

เว็บกำลังโตแบบก้าวกระโดดจนพูดได้เต็มปากว่าตามแทบไม่ทัน ทุกๆ วัน มีการเผยแพร่หน้าเว็บ สินค้า รีวิว และชุดข้อมูลใหม่ๆ นับพันล้านรายการ ซึ่งเป็นเชื้อเพลิงสำคัญให้กับทุกอย่าง ตั้งแต่งานวิจัยตลาด ไปจนถึงการเทรน AI และการช้อป Amazon รอบถัดไปของคุณ ในฐานะคนที่คลุกคลีกับ SaaS และระบบอัตโนมัติมาหลายปี ผมเห็นกับตาว่าข้อมูลที่ใช่สามารถชี้ชะตาได้เลยว่าธุรกิจจะไปต่อหรือสะดุดตรงไหน แต่ประเด็นคือ การเก็บ อัปเดต และทำความเข้าใจกับข้อมูลบนเว็บทั้งหมดนี้กลับยากขึ้น ไม่ใช่ง่ายขึ้น Web scraper แบบเดิมเริ่มตามไม่ทัน และธุรกิจต่างๆ ก็ต้องการวิธีที่ฉลาดและเร็วกว่าในการเปลี่ยนอินเทอร์เน็ตให้เป็นอินไซต์ที่เอาไปใช้ได้จริง นี่แหละคือจุดที่ cloud crawler เข้ามา—เครื่องมือที่กำลังค่อยๆ ปฏิวัติวิธีที่องค์กรค้นหาและใช้ประโยชน์จากข้อมูลเว็บในระดับใหญ่
แล้วจริงๆ cloud crawler คืออะไร? มันต่างจาก web scraper ที่คุณคุ้นกันอยู่แล้วอย่างไร? และทำไมทีมตั้งแต่ฝ่ายขายไปจนถึงปฏิบัติการถึงทุ่มกับเทคโนโลยีนี้เพื่อให้ก้าวนำในโลกที่ขับเคลื่อนด้วยข้อมูล? มาลงลึกกัน แกะคำศัพท์ให้เข้าใจง่าย และดูว่า cloud crawler (โดยเฉพาะโซลูชันของ Thunderbit) กำลังเปลี่ยนเกมสำหรับธุรกิจยุคใหม่อย่างไร
Cloud Crawler คืออะไร? ก้าวต่อไปของการค้นพบข้อมูล
ดึงข้อมูลจากทุกเว็บไซต์ด้วย AI Get Started Free
มาทำความเข้าใจกันแบบตรงไปตรงมา: cloud crawler ไม่ใช่แค่ web scraper ที่ไปรันบนคลาวด์ แต่มันใกล้เคียงกับ “เครื่องยนต์ค้นพบข้อมูล” มากกว่า—ระบบอัจฉริยะบนคลาวด์ที่ออกแบบมาเพื่อค้นหา ดึง และวิเคราะห์ชุดข้อมูลขนาดใหญ่มหาศาลจากทั่วทั้งอินเทอร์เน็ตโดยอัตโนมัติ ขณะที่ web scraper แบบดั้งเดิมมักดึงข้อมูลจากไม่กี่หน้า (ส่วนใหญ่ทีละหน้า และมักทำงานจากเครื่องเดียว) cloud crawler ทำงานคนละระดับเลย มันรันบนดาต้าเซ็นเตอร์คลาวด์ที่ทรงพลัง สามารถไล่เก็บข้อมูลจากหน้าเว็บนับพันหรือแม้แต่นับล้านหน้าได้พร้อมกัน และประมวลผลได้ตั้งแต่ข้อความ รูปภาพ ไปจนถึง PDF ไม่ว่าเว็บไซต์เป้าหมายจะซับซ้อนหรือกระจัดกระจายแค่ไหนก็ตาม
ลองนึกภาพแบบนี้: ถ้า web scraper คือบรรณารักษ์หนึ่งคนที่คัดลอกข้อความจากหนังสือทีละหน้า cloud crawler ก็คือทีมซูเปอร์คอมพิวเตอร์ที่สแกนหนังสือทุกเล่มในห้องสมุดพร้อมกัน พร้อมติดแท็ก จัดระเบียบ และวิเคราะห์เนื้อหาไปในคราวเดียว ผลลัพธ์คือธุรกิจได้ข้อมูลที่ครบกว่า สดกว่า และเอาไปใช้ได้จริงมากกว่า โดยไม่ติดคอขวดเรื่องฮาร์ดแวร์ในเครื่องหรือการลงแรงแบบ manual (Sitebulb, Octoparse)
Cloud Crawler vs. Traditional Web Scraper: ต่างกันจริงๆ ตรงไหน?
ถ้าคุณเคยใช้ web scraper มาก่อน ก็น่าจะพอรู้พื้นฐาน: ชี้มันไปที่หน้าเว็บ กำหนดว่าต้องการอะไร แล้วปล่อยให้มันดึงข้อมูลให้ แต่พอเว็บใหญ่ขึ้นและซับซ้อนขึ้น วิธีเดิมก็เริ่มเผยข้อจำกัด ลองดูความแตกต่างระหว่าง cloud crawler กับ traditional web scraper กัน:
| ฟีเจอร์/ประเด็น | Traditional Web Scraper | Cloud Crawler |
|---|---|---|
| การติดตั้ง | ทำงานบนอุปกรณ์หรือเซิร์ฟเวอร์ของคุณ | รันบนคลาวด์ (ดาต้าเซ็นเตอร์ระยะไกล) |
| ขนาดงาน | ถูกจำกัดด้วยพลังเครื่องคอมพิวเตอร์ของคุณ | ทำงานแบบขนานขนาดใหญ่—หลายพันหน้าพร้อมกัน |
| ความเร็ว | ช้ากว่า โดยเฉพาะงานใหญ่ๆ | ประมวลผลแบบแบตช์ได้เร็วมาก |
| การดูแลรักษา | ต้องอัปเดตบ่อย และพังง่ายเมื่อเว็บเปลี่ยน | ทำงานบนคลาวด์ อัปเดตอัตโนมัติ เปราะบางน้อยกว่า |
| ประเภทข้อมูล | ส่วนใหญ่เป็นข้อความ บางครั้งเป็นรูปภาพ | ข้อความ รูปภาพ PDF และเลย์เอาต์ที่ซับซ้อน |
| การเข้าถึง | ผูกกับอุปกรณ์/เครือข่ายของคุณ | เข้าถึงได้จากทุกที่ ทุกอุปกรณ์ |
| การตั้งเวลา | ทำด้วยมือหรืออัตโนมัติแบบพื้นฐาน | ตั้งเวลาขั้นสูง งานซ้ำได้ตามรอบ |
| เหมาะที่สุดสำหรับ | โปรเจกต์เล็กๆ เว็บไซต์ที่ไม่ซับซ้อน | งานข้อมูลขนาดใหญ่ งานบ่อย หรือเว็บไซต์ที่ซับซ้อน |
cloud crawler ถูกสร้างมาเพื่อเว็บยุคใหม่—ที่ข้อมูลอยู่ทุกที่ และความเร็วกับสเกลเป็นสิ่งที่ต่อรองไม่ได้ (GPTBots, Octoparse)
Cloud Crawler ช่วยเร่งประสิทธิภาพการเก็บข้อมูลได้อย่างไร
มาถึงจุดที่น่าสนใจจริงๆ cloud crawler ใช้พลังของ cloud computing ในการประมวลผลหน้าเว็บนับพันแบบขนาน นั่นหมายความว่าคุณสามารถดึงแคตตาล็อกอีคอมเมิร์ซทั้งชุด ติดตามราคาคู่แข่งจากหลายสิบเว็บไซต์ หรือรวมประกาศอสังหาฯ จากทุกพอร์ทัลใหญ่ได้—ทั้งหมดนี้ในเวลาเพียงเสี้ยวเดียวของที่ต้องใช้หากใช้ scraper แบบเดิม
ทำไมเรื่องนี้ถึงสำคัญ? เพราะในอุตสาหกรรมอย่างอีคอมเมิร์ซ การเงิน และอสังหาริมทรัพย์ ความสดใหม่ของข้อมูลคือทุกอย่าง ราคา สต็อก และแนวโน้มตลาดเปลี่ยนได้แทบทุกนาที การรอหลายชั่วโมงหรือหลายวันให้ local scraper ทำงานเสร็จไม่ใช่ตัวเลือกอีกต่อไป cloud crawler ไม่ได้ถูกจำกัดด้วย RAM ของแล็ปท็อปหรือ Wi‑Fi ในออฟฟิศ—มันขยายขนาดได้ตามต้องการ เพื่อให้คุณรับมือกับงานหนักได้แบบไม่สะดุด (Zyte, Octoparse)
อุตสาหกรรมที่ได้ประโยชน์จากประสิทธิภาพแบบนี้มากที่สุด ได้แก่:
- อีคอมเมิร์ซ: ติดตามราคา รวมแคตตาล็อกสินค้า วิเคราะห์รีวิว
- อสังหาริมทรัพย์: รวมประกาศ ติดตามเทรนด์ตลาด เปรียบเทียบทรัพย์สิน
- การเงิน: วิเคราะห์ข่าวและอารมณ์ตลาด ติดตามหุ้น/คริปโต และเฝ้าดูข้อมูลกำกับดูแล
- ฝ่ายขายและการตลาด: หาลีด วิจัยคู่แข่ง และจับสัญญาณเทรนด์
และพูดตรงๆ นี่เป็นแค่ส่วนหนึ่งของภาพทั้งหมด ถ้าคุณต้องการข้อมูลเว็บในระดับใหญ่ cloud crawler คือเพื่อนซี้คนใหม่ของคุณ
โซลูชัน Cloud Crawler ของ Thunderbit: เร็ว ยืดหยุ่น และทรงพลัง
ขออนุญาตสวมหมวก Thunderbit สักครู่หนึ่งนะ (เอาจริงๆ ผมแทบไม่เคยถอดมันเลย) โหมด cloud scraping ของ Thunderbit คือคำตอบของเราต่อความท้าทายด้านข้อมูลยุคใหม่—cloud crawler ที่สร้างมาเพื่อผู้ใช้งานธุรกิจที่ต้องการผลลัพธ์ ไม่ใช่ปัญหา
สิ่งที่ทำให้ cloud crawler ของ Thunderbit โดดเด่น:
- ดึงข้อมูลแบบแบตช์ความเร็วสูง: ดึงได้สูงสุด 50 หน้าในคราวเดียว โดยใช้เซิร์ฟเวอร์คลาวด์ในสหรัฐฯ ยุโรป และเอเชียเพื่อครอบคลุมทั่วโลก ไม่ต้องนั่งรอให้แล็ปท็อปค่อยๆ ประมวลผลรายการยาวๆ อีกต่อไป
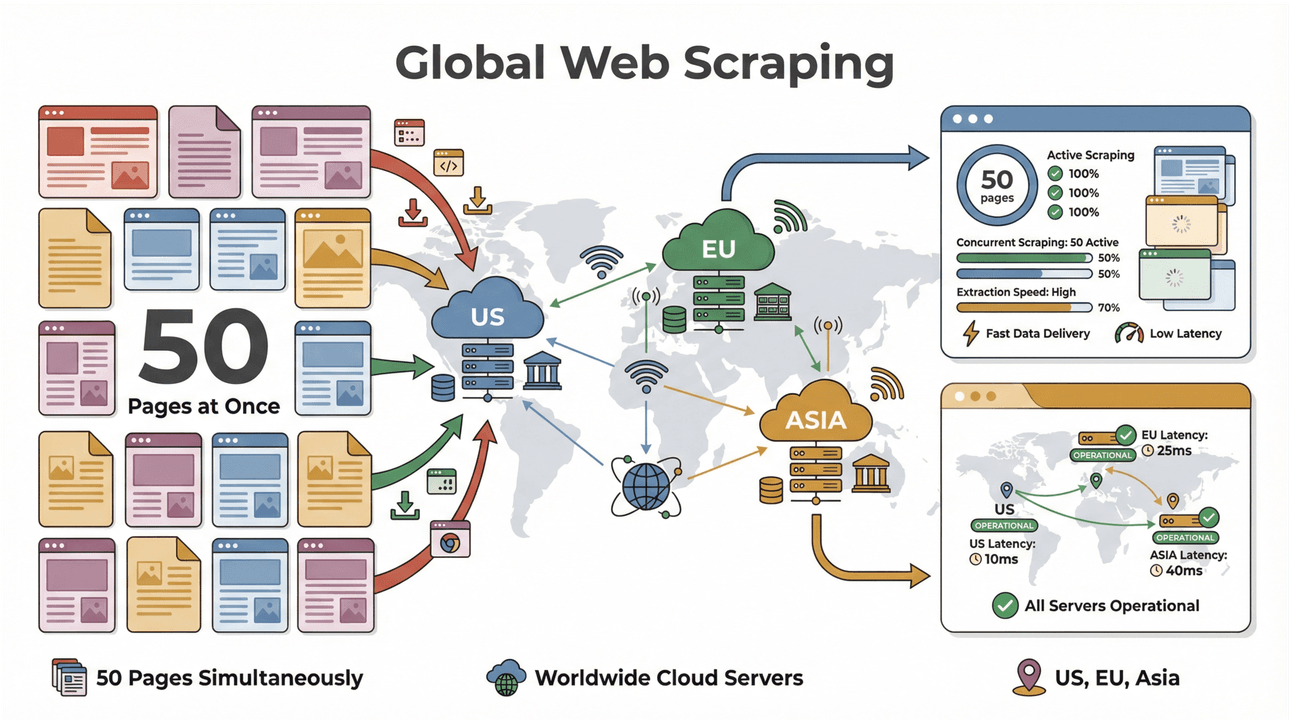
- รองรับหน้าที่ซับซ้อน: AI ของ Thunderbit จัดการได้ตั้งแต่เว็บไซต์อีคอมเมิร์ซแบบไดนามิก ไปจนถึง PDF ยากๆ และแม้แต่การดึงรูปภาพ ถ้าอยู่บนเว็บ Thunderbit ก็น่าจะดึงได้ (Thunderbit)
- ไล่เก็บข้อมูลจากหน้าย่อย: ต้องการเพิ่มรายละเอียดจากหน้าย่อย เช่น สเปกสินค้า หรือประวัติผู้เขียนใช่ไหม? AI ของ Thunderbit สามารถเข้าไปแต่ละหน้าย่อยแล้วรวมผลลัพธ์เข้ากับชุดข้อมูลหลักของคุณได้ (Thunderbit)
- จัดโครงสร้างข้อมูลอย่างชาญฉลาด: ใช้ “AI Suggest Fields” ให้ Thunderbit อ่านเว็บไซต์แล้วแนะนำคอลัมน์ที่เหมาะสมที่สุด—ไม่ต้องเขียนโค้ดหรือสร้างเทมเพลตเอง
- ส่งออกได้ทุกที่: ส่งข้อมูลตรงไปยัง Excel, Google Sheets, Airtable หรือ Notion หรือจะดาวน์โหลดเป็น CSV/JSON ก็ได้ เลือกตามเวิร์กโฟลว์ของคุณ (Thunderbit)
- ไม่ต้องดูแลรักษาเอง: AI ของ Thunderbit ปรับตัวตามการเปลี่ยนแปลงของเว็บไซต์ ทำให้คุณไม่ต้องคอยแก้ scraper ที่พังอยู่เรื่อยๆ (Thunderbit)
และใช่ คุณสามารถลองทั้งหมดนี้ได้ด้วย แผนฟรี —ไม่ต้องเชื่อผมก็ได้
ลองใช้ Thunderbit Cloud Scraper ฟรี
การติดตั้ง Cloud Crawler: คลาวด์ vs. โลคัล—แบบไหนเหมาะกับคุณ?
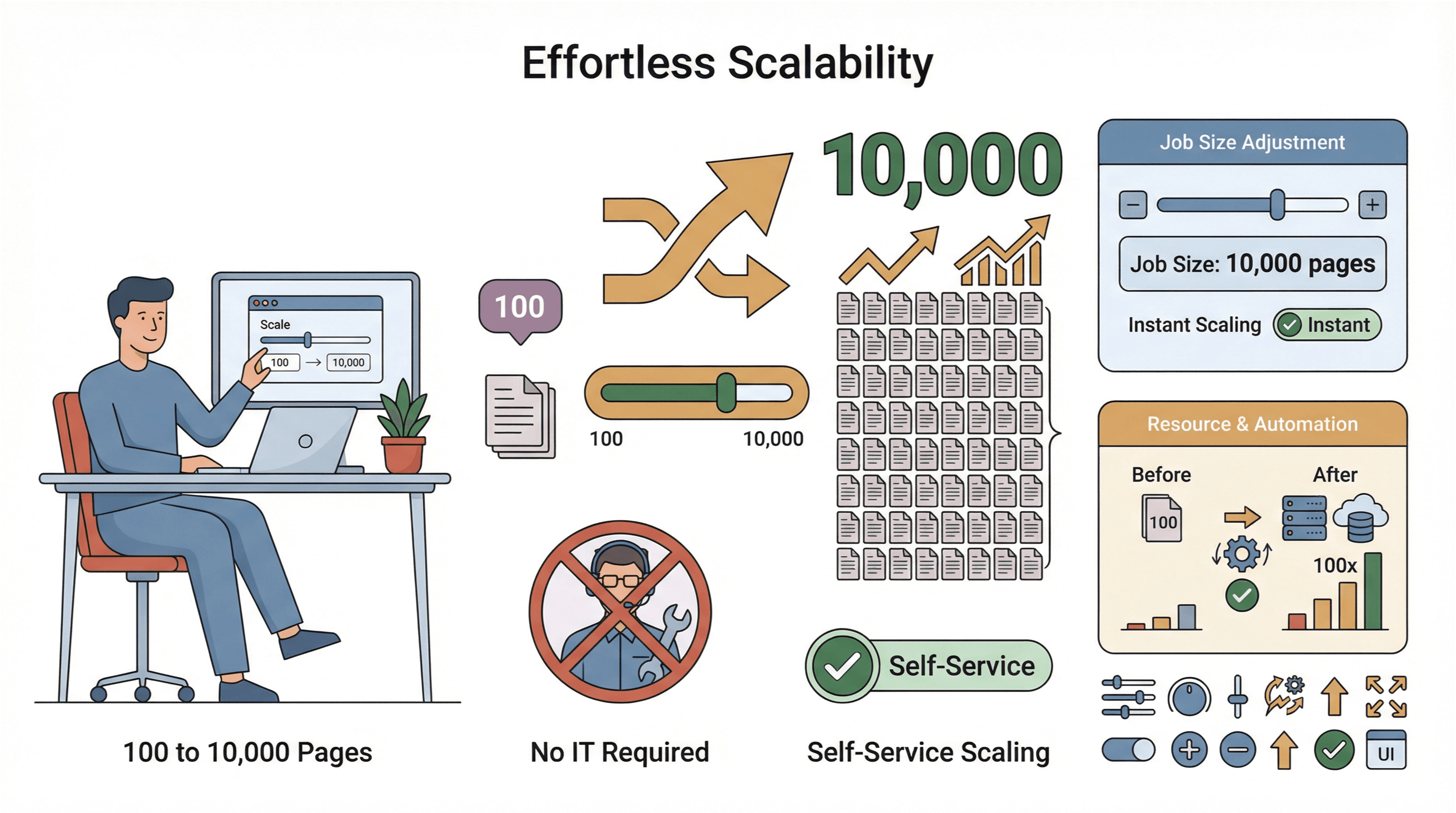
หนึ่งในข้อได้เปรียบที่ใหญ่ที่สุดของ cloud crawler คือความยืดหยุ่นในการติดตั้ง ถ้าเป็น crawler แบบดั้งเดิม (local) คุณจะผูกอยู่กับอุปกรณ์ เครือข่าย และมักมาพร้อมปัญหาการตั้งค่าจุกจิกมากมาย ถ้าคอมพิวเตอร์เข้าสลีปหรืออินเทอร์เน็ตหลุด งานดึงข้อมูลก็หยุดทันที ถ้าจะขยายงานก็ต้องซื้อฮาร์ดแวร์เพิ่มหรือรันสคริปต์หลายตัว
cloud crawler พลิกเกมนี้ได้:
- ไม่ต้องใช้ฮาร์ดแวร์พิเศษ: งานหนักทั้งหมดเกิดขึ้นบนคลาวด์ คุณสามารถเริ่มดึงข้อมูลขนาดใหญ่ได้จาก Chromebook, Mac หรือแม้แต่โทรศัพท์
- เข้าถึงได้จากทุกที่: เดินทางอยู่ ทำงานระยะไกลอยู่ ก็ไม่มีปัญหา—cloud crawler ของคุณพร้อมใช้งานเสมอ
- ขยายงานได้ง่าย: ต้องดึง 10,000 หน้าแทน 100 หน้าใช่ไหม? แค่เพิ่มขนาดงาน ไม่ต้องให้ IT เข้ามาช่วย
- เก็บข้อมูลได้ระดับโลก: ด้วยเซิร์ฟเวอร์คลาวด์หลายภูมิภาค คุณจึงเข้าถึงเนื้อหาที่จำกัดตามภูมิภาคและจัดการเรื่อง compliance ได้ง่ายขึ้น (PromptCloud)
แน่นอนว่าเรื่องความปลอดภัยและการปฏิบัติตามข้อกำหนดยังคงเป็นเรื่องสำคัญเสมอ cloud crawler ที่ดีจริงๆ (รวมถึง Thunderbit) จะใช้การเชื่อมต่อแบบเข้ารหัส เคารพข้อกำหนดของเว็บไซต์ และมีฟีเจอร์ช่วยให้คุณจัดการข้อมูลที่ละเอียดอ่อนได้อย่างรับผิดชอบ
ผลกระทบในโลกจริง: Cloud Crawler กำลังเปลี่ยนกลยุทธ์ที่ขับเคลื่อนด้วยข้อมูลอย่างไร
มาดูแบบเป็นรูปธรรมกัน ทำไมธุรกิจถึงหันมาใช้ cloud crawler? เพราะพวกเขาเห็นผลลัพธ์จริงที่วัดได้:
- วิเคราะห์ตลาดแบบเรียลไทม์: ผู้ค้าปลีกใช้ cloud crawler เพื่อติดตามราคาคู่แข่งและสต็อกแบบเรียลไทม์ ทำให้ตั้งราคาได้แบบไดนามิกและตอบสนองต่อการเปลี่ยนแปลงของตลาดได้เร็วขึ้น (Zyte)
- คาดการณ์เทรนด์ผู้บริโภค: แบรนด์ต่างๆ รวมรีวิว โพสต์โซเชียล และบทสนทนาในฟอรัมเพื่อจับสัญญาณเทรนด์ที่กำลังมา และปรับแคมเปญได้ทันที
- ฝ่ายขายและการหาลีด: ทีมขายสร้างรายชื่อลีดที่อัปเดตอยู่เสมอจากไดเรกทอรี เว็บไซต์อีเวนต์ และแม้แต่ PDF—พร้อมป้อน CRM ด้วยคอนแท็กต์ใหม่ที่คัดมาแล้ว (Thunderbit)
- ปฏิบัติการและ compliance: สถาบันการเงินใช้ cloud crawler เพื่อติดตามการอัปเดตกฎระเบียบ ข่าวสาร และเอกสารยื่นในหลายเขตอำนาจศาล—ลดความเสี่ยงและไม่ตกขบวนการเปลี่ยนแปลง
แก่นแท้ของทั้งหมดนี้คืออะไร? cloud crawler ช่วยให้ทีมทำงานได้เร็วขึ้น ตัดสินใจได้ฉลาดขึ้น และแซงหน้าคู่แข่งที่ยังติดอยู่กับวิธีช้าๆ แบบเดิม
ฟีเจอร์สำคัญที่ควรมองหาใน Cloud Crawler
ดูราคาและฟีเจอร์ของ Thunderbit Get Started Free
cloud crawler ไม่ได้เหมือนกันทุกตัว หากคุณกำลังพิจารณาอยู่ นี่คือฟีเจอร์ที่ควรให้ความสำคัญมากที่สุด (และเป็นจุดที่ Thunderbit ทำได้ดี):
- ความสามารถในการสเกล: รองรับหลายพันหน้าได้พร้อมกันไหม? งานใหญ่ขึ้นแล้วช้าลงหรือเปล่า?
- ใช้งานง่าย: อินเทอร์เฟซเหมาะกับผู้ใช้ที่ไม่ใช่สายเทคนิคไหม? ตั้งค่างานได้ในไม่กี่คลิกหรือไม่?
- รองรับหลายประเภทข้อมูล: ข้อความ รูปภาพ PDF หน้าย่อย—ทำได้ครบไหม?
- การเชื่อมต่อ: ส่งออกไปยังเครื่องมือที่คุณชอบได้หรือไม่ เช่น Excel, Sheets, Notion, Airtable?
- การตั้งเวลา: ตั้งงานซ้ำเพื่อให้ข้อมูลสดใหม่อยู่เสมอได้ไหม?
- AI Assistance: มีคำแนะนำฟิลด์อัจฉริยะ การเสริมข้อมูล และการปรับตามการเปลี่ยนแปลงของเว็บแบบอัตโนมัติหรือไม่?
- ความปลอดภัยและ compliance: ข้อมูลและ credentials ของคุณได้รับการปกป้องไหม? ช่วยให้คุณปฏิบัติตามกฎหมายความเป็นส่วนตัวได้หรือไม่?
Thunderbit ตอบโจทย์ครบทุกข้อ จึงเป็นตัวเลือกอันดับต้นๆ สำหรับทีมที่ต้องการพลังสูงโดยไม่ต้องเจ็บปวดกับความซับซ้อน
เริ่มต้นใช้งาน: ใช้ Cloud Crawler กับธุรกิจของคุณอย่างไร
พร้อมเริ่มแล้วใช่ไหม? นี่คือวิธีเริ่มต้นใช้งาน cloud crawler อย่าง Thunderbit แบบที่ผู้ใช้ธุรกิจทั่วไปทำได้:
- ติดตั้ง Thunderbit Chrome Extension: ตั้งค่าได้เร็ว ไม่ต้องให้ IT มาช่วย
- เลือกเป้าหมาย: เปิดเว็บไซต์ ลิสต์ หรือเอกสารที่คุณต้องการดึงข้อมูล
- คลิก “AI Suggest Fields”: ให้ AI ของ Thunderbit สแกนหน้าเว็บและแนะนำคอลัมน์ที่ควรดึง
- ปรับแต่งตามต้องการ: เพิ่ม ลบ หรือเปลี่ยนชื่อฟิลด์ให้ตรงกับงานของคุณ
- เลือก Cloud Scraping Mode: สำหรับงานใหญ่หรือเว็บไซต์ซับซ้อน ให้สลับเป็นโหมดคลาวด์เพื่อความเร็วสูงสุด
- เริ่มดึงข้อมูล: Thunderbit จะประมวลผลได้สูงสุด 50 หน้าในคราวเดียวบนคลาวด์
- ตรวจสอบและส่งออก: ดูตัวอย่างผลลัพธ์ แล้วส่งออกไปยัง Excel, Google Sheets, Notion หรือ Airtable
- ตั้งงานซ้ำตามรอบ: ถ้าต้องใช้ต่อเนื่อง ให้ตั้งเวลาสำหรับการดึงข้อมูลอัตโนมัติ—ข้อมูลของคุณจะอัปเดตเอง (Thunderbit Docs)
ทิปสั้นๆ: เริ่มจากงานเล็กๆ ก่อนเพื่อให้คุ้นมือ แล้วค่อยขยายเมื่อมั่นใจขึ้น และอย่ากลัวที่จะใช้ซัพพอร์ตหรือเอกสารของ Thunderbit—เพราะพวกเขามีไว้ช่วยคุณอยู่แล้ว
เริ่ม Cloud Crawling กับ Thunderbit
อนาคตของการเก็บข้อมูล: Cloud Crawler จะไปทางไหนต่อ?
การปฏิวัติของ cloud crawler เพิ่งเริ่มต้นเท่านั้น สิ่งที่ผมกำลังจับตาในอีกไม่กี่ปีข้างหน้ามีดังนี้:
- การดึงข้อมูลด้วย AI ที่ฉลาดขึ้น: cloud crawler กำลังเก่งขึ้นในการเข้าใจบริบท ความสัมพันธ์ และแม้แต่อารมณ์ ทำให้ข้อมูลที่เก็บได้มีมูลค่ามากกว่าเดิม (GPTBots)
- รองรับประเภทข้อมูลใหม่ๆ: คาดว่าจะจัดการวิดีโอ เสียง และคอนเทนต์แบบอินเทอร์แอกทีฟได้ดีขึ้น ไม่ใช่แค่ข้อความและรูปภาพแบบคงที่
- ระบบอัตโนมัติที่ลึกกว่าเดิม: ตั้งเวลาอัตโนมัติไปจนถึงแจ้งเตือนแบบเรียลไทม์ cloud crawler จะยิ่งแทบไม่ต้องให้ผู้ใช้ลงมือเอง
- การปฏิบัติตามข้อกำหนดที่ดีขึ้น: เมื่อกฎหมายความเป็นส่วนตัวพัฒนาไป cloud crawler จะมีเครื่องมือมากขึ้นเพื่อช่วยทีมทำงานให้สอดคล้องกับกฎระเบียบ
- เชื่อมกับ BI และ AI tools: ทำ pipeline ตรงจาก cloud crawler ไปยังแพลตฟอร์มวิเคราะห์ข้อมูล แดชบอร์ด และ machine learning
พูดสั้นๆ cloud crawler กำลังจะกลายเป็นกระดูกสันหลังของกลยุทธ์ธุรกิจดิจิทัล—ตั้งแต่การเปิดตัวสินค้า ไปจนถึงการพยากรณ์ด้วย AI (Thunderbit Blog)
สรุป: ทำไม Cloud Crawler ถึงจำเป็นสำหรับธุรกิจยุคใหม่
สรุปให้สั้นที่สุด: เว็บกำลังพุ่งทะลักด้วยข้อมูล และวิธีเก็บข้อมูลแบบเก่าไม่สามารถตามให้ทันได้อีกต่อไป cloud crawler คือวิวัฒนาการถัดไป—มอบความเร็ว ขนาดการทำงาน และความฉลาดที่ scraper แบบดั้งเดิมเทียบไม่ได้ เครื่องมืออย่าง Thunderbit ทำให้ทุกทีม ไม่ว่าจะสายเทคนิคหรือไม่ สามารถเข้าถึงศักยภาพเต็มรูปแบบของข้อมูลบนเว็บได้—ช่วยให้ตัดสินใจได้ฉลาดขึ้น ตอบสนองได้ไวขึ้น และสร้างความได้เปรียบในการแข่งขันที่แท้จริง
ถ้าคุณพร้อมจะทิ้งการดึงข้อมูลแบบ manual และข้อมูลที่ช้าเกินไป ตอนนี้คือเวลาที่เหมาะที่สุดในการลองดูว่า cloud crawler ทำอะไรให้ธุรกิจของคุณได้บ้าง ลองใช้โหมด cloud scraping ของ Thunderbit แล้วคุณจะเห็นว่าการค้นพบข้อมูลยุคใหม่ง่ายและทรงพลังแค่ไหน และถ้าอยากเจาะลึกกว่านี้ ลองอ่าน Thunderbit Blog เพื่อดูคู่มือ ทิปส์ และตัวอย่างใช้งานจริงเพิ่มเติม
คำถามที่พบบ่อย
1. Cloud crawler คืออะไรแบบเข้าใจง่ายๆ?
Cloud crawler คือเครื่องมือบนคลาวด์ที่ค้นหา ดึง และวิเคราะห์ข้อมูลจำนวนมากจากเว็บโดยอัตโนมัติ ต่างจาก scraper แบบดั้งเดิมที่รันบนอุปกรณ์ของคุณ Cloud crawler ทำงานในดาต้าเซ็นเตอร์ที่ทรงพลัง จึงรองรับทั้งสเกลใหญ่และความเร็วสูง
2. Cloud crawler ต่างจาก web scraper ทั่วไปอย่างไร?
Cloud crawler ทำงานบนคลาวด์ จัดการได้หลายพันหน้าพร้อมกัน รองรับข้อมูลที่ซับซ้อนอย่างรูปภาพและ PDF และไม่ต้องคอยดูแลหรือใช้ฮาร์ดแวร์ในเครื่อง ส่วน scraper แบบดั้งเดิมจะถูกจำกัดด้วยพลังเครื่องและเหมาะกับงานเล็กๆ ที่ไม่ซับซ้อนกว่า
3. ข้อดีหลักของการใช้ cloud crawler มีอะไรบ้าง?
Cloud crawler ช่วยเก็บข้อมูลได้เร็ว รองรับงานขนาดใหญ่ ใช้งานได้จากทุกที่ และมีฟีเจอร์ขั้นสูงอย่างการตั้งเวลาและการดึงข้อมูลด้วย AI เหมาะมากสำหรับธุรกิจที่ต้องการข้อมูลสดใหม่และเอาไปใช้ได้จริงอย่างรวดเร็ว
4. Cloud crawler ของ Thunderbit ใช้กับธุรกิจอย่างไร?
Cloud crawler ของ Thunderbit ช่วยให้คุณตั้งค่างานดึงข้อมูลได้ในไม่กี่คลิก—ไม่ต้องเขียนโค้ด คุณสามารถดึงข้อมูลจากเว็บไซต์ PDF และรูปภาพ เสริมข้อมูลด้วย AI และส่งออกตรงไปยัง Excel, Google Sheets, Notion หรือ Airtable ออกแบบมาสำหรับผู้ใช้ที่ไม่ใช่สายเทคนิคแต่ต้องการผลลัพธ์จริง
5. Cloud crawling ปลอดภัยและสอดคล้องกับกฎหมายความเป็นส่วนตัวหรือไม่?
ใช่ cloud crawler ชั้นนำอย่าง Thunderbit ใช้การเชื่อมต่อแบบเข้ารหัสและแนวปฏิบัติที่ดีด้านความปลอดภัยของข้อมูลเสมอ แต่คุณควรดึงเฉพาะข้อมูลสาธารณะที่เข้าถึงได้ และเคารพข้อกำหนดการใช้งานของเว็บไซต์รวมถึงกฎหมายความเป็นส่วนตัวเสมอ
พร้อมดูหรือยังว่า cloud crawler ทำอะไรได้บ้าง? ดาวน์โหลด Thunderbit แล้วเริ่มสำรวจโลกของการเก็บข้อมูลขนาดใหญ่บนคลาวด์ได้เลยวันนี้
ลองใช้ Thunderbit Cloud Crawler วันนี้ Get Started Free
เรียนรู้เพิ่มเติม




