื่อมีเครื่องมือที่ขับเคลื่อนด้วย AI อย่าง Thunderbit เข้ามา คุณสามารถรวมข้อดีของทั้งสองโลกเข้าด้วยกันได้—ทั้งการดึงข้อมูลอย่างชาญฉลาดและการเชื่อมเวิร์กโฟลว์อัตโนมัติที่ลื่นไหล ในคู่มือนี้ ผมจะพาคุณไล่ดูแบบชัด ๆ ว่าในปี 2026 จะใช้ Zapier เพื่อ web scraping อย่างไร มีข้อจำกัดตรงไหน และจะยกระดับระบบอัตโนมัติของคุณด้วย Thunderbit ได้อย่างไร ไม่ว่าคุณจะเป็นเซลส์ นักการตลาด หรือแค่เบื่อการคีย์ข้อมูลเอง มาลุยกันเลย
Zapier Web Scraping คืออะไร และทำไมจึงสำคัญในปี 2026?
เริ่มจากพื้นฐานก่อน Zapier web scraping คือการใช้ Zapier—แพลตฟอร์ม automation แบบ no-code ชั้นนำของโลก—เพื่อทำให้การเก็บและส่งต่อข้อมูลจากเว็บเข้าไปยังเครื่องมือธุรกิจของคุณเป็นอัตโนมัติ Zapier เชื่อมต่อได้กับ แอปมากกว่า 7,000 แอป (เช่น Google Sheets, HubSpot, Slack, Salesforce และอื่น ๆ) ทำให้คุณสร้าง “Zaps” ที่จะเริ่มทำงานเมื่อมีบางอย่างเกิดขึ้น (เช่น มีแถวใหม่ในสเปรดชีต) แล้วสั่งให้ทำงานต่อ (เช่น ส่งอีเมลหรืออัปเดต CRM)
แต่ประเด็นคือ: Zapier ไม่ได้มีตัวดึงข้อมูลจากเว็บในตัวแบบจริงจัง มันทำหน้าที่เป็นตัวกลางเชื่อมข้อมูลที่ถูกดึงมาจากเว็บ—มักมาจากเครื่องมือภายนอกหรือ API—ไปยังปลายทางที่คุณต้องการ ตัวอย่างเช่น คุณอาจใช้ Chrome extension หรือ scraper ที่ขับเคลื่อนด้วย AI เพื่อดึงลีดจากไดเรกทอรี ส่งออกไปยัง Google Sheets แล้วให้ Zapier เพิ่มข้อมูลเข้า CRM ให้อัตโนมัติ
แล้วทำไมเรื่องนี้ถึงสำคัญมากในปี 2026? เพราะความต้องการด้านการเก็บข้อมูลแบบอัตโนมัติกำลังพุ่งสูง ตลาด web scraping ทั่วโลกคาดว่าจะแตะ 1.17 พันล้านดอลลาร์ในปี 2026 ขณะที่ตลาด AI-driven scraping เพียงอย่างเดียวก็โตถึง 10.2 พันล้านดอลลาร์ ทีมขายและการตลาดถูกกดดันให้ทำได้มากขึ้นด้วยทรัพยากรที่น้อยลง และการคีย์ข้อมูลด้วยมือก็เป็นตัวทำลายประสิทธิภาพชั้นดี—ทำให้ธุรกิจสูญเสียได้สูงถึง 28,500 ดอลลาร์ต่อพนักงานต่อปี และกินเวลาไปกว่า 9 ชั่วโมงต่อสัปดาห์ กับงานซ้ำ ๆ
 Zapier web scraping จึงสำคัญ เพราะมันช่วยให้คนที่ไม่ใช่สายเทคนิคสามารถทำงานอัตโนมัติได้ ช่วยคืนเวลาให้ทีมไปโฟกัสกับการขายและการตลาดจริง ๆ ในความเป็นจริง ทีมขายที่ทำงานซ้ำ ๆ แบบ manual ให้เป็นอัตโนมัติ จะประหยัดเวลาได้เฉลี่ย 6 ชั่วโมงต่อสัปดาห์ต่อหนึ่งคน และการตลาดแบบอัตโนมัติให้ผลตอบแทน 544% ROI ใน 3 ปี
Zapier web scraping จึงสำคัญ เพราะมันช่วยให้คนที่ไม่ใช่สายเทคนิคสามารถทำงานอัตโนมัติได้ ช่วยคืนเวลาให้ทีมไปโฟกัสกับการขายและการตลาดจริง ๆ ในความเป็นจริง ทีมขายที่ทำงานซ้ำ ๆ แบบ manual ให้เป็นอัตโนมัติ จะประหยัดเวลาได้เฉลี่ย 6 ชั่วโมงต่อสัปดาห์ต่อหนึ่งคน และการตลาดแบบอัตโนมัติให้ผลตอบแทน 544% ROI ใน 3 ปี
Zapier Web Scraping ช่วยให้ทำงานอัตโนมัติได้อย่างไร: เวิร์กโฟลว์แบบทีละขั้น
ดึงข้อมูลเว็บด้วย AI ได้ใน 2 คลิก Get Started Free
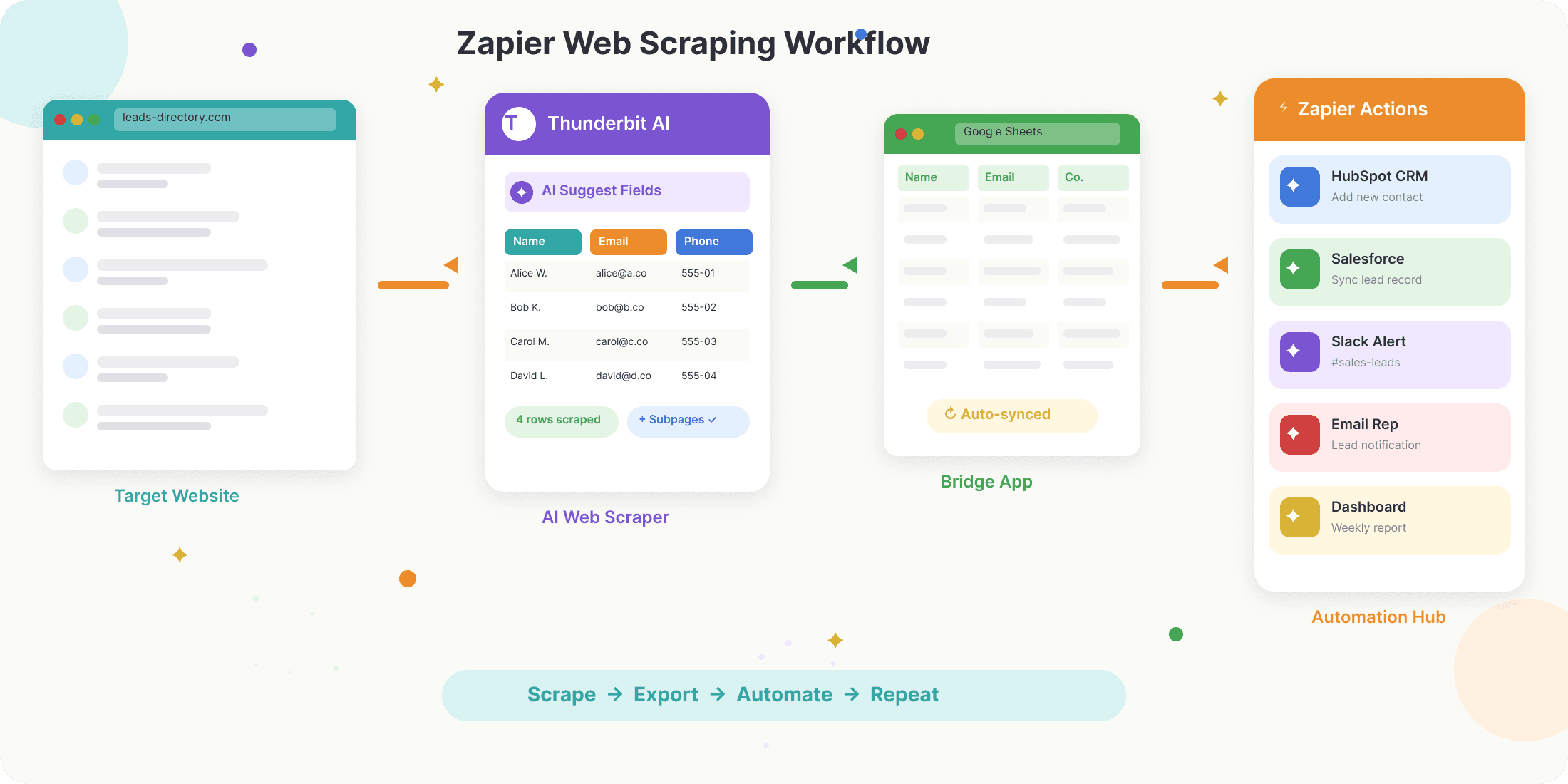
แล้วเวิร์กโฟลว์ Zapier web scraping แบบจริง ๆ หน้าตาเป็นอย่างไร? ภาพรวมจะประมาณนี้:
- ดึงข้อมูลจากเว็บ: ใช้ Chrome extension (เช่น Thunderbit), API (เช่น Apify หรือ Browse AI) หรือเครื่องมือของบุคคลที่สามเพื่อดึงข้อมูลจากเว็บไซต์เป้าหมาย
- ส่งออกข้อมูลไปยังแอป “ตัวกลาง”: โดยมากจะส่งออกไปยัง Google Sheets, Airtable หรือ Notion ซึ่งเป็นแพลตฟอร์มที่ Zapier ตรวจจับการเปลี่ยนแปลงได้ง่าย
- ตั้ง Trigger ใน Zapier: สร้าง Zap ใหม่ให้ทำงานเมื่อมีแถวใหม่ถูกเพิ่มเข้ามาในสเปรดชีต
- ตั้งค่าการทำงานต่อเนื่อง: เพิ่มขั้นตอนใน Zap เพื่อส่งข้อมูลไปยัง CRM, อีเมล, Slack หรือแอปอีกกว่า 7,000 รายการ
ตารางด้านล่างเป็นตัวอย่าง flow อัตโนมัติที่ทีมขายและการตลาดใช้กันบ่อย:
| กรณีใช้งาน | เครื่องมือดึงข้อมูล | แอปตัวกลาง | Trigger ใน Zapier | การทำงาน |
|---|---|---|---|---|
| สร้างลีด | Thunderbit | Google Sheets | มีแถวใหม่ในสเปรดชีต | เพิ่มเข้า HubSpot CRM |
| ติดตามราคา | Apify | Airtable | มีเรคคอร์ดใหม่ | ส่งแจ้งเตือนผ่าน Slack |
| รวมคอนเทนต์ | Browse AI | Notion | มีไอเท็มใหม่ในฐานข้อมูล | ส่งอีเมลสรุป |
| ติดตามคู่แข่ง | ScrapingBee | Google Sheets | มีแถวใหม่ | อัปเดต Salesforce |
แพทเทิร์น “ดึง → ส่งออก → ทำงานอัตโนมัติ” แบบนี้คือแกนหลักของเวิร์กโฟลว์ข้อมูล no-code สมัยใหม่
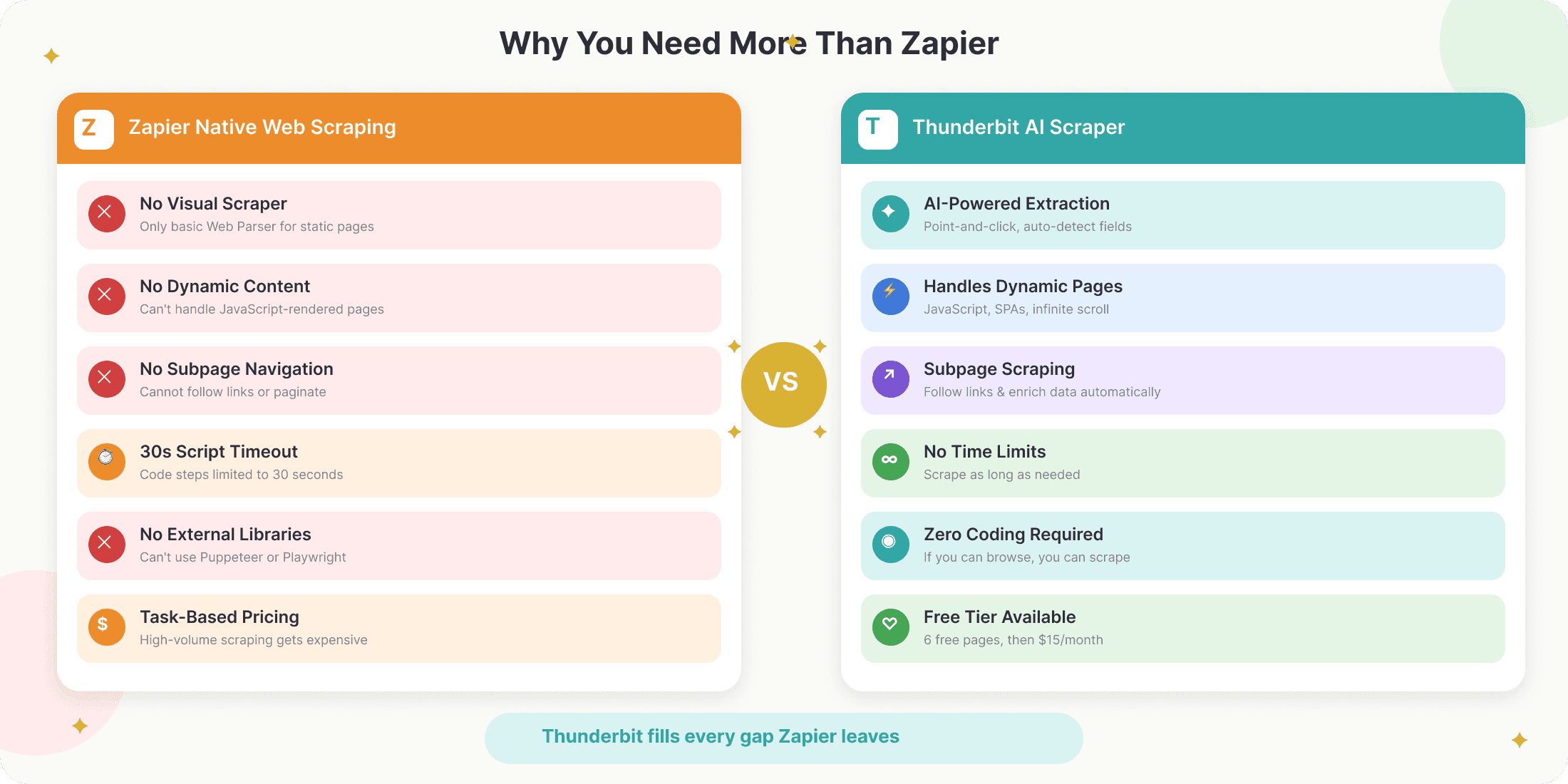
ข้อจำกัดสำคัญของ Zapier Web Scraping ในปี 2026
ก่อนจะตื่นเต้นเกินไป มาพูดถึงข้อจำกัดกันตรง ๆ: web scraping แบบ built-in ของ Zapier ยังจำกัดอยู่มาก สิ่งที่ควรรู้มีดังนี้:
- ไม่มี Visual Scraper: “Web Parser” ของ Zapier ดึงได้แค่เนื้อหาหลักจากหน้าเว็บแบบสแตติก เช่น บทความบล็อก ไม่เหมาะกับข้อมูลที่มีโครงสร้าง ตาราง หรือรายการสินค้า
- รับมือคอนเทนต์แบบ dynamic ไม่ได้: ถ้าเว็บโหลดข้อมูลผ่าน JavaScript (เช่น infinite scroll, pop-up หรือ table แบบโต้ตอบได้) parser ของ Zapier จะไม่เห็นข้อมูลเหล่านั้น
- ข้อจำกัดของ Code Step: แม้ Zapier จะให้รัน Python หรือ JavaScript ได้ แต่คุณติดตั้ง external libraries ไม่ได้ และสคริปต์ถูกจำกัดแค่ 30 วินาที กับ RAM 512 MB ทำให้ใช้ headless browser อย่าง Puppeteer หรือ Playwright ไม่ได้
- ไม่รองรับ subpage หรือ pagination: Zapier ไม่สามารถไล่ลิงก์ไปยังหน้าย่อยหรือเก็บข้อมูลหลายหน้าแบบ native ได้
- คิดค่าบริการตามจำนวน task: ทุก action ใน Zap จะถูกนับเป็น “task” ดังนั้นถ้า scraping ปริมาณมาก ค่าใช้จ่ายจะพุ่งเร็วมาก
- เวิร์กโฟลว์แบบเส้นตรง: Zaps ทำงานเป็นลำดับตรง ๆ การแตกแขนงหรือเงื่อนไขซับซ้อนยังสู้เครื่องมืออย่าง Make หรือ n8n ไม่ได้
สรุปสั้น ๆ: Zapier เหมาะมากกับการทำงานอัตโนมัติ “หลังจาก” คุณได้ข้อมูลมาแล้ว แต่ไม่ได้ถูกออกแบบมาให้เป็นตัวทำ scraping หนัก ๆ ด้วยตัวเอง ถ้าเกินกว่าการดึงบทความพื้นฐาน คุณจะต้องมี scraper เฉพาะทาง
ยกระดับ Zapier Web Scraping ด้วย Thunderbit: พลังของการเชื่อมต่อกัน
ตรงนี้แหละที่ Thunderbit เข้ามาเติมเต็ม Thunderbit คือ Chrome extension สำหรับ web scraping ที่ขับเคลื่อนด้วย AI และออกแบบมาสำหรับผู้ใช้ธุรกิจ—ไม่ต้องเขียนโค้ด ไม่ต้องมีเทมเพลต แค่ 2 คลิกก็ดึงข้อมูลแบบมีโครงสร้างจากเว็บไซต์ไหนก็ได้
Thunderbit ช่วยปิดช่องว่างเหล่านี้ได้อย่างไร:
- ดึงข้อมูลด้วย AI: คลิก “AI Suggest Fields” แล้ว Thunderbit จะอ่านหน้าเว็บ แนะนำคอลัมน์ เช่น ชื่อ อีเมล ราคา ฯลฯ และดึงข้อมูลให้อัตโนมัติ—ไม่ต้องตั้งค่า
- รับมือหน้าเว็บ dynamic และซับซ้อนได้: AI ของ Thunderbit สามารถดึงข้อมูลจากเว็บที่ใช้ JavaScript หนัก ๆ จัดการ pagination และแม้แต่เข้าไปตาม subpage เพื่อเพิ่มความสมบูรณ์ของชุดข้อมูล
- ไม่ต้องเขียนโค้ด: ทุกอย่างเป็นแบบคลิกเลือก ถ้าคุณใช้เบราว์เซอร์เป็น คุณก็ใช้ Thunderbit ได้
- ส่งออกได้ทุกที่: ส่งออกข้อมูลที่ดึงได้ไปยัง Google Sheets, Airtable, Notion, Excel หรือ CSV ได้ทันที ทำให้พร้อมใช้กับ Zapier
- ตั้งเวลาสแกนซ้ำได้: กำหนดให้ดึงข้อมูลซ้ำเป็นรอบ ๆ ได้เป็นภาษาง่าย ๆ เช่น ทุกชั่วโมง ทุกวัน หรือทุกสัปดาห์ เพื่อให้ข้อมูลสดใหม่เสมอโดยไม่ต้องลงมือเอง
ความมหัศจรรย์เกิดขึ้นเมื่อคุณเอาพลังการดึงข้อมูลของ Thunderbit มารวมกับพลัง automation ของ Zapier Thunderbit จัดการเก็บข้อมูล ส่วน Zapier ส่งต่อข้อมูลไปยังทุกที่ที่คุณต้องการ
คู่มือทีละขั้น: ทำให้การเก็บข้อมูลเว็บเป็นอัตโนมัติด้วย Zapier และ Thunderbit
มาดู workflow จริงกันแบบไม่ใช้ศัพท์เทคนิคเยอะ เน้นทำตามได้เลย
1. ดึงข้อมูลด้วย Thunderbit
- ติดตั้ง Thunderbit Chrome Extension (เริ่มใช้ฟรีได้)
- เข้าไปยังเว็บไซต์เป้าหมายของคุณ (เช่น ไดเรกทอรีของลีดที่ต้องการ)
- คลิกไอคอน Thunderbit แล้วเลือก “AI Suggest Fields” ให้ AI ช่วยตรวจจับว่ามีข้อมูลอะไรบนหน้าเว็บบ้าง
- ปรับคอลัมน์ถ้าจำเป็น แล้วกด “Scrape” Thunderbit จะดึงข้อมูลและแสดงในตาราง
- ถ้าต้องการข้อมูลเพิ่ม ใช้ “Scrape Subpages” เพื่อเข้าไปตามลิงก์แต่ละหน้าและเสริมข้อมูลให้ครบขึ้น (เช่น ดึงอีเมลจากหน้าบริษัท)
2. ส่งออกข้อมูลไปยัง Google Sheets
- ใน Thunderbit ให้คลิก “Export” แล้วเลือก Google Sheets
- ล็อกอินและเลือกสเปรดชีตปลายทาง
- Thunderbit จะใส่ข้อมูลที่ดึงมาให้ในชีต พร้อมให้ Zapier นำไปใช้งานต่อ
3. สร้าง Zap ใน Zapier
- ล็อกอินเข้า Zapier
- สร้าง Zap ใหม่โดยใช้ trigger “New Spreadsheet Row in Google Sheets”
- เชื่อมบัญชี Google และเลือกชีตที่ Thunderbit กำลังอัปเดตอยู่
4. เพิ่ม Action เพื่อทำงานอัตโนมัติ
- เพิ่มขั้นตอนเพื่อส่งข้อมูลไปยัง CRM ของคุณ (เช่น HubSpot, Salesforce), อีเมล, Slack หรือที่ไหนก็ตามที่ต้องใช้
- ใช้ Formatter หรือ Filter ของ Zapier เพื่อทำความสะอาดหรือยืนยันข้อมูลก่อนส่งต่อ
- ทดสอบ Zap เพื่อให้แน่ใจว่าทุกอย่างไหลลื่นตามที่คาด

5. ตั้งเวลาและติดตามผล
- ถ้าคุณต้องการข้อมูลใหม่เป็นประจำ ให้ตั้ง scheduled scrape ใน Thunderbit เช่น “ทุกวันเวลา 9 โมงเช้า”
- Zapier จะประมวลผลแถวใหม่โดยอัตโนมัติเมื่อเข้ามา ไม่ต้องทำเอง
เคล็ดลับเพิ่มประสิทธิภาพ:
- แบ่งการดึงข้อมูลเป็นรอบ ๆ เพื่อลดโอกาสชนกับ task limit ของ Zapier
- ตั้งแจ้งเตือน error ใน Zapier ผ่าน Slack หรืออีเมล เพื่อจับปัญหาให้ไว
- ถ้าเวิร์กโฟลว์มีปริมาณสูง ลองอัปเกรดแพ็กเกจ Zapier หรือรวมข้อมูลเป็นชุดก่อนอัปเดต
ตัวอย่างจริง: ใช้ Zapier Web Scraping เพื่อปรับปรุงการติดตามลีดขาย
ลองใส่ลงในสถานการณ์ธุรกิจจริง สมมติว่าคุณเป็นผู้จัดการฝ่ายขายของบริษัท SaaS และต้องการติดตามลีดใหม่จากไดเรกทอรีในอุตสาหกรรมนิชที่ไม่มี API
วิธีเดิม: คุณหรือทีมต้องใช้เวลาหลายชั่วโมงทุกสัปดาห์ในการคัดลอกชื่อ อีเมล และข้อมูลบริษัทลงสเปรดชีต แล้วค่อยอัปเดต CRM เองทีละรายการ
วิธีใหม่ด้วย Thunderbit + Zapier:
- Thunderbit ดึงข้อมูลจากไดเรกทอรี—รวมถึง subpage ที่มีอีเมลตรงและโปรไฟล์ LinkedIn
- ส่งออกข้อมูลไปยัง Google Sheets—ข้อมูลเป็นระเบียบ สะอาด และอัปเดตอยู่เสมอ
- Zapier เฝ้าดูแถวใหม่—ลีดใหม่แต่ละรายการจะกระตุ้น workflow ทันที
- เพิ่มลีดเข้า HubSpot CRM อัตโนมัติ กำหนดผู้รับผิดชอบ และส่งแจ้งเตือนผ่าน Slack ไปยังทีม
- ส่งอีเมลสรุปรายสัปดาห์ ไปยังผู้บริหาร และไฮไลต์ลีดที่มีมูลค่าสูงเพื่อให้ติดตามต่อ
ผลลัพธ์ล่ะ? ทีมต่าง ๆ รายงานว่าสามารถประหยัดเวลาได้ มากกว่า 6 ชั่วโมงต่อสัปดาห์ต่อคน, เก็บ ลีดคุณภาพสูงได้เพิ่มขึ้น 40%, และเพิ่มอัตราการปิดการขายขึ้น 15–25% บริษัทบริการทางการเงินแห่งหนึ่งเห็น ROI 70% และ อัตรา conversion ของลีดเพิ่มขึ้น 40% หลังทำให้ pipeline การหาลีดเป็นอัตโนมัติ (browsercat.com)
เปรียบเทียบ Zapier, Thunderbit และโซลูชัน web scraping อื่น ๆ สำหรับ automation
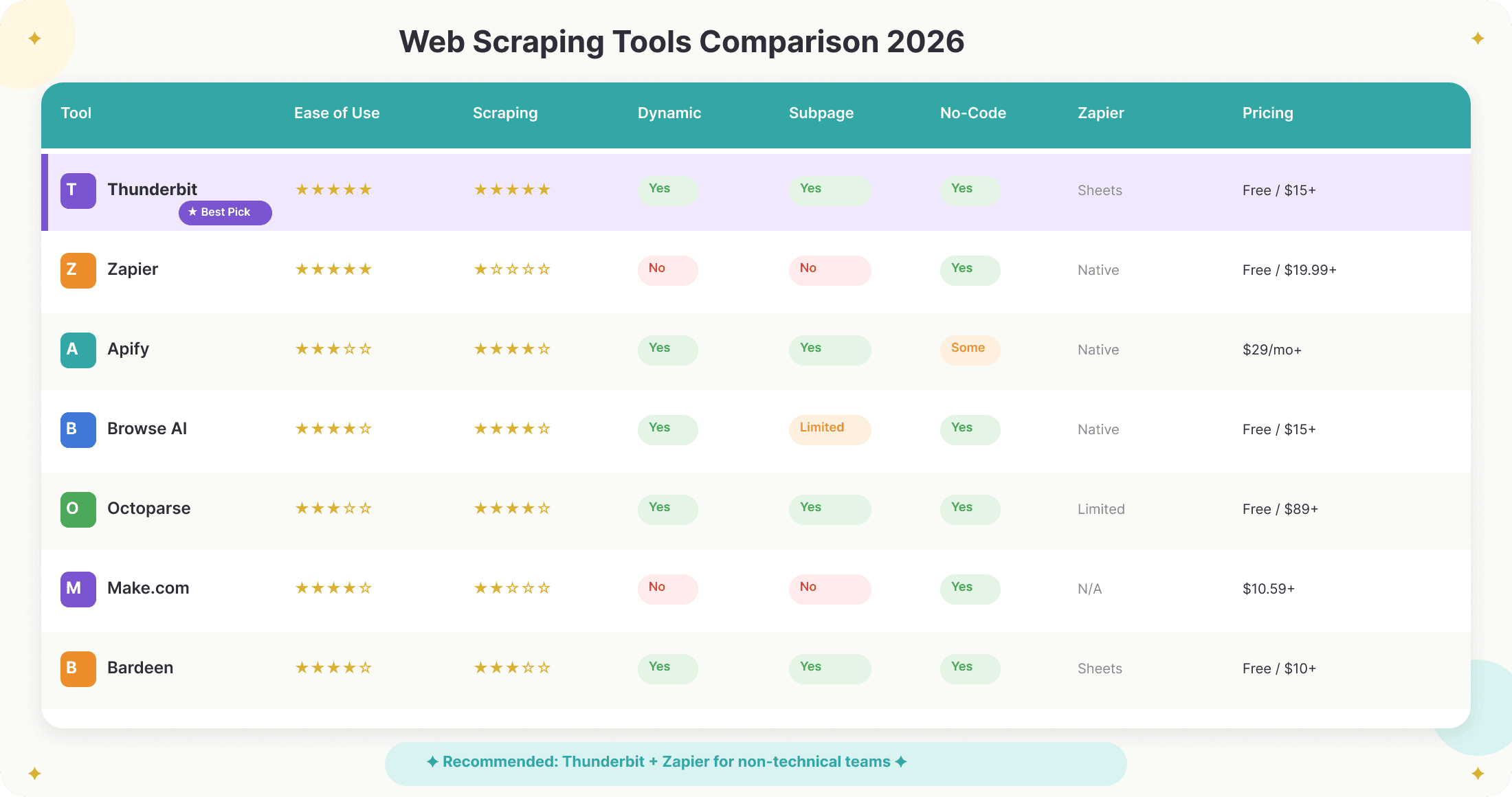
 นี่คือภาพรวมว่าเครื่องมือชั้นนำทำงานได้ดีแค่ไหนสำหรับ automation ทางธุรกิจในปี 2026:
นี่คือภาพรวมว่าเครื่องมือชั้นนำทำงานได้ดีแค่ไหนสำหรับ automation ทางธุรกิจในปี 2026:
| เครื่องมือ | ใช้งานง่าย | พลังการดึงข้อมูล | รองรับหน้า dynamic | ดึง subpage | No-code | เชื่อมกับ Zapier | ราคา |
|---|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ใช่ | ใช่ | ใช่ | ผ่าน Sheets/Airtable | ฟรี (6 หน้า), เริ่ม $15/เดือน |
| Zapier (native) | ⭐⭐⭐⭐⭐ | ⭐ | ไม่ได้ | ไม่ได้ | ใช่ | — | ฟรี (100 tasks), เริ่ม $19.99/เดือน |
| Apify | ⭐⭐⭐ | ⭐⭐⭐⭐ | ใช่ | ใช่ | บางส่วน | Native | เริ่ม $29/เดือน |
| Browse AI | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ใช่ | จำกัด | ใช่ | Native | ฟรี (50 credits), เริ่ม $15/เดือน |
| Octoparse | ⭐⭐⭐ | ⭐⭐⭐⭐ | ใช่ | ใช่ | ใช่ | จำกัด | ฟรี, เริ่ม $89/เดือน |
| Make.com | ⭐⭐⭐⭐ | ⭐⭐ | ไม่ได้ | ไม่ได้ | ใช่ | Native | เริ่ม $10.59/เดือน |
| Bardeen | ⭐⭐⭐⭐ | ⭐⭐⭐ | ใช่ | ใช่ | ใช่ | ผ่าน Sheets | ฟรี, เริ่ม $10/เดือน |
คำแนะนำ:
- สำหรับผู้ใช้ที่ไม่ใช่สายเทคนิค แต่ต้องการ scraping ที่เร็ว เชื่อถือได้ และยืดหยุ่น พร้อม automation ที่ตั้งค่าง่าย Thunderbit + Zapier คือจุดที่ลงตัวที่สุด
- สำหรับทีมที่มีนักพัฒนาเยอะ หรือมีงาน scraping ปริมาณสูงและซับซ้อน Apify หรือ Octoparse อาจเหมาะกว่า แต่จะต้องใช้เวลาเซ็ตอัปมากขึ้น
- ถ้าต้องการ scraping และ automation บนเบราว์เซอร์ Bardeen ก็เป็นทางเลือกที่ดี แต่หลายครั้งก็ยังต้องพึ่ง Zapier สำหรับ workflow ช่วงปลายทาง
อนาคตของ Zapier Web Scraping: No-code, AI และเทรนด์ automation ในปี 2026
คลื่นลูกต่อไปของ automation คือเรื่องของ AI agents และการ orchestration แบบ no-code ภายในสิ้นปี 2026 40% ของแอปองค์กรจะมี AI agent เฉพาะงาน เพิ่มขึ้นจากไม่ถึง 5% ในปี 2025 ตอนนี้ Zapier ก็เดินหน้าเร็วมาก ทั้งการปล่อย AI Actions, Copilot และ autonomous Agents ที่ให้ผู้ใช้บรรยาย workflow เป็นภาษาธรรมดา แล้วให้แพลตฟอร์มสร้างให้โดยอัตโนมัติ
ในขณะเดียวกัน scraper ที่ขับเคลื่อนด้วย AI อย่าง Thunderbit ก็กำลังทำให้การดึงข้อมูลทนทานและเข้าถึงง่ายขึ้น ไม่ต้องมานั่งพะวงกับ CSS selector ที่เปราะบางอีกต่อไป—แค่บอก AI ว่าคุณต้องการอะไร แล้วระบบก็จัดการส่วนที่เหลือให้ Self-healing scrapers, การดึงข้อมูลแบบอาศัยภาพ (vision-based extraction) และ automation แบบตั้งเวลา กำลังกลายเป็นมาตรฐาน
แล้วสิ่งนี้หมายความว่าอย่างไรสำหรับผู้ใช้ธุรกิจ?
- 80% ของผลิตภัณฑ์ด้านเทคโนโลยีจะถูกสร้างโดยคนที่ไม่ใช่นักพัฒนาในปี 2026 (Gartner)
- ทีมที่ขับเคลื่อนด้วยข้อมูลมีโอกาสหาลูกค้าได้มากกว่า 23 เท่า และ มีกำไรมากกว่า 19 เท่า
- การผสาน AI scraping เข้ากับ no-code automation กำลังเปิดโอกาสทางธุรกิจใหม่ ๆ ตั้งแต่ dynamic pricing ไปจนถึง real-time lead gen และการวิจัยตลาดในวงกว้าง
สรุปง่าย ๆ คือ ถ้าคุณยังไม่ทำให้เวิร์กโฟลว์ข้อมูลจากเว็บเป็นอัตโนมัติ คุณกำลังปล่อยทั้งเงินและเวลาให้หลุดมือไปโดยเปล่าประโยชน์
บทสรุปและประเด็นสำคัญ
Zapier web scraping กำลังเปลี่ยนวิธีที่ทีมขายและการตลาดทำงานในปี 2026 แต่จะได้ผลก็ต่อเมื่อจับคู่กับเครื่องมือที่เหมาะสม Zapier เก่งในการทำงานอัตโนมัติหลังจากคุณมีข้อมูลแล้ว แต่ไม่เหมาะกับงานหนักของการดึงข้อมูลจากเว็บด้วยตัวเอง นั่นคือจุดที่ Thunderbit เข้ามา ด้วยการดึงข้อมูลแบบ no-code ที่ขับเคลื่อนด้วย AI ซึ่งใคร ๆ ก็ใช้ได้
สรุปสำคัญ:
- Zapier คือแกนกลางของ automation สำหรับธุรกิจกว่า 3.4 ล้านแห่ง แต่ความสามารถด้าน web scraping ยังจำกัดอยู่ที่ parsing ขั้นพื้นฐานหรือการเชื่อมต่อเครื่องมือภายนอก
- Thunderbit เติมเต็มช่องว่าง ด้วยการดึงข้อมูลแบบใช้ AI ใน 2 คลิก รองรับหน้า dynamic, subpage และงานตามเวลา โดยไม่ต้องเขียนโค้ด
- เวิร์กโฟลว์ที่ดีที่สุด: ดึงด้วย Thunderbit → ส่งออกไป Google Sheets/Airtable → ทำ automation ด้วย Zapier
- ผลลัพธ์: ทีมประหยัดเวลา เพิ่มคุณภาพลีด และสร้าง ROI ที่วัดผลได้—บางอุตสาหกรรมสูงถึง 70%
- อนาคตคือ AI + no-code: ภายในปี 2026 งาน automation ส่วนใหญ่ในธุรกิจจะถูกสร้างโดยคนที่ไม่ใช่นักพัฒนา โดยมี AI agent และ scraper อัจฉริยะที่ทนทานเป็นแรงขับเคลื่อน
พร้อมเลิกคีย์ข้อมูลเองและปลดล็อกพลังของเวิร์กโฟลว์ข้อมูลจากเว็บแบบอัตโนมัติแล้วหรือยัง? ดาวน์โหลด Thunderbit ตั้งค่า Zap แรกของคุณ แล้วดูว่า automation จะง่ายแค่ไหนในปี 2026 และถ้าอยากได้เคล็ดลับเพิ่มเติม ลองอ่าน Thunderbit Blog
ลองใช้ AI Web Scraper Get Started Free
คำถามที่พบบ่อย
1. Zapier ดึงข้อมูลจากทุกเว็บไซต์ได้โดยตรงไหม?
ไม่ได้ Zapier ไม่มี visual web scraper ในตัว มันทำได้แค่ parse เนื้อหาสแตติกพื้นฐานผ่าน Web Parser หรือเชื่อมกับเครื่องมือ scraping ภายนอก สำหรับข้อมูลที่มีโครงสร้างหรือเป็น dynamic ควรใช้ scraper เฉพาะทางอย่าง Thunderbit แล้วส่งออกไป Google Sheets ให้ Zapier จัดการต่อ
2. ข้อจำกัดหลักของ Zapier web scraping คืออะไร?
Zapier รับมือหน้าเว็บที่เรนเดอร์ด้วย JavaScript, การตามลิงก์ไป subpage หรือการดึงข้อมูลที่ซับซ้อนไม่ได้ code step จำกัดแค่ 30 วินาทีและ RAM 512 MB และไม่สามารถใช้ external libraries ได้ นอกจากนี้ ถ้าสแครปปริมาณมาก ค่าใช้จ่ายจะสูงเพราะคิดตามจำนวน task
3. Thunderbit เชื่อมกับ Zapier อย่างไร?
Thunderbit ดึงข้อมูลจากเว็บไซต์ใดก็ได้แล้วส่งออกโดยตรงไปยัง Google Sheets, Airtable หรือ Notion จากนั้น Zapier จะ trigger เมื่อมีแถวใหม่ในแพลตฟอร์มเหล่านี้ เพื่อทำงานต่อ เช่น เพิ่มลีดเข้า CRM ส่งแจ้งเตือน หรืออัปเดตแดชบอร์ด
4. วิธีที่ดีที่สุดในการทำให้การติดตามลีดขายอัตโนมัติด้วย Zapier และ web scraping คืออะไร?
ใช้ Thunderbit ดึงลีดจากเว็บไซต์เป้าหมาย ส่งออกไป Google Sheets แล้วตั้ง Zap ให้เพิ่มลีดใหม่เข้า CRM และแจ้งทีมของคุณ ตั้งเวลาสแกนซ้ำใน Thunderbit เพื่อให้มีข้อมูลใหม่อยู่เสมอ
5. ปี 2026 ควรจับตาเทรนด์อะไรใน automation ด้าน web scraping?
ให้จับตา scraper ที่ขับเคลื่อนด้วย AI และ self-healing, เครื่องมือสร้าง workflow แบบ no-code และ agentic AI ที่จัดการ automation หลายขั้นตอนได้ อนาคตคือเรื่องของความทนทาน การเข้าถึงง่าย และการผสาน scraping เข้ากับกระบวนการธุรกิจอย่างไร้รอยต่อ
อ่านเพิ่มเติม
- 10 อันดับซอฟต์แวร์ Web Scraper ที่ดีที่สุดในปี 2026
- วิธีเริ่มต้นสอนดึงข้อมูลเว็บด้วย Thunderbit
- 10 อันดับ AI Web Scraping Tools ที่ช่วยเพิ่มประสิทธิภาพในปี 2026
- 9 อันดับ No Code Web Scraper สำหรับโซลูชันอัตโนมัติ
- วิธีเชี่ยวชาญการดึงข้อมูลอัตโนมัติด้วย Thunderbit
พร้อมทำให้เวิร์กโฟลว์ข้อมูลเว็บของคุณเป็นอัตโนมัติแล้วหรือยัง? ลอง Thunderbit ฟรี แล้วดูว่าการเชื่อม scraping กับ automation ในปี 2026 นั้นง่ายแค่ไหน




