

เว็บเต็มไปด้วยข้อมูลมีค่า—ไม่ว่าคุณจะอยู่ในสายงานขาย อีคอมเมิร์ซ หรือวิจัยตลาด การทำ Web Scraping คืออาวุธลับสำหรับการหาลูกค้าเป้าหมาย ติดตามราคา และวิเคราะห์คู่แข่ง แต่ประเด็นคือ: ยิ่งธุรกิจหันมาใช้การดึงข้อมูลมากขึ้น เว็บไซต์ต่าง ๆ ก็ยิ่งป้องกันเข้มขึ้นไปด้วย การเปลี่ยนแปลงนี้เกิดขึ้นจริง: การวิเคราะห์ของ ppc.land ปี 2024 พบว่ามากกว่าหนึ่งในสามของเว็บไซต์ 1,000 อันดับแรกได้บล็อก crawler ของ OpenAI ไปแล้ว — และชุดเครื่องมือป้องกันแบบกว้าง ๆ อย่าง การแบน IP, CAPTCHA และ browser fingerprinting ก็กลายเป็นเรื่องปกติมากกว่าจะเป็นข้อยกเว้น
ถ้าคุณเคยเห็นสคริปต์ Python รันได้ลื่น ๆ อยู่ 20 นาที แล้วจู่ ๆ ก็ชนกำแพงของข้อผิดพลาด 403 คุณคงรู้ว่ามันหงุดหงิดแค่ไหน
ผมอยู่ในสาย SaaS และ automation มาหลายปี และได้เห็นกับตาว่าโปรเจกต์ scraping สามารถเปลี่ยนจาก “ว้าว ง่ายจัง” ไปเป็น “ทำไมโดนบล็อกทุกเว็บ” ได้ในพริบตา งั้นมาลงมือแบบใช้งานได้จริงกันเลย: ผมจะพาคุณไล่ดูวิธีทำ Web Scraping ด้วย Python โดยไม่ให้ถูกบล็อก แชร์เทคนิคและโค้ดตัวอย่างที่ดีที่สุด และบอกด้วยว่าเมื่อไหร่ควรเริ่มมองทางเลือกที่ขับเคลื่อนด้วย AI อย่าง Thunderbit ไม่ว่าคุณจะเป็นโปร Python หรือเพิ่ง scraping แบบเอาตัวรอดอยู่ก็ตาม คุณจะได้ชุดเครื่องมือสำหรับการดึงข้อมูลที่เชื่อถือได้และไม่โดนบล็อก
Web Scraping โดยไม่ให้ถูกบล็อกใน Python คืออะไร?
แก่นแท้ของมันคือ Web Scraping โดยไม่ให้ถูกบล็อก หมายถึงการดึงข้อมูลจากเว็บไซต์ในลักษณะที่ไม่ไปกระตุ้นระบบป้องกันบอตของเว็บ ในโลก Python เรื่องนี้ไม่ได้จบแค่การเขียนลูป requests.get() เท่านั้น—แต่คือการทำตัวให้กลมกลืน เลียนแบบผู้ใช้จริง และก้าวนำระบบตรวจจับไปหนึ่งก้าว
ทำไมต้อง Python? Python เป็นภาษายอดนิยมที่สุดสำหรับ Web Scraping—เพราะไวยากรณ์เรียบง่าย มี ecosystem ขนาดใหญ่ (เช่น requests, BeautifulSoup, Scrapy, Selenium) และยืดหยุ่นตั้งแต่สคริปต์สั้น ๆ ไปจนถึง crawler แบบกระจาย แต่ความนิยมก็มีราคาที่ต้องจ่าย: ระบบป้องกันบอตจำนวนมากตอนนี้ปรับมาให้มองหารูปแบบการ scraping ที่ใช้ Python ได้แล้ว
ดังนั้นถ้าคุณอยาก scrape ให้เสถียร คุณต้องก้าวข้ามพื้นฐานไปอีกขั้น นั่นหมายถึงการเข้าใจว่าเว็บไซต์ตรวจจับบอตอย่างไร และคุณจะเอาชนะมันได้อย่างไร—โดยไม่ข้ามเส้นด้านจริยธรรมหรือกฎหมาย
ทำไมการหลีกเลี่ยงการถูกบล็อกจึงสำคัญกับโปรเจกต์ Python Web Scraping
การถูกบล็อกไม่ใช่แค่ปัญหาทางเทคนิคเล็ก ๆ มันสามารถทำให้ทั้ง workflow ของธุรกิจสะดุดได้ มาดูแบบเป็นข้อ ๆ:
| กรณีใช้งาน | ผลกระทบเมื่อถูกบล็อก |
|---|---|
| การหาลูกค้าเป้าหมาย | รายชื่อผู้มุ่งหวังไม่ครบหรือข้อมูลเก่า ยอดขายหาย |
| การติดตามราคา | พลาดการเปลี่ยนแปลงราคาคู่แข่ง ตัดสินใจตั้งราคาพลาด |
| การรวบรวมคอนเทนต์ | ข้อมูลข่าว รีวิว หรือข้อมูลวิจัยขาดหาย |
| วิเคราะห์ตลาด | มองไม่เห็นภาพในส่วนของการติดตามคู่แข่งหรืออุตสาหกรรม |
| ประกาศอสังหาริมทรัพย์ | ข้อมูลทรัพย์สินไม่แม่นยำหรือเก่า พลาดโอกาส |
เมื่อ scraper ถูกบล็อก คุณไม่ได้แค่ขาดข้อมูล—แต่ยังเสียทรัพยากร เสี่ยงปัญหาด้านการปฏิบัติตามข้อกำหนด และอาจตัดสินใจทางธุรกิจผิดจากข้อมูลที่ไม่ครบถ้วน ในโลกที่ 79% ของธุรกิจพึ่งพา web scraping สำหรับการหาลูกค้าเป้าหมาย ความน่าเชื่อถือคือทุกอย่าง
เว็บไซต์ตรวจจับและบล็อก Python Web Scraper อย่างไร
เว็บไซต์ฉลาดขึ้นมากในการจับบอต ต่อไปนี้คือมาตรการป้องกันการ scraping ที่พบบ่อยที่สุดที่คุณจะเจอ (Medium, Bright Data):
- การขึ้นบัญชีดำตาม IP Address: ถ้าส่งคำขอมากเกินไปจาก IP เดียว ก็โดนบล็อก
- ตรวจ User-Agent และ Header: คำขอที่ขาด headers หรือใช้ headers ทั่วไปเกินไป (เช่น
python-requests/2.25.1ค่าเริ่มต้นของ Python) จะดูสะดุดตา - Rate Limiting: ส่งคำขอถี่เกินไปในช่วงสั้น ๆ ก็โดนจำกัดความเร็วหรือแบน
- CAPTCHA: ปริศนาแบบ “พิสูจน์ว่าคุณไม่ใช่บอต” ที่บอตแก้ไม่ได้ง่าย ๆ
- การวิเคราะห์พฤติกรรม: เว็บไซต์คอยดูรูปแบบที่ดูเป็นหุ่นยนต์ เช่น กดปุ่มเดิมในจังหวะเดิมตลอด
- Honeypots: ลิงก์หรือช่องฟอร์มที่ซ่อนไว้ ซึ่งมีแต่บอตเท่านั้นที่จะไปยุ่ง
- Browser Fingerprinting: เก็บรายละเอียดเกี่ยวกับเบราว์เซอร์และอุปกรณ์ของคุณเพื่อจับเครื่องมือ automation
- การติดตามคุกกี้และเซสชัน: บอตที่จัดการคุกกี้หรือเซสชันไม่ดีจะถูกมองว่าไม่ปกติ
ให้นึกเหมือนการตรวจที่สนามบิน: ถ้าคุณดู ท่าทาง และเคลื่อนไหวเหมือนคนอื่น คุณก็ผ่านฉลุย แต่ถ้าคุณใส่เสื้อโค้ทยาวกับแว่นกันแดดมาเต็มยศ ก็เตรียมตัวตอบคำถามเพิ่มได้เลย
เทคนิค Python ที่จำเป็นสำหรับ Web Scraping โดยไม่ให้ถูกบล็อก
มาดูของจริงกัน: จะหลีกเลี่ยงการถูกบล็อกตอน scraping ด้วย Python ได้อย่างไร ต่อไปนี้คือกลยุทธ์หลักที่ scraper ทุกคนควรรู้:

การหมุนเวียน Proxy และ IP Address
ทำไมถึงสำคัญ: ถ้าคำขอทั้งหมดมาจาก IP เดียว คุณจะเป็นเป้าง่ายสำหรับการแบน IP proxy แบบหมุนเวียนช่วยกระจายคำขอไปหลาย IP ทำให้บล็อกคุณยากขึ้นมาก
วิธีทำใน Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...proxy เพิ่มเติม
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# ประมวลผล response
คุณสามารถใช้บริการ proxy แบบเสียเงิน (เช่น residential หรือ rotating proxies) เพื่อความเสถียรที่มากขึ้น (ScrapingBee).
การตั้งค่า User-Agent และ Headers แบบกำหนดเอง
ทำไมถึงสำคัญ: headers ค่าเริ่มต้นของ Python ตะโกนว่า “บอต” ออกมาเลย ให้เลียนแบบเบราว์เซอร์จริงโดยตั้ง user-agent และ headers อื่น ๆ
ตัวอย่างโค้ด:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
สลับ user-agent ไปเรื่อย ๆ เพื่อเพิ่มความแนบเนียน (ZenRows).
การสุ่มเวลาและรูปแบบการส่งคำขอ
ทำไมถึงสำคัญ: บอตเร็วและคาดเดาได้ ส่วนมนุษย์ช้าและไม่แน่นอน ใส่ดีเลย์และสลับรูปแบบการเข้าชมของคุณ
ทิปสำหรับ Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # รอ 2–7 วินาที
ถ้าใช้ Selenium คุณยังสุ่มเส้นทางการคลิกและแพตเทิร์นการเลื่อนหน้าได้ด้วย
การจัดการคุกกี้และเซสชัน
ทำไมถึงสำคัญ: หลายเว็บไซต์ต้องใช้คุกกี้หรือโทเค็นเซสชันเพื่อเข้าถึงเนื้อหา บอตที่ไม่จัดการส่วนนี้มักโดนบล็อก
วิธีจัดการใน Python:
import requests
session = requests.Session()
response = session.get(url)
# session จะจัดการคุกกี้ให้โดยอัตโนมัติ
ถ้า flow ซับซ้อนขึ้น ให้ใช้ Selenium เพื่อดึงและนำคุกกี้กลับมาใช้ซ้ำ
จำลองพฤติกรรมมนุษย์ด้วย Headless Browser
ทำไมถึงสำคัญ: บางเว็บไซต์ใช้ JavaScript การขยับเมาส์ หรือการเลื่อนหน้าเป็นสัญญาณว่าคนจริงกำลังใช้งาน Headless browser อย่าง Selenium หรือ Playwright ช่วยเลียนแบบการกระทำเหล่านี้ได้
ตัวอย่างด้วย Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
วิธีนี้ช่วยให้คุณหลีกเลี่ยงการวิเคราะห์พฤติกรรมและคอนเทนต์แบบไดนามิก (ScrapingBee).
กลยุทธ์ขั้นสูง: หลีกเลี่ยง CAPTCHA และ Honeypot ใน Python
CAPTCHA ถูกออกแบบมาเพื่อหยุดบอตทันที บางไลบรารีของ Python สามารถแก้ CAPTCHA แบบง่าย ๆ ได้ แต่ scraper ระดับจริงจังส่วนใหญ่พึ่งพาบริการจากภายนอก (เช่น 2Captcha หรือ Anti-Captcha) เพื่อแก้ให้โดยมีค่าบริการ (Medium).
ตัวอย่างการเชื่อมต่อ:
# โค้ดกึ่งตัวอย่างสำหรับใช้ 2Captcha API
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# รอคำตอบ แล้วค่อยส่งกลับไปพร้อมคำขอของคุณ
Honeypots คือช่องหรือาลิงก์ที่ซ่อนไว้ ซึ่งมีแต่บอตเท่านั้นที่จะไปแตะ หลีกเลี่ยงการคลิกหรือส่งข้อมูลอะไรที่ไม่เห็นชัดในเบราว์เซอร์จริง (ZenRows).
การออกแบบ headers ให้แข็งแรงด้วยไลบรารี Python
นอกจาก user-agent แล้ว คุณยังหมุนเวียนและสุ่ม headers อื่น ๆ ได้ด้วย เช่น Referer, Accept, Origin เพื่อให้กลมกลืนยิ่งขึ้น
ด้วย Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# headers อื่น ๆ
}
}
ด้วย Selenium: ใช้ browser profile หรือ extension เพื่อตั้ง headers หรือ inject ผ่าน JavaScript
อัปเดตรายการ headers ของคุณอยู่เสมอ—ลองคัดลอกคำขอจริงจาก browser DevTools มาเป็นแนวทาง
เมื่อการ scraping แบบ Python ดั้งเดิมไม่พอ: การเติบโตของเทคโนโลยีป้องกันบอต
ความจริงก็คือ: ยิ่ง scraping ได้รับความนิยมมากเท่าไร การอัปเกรดระบบป้องกันบอตก็ยิ่งเพิ่มขึ้นเท่านั้น เว็บไซต์ใหญ่ตอนนี้บล็อกไม่ใช่แค่บอตที่ดูชัด ๆ แต่รวมถึง headless browser ที่ซับซ้อนและ rotating proxy ด้วย การตรวจจับด้วย AI, เกณฑ์จำกัดคำขอแบบไดนามิก และ browser fingerprinting ทำให้แม้แต่สคริปต์ Python ขั้นสูงก็ยังยากจะไม่ให้ถูกตรวจพบ (Medium).
บางครั้งไม่ว่าโค้ดคุณจะฉลาดแค่ไหน คุณก็ยังเจอกำแพงอยู่ดี และนั่นคือจังหวะที่ต้องมองหาวิธีอื่น
Thunderbit: ทางเลือก AI Web Scraper แทนการ Scrape ด้วย Python
เมื่อ Python ไปได้ถึงขีดจำกัด Thunderbit ก็เข้ามาเป็น web scraper แบบ no-code ที่ขับเคลื่อนด้วย AI และสร้างมาสำหรับผู้ใช้งานธุรกิจ—not just developers แทนที่จะต้องมานั่งสู้กับ proxy, headers และ CAPTCHA ให้ปวดหัว Thunderbit ใช้ AI agent อ่านหน้าเว็บ แนะนำฟิลด์ที่ควรดึง และจัดการทุกอย่างตั้งแต่การไปยังหน้าย่อยจนถึงการส่งออกข้อมูล
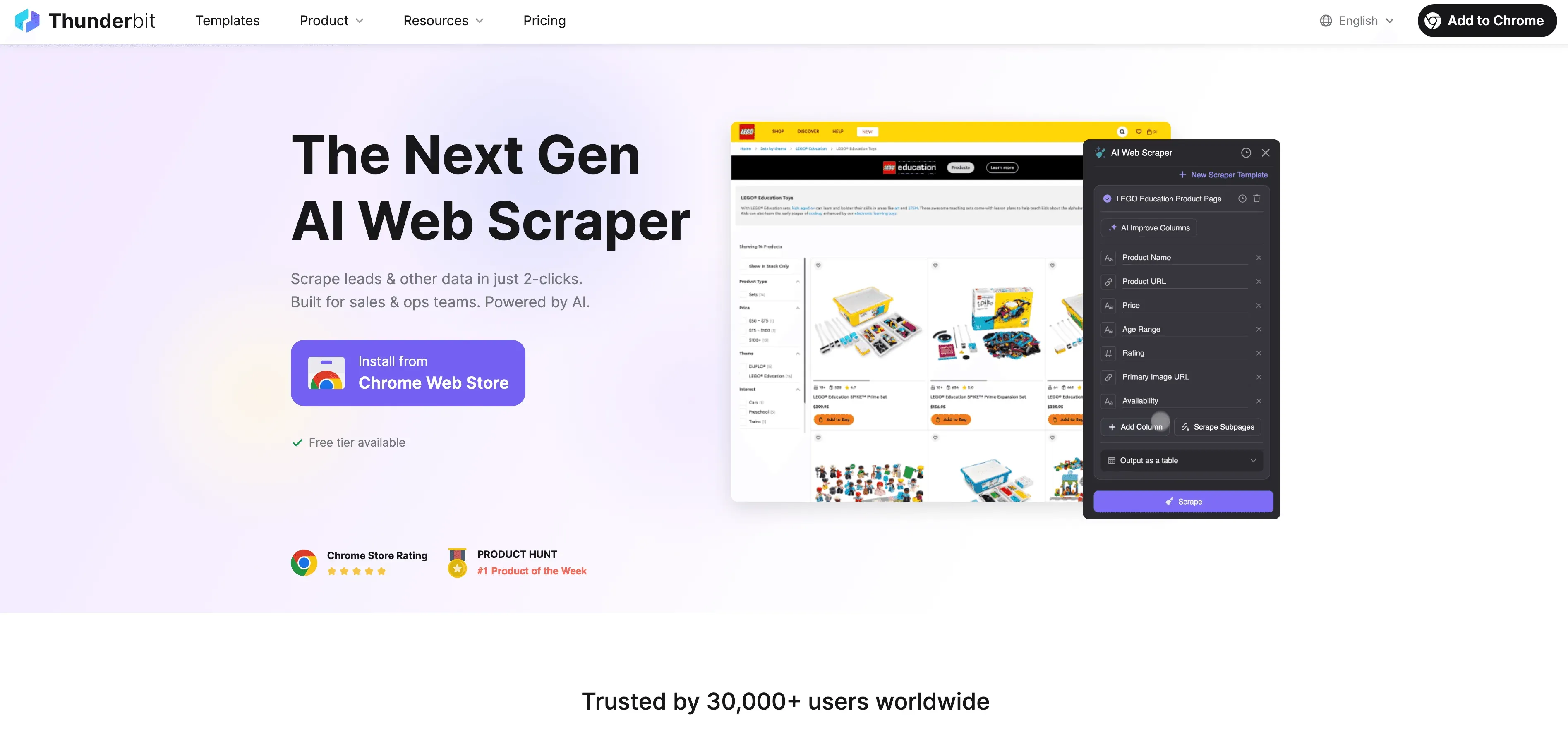
อะไรที่ทำให้ Thunderbit ต่างออกไป?
- AI Field Suggestion: คลิก “AI Suggest Fields” แล้ว Thunderbit จะสแกนหน้าเว็บ แนะนำคอลัมน์ และยังสร้างคำสั่งดึงข้อมูลให้อีกด้วย
- การ scrape หน้าย่อย: Thunderbit สามารถเข้าไปยังแต่ละหน้าย่อย (เช่น รายละเอียดสินค้า หรือโปรไฟล์ LinkedIn) และเติมข้อมูลในตารางของคุณให้โดยอัตโนมัติ
- Cloud หรือ Browser Scraping: เลือกตัวเลือกที่เร็วที่สุด—ใช้ cloud สำหรับเว็บสาธารณะ และใช้ browser สำหรับหน้าที่ต้องล็อกอิน
- Scheduled Scraping: ตั้งค่าแล้วปล่อยได้เลย—Thunderbit สามารถ scrape ตามกำหนดเวลา ทำให้ข้อมูลสดใหม่อยู่เสมอ
- Instant Templates: สำหรับเว็บไซต์ยอดนิยม (Amazon, Zillow, Shopify ฯลฯ) Thunderbit มีเทมเพลตแบบคลิกเดียว ไม่ต้องตั้งค่า
- ส่งออกข้อมูลฟรี: ส่งออกไปยัง Excel, Google Sheets, Airtable หรือ Notion ได้เลย—ไม่คิดค่าใช้จ่ายเพิ่ม
Thunderbit ได้รับความไว้วางใจจากผู้ใช้มากกว่า 100,000 คนทั่วโลก และคุณไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว
ดึงข้อมูลจากเว็บไซต์ใดก็ได้ด้วย AI Get Started Free
Thunderbit ช่วยให้ผู้ใช้หลีกเลี่ยงการถูกบล็อกและทำงานดึงข้อมูลอัตโนมัติได้อย่างไร
AI ของ Thunderbit ไม่ได้แค่เลียนแบบพฤติกรรมมนุษย์—แต่มันปรับตัวให้เข้ากับแต่ละเว็บไซต์แบบเรียลไทม์ ลดความเสี่ยงที่จะถูกบล็อกได้มากขึ้น นี่คือวิธีทำงาน:
- AI ปรับตามการเปลี่ยนแปลงของเลย์เอาต์: ลดงานแก้โค้ดเมื่อเว็บอัปเดตดีไซน์ — คุณไม่ต้องกลับไปจูนตัวเลือก selector ใหม่ทุกสัปดาห์
- จัดการหน้าย่อยและ pagination: Thunderbit ไล่ตามลิงก์และรายการหลายหน้าให้คุณ เหมือนคนที่คลิกไล่ไปทีละหน้า
- Cloud scraping แบบเป็นชุด: รันงานจาก cloud ของ Thunderbit แทนที่จะใช้แล็ปท็อปของคุณ โดยกำหนดขนาด batch ตามแพ็กเกจ (ดู หน้าราคา สำหรับข้อจำกัดปัจจุบัน)
- โค้ดให้น้อยลง ต้องดูแลน้อยลง: คุณไม่ต้องไล่หา selector ที่พังตอนเที่ยงคืนเมื่อเว็บไซต์เปลี่ยน โดน AI อ่านหน้าใหม่ให้อีกครั้ง
ถ้าอยากเจาะลึกกว่านี้ ลองดู วิธีดึงข้อมูลจากเว็บไซต์ใดก็ได้ด้วย AI
เปรียบเทียบ Python Scraping กับ Thunderbit: แบบไหนควรเลือก?
มาวางเทียบกันชัด ๆ:
| ฟีเจอร์ | Python Scraping | Thunderbit |
|---|---|---|
| เวลาในการตั้งค่า | ปานกลาง–สูง (สคริปต์, proxy ฯลฯ) | ต่ำ (2 คลิก ที่เหลือ AI จัดการ) |
| ทักษะทางเทคนิค | ต้องเขียนโค้ด | ไม่ต้องเขียนโค้ด |
| ความน่าเชื่อถือ | แปรผัน (พังง่าย) | สูง (AI ปรับตามการเปลี่ยนแปลง) |
| ความเสี่ยงถูกบล็อก | ปานกลาง–สูง | ต่ำ (AI เลียนแบบผู้ใช้และปรับตัว) |
| การขยายสเกล | ต้องมีโค้ดและ cloud ตั้งเอง | มี cloud/batch scraping ในตัว |
| การดูแลรักษา | บ่อย (เว็บเปลี่ยน, ถูกบล็อก) | น้อยมาก (AI ปรับอัตโนมัติ) |
| ตัวเลือกการส่งออก | ทำเอง (CSV, DB) | ส่งตรงไป Sheets, Notion, Airtable, CSV |
| ค่าใช้จ่าย | ฟรี (แต่กินเวลา) | มีแผนฟรี และแผนเสียเงินสำหรับการใช้งานระดับใหญ่ |
เมื่อไหร่ควรใช้ Python:
- คุณต้องการการควบคุมเต็มรูปแบบ ตรรกะแบบกำหนดเอง หรือการเชื่อมต่อกับ workflow Python อื่น ๆ
- คุณกำลัง scrape เว็บไซต์ที่มีระบบป้องกันบอตน้อย
เมื่อไหร่ควรใช้ Thunderbit:
- คุณต้องการความเร็ว ความเสถียร และไม่ต้องตั้งค่าอะไรเลย
- คุณกำลัง scrape เว็บไซต์ที่ซับซ้อนหรือเปลี่ยนบ่อย
- คุณไม่อยากยุ่งกับ proxy, CAPTCHA หรือโค้ด
ลองใช้ Thunderbit AI Web Scraper ฟรี
คู่มือทีละขั้นตอน: ตั้งค่า Web Scraping โดยไม่ให้ถูกบล็อกใน Python
มาลองดูตัวอย่างใช้งานจริง: ดึงข้อมูลสินค้าจากเว็บไซต์ตัวอย่าง โดยใช้แนวปฏิบัติป้องกันการบล็อกไปพร้อมกัน
1. ติดตั้งไลบรารีที่จำเป็น
pip install requests beautifulsoup4 fake-useragent
2. เตรียมสคริปต์ของคุณ
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # เปลี่ยนเป็น URL ของคุณ
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# ดึงข้อมูลตรงนี้
print(soup.title.text)
else:
print(f"ถูกบล็อกหรือเกิดข้อผิดพลาดที่ {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # หน่วงเวลาแบบสุ่ม
3. เพิ่มการหมุนเวียน Proxy (ตัวเลือกเสริม)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# proxy เพิ่มเติม
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...ส่วนที่เหลือของโค้ด
4. จัดการคุกกี้และเซสชัน
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...ส่วนที่เหลือของโค้ด
5. เคล็ดลับแก้ปัญหา
- ถ้าเจอข้อผิดพลาด 403/429 เยอะ ๆ ให้ชะลอคำขอหรือเปลี่ยน proxy ใหม่
- ถ้าเจอ CAPTCHA ให้ลองใช้ Selenium หรือบริการแก้ CAPTCHA
- ตรวจดู
robots.txtและข้อกำหนดการใช้งานของเว็บไซต์ทุกครั้ง
สรุปและประเด็นสำคัญ
การทำ Web Scraping ใน Python นั้นทรงพลัง—แต่การถูกบล็อกก็ยังเป็นความเสี่ยงต่อเนื่องเมื่อเทคโนโลยีป้องกันบอตพัฒนาไปเรื่อย ๆ วิธีที่ดีที่สุดในการหลีกเลี่ยงการถูกบล็อกคืออะไร? คือการผสานแนวปฏิบัติทางเทคนิคที่ดี (หมุนเวียน proxy, headers ฉลาด ๆ, หน่วงเวลาแบบสุ่ม, จัดการ session และ headless browser) เข้ากับความเคารพกติกาและจริยธรรมของเว็บไซต์
แต่บางครั้ง แม้เทคนิค Python ที่ดีที่สุดก็ยังไม่พอ นั่นคือจุดที่เครื่องมือ AI อย่าง Thunderbit เข้ามา—แบบ no-code ออกแบบมาเพื่อจัดการกับการเปลี่ยนเลย์เอาต์และ pagination ที่ทำให้สคริปต์แข็ง ๆ พัง และเหมาะกับผู้ใช้ธุรกิจที่ไม่อยากเสียเวลาคอยดูแลงาน Selenium ตอนกลางคืน
อยากเห็นไหมว่าการ scraping ทำได้ง่ายแค่ไหน? ดาวน์โหลด Thunderbit Chrome Extension แล้วลองด้วยตัวเอง—หรือเข้าไปดู บล็อก ของเราเพื่อดูเคล็ดลับและบทเรียนเกี่ยวกับการ scraping เพิ่มเติม
คำถามที่พบบ่อย
1. ทำไมเว็บไซต์ถึงบล็อก Python web scraper?
เว็บไซต์บล็อก scraper เพื่อปกป้องข้อมูลของตัวเอง ป้องกันเซิร์ฟเวอร์ทำงานหนักเกินไป และหยุดบอตอัตโนมัติไม่ให้ใช้บริการในทางที่ผิด สคริปต์ Python มักสังเกตได้ง่ายถ้าใช้ headers ค่าเริ่มต้น ไม่จัดการคุกกี้ หรือส่งคำขอถี่เกินไป
2. วิธีที่มีประสิทธิภาพที่สุดในการหลีกเลี่ยงการถูกบล็อกตอน scraping ด้วย Python คืออะไร?
ใช้ rotating proxy ตั้ง user-agent และ headers ให้สมจริง สุ่มเวลาในการส่งคำขอ จัดการคุกกี้/เซสชัน และจำลองพฤติกรรมมนุษย์ด้วยเครื่องมืออย่าง Selenium หรือ Playwright
3. Thunderbit ช่วยหลีกเลี่ยงการถูกบล็อกได้อย่างไรเมื่อเทียบกับสคริปต์ Python?
Thunderbit ใช้ AI ปรับตัวให้เข้ากับเลย์เอาต์ของเว็บ เลียนแบบการท่องเว็บของมนุษย์ และจัดการหน้าย่อยกับ pagination ให้อัตโนมัติ มันลดความเสี่ยงของการถูกบล็อกด้วยการกลมกลืนและอัปเดตวิธีทำงานแบบเรียลไทม์—ไม่ต้องเขียนโค้ดหรือใช้ proxy
4. เมื่อไหร่ควรใช้ Python scraping เทียบกับเครื่องมือ AI อย่าง Thunderbit?
ใช้ Python เมื่อคุณต้องการตรรกะแบบกำหนดเอง การเชื่อมต่อกับโค้ด Python อื่น ๆ หรือกำลัง scrape เว็บไซต์ที่ไม่ซับซ้อน ใช้ Thunderbit สำหรับการ scrape ที่เร็ว เชื่อถือได้ และขยายสเกลได้—โดยเฉพาะเมื่อเว็บไซต์ซับซ้อน เปลี่ยนบ่อย หรือบล็อกสคริปต์อย่างหนัก
5. Web scraping ถูกกฎหมายไหม?
Web scraping ถูกกฎหมายสำหรับข้อมูลที่เปิดเผยต่อสาธารณะ แต่คุณต้องเคารพข้อกำหนดการใช้งาน นโยบายความเป็นส่วนตัว และกฎหมายที่เกี่ยวข้องของแต่ละเว็บไซต์ ห้ามดึงข้อมูลอ่อนไหวหรือข้อมูลส่วนตัว และควรทำอย่างมีจริยธรรมและรับผิดชอบเสมอ
พร้อมจะ scrape อย่างฉลาดขึ้น ไม่ใช่เหนื่อยขึ้นแล้วหรือยัง? ลอง Thunderbit แล้วทิ้งปัญหาการถูกบล็อกไว้ข้างหลัง
อ่านเพิ่มเติม:
- การ scraping Google News ด้วย Python: คู่มือทีละขั้นตอน
- สร้างเครื่องมือติดตามราคาของ Best Buy ด้วย Python
- 14 วิธีทำ Web Scraping โดยไม่ให้ถูกบล็อก
- 10 เคล็ดลับดีที่สุดในการไม่ให้ถูกบล็อกตอนทำ Web Scraping
ลองใช้ AI Web Scraper Get Started Free




