การทำ Web Scraping ผิดกฎหมายหรือไม่? นี่คือคำถามมูลค่าหลายล้านที่ผมได้ยินจากผู้ก่อตั้ง นักการตลาด และสายข้อมูลทุกสัปดาห์
ด้วย —เป็นครั้งแรกที่ทราฟฟิกอัตโนมัติแซงกิจกรรมของมนุษย์—and ซึ่งส่วนใหญ่เป็นการทำ Web Scraping เพื่อใช้ในธุรกิจ ข่าวกรองการขาย และการฝึก AI ก็ไม่แปลกเลยที่ทุกคนพยายามหาว่าเส้นกฎหมายอยู่ตรงไหน
วันหนึ่งคุณอาจเห็นพาดหัวข่าวว่าศาลตัดสินว่าการดึงข้อมูลสาธารณะทำได้ตามกฎหมาย อีกวันหนึ่งหน่วยงานกำกับดูแลก็ออกมาเตือนเรื่องการรวบรวมข้อมูลจากโซเชียลมีเดียแบบ "ผิดกฎหมาย" มันชวนสับสน แม้แต่กับคนอย่างผมที่ใช้เวลาทั้งวันสร้างเครื่องมือ AI Web Scraper ที่
แล้ว Web Scraping ผิดกฎหมายหรือไม่? คำตอบไม่ได้มีแค่ใช่หรือไม่ใช่ มันขึ้นอยู่กับว่าคุณกำลังดึงข้อมูลอะไร ดึงจากที่ไหน ใช้ข้อมูลนั้นอย่างไร และกฎหมายในประเทศของคุณว่าไว้อย่างไร
ในบทความเชิงลึกนี้ ผมจะอธิบายภาพรวมทางกฎหมาย แยกแยะความเชื่อผิด ๆ ที่พบบ่อย และแชร์เคล็ดลับใช้งานจริง (พร้อมเรื่องเล่าจากสนามจริงเล็กน้อย) เพื่อให้คุณทำงานได้อย่างสอดคล้องกับกฎหมาย—ไม่ว่าคุณจะเป็นผู้ก่อตั้งเดี่ยว ๆ หรือทีมข้อมูลในบริษัท Fortune 500
Web Scraping กับกฎหมาย: มีเส้นแบ่งที่ชัดเจนไหม?
ถ้าคุณหวังคำตอบสั้น ๆ ในประโยคเดียว ผมขอบอกไว้เลยว่า: กฎหมายยังไม่ได้ขีดเส้นแบ่งที่ชัดเจนและสว่างจ้าให้กับ Web Scraping
แต่สิ่งที่มีคือชุดกฎที่ทับซ้อนกันหลายชั้น—เรื่องกรรมสิทธิ์ข้อมูล ความเป็นส่วนตัว ทรัพย์สินทางปัญญา กฎหมายต่อต้านการแฮ็ก และข้อกำหนดการใช้งานหรือ Terms of Service (ToS) ที่ขึ้นชื่อ แต่ละอย่างอาจเข้ามาเกี่ยวข้องได้ และคำตอบมักขึ้นอยู่กับสถานการณ์เฉพาะของคุณ ()
มาดู 3 หมวดกฎหมายหลักกัน:
- กรรมสิทธิ์ข้อมูล: โดยทั่วไป ข้อเท็จจริงและข้อมูลสาธารณะ เช่น ราคา หรือเบอร์โทรศัพท์ มักไม่สามารถจดลิขสิทธิ์ได้ แต่เนื้อหาสร้างสรรค์ เช่น บทความ รูปภาพ และฐานข้อมูลที่เป็นกรรมสิทธิ์ อาจได้รับความคุ้มครอง—โดยเฉพาะในสหภาพยุโรปที่มีกฎหมาย "สิทธิในฐานข้อมูล" โดยตรง ().
- ความเป็นส่วนตัว: กฎหมายคุ้มครองข้อมูลส่วนบุคคลสมัยใหม่ เช่น GDPR ในยุโรป และ PIPL ในจีน มองว่าข้อมูลส่วนบุคคลเป็นสินทรัพย์ที่อยู่ภายใต้การกำกับดูแล แม้จะถูกโพสต์แบบสาธารณะก็ตาม การดึงชื่อ อีเมล หรือโปรไฟล์โซเชียลโดยไม่มีฐานทางกฎหมายอาจทำให้คุณมีปัญหาได้ ().
- สัญญา (ข้อกำหนดการใช้งาน): หลายเว็บไซต์ห้ามการดึงข้อมูลอย่างชัดเจนใน ToS แม้ ToS จะไม่ใช่กฎหมาย แต่ศาลสามารถมองว่ามันเป็นสัญญาที่มีผลผูกพันได้ การฝ่าฝืนอาจนำไปสู่คดีความ และในบางกรณียังอาจเข้าข่ายกฎหมายต่อต้านการแฮ็ก หากคุณหลีกเลี่ยงมาตรการทางเทคนิค ().
แล้ว Web Scraping ผิดกฎหมายหรือไม่? บางครั้งใช่ บางครั้งไม่ใช่ และบ่อยครั้งคือ "แล้วแต่กรณี" รายละเอียดเล็ก ๆ นั่นแหละคือจุดสำคัญ
เปรียบเทียบมุมมองทางกฎหมาย: สหรัฐฯ สหภาพยุโรป สหราชอาณาจักร จีน
นี่คือตารางสรุปให้เห็นว่าแต่ละภูมิภาคมอง Web Scraping อย่างไร:
| ภูมิภาค | การดึงข้อมูลสาธารณะ | การดึงข้อมูลส่วนบุคคล/ข้อมูลส่วนตัว | การบังคับใช้และประเด็นสำคัญ |
|---|---|---|---|
| สหรัฐฯ | โดยทั่วไปอนุญาตสำหรับข้อมูลสาธารณะ (ดู hiQ v. LinkedIn). การฝ่าฝืน ToS อาจนำไปสู่คดีแพ่ง | ถูกจำกัด/ผิดกฎหมายหากคุณฝ่าด่านล็อกอินหรือใช้ข้อมูลส่วนบุคคลในทางที่ผิด กฎหมายระดับรัฐ เช่น CCPA อาจมีผลบังคับใช้ | จดหมายสั่งหยุดและเลิกทำ การบล็อก IP คดีความ CFAA ใช้เมื่อคุณเลี่ยงอุปสรรคทางเทคนิค |
| สหภาพยุโรป | อนุญาตแบบมีเงื่อนไขสำหรับข้อมูลสาธารณะที่ไม่ใช่ข้อมูลส่วนบุคคล สิทธิในฐานข้อมูลอาจนำมาใช้ได้ EU AI Act (2026) เพิ่มข้อกำหนดเรื่องความโปร่งใสของข้อมูลฝึก AI | ถูกกำกับอย่างเข้มภายใต้ GDPR—แม้ข้อมูลส่วนบุคคลที่เปิดเผยต่อสาธารณะก็ยังต้องมีฐานทางกฎหมาย | หน่วยงานคุ้มครองข้อมูลสามารถปรับโทษเมื่อมีการละเมิดความเป็นส่วนตัว ลิขสิทธิ์/สิทธิในฐานข้อมูลก็ถูกบังคับใช้ด้วย EU AI Act ห้ามการดึงภาพใบหน้าจากอินเทอร์เน็ตเพื่อใช้กับ AI |
| สหราชอาณาจักร | คล้ายสหภาพยุโรป ข้อมูลสาธารณะที่ไม่ใช่ข้อมูลส่วนบุคคลสามารถดึงได้ แต่ต้องเคารพสิทธิข้อมูลและสัญญา | เข้มงวดกับข้อมูลส่วนบุคคล—UK GDPR มีผลบังคับใช้ Computer Misuse Act เอาผิดการเข้าถึงโดยไม่ได้รับอนุญาต | ICO สามารถลงโทษการละเมิดการคุ้มครองข้อมูลได้ ศาลอาจบังคับใช้ ToS |
| จีน | ควบคุมอย่างเข้ม ข้อมูลสาธารณะที่ไม่ใช่ข้อมูลส่วนบุคคลอาจดึงใช้ภายในได้ แต่โดยรวมระมัดระวังมาก | ถูกจำกัดอย่างมาก—PIPL ต้องได้รับความยินยอมสำหรับข้อมูลส่วนบุคคล กฎหมายแข่งขันทางการค้าที่ไม่เป็นธรรมก็มีผล | มีคดีอาญาสำหรับการดึงข้อมูลขนาดใหญ่ ศาลใช้กฎหมายแข่งขันที่ไม่เป็นธรรมเพื่อหยุดการดึงข้อมูลที่ไม่ได้รับอนุญาต |
(, )
การทำ Web Scraping ผิดกฎหมายหรือไม่? ปัจจัยทางกฎหมายสำคัญที่ต้องพิจารณา
แล้วอะไรคือสิ่งที่ตัดสินว่าการทำ Scraping ของคุณถูกกฎหมายหรือมีความเสี่ยง? ปัจจัยสำคัญมีดังนี้:
- ข้อมูลสาธารณะเทียบกับข้อมูลส่วนตัว: การดึงข้อมูลที่ใคร ๆ ก็เห็นได้บนเว็บเปิดทั่วไปมักปลอดภัยกว่า แต่ถ้าเป็นข้อมูลที่อยู่หลังล็อกอิน เพย์วอลล์ หรือกำแพงทางเทคนิค? แบบนั้นมีแนวโน้มจะผิดกฎหมาย ().
- ลักษณะของข้อมูล: ข้อมูลส่วนบุคคล เช่น ชื่อ อีเมล โปรไฟล์ จะกระตุ้นให้กฎหมายความเป็นส่วนตัวเข้ามาเกี่ยวข้อง เนื้อหาที่มีลิขสิทธิ์ เช่น บทความและรูปภาพ ไม่ควรถูกคัดลอกทั้งชุด ส่วนข้อเท็จจริงล้วน ๆ เช่น ราคา หรือสภาพอากาศ มักทำได้ค่อนข้างเสรี ().
- วัตถุประสงค์การใช้งาน: การวิเคราะห์ภายในหรือการวิจัยมักถูกมองผ่อนปรนมากกว่าการนำข้อมูลที่ดึงมาไปเผยแพร่ซ้ำหรือขายต่อ ถ้าเอาข้อมูลที่ดึงมาไปใช้แข่งกับแหล่งข้อมูลต้นทางโดยตรง? นั่นคือสูตรสำเร็จของคดีความ ().
- การปฏิบัติตามกฎของเว็บไซต์: ตรวจสอบ robots.txt และ ToS เสมอ robots.txt ไม่ได้ผูกพันตามกฎหมาย แต่การเคารพเป็นแนวปฏิบัติที่ดี การละเมิด ToS อาจทำให้เกิดคดีแพ่งหรือแย่กว่านั้น ().
- มาตรการทางเทคนิค: การดึงข้อมูลด้วยความเร็วที่เหมือนมนุษย์ และไม่เลี่ยงมาตรการความปลอดภัยคือเรื่องสำคัญ การยิงคำขอถี่เกินไปหรือหลบ CAPTCHA อาจข้ามเส้นไปสู่การแฮ็กได้ ().
อะไรเปลี่ยนไปในช่วงปี 2024–2026: คดีความและกฎระเบียบสำคัญ
ภูมิทัศน์ทางกฎหมายของ Web Scraping เปลี่ยนไปมากตั้งแต่ปี 2023 นี่คือพัฒนาการที่คนทำ Scraper ทุกคนควรรู้:
คำตัดสินคดีสำคัญ
-
Meta v. Bright Data (2024): ศาลรัฐบาลกลางสหรัฐฯ ผู้พิพากษาเห็นว่า "ผู้เยี่ยมชมไม่ถือเป็น 'ผู้ใช้' เว้นแต่จะมีบัญชี" Meta ถอนข้อเรียกร้องที่เหลือไม่นานหลังจากนั้น นี่คือชัยชนะครั้งสำคัญของการดึงข้อมูลสาธารณะ
-
X Corp v. Bright Data (2024): Twitter (ปัจจุบันคือ X) แพ้คดีลักษณะคล้ายกัน ยืนยันหลักการเดียวกันว่า การดึงข้อมูลที่เปิดให้เข้าถึงสาธารณะโดยไม่ต้องล็อกอินไม่ถือเป็นการละเมิด ToS เพราะผู้ดึงข้อมูลไม่ได้ยอมรับเงื่อนไขเหล่านั้นตั้งแต่แรก
-
Reddit v. Perplexity AI (ตุลาคม 2025): Reddit โดยอ้าง DMCA และกล่าวหาว่ามีการเลี่ยงระบบป้องกันบอท นี่สะท้อนกลยุทธ์ทางกฎหมายแบบใหม่: แพลตฟอร์มหันไปใช้ ข้อเรียกร้องด้านลิขสิทธิ์และการหลบเลี่ยงมาตรการป้องกัน แทน CFAA
-
NYT v. OpenAI (มีนาคม 2025): ผู้พิพากษารัฐบาลกลาง โดยปฏิเสธคำร้องของ OpenAI ที่ต้องการยกฟ้อง คดีนี้อาจกลายเป็นบรรทัดฐานสำคัญว่า การดึงเนื้อหาไปฝึกโมเดล AI ถือเป็น "fair use" หรือไม่
-
ข้อตกลงของ Anthropic (กันยายน 2025): Anthropic ตกลงจ่าย 1.5 พันล้านดอลลาร์เพื่อยุติคดีรวมในสหรัฐฯ เกี่ยวกับการใช้ข้อความที่มีลิขสิทธิ์เพื่อฝึกโมเดล AI ของตน—สะท้อนว่าต้นทุนของการดึงข้อมูลเพื่อ AI นั้นมีอยู่จริง
แนวโน้มใหญ่: จาก CFAA ไปสู่กฎหมายสัญญาและลิขสิทธิ์
รูปแบบชัดเจนมาก: CFAA (Computer Fraud and Abuse Act) กำลังสูญเสียพลังในฐานะอาวุธต่อผู้ที่ดึงข้อมูลสาธารณะ บริษัทที่พยายามใช้ CFAA เล่นงานการดึงข้อมูลสาธารณะ—Meta, X, LinkedIn—ส่วนใหญ่ไม่สำเร็จ แต่สนามกฎหมายกำลังย้ายไปที่:
- กฎหมายสัญญา (การละเมิด ToS—แต่ศาลกำลังบอกว่าผู้ที่ไม่ใช่ผู้ใช้ไม่ได้ถูกผูกพันด้วย ToS)
- ข้อเรียกร้องด้านลิขสิทธิ์ (โดยเฉพาะข้อมูลฝึก AI)
- กฎหมายต่อต้านการเลี่ยงมาตรการป้องกัน (DMCA มาตรา 1201)
สำหรับคนทำ Scraper นั่นหมายความว่าความเสี่ยงทางกฎหมายไม่ได้หายไป—แค่ย้ายที่เท่านั้น
การเปลี่ยนแปลงด้านกฎระเบียบ
- อัปเดต CCPA ปี 2026: กฎ CCPA ฉบับปรับปรุงของแคลิฟอร์เนีย เพิ่มกฎใหม่สำหรับเทคโนโลยีการตัดสินใจอัตโนมัติ (ADMT) การประเมินความเสี่ยง และภาระหน้าที่ของ data broker
- กฎหมายความเป็นส่วนตัวระดับรัฐในสหรัฐฯ ฉบับใหม่: Indiana, Kentucky และ Rhode Island ออกกฎหมายความเป็นส่วนตัวแบบครอบคลุมซึ่งมีผลในปี 2026
- EU AI Act: การบังคับใช้เต็มรูปแบบเริ่มขึ้น —กำหนดให้นักพัฒนา AI ต้องเปิดเผยแหล่งที่มาของข้อมูลฝึก เคารพการไม่ยินยอมให้ใช้ลิขสิทธิ์ และห้ามการดึงภาพใบหน้าสำหรับระบบ AI
- AI Accountability for Publishers Act (กุมภาพันธ์ 2026): ร่างกฎหมายสหรัฐฯ ที่จะบังคับให้บริษัท AI ต้องขออนุญาตและจ่ายค่าตอบแทนให้สำนักพิมพ์ก่อนดึงเนื้อหาของพวกเขา
นโยบายการทำ Scraping ของแพลตฟอร์มใหญ่: สิ่งที่คุณต้องรู้
ไม่ใช่ทุกเว็บไซต์ที่จะมองการดึงข้อมูลเหมือนกัน นี่คือภาพรวมรายแพลตฟอร์มว่าเว็บไซต์ใหญ่ ๆ อนุญาตอะไร บล็อกอะไร และศาลเคยวินิจฉัยไว้อย่างไร:
| แพลตฟอร์ม | ToS เกี่ยวกับการดึงข้อมูล | มาตรการทางเทคนิค | การบังคับใช้ทางกฎหมาย | อะไรที่ถือว่าปลอดภัยในทางปฏิบัติ |
|---|---|---|---|---|
| Google (Search & Maps) | ห้ามการเข้าถึงแบบอัตโนมัติใน ToS และ Maps Platform มีข้อกำหนด "No Scraping" ชัดเจน | SearchGuard JS challenges, CAPTCHA, rate limiting อัปเดต robots.txt ในปี 2025 เพื่อบล็อก AI crawler | ฟ้องผู้ดึงข้อมูลในเดือนธันวาคม 2025 โดยใช้ DMCA และบล็อก AI crawler อย่างจริงจัง (Anthropic, Meta, OpenAI) | การดึงข้อมูลธุรกิจสาธารณะจาก Google Maps มีเหตุผลรองรับทางกฎหมาย (ตามบรรทัดฐาน hiQ) แต่คาดว่าจะโดนบล็อกทางเทคนิค ใช้ API ทางการเมื่อทำได้ |
| Amazon | ห้ามการดึงข้อมูลทุกรูปแบบอย่างชัดเจนใน Conditions of Use ("ห้ามใช้หุ่นยนต์ สไปเดอร์ สแครปเปอร์ หรือวิธีอัตโนมัติอื่นใด") | ตรวจจับบอทอย่างเข้มงวด, CAPTCHA, การบล็อก IP, robots.txt บล็อกบอททั้งหมด ยกเว้น Googlebot/Bingbot และตั้งแต่ปี 2025 ก็บล็อก AI crawler ด้วย | ฟ้อง Perplexity AI ในเดือนพฤศจิกายน 2025 และส่งจดหมายสั่งหยุดและเลิกทำเป็นประจำ ปรับ BSA ในเดือนมีนาคม 2026 ให้มีกฎสำหรับ AI agent | ข้อมูลสินค้าสาธารณะ เช่น ราคาและรายการสินค้า เป็นข้อเท็จจริงที่ดึงได้ภายใต้กฎหมายสหรัฐฯ แต่ Amazon เอาจริงมาก ควรจำกัดอัตราคำขอและหลีกเลี่ยงข้อมูลส่วนบุคคล |
| ห้ามการดึงข้อมูลใน ToS และกำหนดให้ผู้ใช้ต้องยอมรับเงื่อนไขก่อนเข้าถึงบริการ | ใช้กำแพงล็อกอินกับข้อมูลโปรไฟล์ส่วนใหญ่ ตรวจจับบอท และจำกัดอัตรา | คดี hiQ ยืนยันว่าการดึงโปรไฟล์สาธารณะที่ไม่ต้องล็อกอินไม่ละเมิด CFAA แต่ LinkedIn ชนะคดีในข้อเรียกร้องด้านสัญญา/การแข่งขันไม่เป็นธรรมเมื่อมีการใช้บัญชีปลอม | โปรไฟล์สาธารณะที่มองเห็นได้โดยไม่ต้องล็อกอินสามารถดึงได้ในทางกฎหมาย อย่าสร้างบัญชีปลอมและอย่าดึงข้อมูลที่อยู่หลังล็อกอิน | |
| Meta (Facebook & Instagram) | ToS ห้ามการดึงข้อมูล และมีกฎแยกกันสำหรับข้อมูลที่ล็อกอินกับไม่ล็อกอิน | ใช้กำแพงล็อกอินกับคอนเทนต์ส่วนใหญ่ และมีระบบตรวจจับบอทขั้นสูง | แพ้ Bright Data ในปี 2024—ศาลตัดสินว่า ToS ใช้กับผู้ที่ไม่ได้ล็อกอินไม่ได้ และ Meta ถอนข้อเรียกร้องที่เหลือ | ข้อมูลสาธารณะ เช่น หน้าเพจธุรกิจและโพสต์สาธารณะที่มองเห็นโดยไม่ต้องล็อกอินอยู่ในพื้นที่ปลอดภัยกว่า อย่าดึงโปรไฟล์ส่วนตัวหรือข้อมูลหลังล็อกอิน |
| X (Twitter) | อัปเดต ToS ในปี 2023 เพื่อห้ามการดึงและการ crawl ทั้งหมดโดยไม่ได้รับความยินยอมเป็นลายลักษณ์อักษร และยกเลิกข้อยกเว้น robots.txt เดิม | robots.txt บล็อก crawler ทั้งหมด (Disallow: /), Cloudflare Turnstile, จำกัดอัตราเข้มงวด (300 คำขอ/ชั่วโมง), ให้คะแนนความน่าเชื่อถือของ IP | แพ้ Bright Data ในประเด็นข้อมูลสาธารณะ แต่ยังคงจำกัดการเข้าถึงทางเทคนิคอย่างหนัก | ทวีตและโปรไฟล์สาธารณะยังพอมีเหตุผลรองรับทางกฎหมาย แต่กำแพงทางเทคนิคของ X ในปี 2026 นับว่าโหดมาก ควรคาดว่าจะโดนบล็อกหากไม่มีโครงสร้างพร็อกซีระดับพรีเมียม |
สรุปสั้น ๆ: ศาลมักตัดสินสอดคล้องกันว่า การดึง ข้อมูลที่มองเห็นได้สาธารณะโดยไม่ต้องล็อกอิน ไม่ละเมิด CFAA แต่แพลตฟอร์มยังสามารถเล่นงานคุณด้วยกฎหมายสัญญา ลิขสิทธิ์ หรือกฎหมายต่อต้านการเลี่ยงมาตรการป้องกันได้—and พวกเขาจะทำให้ชีวิตคุณลำบากด้วยกำแพงทางเทคนิคเสมอ ควรดึงข้อมูลอย่างรับผิดชอบ
ข้อมูลฝึก AI กับ Web Scraping: สมรภูมิทางกฎหมายใหม่
ถ้าคุณติดตามข่าวในปี 2026 คุณจะรู้ว่า การดึงข้อมูลไปฝึกโมเดล AI กลายเป็นสมรภูมิทางกฎหมายที่ร้อนแรงที่สุด นี่คือสิ่งที่กำลังเกิดขึ้น:
- คดีลิขสิทธิ์กำลังเพิ่มขึ้นเรื่อย ๆ New York Times, นักเขียน และสำนักพิมพ์ต่างฟ้อง OpenAI, Anthropic และรายอื่น ๆ โดยกล่าวว่าการดึงเนื้อหาที่มีลิขสิทธิ์จำนวนมากไปฝึก LLM ไม่ใช่ "fair use" Anthropic ยอมความในคดีรวมใหญ่ด้วยเงิน 1.5 พันล้านดอลลาร์ในปี 2025—สะท้อนว่าต้นทุนของการดึงข้อมูลเพื่อ AI นั้นเป็นเรื่องจริง
- ข้อแก้ต่างเรื่อง "fair use" ยังไม่มั่นคง ศาลสหรัฐฯ ยังไม่มีคำวินิจฉัยเด็ดขาดว่าการฝึก AI บนข้อมูลที่ดึงมานั้นเป็น fair use หรือไม่ คำตัดสินช่วงแรกบ่งชี้ว่ามันขึ้นอยู่มากกับ วิธี ที่ได้มาซึ่งข้อมูล และ สิ่งที่ ทำกับผลลัพธ์ของ AI
- กฎหมายใหม่กำลังมา (เสนอในเดือนกุมภาพันธ์ 2026) ตั้งเป้าให้บริษัท AI ต้องขออนุญาตและจ่ายเงินให้สำนักพิมพ์ก่อนดึงเนื้อหาของพวกเขา
- EU AI Act (บังคับใช้เต็มรูปแบบ ) กำหนดให้นักพัฒนา AI เปิดเผยแหล่งที่มาของข้อมูลฝึก เคารพการไม่ยินยอมให้ใช้ลิขสิทธิ์ในรูปแบบที่อ่านได้ด้วยเครื่อง (ภายใต้ข้อยกเว้น TDM ของ Copyright Directive) และติดป้ายกำกับเนื้อหาที่สร้างโดย AI นอกจากนี้ยังกำหนดห้ามระบบ AI ที่ดึงภาพใบหน้าจากอินเทอร์เน็ต
- AI/LLM crawler โตระเบิด AI crawler เพิ่มส่วนแบ่งทราฟฟิกเว็บจาก 2.6% เป็น 10.1% ภายในแค่แปดเดือน GPTBot ของ OpenAI เพียงตัวเดียวโตขึ้น 305% เพื่อตอบโต้ เว็บไซต์ใหญ่ ๆ เช่น Amazon, Reddit และ NYT กำลังอัปเดต robots.txt เพื่อบล็อก AI crawler อย่างชัดเจน
สิ่งนี้หมายความว่าอะไรสำหรับคุณ: ถ้าคุณดึงข้อมูลเพื่อวัตถุประสงค์ทางธุรกิจแบบเดิม ๆ เช่น หา leads, เฝ้าราคาสินค้า, หรือศึกษาตลาด กฎเฉพาะด้าน AI เหล่านี้อาจไม่กระทบโดยตรง แต่ถ้าคุณนำข้อมูลที่ดึงมาไปป้อนให้โมเดล AI ต้องระวังให้มาก—และควรขอคำแนะนำทางกฎหมาย
กฎหมาย Web Scraping ทั่วโลก: เปรียบเทียบแบบเร็ว ๆ
มาดูภาพรวมระดับโลกกัน:
- สหรัฐอเมริกา: ไม่มีการห้ามแบบครอบจักรวาล การดึงข้อมูลจากเว็บไซต์ที่เปิดสู่สาธารณะโดยทั่วไปถือว่าทำได้ตามกฎหมาย () และคำตัดสินปี 2024 ในคดี Meta และ X Corp ยิ่งช่วยหนุนกรณีการดึงข้อมูลสาธารณะ แต่การดึงที่อยู่หลังล็อกอินหรือกำแพงเทคนิคยังอาจกระตุ้นให้ CFAA เข้ามาได้ แนวโน้มตอนนี้คือบริษัทเริ่มหันไปใช้ กฎหมายสัญญาและข้อเรียกร้องด้านลิขสิทธิ์ แทน กฎหมายความเป็นส่วนตัวก็ขยายตัวเร็ว: CCPA มีอัปเดตสำคัญมีผล 1 มกราคม 2026 รวมถึงกฎใหม่เรื่องการตัดสินใจอัตโนมัติและภาระของ data broker Indiana, Kentucky และ Rhode Island ก็ออกกฎหมายความเป็นส่วนตัวแบบครอบคลุมในปี 2026 ด้วย
- สหภาพยุโรป: กฎหมายความเป็นส่วนตัวเข้มงวด GDPR ใช้กับข้อมูลส่วนบุคคลที่เปิดเผยต่อสาธารณะด้วย สิทธิในฐานข้อมูลสามารถขวางการดึงข้อมูลเชิงโครงสร้างในวงกว้างได้ (). ใหม่: จะบังคับใช้เต็มรูปแบบในวันที่ 2 สิงหาคม 2026 โดยกำหนดให้นักพัฒนา AI ต้องเปิดเผยแหล่งข้อมูลฝึกและเคารพการไม่ยินยอมให้ใช้ลิขสิทธิ์ กฎหมายนี้ห้ามการดึงภาพใบหน้าจากอินเทอร์เน็ตเพื่อนำไปใช้กับระบบ AI ด้วย
- สหราชอาณาจักร: สะท้อนกฎของ EU หลัง Brexit ข้อมูลสาธารณะดึงได้ แต่การดึงข้อมูลส่วนบุคคลถูกกำกับอย่างเข้มงวด Computer Misuse Act สามารถเอาผิดการเข้าถึงโดยไม่ได้รับอนุญาต
- จีน: เข้มงวดมาก PIPL และ Data Security Law ต้องได้รับความยินยอมสำหรับข้อมูลส่วนบุคคล ศาลใช้กฎหมายการแข่งขันทางการค้าที่ไม่เป็นธรรมเพื่อปิดกั้นการดึงข้อมูลที่กระทบธุรกิจ ().
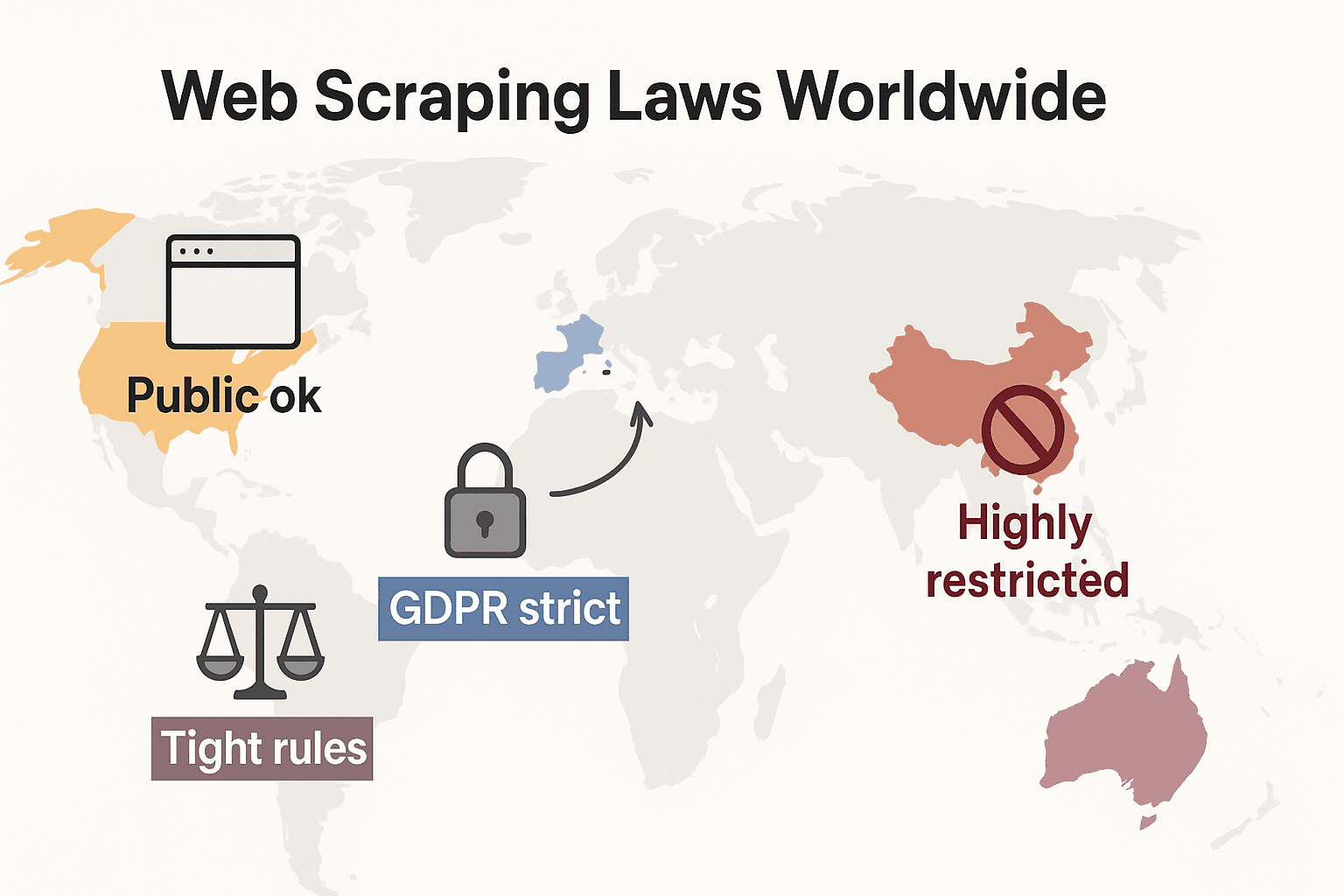
สรุป: การดึงข้อมูลสาธารณะที่ไม่ใช่ข้อมูลส่วนบุคคลเพื่อใช้ภายในองค์กรมักปลอดภัยที่สุด ส่วนอย่างอื่น? ตรวจสอบกฎหมายท้องถิ่นและทำอย่างระมัดระวัง
ความเชื่อผิด ๆ ที่พบบ่อยเกี่ยวกับความถูกกฎหมายของ Web Scraping
มาหักล้างความเชื่อผิด ๆ ที่ผมได้ยินบ่อย ๆ กัน:
- ความเชื่อผิด 1: "Web Scraping ผิดกฎหมายแน่นอน"
ไม่จริง ไม่มีกฎหมายไหนห้าม Web Scraping ทุกกรณี สิ่งที่สำคัญคือคุณดึงอะไรและดึงอย่างไร (). - ความเชื่อผิด 2: "ถ้าข้อมูลเป็นสาธารณะ ฉันจะเอาไปใช้อะไรก็ได้"
ไม่ถึงขนาดนั้น ข้อมูลสาธารณะยังอาจถูกคุ้มครองด้วยกฎหมายความเป็นส่วนตัวหรือลิขสิทธิ์ และ ToS อาจจำกัดการใช้งานบางแบบ (). - ความเชื่อผิด 3: "Web Scraping คือการแฮ็กเหมือนกัน"
ไม่ใช่ การดึงข้อมูลจากหน้าเว็บที่เปิดสาธารณะไม่ใช่การแฮ็ก แต่การเลี่ยงล็อกอินหรือกำแพงทางเทคนิคเป็นอีกเรื่องหนึ่ง (). - ความเชื่อผิด 4: "ถ้าไม่ถูกจับได้ก็โอเค"
ความคิดนี้เสี่ยงมาก หลายเว็บไซต์มีเทคโนโลยีต่อต้านบอทและจะตรวจเจอ ความเงียบไม่ได้แปลว่าอนุญาต - ความเชื่อผิด 5: "ถ้าให้เครดิตหรือใช้ภายในองค์กรก็โอเค"
การให้เครดิตไม่ได้ลบล้างกฎหมายลิขสิทธิ์หรือความเป็นส่วนตัว การใช้ภายในองค์กรปลอดภัยกว่า แต่ไม่ใช่ใบผ่านฟรี - ความเชื่อผิด 6: "Web Scraping ทุกแบบละเมิดความเป็นส่วนตัว"
ไม่ใช่ทุกการดึงข้อมูลจะเกี่ยวกับข้อมูลส่วนบุคคล แต่ถ้าดึงข้อมูลส่วนบุคคลจำนวนมากโดยไม่มีมาตรการป้องกัน มักผิดกฎหมายแทบทุกครั้ง (). - ความเชื่อผิด 7: "ถ้า ToS ของเว็บไซต์ห้ามการดึงข้อมูล แปลว่าการดึงข้อมูลจะผิดกฎหมายเสมอ"
ไม่จำเป็นเสมอไป ในปี 2024 ศาลตัดสินในคดี Meta v. Bright Data และ X Corp v. Bright Data ว่า ToS ไม่สามารถผูกพันผู้ใช้ที่ไม่เคยยอมรับเงื่อนไขนั้นได้—พูดง่าย ๆ คือ ถ้าคุณดึงข้อมูลโดยไม่ล็อกอินหรือไม่สร้างบัญชี ToS ของเว็บนั้นอาจไม่ใช้กับคุณ เรื่องนี้ยังพัฒนาอยู่ แต่ถือเป็นการเปลี่ยนแปลงที่สำคัญ
วิธีดึงข้อมูลอย่างถูกกฎหมาย: แนวปฏิบัติที่ดีที่สุดเพื่อให้สอดคล้องกับกฎ
นี่คือเช็กลิสต์ที่ผมใช้เสมอสำหรับการทำ Web Scraping ที่ถูกกฎหมายและมีจริยธรรม:
- อ่านและเคารพ Terms of Service ของเว็บไซต์ ถ้าระบุว่า "ห้ามดึงข้อมูล" ให้พิจารณาหยุด หรือขออนุญาตก่อน ().
- ยึดเฉพาะข้อมูลสาธารณะ ถ้าต้องใช้รหัสผ่าน แปลว่าถูกจำกัด—อย่าไปดึงมัน ().
- ตรวจ robots.txt และดึงแบบสุภาพ แม้ไม่ผูกพันตามกฎหมาย แต่เป็นมารยาทที่ดี อย่ายิงคำขอใส่เซิร์ฟเวอร์ถี่เกินไป—เว้นช่วงระหว่างคำขอ ().
- หลีกเลี่ยงข้อมูลส่วนบุคคล เว้นแต่คุณมีฐานทางกฎหมาย ถ้าจำเป็นต้องเก็บ ให้ปฏิบัติตาม GDPR/CCPA และเก็บเฉพาะเท่าที่จำเป็น
- อย่านำเนื้อหาที่ดึงมาไปเผยแพร่ซ้ำทั้งชุด เพิ่มคุณค่า การวิเคราะห์ หรือขออนุญาตก่อน ().
- อย่านำเนื้อหาที่ดึงมาไปป้อนโมเดล AI โดยไม่ตรวจเรื่องลิขสิทธิ์ ภูมิทัศน์ทางกฎหมายกำลังเปลี่ยนเร็ว—ถ้านี่คือ use case ของคุณ ควรขอคำแนะนำก่อน
- ใช้ API ทางการหรือการส่งออกข้อมูลเมื่อมีให้ใช้ เพราะออกแบบมาเพื่อจุดประสงค์นี้และมักปลอดภัยกว่า ().
- โปร่งใสและตรวจสอบย้อนกลับได้ ถ้าคุณเก็บข้อมูลส่วนบุคคล ให้แจ้งผู้ใช้และเก็บบันทึกกิจกรรมไว้
- ลดปริมาณข้อมูลและเก็บอย่างปลอดภัย เก็บเฉพาะที่ต้องใช้ รักษาความถูกต้อง และจัดเก็บให้ปลอดภัย
- ติดตามข่าวและขอคำปรึกษาทางกฎหมายเมื่อเป็นกรณีขอบเขต กฎหมายและคำตัดสินเปลี่ยนเร็วมาก—โดยเฉพาะ EU AI Act และกฎหมายความเป็นส่วนตัวระดับรัฐในสหรัฐฯ ถ้าไม่แน่ใจ ให้ถามผู้เชี่ยวชาญ
การใช้เครื่องมือ Web Scraping อย่างถูกกฎหมาย: สิ่งที่ธุรกิจควรรู้
เครื่องมือ Web Scraping อย่าง ช่วยให้คนที่ไม่เขียนโค้ดก็เก็บข้อมูลได้ แต่คุณยังต้องใช้อย่างรับผิดชอบ:
- เลือกเครื่องมือที่เน้นความสอดคล้องกับกฎ เช่น Thunderbit จะดึงเฉพาะสิ่งที่คุณมองเห็นได้ในเบราว์เซอร์—ไม่มีการแฮ็ก API แบบลับ ๆ หรือเข้าถึงโดยไม่ได้รับอนุญาต ().
- ใช้ในกรณีที่เหมาะสมตามกฎหมาย การวิเคราะห์ภายใน งานวิจัยตลาด และการติดตามราคาคู่แข่งมักปลอดภัยกว่า การเผยแพร่ซ้ำหรือขายข้อมูลที่ดึงมาเสี่ยงกว่ามาก
- ตั้งค่าเครื่องมือให้สอดคล้องกับกฎ กำหนดช่วงหน่วงการดึงข้อมูล เคารพ robots.txt และใช้เทมเพลตที่เก็บเฉพาะสิ่งที่ต้องการ
- เก็บไว้ใช้ภายในองค์กร การใช้ข้อมูลภายในปลอดภัยกว่าการนำไปเผยแพร่
- ให้ทีมของคุณเข้าใจกฎ ต้องแน่ใจว่าทุกคนรู้ข้อจำกัดและแนวปฏิบัติที่ดีที่สุด
- ใช้ฟีเจอร์ compliance ที่มีในตัว Thunderbit เตือนผู้ใช้เมื่อเจอเว็บไซต์ที่เสี่ยง ดึงข้อมูลด้วยความเร็วที่เหมือนมนุษย์ และไม่เก็บข้อมูลของคุณไว้บนเซิร์ฟเวอร์ของบริษัท
- อย่าฝืน ถ้าเครื่องมือดึงข้อมูลจากเว็บไซต์หนึ่งไม่ได้ อย่าพยายามหาวิธีแฮ็กอ้อมไปมา ข้อมูลบางอย่างไม่สามารถเอามาได้โดยไม่เสี่ยง
แนวทางของ Thunderbit: เปิดทางสู่การทำ AI Web Scraping ที่สอดคล้องกับกฎหมาย
ที่ เราใช้เวลามากกับเรื่อง compliance นี่คือวิธีที่ AI Web Scraper ของเราช่วยให้ผู้ใช้เดินอยู่บนเส้นที่ถูกต้องตามกฎหมาย:
- ดึงเฉพาะสิ่งที่คุณมองเห็นได้ Thunderbit ทำงานภายในเซสชันเบราว์เซอร์ของคุณ จึงไม่สามารถเข้าถึงข้อมูลที่คุณคัดลอกด้วยตัวเองไม่ได้
- แนะนำผู้ใช้ด้วยคำเตือน ถ้าคุณพยายามดึงข้อมูลจากเว็บไซต์ที่มีกฎต่อต้านการดึงข้อมูลเข้มงวด Thunderbit จะเตือนคุณ
- ความเร็วในการดึงข้อมูลแบบเหมือนมนุษย์ ไม่ว่าคุณจะดึงแบบโลคัลหรือบนคลาวด์ Thunderbit จะหลีกเลี่ยงการยิงคำขอถี่เกินไป
- เลือกข้อมูลได้ปรับแต่งได้ AI ของเราจะเสนอคอลัมน์ที่เกี่ยวข้อง ช่วยให้คุณเก็บเฉพาะที่จำเป็น
- จัดการหน้าย่อยและการแบ่งหน้าได้ Thunderbit เดินเว็บไซต์เหมือนผู้ใช้จริง พร้อมเคารพโครงสร้างของเว็บ
- ความเป็นส่วนตัวและความปลอดภัย ข้อมูลของคุณยังเป็นของคุณ Thunderbit ไม่เก็บหรือเอาไปใช้ซ้ำ
- ส่งออกที่เป็นมิตรต่อ compliance ส่งออกตรงไปยัง Google Sheets, Airtable, Notion หรือ CSV เพื่อใช้งานภายในอย่างปลอดภัย
- การตั้งเวลาและอัตโนมัติ ตั้งให้ดึงข้อมูลซ้ำตามรอบอย่างรับผิดชอบ
- รองรับหลายภาษา UI ของ Thunderbit รองรับ 34 ภาษา ทำให้การปฏิบัติตามกฎเข้าถึงได้ทั่วโลก
- อัปเดตเทมเพลตสม่ำเสมอ เทมเพลตแบบทันทีของเราสำหรับเว็บไซต์ยอดนิยมจะถูกอัปเดตให้สอดคล้องกับการเปลี่ยนแปลงทางกฎหมายและเทคนิค
ด้วยการฝัง compliance ไว้ในตัวผลิตภัณฑ์ Thunderbit ช่วยให้ทีมเก็บข้อมูลที่ต้องการได้ โดยไม่ต้องปวดหัวเรื่องกฎหมาย
ก้าวนำให้ทัน: ปรับตัวต่อการเปลี่ยนแปลงด้านกฎหมายและเทคนิคใน Web Scraping
Web Scraping ไม่ใช่งานแบบตั้งค่าแล้วปล่อยไว้ กฎหมายและโครงสร้างเว็บไซต์เปลี่ยนตลอดเวลา นี่คือวิธีรักษาความนำหน้า:
- ติดตามพัฒนาการทางกฎหมาย ความเร็วของการเปลี่ยนแปลงเร่งขึ้นมากในปี 2024–2026—ติดตามข่าวกฎหมายเทคโนโลยี อัปเดตจากหน่วยงานกำกับดูแล และบล็อกอุตสาหกรรม (เช่น ) จับตาการบังคับใช้ EU AI Act (สิงหาคม 2026) กฎหมายความเป็นส่วนตัวระดับรัฐใหม่ในสหรัฐฯ และคดีลิขสิทธิ์ AI ที่ยังดำเนินอยู่
- ปรับตัวต่อการเปลี่ยนแปลงทางเทคนิค เว็บไซต์ปรับเลย์เอาต์และระบบป้องกันบอทอยู่ตลอด แพลตฟอร์มใหญ่ ๆ เช่น Amazon, X และ Google เข้มงวดขึ้นมากในปี 2025–2026 AI และเทมเพลตของ Thunderbit ถูกออกแบบมาเพื่อปรับตัวอัตโนมัติ
- ใช้ API ทางการเมื่อมีให้ใช้ ถ้าเว็บไซต์เปลี่ยนไปใช้โมเดล API แบบเสียเงิน ลองเปลี่ยนไปใช้เพื่อความเสถียรและสอดคล้องกับกฎ
- ตรวจสอบการทำ Scraping ของคุณเป็นระยะ บันทึกแหล่งข้อมูล ตรวจสอบการเปลี่ยนแปลงของ ToS หรือ policy และปรับกลยุทธ์ตามความเหมาะสม
- ใช้ประโยชน์จากการอัปเดตเทมเพลตของ Thunderbit ทีมของเราคอยอัปเดตเทมเพลตให้ทันสมัย คุณจึงไม่ต้องกังวลกับการเปลี่ยนแปลงที่ทำให้พังหรือข้อกำหนดใหม่ด้าน compliance
- ยืดหยุ่นเข้าไว้ ถ้าแหล่งข้อมูลไหนเสี่ยงเกินไป ให้เปลี่ยนไปใช้อีกแหล่ง หรือหาพันธมิตรแทน
ด้วยเครื่องมือและกรอบความคิดที่เหมาะสม คุณสามารถให้ท่อข้อมูลเดินต่อได้—โดยไม่ไปเหยียบกับระเบิดทางกฎหมาย
สรุป: การนำทางภูมิทัศน์ทางกฎหมายของ Web Scraping
Web Scraping ไม่ได้ผิดกฎหมายโดยตัวของมันเอง—มันคือเครื่องมือทรงพลังสำหรับธุรกิจ การวิจัย และนวัตกรรม แต่เหมือนเครื่องมือทุกชนิด มันมาพร้อมกติกา สิ่งสำคัญคือเข้าใจว่าคุณกำลังดึงอะไร ดึงอย่างไร และจะทำอะไรกับข้อมูลนั้น เคารพกฎหมายท้องถิ่น ปฏิบัติตามนโยบายของเว็บไซต์ และใช้เครื่องมือที่เน้น compliance อย่าง เพื่อให้การทำงานของคุณอยู่เหนือข้อกังวลทางกฎหมาย
คำตัดสินในช่วงปี 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) ช่วยหนุนกรณีการดึงข้อมูลสาธารณะ แต่ความเสี่ยงใหม่ ๆ กำลังเกิดขึ้นรอบข้อมูลฝึก AI ข้อเรียกร้องด้านลิขสิทธิ์ และ EU AI Act นโยบายเฉพาะแพลตฟอร์มก็แตกต่างกันมาก—Google, Amazon, LinkedIn, Meta และ X ต่างบังคับกฎไม่เหมือนกัน—ดังนั้นต้องรู้ภูมิทัศน์ก่อนลงมือ
ถ้าไม่แน่ใจเมื่อไร ให้ขอคำปรึกษาทางกฎหมาย—โดยเฉพาะงานใหญ่หรืองานที่อ่อนไหว และอย่าลืมว่าภูมิทัศน์ทางกฎหมายเปลี่ยนตลอดเวลา จึงต้องติดตามข่าวและปรับตัวให้ไว
อยากเรียนรู้เพิ่มเติมเกี่ยวกับ Web Scraping, compliance และ automation ใช่ไหม? ดู เพื่ออ่านคู่มือเพิ่มเติม หรือทดลองใช้ ด้วยตัวคุณเอง
คำถามที่พบบ่อย
1. Web Scraping ผิดกฎหมายทุกที่ไหม?
ไม่ใช่ Web Scraping ไม่ได้ผิดกฎหมายโดยตัวมันเอง แต่ความถูกกฎหมายขึ้นอยู่กับว่าคุณดึงอะไร ดึงอย่างไร และคุณอยู่ที่ไหน การดึงข้อมูลสาธารณะที่ไม่ใช่ข้อมูลส่วนบุคคลเพื่อใช้ภายในองค์กรโดยทั่วไปทำได้ในหลายภูมิภาค แต่การดึงข้อมูลส่วนบุคคลหรือข้อมูลที่มีลิขสิทธิ์ หรือการละเมิดข้อกำหนดของเว็บไซต์ อาจผิดกฎหมาย ().
2. ถ้าไม่สน robots.txt การทำ Scraping จะผิดกฎหมายไหม?
robots.txt ไม่ได้ผูกพันตามกฎหมาย แต่การเคารพมันเป็นแนวปฏิบัติที่ดีที่สุด การเมิน robots.txt ไม่ได้ทำให้คุณถูกฟ้องโดยตัวมันเอง แต่ถ้ามีข้อพิพาท มันอาจทำให้คุณดูเป็น "ผู้กระทำที่ไม่เหมาะสม" ().
3. ฉันสามารถดึงข้อมูลจาก Google, Amazon หรือ LinkedIn ได้ไหม?
เรื่องนี้ซับซ้อน ทั้งสามแพลตฟอร์มห้ามการดึงข้อมูลใน ToS ของตน แต่ศาลเคยตัดสินว่า ToS อาจไม่ผูกพันผู้ใช้ที่ไม่ได้ล็อกอิน (ดูคดี Meta v. Bright Data และ X Corp v. Bright Data ซึ่งทั้งคู่เกิดในปี 2024) การดึงข้อมูลสาธารณะที่มองเห็นได้ เช่น ราคาสินค้า รายชื่อธุรกิจ หรือโปรไฟล์สาธารณะ โดยทั่วไปยังพอมีเหตุผลรองรับในกฎหมายสหรัฐฯ อย่างไรก็ตาม แต่ละแพลตฟอร์มบังคับใช้กฎต่างกันมาก: Amazon ใช้การดำเนินคดีอย่างเข้มที่สุด (ฟ้อง Perplexity AI ในเดือนพฤศจิกายน 2025), LinkedIn พึ่งกำแพงทางเทคนิคและข้อเรียกร้องด้านสัญญา, ส่วน Google ใช้มาตรการบังคับใช้ผ่าน DMCA มากขึ้นเรื่อย ๆ ต้องดึงอย่างรับผิดชอบและคาดว่าจะเจอมาตรการโต้กลับทางเทคนิค
4. ฉันสามารถดึงข้อมูลจาก Facebook หรือ Instagram ได้ไหม?
หลังคดี Meta v. Bright Data (2024) การดึงข้อมูลสาธารณะจาก Facebook และ Instagram โดยไม่ต้องล็อกอิน มีสถานะทางกฎหมายที่แข็งแรงขึ้น ศาลตัดสินว่า ToS ของ Meta ไม่ใช้กับผู้ที่ไม่ใช่ผู้ใช้ แต่ห้ามสร้างบัญชีปลอมและห้ามดึงข้อมูลที่อยู่หลังหน้าล็อกอินเด็ดขาด—นั่นข้ามเส้นแน่นอน
5. ฉันสามารถดึงข้อมูลจาก X (Twitter) ได้ไหม?
X อัปเดต ToS ในปี 2023 เพื่อห้ามการดึงข้อมูลทุกแบบที่ไม่มีความยินยอมเป็นลายลักษณ์อักษร และยังใช้มาตรการทางเทคนิคอย่างเข้มข้น (Cloudflare Turnstile, จำกัด 300 คำขอ/ชั่วโมง, ให้คะแนนความน่าเชื่อถือของ IP) อย่างไรก็ตาม Bright Data ชนะคดีในประเด็นใกล้เคียงกัน—ข้อมูลสาธารณะที่ดึงโดยไม่มีบัญชีไม่ถูกผูกด้วย ToS ของ X ในทางเทคนิค X เป็นหนึ่งในแพลตฟอร์มที่ดึงยากที่สุดในปี 2026
6. การดึงข้อมูลไปฝึกโมเดล AI ถูกกฎหมายไหม?
นี่คือคำถามที่ยังเปิดอยู่ใหญ่ที่สุดในปี 2026 คดีใหญ่ ๆ เช่น NYT v. OpenAI และข้อตกลง 1.5 พันล้านดอลลาร์ของ Anthropic บ่งบอกถึงความเสี่ยงทางกฎหมายสูง EU AI Act กำหนดให้ต้องเปิดเผยแหล่งข้อมูลฝึกและเคารพการไม่ยินยอมให้ใช้ลิขสิทธิ์ ร่าง AI Accountability for Publishers Act ก็จะบังคับให้ต้องขออนุญาตและจ่ายเงิน หากคุณจะดึงข้อมูลไปฝึก AI ควรขอคำแนะนำทางกฎหมายก่อนดำเนินการ
7. วิธีที่ปลอดภัยที่สุดในการใช้เครื่องมืออย่าง Thunderbit คืออะไร?
ยึดเฉพาะการดึงข้อมูลสาธารณะ เคารพข้อกำหนดของเว็บไซต์ หลีกเลี่ยงข้อมูลส่วนบุคคล เว้นแต่คุณมีฐานทางกฎหมาย และใช้ข้อมูลภายในองค์กร Thunderbit ถูกออกแบบมาเพื่อช่วยให้คุณสอดคล้องกับกฎ โดยดึงเฉพาะสิ่งที่มองเห็นได้ในเบราว์เซอร์และเตือนเมื่อเจอเว็บไซต์ที่เสี่ยง ().
8. ฉันสามารถดึงข้อมูลไปใช้เชิงพาณิชย์ได้ไหม?
ขึ้นอยู่กับกรณี การใช้ข้อมูลที่ดึงมาเพื่อการวิเคราะห์ภายในหรือการวิจัยมักปลอดภัยกว่า การเผยแพร่ซ้ำหรือขายข้อมูลที่ดึงมา โดยเฉพาะถ้าเป็นข้อมูลที่มีลิขสิทธิ์หรือข้อมูลส่วนบุคคล มีความเสี่ยงสูงกว่ามาก และอาจต้องขออนุญาตหรือขอไลเซนส์
9. จะติดตามการเปลี่ยนแปลงทางกฎหมายและเทคนิคใน Web Scraping ได้อย่างไร?
ติดตามข่าวกฎหมายเทคโนโลยี เฝ้าดูการเปลี่ยนแปลงของ ToS หรือ policy บนเว็บไซต์เป้าหมาย และใช้เครื่องมืออย่าง Thunderbit ที่อัปเดตเทมเพลตและฟีเจอร์ compliance อยู่เสมอ สิ่งสำคัญในปี 2026 ที่ควรจับตา: การบังคับใช้ EU AI Act ในเดือนสิงหาคม คดีลิขสิทธิ์ AI ที่ยังดำเนินอยู่ และกฎหมายความเป็นส่วนตัวระดับรัฐใหม่ของสหรัฐฯ ถ้าไม่แน่ใจ ให้ปรึกษาผู้เชี่ยวชาญด้านกฎหมาย