

มีอะไรคลาสสิกมาก ๆ กับการเปิดเทอร์มินัล พิมพ์คำสั่งแค่บรรทัดเดียว แล้วเฝ้าดูข้อมูลเว็บดิบไหลเข้ามา ราวกับเปิดประตูเข้าสู่เมทริกซ์ สำหรับนักพัฒนาและผู้ใช้สายเทคนิคขั้นสูง cURL คือไม้กายสิทธิ์ชิ้นนั้น—เครื่องมือบรรทัดคำสั่งที่ดูไม่หวือหวา แต่ทำงานเงียบ ๆ อยู่ในอุปกรณ์นับพันล้าน ตั้งแต่เซิร์ฟเวอร์คลาวด์ไปจนถึงตู้เย็นอัจฉริยะของคุณ และแม้จะเข้าสู่ปี 2026 แล้ว พร้อมกับเครื่องมือสแครปแบบไม่ต้องเขียนโค้ดและเครื่องมือ AI มากมาย การสแครปเว็บด้วย cURL ก็ยังเป็นตัวเลือกแรก ๆ สำหรับใครก็ตามที่ต้องการความเร็ว การควบคุม และการสั่งงานด้วยสคริปต์
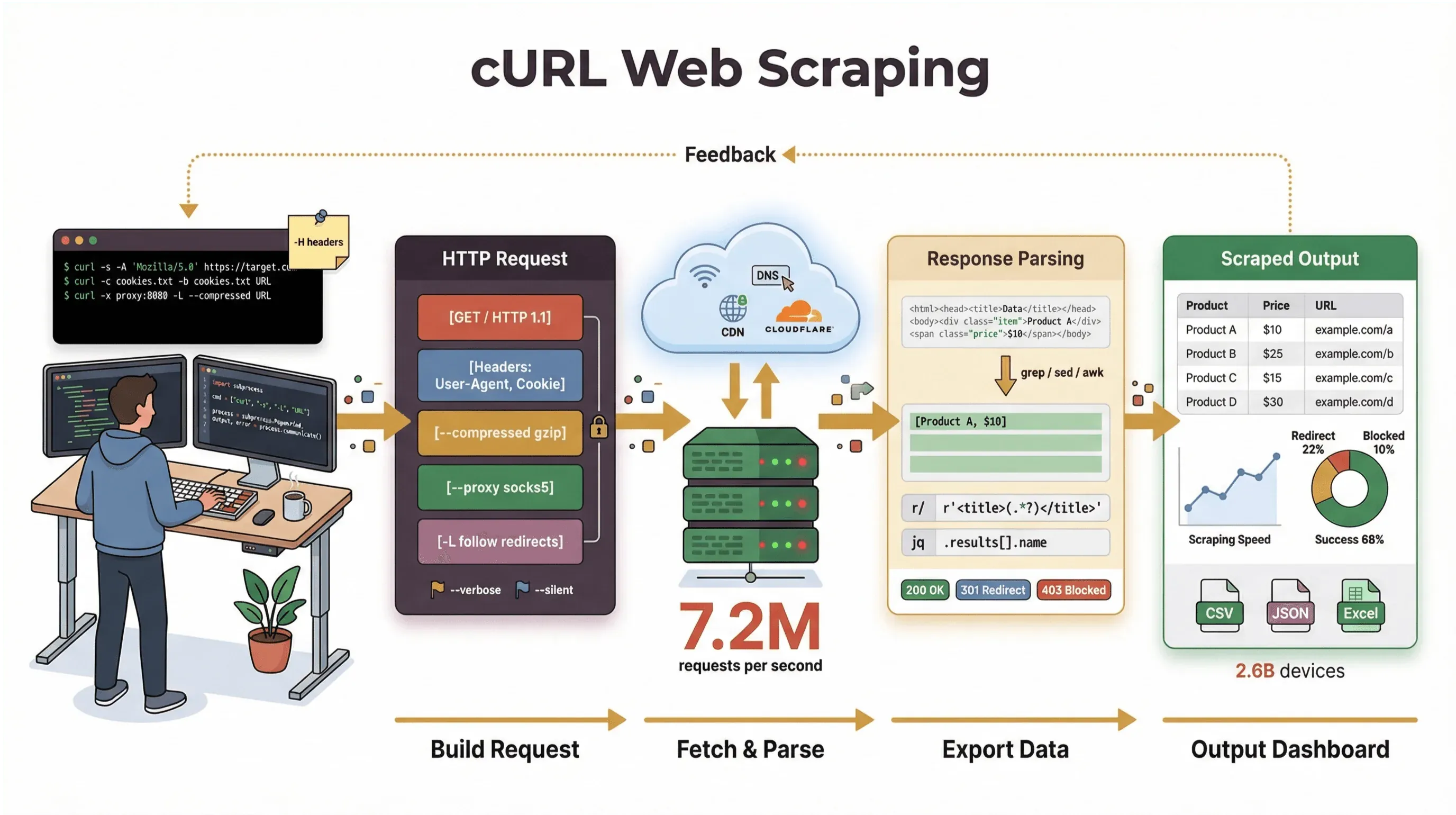 ผมใช้เวลาหลายปีในการสร้างเครื่องมืออัตโนมัติและช่วยทีมต่าง ๆ จัดการข้อมูลเว็บ และผมก็ยังเลือกใช้ cURL เสมอเวลาต้องดึงหน้าเว็บ แก้บั๊ก API หรือทำต้นแบบเวิร์กโฟลว์การสแครป ในคู่มือนี้ ผมจะพาคุณไล่ดูบทสอนการสแครปเว็บด้วย cURL ตั้งแต่พื้นฐานไปจนถึงเทคนิคระดับโปร—พร้อมตัวอย่างคำสั่งจริง เคล็ดลับใช้ได้จริง และมุมมองที่ชัดเจนว่า cURL เด่นตรงไหน (และติดข้อจำกัดตรงไหน) และถ้าคุณเป็นผู้ใช้สายธุรกิจที่ไม่อยากแตะบรรทัดคำสั่ง ผมจะให้ดูด้วยว่า Thunderbit เว็บสแครปเปอร์ที่ขับเคลื่อนด้วย AI ของเรา ช่วยให้คุณเปลี่ยนจาก “ฉันต้องการข้อมูลนี้” ไปเป็น “นี่คือสเปรดชีตของฉัน” ได้ในสองคลิก โดยไม่ต้องเขียนโค้ด
ผมใช้เวลาหลายปีในการสร้างเครื่องมืออัตโนมัติและช่วยทีมต่าง ๆ จัดการข้อมูลเว็บ และผมก็ยังเลือกใช้ cURL เสมอเวลาต้องดึงหน้าเว็บ แก้บั๊ก API หรือทำต้นแบบเวิร์กโฟลว์การสแครป ในคู่มือนี้ ผมจะพาคุณไล่ดูบทสอนการสแครปเว็บด้วย cURL ตั้งแต่พื้นฐานไปจนถึงเทคนิคระดับโปร—พร้อมตัวอย่างคำสั่งจริง เคล็ดลับใช้ได้จริง และมุมมองที่ชัดเจนว่า cURL เด่นตรงไหน (และติดข้อจำกัดตรงไหน) และถ้าคุณเป็นผู้ใช้สายธุรกิจที่ไม่อยากแตะบรรทัดคำสั่ง ผมจะให้ดูด้วยว่า Thunderbit เว็บสแครปเปอร์ที่ขับเคลื่อนด้วย AI ของเรา ช่วยให้คุณเปลี่ยนจาก “ฉันต้องการข้อมูลนี้” ไปเป็น “นี่คือสเปรดชีตของฉัน” ได้ในสองคลิก โดยไม่ต้องเขียนโค้ด
มาดูกันว่าทำไม cURL ถึงยังสำคัญกับการสแครปเว็บในปี 2026 ใช้อย่างไรให้คุ้มค่า และเมื่อไหร่ถึงเวลาต้องหยิบเครื่องมือที่ทรงพลังกว่านี้มาใช้
cURL คืออะไร? พื้นฐานของการสแครปเว็บด้วย cURL
แก่นของมัน cURL คือเครื่องมือบรรทัดคำสั่งและไลบรารีสำหรับโอนย้ายข้อมูลผ่าน URL มันมีมานานเกือบ 30 ปีแล้ว (ใช่, จริง) และพบได้ทุกที่—ฝังอยู่ในระบบปฏิบัติการ ขับเคลื่อนสคริปต์ และจัดการการส่งข้อมูลอย่างเงียบ ๆ ในการติดตั้งมากกว่า สองหมื่นล้านครั้ง ถ้าคุณเคยรันคำสั่งสั้น ๆ เพื่อดึงหน้าเว็บ ทดสอบ API หรือดาวน์โหลดไฟล์ ก็มีโอกาสสูงมากว่าคุณเคยใช้ cURL มาแล้ว
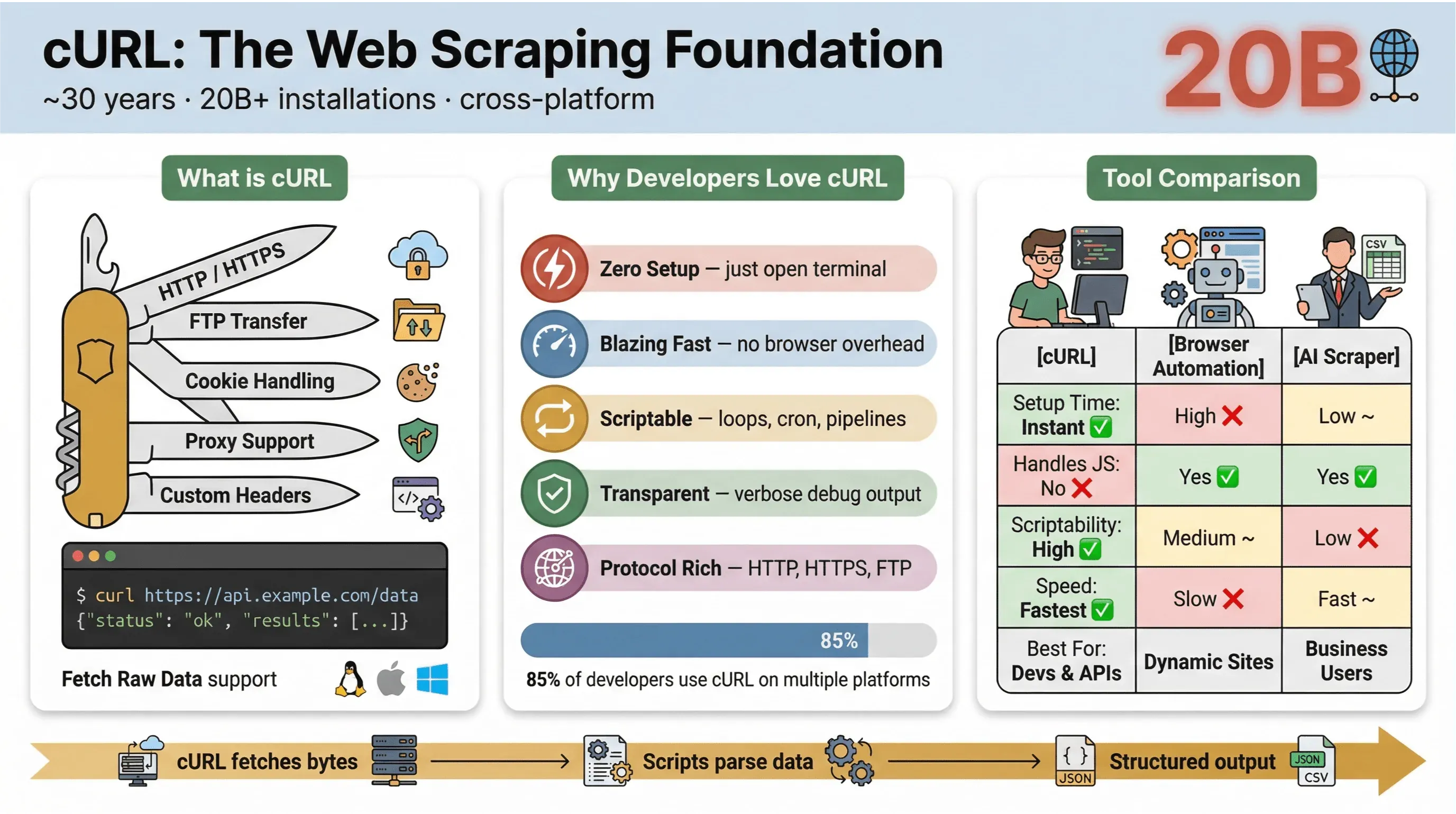 สิ่งที่ทำให้ cURL ได้รับความนิยมมากในการสแครปเว็บคือ:
สิ่งที่ทำให้ cURL ได้รับความนิยมมากในการสแครปเว็บคือ:
- เบาและใช้งานได้ข้ามแพลตฟอร์ม: ใช้ได้บน Linux, macOS, Windows และแม้แต่อุปกรณ์ฝังตัว
- รองรับหลายโปรโตคอล: จัดการ HTTP, HTTPS, FTP และอื่น ๆ
- สั่งงานด้วยสคริปต์ได้: เหมาะกับงานอัตโนมัติ งาน cron และโค้ดเชื่อมต่อระบบ
- ไม่ต้องโต้ตอบกับผู้ใช้: ออกแบบมาสำหรับการใช้งานแบบไม่ต้องมีคนคอยกด เหมาะกับงานแบบ batch และ pipeline
แต่ขอพูดให้ชัด: งานหลักของ cURL คือการดึงข้อมูลดิบ—HTML, JSON, รูปภาพ และอะไรก็ตามที่คุณต้องการ มันไม่ได้ช่วยแยกวิเคราะห์ เรนเดอร์ หรือจัดโครงสร้างข้อมูลให้คุณ ลองมอง cURL เป็น “ไมล์แรก” ของการสแครปเว็บ: มันพาคุณไปถึงบิตข้อมูล แต่คุณยังต้องใช้เครื่องมืออื่น (เช่น สคริปต์ Python, grep/sed/awk หรือ AI web scraper) เพื่อแปลงข้อมูลนั้นให้เป็นข้อมูลที่มีโครงสร้าง
ถ้าอยากดูเอกสารทางการ ลองอ่าน คู่มือการเขียนสคริปต์ HTTP ของ cURL
ทำไมต้องใช้ cURL สำหรับการสแครปเว็บ? (บทสอนการสแครปเว็บด้วย curl)
แล้วทำไมนักพัฒนาและผู้ใช้สายเทคนิคยังกลับมาใช้ cURL สำหรับการสแครปเว็บอยู่เรื่อย ๆ ทั้งที่มีเครื่องมือใหม่ ๆ มากมาย? นี่คือจุดเด่นของ cURL:
- ตั้งค่าน้อย: ไม่ต้องติดตั้ง ไม่ต้องพึ่งพาอะไร แค่เปิดเทอร์มินัลแล้วเริ่มได้เลย
- เร็ว: ดึงข้อมูลได้ทันทีโดยไม่ต้องรอเบราว์เซอร์โหลด
- สั่งงานด้วยสคริปต์ได้: วนลูป URL อัตโนมัติ ส่งคำขอเป็นชุด และต่อคำสั่งได้ง่าย
- รองรับโปรโตคอลและฟีเจอร์หลากหลาย: จัดการคุกกี้ พร็อกซี รีไดเรกต์ เฮดเดอร์แบบกำหนดเอง และอื่น ๆ
- โปร่งใส: ดูได้ชัดเจนว่าเกิดอะไรขึ้นด้วยเอาต์พุตแบบ verbose/debug
จาก แบบสำรวจผู้ใช้ cURL ปี 2025 ผู้ตอบแบบสอบถาม 85.7% บอกว่าใช้เครื่องมือบรรทัดคำสั่ง cURL และ 96.2% ใช้บน Linux ซึ่งยังคงเป็นแพลตฟอร์มอันดับหนึ่งของ cURL แบบทิ้งห่างมาก
--- มันยังคงเป็นมีดพับสวิสสำหรับคำขอ HTTP การดึงข้อมูลแบบรวดเร็ว และการแก้ปัญหาเฉพาะหน้า
นี่คือตารางเปรียบเทียบแบบเร็วระหว่าง cURL กับวิธีสแครปแบบอื่น:
| ฟีเจอร์ | cURL | การทำงานอัตโนมัติผ่านเบราว์เซอร์ (เช่น Selenium) | AI Web Scraper (เช่น Thunderbit) |
|---|---|---|---|
| เวลาในการตั้งค่า | ทันที | สูง | ต่ำ |
| สั่งงานด้วยสคริปต์ | สูง | ปานกลาง | ต่ำ (ไม่ต้องเขียนโค้ด) |
| จัดการ JavaScript | ไม่ได้ | ได้ | ได้ (Thunderbit: ผ่านเบราว์เซอร์) |
| รองรับคุกกี้/เซสชัน | ต้องตั้งเอง | อัตโนมัติ | อัตโนมัติ |
| การจัดโครงสร้างข้อมูล | ต้องทำเอง (ค่อย parse) | ต้องทำเอง (ค่อย parse) | ใช้ AI/เทมเพลต |
| เหมาะที่สุดสำหรับ | นักพัฒนา, ดึงข้อมูลเร็ว ๆ | เว็บไซต์ซับซ้อน, ไดนามิก | ผู้ใช้ธุรกิจ, ส่งออกข้อมูลแบบมีโครงสร้าง |
สรุปสั้น ๆ: cURL แพ้ยากมากสำหรับการดึงข้อมูลแบบเร็วและสั่งงานได้ โดยเฉพาะกับหน้าเว็บแบบคงที่, API หรือเวลาที่คุณต้องการทำเวิร์กโฟลว์ง่าย ๆ ให้อัตโนมัติ แต่พอคุณต้องแยกวิเคราะห์ HTML ที่ซับซ้อน จัดการ JavaScript หรือส่งออกข้อมูลแบบมีโครงสร้าง คุณก็จะอยากใช้เครื่องมือเฉพาะทางมากกว่า
เริ่มต้น: ตัวอย่างคำสั่ง cURL พื้นฐานสำหรับการสแครปเว็บ
มาลงมือกันเลย นี่คือวิธีใช้ cURL สำหรับงานสแครปเว็บพื้นฐาน แบบทีละขั้น
ดึง HTML ดิบด้วย cURL
กรณีใช้งานที่ง่ายที่สุด: ดึง HTML ของหน้าเว็บ
curl https://books.toscrape.com/
คำสั่งนี้จะดึงหน้าแรกของ Books to Scrape ซึ่งเป็นไซต์เดโมสาธารณะสำหรับการสแครปเว็บ คุณจะเห็นเอาต์พุต HTML ดิบในเทอร์มินัล—ลองมองหาทั้งแท็กอย่าง <title> หรือข้อความอย่าง “In stock.”
บันทึกเอาต์พุตลงไฟล์
อยากเก็บ HTML ไว้ค่อยเอาไป parse ทีหลังใช่ไหม? ใช้แฟล็ก -o:
curl -o page.html https://books.toscrape.com/
ตอนนี้คุณจะได้ไฟล์ page.html ที่มี HTML ครบถ้วน เหมาะมากสำหรับการวิเคราะห์ต่อหรือ parse ด้วยเครื่องมืออื่น
ส่งคำขอ POST ด้วย cURL
ต้องส่งฟอร์มหรือคุยกับ API ใช่ไหม? ใช้แฟล็ก -d สำหรับคำขอ POST นี่คือตัวอย่างจาก httpbin เว็บไซต์ที่สร้างมาเพื่อทดสอบ HTTP โดยเฉพาะ:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
คุณจะได้คำตอบ JSON ที่สะท้อนข้อมูลที่ส่งไป เหมาะมากสำหรับการทดสอบและทำต้นแบบ
ดูเฮดเดอร์และดีบัก
บางครั้งคุณอยากดู response headers หรือดีบักคำขอ:
-
ดูเฉพาะเฮดเดอร์ (คำขอ HEAD):
curl -I https://books.toscrape.com/ -
รวมเฮดเดอร์ไปกับเนื้อหา:
curl -i https://httpbin.org/get -
เอาต์พุตแบบ verbose/debug:
curl -v https://books.toscrape.com/
แฟล็กเหล่านี้ช่วยให้เข้าใจว่าเกิดอะไรขึ้นเบื้องหลัง ซึ่งสำคัญมากสำหรับการแก้ปัญหา
นี่คือตารางอ้างอิงสั้น ๆ สำหรับคำสั่งเหล่านี้:
| งาน | ตัวอย่างคำสั่ง | หมายเหตุ |
|---|---|---|
| ดึง HTML | curl URL | แสดง HTML ออกที่เทอร์มินัล |
| บันทึกลงไฟล์ | curl -o file.html URL | เขียนเอาต์พุตลงไฟล์ |
| ตรวจสอบเฮดเดอร์ | curl -I URL หรือ curl -i URL | -I สำหรับ HEAD อย่างเดียว, -i รวมเฮดเดอร์กับเนื้อหา |
| ส่งข้อมูลฟอร์ม POST | curl -d "a=1&b=2" URL | ส่งข้อมูลที่เข้ารหัสแบบฟอร์ม |
| ดีบักคำขอ/คำตอบ | curl -v URL | แสดงรายละเอียดคำขอ/คำตอบ |
ถ้าอยากดูตัวอย่างเพิ่มเติม ลองอ่าน เอกสารการเขียนสคริปต์ของ cURL แบบทางการ
อัปเลเวล: การสแครปเว็บขั้นสูงด้วย cURL (web-scraping-with-curl)
เมื่อคุณคุ้นกับพื้นฐานแล้ว cURL ก็เปิดโลกของฟีเจอร์ขั้นสูงสำหรับงานสแครปที่ซับซ้อนขึ้น
จัดการคุกกี้และเซสชัน
หลายเว็บไซต์ต้องใช้คุกกี้เพื่อคงสถานะล็อกอินหรือใช้ติดตามผู้ใช้ ด้วย cURL คุณสามารถเก็บและนำคุกกี้กลับมาใช้ซ้ำระหว่างคำขอได้:
# เก็บคุกกี้หลังล็อกอิน
curl -c cookies.txt https://example.com/login
# ใช้คุกกี้สำหรับคำขอถัดไป
curl -b cookies.txt https://example.com/account
วิธีนี้ช่วยให้คุณจำลองเซสชันของเบราว์เซอร์และเข้าถึงหน้าที่ซ่อนอยู่หลังล็อกอินได้ (ตราบใดที่ไม่ได้มีด่าน JavaScript)
ปลอม User-Agent และเฮดเดอร์แบบกำหนดเอง
บางเว็บไซต์แสดงเนื้อหาแตกต่างกันตาม User-Agent หรือเฮดเดอร์ที่ส่งไป ตามค่าเริ่มต้น cURL จะระบุตัวเองว่า “curl/VERSION” ซึ่งอาจทำให้ถูกบล็อกหรือได้เนื้อหาอีกแบบ หากต้องการให้เหมือนเบราว์เซอร์:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
คุณยังตั้งเฮดเดอร์แบบกำหนดเองได้ เช่น ความต้องการด้านภาษา:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
วิธีนี้ช่วยให้คุณได้เนื้อหาแบบเดียวกับที่เบราว์เซอร์จริงเห็น
ใช้พร็อกซีสำหรับการสแครปเว็บ
ต้องส่งคำขอผ่านพร็อกซี (เพื่อทดสอบตามภูมิภาคหรือหลีกเลี่ยงการบล็อก IP) ใช้แฟล็ก -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
แต่อย่าลืมใช้พร็อกซีอย่างรับผิดชอบและอยู่ในขอบเขตเงื่อนไขการใช้งานของเว็บไซต์
ทำให้การสแครปหลายหน้าทำงานอัตโนมัติ
อยากสแครปหลายหน้า เช่น รายการสินค้าที่มีการแบ่งหน้า? ใช้ลูปในเชลล์แบบง่าย ๆ:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
คำสั่งนี้จะดึงหน้าที่ 2 ถึง 5 ของแคตตาล็อก Books to Scrape และบันทึกแต่ละหน้าแยกเป็นไฟล์ต่างหาก (หน้า 1 คือหน้าแรก)
ข้อจำกัดของการสแครปเว็บด้วย cURL: สิ่งที่คุณต้องรู้
แม้ผมจะชอบ cURL มาก แต่มันก็ไม่ใช่ยาวิเศษ นี่คือจุดที่มันยังสู้ไม่ไหว:
- ไม่รัน JavaScript: cURL รับมือกับหน้าที่ต้องใช้ JavaScript เพื่อเรนเดอร์เนื้อหาหรือผ่านด่านป้องกันบอทไม่ได้ (developers.cloudflare.com)
- ต้อง parse เอง: คุณจะได้ HTML หรือ JSON ดิบ ๆ แต่ต้องแยกวิเคราะห์เอง—มักต้องใช้สคริปต์หรือเครื่องมือเสริม
- การจัดการเซสชันมีข้อจำกัด: การจัดการล็อกอินที่ซับซ้อน โทเคน หรือฟอร์มหลายขั้นตอนอาจยุ่งเหยิงเร็วมาก
- ไม่มีการจัดโครงสร้างข้อมูลในตัว: cURL ไม่ได้แปลงหน้าเว็บให้เป็นแถว ตาราง หรือสเปรดชีตให้คุณ
- เสี่ยงถูกตรวจจับโดยระบบป้องกันบอท: หลายเว็บไซต์ใช้ระบบป้องกันบอทขั้นสูง (JavaScript, fingerprinting, CAPTCHA) ซึ่ง cURL ไม่สามารถข้ามได้ (datadome.co)
นี่คือตารางเปรียบเทียบแบบเร็ว:
| ข้อจำกัด | cURL อย่างเดียว | เครื่องมือสแครปยุคใหม่ (เช่น Thunderbit) |
|---|---|---|
| รองรับ JavaScript | ไม่ | ได้ |
| การจัดโครงสร้างข้อมูล | ทำเอง | อัตโนมัติ (AI/เทมเพลต) |
| การจัดการเซสชัน | ทำเอง | อัตโนมัติ |
| ข้ามระบบป้องกันบอท | จำกัด | ขั้นสูง (ใช้เบราว์เซอร์/AI) |
| ใช้งานง่าย | เชิงเทคนิค | ไม่ต้องมีพื้นฐานเทคนิค |
สำหรับหน้าเว็บแบบคงที่และ API, cURL นั้นยอดเยี่ยมมาก แต่ถ้าเป็นงานที่ไดนามิกหรือมีการป้องกัน คุณจะอยากขยับไปใช้ชุดเครื่องมือที่เหมาะกว่า
Thunderbit เทียบกับ cURL: แนวทางสแครปเว็บที่ดีที่สุดสำหรับผู้ใช้สายไม่เทคนิค
ตอนนี้มาพูดถึง Thunderbit ส่วนขยาย Chrome สำหรับเว็บสแครปที่ขับเคลื่อนด้วย AI ของเรา ถ้าคุณเป็นเซลส์ นักการตลาด หรือสายปฏิบัติการที่อยากดึงข้อมูลจากเว็บไซต์ลง Excel, Google Sheets หรือ Notion โดยไม่ต้องแตะบรรทัดคำสั่ง Thunderbit คือเครื่องมือที่สร้างมาเพื่อคุณ
นี่คือการเปรียบเทียบ Thunderbit กับ cURL:
| ฟีเจอร์ | cURL | Thunderbit |
|---|---|---|
| หน้าตา/การใช้งาน | บรรทัดคำสั่ง | คลิกเพื่อใช้งาน (ส่วนขยาย Chrome) |
| AI แนะนำฟิลด์ | ไม่มี | มี (AI อ่านหน้าเว็บและแนะนำคอลัมน์) |
| จัดการการแบ่งหน้า/หน้ารอง | ต้องเขียนสคริปต์เอง | อัตโนมัติ (AI ตรวจจับและสแครป) |
| การส่งออกข้อมูล | ทำเอง (parse + บันทึก) | ส่งตรงไป Excel, Google Sheets, Notion, Airtable |
| หน้า JavaScript/หน้าที่มีการป้องกัน | ไม่ได้ | ได้ (สแครปผ่านเบราว์เซอร์) |
| ไม่ต้องเขียนโค้ด | ไม่ (ต้องสคริปต์) | ใช่ (ใครก็ใช้ได้) |
| แพ็กเกจฟรี | ฟรีเสมอ | ฟรีได้สูงสุด 6 หน้า (10 หน้าพร้อมบูสต์ทดลองใช้) |
ด้วย Thunderbit คุณแค่เปิดส่วนขยาย คลิก “แนะนำฟิลด์ด้วย AI” แล้วปล่อยให้ AI ช่วยคิดว่าจะดึงข้อมูลอะไรออกมาได้บ้าง คุณสามารถสแครปตาราง รายการ รายละเอียดสินค้า และยังให้ระบบเข้าไปยังหน้ารองได้โดยอัตโนมัติ จากนั้นก็ส่งออกข้อมูลไปยังเครื่องมือธุรกิจที่คุณชอบได้ตรง ๆ ไม่ต้อง parse ไม่ต้องปวดหัว
Thunderbit ได้รับความไว้วางใจจากผู้ใช้มากกว่า 100,000 คนทั่วโลก และเป็นที่นิยมอย่างยิ่งในทีมขาย อีคอมเมิร์ซ และอสังหาริมทรัพย์ที่ต้องการข้อมูลมีโครงสร้างอย่างรวดเร็ว
ลองใช้ส่วนขยาย Chrome ของ Thunderbit สำหรับการสแครปเว็บ
อยากลองใช่ไหม? ดาวน์โหลดส่วนขยาย Chrome ได้ที่นี่
ใช้ cURL และ Thunderbit ร่วมกัน: กลยุทธ์การสแครปเว็บที่ยืดหยุ่น
ถ้าคุณเป็นผู้ใช้สายเทคนิค ไม่จำเป็นต้องเลือกใช้แค่เครื่องมือเดียว จริง ๆ แล้ว หลายทีมใช้ cURL กับ Thunderbit ร่วมกันเพื่อความยืดหยุ่นสูงสุด:
- ทำต้นแบบด้วย cURL: ใช้ cURL ทดสอบ endpoint ดูเฮดเดอร์ และทำความเข้าใจว่าเว็บไซต์ตอบสนองอย่างไร
- ขยายงานด้วย Thunderbit: เมื่อคุณต้องการข้อมูลมีโครงสร้าง การสแครปหลายหน้า หรือเวิร์กโฟลว์ที่ทำซ้ำได้ ให้เปลี่ยนไปใช้ Thunderbit สำหรับการดึงข้อมูลแบบคลิกแล้วได้ผลลัพธ์และการส่งออกตรง ๆ
นี่คือตัวอย่างเวิร์กโฟลว์สำหรับการวิจัยตลาด:
- ใช้ cURL ดึงไม่กี่หน้าและตรวจดูโครงสร้าง HTML
- ระบุฟิลด์ข้อมูลที่คุณต้องการ (เช่น ชื่อสินค้า ราคา รีวิว)
- เปิด Thunderbit คลิก “แนะนำฟิลด์ด้วย AI” แล้วปล่อยให้ AI ตั้งค่าเครื่องมือสแครป
- สแครปทุกหน้า (รวมถึงหน้ารองหรือรายการที่แบ่งหน้า) แล้วส่งออกไป Google Sheets
- วิเคราะห์ แชร์ และนำข้อมูลไปใช้—ไม่ต้อง parse เอง
นี่คือตารางการตัดสินใจแบบเร็ว:
| สถานการณ์ | ใช้ cURL | ใช้ Thunderbit | ใช้ทั้งคู่ |
|---|---|---|---|
| ดึง API หรือหน้าเว็บแบบคงที่แบบเร็ว | ✅ | ||
| ต้องการข้อมูลมีโครงสร้างในสเปรดชีต | ✅ | ||
| ดีบักเฮดเดอร์/คุกกี้ | ✅ | ||
| สแครปหน้าที่ไดนามิก/ใช้ JS เยอะ | ✅ | ||
| สร้างเวิร์กโฟลว์แบบไม่ต้องเขียนโค้ดที่ทำซ้ำได้ | ✅ | ||
| ทำต้นแบบแล้วค่อยขยายงาน | ✅ | ✅ | เวิร์กโฟลว์แบบผสม |
ความท้าทายและหลุมพรางที่พบบ่อยในการสแครปเว็บด้วย cURL
ก่อนจะลุยเต็มที่กับ cURL มาคุยกันเรื่องความท้าทายในโลกจริงที่คุณจะเจอ:
- ระบบป้องกันบอท: หลายเว็บไซต์ใช้การป้องกันขั้นสูง (JavaScript challenges, CAPTCHA, fingerprinting) ที่ cURL ข้ามไม่ได้ (developers.cloudflare.com)
- ปัญหาคุณภาพข้อมูล: HTML ที่เปลี่ยนไป ฟิลด์ที่หายไป หรือเลย์เอาต์ที่ไม่สม่ำเสมออาจทำให้สคริปต์พัง
- ภาระการบำรุงรักษา: ทุกครั้งที่เว็บไซต์เปลี่ยน คุณต้องอัปเดตตรรกะการ parse ของคุณ
- ความเสี่ยงด้านกฎหมายและการปฏิบัติตามข้อกำหนด: ควรตรวจสอบเงื่อนไขการใช้งานของเว็บไซต์ robots.txt และกฎหมายที่เกี่ยวข้องก่อนสแครปเสมอ ข้อมูลจะเป็นสาธารณะก็ไม่ได้แปลว่านำไปใช้ได้ฟรี (calawyers.org, polsinelli.com)
- ข้อจำกัดด้านสเกล: cURL เหมาะมากกับงานเล็ก ๆ แต่ถ้าจะสแครประดับใหญ่ คุณต้องจัดการพร็อกซี rate limit และการจัดการข้อผิดพลาดเอง
เคล็ดลับสำหรับการแก้ปัญหาและการทำให้สอดคล้องกับข้อกำหนด:
- เริ่มจากไซต์เดโมหรือไซต์ที่อนุญาตเสมอ (เช่น Books to Scrape)
- เคารพ rate limit—อย่ายิงคำขอถี่เกินไป
- หลีกเลี่ยงการสแครปข้อมูลส่วนบุคคล เว้นแต่มีฐานทางกฎหมายรองรับ
- ถ้าชนกำแพง JavaScript หรือ CAPTCHA ให้พิจารณาเปลี่ยนไปใช้เครื่องมือแบบเบราว์เซอร์อย่าง Thunderbit
สรุปทีละขั้น: วิธีสแครปเว็บไซต์ด้วย cURL
นี่คือเช็กลิสต์อ้างอิงเร็วสำหรับการสแครปเว็บด้วย cURL:
- ระบุ URL เป้าหมายของคุณ: เริ่มจากหน้าแบบคงที่หรือ endpoint ของ API
- ดึงหน้าเว็บ:
curl URL - บันทึกเอาต์พุตลงไฟล์:
curl -o file.html URL - ดูเฮดเดอร์/ดีบัก:
curl -I URL,curl -v URL - ส่งข้อมูล POST:
curl -d "a=1&b=2" URL - จัดการคุกกี้/เซสชัน:
curl -c cookies.txt ...,curl -b cookies.txt ... - ตั้งเฮดเดอร์/User-Agent แบบกำหนดเอง:
curl -A "..." -H "..." URL - ตามรีไดเรกต์:
curl -L URL - ใช้พร็อกซี (ถ้าจำเป็น):
curl -x proxy:port URL - ทำการสแครปหลายหน้าให้เป็นอัตโนมัติ: ใช้ลูปในเชลล์หรือสคริปต์
- แยกวิเคราะห์และจัดโครงสร้างข้อมูล: ใช้เครื่องมือหรือสคริปต์เสริมตามต้องการ
- เปลี่ยนไปใช้ Thunderbit สำหรับการสแครปแบบมีโครงสร้าง ไม่ต้องเขียนโค้ด หรือหน้าเว็บไดนามิก
บทสรุปและประเด็นสำคัญ: การเลือกเครื่องมือสแครปเว็บที่เหมาะสม
ดึงข้อมูลจากทุกเว็บไซต์ได้ด้วย AI Get Started Free
การสแครปเว็บด้วย cURL ยังคงเป็นทักษะทรงพลังสำหรับผู้ใช้สายเทคนิคในปี 2026—โดยเฉพาะสำหรับการดึงข้อมูลเร็ว ๆ การทำต้นแบบ และงานอัตโนมัติ ความเร็ว ความสามารถในการสั่งงานด้วยสคริปต์ และความแพร่หลายของ cURL ทำให้มันเป็นของที่อยู่คู่กล่องเครื่องมือของนักพัฒนา แต่เมื่อเว็บมีความไดนามิกมากขึ้นและมีการป้องกันมากขึ้น รวมถึงเมื่อผู้ใช้สายธุรกิจต้องการข้อมูลมีโครงสร้างโดยไม่ต้องเขียนโค้ด เครื่องมืออย่าง Thunderbit ก็กำลังกำหนดนิยามใหม่ของสิ่งที่เป็นไปได้
ประเด็นสำคัญ:
- ใช้ cURL สำหรับหน้าเว็บแบบคงที่, API และการทำต้นแบบแบบเร็ว ๆ โดยเฉพาะเมื่อคุณต้องการควบคุมทุกอย่างได้เต็มที่
- เปลี่ยนไปใช้ Thunderbit (หรือ AI web scraper อื่น ๆ) เมื่อคุณต้องการข้อมูลมีโครงสร้าง ต้องรับมือกับหน้าเว็บที่ไดนามิก/ใช้ JavaScript หนัก หรืออยากได้เวิร์กโฟลว์แบบไม่ต้องเขียนโค้ดที่เหมาะกับงานธุรกิจ
- ใช้ทั้งสองอย่างร่วมกันเพื่อความยืดหยุ่นสูงสุด: ทำต้นแบบด้วย cURL แล้วค่อยขยายและจัดโครงสร้างด้วย Thunderbit
- สแครปอย่างรับผิดชอบเสมอ—เคารพเงื่อนไขเว็บไซต์ rate limit และขอบเขตทางกฎหมาย
อยากเห็นไหมว่าการสแครปเว็บจะง่ายแค่ไหน? ลองใช้ส่วนขยาย Chrome ฟรีของ Thunderbit แล้วสัมผัสการดึงข้อมูลด้วย AI ด้วยตัวเอง และถ้าคุณอยากลงลึกกว่านี้ ลองดู บล็อกของ Thunderbit เพื่ออ่านบทสอน เคล็ดลับ และอินไซต์อุตสาหกรรมเพิ่มเติม คุณอาจจะชอบด้วย:
- วิธีสแครปทุกเว็บไซต์ด้วย AI
- วิธีสแครปข้อมูลเว็บไซต์ลง Excel ด้วย AI
- การสแครปข้อมูลคืออะไร และทำอย่างไรในปี 2025
ขอให้สนุกกับการสแครป—และขอให้ข้อมูลของคุณสะอาด มีโครงสร้าง และอยู่แค่ห่างจากคำสั่งหนึ่งบรรทัดหรือหนึ่งคลิกเสมอ
สำรวจแพ็กเกจ Thunderbit สำหรับการสแครปเว็บแบบรองรับการขยายตัว
คำถามที่พบบ่อย
1. cURL จัดการหน้าเว็บที่เรนเดอร์ด้วย JavaScript ได้ไหม?
ไม่ได้ cURL ไม่สามารถรัน JavaScript ได้ มันดึง HTML ดิบตามที่เซิร์ฟเวอร์ส่งมาเท่านั้น ถ้าหน้าเว็บต้องใช้ JavaScript เพื่อเรนเดอร์เนื้อหาหรือผ่านด่านป้องกันบอท cURL จะเข้าถึงข้อมูลนั้นไม่ได้ สำหรับกรณีนั้นให้ใช้เครื่องมือแบบเบราว์เซอร์อย่าง Thunderbit
2. จะบันทึกเอาต์พุตของ cURL ลงไฟล์โดยตรงได้อย่างไร?
ใช้แฟล็ก -o: curl -o filename.html URL คำสั่งนี้จะเขียนเนื้อหาตอบกลับลงไฟล์แทนที่จะแสดงในเทอร์มินัล
3. cURL กับ Thunderbit ต่างกันอย่างไรสำหรับการสแครปเว็บ?
cURL เป็นเครื่องมือบรรทัดคำสั่งสำหรับดึงข้อมูลเว็บดิบ ๆ เหมาะกับผู้ใช้สายเทคนิคและงานอัตโนมัติ Thunderbit เป็นส่วนขยาย Chrome ที่ขับเคลื่อนด้วย AI ออกแบบมาสำหรับผู้ใช้ธุรกิจที่ต้องการดึงข้อมูลมีโครงสร้างจากทุกเว็บไซต์ จัดการหน้าไดนามิก และส่งออกตรงไปยังเครื่องมืออย่าง Excel หรือ Google Sheets โดยไม่ต้องเขียนโค้ด
4. การสแครปเว็บไซต์ด้วย cURL ถูกกฎหมายไหม?
โดยทั่วไปการสแครปข้อมูลสาธารณะถือว่าถูกกฎหมายในสหรัฐฯ หลังคำตัดสินของศาลล่าสุด แต่ควรตรวจสอบเงื่อนไขการใช้งานของเว็บไซต์ robots.txt และกฎหมายที่เกี่ยวข้องเสมอ หลีกเลี่ยงการสแครปข้อมูลส่วนบุคคลหรือข้อมูลที่ได้รับการคุ้มครองโดยไม่ได้รับอนุญาต และเคารพ rate limit กับหลักจริยธรรม (calawyers.org, polsinelli.com)
5. ควรเปลี่ยนจาก cURL ไปใช้เครื่องมือขั้นสูงอย่าง Thunderbit เมื่อไหร่?
ถ้าคุณต้องสแครปหน้าเว็บที่ไดนามิก/ใช้ JavaScript หนัก อยากได้ข้อมูลมีโครงสร้างในสเปรดชีต หรือชอบเวิร์กโฟลว์แบบไม่ต้องเขียนโค้ด Thunderbit คือทางเลือกที่ดีกว่า ใช้ cURL สำหรับงานเร็ว ๆ เชิงเทคนิค; ใช้ Thunderbit สำหรับการดึงข้อมูลที่เหมาะกับงานธุรกิจและทำซ้ำได้
สำหรับเคล็ดลับและบทสอนการสแครปเว็บเพิ่มเติม เยี่ยมชม บล็อกของ Thunderbit หรือดู ช่อง YouTube ของเรา
ลองใช้ Thunderbit AI Web Scraper Get Started Free




